Introduction
Le paysage de intelligence artificielle a été radicalement remodelé au cours des dernières années par l’avènement de grands modèles linguistiques (LLM). Ces outils puissants ont évolué de simples traitements de texte à des systèmes complexes capables de comprendre et de générer du texte de type humain, réalisant des progrès significatifs en termes de capacités et d'applications. À l'avant-garde de cette évolution se trouve la dernière offre de Meta, Llama 3, qui promet de repousser les limites de ce que les modèles ouverts peuvent réaliser en termes d'accessibilité et de performances.
Table des matières
Principales caractéristiques de Lama 3
- Llama 3 maintient une architecture de transformateur uniquement décodeur avec des améliorations significatives, notamment un tokenizer prenant en charge 128,000 XNUMX jetons, améliorant ainsi l'efficacité du codage de la langue.
- Intégré à des modèles de 8 et 70 milliards de paramètres, améliorant l'efficacité de l'inférence pour un traitement ciblé et efficace.
- Llama 3 surpasse ses prédécesseurs et concurrents dans divers critères, excellant dans des tâches telles que MMLU et HumanEval.
- Formé sur un ensemble de données de plus de 15 XNUMX milliards de jetons, sept fois plus grand que Llama 2L'ensemble de données de, intégrant une représentation linguistique diversifiée et des données non anglaises provenant de plus de 30 langues.
- Des lois de mise à l'échelle détaillées optimisent la combinaison de données et les ressources de calcul, garantissant des performances robustes dans diverses applications tout en triplant l'efficacité du processus de formation par rapport à Llama 2.
- Une phase post-formation améliorée combine un réglage fin supervisé, un échantillonnage de rejet et une optimisation des politiques pour améliorer la qualité du modèle et les capacités de prise de décision.
- Disponible sur les principales plates-formes, il présente des fonctionnalités améliorées d'efficacité et de sécurité du tokenizer, permettant aux développeurs d'adapter les applications et d'assurer un déploiement responsable de l'IA.
Parlons de la ville de l'IA
Clément Delangue, Co-fondateur & PDG de HuggingFace
Yann LeCun, professeur à NYU | Scientifique en chef de l'IA chez Meta | Chercheur en IA, Machine Learning, Robotique, etc. | Lauréat du prix ACM Turing.
Andrej Karpathy, équipe fondatrice d'OpenAI
Méta Lama 3 représente la dernière avancée dans la série de modèles de langage de Meta, marquant une avancée significative dans l'évolution de l'IA générative. Disponible dès maintenant, cette nouvelle génération comprend des modèles avec 8 milliards et 70 milliards de paramètres, chacun conçu pour exceller dans une large gamme d'applications. Qu'il s'agisse de conversations quotidiennes ou de tâches de raisonnement complexes, Llama 3 établit une nouvelle norme en matière de performances, surpassant ses prédécesseurs dans de nombreux critères de référence de l'industrie. Llama 3 est accessible gratuitement, permettant à la communauté de stimuler l'innovation en matière d'IA, du développement d'applications à l'amélioration des outils de développement et au-delà.
Architecture du modèle et améliorations de Llama 2
Llama 3 conserve l'architecture éprouvée du transformateur uniquement par décodeur tout en incorporant des améliorations significatives qui élèvent ses fonctionnalités au-delà de celles de Llama 2. Adhérant à une philosophie de conception cohérente, Llama 3 comprend un tokenizer qui prend en charge un vocabulaire étendu de 128,000 3 jetons, améliorant considérablement l'efficacité du modèle. dans le langage de codage. Cette évolution se traduit par des performances globales nettement améliorées. De plus, pour améliorer l'efficacité de l'inférence, Llama 8 intègre l'attention de requête groupée (GQA) dans ses modèles de 70 et 8,192 milliards de paramètres. Ce modèle utilise également des séquences de 3 XNUMX jetons avec une technique de masquage qui empêche l’attention personnelle de s’étendre au-delà des limites du document, garantissant ainsi un traitement plus ciblé et plus efficace. Ces améliorations améliorent collectivement la capacité de Llama XNUMX à gérer un plus large éventail de tâches avec une précision et une efficacité accrues.
| Fonctionnalité | Llama 2 | Llama 3 |
| Plage de paramètres | Paramètres 7B à 70B | Paramètres 8B et 70B, avec des plans pour 400B+ |
| Architecture du modèle | Basé sur l'architecture du transformateur | Architecture de transformateur standard pour décodeur uniquement |
| Efficacité de la tokenisation | Longueur du contexte jusqu'à 4096 jetons | Utilise un tokenizer avec un vocabulaire de 128 XNUMX jetons |
| Données d'entraînement | 2 XNUMX milliards de jetons provenant de sources accessibles au public | Plus de 15 T de jetons provenant de sources accessibles au public |
| Efficacité de l'inférence | Améliorations comme GQA pour le modèle 70B | Attention aux requêtes groupées (GQA) pour une efficacité améliorée |
| Méthodes de réglage fin | Mise au point supervisée et RLHF | Mise au point supervisée (SFT), échantillonnage de rejet, PPO, DPO |
| Considérations de sécurité et d’éthique | Sûr selon des tests rapides contradictoires | Une équipe rouge étendue pour la sécurité |
| Open Source et accessibilité | Licence communautaire avec certaines restrictions | Vise une approche ouverte pour favoriser un écosystème d’IA |
| Cas d'usage | Optimisé pour le chat et la génération de code | Large utilisation dans plusieurs domaines en mettant l'accent sur le suivi des instructions |
Résultats d'analyse comparative par rapport à d'autres modèles
Llama 3 a placé la barre plus haut en matière d'IA générative, surpassant ses prédécesseurs et ses concurrents dans une variété de critères. Il a particulièrement excellé dans des tests tels que MMLU, qui évalue les connaissances dans divers domaines, et HumanEval, axé sur les compétences en codage. De plus, Llama 3 a surpassé d'autres modèles à paramètres élevés comme Gemini 1.5 Pro de Google et Claude 3 Sonnet d'Anthropic, en particulier dans les tâches complexes de raisonnement et de compréhension.
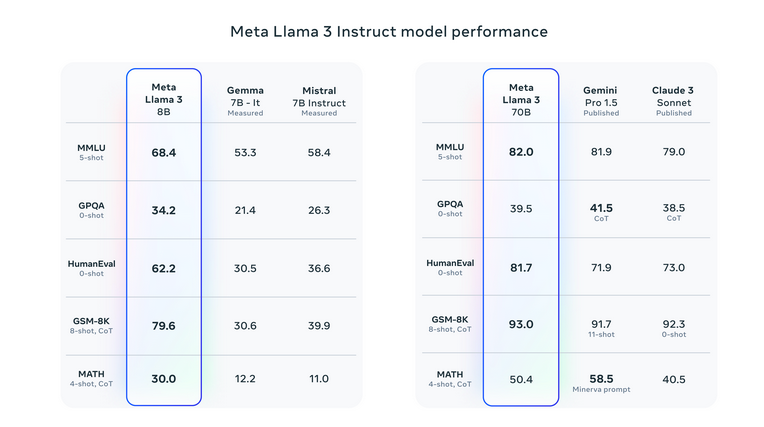
S'il te plait regarde détails de l'évaluation pour le réglage et les paramètres avec lesquels ces évaluations sont calculées.
Évaluation sur des ensembles de tests standard et personnalisés
Meta a créé des ensembles d'évaluation uniques au-delà des références traditionnelles pour tester Llama 3 sur diverses applications du monde réel. Ce cadre d'évaluation sur mesure comprend 1,800 12 invites couvrant 3 cas d'utilisation critiques : donner des conseils, réfléchir, classer, répondre à des questions fermées et ouvertes, codage, composition créative, extraction de données, jeux de rôle, raisonnement logique, réécriture de texte et résumé. Restreindre l'accès à cet ensemble spécifique, même pour les équipes de modélisation de Meta, protège contre un éventuel surajustement du modèle. Cette approche de tests rigoureux a prouvé les performances supérieures de Llama XNUMX, surpassant souvent les autres modèles. Soulignant ainsi son adaptabilité et sa compétence.
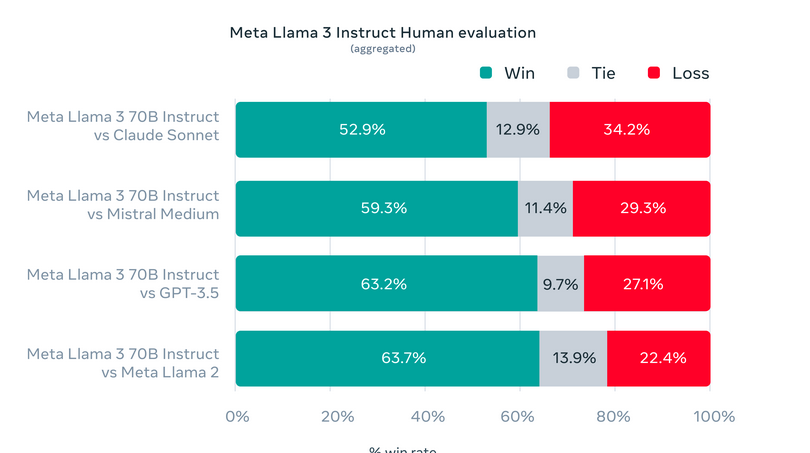
S'il te plait regarde détails de l'évaluation pour le réglage et les paramètres avec lesquels ces évaluations sont calculées.
Données de formation et stratégies de mise à l’échelle
Explorons maintenant les données de formation et les stratégies de mise à l'échelle :
Données d'entraînement
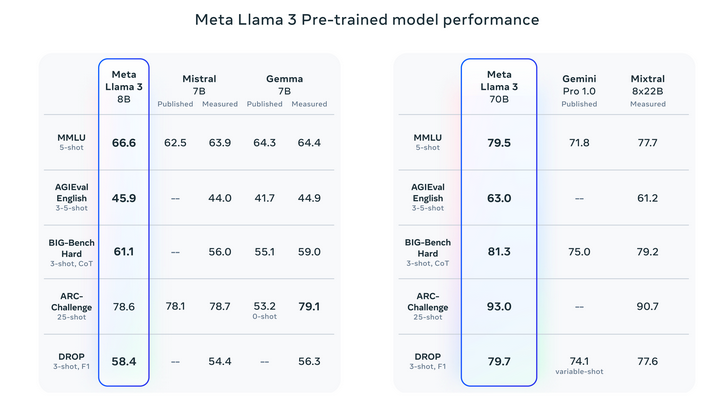
- L'ensemble de données d'entraînement de Llama 3, plus de 15 2 milliards de jetons, est sept fois supérieur à celui de Llama XNUMX.
- L'ensemble de données comprend quatre fois plus de code et plus de 5 % de données non anglaises de haute qualité provenant de 30 langues. Assurer une représentation linguistique diversifiée pour les applications multilingues.
- Pour maintenir la qualité des données, Meta utilise des pipelines de filtrage de données sophistiqués, notamment des filtres heuristiques, des filtres NSFW, une déduplication sémantique et des classificateurs de texte.
- Tirant parti des informations issues des modèles Llama précédents, ces systèmes améliorent la formation de Llama 3 en identifiant et en incorporant des données de qualité.
Stratégies de mise à l'échelle
- Meta s'est concentré sur la maximisation de l'utilité de l'ensemble de données de Llama 3 en développant des lois de mise à l'échelle détaillées.
- L'optimisation de la combinaison de données et des ressources informatiques a permis de prédire avec précision les performances du modèle pour diverses tâches.
- La prospective stratégique garantit des performances robustes dans diverses applications telles que les quiz, les STEM, le codage et les connaissances historiques.
- Insights a révélé la quantité optimale de calcul d’entraînement pour Chinchilla pour le modèle de paramètres 8B, soit environ 200 milliards de jetons.
- Les modèles 8B et 70B continuent d’améliorer leurs performances de manière linéaire avec jusqu’à 15 XNUMX milliards de jetons.
- Meta a atteint plus de 400 TFLOPS par GPU en utilisant 16,000 24,000 GPU simultanément sur XNUMX XNUMX clusters GPU personnalisés.
- Les innovations dans l'infrastructure de formation comprennent la détection automatisée des erreurs, la maintenance du système et des solutions de stockage évolutives.
- Ces avancées ont triplé l'efficacité de l'entraînement de Llama 3 par rapport à Llama 2, atteignant un temps d'entraînement effectif de plus de 95 %.
- Ces améliorations établissent de nouvelles normes pour la formation de grands modèles de langage, repoussant ainsi les limites de l'IA.
Instruction de réglage fin
- Le réglage des instructions améliore la fonctionnalité des modèles de discussion pré-entraînés.
- Le processus combine le réglage fin supervisé, l’échantillonnage par rejet, le PPO et le DPO.
- Les invites dans SFT et les classements de préférences dans PPO/DPO sont cruciaux pour les performances du modèle.
- Conservation méticuleuse des données et assurance qualité par des annotateurs humains.
- Les classements de préférences dans PPO/DPO améliorent les performances des tâches de raisonnement et de codage.
- Modèles capables de produire des réponses correctes mais peuvent avoir des difficultés avec la sélection.
- La formation avec classement des préférences améliore la prise de décision dans les tâches complexes.
Déploiement de Llama3
Llama 3 est configuré pour une disponibilité généralisée sur les principales plates-formes, y compris les services cloud et les fournisseurs d'API modèles. Il présente une efficacité améliorée du tokenizer, réduisant l'utilisation des jetons jusqu'à 15 % par rapport à Llama 2, et intègre Group Query Attention (GQA) dans le modèle 8B pour maintenir l'efficacité de l'inférence, même avec 1 milliard de paramètres supplémentaires par rapport à Llama 2 7B. Le logiciel open source « Llama Recipes » offre des ressources complètes pour des stratégies pratiques de déploiement et d'optimisation, prenant en charge l'application polyvalente de Llama 3.
Améliorations et fonctionnalités de sécurité dans Llama 3
Llama 3 est conçu pour donner aux développeurs les outils et la flexibilité nécessaires pour adapter les applications en fonction de besoins spécifiques. Il améliore l’écosystème ouvert de l’IA. Cette version introduit de nouveaux outils de sécurité et de confiance, notamment Llama Guard 2, Cybersec Eval 2 et Code Shield, qui aident à filtrer le code non sécurisé lors de l'inférence. Llama 3 a été développé en partenariat avec torchtune, une bibliothèque native de PyTorch qui permet une création, un réglage précis et des tests efficaces et respectueux de la mémoire des LLM. Cette bibliothèque prend en charge l'intégration avec des plates-formes telles que Hugging Face et Weights & Biases. Il facilite également une inférence efficace sur divers appareils via Executorch.
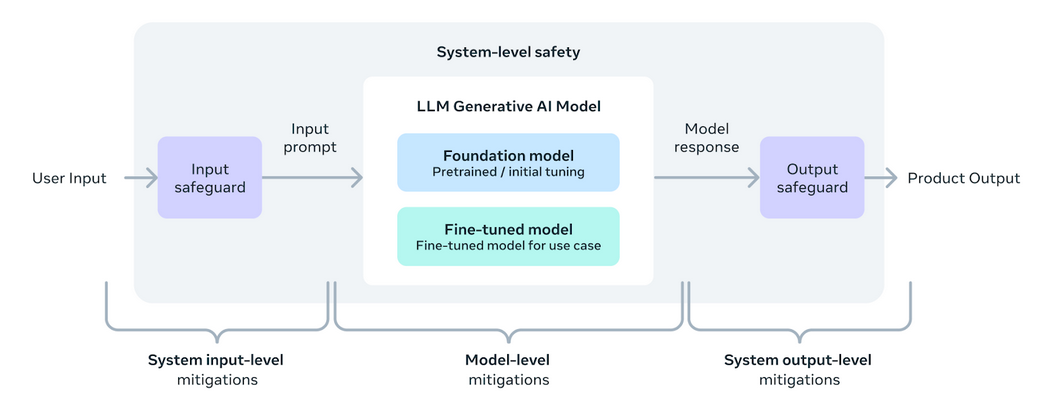
Une approche systémique du déploiement responsable garantit que les modèles Llama 3 sont non seulement utiles mais également sûrs. Le réglage fin des instructions est un élément clé, considérablement amélioré par les efforts d'équipe rouge qui testent la sécurité et la robustesse contre une utilisation abusive potentielle dans des domaines tels que la cybersécurité. L'introduction de Llama Guard 2 intègre la taxonomie MLCommons pour prendre en charge l'établissement de normes industrielles, tandis que CyberSecEval 2 améliore les mesures de sécurité contre l'utilisation abusive du code.
L'adoption d'une approche ouverte dans le développement de Llama 3 vise à unir la communauté de l'IA et à répondre efficacement aux risques potentiels. La méta est mise à jour Guide d'utilisation responsable (RUG) décrit les meilleures pratiques pour garantir que toutes les entrées et sorties du modèle respectent les normes de sécurité, complétées par les outils de modération de contenu proposés par les fournisseurs de cloud. Ces efforts collectifs visent à favoriser une utilisation sûre, responsable et innovante des LLM dans diverses applications.
Développements futurs pour Llama 3
La version initiale des modèles Llama 3, y compris les versions 8B et 70B. Ce n'est que le début des développements prévus pour cette série. Meta forme actuellement des modèles encore plus grands avec plus de 400 milliards de paramètres. Ces modèles promettront des capacités améliorées, telles que la multimodalité, la communication multilingue, des fenêtres contextuelles étendues et des performances globales plus élevées. Dans les mois à venir, ces modèles avancés seront introduits. Accompagné d'un document de recherche détaillé décrivant les résultats de la formation de Llama 3. Meta a partagé les premiers instantanés de la formation en cours de leur plus grand modèle LLM, offrant un aperçu des versions futures.
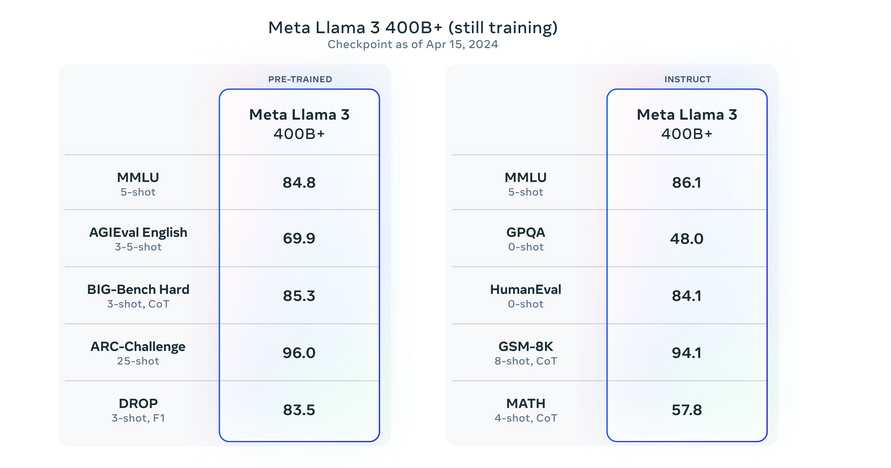
S'il te plait regarde détails de l'évaluation pour le réglage et les paramètres avec lesquels ces évaluations sont calculées.
Impact et approbation de Llama 3
- Llama 3 est rapidement devenu le modèle le plus rapide à atteindre la première place des tendances sur Hugging Face. Atteindre ce record quelques heures seulement après sa sortie.
Cliquez ici pour accéder au lien.
- Après le développement de 30,000 1 modèles de Llama 2 et 3, Llama XNUMX est sur le point d’avoir un impact significatif sur l’écosystème de l’IA.
- Les principales plateformes d'IA et de cloud comme AWS, Microsoft Azure, Google Cloud et Hugging Face ont rapidement intégré Llama 3.
- La présence du modèle sur Kaggle élargit son accessibilité, encourageant une exploration et un développement plus pratiques au sein de la communauté de la science des données.
- Disponible sur LlamaIndex, cette ressource compilée par des experts comme @ravithejads et @LoganMarkewich fournit des conseils détaillés sur l'utilisation de Llama 3 dans une gamme d'applications, des tâches simples aux pipelines RAG complexes. Cliquez ici pour lien d'accès.
Conclusion
Llama 3 établit une nouvelle norme dans l'évolution des grands modèles linguistiques. Ils améliorent les capacités de l’IA dans une gamme de tâches grâce à son architecture et son efficacité avancées. Ses tests complets démontrent des performances supérieures, surpassant les modèles prédécesseurs et contemporains. Avec des stratégies de formation robustes et des mesures de sécurité innovantes comme Llama Guard 2 et Cybersec Eval 2. Llama 3 souligne l'engagement de Meta en faveur du développement responsable de l'IA. À mesure que Llama 3 devient largement disponible, il promet de générer des progrès significatifs dans les applications d’IA. Offrant également aux développeurs un outil puissant pour explorer et repousser les frontières technologiques.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/04/meta-llama-3-redefining-large-language-model-standards/

