Introduction
Dans le monde de intelligence artificielle, imaginez une technique d'apprentissage qui permet aux machines de s'appuyer sur leurs connaissances existantes et de relever de nouveaux défis avec expertise. Cette technique unique est appelée apprentissage par transfert. Ces dernières années, nous avons assisté à une expansion des capacités et des applications des modèles génératifs. Nous pouvons utiliser l'apprentissage par transfert pour simplifier la formation des modèles génératifs. Imaginez un artiste talentueux qui, maîtrisant diverses formes d’art, peut créer sans effort un chef-d’œuvre en s’appuyant sur ses diverses compétences. De même, l’apprentissage par transfert permet aux machines d’utiliser les connaissances acquises dans un domaine pour exceller dans un autre. Cette capacité fantastique et incroyable de transfert de connaissances a ouvert un monde de possibilités en matière d’intelligence artificielle.
Objectifs d'apprentissage
Dans cet article, nous allons
- Obtenez un aperçu du concept d'apprentissage par transfert et découvrez les avantages qu'il offre dans le monde de l'apprentissage automatique.
- Nous explorerons également diverses applications du monde réel où l’apprentissage par transfert est utilisé efficacement.
- Ensuite, comprenez le processus étape par étape de construction d'un modèle pour classer les gestes de la main pierre-papier-ciseaux.
- Découvrez comment appliquer des techniques d'apprentissage par transfert pour former et tester votre modèle efficacement.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Transfert d'apprentissage
Imaginez-vous être un enfant et vouloir avec impatience apprendre à faire du vélo pour la première fois. Il vous sera difficile de maintenir votre équilibre et d’apprendre. À ce moment-là, il faut tout apprendre à partir de zéro. N'oubliez pas de garder l'équilibre, une poignée de direction, d'utiliser des pauses et tout irait pour le mieux. Cela prend beaucoup de temps, et après de nombreux essais infructueux, vous apprendrez enfin tout.
De même, imaginez maintenant si vous souhaitez apprendre la moto. Dans ce cas, vous n'êtes pas obligé de tout apprendre à partir de zéro comme vous le faisiez dans votre enfance. Maintenant, vous savez déjà beaucoup de choses. Vous possédez déjà certaines compétences telles que comment garder l'équilibre, comment diriger la poignée et comment utiliser les pauses. Maintenant, vous devez transférer toutes ces compétences et acquérir des compétences supplémentaires comme utiliser des engrenages. Ce qui rend la tâche beaucoup plus facile pour vous et prend moins de temps à apprendre. Comprenons maintenant l’apprentissage par transfert d’un point de vue technique.
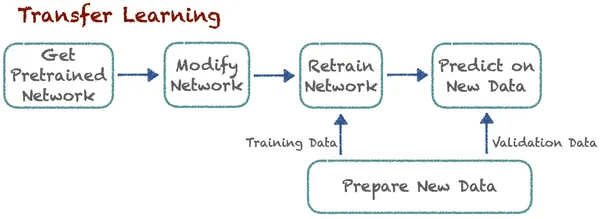
L'apprentissage par transfert améliore l'apprentissage dans une nouvelle tâche en transférant les connaissances d'une leçon connexe que les experts ont déjà découverte. Cette technique permet aux algorithmes de mémoriser de nouvelles tâches à l'aide de modèles pré-entraînés. Disons qu'il existe un algorithme qui classe les chats et les chiens. Désormais, les experts utilisent le même modèle pré-entraîné avec quelques modifications pour classer les voitures et les camions. L'idée de base ici est la classification. Ici, l’apprentissage de nouvelles tâches s’appuie sur des enseignements déjà connus. L'algorithme peut stocker et accéder à ces connaissances précédemment apprises.
Avantages de l'apprentissage par transfert
- Apprentissage plus rapide : Comme le modèle n’apprend pas à partir de zéro, l’apprentissage de nouvelles tâches prend très peu de temps. Il utilise des connaissances pré-entraînées, réduisant considérablement le temps de formation et les ressources informatiques. Le modèle a besoin d’une longueur d’avance. De cette façon, il bénéficie d’un apprentissage plus rapide.
- Performance améliorée: Les modèles qui utilisent l'apprentissage par transfert obtiennent de meilleures performances, en particulier lorsqu'ils affinent un modèle pré-entraîné pour une tâche connexe, par rapport aux modèles qui apprennent tout à partir de zéro. Cela a conduit à une plus grande précision et efficacité.
- Efficacité des données : Nous savons que la formation de modèles d’apprentissage profond nécessite beaucoup de données. Cependant, nous avons besoin d’ensembles de données plus petits pour les modèles d’apprentissage par transfert, car ils héritent des connaissances du domaine source. Ainsi, cela réduit le besoin de grandes quantités de données étiquetées.
- Économise des ressources : Créer et maintenir des modèles à grande échelle à partir de zéro peut nécessiter beaucoup de ressources. L'apprentissage par transfert permet aux organisations d'utiliser efficacement les ressources existantes. Et nous n’avons pas besoin de beaucoup de ressources pour obtenir suffisamment de données pour nous entraîner.
- Apprentissage continu : L’apprentissage continu peut être réalisé par l’apprentissage par transfert. Les modèles peuvent continuellement apprendre et s'adapter à de nouvelles données, tâches ou environnements. Ainsi, il réalise un apprentissage continu, essentiel dans l’apprentissage automatique.
- Résultats de pointe : L'apprentissage par transfert a joué un rôle crucial dans l'obtention de résultats de pointe. Il a obtenu des résultats de pointe dans de nombreux concours et tests d'apprentissage automatique. C’est désormais devenu une technique standard dans ce domaine.
Applications de l'apprentissage par transfert
L’apprentissage par transfert revient à utiliser vos connaissances existantes pour rendre l’apprentissage de nouvelles choses plus simple. Il s'agit d'une technique puissante largement utilisée dans différents domaines pour améliorer les capacités des programmes informatiques. Explorons maintenant quelques domaines communs dans lesquels l'apprentissage par transfert joue un rôle essentiel.
Vision par ordinateur:
Merci beaucoup vision par ordinateur les tâches utilisent largement l'apprentissage par transfert, en particulier dans la détection d'objets, où les experts affinent des modèles pré-entraînés tels que ResNet, VGG ou MobileNet pour des tâches de reconnaissance d'objets spécifiques. Certains modèles comme FaceNet et OpenFace utilisent l'apprentissage par transfert pour reconnaître les visages dans différentes conditions d'éclairage, poses et angles. Les modèles pré-entraînés sont également adaptés aux tâches de classification d'images. Ceux-ci incluent l’analyse d’images médicales, la surveillance de la faune et le contrôle qualité dans la fabrication.
Traitement du langage naturel (NLP):
Il existe certains modèles d'apprentissage par transfert comme BERT ainsi que GPT où ces modèles sont affinés pour l’analyse des sentiments. Afin qu'ils puissent comprendre le sentiment du texte dans diverses situations, le modèle Transformer de Google utilise l'apprentissage par transfert pour traduire le texte entre les langues.
Véhicules autonomes:
L’application de l’apprentissage par transfert dans véhicules autonomes est un domaine de développement critique et en évolution rapide dans l’industrie automobile. Il existe de nombreux segments dans ce domaine où l’apprentissage par transfert est utilisé. Certains concernent la détection d'objets, la reconnaissance d'objets, la planification de chemins, la prédiction de comportement, la fusion de capteurs, le contrôle de la circulation et bien d'autres encore.
Génération de contenu :
Génération de contenu est une application passionnante de l’apprentissage par transfert. GPT-3 (Generative Pre-trained Transformer 3) a été formé sur de grandes quantités de données textuelles. Il peut générer du contenu créatif dans de nombreux domaines. GPT-3 et d'autres modèles génèrent du contenu créatif, notamment de l'art, de la musique, de la narration et de la génération de code.
Systèmes de recommandation :
Nous connaissons tous les avantages de systèmes de recommandation. Cela nous simplifie tout simplement un peu la vie, et oui, nous utilisons ici aussi l’apprentissage par transfert. De nombreuses plateformes en ligne, notamment Netflix et YouTube, utilisent l'apprentissage par transfert pour recommander des films et des vidéos en fonction des préférences des utilisateurs.
Pour en savoir plus : Comprendre l'apprentissage par transfert pour le Deep Learning
Améliorer les modèles génératifs
Les modèles génératifs constituent l’un des concepts les plus passionnants et révolutionnaires dans le domaine en évolution rapide de l’intelligence artificielle. À bien des égards, l'apprentissage par transfert peut améliorer la fonctionnalité et les performances des modèles d'IA génératifs tels que GAN (Réseaux Adversaires Génératifs) or VAE (auto-encodeurs variationnels). L’un des principaux avantages de l’apprentissage par transfert est qu’il permet aux modèles d’utiliser les connaissances acquises sur différentes tâches connexes. Nous savons que les modèles génératifs nécessitent une formation approfondie. Pour obtenir de meilleurs résultats, il est essentiel de l’entraîner sur de grands ensembles de données, une pratique fortement soutenue par l’apprentissage par transfert. Au lieu de repartir de zéro, les modèles peuvent lancer une activité avec des connaissances préexistantes.
Dans le cas des GAN ou des VAE, les experts peuvent pré-entraîner les parties discriminatrices ou encodeurs-décodeurs du modèle sur un ensemble de données ou un domaine plus large. Cela peut accélérer le processus de formation. Les modèles génératifs nécessitent généralement de grandes quantités de données spécifiques à un domaine pour générer un contenu de haute qualité. L'apprentissage par transfert peut résoudre ce problème car il ne nécessite que des ensembles de données plus petits. Il facilite également l’apprentissage continu et l’adaptation de modèles génératifs.
L’apprentissage par transfert a déjà trouvé des applications pratiques dans l’amélioration des modèles d’IA générative. Il a été utilisé pour adapter des modèles basés sur du texte comme GPT-3 afin de générer des images et d'écrire du code. Dans le cas des GAN, l’apprentissage par transfert peut aider à créer des images hyperréalistes. À mesure que l’IA générative continue de s’améliorer, l’apprentissage par transfert sera extrêmement important pour l’aider à réaliser encore plus d’excellentes choses.
Mobile Net V2
Google a créé MobileNetV2, une architecture de réseau neuronal pré-entraînée robuste largement utilisée dans les applications de vision par ordinateur et d'apprentissage en profondeur. Ils voulaient initialement que ce modèle traite et analyse rapidement les images, dans le but d’atteindre des performances de pointe sur une variété de tâches. Il s’agit désormais d’une option très appréciée pour de nombreuses tâches de vision par ordinateur. MobileNetV2 est spécialement conçu pour être léger et efficace. Il nécessite un nombre relativement restreint de paramètres et permet d’obtenir des résultats impressionnants et très précis.
Malgré son efficacité, MobileNetV2 maintient une grande précision dans diverses tâches de vision par ordinateur. MobileNetV2 introduit le concept de résidus inversés. Contrairement aux résidus traditionnels, où la sortie d'une couche est ajoutée à son entrée, les résidus inversés utilisent une connexion raccourcie pour ajouter les informations à la production. Cela rend le modèle plus profond et plus efficace.
Les résidus inversés utilisent une connexion raccourci pour ajouter les informations à la production, contrairement aux résidus traditionnels où la sortie d'une couche est ajoutée à son entrée. Vous pouvez utiliser ce modèle MobileNetV2 pré-entraîné et l'affiner pour des applications spécifiques. Ainsi, cela permet d'économiser beaucoup de temps ainsi que de ressources de calcul, conduisant à une réduction des coûts de calcul. En raison de son efficacité et de son efficience, MobileNetV2 est largement utilisé dans l'industrie et la recherche. TensorFlow Hub offre un accès facile aux modèles MobileNetV2 pré-entraînés. Cela simplifie l'intégration du modèle dans des projets basés sur Tensorflow.
Classification Pierre-Papier-Ciseaux
Commençons par construire un apprentissage automatique modèle pour la tâche de classification pierre-papier-ciseaux. Nous utiliserons la technique d’apprentissage par transfert pour mettre en œuvre. Pour cela, nous utilisons le modèle pré-entraîné MobileNet V2.

Ensemble de données Pierre-Papier-Ciseaux
L'ensemble de données « Rock Paper Scissors » est une collection de 2,892 XNUMX images. Il se compose de diverses mains dans les trois poses différentes. Ceux-ci sont,
- Roche: Le poing fermé.
- Livre: La paume ouverte.
- Les ciseaux: Les deux doigts étendus formant un V.
Les images incluent des mains de personnes de races, d’âges et de sexes différents. Toutes les images ont le même fond blanc uni. Cette diversité en fait une ressource précieuse pour les applications d’apprentissage automatique et de vision par ordinateur. Cela permet d’éviter à la fois le surapprentissage et le sous-apprentissage.
Chargement et exploration de l'ensemble de données
Commençons par importer les bibliothèques de base requises. Ce projet nécessite Tensorflow, Tensorflow Hub, des ensembles de données Tensorflow pour l'ensemble de données, matplotlib pour la visualisation, numpy et OS.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import matplotlib.pylab as plt
import numpy as np
import os
À l'aide des ensembles de données Tensorflow, chargez l'ensemble de données « Rock Paper Scissors ». Ici, nous lui fournissons quatre paramètres. Nous devons mentionner le nom de l'ensemble de données que nous devons charger. Ici, c'est rock_paper_scissors. Pour demander des informations sur l'ensemble de données, définissez with_info sur True. Ensuite, pour charger l'ensemble de données au format supervisé, définissez as_supervised sur True.
Et enfin, définissez les splits que nous souhaitons charger. Ici, nous devons former et tester les partitions. Chargez les ensembles de données et les informations dans les variables correspondantes.
datasets, info = tfds.load( name='rock_paper_scissors', # Specify the name of the dataset you want to load. with_info=True, # To request information about the dataset as_supervised=True, # Load the dataset in a supervised format. split=['train', 'test'] # Define the splits you want to load.
)
Imprimer les informations
Imprimez maintenant les informations. Il publiera tous les détails de l'ensemble de données. Il s'agit du nom, de la version, de la description, de la ressource de l'ensemble de données d'origine, des caractéristiques, du nombre total d'images, des numéros fractionnés, de l'auteur et bien d'autres détails.
info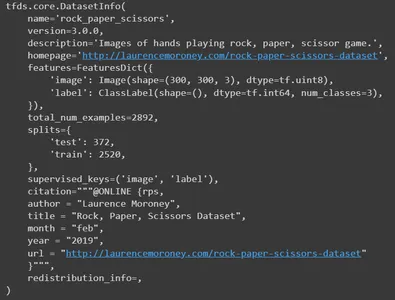
Maintenant, imprimez quelques exemples d’images à partir de l’ensemble de données d’entraînement.
train, info_train = tfds.load(name='rock_paper_scissors', with_info=True, split='train')
tfds.show_examples(info_train,train)
Nous chargeons d’abord l’ensemble de données « Rock Paper Scissors » avec les enfants. Fonction Load (), spécifiant séparément les divisions de formation et de test. Ensuite, nous concaténons les ensembles de données de formation et de test à l’aide de la méthode .concatenate(). Enfin, nous mélangeons l'ensemble de données combiné à l'aide de la méthode .shuffle() avec une taille de tampon de 3000 XNUMX. Vous disposez désormais d'une seule variable d'ensemble de données qui combine les données d'entraînement et de test.
dataset=datasets[0].concatenate(datasets[1])
dataset=dataset.shuffle(3000)Nous devons diviser l'ensemble de données en ensembles de données de formation, de test et de validation à l'aide des méthodes skip() et take(). Nous utilisons les 600 premiers échantillons de l'ensemble de données pour la validation. Ensuite, nous créons un ensemble de données temporaire en excluant les 600 images initiales. Dans cet ensemble de données temporaires, nous sélectionnons les 400 premières photos à tester. Encore une fois, dans l'ensemble de données d'entraînement, il prend toutes les images de l'ensemble de données temporaires après avoir ignoré les 400 premières images.
Voici un résumé de la façon dont les données sont divisées :
- rsp_val : 600 exemples pour validation.
- rsp_test : 400 échantillons à tester.
- rsp_train : les exemples restants pour la formation.
rsp_val=dataset.take(600)
rsp_test_temp=dataset.skip(600)
rsp_test=rsp_test_temp.take(400)
rsp_train=rsp_test_temp.skip(400)Voyons donc combien d'images se trouvent dans l'ensemble de données d'entraînement.
len(list(rsp_train)) #1892
#It has 1892 images in totalPré-traitement des données
Maintenant, effectuons un prétraitement pour notre ensemble de données. Pour cela, nous définirons une échelle de fonctions. Nous lui passerons l'image et son étiquette correspondante comme arguments. En utilisant la méthode cast, nous convertirons le type de données de l'image en float32. Ensuite, à l’étape suivante, nous devons normaliser les valeurs des pixels de l’image. Il met à l'échelle les valeurs de pixels de l'image dans la plage [0, 1]. Le redimensionnement des images est une étape de prétraitement courante permettant de garantir que toutes les images d'entrée ont les dimensions exactes, souvent requises lors de la formation de modèles d'apprentissage profond. Nous renverrons donc les images de taille [224,224]. Pour les étiquettes, nous effectuerons un encodage onehot. L'étiquette sera convertie en un vecteur codé à chaud si vous avez trois classes (Pierre, Papier, Ciseaux). Ce vecteur est renvoyé.
Par exemple, si le label est 1 (Papier), il sera transformé en [0, 1, 0]. Ici, chaque élément correspond à une classe. Le « 1 » est placé à la position correspondant à cette classe particulière (Papier). De même, pour les étiquettes de roche, le vecteur sera [1, 0, 0], et pour les ciseaux, ce sera [0, 0, 1].
Code
def scale(image, label): image = tf.cast(image, tf.float32) image /= 255.0 return tf.image.resize(image,[224,224]), tf.one_hot(label, 3)Maintenant, définissez une fonction pour créer des ensembles de données par lots et prétraités pour la formation, les tests et la validation. Appliquez la fonction d'échelle prédéfinie aux trois ensembles de données. Définissez la taille du lot sur 64 et transmettez-la comme argument. Ceci est courant dans le deep learning, où les modèles sont souvent formés sur des lots de données plutôt que sur des exemples individuels. Nous devons mélanger l'ensemble de données du train pour éviter le surajustement. Enfin, renvoyez les trois ensembles de données mis à l'échelle.
def get_dataset(batch_size=64): train_dataset_scaled = rsp_train.map(scale).shuffle(1900).batch(batch_size) test_dataset_scaled = rsp_test.map(scale).batch(batch_size) val_dataset_scaled = rsp_val.map(scale).batch(batch_size) return train_dataset_scaled, test_dataset_scaled, val_dataset_scaledChargez les trois ensembles de données individuellement à l'aide de la fonction get_dataset. Ensuite, mettez en cache les ensembles de données d’entraînement et de validation. La mise en cache est une technique précieuse pour améliorer les performances de chargement des données, en particulier lorsque vous disposez de suffisamment de mémoire pour stocker les ensembles de données. La mise en cache signifie que les données sont chargées en mémoire et conservées pour un accès plus rapide pendant les étapes de formation et de validation. Cela peut accélérer la formation, en particulier si votre processus de formation implique plusieurs époques, car cela évite de charger de manière répétée les mêmes données depuis le stockage.
train_dataset, test_dataset, val_dataset = get_dataset()
train_dataset.cache()
val_dataset.cache()Chargement d'un modèle pré-entraîné
À l'aide de Tensorflow Hub, chargez un extracteur de fonctionnalités MobileNet V2 pré-entraîné. Et configurez-le comme une couche dans un Modèle Kéras. Ce modèle MobileNet est formé sur un grand ensemble de données et peut être utilisé pour extraire des fonctionnalités à partir d'images. Maintenant, créez une couche keras à l'aide de l'extracteur de fonctionnalités MobileNet V2. Ici, spécifiez le input_shape comme (224, 224, 3). Cela indique que le modèle attend des images d'entrée de dimensions 224 × 224 pixels et trois canaux de couleur (RVB). Définissez l'attribut entraînable de cette couche sur False. Cela indique que vous ne souhaitez pas affiner le modèle MobileNet V2 pré-entraîné pendant votre processus de formation. Mais vous pouvez ajouter vos calques personnalisés par-dessus.
feature_extractor = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
feature_extractor_layer = hub.KerasLayer(feature_extractor, input_shape=(224,224,3))
feature_extractor_layer.trainable = FalseModèle de bâtiment
Il est temps de créer le modèle séquentiel TensorFlow Keras en ajoutant des couches à la couche d'extracteur de fonctionnalités MobileNet V2. Au feature_extractor_layer, nous ajouterons une couche de suppression. Nous fixerons ici un taux d'abandon de 0.5. Cette méthode de régularisation est ce que nous faisons pour éviter le surajustement. Pendant l'entraînement, si le taux d'abandon est fixé à 0.5, le modèle perdra en moyenne 50 % des unités. Ensuite, nous ajoutons une couche dense avec trois unités de sortie et, dans cette étape, nous utilisons la fonction d'activation « softmax ». « Softmax » est une fonction d'activation largement utilisée pour résoudre des problèmes de classification multi-classes. Il calcule la distribution de probabilité sur les classes de chaque image d'entrée (Pierre, Papier, Ciseaux). Ensuite, imprimez le résumé du modèle.
model = tf.keras.Sequential([ feature_extractor_layer, tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(3,activation='softmax')
]) model.summary()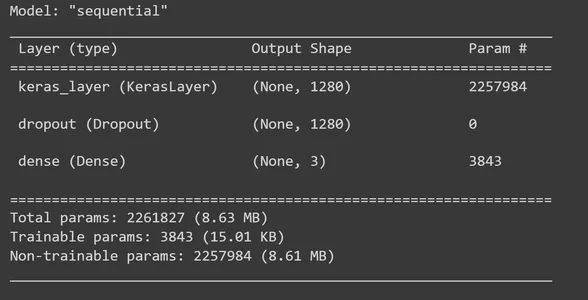
Il est temps de compiler notre modèle. Pour cela, nous utilisons l'optimiseur Adam et la fonction de perte C.ategoricalCrossentropy. L'argument from_logits=True indique que la sortie de votre modèle produit des logits bruts (scores non normalisés) au lieu de distributions de probabilité. Pour surveiller pendant la formation, nous utilisons des mesures de précision.
model.compile( optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['acc'])Les fonctions appelées rappels peuvent être exécutées à différentes étapes de la formation, y compris à la fin de chaque lot ou époque. Dans ce contexte, nous définissons un rappel personnalisé dans TensorFlow Keras dans le but de collecter et d'enregistrer les valeurs de perte et de précision au niveau du lot pendant la formation.
class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()Maintenant, créez un objet de la classe créée. Ensuite, entraînez le modèle à l'aide de la méthode fit_generator. Pour ce faire, nous devons fournir les paramètres nécessaires. Nous avons besoin d'un ensemble de données de formation mentionnant le nombre d'époques dont il a besoin pour s'entraîner, l'ensemble de données de validation et les rappels définis.
batch_stats_callback = CollectBatchStats() history = model.fit_generator(train_dataset, epochs=5, validation_data=val_dataset, callbacks = [batch_stats_callback])visualisations
À l'aide de matplotlib, tracez la perte d'entraînement au fil des étapes d'entraînement à l'aide des données collectées par le rappel CollectBatchStats. Nous pouvons observer comment la perte est optimisée sur le terrain au fur et à mesure de la progression de la formation.
plt.figure()
plt.ylabel("Loss")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses)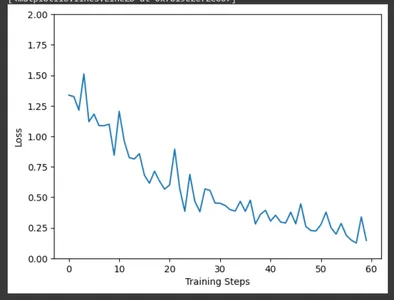
De même, tracez la précision des étapes d’entraînement. Ici aussi, on peut observer l’augmentation de la précision au fur et à mesure de la progression de l’entraînement.
plt.figure()
plt.ylabel("Accuracy")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc)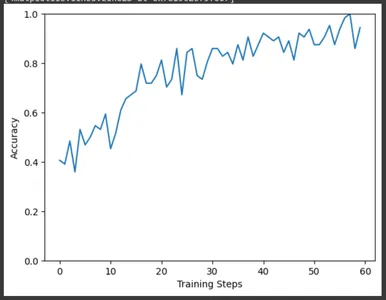
Évaluation et résultats
Il est temps d'évaluer notre modèle à l'aide d'un ensemble de données de test. La variable result contiendra les résultats de l'évaluation, y compris la perte de test et toute autre métrique que vous avez définie lors de la compilation du modèle. Extrayez la perte de test et la précision du test du tableau de résultats et imprimez-les. Nous obtiendrons une perte de 0.14 et une précision d'environ 96% pour notre modèle.
result=model.evaluate(test_dataset)
test_loss = result[0] # Test loss
test_accuracy = result[1] # Test accuracy
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_accuracy}") #Test Loss: 0.14874716103076935
#Test Accuracy: 0.9674999713897705
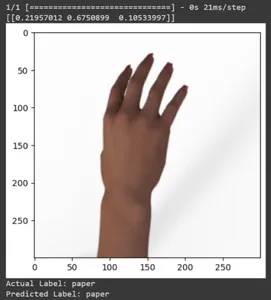
Voyons la prédiction pour quelques images de test. Cette boucle parcourt les dix premiers échantillons de l'ensemble de données rsp_test. Appliquez la fonction d'échelle pour prétraiter l'image et l'étiquette. Nous effectuons la mise à l'échelle de l'image et l'encodage one-hot de la marque. Il imprimera l'étiquette réelle (convertie à partir d'un format codé à chaud) et l'étiquette prédite (basée sur la classe avec la probabilité la plus élevée dans les prédictions).
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])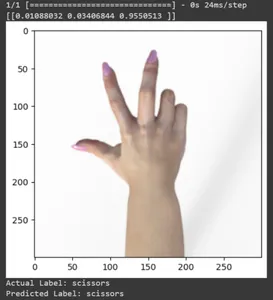
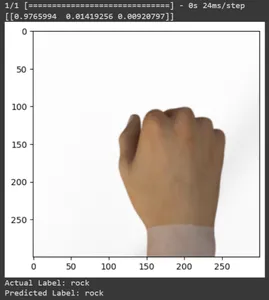
Imprimons les prédictions de toutes les images de test. Il générera des prévisions pour l'ensemble de données de test à l'aide de votre modèle TensorFlow Keras entraîné, puis extraira les étiquettes de classe (indices de classe) avec la probabilité la plus élevée pour chaque prédiction.
np.argmax(model.predict(test_dataset),axis=1)Imprimez la matrice de confusion pour les prédictions du modèle. La matrice de confusion fournit une analyse détaillée de la manière dont les prédictions du modèle s'alignent sur les étiquettes. Il s'agit d'un outil précieux pour évaluer les performances d'un modèle de classification. Il donne à chaque classe de vrais positifs, de vrais négatifs et de faux positifs.
for f0,f1 in rsp_test.map(scale).batch(400): y=np.argmax(f1, axis=1) y_pred=np.argmax(model.predict(f0),axis=1) print(tf.math.confusion_matrix(labels=y, predictions=y_pred, num_classes=3)) #Output tf.Tensor(
[[142 3 0] [ 1 131 1] [ 0 1 121]], shape=(3, 3), dtype=int32) Enregistrement et chargement du modèle entraîné
Enregistrez le modèle entraîné. Ainsi, lorsque vous devez utiliser le modèle, vous n'avez pas besoin de tout enseigner à partir de zéro. Vous devez charger le modèle et l'utiliser pour la prédiction.
model.save('./path/', save_format='tf')Vérifions le modèle en le chargeant.
loaded_model = tf.keras.models.load_model('path')De même, comme nous l'avons fait précédemment, testons le modèle avec quelques exemples d'images dans l'ensemble de données de test.
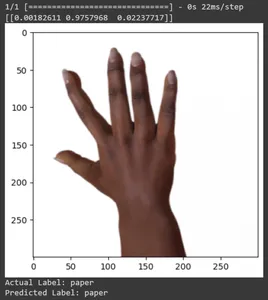
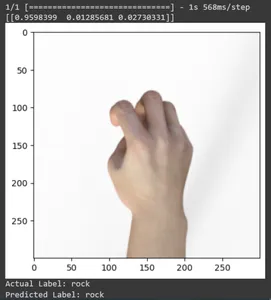
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=loaded_model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])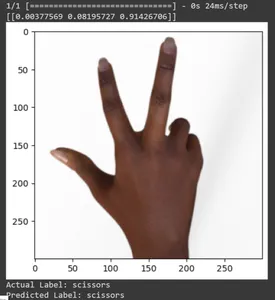
Conclusion
Dans cet article, nous avons appliqué l'apprentissage par transfert pour la tâche de classification Pierre-Papier-Ciseaux. Nous avons utilisé un modèle Mobilenet V2 pré-entraîné pour cette tâche. Notre modèle fonctionne avec succès avec une précision d'environ 96 %. Dans les images de prédictions, nous pouvons voir dans quelle mesure notre modèle prédit. Les trois derniers clichés montrent à quel point c'est parfait, même si la pose de la main est imparfaite. Pour représenter des « ciseaux », ouvrez trois doigts au lieu d'utiliser une configuration à deux doigts. Pour « Rock », ne formez pas un poing complètement fermé. Mais notre modèle peut néanmoins comprendre la classe correspondante et la prédire parfaitement.
Faits marquants
- L’apprentissage par transfert consiste avant tout à transférer des connaissances. Les connaissances acquises lors de la tâche précédente sont utilisées pour apprendre un nouveau travail.
- L’apprentissage par transfert a le potentiel de révolutionner le domaine de l’apprentissage automatique. Il offre plusieurs avantages, notamment un apprentissage accéléré et des performances améliorées.
- L'apprentissage par transfert favorise l'apprentissage continu, où les modèles peuvent changer au fil du temps pour gérer de nouvelles informations, tâches ou environnement.
- Il s'agit d'une méthode flexible et efficace qui augmente l'efficacité et l'efficience des modèles d'apprentissage automatique.
- Dans cet article, nous avons tout appris sur l'apprentissage par transfert, ses avantages et ses applications. Nous avons également implémenté l'utilisation d'un modèle pré-entraîné sur un nouvel ensemble de données pour effectuer la tâche de classification pierre-papier-ciseaux.
Foire aux questions (FAQ)
A. L'apprentissage par transfert est l'amélioration de l'apprentissage dans une nouvelle tâche grâce au transfert de connaissances à partir d'une leçon connexe qui a déjà été découverte. Cette technique permet aux algorithmes de mémoriser de nouvelles tâches à l'aide de modèles pré-entraînés.
A. Vous pouvez adapter ce projet à d'autres tâches de classification d'images en remplaçant l'ensemble de données Rock-Paper-Scissors par votre ensemble de données. De plus, vous devez affiner le modèle en fonction des exigences du nouvel emploi.
R. MobileNet V2 est un modèle d'extracteur de fonctionnalités pré-entraîné disponible dans TensorFlow Hub. Dans les scénarios d'apprentissage par transfert, les praticiens utilisent souvent MobileNetV2 comme extracteur de fonctionnalités. Ils affinent le modèle MobileNetV2 pré-entraîné pour une tâche particulière en incorporant des couches spécifiques à la tâche au-dessus. Son approche permet une formation rapide et efficace sur diverses tâches de vision par ordinateur.
R. TensorFlow est un framework d'apprentissage automatique open source développé par Google. Largement utilisé pour créer et former des modèles d’apprentissage automatique et des modèles d’apprentissage intense.
A. Le réglage fin est une technique d'apprentissage par transfert partagé dans laquelle vous prenez un modèle pré-entraîné et le formez davantage sur votre tâche spécifique avec un taux d'apprentissage inférieur. Cela permet au modèle d'adapter ses connaissances aux nuances de la tâche cible.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/10/transfer-learning-a-rock-paper-scissors-case-study/

