Cet article a été publié dans le cadre du Blogathon sur la science des données.
Introduction sur la mémoire à long terme
Avez-vous vu "Souvenir” ou il y a des problèmes de mémoire à court terme. LSTM est une version spéciale de RNN qui résout ce problème de RNN grâce au concept de portes.
Les problèmes de prédiction de séquences sont considérés depuis longtemps comme l'un des problèmes les plus difficiles. Ils incluent un large éventail de problèmes allant de la prédiction du mot suivant de la phrase à la recherche de modèles dans les données boursières, de la compréhension des intrigues de films à la reconnaissance de votre façon de parler. Comme nous l'avons déjà évoqué, le LSTM travaille sur le concept de portes. Il y a 3 portes principales dans LSTM nommé Oubliez la porte, la porte d'entrée et Porte de sortie.
Dans l'article précédent, nous avons déjà discuté de la façon dont la mémoire à long court terme résout les limitations du RNNS, dans cet article, nous comprendrons toutes les portes en détail et examinerons une implémentation simple de cet algorithme.
Idée de base derrière LSTM
La mémoire à long terme ou LSTM est capable d'apprendre des dépendances à long terme. Cet algorithme a été introduit pour la première fois par Hochreiter et Schmidhuber en 1997. Les LSTM fonctionnent bien sur une grande variété de problèmes séquentiels et sont maintenant largement utilisés dans l'industrie. Se souvenir du contexte de la phrase pendant une longue période est leur comportement par défaut, pas quelque chose qu'ils ont du mal à apprendre.
Les réseaux de neurones récurrents ont une structure très simple, comme une seule couche tan-h :
D'autre part, la mémoire à long court terme a également une structure en forme de chaîne, mais elle est légèrement différente de RNN. Ils travaillent sur les concepts de Gate.

Ne vous détraquez pas avec cette architecture, nous allons la décomposer en étapes plus simples qui en feront un morceau de gâteau à saisir. LSTM a principalement 3 portes
- Oubliez la porte
- Porte d'entrée
- Porte de sortie
Examinons de près toutes ces portes et essayons de comprendre les moindres détails derrière toutes ces portes.
Oubliez la porte
Prenons un exemple de problème de prédiction de texte.

Dès que 'while' est rencontré, la porte d'oubli se rend compte qu'il peut y avoir un changement dans le sujet de la phrase ou le contexte de la phrase. Par conséquent, le sujet de la phrase est oublié et la place du sujet est libérée. Quand on commence à parler de « Chirag », cette position du sujet est attribuée à « Chirag ».
Toutes les informations non pertinentes sont supprimées via la multiplication d'un filtre. Ceci est nécessaire pour optimiser l'exécution du réseau LSTM.

L'état caché précédent Ht-1 et le vecteur événement courant Xt sont réunis et multipliés par la matrice de poids avec un ajout de l'activation sigmoïde et un certain biais, qui génère les scores de probabilité. Puisqu'une activation sigmoïde est appliquée, la sortie sera toujours 0 ou 1. Si la sortie est 0 pour la valeur particulière dans l'état de la cellule, cela signifie que la porte d'oubli veut oublier cette information. De même, un 1 signifie qu'il veut se souvenir de l'information. Maintenant, cette sortie vectorielle de la fonction sigmoïde est multipliée par l'état de la cellule.
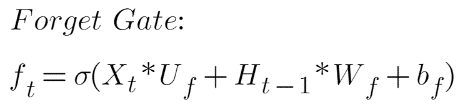
Ici:
Xt est le vecteur d'entrée actuel
Uf est le poids associé à l'entrée
Ht-1 est l'état caché précédent
Wf est le poids associé à l'état caché
Bf est le biais qui s'y ajoute
Si nous prenons le poids commun, alors cette formule peut s'écrire :
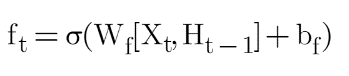
Regardons maintenant l'équation de l'état de la cellule mémoire qui est :
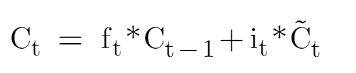
Si vous voyez ici, la porte oubliée est multipliée par l'état de la cellule de l'horodatage précédent et il s'agit d'une multiplication élément par élément. Chaque fois que nous avons 1 dans la matrice de la porte oubliée, elle conservera la valeur et chaque fois que nous aurons 0 dans la porte oubliée, elle éliminera cette information. Prenons un exemple :

Chaque fois que notre modèle verra M. Watson, il conservera cette information ou ce contexte dans l'état de cellule C1 . Maintenant, C sera une matrice, n'est-ce pas ? Ainsi, une partie de sa valeur conservera les informations que nous avons ici avec M. Watson et maintenant la porte d'oubli ne permettra pas aux informations de changer et c'est pourquoi les informations seront conservées tout au long. Dans RNN, ces informations auraient changé rapidement au fur et à mesure que notre modèle voit le mot suivant. Maintenant, quand nous rencontrons un autre mot disons Mme Mary, alors maintenant la porte d'oubli oubliera les informations de M. Watson et ajoutera les informations de Mme Mary. Cet ajout de nouvelles informations se fait par une autre porte dite Input gate que nous étudierons ensuite.
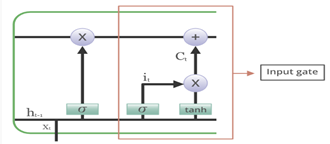
Porte d'entrée
Pour avoir l'intuition derrière cela, prenons un autre exemple :

Ici, l'information importante est que "Prince" se sentait nauséeux et c'est pourquoi il n'a pas pu profiter de la fête. Le fait qu'il ait raconté tout cela au téléphone n'est pas important et peut être ignoré. Cette technique d'ajout de nouvelles connaissances/informations peut être effectuée via le contribution portail. Il est essentiellement utilisé pour quantifier l'importance des nouvelles informations portées par l'entrée.
L'équation de la porte d'entrée est :
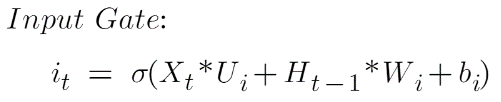
Ici:
Xt est le vecteur d'entrée actuel à l'horodatage t
Ui est la matrice de pondération associée à l'entrée
Ht-1 est l'état caché précédent
Wi est le poids associé à l'état caché
bi est le biais qui s'y ajoute
Si nous prenons le poids commun, alors cette formule peut s'écrire :

Maintenant, nous devons comprendre la valeur du candidat. Regardons à nouveau l'équation d'état de la cellule mémoire :
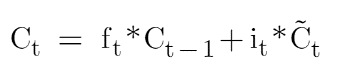
Où ![]() est la valeur candidate représentée par :
est la valeur candidate représentée par :
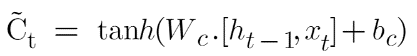
L'équation de la valeur candidate est très similaire au réseau neuronal récurrent simple. Cette valeur candidate sera chargée d'ajouter de nouvelles informations et comme son nom l'indique "Valeur candidate", il s'agit d'une valeur candidate qui signifie de nouvelles informations potentielles que nous pouvons ajouter, et que de nouvelles informations potentielles seront filtrées par cette porte d'entrée.
Puisque nous utilisons la fonction d'activation sigmoïde dans la porte d'entrée, nous savons que la sortie de la porte d'entrée sera dans la plage de 0-1, et donc elle filtrera les nouvelles informations à ajouter puisque la valeur candidate a tan- h fonction d'activation qui signifie que sa valeur sera comprise entre 1 et -1. Si la valeur est négative, les informations sont soustraites de l'état de la cellule et si elle est positive, les informations sont ajoutées à l'état de la cellule à l'horodatage actuel. Prenons un exemple.

Maintenant, clairement au lieu de "elle", cela devrait être "son", et à la place de "était", cela devrait être "volonté" parce que si nous regardons le contexte, le lecteur parle du futur. Ainsi, chaque fois que notre modèle atteint ce mot "demain", il doit également ajouter cette information avec toutes les informations dont il disposait auparavant. C'est donc un exemple où nous n'avons rien à oublier, mais nous ajoutons simplement de nouvelles informations tout en conservant les informations utiles que nous avions auparavant. Ainsi, ce modèle a la capacité de conserver les anciennes informations pendant une longue période tout en ajoutant des informations.
Porte de sortie
Toutes les informations circulant dans l'état de la cellule mémoire ne sont pas aptes à être émises. Visualisons cela avec un exemple :

Dans cette phrase, il pourrait y avoir un certain nombre de sorties pour l'espace vide. Si un être humain lisait cette phrase, alors il devinerait que le dernier mot "courageux" est un adjectif utilisé pour décrire un nom, et donc il/elle devinera que la réponse doit être un nom. Ainsi, la sortie appropriée pour ce blanc serait 'Bob'.
Le travail de sélection des informations utiles à partir de l'état de la cellule mémoire est effectué via la porte de sortie. Regardons l'équation de la porte de sortie :
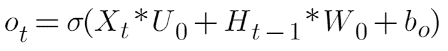
Où es-tuo et Wo sont les poids attribués respectivement au vecteur d'entrée et à l'état caché. La valeur de la porte de sortie est également comprise entre 0 et 1 puisque nous utilisons la fonction d'activation sigmoïde. Pour calculer l'état caché, nous utiliserons l'état de la porte de sortie et de la cellule mémoire :
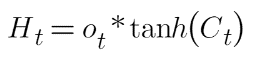
Où Ot est la matrice de la porte de sortie et Ct est la matrice d'état cellulaire.

L'architecture globale de LSTM ressemble à ceci :

Vous devez vous demander comment ces portes savent quelles informations oublier et lesquelles ajouter, et les réponses se trouvent dans les matrices de poids. N'oubliez pas que nous allons entraîner ce modèle et après l'entraînement, les valeurs de ces poids seront mises à jour de telle manière qu'il construira un certain niveau de compréhension, ce qui signifie qu'après l'entraînement, notre modèle développera une compréhension de quelles informations sont utiles et lesquelles l'information n'est pas pertinente et cette compréhension se construit en examinant des milliers et des milliers de données.
Une mise en œuvre est nécessaire
Construisons un modèle qui peut prédire certains n nombre de caractères après le texte original de Macbeth. Le texte original se trouve ici. Une édition révisée du fichier .txt est disponible ici.
We
Importation de bibliothèques
# Importation des dépendances numpy et keras import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.utils import np_utils
Chargement du fichier texte
#load text filename = "macbeth.txt" text = (open(filename).read()).lower() # mappage de caractères avec des entiers unique_chars = triés(list(set(text))) char_to_int = {} int_to_char = { } for i, c in enumerate (unique_chars): char_to_int.update({c: i}) int_to_char.update({i: c})
Dans le code ci-dessus, nous lisons le fichier '.txt' de notre système. Dans uniques_chars nous avons tous les caractères uniques dans le texte. Dans char_to_int tous les caractères uniques du texte ont reçu un numéro car l'ordinateur ne peut pas comprendre le mot, nous devons donc le convertir en langage machine. Ceci est fait pour faciliter la partie calcul
Préparation de l'ensemble de données
#preparing input and output dataset X = [] Y = [] for i in range(0,n-50,1): sequence = text[I:i+50] label = text[i+50] X.append( [char_to_int[char] for char in s]) Y.append(char_to_int[label])
Nous préparerons notre modèle de telle manière que si nous voulons prédire 'O' dans 'HELLO', nous ressentirons ['H','E','L','L'] comme entrée et nous obtiendrons [ 'O'] comme sortie. De même, ici nous fixons la longueur de la fenêtre que nous voulons (fixée à 50 dans l'exemple) puis sauvegardons les encodages des 49 premiers caractères dans X et la sortie attendue c'est-à-dire le 50ème caractère dans Y.
Remodelage de X
#reshaping, normalisation et un encodage à chaud X_modified = numpy.reshape(X,(len(X),50,1)) X_modified = X_modified/float(len(ujique_chars)) Y_modified = np_utils.to_categorical(Y)
Obtenir l'entrée dans la bonne forme est la partie la plus cruciale de cette implémentation. Nous devons comprendre comment LSTM accepte l'entrée et sous quelle forme il a besoin de notre entrée. Si vous consultez la documentation, vous constaterez qu'elle prend des entrées dans [Samples, Time-steps, Features] où les échantillons sont le nombre de points de données dont nous disposons, les pas de temps sont la taille de la fenêtre (combien de mots voulez-vous regarder retour afin de prédire le mot suivant), les caractéristiques font référence au nombre de variables dont nous disposons pour la valeur réelle correspondante dans Y.
La mise à l'échelle des valeurs est une partie très cruciale lors de la construction d'un modèle et, par conséquent, nous mettons à l'échelle les valeurs dans X_modified entre 0-1 et une encodage à chaud des valeurs vraies dans Y_modified.
Définition du modèle LSTM
# définir le modèle LSTM model = Sequential() model.add(LSTM(300,input_shape=(X_modified.shape[1],X_modified.shape[2]),return_sequences=True)) model.add(Dropout(0.2)) model.add(LSTM(300)) model.add(Dropout(0.2)) model.add(Dense(Y_modified.shape[1],activation = 'softmax')) model.compile(loss='categorical_crossentropy' , optimiseur = 'adam) modèle.summary()
Dans la première couche, nous prenons 300 unités de mémoire et nous utilisons également des séquences de retour d'hyperparamètres qui garantissent que la couche suivante reçoit des séquences et pas seulement des données aléatoires. Regardez l'hyperparamètre 'input_shape' ici, j'ai passé des pas de temps et un certain nombre de fonctionnalités et par défaut, il sélectionnera tous les points de données disponibles. Si vous êtes toujours confus, veuillez imprimer la forme de X_modified et vous comprendrez ce que j'essaie de dire. Ensuite, j'utilise une couche A Dropout ici pour éviter le surajustement. Enfin, nous avons une couche entièrement connectée avec une fonction d'activation "softmax" et des neurones égaux à un nombre de caractères uniques.
Ajuster le modèle et faire des prédictions
# adapter le modèle
model.fit (X_modified, Y_modified, époques = 200, batch_size = 40)
# choisir une graine au hasard
start_index = numpy.random.randint(0, len(X)-1)
prédire_chaîne = X[start_index]
# générer des caractères
pour i dans la plage (50):
x = numpy.reshape(predict_string, (1, len(predict_string), 1))
x = x / float(len(unique_chars))
#prédire
pred_index = numpy.argmax(model.predict(x, verbeux=0))
char_out = int_to_char[pred_index]
seq_in = [int_to_char[value] pour la valeur dans predict_string]
impression(char_out)
prévoir_string.append(pred_index)
prévoir_string = prédire_string[1:len(predict_string)]
Le modèle est ajusté sur 200 époques, avec une taille de lot de 40. Pour la prédiction, nous prenons d'abord au hasard un indice de départ. Nous plaçons cette phrase aléatoire dans une variable nommée 'predict_string'. Nous remodelons ensuite get à partir du modèle pour donner le codage de caractères du caractère prédit, ce qui signifie que la sortie sera numérique, nous le décodons donc en valeur de caractère, puis l'ajoutons au modèle. Finalement, après suffisamment d'époques d'entraînement, cela donnera de meilleurs résultats au fil du temps. C'est ainsi que vous utiliseriez LSTM pour résoudre une tâche de prédiction de séquence.
Conclusion sur la mémoire à long terme
Les LSTM ou mémoire à long terme sont un cas particulier de RNN qui tente de résoudre les problèmes rencontrés par RNN. Les problèmes tels que les dépendances à long terme, la disparition et les problèmes de gradient explosif sont résolus très facilement par la mémoire à long terme à l'aide de portes. Il a principalement 3 portes appelées Forget Gate, Input Gate et Output Gate. Forget gate est utilisé pour oublier les informations inutiles. La porte d'entrée est utilisée pour ajouter de nouvelles informations importantes au modèle. De plus, les informations ne sont pas mises à jour rapidement contrairement aux RNN.
Voici quelques points clés de l'article :
- La mémoire à long court terme ou LSTM est utilisée pour les données séquentielles telles que les données de séries chronologiques, les données audio, etc.
- La mémoire à long court terme ou LSTM surpasse les autres modèles lorsque nous voulons que notre modèle apprenne des dépendances à long terme.
- Il résout les problèmes rencontrés par RNN (Vanishing and exploding gradient problems).
- Il travaille sur les concepts du gate (Forget gate, Input gate, et Output gate).
- 2 états sont transmis au prochain horodatage qui sont l'état caché et l'état de la cellule.
- La capacité de la mémoire à long court terme à oublier, mémoriser et mettre à jour les informations lui donne une longueur d'avance sur les RNN.
J'espère que cet article vous a plu si oui alors commentez et partagez le avec vos amis pour qu'ils puissent en profiter. Pour toute doute ou question, n'hésitez pas à me contacter par Email
Connectez-vous avec moi sur LinkedIn et Twitter
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.

