Il s'agit d'un article invité co-écrit avec l'équipe PyTorch de Meta et s'inscrit dans la continuité de Partie 1 de cette série, où nous démontrons les performances et la facilité d'exécution de PyTorch 2.0 sur AWS.
La recherche sur l'apprentissage automatique (ML) a prouvé que les grands modèles de langage (LLM) formés avec des ensembles de données considérablement volumineux permettent d'obtenir une meilleure qualité de modèle. Au cours des dernières années, la taille des modèles de la génération actuelle a considérablement augmenté et ils nécessitent des outils et une infrastructure modernes pour être formés de manière efficace et à grande échelle. Le parallélisme des données distribuées (DDP) de PyTorch permet de traiter les données à grande échelle de manière simple et robuste, mais il nécessite que le modèle tienne sur un seul GPU. La bibliothèque PyTorch Fully Sharded Data Parallel (FSDP) brise cette barrière en permettant le partitionnement de modèles pour former de grands modèles sur des travailleurs parallèles de données.
La formation de modèles distribués nécessite un cluster de nœuds de travail pouvant évoluer. Service Amazon Elastic Kubernetes (Amazon EKS) est un service populaire conforme à Kubernetes qui simplifie considérablement le processus d'exécution des charges de travail IA/ML, le rendant plus gérable et moins long.
Dans cet article de blog, AWS collabore avec l'équipe PyTorch de Meta pour discuter de la façon d'utiliser la bibliothèque PyTorch FSDP pour réaliser une mise à l'échelle linéaire des modèles d'apprentissage profond sur AWS de manière transparente à l'aide d'Amazon EKS et Conteneurs AWS Deep Learning (DLC). Nous le démontrons à travers une mise en œuvre étape par étape de la formation des modèles 7B, 13B et 70B Llama2 à l'aide d'Amazon EKS avec 16 Cloud de calcul élastique Amazon (Amazon EC2) p4de.24xlarge instances (chacune avec 8 GPU NVIDIA A100 Tensor Core et chaque GPU avec 80 Go de mémoire HBM2e) ou 16 EC2 p5.48xlarge instances (chacune avec 8 GPU NVIDIA H100 Tensor Core et chaque GPU avec 80 Go de mémoire HBM3), permettant une mise à l'échelle presque linéaire du débit et permettant finalement un temps de formation plus rapide.
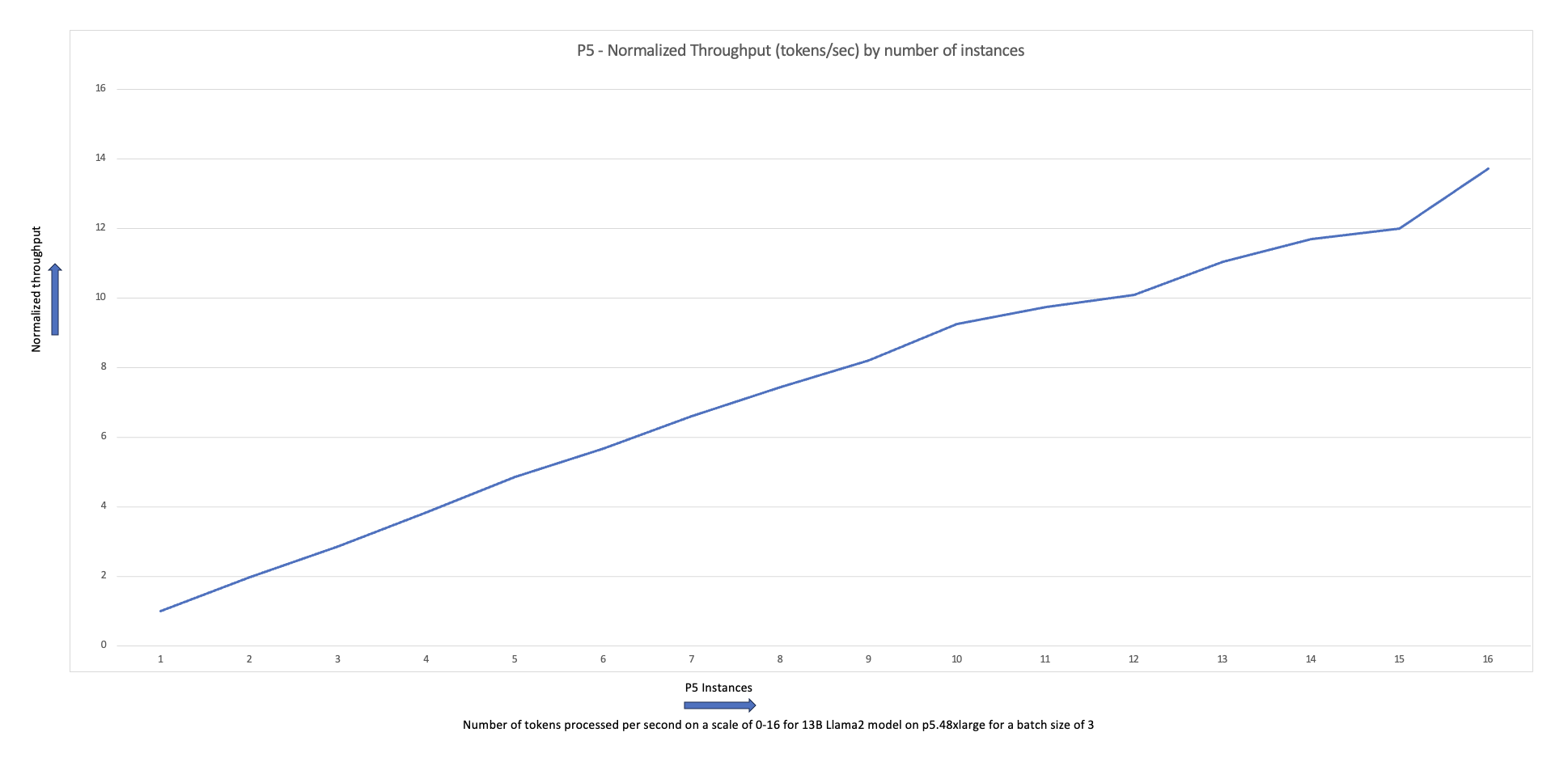
Le graphique de mise à l'échelle suivant montre que les instances p5.48xlarge offrent une efficacité de mise à l'échelle de 87 % avec le réglage fin de FSDP Llama2 dans une configuration de cluster à 16 nœuds.
Les défis de la formation des LLM
Les entreprises adoptent de plus en plus les LLM pour une gamme de tâches, notamment les assistants virtuels, la traduction, la création de contenu et la vision par ordinateur, afin d'améliorer l'efficacité et la précision d'une variété d'applications.
Cependant, la formation ou le réglage précis de ces grands modèles pour un cas d'utilisation personnalisé nécessitent une grande quantité de données et de puissance de calcul, ce qui ajoute à la complexité globale de l'ingénierie de la pile ML. Cela est également dû à la mémoire limitée disponible sur un seul GPU, qui restreint la taille du modèle pouvant être entraîné, ainsi que la taille du lot par GPU utilisé pendant l'entraînement.
Pour relever ce défi, diverses techniques de parallélisme de modèles telles que DeepSpeed Zéro ainsi que PyTorch FSDP ont été créés pour vous permettre de surmonter cette barrière de mémoire GPU limitée. Cela se fait en adoptant une technique parallèle de données fragmentées, dans laquelle chaque accélérateur ne contient qu'une tranche (une tesson) d'une réplique de modèle au lieu de la réplique de modèle entière, ce qui réduit considérablement l'empreinte mémoire de la tâche de formation.
Cet article montre comment utiliser PyTorch FSDP pour affiner le modèle Llama2 à l'aide d'Amazon EKS. Nous y parvenons en augmentant la capacité de calcul et de GPU pour répondre aux exigences du modèle.
Aperçu du PDSF
Dans la formation PyTorch DDP, chaque GPU (appelé travailleur dans le contexte de PyTorch) contient une copie complète du modèle, y compris les poids du modèle, les gradients et les états de l'optimiseur. Chaque travailleur traite un lot de données et, à la fin du retour en arrière, utilise un tout réduire opération pour synchroniser les dégradés entre différents travailleurs.
Le fait d'avoir une réplique du modèle sur chaque GPU limite la taille du modèle pouvant être hébergé dans un flux de travail DDP. FSDP aide à surmonter cette limitation en partitionnant les paramètres du modèle, les états de l'optimiseur et les gradients entre les travailleurs parallèles de données tout en préservant la simplicité du parallélisme des données.
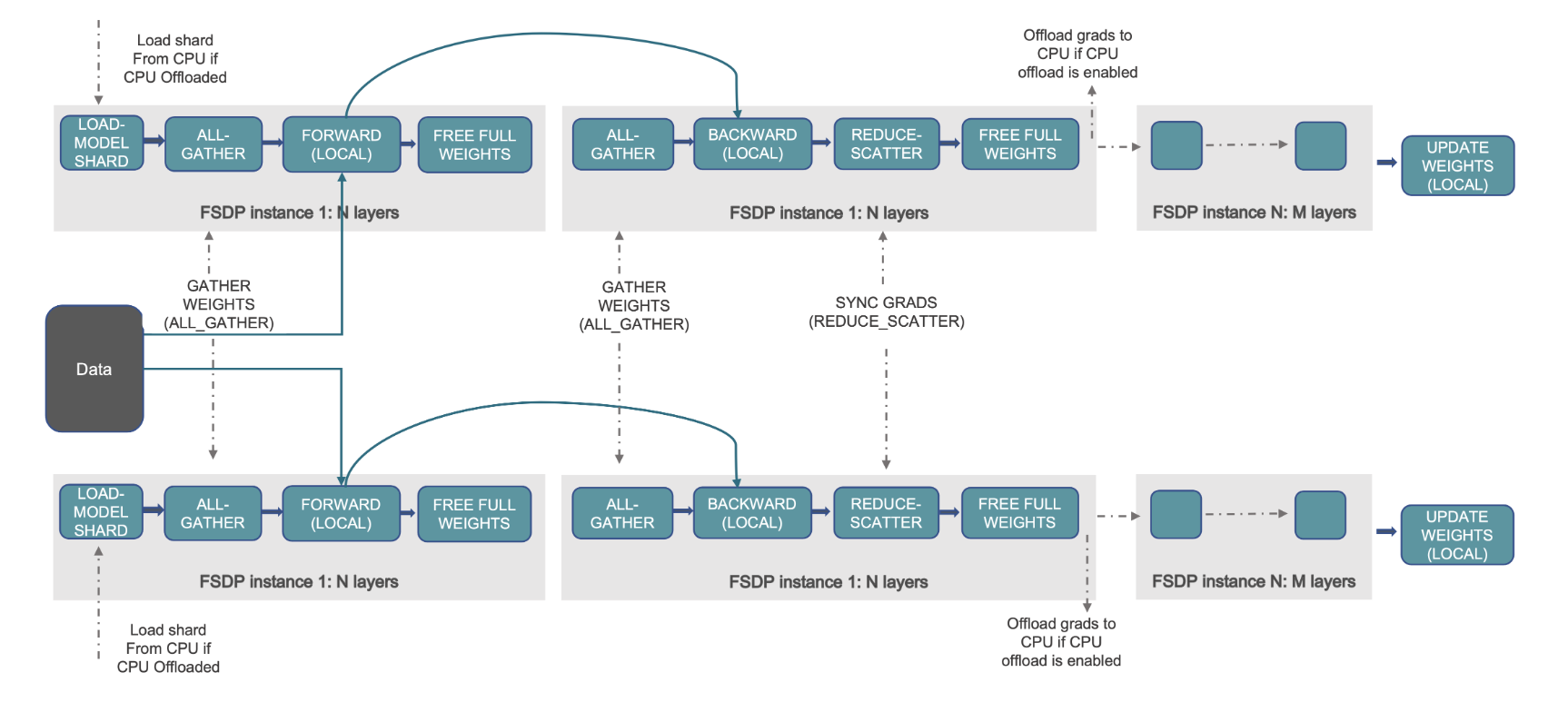
Ceci est démontré dans le diagramme suivant, où dans le cas de DDP, chaque GPU contient une copie complète de l'état du modèle, y compris l'état de l'optimiseur (OS), les gradients (G) et les paramètres (P) : M(OS + G +P). Dans FSDP, chaque GPU ne contient qu'une tranche de l'état du modèle, y compris l'état de l'optimiseur (OS), les gradients (G) et les paramètres (P) : M (OS + G + P). L'utilisation de FSDP entraîne une empreinte mémoire GPU nettement inférieure à celle du DDP pour tous les travailleurs, ce qui permet la formation de très grands modèles ou l'utilisation de lots de plus grande taille pour les tâches de formation.

Cependant, cela se fait au prix d'une surcharge de communication accrue, qui est atténuée grâce aux optimisations FSDP telles que le chevauchement des processus de communication et de calcul avec des fonctionnalités telles que préchargement. Pour des informations plus détaillées, reportez-vous à Premiers pas avec le protocole FSDP (Fully Sharded Data Parallel).
FSDP propose divers paramètres qui vous permettent d'ajuster les performances et l'efficacité de vos tâches de formation. Certaines des fonctionnalités et capacités clés de FSDP incluent :
- Politique d'emballage du transformateur
- Précision mixte flexible
- Point de contrôle d'activation
- Diverses stratégies de partitionnement pour s'adapter à différentes vitesses de réseau et topologies de cluster :
- FULL_SHARD – Paramètres du modèle de fragment, gradients et états de l'optimiseur
- HYBRID_SHARD – Fragment complet au sein d'un nœud DDP entre les nœuds ; prend en charge un groupe de partitionnement flexible pour une réplique complète du modèle (HSDP)
- SHARD_GRAD_OP – Shard uniquement les dégradés et les états de l'optimiseur
- NO_SHARD – Similaire à DDP
Pour plus d'informations sur FSDP, reportez-vous à Formation efficace à grande échelle avec Pytorch FSDP et AWS.
La figure suivante montre comment FSDP fonctionne pour deux processus de données parallèles.
Vue d'ensemble de la solution
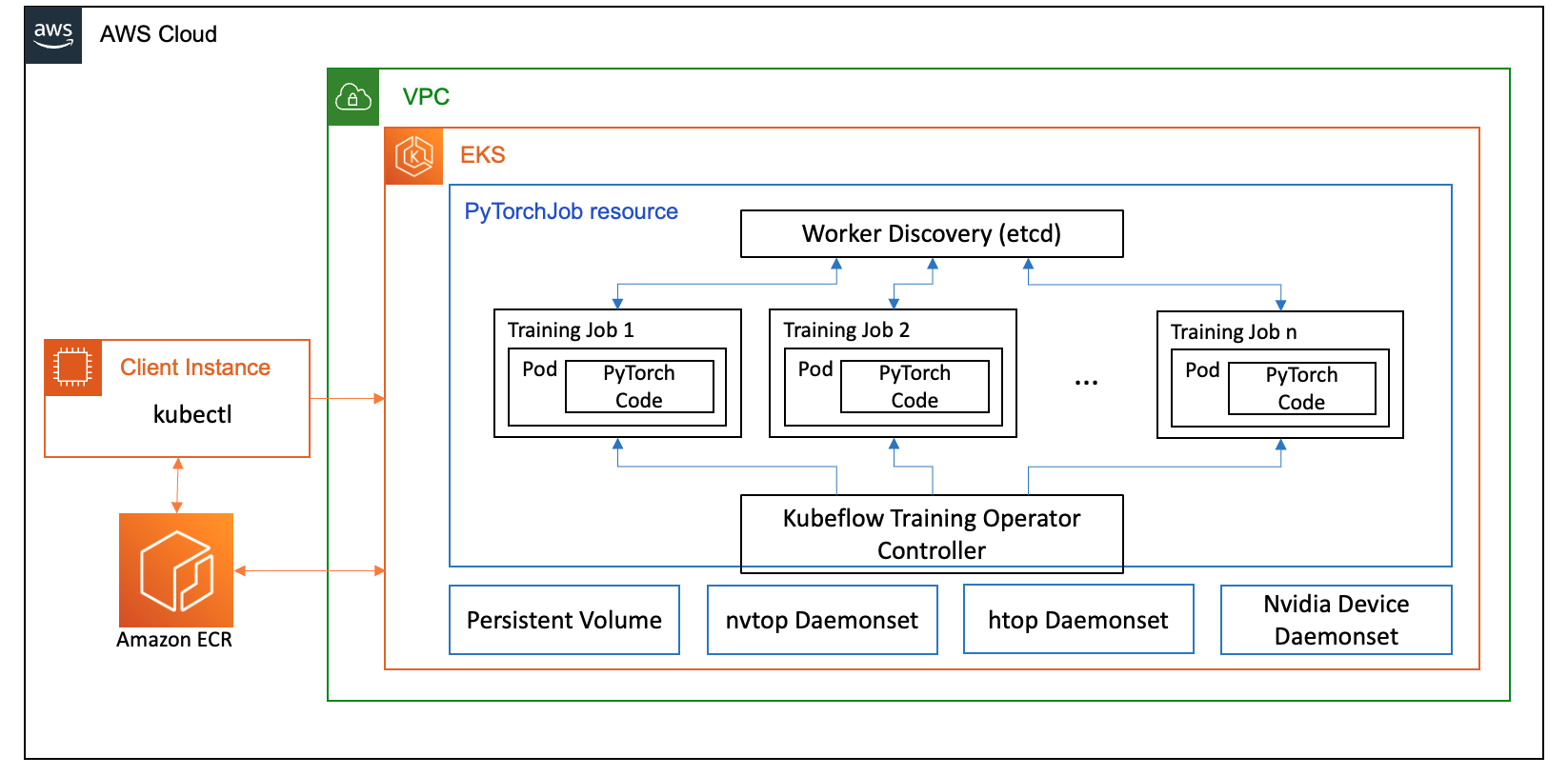
Dans cet article, nous avons configuré un cluster de calcul à l'aide d'Amazon EKS, qui est un service géré pour exécuter Kubernetes dans le cloud AWS et les centres de données sur site. De nombreux clients adoptent Amazon EKS pour exécuter des charges de travail d'IA/ML basées sur Kubernetes, profitant de ses performances, de son évolutivité, de sa fiabilité et de sa disponibilité, ainsi que de ses intégrations avec la mise en réseau, la sécurité et d'autres services AWS.
Pour notre cas d'utilisation FSDP, nous utilisons le Opérateur de formation Kubeflow sur Amazon EKS, qui est un projet natif de Kubernetes qui facilite le réglage fin et la formation distribuée évolutive pour les modèles ML. Il prend en charge divers frameworks ML, notamment PyTorch, que vous pouvez utiliser pour déployer et gérer des tâches de formation PyTorch à grande échelle.
En utilisant la ressource personnalisée PyTorchJob de Kubeflow Training Operator, nous exécutons des tâches de formation sur Kubernetes avec un nombre configurable de réplicas de travail, ce qui nous permet d'optimiser l'utilisation des ressources.
Voici quelques composants de l'opérateur de formation qui jouent un rôle dans notre cas d'utilisation de réglage fin de Llama2 :
- Un contrôleur Kubernetes centralisé qui orchestre les tâches de formation distribuées pour PyTorch.
- PyTorchJob, une ressource personnalisée Kubernetes pour PyTorch, fournie par l'opérateur de formation Kubeflow, pour définir et déployer des tâches de formation Llama2 sur Kubernetes.
- etcd, qui est lié à la mise en œuvre du mécanisme de rendez-vous pour coordonner la formation distribuée des modèles PyTorch. Ce
etcdLe serveur, dans le cadre du processus de rendez-vous, facilite la coordination et la synchronisation des travailleurs participants lors des formations distribuées.
Le diagramme suivant illustre l'architecture de la solution.
La plupart des détails seront résumés par les scripts d'automatisation que nous utilisons pour exécuter l'exemple Llama2.
Nous utilisons les références de code suivantes dans ce cas d'utilisation :
Qu’est-ce que Llama2 ?
Llama2 est un LLM pré-entraîné sur 2 2 milliards de jetons de texte et de code. Il s'agit de l'un des LLM les plus vastes et les plus puissants disponibles aujourd'hui. Vous pouvez utiliser LlamaXNUMX pour diverses tâches, notamment le traitement du langage naturel (NLP), la génération de texte et la traduction. Pour plus d'informations, reportez-vous à Débuter avec Lama.
Llama2 est disponible en trois tailles de modèles différentes :
- Lama2-70b – Il s’agit du plus grand modèle Llama2, avec 70 milliards de paramètres. C'est le modèle Llama2 le plus puissant et peut être utilisé pour les tâches les plus exigeantes.
- Lama2-13b – Il s’agit d’un modèle Llama2 de taille moyenne, avec 13 milliards de paramètres. C'est un bon équilibre entre performance et efficacité et peut être utilisé pour une variété de tâches.
- Lama2-7b – Il s’agit du plus petit modèle Llama2, avec 7 milliards de paramètres. Il s'agit du modèle Llama2 le plus efficace et peut être utilisé pour des tâches qui ne nécessitent pas le plus haut niveau de performance.
Cet article vous permet d'affiner tous ces modèles sur Amazon EKS. Pour fournir une expérience simple et reproductible de création d'un cluster EKS et d'exécution de tâches FSDP dessus, nous utilisons le aws-do-eks projet. L'exemple fonctionnera également avec un cluster EKS préexistant.
Une procédure pas à pas scénarisée est disponible sur GitHub pour une expérience hors des sentiers battus. Dans les sections suivantes, nous expliquons le processus de bout en bout plus en détail.
Provisionner l’infrastructure de la solution
Pour les expériences décrites dans cet article, nous utilisons des clusters avec des nœuds p4de (GPU A100) et p5 (GPU H100).
Cluster avec des nœuds p4de.24xlarge
Pour notre cluster avec des nœuds p4de, nous utilisons ce qui suit eks-gpu-p4de-odcr.yaml script:
En utilisant exctl et le manifeste de cluster précédent, nous créons un cluster avec des nœuds p4de :
Cluster avec des nœuds p5.48xlarge
Un modèle Terraform pour un cluster EKS avec des nœuds P5 se trouve dans ce qui suit GitHub repo.
Vous pouvez personnaliser le cluster via le variables.tf puis créez-le via la CLI Terraform :
Vous pouvez vérifier la disponibilité du cluster en exécutant une simple commande kubectl :
Le cluster est sain si le résultat de cette commande affiche le nombre attendu de nœuds à l'état Prêt.
Conditions préalables au déploiement
Pour exécuter FSDP sur Amazon EKS, nous utilisons le PyTorchJob ressource personnalisée. Cela demande etcd ainsi que Opérateur de formation Kubeflow comme conditions préalables.
Déployez etcd avec le code suivant :
Déployez Kubeflow Training Operator avec le code suivant :
Créer et transmettre une image de conteneur FSDP vers Amazon ECR
Utilisez le code suivant pour créer une image de conteneur FSDP et transférez-la vers Registre des conteneurs élastiques Amazon (Amazon ECR) :
Créer le manifeste FSDP PyTorchJob
Insérez votre Jeton visage câlin dans l'extrait suivant avant de l'exécuter :
Configurez votre PyTorchJob avec .env fichier ou directement dans vos variables d'environnement comme ci-dessous :
Générez le manifeste PyTorchJob à l'aide du modèle FSDP ainsi que générer.sh script ou créez-le directement à l'aide du script ci-dessous :
Exécutez le PyTorchJob
Exécutez le PyTorchJob avec le code suivant :
Vous verrez le nombre spécifié de pods de travail FDSP créés et, après avoir extrait l'image, ils entreront dans un état En cours d'exécution.
Pour voir l'état du PyTorchJob, utilisez le code suivant :
Pour arrêter le PyTorchJob, utilisez le code suivant :
Une fois une tâche terminée, elle doit être supprimée avant de lancer une nouvelle exécution. Nous avons également observé que la suppression duetcdpod et le laisser redémarrer avant de lancer une nouvelle tâche permet d'éviter un RendezvousClosedError.
Mettre à l'échelle le cluster
Vous pouvez répéter les étapes précédentes de création et d'exécution de tâches tout en faisant varier le nombre et le type d'instance de nœuds de travail dans le cluster. Cela vous permet de produire des graphiques de mise à l'échelle comme celui présenté précédemment. En général, vous devriez constater une réduction de l’empreinte mémoire du GPU, une réduction de la durée d’époque et une augmentation du débit lorsque davantage de nœuds sont ajoutés au cluster. Le graphique précédent a été produit en menant plusieurs expériences utilisant un groupe de nœuds p5 variant de 1 à 16 nœuds.
Observer la charge de travail de formation FSDP
L'observabilité des charges de travail d'intelligence artificielle générative est importante pour permettre une visibilité sur vos tâches en cours et pour aider à maximiser l'utilisation de vos ressources de calcul. Dans cet article, nous utilisons à cette fin quelques outils d’observabilité natifs de Kubernetes et open source. Ces outils vous permettent de suivre les erreurs, les statistiques et le comportement des modèles, faisant de l'observabilité de l'IA un élément crucial de tout cas d'utilisation commerciale. Dans cette section, nous montrons différentes approches pour observer les emplois de formation FSDP.
Journaux du pod de travail
Au niveau le plus élémentaire, vous devez pouvoir voir les journaux de vos modules d'entraînement. Cela peut facilement être fait à l’aide de commandes natives Kubernetes.
Tout d’abord, récupérez une liste de pods et localisez le nom de celui pour lequel vous souhaitez voir les journaux :
Affichez ensuite les journaux du pod sélectionné :

Un seul journal de groupe de travailleurs (dirigeant élu) répertoriera les statistiques globales de l'emploi. Le nom du pod leader élu est disponible au début de chaque journal du pod de travailleurs, identifié par la clé master_addr=.
Utilisation de l'UC
Les charges de travail de formation distribuées nécessitent à la fois des ressources CPU et GPU. Pour optimiser ces charges de travail, il est important de comprendre comment ces ressources sont utilisées. Heureusement, d'excellents utilitaires open source sont disponibles pour aider à visualiser l'utilisation du CPU et du GPU. Pour afficher l'utilisation du processeur, vous pouvez utiliserhtop. Si vos pods de travail contiennent cet utilitaire, vous pouvez utiliser la commande ci-dessous pour ouvrir un shell dans un pod, puis exécuterhtop.
Alternativement, vous pouvez déployer un htopdaemonsetcomme celui fourni dans ce qui suit GitHub repo.
Ladaemonsetexécutera un pod htop léger sur chaque nœud. Vous pouvez exécuter dans n'importe lequel de ces pods et exécuter lehtopcommander:
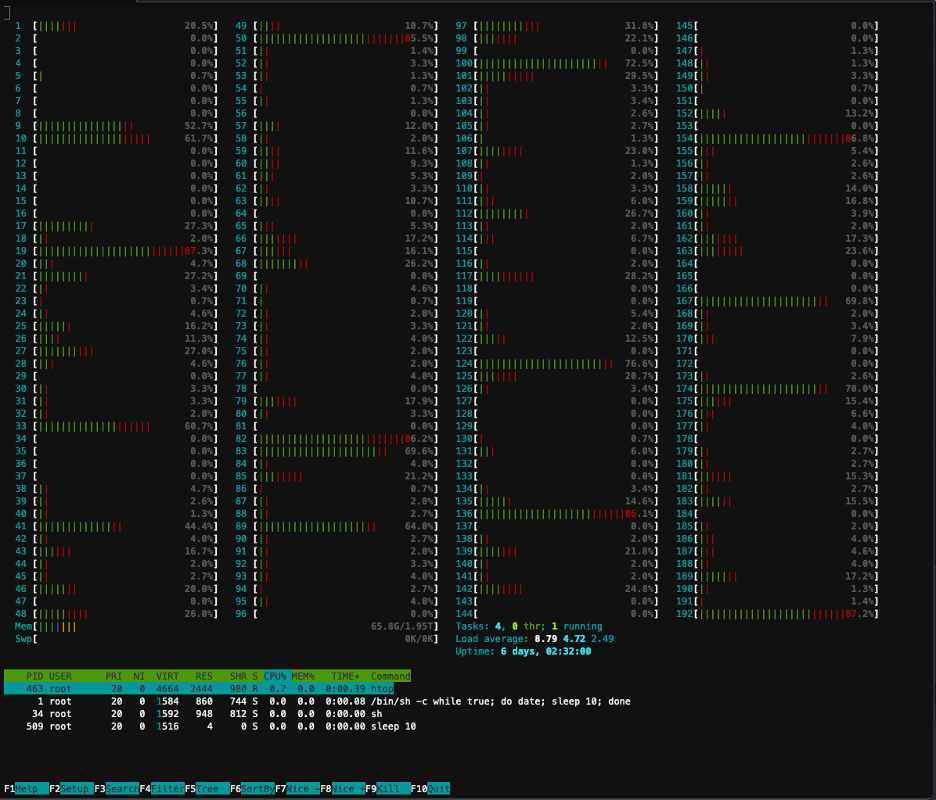
La capture d'écran suivante montre l'utilisation du processeur sur l'un des nœuds du cluster. Dans ce cas, nous examinons une instance P5.48xlarge, dotée de 192 processeurs virtuels. Les cœurs du processeur sont inactifs pendant que les poids des modèles sont téléchargés, et nous constatons une utilisation croissante pendant que les poids des modèles sont chargés dans la mémoire GPU.
Utilisation du processeur graphique
Si lanvtopL'utilitaire est disponible dans votre pod, vous pouvez l'exécuter en utilisant ci-dessous, puis exécuternvtop.
Alternativement, vous pouvez déployer un nvtopdaemonsetcomme celui fourni dans ce qui suit GitHub repo.
Cela exécutera unnvtoppod sur chaque nœud. Vous pouvez exécuter dans n'importe lequel de ces pods et exécuternvtop:
La capture d'écran suivante montre l'utilisation du GPU sur l'un des nœuds du cluster de formation. Dans ce cas, nous examinons une instance P5.48xlarge, dotée de 8 GPU NVIDIA H100. Les GPU sont inactifs pendant que les pondérations du modèle sont téléchargées, puis l'utilisation de la mémoire du GPU augmente à mesure que les pondérations du modèle sont chargées sur le GPU, et l'utilisation du GPU atteint 100 % pendant que les itérations de formation sont en cours.

Tableau de bord Grafana
Maintenant que vous comprenez comment votre système fonctionne au niveau du pod et du nœud, il est également important d'examiner les métriques au niveau du cluster. Les métriques d'utilisation agrégées peuvent être collectées par NVIDIA DCGM Exporter et Prometheus et visualisées dans Grafana.
Un exemple de déploiement Prometheus-Grafana est disponible dans ce qui suit GitHub repo.
Un exemple de déploiement d'exportateur DCGM est disponible dans ce qui suit GitHub repo.
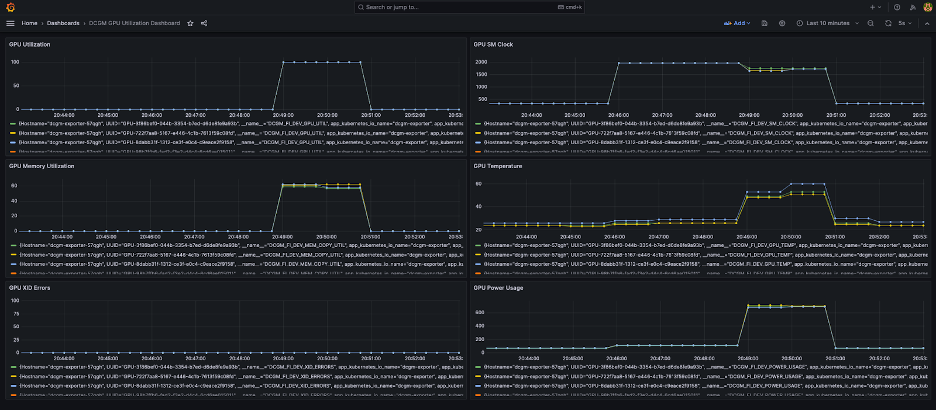
Un simple tableau de bord Grafana est présenté dans la capture d'écran suivante. Il a été construit en sélectionnant les métriques DCGM suivantes : DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPet DCGM_FI_DEV_POWER_USAGE. Le tableau de bord peut être importé dans Prometheus depuis GitHub.
Le tableau de bord suivant montre une exécution d'une tâche de formation à une seule époque Llama2 7b. Les graphiques montrent qu'à mesure que l'horloge du multiprocesseur de streaming (SM) augmente, la consommation d'énergie et la température des GPU augmentent également, ainsi que l'utilisation du GPU et de la mémoire. Vous pouvez également voir qu’il n’y a eu aucune erreur XID et que les GPU étaient sains pendant cette exécution.
Depuis mars 2024, l'observabilité GPU pour EKS est prise en charge nativement dans Informations sur les conteneurs CloudWatch. Pour activer cette fonctionnalité, déployez simplement le module complémentaire CloudWatch Observability dans votre cluster EKS. Vous pourrez ensuite parcourir les métriques au niveau des pods, des nœuds et des clusters via des tableaux de bord préconfigurés et personnalisables dans Container Insights.
Nettoyer
Si vous avez créé votre cluster à l'aide des exemples fournis dans ce blog, vous pouvez exécuter le code suivant pour supprimer le cluster et toutes les ressources qui lui sont associées, y compris le VPC :
Pour eksctl :
Pour la terraformation :
Caractéristiques à venir
FSDP devrait inclure une fonctionnalité de partage par paramètre, visant à améliorer encore son empreinte mémoire par GPU. De plus, le développement continu de la prise en charge du FP8 vise à améliorer les performances FSDP sur les GPU H100. Enfin, lorsque FSDP est intégré àtorch.compile, nous espérons voir des améliorations supplémentaires des performances et l'activation de fonctionnalités telles que les points de contrôle d'activation sélectifs.
Conclusion
Dans cet article, nous avons expliqué comment FSDP réduit l'empreinte mémoire sur chaque GPU, permettant ainsi la formation de modèles plus grands plus efficacement et une mise à l'échelle quasi linéaire du débit. Nous l'avons démontré en implémentant étape par étape la formation d'un modèle Llama2 à l'aide d'Amazon EKS sur des instances P4de et P5 et en utilisant des outils d'observabilité tels que kubectl, htop, nvtop et dcgm pour surveiller les journaux, ainsi que l'utilisation du CPU et du GPU.
Nous vous encourageons à profiter de PyTorch FSDP pour vos propres travaux de formation LLM. Commencez à aws-do-fsdp.
À propos des auteurs
 Kanwaljit Khurmi est architecte principal de solutions IA/ML chez Amazon Web Services. Il travaille avec les clients AWS pour leur fournir des conseils et une assistance technique, les aidant ainsi à améliorer la valeur de leurs solutions d'apprentissage automatique sur AWS. Kanwaljit est spécialisé dans l'aide aux clients avec des applications informatiques conteneurisées et distribuées et d'apprentissage en profondeur.
Kanwaljit Khurmi est architecte principal de solutions IA/ML chez Amazon Web Services. Il travaille avec les clients AWS pour leur fournir des conseils et une assistance technique, les aidant ainsi à améliorer la valeur de leurs solutions d'apprentissage automatique sur AWS. Kanwaljit est spécialisé dans l'aide aux clients avec des applications informatiques conteneurisées et distribuées et d'apprentissage en profondeur.
 Alex Yankoulski est architecte de solutions principal pour l'apprentissage automatique autogéré chez AWS. C'est un ingénieur logiciel et infrastructure full-stack qui aime effectuer un travail approfondi et pratique. Dans son rôle, il se concentre sur l'aide aux clients dans la conteneurisation et l'orchestration des charges de travail de ML et d'IA sur les services AWS basés sur des conteneurs. Il est également l'auteur de l'open source faire un cadre et un capitaine Docker qui aime appliquer les technologies de conteneurs pour accélérer le rythme de l'innovation tout en résolvant les plus grands défis du monde.
Alex Yankoulski est architecte de solutions principal pour l'apprentissage automatique autogéré chez AWS. C'est un ingénieur logiciel et infrastructure full-stack qui aime effectuer un travail approfondi et pratique. Dans son rôle, il se concentre sur l'aide aux clients dans la conteneurisation et l'orchestration des charges de travail de ML et d'IA sur les services AWS basés sur des conteneurs. Il est également l'auteur de l'open source faire un cadre et un capitaine Docker qui aime appliquer les technologies de conteneurs pour accélérer le rythme de l'innovation tout en résolvant les plus grands défis du monde.
 Ana Simoès est un spécialiste principal de l'apprentissage automatique, ML Frameworks chez AWS. Elle aide les clients à déployer l'IA, le ML et l'IA générative à grande échelle sur une infrastructure HPC dans le cloud. Ana se concentre sur l'aide aux clients pour obtenir un rapport qualité-prix pour les nouvelles charges de travail et les cas d'utilisation de l'IA générative et de l'apprentissage automatique.
Ana Simoès est un spécialiste principal de l'apprentissage automatique, ML Frameworks chez AWS. Elle aide les clients à déployer l'IA, le ML et l'IA générative à grande échelle sur une infrastructure HPC dans le cloud. Ana se concentre sur l'aide aux clients pour obtenir un rapport qualité-prix pour les nouvelles charges de travail et les cas d'utilisation de l'IA générative et de l'apprentissage automatique.
 Hamid Shojanazeri est un ingénieur partenaire chez PyTorch travaillant sur l'optimisation de modèles open source hautes performances et la formation distribuée (PDSF), et inférence. Il est le co-créateur de recette de lama et contributeur à TorcheServe. Son principal intérêt est d’améliorer la rentabilité, en rendant l’IA plus accessible à la communauté au sens large.
Hamid Shojanazeri est un ingénieur partenaire chez PyTorch travaillant sur l'optimisation de modèles open source hautes performances et la formation distribuée (PDSF), et inférence. Il est le co-créateur de recette de lama et contributeur à TorcheServe. Son principal intérêt est d’améliorer la rentabilité, en rendant l’IA plus accessible à la communauté au sens large.
 Moins de Wright est un ingénieur IA/partenaire chez PyTorch. Il travaille sur les noyaux Triton/CUDA (Accélérer Dequant avec la décomposition du travail SplitK); optimiseurs paginés, diffusés en continu et quantifiés ; et PyTorch distribué (PyTorch FSDP).
Moins de Wright est un ingénieur IA/partenaire chez PyTorch. Il travaille sur les noyaux Triton/CUDA (Accélérer Dequant avec la décomposition du travail SplitK); optimiseurs paginés, diffusés en continu et quantifiés ; et PyTorch distribué (PyTorch FSDP).
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

