Ces dernières années, les lacs de données sont devenus une architecture courante et la validation de la qualité des données est un facteur essentiel pour améliorer la réutilisabilité et la cohérence des données. Qualité des données AWS Glue réduit les efforts requis pour valider les données de quelques jours à quelques heures et fournit des recommandations informatiques, des statistiques et des informations sur les ressources requises pour exécuter la validation des données.
AWS Glue Data Quality repose sur DeeQu, un outil open source développé et utilisé chez Amazon pour calculer les mesures de qualité des données et vérifier les contraintes de qualité des données et les changements dans la distribution des données afin que vous puissiez vous concentrer sur la description de l'apparence des données au lieu de mettre en œuvre des algorithmes.
Dans cet article, nous fournissons des résultats de référence sur l'exécution d'ensembles de règles de qualité de données de plus en plus complexes sur un ensemble de données de test prédéfini. Dans le cadre des résultats, nous montrons comment AWS Glue Data Quality fournit des informations sur le temps d'exécution des tâches d'extraction, de transformation et de chargement (ETL), les ressources mesurées en termes d'unités de traitement de données (DPU) et comment vous pouvez suivre le coût. d'exécuter AWS Glue Data Quality pour les pipelines ETL en définissant des rapports de coûts personnalisés dans AWS Cost Explorer.
Vue d'ensemble de la solution
Nous commençons par définir notre ensemble de données de test afin d'explorer comment AWS Glue Data Quality évolue automatiquement en fonction des ensembles de données d'entrée.
Détails de l'ensemble de données
L'ensemble de données de test contient 104 colonnes et 1 million de lignes stockées au format Parquet. Tu peux télécharger le jeu de données ou recréez-le localement à l'aide du script Python fourni dans le dépôt. Si vous choisissez d'exécuter le script du générateur, vous devez installer le Pandas ainsi que Mimesis packages dans votre environnement Python :
Le schéma de l'ensemble de données est une combinaison de variables numériques, catégorielles et de chaîne afin d'avoir suffisamment d'attributs pour utiliser une combinaison de qualité de données AWS Glue intégrée. types de règles. Le schéma reproduit certains des attributs les plus courants trouvés dans les données des marchés financiers, tels que le ticker des instruments, les volumes négociés et les prévisions de prix.
Ensembles de règles de qualité des données
Nous catégorisons certains des types de règles AWS Glue Data Quality intégrés pour définir la structure de référence. Les catégories déterminent si les règles effectuent des vérifications de colonnes qui ne nécessitent pas d'inspection au niveau des lignes (règles simples), d'analyse ligne par ligne (règles moyennes) ou de vérifications de type de données, en comparant éventuellement les valeurs des lignes avec d'autres sources de données (règles complexes). ). Le tableau suivant résume ces règles.
| Règles simples | Règles moyennes | Règles complexes |
| Nombre de colonnes | DistinctValuesCount | Valeurs de colonnes |
| Type de données de colonne | Est complet | état complet |
| ColonneExiste | Somme | Intégrité Référentielle |
| ColumnNamesMatchPattern | Écart-type | Corrélation des colonnes |
| Nombre de lignes | Médian | RowCountMatch |
| Longueur de colonne | . | . |
Nous définissons huit tâches ETL AWS Glue différentes dans lesquelles nous exécutons les ensembles de règles de qualité des données. Chaque tâche est associée à un nombre différent de règles de qualité des données. Chaque travail est également associé à un balise de répartition des coûts définie par l'utilisateur que nous utilisons pour créer ultérieurement un rapport sur les coûts de qualité des données dans AWS Cost Explorer.
Nous fournissons la définition en texte brut de chaque ensemble de règles dans le tableau suivant.
| Nom du travail | Règles simples | Règles moyennes | Règles complexes | Nombre de règles | Jour | Définition |
| ensemble de règles-0 | 0 | 0 | 0 | 0 | dqjob:rs0 | - |
| ensemble de règles-1 | 0 | 0 | 1 | 1 | dqjob:rs1 | Lien |
| ensemble de règles-5 | 3 | 1 | 1 | 5 | dqjob:rs5 | Lien |
| ensemble de règles-10 | 6 | 2 | 2 | 10 | dqjob:rs10 | Lien |
| ensemble de règles-50 | 30 | 10 | 10 | 50 | dqjob:rs50 | Lien |
| ensemble de règles-100 | 50 | 30 | 20 | 100 | dqjob:rs100 | Lien |
| ensemble de règles-200 | 100 | 60 | 40 | 200 | dqjob:rs200 | Lien |
| ensemble de règles-400 | 200 | 120 | 80 | 400 | dqjob:rs400 | Lien |
Créez les tâches AWS Glue ETL contenant les ensembles de règles de qualité des données
Nous téléchargeons le ensemble de données de test à Service de stockage simple Amazon (Amazon S3) ainsi que deux fichiers CSV supplémentaires que nous utiliserons pour évaluer les règles d'intégrité référentielle dans AWS Glue Data Quality (isocodes.csv ainsi que échanges.csv) après avoir été ajoutés au catalogue de données AWS Glue. Effectuez les étapes suivantes :
- Sur la console Amazon S3, créez un nouveau compartiment S3 dans votre compte et téléchargez le ensemble de données de test.
- Créez un dossier dans le compartiment S3 appelé
isocodeset télécharger le isocodes.csv fichier. - Créez un autre dossier dans le compartiment S3 appelé Exchange et téléchargez le échanges.csv fichier.
- Sur la console AWS Glue, exécutez deux robots d'exploration AWS Glue, un pour chaque dossier afin d'enregistrer le contenu CSV dans AWS Glue Data Catalog (
data_quality_catalog). Pour obtenir des instructions, reportez-vous à Ajout d'un robot d'exploration AWS Glue.
Les robots d'exploration AWS Glue génèrent deux tables (exchanges ainsi que isocodes) dans le cadre du catalogue de données AWS Glue.

Nous allons maintenant créer le Gestion des identités et des accès AWS (JE SUIS) rôle de l' qui sera assumé par les tâches ETL au moment de l'exécution :
- Sur la console IAM, créez un nouveau rôle IAM appelé
AWSGlueDataQualityPerformanceRole - Pour Type d'entité de confiance, sélectionnez Service AWS.
- Pour Service ou cas d'utilisation, choisissez Colle.
- Selectionnez Suivant.

- Pour Politiques d'autorisation, Entrer
AWSGlueServiceRole - Selectionnez Suivant.

- Créez et attachez une nouvelle stratégie en ligne (
AWSGlueDataQualityBucketPolicy) avec le contenu suivant. Remplacez l'espace réservé par le nom du compartiment S3 que vous avez créé précédemment :
Ensuite, nous créons l'une des tâches AWS Glue ETL, ruleset-5.
- Sur la console AWS Glue, sous Emplois ETL dans le volet de navigation, choisissez ETL visuel.
- Dans le Créer un emploi section, choisissez ETL visuel.x

- Dans l'éditeur visuel, ajoutez un Source de données – Compartiment S3 nœud source :
- Pour URL S3, entrez le dossier S3 contenant l'ensemble de données de test.
- Pour Format de données, choisissez Parquet.

- Créez un nouveau nœud d'action, Transformer : évaluer-données-catalogue:
- Pour Parents de nœud, choisissez le nœud que vous avez créé.
- Ajoutez le définition de l'ensemble de règles-5 sous Éditeur d'ensemble de règles.

- Faites défiler jusqu'à la fin et sous Configuration des performances, activer Données de cache.

- Sous Détails du poste, Pour Rôle IAM, choisissez
AWSGlueDataQualityPerformanceRole.
- Dans le Tags section, définir dqjob marquer comme rs5.
Cette balise sera différente pour chacune des tâches ETL de qualité des données ; nous les utilisons dans AWS Cost Explorer pour examiner le coût des tâches ETL.

- Selectionnez Épargnez.
- Répétez ces étapes avec le reste des ensembles de règles pour définir toutes les tâches ETL.

Exécuter les tâches AWS Glue ETL
Effectuez les étapes suivantes pour exécuter les tâches ETL :
- Sur la console AWS Glue, choisissez ETL visuel sous Emplois ETL dans le volet de navigation.
- Sélectionnez le travail ETL et choisissez Exécuter le travail.
- Répétez l’opération pour toutes les tâches ETL.

Une fois les tâches ETL terminées, le Surveillance de l'exécution des tâches La page affichera les détails du travail. Comme le montre la capture d'écran suivante, un Heures DPU La colonne est fournie pour chaque tâche ETL.

Examiner les performances
Le tableau suivant résume la durée, les heures DPU et les coûts estimés liés à l'exécution des huit ensembles de règles de qualité de données différents sur le même ensemble de données de test. Notez que tous les ensembles de règles ont été exécutés avec l'intégralité de l'ensemble de données de test décrit précédemment (104 colonnes, 1 million de lignes).
| Nom du travail ETL | Nombre de règles | Jour | Durée (sec) | Nombre d'heures DPU | Nombre de DPU | Coût ($) |
| ensemble de règles-400 | 400 | dqjob:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| ensemble de règles-200 | 200 | dqjob:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| ensemble de règles-100 | 100 | dqjob:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| ensemble de règles-50 | 50 | dqjob:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| ensemble de règles-10 | 10 | dqjob:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| ensemble de règles-5 | 5 | dqjob:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| ensemble de règles-1 | 1 | dqjob:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| ensemble de règles-0 | 0 | dqjob:rs0 | 53.2 | 0.15 | 10 | $0.06 |
Le coût de l'évaluation d'un ensemble de règles vide est proche de zéro, mais il a été inclus car il peut être utilisé comme test rapide pour valider les rôles IAM associés aux tâches AWS Glue Data Quality et les autorisations de lecture sur l'ensemble de données de test dans Amazon S3. Le coût des tâches de qualité des données ne commence à augmenter qu’après avoir évalué des ensembles de règles comportant plus de 100 règles, restant constant en dessous de ce nombre.
Nous pouvons observer que le coût de gestion de la qualité des données pour le plus grand ensemble de règles du benchmark (400 règles) est toujours légèrement supérieur à 0.50 $.
Analyse des coûts de qualité des données dans AWS Cost Explorer
Afin de voir les balises de tâche ETL de qualité des données dans AWS Cost Explorer, vous devez activer les balises de répartition des coûts définies par l'utilisateur d'abord.
Une fois que vous avez créé et appliqué des balises définies par l'utilisateur à vos ressources, l'apparition des clés de balise sur la page des balises de répartition des coûts pour l'activation peut prendre jusqu'à 24 heures. L'activation des clés de balise peut ensuite prendre jusqu'à 24 heures.
- Sur AWS Explorateur de coûts console, choisissez Rapports enregistrés dans Cost Explorer dans le volet de navigation.
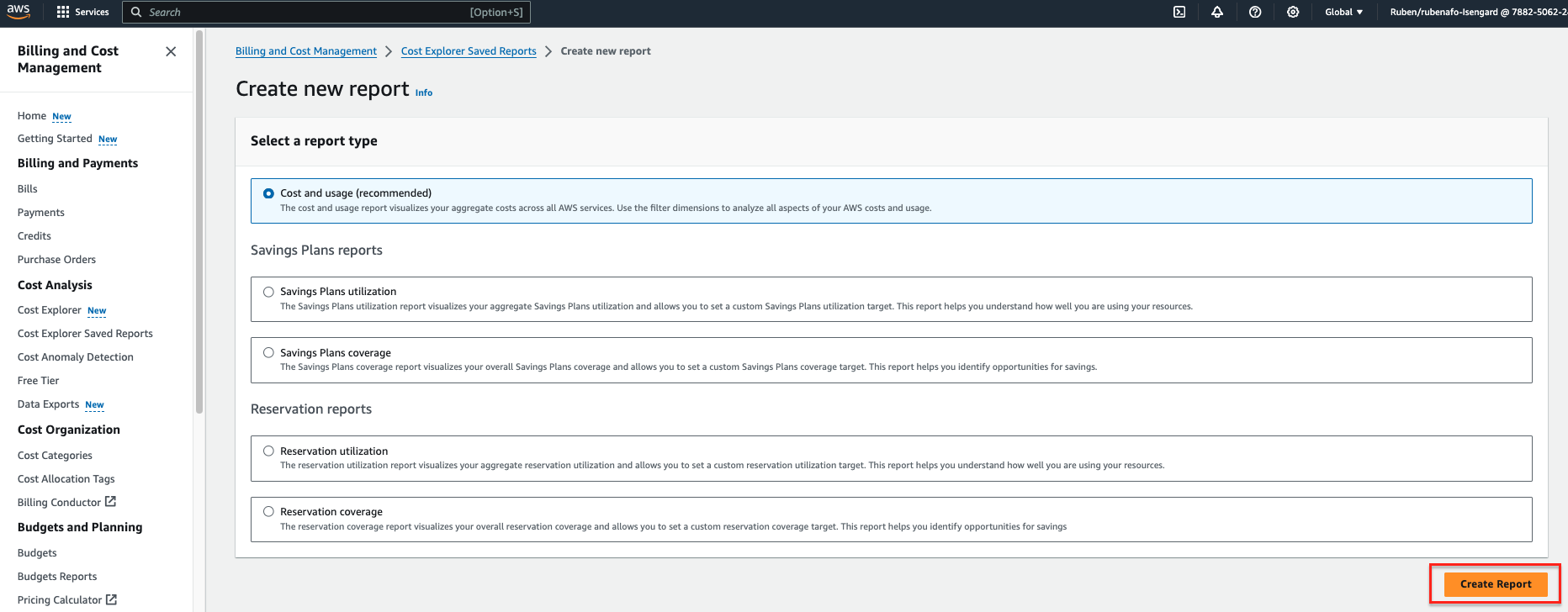
- Selectionnez Créer un nouveau rapport.

- Sélectionnez Coût et utilisation comme type de rapport.
- Selectionnez Créer un rapport.
- Pour Date de Gamme, saisissez une plage de dates.
- Pour granularité¸ choisissez Tous les jours.
- Pour Dimension, choisissez Jour, puis choisissez le
dqjobÉtiquette.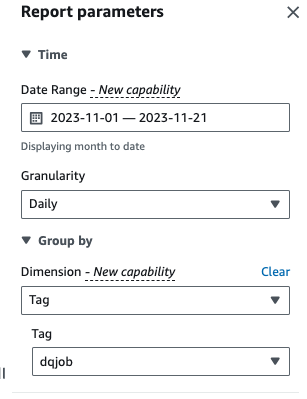
- Sous Filtres appliqués, choisir la
dqjobbalise et les huit balises utilisées dans les ensembles de règles de qualité des données (rs0, rs1, rs5, rs10, rs50, rs100, rs200 et rs400).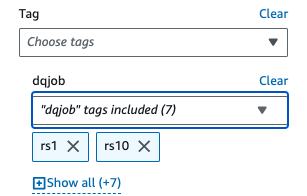
- Selectionnez Appliquer.
Le rapport Coût et utilisation sera mis à jour. L'axe X affiche les balises de l'ensemble de règles de qualité des données sous forme de catégories. Le Coût et utilisation Le graphique dans AWS Cost Explorer s'actualisera et affichera le coût mensuel total des dernières tâches ETL de qualité des données exécutées, agrégé par tâche ETL.

Nettoyer
Pour nettoyer l'infrastructure et éviter des frais supplémentaires, procédez comme suit :
- Videz le compartiment S3 initialement créé pour stocker l'ensemble de données de test.
- Supprimez les tâches ETL que vous avez créées dans AWS Glue.
- Supprimer l'
AWSGlueDataQualityPerformanceRoleRôle IAM. - Supprimez le rapport personnalisé créé dans AWS Cost Explorer.
Conclusion
AWS Glue Data Quality fournit un moyen efficace d'intégrer la validation de la qualité des données dans les pipelines ETL et évolue automatiquement pour s'adapter à des volumes croissants de données. Les types de règles de qualité des données intégrés offrent un large éventail d'options pour personnaliser les contrôles de qualité des données et se concentrer sur l'apparence de vos données au lieu de mettre en œuvre une logique indifférenciée.
Dans cette analyse comparative, nous avons montré comment les ensembles de règles AWS Glue Data Quality de taille courante entraînent peu ou pas de frais généraux, alors que dans les cas complexes, le coût augmente de manière linéaire. Nous avons également examiné comment vous pouvez baliser les tâches AWS Glue Data Quality pour rendre les informations sur les coûts disponibles dans AWS Cost Explorer pour un reporting rapide.
La qualité des données AWS Glue est généralement disponible dans toutes les régions AWS où AWS Glue est disponible. Apprenez-en davantage sur AWS Glue Data Quality et AWS Glue Data Catalog dans Premiers pas avec AWS Glue Data Quality à partir du catalogue de données AWS Glue.
À propos des auteurs
 Rubén Afonso est un architecte mondial de solutions de services financiers chez AWS. Il aime travailler sur les défis d’analyse et d’IA/ML, avec une passion pour l’automatisation et l’optimisation. Lorsqu'il n'est pas au travail, il aime découvrir des endroits cachés hors des sentiers battus autour de Barcelone.
Rubén Afonso est un architecte mondial de solutions de services financiers chez AWS. Il aime travailler sur les défis d’analyse et d’IA/ML, avec une passion pour l’automatisation et l’optimisation. Lorsqu'il n'est pas au travail, il aime découvrir des endroits cachés hors des sentiers battus autour de Barcelone.
 Kalyan Kumar Neelampudi (KK) est un architecte de solutions partenaires spécialisé (analyse de données et IA générative) chez AWS. Il agit en tant que conseiller technique et collabore avec divers partenaires AWS pour concevoir, mettre en œuvre et créer des pratiques autour de l'analyse de données et des charges de travail IA/ML. En dehors du travail, c'est un passionné de badminton et un aventurier culinaire, explorant les cuisines locales et voyageant avec son partenaire pour découvrir de nouveaux goûts et expériences.
Kalyan Kumar Neelampudi (KK) est un architecte de solutions partenaires spécialisé (analyse de données et IA générative) chez AWS. Il agit en tant que conseiller technique et collabore avec divers partenaires AWS pour concevoir, mettre en œuvre et créer des pratiques autour de l'analyse de données et des charges de travail IA/ML. En dehors du travail, c'est un passionné de badminton et un aventurier culinaire, explorant les cuisines locales et voyageant avec son partenaire pour découvrir de nouveaux goûts et expériences.

Gonzalo herreros est architecte Big Data senior au sein de l'équipe AWS Glue.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

