Apache Kafka est bien connu pour ses performances et sa capacité d'optimisation pour divers cas d'utilisation. Mais parfois, il peut être difficile de trouver la bonne configuration d'infrastructure qui réponde à vos exigences de performances spécifiques tout en minimisant le coût de l'infrastructure.
Cet article explique comment l'infrastructure sous-jacente affecte les performances d'Apache Kafka. Nous discutons des stratégies sur la façon de dimensionner vos clusters pour répondre à vos exigences de débit, de disponibilité et de latence. En cours de route, nous répondons à des questions telles que "quand est-il judicieux d'augmenter ou de réduire l'échelle ?" Nous terminons par des conseils sur la manière de vérifier en continu la taille de vos clusters de production.
Nous utilisons des tests de performance pour illustrer et expliquer l'effet et le compromis de différentes stratégies pour dimensionner votre cluster. Mais comme d'habitude, il est important de ne pas se fier aveuglément aux références que vous trouvez sur Internet. Nous montrons donc non seulement comment reproduire les résultats, mais nous expliquons également comment utiliser un cadre de test de performance pour exécuter vos propres tests pour vos caractéristiques de charge de travail spécifiques.
Dimensionnement des clusters Apache Kafka
Les goulots d'étranglement de ressources les plus courants pour les clusters du point de vue de l'infrastructure sont le débit du réseau, le débit de stockage et le débit du réseau entre les courtiers et le backend de stockage pour les courtiers utilisant le stockage en réseau tel que Boutique de blocs élastiques Amazon (AmazonEBS).
Le reste de l'article explique comment la limite de débit soutenu d'un cluster dépend non seulement des limites de stockage et de débit réseau des courtiers, mais également du nombre de courtiers et de groupes de consommateurs ainsi que du facteur de réplication. r. Nous dérivons la formule suivante (appelée équation 1 tout au long de cet article) pour la limite théorique de débit soutenu tcluster étant donné les caractéristiques d'infrastructure d'un cluster spécifique :
Pour les clusters de production, il est recommandé de cibler le débit réel à 80 % de sa limite théorique de débit soutenu. Considérez, par exemple, un cluster à trois nœuds avec des courtiers m5.12xlarge, un facteur de réplication de 3, des volumes EBS avec un débit de base de 1000 800 Mo/s et deux groupes de consommateurs consommant depuis la pointe du sujet. En tenant compte de tous ces paramètres, le débit soutenu absorbé par le cluster devrait viser XNUMX Mo/sec.
Cependant, ce calcul de débit fournit simplement une limite supérieure pour les charges de travail optimisées pour les scénarios à haut débit. Quelle que soit la façon dont vous configurez vos rubriques et les clients qui lisent et écrivent dans ces rubriques, le cluster ne peut pas absorber plus de débit. Pour les charges de travail présentant des caractéristiques différentes, telles que les charges de travail sensibles à la latence ou à forte intensité de calcul, le débit réel pouvant être absorbé par un cluster tout en répondant à ces exigences supplémentaires est souvent inférieur.
Pour trouver la bonne configuration pour votre charge de travail, vous devez remonter à partir de votre cas d'utilisation et déterminer les exigences appropriées en matière de débit, de disponibilité, de durabilité et de latence. Ensuite, utilisez l'équation 1 pour obtenir le dimensionnement initial de votre cluster en fonction de vos besoins en matière de débit, de durabilité et de stockage. Vérifiez ce dimensionnement initial du cluster en exécutant des tests de performances, puis affinez la taille du cluster, la configuration du cluster et la configuration du client pour répondre à vos autres exigences. Enfin, ajoutez de la capacité supplémentaire pour les clusters de production afin qu'ils puissent toujours ingérer le débit attendu même si le cluster fonctionne à capacité réduite, par exemple, pendant la maintenance, la mise à l'échelle ou la perte d'un courtier. En fonction de votre charge de travail, vous pouvez même envisager d'ajouter suffisamment de capacité de réserve pour résister à un événement affectant tous les courtiers d'une zone de disponibilité entière.
Le reste de l'article plonge plus profondément dans les aspects du dimensionnement des clusters. Les aspects les plus importants sont les suivants :
- Vous avez souvent le choix entre une montée en charge ou une montée en charge pour augmenter le débit et les performances d'un cluster. Les petits courtiers vous donnent des incréments de capacité plus petits et ont un rayon de souffle plus petit au cas où ils deviendraient indisponibles. Mais le fait d'avoir de nombreux petits courtiers augmente le temps nécessaire aux opérations qui nécessitent une mise à jour continue des courtiers pour se terminer, et augmente la probabilité d'échec.
- Tout le trafic que les producteurs envoient dans un cluster est conservé sur le disque. Par conséquent, le débit sous-jacent du volume de stockage peut devenir le goulot d'étranglement du cluster. Dans ce cas, il est logique d'augmenter le débit du volume si possible ou d'ajouter plus de volumes au cluster.
- Toutes les données conservées sur les volumes EBS traversent le réseau. Les instances optimisées pour Amazon EBS sont livrées avec une capacité dédiée pour les E/S Amazon EBS, mais le réseau Amazon EBS dédié peut toujours devenir le goulot d'étranglement du cluster. Dans ce cas, il est logique de faire évoluer les courtiers, car les plus grands courtiers ont un débit réseau Amazon EBS plus élevé.
- Plus il y a de groupes de consommateurs qui lisent à partir du cluster, plus il y a de données qui sortent sur le Cloud de calcul élastique Amazon (Amazon EC2) réseau des courtiers. Selon le type et la taille du courtier, le réseau Amazon EC2 peut devenir le goulot d'étranglement du cluster. Dans ce cas, il est logique de faire évoluer les courtiers, car les plus grands courtiers ont un débit réseau Amazon EC2 plus élevé.
- Pour les latences put p99, l'activation du chiffrement dans le cluster a un impact substantiel sur les performances. La mise à l'échelle des courtiers d'un cluster peut réduire considérablement la latence de p99 par rapport aux courtiers plus petits.
- Lorsque les consommateurs prennent du retard ou doivent retraiter des données historiques, les données demandées peuvent ne plus résider en mémoire et les courtiers doivent extraire les données du volume de stockage. Cela provoque des lectures d'E/S non séquentielles. Lors de l'utilisation de volumes EBS, cela entraîne également un trafic réseau supplémentaire vers le volume. L'utilisation de courtiers plus grands avec plus de mémoire ou l'activation de la compression peut atténuer cet effet.
- L'utilisation des capacités de rafale de votre cluster est un moyen très puissant d'absorber les pics de débit soudains sans faire évoluer votre cluster, ce qui prend du temps. La capacité de rafale aide également à répondre aux événements opérationnels. Par exemple, lorsque les courtiers sont en cours de maintenance ou que les partitions doivent être rééquilibrées au sein du cluster, ils peuvent utiliser les performances en rafale pour terminer l'opération plus rapidement.
- Surveiller ou alerter sur les métriques de cluster importantes liées à l'infrastructure telles que
BytesInPerSec,ReplicationBytesInPerSec,BytesOutPerSecetReplicationBytesOutPerSecpour recevoir une notification lorsque la taille de cluster actuelle n'est plus optimale pour la taille de cluster actuelle.
Le reste du message fournit un contexte supplémentaire et explique le raisonnement derrière ces recommandations.
Comprendre les goulots d'étranglement des performances d'Apache Kafka
Avant de commencer à parler des goulots d'étranglement des performances du point de vue de l'infrastructure, revoyons comment les données circulent au sein d'un cluster.
Pour cet article, nous supposons que les producteurs et les consommateurs se comportent bien et selon les meilleures pratiques, sauf indication contraire explicite. Par exemple, nous supposons que les producteurs équilibrent uniformément la charge entre les courtiers, que les courtiers hébergent le même nombre de partitions, qu'il y a suffisamment de partitions pour ingérer le débit, que les consommateurs consomment directement à partir de la pointe du flux, etc. Les courtiers reçoivent la même charge et font le même travail. Nous nous concentrons donc uniquement sur le Broker 1 dans le schéma suivant d'un flux de données au sein d'un cluster.

Les producteurs envoient un débit cumulé de tcluster dans le cluster. Comme le trafic se répartit uniformément entre les courtiers, le courtier 1 reçoit un débit entrant de tcluster/3. Avec un facteur de réplication de 3, le courtier 1 réplique le trafic qu'il reçoit directement vers les deux autres courtiers (les lignes bleues). De même, le courtier 1 reçoit le trafic de réplication de deux courtiers (les lignes rouges). Chaque groupe de consommateurs consomme le trafic qui est directement produit dans le courtier 1 (les lignes vertes). Tout le trafic qui arrive dans le Broker 1 en provenance des producteurs et le trafic de réplication en provenance d'autres Brokers est finalement conservé dans les volumes de stockage attachés au Broker.
Par conséquent, le débit du volume de stockage et du réseau de courtiers sont étroitement liés au débit global du cluster et justifient un examen plus approfondi.
Caractéristiques de débit du backend de stockage
Apache Kafka a été conçu pour utiliser de grandes opérations d'E/S séquentielles lors de l'écriture de données sur le disque. Les producteurs ne font qu'ajouter des données à la pointe du journal, ce qui provoque des écritures séquentielles. De plus, Apache Kafka ne se vide pas de manière synchrone sur le disque. Au lieu de cela, Apache Kafka écrit dans le cache de pages, laissant au système d'exploitation le soin de vider les pages sur le disque. Il en résulte de grandes opérations d'E/S séquentielles, ce qui optimise le débit du disque.
À de nombreuses fins pratiques, le courtier peut gérer le débit complet du volume et n'est pas limité par les IOPS. Nous supposons que les consommateurs lisent à partir de la pointe du sujet. Cela implique que les performances des volumes EBS sont liées au débit et non liées aux E/S, et que les lectures sont servies à partir du cache de page.
Le débit d'entrée du backend de stockage dépend des données que les producteurs envoient directement au courtier ainsi que du trafic de réplication
ic que le courtier reçoit de ses pairs. Pour un débit agrégé produit dans le cluster de tcluster et un facteur de réplication de r, le débit reçu par le stockage du courtier est le suivant :
Par conséquent, la limite de débit soutenu de l'ensemble du cluster est liée par les éléments suivants :
AWS propose différentes options pour le stockage de blocs : stockage d'instance et Amazon EBS. Le stockage d'instance est situé sur des disques physiquement connectés à l'ordinateur hôte, tandis qu'Amazon EBS est un stockage en réseau.
Les familles d'instances fournies avec le stockage d'instance atteignent des IOPS et un débit de disque élevés. Par exemple, les instances Amazon EC2 I3 incluent un stockage d'instance basé sur SSD NVMe optimisé pour une faible latence, des performances d'E/S aléatoires très élevées et un débit de lecture séquentielle élevé. Cependant, les volumes sont liés aux courtiers. Leurs caractéristiques, notamment leur taille, ne dépendent que de la famille d'instance, et la taille du volume n'est pas adaptable. De plus, lorsqu'un courtier tombe en panne et doit être remplacé, le volume de stockage est perdu. Le courtier de remplacement doit alors répliquer les données d'autres courtiers. Cette réplication entraîne une charge supplémentaire sur le cluster en plus de la capacité réduite due à la perte du courtier.
En revanche, les caractéristiques des volumes EBS peuvent être adaptées en cours d'utilisation. Vous pouvez utiliser ces fonctionnalités pour faire évoluer automatiquement le stockage du courtier au fil du temps plutôt que de provisionner le stockage pour les pics ou d'ajouter des courtiers supplémentaires. Certains types de volumes EBS, tels que gp3, io2 et st1, vous permettent également d'adapter le débit et les caractéristiques IOPS des volumes existants. De plus, le cycle de vie des volumes EBS est indépendant du courtier : si un courtier tombe en panne et doit être remplacé, le volume EBS peut être rattaché au courtier de remplacement. Cela évite la majeure partie du trafic de réplication autrement requis.
L'utilisation de volumes EBS est donc souvent un bon choix pour de nombreuses charges de travail Apache Kafka courantes. Ils offrent plus de flexibilité et permettent des opérations de mise à l'échelle et de récupération plus rapides.
Caractéristiques de débit Amazon EBS
Lorsque vous utilisez Amazon EBS comme backend de stockage, vous avez le choix entre plusieurs types de volume. Les caractéristiques de débit des différents types de volumes varient entre 128 Mo/s et 4000 XNUMX Mo/s (pour plus d'informations, reportez-vous à Types de volumes Amazon EBS). Vous pouvez même choisir d'attacher plusieurs volumes à un courtier pour augmenter le débit au-delà de ce qui peut être fourni par un seul volume.
Cependant, Amazon EBS est un stockage en réseau. Toutes les données qu'un courtier écrit sur un volume EBS doivent traverser le réseau jusqu'au backend Amazon EBS. Les familles d'instances de nouvelle génération, comme la famille M5, sont des instances optimisées pour Amazon EBS avec une capacité dédiée pour les E/S Amazon EBS. Mais il existe des limites sur le débit et les IOPS qui dépendent de la taille de l'instance et pas seulement de la taille du volume. La capacité dédiée pour Amazon EBS fournit un débit de base et des IOPS plus élevés pour les instances plus importantes. La capacité varie entre 81 Mo/sec et 2375 Mo/sec. Pour plus d'informations, reportez-vous à Types d'instances pris en charge.
Lors de l'utilisation d'Amazon EBS pour le stockage, nous pouvons adapter la formule de la limite de débit soutenu du cluster afin d'obtenir une limite supérieure plus stricte :
Débit du réseau Amazon EC2
Jusqu'à présent, nous n'avons considéré que le trafic réseau vers le volume EBS. Mais la réplication et les groupes de consommateurs génèrent également du trafic réseau Amazon EC2 hors du courtier. Le trafic que les producteurs envoient à un courtier est répliqué sur r-1 courtiers. De plus, chaque groupe de consommateurs lit le trafic qu'un courtier ingère. Par conséquent, le trafic réseau sortant global est le suivant :
La prise en compte de ce trafic nous donne finalement une borne supérieure raisonnable pour la limite de débit soutenu du cluster, que nous avons déjà vue dans l'équation 1 :
Pour les charges de travail de production, nous vous recommandons de maintenir le débit réel de votre charge de travail en dessous de 80 % de la limite de débit soutenu théorique telle qu'elle est déterminée par cette formule. De plus, nous supposons que tous les producteurs de données envoyés dans le cluster sont finalement lus par au moins un groupe de consommateurs. Lorsque le nombre de consommateurs est supérieur ou égal à 1, le trafic réseau Amazon EC2 sortant d'un courtier est toujours supérieur au trafic entrant dans le courtier. Nous pouvons donc ignorer le trafic de données vers les courtiers en tant que goulot d'étranglement potentiel.
Avec l'équation 1, nous pouvons vérifier si un cluster avec une infrastructure donnée peut absorber le débit requis pour notre charge de travail dans des conditions idéales. Pour plus d'informations sur la bande passante réseau Amazon EC2 des instances m5.8xlarge et supérieures, reportez-vous à Types d'instances Amazon EC2. Vous pouvez également trouver la bande passante Amazon EBS des instances m5.4xlarge sur la même page. Les instances plus petites utilisent des systèmes basés sur le crédit pour la bande passante réseau Amazon EC2 et la bande passante Amazon EBS. Pour la bande passante de base du réseau Amazon EC2, reportez-vous à Les performances du réseau. Pour la bande passante de base d'Amazon EBS, reportez-vous à Types d'instances pris en charge.
Adaptez la taille de votre cluster pour optimiser les performances et les coûts
Alors, qu'est-ce qu'on en retire ? Plus important encore, gardez à l'esprit que ces résultats n'indiquent que la limite de débit soutenu d'un cluster dans des conditions idéales. Ces résultats peuvent vous donner un nombre général pour la limite de débit soutenu attendue de vos clusters. Mais vous devez exécuter vos propres expériences pour vérifier ces résultats pour votre charge de travail et votre configuration spécifiques.
Cependant, nous pouvons tirer quelques conclusions de cette estimation de débit : l'ajout de courtiers augmente le débit soutenu du cluster. De même, la diminution du facteur de réplication augmente le débit soutenu du cluster. L'ajout de plusieurs groupes de consommateurs peut réduire le débit soutenu du cluster si le réseau Amazon EC2 devient le goulot d'étranglement.
Effectuons quelques expériences pour obtenir des données empiriques sur le débit de cluster soutenu pratique qui tient également compte des latences de mise en place des producteurs. Pour ces tests, nous maintenons le débit dans les 80 % recommandés de la limite de débit soutenu des clusters. Lors de l'exécution de vos propres tests, vous remarquerez peut-être que les clusters peuvent même fournir un débit supérieur à ce que nous montrons.
Mesurez le débit du cluster Amazon MSK et placez les latences
Pour créer l'infrastructure des expériences, nous utilisons Amazon Managed Streaming pour Apache Kafka (AmazonMSK). Amazon MSK provisionne et gère des clusters Apache Kafka hautement disponibles qui s'appuient sur le stockage Amazon EBS. La discussion suivante s'applique donc également aux clusters qui n'ont pas été provisionnés via Amazon MSK, s'ils sont soutenus par des volumes EBS.
Les expériences sont basées sur la kafka-producer-perf-test.sh et kafka-consumer-perf-test.sh outils inclus dans la distribution Apache Kafka. Les tests utilisent six producteurs et deux groupes de consommateurs avec six consommateurs chacun qui lisent et écrivent simultanément à partir du cluster. Comme mentionné précédemment, nous veillons à ce que les clients et les courtiers se comportent bien et selon les meilleures pratiques : les producteurs répartissent équitablement la charge entre les courtiers, les courtiers hébergent le même nombre de partitions, les consommateurs consomment directement du bout du flux, les producteurs et les consommateurs sont sur-approvisionnés afin qu'ils ne deviennent pas un goulot d'étranglement dans les mesures, et ainsi de suite.
Nous utilisons des clusters dont les courtiers sont déployés dans trois zones de disponibilité. De plus, la réplication est définie sur 3 et acks est fixé à all pour atteindre une durabilité élevée des données qui sont conservées dans le cluster. Nous avons également configuré un batch.size de 256 ko ou 512 ko et régler linger.ms à 5 millisecondes, ce qui réduit la surcharge liée à l'ingestion de petits lots d'enregistrements et optimise donc le débit. Le nombre de partitions est ajusté à la taille du courtier et au débit du cluster.
La configuration pour les courtiers supérieurs à m5.2xlarge a été adaptée selon les directives du Guide du développeur Amazon MSK. En particulier lors de l'utilisation débit provisionné, il est essentiel d'optimiser la configuration du cluster en conséquence.
La figure suivante compare les latences put pour trois clusters avec différentes tailles de courtier. Pour chaque cluster, les producteurs exécutent environ une douzaine de tests de performances individuels avec différentes configurations de débit. Initialement, les producteurs produisent un débit combiné de 16 Mo/s dans le cluster et augmentent progressivement le débit à chaque test individuel. Chaque test individuel dure 1 heure. Pour les instances avec des caractéristiques de performances extensibles, les crédits sont épuisés avant de commencer la mesure des performances réelle.

Pour les courtiers disposant de plus de 334 Go de stockage, nous pouvons supposer que le volume EBS a un débit de base de 250 Mo/sec. Le débit de base du réseau Amazon EBS est de 81.25, 143.75, 287.5 et 593.75 Mo/s pour les différentes tailles d'agent (pour plus d'informations, consultez Types d'instances pris en charge). Le débit de base du réseau Amazon EC2 est de 96, 160, 320 et 640 Mo/s (pour plus d'informations, consultez Les performances du réseau). Notez que cela ne prend en compte que le débit soutenu ; nous discuterons des performances en rafale dans une section ultérieure.
Pour un cluster à trois nœuds avec réplication 3 et deux groupes de consommateurs, les limites de débit d'entrée recommandées selon l'équation 1 sont les suivantes.
| Taille du courtier | Limite de débit soutenu recommandée |
| m5.grand | 58 MB / sec |
| m5.xlarge | 96 MB / sec |
| m5.2xlarge | 192 MB / sec |
| m5.4xlarge | 200 MB / sec |
Même si les courtiers m5.4xlarge ont deux fois plus de vCPU et de mémoire que les courtiers m5.2xlarge, la limite de débit soutenu du cluster augmente à peine lors de la mise à l'échelle des courtiers de m5.2xlarge à m5.4xlarge. En effet, avec cette configuration, le volume EBS utilisé par les courtiers devient un goulot d'étranglement. N'oubliez pas que nous avons supposé un débit de base o
f 250 Mo/s pour ces volumes. Pour un cluster à trois nœuds et un facteur de réplication de 3, chaque courtier doit écrire le même trafic sur le volume EBS que celui envoyé au cluster lui-même. Et comme 80 % du débit de base du volume EBS est de 200 Mo/s, la limite de débit soutenu recommandée du cluster avec les courtiers m5.4xlarge est de 200 Mo/s.
La section suivante décrit comment vous pouvez utiliser le débit provisionné pour augmenter le débit de base des volumes EBS et donc augmenter la limite de débit soutenu de l'ensemble du cluster.
Augmentez le débit du courtier grâce au débit provisionné
D'après les résultats précédents, vous pouvez voir que du point de vue du débit pur, il y a peu d'avantages à augmenter la taille du courtier de m5.2xlarge à m5.4xlarge avec la configuration de cluster par défaut. Le débit de base du volume EBS utilisé par les courtiers limite leur débit. Cependant, Amazon MSK a récemment lancé la possibilité de provisionner un débit de stockage jusqu'à 1000 3 Mo/s. Pour les clusters autogérés, vous pouvez utiliser les types de volume gp2, io1 ou stXNUMX pour obtenir un effet similaire. Selon la taille du courtier, cela peut augmenter considérablement le débit global du cluster.
La figure suivante compare le débit du cluster et les latences d'insertion de différentes tailles de courtier et de différentes configurations de débit provisionné.

Pour un cluster à trois nœuds avec réplication 3 et deux groupes de consommateurs, les limites de débit d'entrée recommandées selon l'équation 1 sont les suivantes.
| Taille du courtier | Configuration du débit provisionné | Limite de débit soutenu recommandée |
| m5.4xlarge | - | 200 MB / sec |
| m5.4xlarge | 480 MB / sec | 384 MB / sec |
| m5.8xlarge | 850 MB / sec | 680 MB / sec |
| m5.12xlarge | 1000 MB / sec | 800 MB / sec |
| m5.16xlarge | 1000 MB / sec | 800 MB / sec |
La configuration de débit provisionné a été soigneusement choisie pour la charge de travail donnée. Avec deux groupes de consommateurs consommant à partir du cluster, il n'est pas logique d'augmenter le débit provisionné des courtiers m4.4xlarge au-delà de 480 Mo/s. Le réseau Amazon EC2, et non le débit du volume EBS, limite la limite de débit soutenu recommandée du cluster à 384 Mo/s. Mais pour les charges de travail avec un nombre différent de consommateurs, il peut être judicieux d'augmenter ou de diminuer davantage la configuration du débit provisionné pour correspondre au débit de base du réseau Amazon EC2.
Évoluez pour augmenter le débit d'écriture du cluster
La mise à l'échelle du cluster augmente naturellement le débit du cluster. Mais comment cela affecte-t-il les performances et les coûts ? Comparons le débit de deux clusters différents : un cluster m5.4xlarge à trois nœuds et un cluster m5.2xlarge à six nœuds, comme illustré dans la figure suivante. La taille de stockage du cluster m5.4xlarge a été adaptée afin que les deux clusters aient la même capacité de stockage totale et donc que le coût de ces clusters soit identique.

Le cluster à six nœuds a presque le double du débit du cluster à trois nœuds et des latences p99 nettement inférieures. En regardant simplement le débit d'entrée du cluster, il peut être judicieux d'augmenter plutôt que d'augmenter, si vous avez besoin de plus de 200 Mo/s de débit. Le tableau suivant résume ces recommandations.
| Nombre de courtiers | Limite de débit soutenu recommandée | ||
| m5.grand | m5.2xlarge | m5.4xlarge | |
| 3 | 58 MB / sec | 192 MB / sec | 200 MB / sec |
| 6 | 115 MB / sec | 384 MB / sec | 400 MB / sec |
| 9 | 173 MB / sec | 576 MB / sec | 600 MB / sec |
Dans ce cas, nous aurions également pu utiliser le débit provisionné pour augmenter le débit du cluster. Comparez, par exemple, la limite de débit soutenu du cluster m5.2xlarge à six nœuds dans la figure précédente avec celle du cluster m5.4xlarge à trois nœuds avec un débit provisionné de l'exemple précédent. La limite de débit soutenu des deux clusters est identique, ce qui est dû à la même limite de bande passante du réseau Amazon EC2 qui augmente généralement proportionnellement à la taille du courtier.
Évoluez pour augmenter le débit de lecture du cluster
Plus les groupes de consommateurs lisent depuis le cluster, plus les données sortent sur le réseau Amazon EC2 des courtiers. Les courtiers plus grands ont un débit de base réseau plus élevé (jusqu'à 25 Go/s) et peuvent donc prendre en charge davantage de groupes de consommateurs lisant à partir du cluster.
La figure suivante compare la façon dont la latence et le débit changent pour le nombre différent de groupes de consommateurs pour un cluster m5.2xlarge à trois nœuds.

Comme le montre cette figure, l'augmentation du nombre de groupes de consommateurs lisant à partir d'un cluster diminue sa limite de débit soutenu. Plus les groupes de consommateurs lisent de consommateurs à partir du cluster, plus il y a de données qui doivent sortir des courtiers sur le réseau Amazon EC2. Le tableau suivant résume ces recommandations.
| Groupes de consommateurs | Limite de débit soutenu recommandée | ||
| m5.grand | m5.2xlarge | m5.4xlarge | |
| 0 | 65 MB / sec | 200 MB / sec | 200 MB / sec |
| 2 | 58 MB / sec | 192 MB / sec | 200 Mo / s ec |
| 4 | 38 MB / sec | 128 MB / sec | 200 MB / sec |
| 6 | 29 MB / sec | 96 MB / sec | 192 MB / sec |
La taille du courtier détermine le débit du réseau Amazon EC2, et il n'y a pas d'autre moyen de l'augmenter que de le mettre à l'échelle. Par conséquent, pour mettre à l'échelle le débit de lecture du cluster, vous devez soit augmenter les courtiers, soit augmenter le nombre de courtiers.
Équilibrer la taille du courtier et le nombre de courtiers
Lors du dimensionnement d'un cluster, vous avez souvent le choix d'effectuer un scale-out ou un scale-up pour augmenter le débit et les performances d'un cluster. En supposant que la taille de stockage est ajustée en conséquence, le coût de ces deux options est souvent identique. Alors, quand devez-vous évoluer ou augmenter votre capacité ?
L'utilisation de courtiers plus petits vous permet de faire évoluer la capacité par incréments plus petits. Amazon MSK veille à ce que les courtiers soient équitablement répartis dans toutes les zones de disponibilité configurées. Vous ne pouvez donc ajouter qu'un nombre de courtiers qui est un multiple du nombre de zones de disponibilité. Par exemple, si vous ajoutez trois courtiers à un cluster m5.4xlarge à trois nœuds avec un débit provisionné, vous augmentez la limite de débit de cluster soutenu recommandée de 100 %, de 384 Mo/s à 768 Mo/s. Toutefois, si vous ajoutez trois courtiers à un cluster m5.2xlarge à six nœuds, vous augmentez la limite de débit de cluster recommandée de 50 %, de 384 Mo/s à 576 Mo/s.
Le fait d'avoir trop peu de très grands courtiers augmente également le rayon d'explosion au cas où un seul courtier serait en panne pour maintenance ou en raison d'une défaillance de l'infrastructure sous-jacente. Par exemple, pour un cluster à trois nœuds, un seul courtier correspond à 33 % de la capacité du cluster, alors qu'il n'est que de 17 % pour un cluster à six nœuds. Lors du provisionnement des clusters selon les meilleures pratiques, vous avez ajouté suffisamment de capacité de réserve pour ne pas affecter votre charge de travail pendant ces opérations. Mais pour les grands courtiers, vous devrez peut-être ajouter plus de capacité de réserve que nécessaire en raison des incréments de capacité plus importants.
Cependant, plus il y a de courtiers dans le cluster, plus les opérations de maintenance et de mise à jour prennent du temps. Le service applique ces modifications séquentiellement à un courtier à la fois pour minimiser l'impact sur la disponibilité du cluster. Lors du provisionnement des clusters selon les meilleures pratiques, vous avez ajouté suffisamment de capacité de réserve pour ne pas affecter votre charge de travail pendant ces opérations. Mais le temps nécessaire pour terminer l'opération est toujours à prendre en compte, car vous devez attendre la fin d'une opération avant de pouvoir en exécuter une autre.
Vous devez trouver un équilibre qui convient à votre charge de travail. Les petits courtiers sont plus flexibles car ils vous offrent des incréments de capacité plus petits. Mais le fait d'avoir trop de petits courtiers augmente le temps nécessaire aux opérations de maintenance pour se terminer et augmente le risque d'échec. Les clusters avec moins de grands courtiers effectuent les opérations de mise à jour plus rapidement. Mais ils viennent avec des incréments de capacité plus importants et un rayon de souffle plus élevé en cas de défaillance du courtier.
Évoluez pour les charges de travail gourmandes en CPU
Jusqu'à présent, nous nous sommes concentrés sur le débit du réseau des courtiers. Mais il existe d'autres facteurs qui déterminent le débit et la latence du cluster. L'un d'eux est le cryptage. Apache Kafka comporte plusieurs couches où le chiffrement peut protéger les données en transit et au repos : chiffrement des données stockées sur les volumes de stockage, chiffrement du trafic entre courtiers et chiffrement du trafic entre clients et courtiers.
Amazon MSK chiffre toujours vos données au repos. Vous pouvez spécifier le Service de gestion des clés AWS (AWS KMS) clé principale client (CMK) que vous souhaitez qu'Amazon MSK utilise pour chiffrer vos données au repos. Si vous ne spécifiez pas de CMK, Amazon MSK crée un CMK gérée par AWS pour vous et l'utilise en votre nom. Pour les données en cours, vous pouvez choisir d'activer le chiffrement des données entre les producteurs et les courtiers (chiffrement en transit), entre les courtiers (chiffrement en cluster) ou les deux.
L'activation du chiffrement dans le cluster oblige les courtiers à chiffrer et à déchiffrer les messages individuels. Par conséquent, l'envoi de messages sur le réseau ne peut plus tirer parti de l'opération efficace de copie zéro. Cela entraîne une surcharge supplémentaire de la bande passante du processeur et de la mémoire.
La figure suivante montre l'impact sur les performances de ces options pour les clusters à trois nœuds avec les courtiers m5.large et m5.2xlarge.
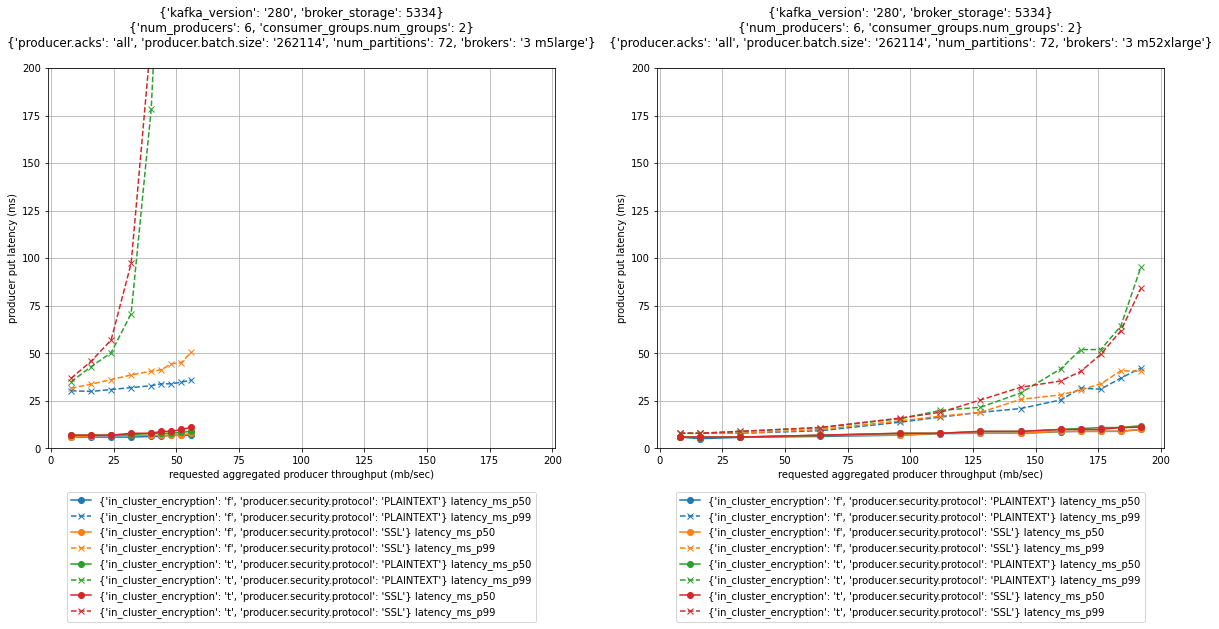
Pour les latences put p99, l'activation du chiffrement dans le cluster a un impact substantiel sur les performances. Comme le montrent les graphiques précédents, la mise à l'échelle des courtiers peut atténuer l'effet. Le p99 a mis la latence à un débit de 52 Mo/s d'un cluster m5.large avec un chiffrement en transit et dans le cluster supérieur à 200 millisecondes (ligne pointillée rouge et verte dans le graphique de gauche). La mise à l'échelle du cluster vers les courtiers m5.2xlarge réduit la latence de p99 au même débit à moins de 15 millisecondes (ligne pointillée rouge et verte dans le graphique de droite).
D'autres facteurs peuvent augmenter les besoins en CPU. La compression ainsi que le compactage des journaux peuvent également avoir un impact sur la charge des clusters.
Mise à l'échelle pour un consommateur qui ne lit pas à partir de la pointe du flux
Nous avons conçu les tests de performance de manière à ce que les consommateurs lisent toujours à partir de la pointe du sujet. Cela signifie en fait que les courtiers peuvent servir les lectures des consommateurs directement à partir de la mémoire, sans provoquer d'E/S de lecture vers Amazon EBS. Contrairement à toutes les autres sections de l'article, nous abandonnons cette hypothèse pour comprendre comment les consommateurs qui ont pris du retard peuvent avoir un impact sur les performances du cluster. Le schéma suivant illustre cette conception.

Lorsqu'un consommateur prend du retard ou doit se remettre d'une panne, il retraite les anciens messages. Dans ce cas, les pages contenant les données peuvent ne plus résider dans le cache de pages et les courtiers doivent extraire les données du volume EBS. Cela entraîne un trafic réseau supplémentaire vers le volume et des lectures d'E/S non séquentielles. Cela peut avoir un impact considérable sur le débit du volume EBS.
Dans un cas extrême, une opération de remblayage peut retraiter l'historique complet des événements. Dans ce cas, l'opération entraîne non seulement des E/S supplémentaires sur le volume EBS, mais charge également de nombreuses pages contenant des données historiques dans le cache de pages, supprimant ainsi les pages contenant des données plus récentes. Par conséquent, les consommateurs qui sont légèrement en retard sur la pointe du sujet et qui liraient généralement directement à partir du cache de page peuvent désormais provoquer des E/S supplémentaires sur le volume EBS, car l'opération de remplissage a évincé la page qu'ils doivent lire de la mémoire.
Une option pour atténuer ces scénarios consiste à activer la compression. En compressant les données brutes, les courtiers peuvent conserver davantage de données dans le cache de pages avant qu'elles ne soient expulsées de la mémoire. Cependant, gardez à l'esprit que la compression nécessite plus de ressources CPU. Si vous ne pouvez pas activer la compression ou si l'activation de la compression ne permet pas d'atténuer ce scénario, vous pouvez également augmenter la taille du cache de pages en augmentant la mémoire disponible pour les courtiers par mise à l'échelle.
Utilisez les performances en rafale pour
s'adapter aux pics de trafic
Jusqu'à présent, nous avons examiné la limite de débit soutenu des clusters. C'est le débit que le cluster peut supporter indéfiniment. Pour les charges de travail de streaming, il est important de comprendre les exigences de débit de base et la taille en conséquence. Cependant, le réseau Amazon EC2, le réseau Amazon EBS et le système de stockage Amazon EBS sont basés sur un système de crédit ; ils fournissent un certain débit de base et peuvent atteindre un débit supérieur pendant une certaine période en fonction de la taille de l'instance. Cela se traduit directement par le débit des clusters MSK. Les clusters MSK ont une limite de débit soutenue et peuvent atteindre un débit supérieur pendant de courtes périodes.
La ligne bleue du graphique suivant montre le débit agrégé d'un cluster m5.large à trois nœuds avec deux groupes de consommateurs. Pendant toute la durée de l'expérience, les producteurs essaient d'envoyer les données le plus rapidement possible dans le cluster. Ainsi, bien que 80 % de la limite de débit soutenu du cluster soit d'environ 58 Mo/s, le cluster peut atteindre un débit bien supérieur à 200 Mo/s pendant près d'une demi-heure.

Pensez-y de cette façon : lors de la configuration de l'infrastructure sous-jacente d'un cluster, vous provisionnez essentiellement un cluster avec une certaine limite de débit soutenu. Compte tenu des capacités de rafale, le cluster peut alors absorber instantanément un débit beaucoup plus élevé pendant un certain temps. Par exemple, si le débit moyen de votre charge de travail est généralement d'environ 50 Mo/s, le cluster m5.large à trois nœuds du graphique précédent peut ingérer plus de quatre fois son débit habituel pendant environ une demi-heure. Et c'est sans aucun changement requis. Cette rafale vers un débit plus élevé est totalement transparente et ne nécessite aucune opération de mise à l'échelle.
Il s'agit d'un moyen très puissant d'absorber les pics de débit soudains sans faire évoluer votre cluster, ce qui prend du temps. De plus, la capacité supplémentaire aide également à répondre aux événements opérationnels. Par exemple, lorsque les courtiers sont en cours de maintenance ou que les partitions doivent être rééquilibrées au sein du cluster, ils peuvent utiliser les performances en rafale pour mettre les courtiers en ligne et se synchroniser plus rapidement. La capacité de rafale est également très utile pour récupérer rapidement des événements opérationnels qui affectent une zone de disponibilité entière et provoquent un important trafic de réplication en réponse à l'événement.
Surveillance et optimisation continue
Jusqu'à présent, nous nous sommes concentrés sur le dimensionnement initial de votre cluster. Mais une fois que vous avez déterminé la taille de cluster initiale correcte, les efforts de dimensionnement ne doivent pas s'arrêter. Il est important de continuer à revoir votre charge de travail après son exécution en production pour savoir si la taille du courtier est toujours appropriée. Vos hypothèses initiales peuvent ne plus tenir dans la pratique ou vos objectifs de conception peuvent avoir changé. Après tout, l'un des grands avantages du cloud computing est que vous pouvez adapter l'infrastructure sous-jacente via un appel API.
Comme nous l'avons mentionné précédemment, le débit de vos clusters de production doit cibler 80 % de leur limite de débit soutenu. Lorsque l'infrastructure sous-jacente commence à connaître des limitations parce qu'elle a dépassé la limite de débit pendant trop longtemps, vous devez faire évoluer le cluster. Idéalement, vous devriez même mettre à l'échelle le cluster avant qu'il n'atteigne ce point. Par défaut, Amazon MSK expose trois métriques qui indiquent quand cette limitation est appliquée à l'infrastructure sous-jacente :
- Équilibre en rafale – Indique le solde restant des crédits de rafale d'E/S pour les volumes EBS. Si cette métrique commence à chuter, envisagez d'augmenter la taille du volume EBS pour augmenter les performances de référence du volume. Si Amazon Cloud Watch ne signale pas cette métrique pour votre cluster, vos volumes sont supérieurs à 5.3 To et ne sont plus soumis aux crédits en rafale.
- SoldeCrédit CPU – Uniquement pertinent pour les courtiers de la famille T3 et indique le nombre de crédits CPU disponibles. Lorsque cette métrique commence à baisser, les courtiers consomment des crédits CPU pour dépasser leurs performances de base CPU. Envisagez de changer le type de courtier pour la famille M5.
- Mise en forme du trafic – Une métrique de haut niveau indiquant le nombre de paquets abandonnés en raison d'un dépassement des allocations réseau. Des détails plus fins sont disponibles lorsque le
PER_BROKERle niveau de surveillance est configuré pour le cluster. Faites évoluer les courtiers si cette métrique est élevée pendant vos charges de travail typiques.
Dans l'exemple précédent, nous avons vu le débit du cluster chuter considérablement après l'épuisement des crédits réseau et l'application de la mise en forme du trafic. Même si nous ne connaissions pas la limite de débit soutenu maximale du cluster, la métrique TrafficShaping dans le graphique suivant indique clairement que nous devons augmenter les courtiers pour éviter une limitation supplémentaire sur la couche réseau Amazon EC2.

Amazon MSK expose des métriques supplémentaires qui vous aident à comprendre si votre cluster est sur- ou sous-provisionné. Dans le cadre de l'exercice de dimensionnement, vous avez déterminé la limite de débit soutenu de votre cluster. Vous pouvez surveiller ou même créer des alarmes sur le BytesInPerSec, ReplicationBytesInPerSec, BytesOutPerSecet ReplicationBytesInPerSec métriques du cluster pour recevoir une notification lorsque la taille actuelle du cluster n'est plus optimale pour les caractéristiques de charge de travail actuelles. De même, vous pouvez surveiller la CPUIdle métrique et alarme lorsque votre cluster est sous- ou sur-provisionné en termes d'utilisation du processeur.
Ce ne sont que les métriques les plus pertinentes pour surveiller la taille de votre cluster du point de vue de l'infrastructure. Vous devez également surveiller l'intégrité du cluster et de l'ensemble de la charge de travail. Pour plus d'informations sur la surveillance des clusters, reportez-vous à Pratiques d'excellence.
Un framework pour tester les performances d'Apache Kafka
Comme mentionné précédemment, vous devez exécuter vos propres tests pour vérifier si les performances d'un cluster correspondent à vos caractéristiques de charge de travail spécifiques. Nous avons publié un cadre de test de performance sur GitHub qui permet d'automatiser la planification et la visualisation de nombreux tests. Nous avons utilisé le même cadre pour générer les graphiques dont nous avons discuté dans cet article.
Le cadre est basé sur la kafka-producer-perf-test.sh et kafka-consumer-perf-test.sh outils qui font partie de la distribution Apache Kafka. Il construit l'automatisation et la visualisation autour de ces outils.
Pour les courtiers plus petits qui sont soumis à des capacités de rupture, vous pouvez également configurer le framework pour générer d'abord une charge excessive sur une période prolongée afin d'épuiser les crédits de mise en réseau, de stockage ou de réseau de stockage. Une fois l'épuisement du crédit terminé, le framework exécute le test de performance réel. Ceci est important pour mesurer la performance du cluster
s qui peuvent être maintenus indéfiniment plutôt que de mesurer les performances de pointe, qui ne peuvent être maintenues que pendant un certain temps.
Pour exécuter votre propre test, reportez-vous au référentiel GitHub, où vous pouvez trouver le Kit de développement AWS Cloud (AWS CDK) et une documentation supplémentaire sur la configuration, l'exécution et la visualisation des résultats du test de performances.
Conclusion
Nous avons discuté de divers facteurs qui contribuent aux performances d'Apache Kafka du point de vue de l'infrastructure. Bien que nous nous soyons concentrés sur Apache Kafka, nous avons également découvert la mise en réseau d'Amazon EC2 et les caractéristiques de performances d'Amazon EBS.
Pour trouver la bonne taille pour vos clusters, travaillez à partir de votre cas d'utilisation pour déterminer les exigences de débit, de disponibilité, de durabilité et de latence.
Commencez par un dimensionnement initial de votre cluster en fonction de vos exigences en matière de débit, de stockage et de durabilité. Évoluez ou utilisez le débit provisionné pour augmenter le débit d'écriture du cluster. Mettez à l'échelle pour augmenter le nombre de consommateurs pouvant consommer à partir du cluster. Évoluez pour faciliter le chiffrement en transit ou dans le cluster et les consommateurs qui ne lisent pas forment la pointe du flux.
Vérifiez ce dimensionnement initial du cluster en exécutant des tests de performances, puis affinez la taille et la configuration du cluster pour qu'elles correspondent à d'autres exigences, telles que la latence. Ajoutez de la capacité supplémentaire pour les clusters de production afin qu'ils puissent supporter la maintenance ou la perte d'un courtier. En fonction de votre charge de travail, vous pouvez même envisager de résister à un événement affectant une zone de disponibilité entière. Enfin, continuez à surveiller les métriques de votre cluster et redimensionnez le cluster au cas où vos hypothèses initiales ne seraient plus valables.
À propos de l’auteur
 Steffen Hausman est architecte principal de streaming chez AWS. Il travaille avec des clients du monde entier pour concevoir et créer des architectures de streaming afin qu'ils puissent tirer parti de l'analyse de leurs données de streaming. Il est titulaire d'un doctorat en informatique de l'Université de Munich et pendant son temps libre, il essaie d'attirer ses filles dans la technologie avec de jolis autocollants qu'il collectionne lors de conférences.
Steffen Hausman est architecte principal de streaming chez AWS. Il travaille avec des clients du monde entier pour concevoir et créer des architectures de streaming afin qu'ils puissent tirer parti de l'analyse de leurs données de streaming. Il est titulaire d'un doctorat en informatique de l'Université de Munich et pendant son temps libre, il essaie d'attirer ses filles dans la technologie avec de jolis autocollants qu'il collectionne lors de conférences.
- Coinsmart. Le meilleur échange Bitcoin et Crypto d'Europe.
- Platoblockchain. Intelligence métaverse Web3. Connaissance amplifiée. ACCÈS LIBRE.
- CryptoHawk. Radar Altcoins. Essai gratuit.
- Source : https://aws.amazon.com/blogs/big-data/best-practices-for-right-sizing-your-apache-kafka-clusters-to-optimize-performance-and-cost/

