Introduction
Dans le monde numérique en évolution rapide d’aujourd’hui, la diffusion de fausses nouvelles est devenue une préoccupation majeure. Avec la facilité croissante d’accès aux plateformes de médias sociaux et à d’autres sources d’information en ligne, il est devenu plus difficile de faire la distinction entre les vraies et les fausses nouvelles. Dans cet article basé sur un projet, nous apprendrons comment créer un modèle d'apprentissage automatique pour détecter avec précision les fausses nouvelles.

Objectifs d'apprentissage:
- Comprendre les bases de traitement du langage naturel (NLP) et comment il peut être utilisé pour prétraiter des données textuelles pour des modèles d'apprentissage automatique.
- Découvrez comment utiliser la classe CountVectorizer de la bibliothèque scikit-learn pour convertir des données texte en vecteurs de caractéristiques numériques.
- Créez un système de détection de fausses nouvelles à l'aide d'algorithmes d'apprentissage automatique tels que la régression logistique et évaluez ses performances.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Description du projet
La diffusion de fausses nouvelles est devenue une préoccupation majeure dans la société actuelle, et il est important de pouvoir identifier les articles de presse qui ne sont pas fondés sur des faits ou qui sont intentionnellement trompeurs. Dans ce projet, nous utiliserons l'apprentissage automatique pour classer les articles d'actualité comme étant réels ou faux en fonction de leur contenu. En identifiant les faux articles, nous pouvons empêcher la propagation de la désinformation et aider les gens à prendre des décisions plus éclairées.
Ce projet concerne l'industrie des médias, les organes d'information et les plateformes de médias sociaux responsables du partage d'articles d'actualité. Classer les articles d’actualité comme étant réels ou faux peut aider ces organisations à améliorer leur modération de contenu et à réduire la propagation de fausses nouvelles.
Énoncé du problème
Ce projet vise à classer les articles d'actualité comme réels ou faux en fonction de leur contenu. Plus précisément, nous utiliserons l’apprentissage automatique pour créer un modèle permettant de prédire si un article d’actualité donné est réel ou faux en fonction de son texte.
Pré-requis
Pour mener à bien ce projet, vous devez comprendre la programmation Python, la manipulation de données, les bibliothèques de visualisation telles que Pandas et Matplotlib, ainsi que les bibliothèques d'apprentissage automatique telles que Scikit-Learn. De plus, des connaissances de base sur les techniques de traitement du langage naturel (NLP) et les méthodes de classification de texte seraient utiles.
Description de l'ensemble de données
L'ensemble de données utilisé dans ce projet est l'« ensemble de données d'actualités fausses et réelles » disponible sur Kaggle, qui contient 50,000 XNUMX articles d'actualité étiquetés comme réels ou faux. L'ensemble de données a été collecté sur divers sites Web d'information et a été prétraité pour supprimer le contenu superflu tel que les balises HTML, les publicités et le texte passe-partout. L'ensemble de données fournit des fonctionnalités telles que le titre, le texte, le sujet et la date de publication de chaque article d'actualité. L'ensemble de données peut être téléchargé à partir du lien suivant : https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset.
Les étapes que nous suivrons dans ce projet sont :
- Collecte et exploration de données
- Prétraitement de texte
- Extraction de caractéristiques
- Formation et évaluation des modèles
- Déploiement
1. Collecte et exploration des données
Pour ce projet, nous utiliserons l'ensemble de données Fake and Real News disponible sur Kaggle. L'ensemble de données contient deux fichiers CSV : un avec de vrais articles d'actualité et un autre avec de faux articles d'actualité. Vous pouvez télécharger l'ensemble de données à partir de ce lien : https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
Une fois que vous avez téléchargé l'ensemble de données, vous pouvez le charger dans un Pandas DataFrame.
Le 'real_news' DataFrame contient de vrais articles d'actualité et leurs étiquettes, ainsi que le 'fausses nouvelles' DataFrame contient de faux articles d'actualité et leurs étiquettes. Jetons un coup d'œil aux premières lignes de chaque DataFrame pour avoir une idée de ce à quoi ressemblent les données : :
Code Python :
Comme on peut le constater, les données contiennent plusieurs colonnes : le titre de l'article, le texte de l'article, le sujet de l'article et la date de publication. Nous utiliserons les colonnes de titre et de texte pour entraîner notre modèle.
Avant de pouvoir commencer à entraîner notre modèle, nous devons effectuer une analyse exploratoire des données pour avoir une idée des données. Par exemple, nous pouvons tracer la distribution des longueurs d'articles dans chaque ensemble de données en utilisant le code suivant :
import matplotlib.pyplot as plt real_lengths = real_news['text'].apply(len)
fake_lengths = fake_news['text'].apply(len) plt.hist(real_lengths, bins=50, alpha=0.5, label='Real')
plt.hist(fake_lengths, bins=50, alpha=0.5, label='Fake')
plt.title('Article Lengths')
plt.xlabel('Length')
plt.ylabel('Count')
plt.legend()
plt.show()
La sortie devrait ressembler à ceci:
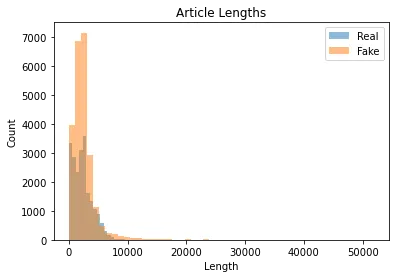
Comme on peut le constater, la longueur des articles est très variable, certains articles étant très courts (moins de 1000 40,000 caractères) et d'autres assez longs (plus de XNUMX XNUMX caractères). Nous devrons en tenir compte lors du prétraitement du texte.
Nous pouvons également examiner les mots les plus courants dans chaque ensemble de données en utilisant le code suivant :
from collections import Counter
import nltk
#downloading stopwords and punkt
nltk.download('stopwords')
nltk.download('punkt') def get_most_common_words(texts, num_words=10): all_words = [] for text in texts: all_words.extend(nltk.word_tokenize(text.lower())) stop_words = set(nltk.corpus.stopwords.words('english')) words = [word for word in all_words if word.isalpha() and word not in stop_words] word_counts = Counter(words) return word_counts.most_common(num_words) real_words = get_most_common_words(real_news['text'])
fake_words = get_most_common_words(fake_news['text']) print('Real News:', real_words)
print('Fake News:', fake_words)
La sortie devrait ressembler à ceci:
Real News: [('trump', 32505), ('said', 15757), ('us', 15247), ('president', 12788), ('would', 12337), ('people', 10749), ('one', 10681), ('also', 9927), ('new', 9825), ('state', 9820)]
Fake News: [('trump', 10382), ('said', 7161), ('hillary', 3890), ('clinton', 3588), ('one', 3466), ('people', 3305), ('would', 3257), ('us', 3073), ('like', 3056), ('also', 3005)]Comme nous pouvons le constater, certains des mots les plus courants dans les deux ensembles de données sont liés à la politique et à l’actuel président américain, Donald Trump. Il existe cependant quelques différences entre les deux ensembles de données, l’ensemble de données sur les fausses nouvelles contenant davantage de références à Hillary Clinton et une plus grande utilisation de mots comme « j’aime ».
Performance du modèle sans supprimer les mots vides (régression logistique utilisée)
Accuracy: 0.9953
Precision: 0.9940
Recall: 0.9963
F1 Score: 0.99512. Prétraitement du texte
Avant de pouvoir commencer à entraîner notre modèle, nous devons prétraiter les données textuelles. Les étapes de prétraitement que nous effectuerons sont :
- Mettre le texte en minuscule
- Supprimer la ponctuation et les chiffres
- Supprimer les mots vides
- Raciner ou lemmatiser le texte
Mettre le texte en minuscule
La mise en minuscule du texte fait référence à la conversion de toutes les lettres d'un morceau de texte en minuscules. Il s'agit d'une étape courante de prétraitement de texte qui peut être utile pour améliorer la précision des modèles de classification de texte. Par exemple, « Bonjour » et « Bonjour » seraient considérés comme deux mots différents par un modèle qui ne tient pas compte de la casse, alors que si le texte est converti en minuscules, ils seraient traités comme le même mot.
Supprimer la ponctuation et les chiffres
La suppression de la ponctuation et des chiffres fait référence à la suppression des caractères non alphabétiques d'un texte. Cela peut être utile pour réduire la complexité du texte et faciliter l’analyse d’un modèle. Par exemple, les mots « Bonjour » et « Bonjour ! » seraient considérés comme des mots différents par un modèle d'analyse de texte s'il ne tient pas compte de la ponctuation.
Supprimer les mots vides
Les mots vides sont des mots très courants dans une langue et qui n'ont pas beaucoup de sens, comme « le », « et », « dans », etc. Supprimer les mots vides d'un morceau de texte peut aider à réduire la dimensionnalité des données. et concentrez-vous sur les mots les plus importants du texte. Cela peut également contribuer à améliorer la précision d'un modèle de classification de texte en réduisant le bruit dans les données.
Raciner ou lemmatiser le texte
La radicalisation et la lemmatisation sont des techniques courantes pour réduire les mots à leur forme de base. La recherche de racines consiste à supprimer les suffixes des mots pour produire un radical ou une racine de mot. Par exemple, le mot « sauter » serait dérivé de « sauter ». Cette technique peut être utile pour réduire la dimensionnalité des données, mais elle peut parfois aboutir à des radicaux qui ne sont pas de véritables mots.
A l’inverse, la lemmatisation consiste à réduire les mots à leur forme de base à l’aide d’un dictionnaire ou d’une analyse morphologique. Par exemple, le mot « sauter » serait lemmatisé en « sauter », qui est un mot réel. Cette technique peut être plus précise que le stemming, mais aussi plus coûteuse en termes de calcul.
La recherche de racines et la lemmatisation peuvent réduire la dimensionnalité des données textuelles et faciliter l'analyse d'un modèle. Cependant, il est important de noter qu’elles peuvent parfois entraîner une perte d’informations. Il est donc important d’expérimenter les deux techniques et de déterminer laquelle fonctionne le mieux pour un problème de classification de texte particulier.
Nous effectuerons ces étapes en utilisant la bibliothèque NLTK, qui fournit divers outils de traitement de texte.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer, WordNetLemmatizer
import string nltk.download('wordnet') stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer() def preprocess_text(text): # Lowercase the text text = text.lower() # Remove punctuation and digits text = text.translate(str.maketrans('', '', string.punctuation + string.digits)) # Tokenize the text words = word_tokenize(text) # Remove stop words words = [word for word in words if word not in stop_words] # Stem or lemmatize the words words = [stemmer.stem(word) for word in words] # Join the words back into a string text = ' '.join(words) return textNous pouvons désormais appliquer cette fonction de prétraitement à chaque article de nos ensembles de données :
real_news['text'] = real_news['text'].apply(preprocess_text)
fake_news['text'] = fake_news['text'].apply(preprocess_text)3. Formation modèle
Nous pouvons entraîner notre modèle maintenant que nous avons prétraité nos données textuelles. Nous utiliserons une approche simple par sac de mots, représentant chaque article comme un vecteur de fréquences de mots. Nous utiliserons le CompteVectorizer classe de la apprendre bibliothèque pour convertir le texte prétraité en vecteurs de caractéristiques.
CountVectorizer est une technique de prétraitement de texte couramment utilisée dans le traitement du langage naturel. Il transforme une collection de documents texte en une matrice de nombre de mots. Chaque ligne de la matrice représente un document et chaque colonne représente un mot de la collection de documents.
Le CountVectorizer convertit une collection de documents texte en une matrice de nombres de jetons. Cela fonctionne en symbolisant d'abord le texte en mots, puis en comptant la fréquence de chaque mot dans chaque document. La matrice résultante peut être utilisée comme entrée dans des algorithmes d'apprentissage automatique pour des tâches telles que la classification de texte.
Le CountVectorizer possède plusieurs paramètres qui peuvent être ajustés pour personnaliser le prétraitement du texte. Par exemple, le paramètre « stop_words » peut être utilisé pour spécifier une liste de mots qui doivent être supprimés du texte avant de compter. Le paramètre « max_df » peut spécifier la fréquence maximale de document pour un mot, au-delà de laquelle le mot est considéré comme un mot vide et supprimé du texte.
L'un des avantages de CountVectorizer est qu'il est simple à utiliser et fonctionne bien pour de nombreux types de problèmes de classification de texte. Il est également très efficace en termes d'utilisation de la mémoire, car il stocke uniquement la fréquence de chaque mot dans chaque document. Un autre avantage est qu’elle est facile à interpréter, car la matrice résultante peut être directement inspectée pour comprendre l’importance des différents mots dans le processus de classification.
D'autres méthodes pour convertir des données textuelles en caractéristiques numériques incluent TF-IDF (fréquence de document inverse de fréquence de terme), Word2Vec, Doc2Vec et GloVe (Vecteurs globaux pour la représentation de mots).
TF-IDF est similaire à CountVectorizer, mais au lieu de simplement compter la fréquence de chaque mot, il prend en compte la fréquence à laquelle le mot apparaît dans l'ensemble du corpus et attribue un poids à chaque mot en fonction de son importance dans le document.
Word2Vec et Doc2Vec sont des méthodes d'apprentissage de représentations vectorielles de faible dimension de mots et de documents qui capturent les relations sémantiques sous-jacentes entre eux.
GloVe est une autre méthode d'apprentissage des représentations vectorielles de mots qui combine les avantages de TF-IDF et de Word2Vec.
Chaque méthode a ses avantages et ses inconvénients, et le choix de la méthode dépend du problème et de l'ensemble de données en question. Pour cet ensemble de données, nous utilisons CountVectorizer comme suit :
from sklearn.feature_extraction.text import CountVectorizer
import scipy.sparse as sp
import numpy as np vectorizer = CountVectorizer()
X_real = vectorizer.fit_transform(real_news['text'])
X_fake = vectorizer.transform(fake_news['text']) X = sp.vstack([X_real, X_fake])
y = np.concatenate([np.ones(X_real.shape[0]), np.zeros(X_fake.shape[0])])
Ici, nous créons d'abord un CompteVectorizer objet et s'adapter au texte prétraité dans l'ensemble de données d'actualités réelles. Nous utilisons ensuite le même vectoriseur pour transformer le texte prétraité en un ensemble de données de fausses nouvelles. Nous empilons ensuite les matrices de caractéristiques des deux ensembles de données verticalement et créons un vecteur d'étiquette correspondant, y.
Maintenant que nous disposons de nos vecteurs de fonctionnalités et d'étiquettes, nous pouvons diviser les données en ensembles d'entraînement et de test :
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Nous pouvons maintenant entraîner notre modèle à l'aide d'un classificateur de régression logistique :
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(random_state=42)
clf.fit(X_train, y_train)
4. Évaluation du modèle
Maintenant que nous avons entraîné notre modèle, nous pouvons évaluer ses performances sur l'ensemble de test. Nous utiliserons nos mesures d'évaluation pour l'exactitude, la précision, le rappel et le score F1.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred) print('Accuracy:', accuracy)
print('Precision:', precision)
print('Recall:', recall)
print('F1 Score:', f1)
La sortie devrait ressembler à ceci:
Accuracy: 0.992522617676591
Precision: 0.9918478260869565
Recall: 0.9932118684430505
F1 Score: 0.9925293344993434
Comme nous pouvons le constater, notre modèle fonctionne très bien, avec une précision de plus de 99 %.
Notre ensemble de données a atteint une précision de test de plus de 99 %, ce qui indique que le modèle peut classer avec précision les articles d'actualité comme étant réels ou faux.
Améliorer le modèle
Bien que notre modèle de régression logistique ait atteint une grande précision sur l'ensemble de tests, nous pourrions potentiellement améliorer ses performances de plusieurs manières :
- Ingénierie des fonctionnalités : au lieu d'utiliser une approche par sac de mots, nous pourrions utiliser des représentations de texte plus avancées, telles que des intégrations de mots ou des modèles de sujets, qui peuvent capturer des relations plus nuancées entre les mots.
- Réglage des hyperparamètres : nous pourrions ajuster les hyperparamètres du modèle de régression logistique à l'aide de méthodes telles que la recherche par grille ou la recherche aléatoire pour trouver l'ensemble optimal de paramètres pour notre ensemble de données.
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# Define a function to train and evaluate a model
def train_and_evaluate_model(model, X_train, y_train, X_test, y_test): # Train the model on the training data model.fit(X_train, y_train) # Predict the labels for the testing data y_pred = model.predict(X_test) # Evaluate the model accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') # Print the evaluation metrics print(f"Accuracy: {accuracy:.4f}") print(f"Precision: {precision:.4f}") print(f"Recall: {recall:.4f}") print(f"F1-score: {f1:.4f}")
# Train and evaluate a Multinomial Naive Bayes model
print("Training and evaluating Multinomial Naive Bayes model...")
nb = MultinomialNB()
train_and_evaluate_model(nb, X_train, y_train, X_test, y_test)
print() # Train and evaluate a Support Vector Machine model
print("Training and evaluating Support Vector Machine model...")
svm = SVC()
train_and_evaluate_model(svm, X_train, y_train, X_test, y_test)Et les résultats sont:
J'ai ajouté un extrait de code pour régler les hyperparamètres à l'aide de GridSearchCV. Vous utilisez également RandomSearchCV ou BayesSearchCV pour régler les hyperparamètres.
from sklearn.model_selection import GridSearchCV # Define a list of hyperparameters to search over
hyperparameters = { 'penalty': ['l1', 'l2'], 'C': [0.1, 1, 10, 100], 'solver': ['liblinear', 'saga']
} # Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(LogisticRegression(), hyperparameters, cv=5)
grid_search.fit(X_train, y_train) # Print the best hyperparameters and test accuracy
print('Best hyperparameters:', grid_search.best_params_)
print('Test accuracy:', grid_search.score(X_test, y_test))
Expérimenter ces méthodes pourrait améliorer encore davantage la précision de notre modèle.
Sauvegarde de notre modèle :
from joblib import dump dump(clf, 'model.joblib')
dump(vectorizer, 'vectorizer.joblib')
La fonction dump de la bibliothèque joblib peut être utilisée pour enregistrer le modèle clf dans le fichier model.joblib. Une fois le modèle enregistré, il peut être chargé dans d'autres scripts Python à l'aide de la fonction de chargement, comme indiqué dans la réponse précédente.
5. Déploiement du modèle
Enfin, nous pouvons déployer notre modèle en tant qu'application Web en utilisant le framework Flask. Nous créerons un formulaire Web simple dans lequel les utilisateurs pourront saisir du texte, et le modèle indiquera si le texte est susceptible d'être une vraie ou une fausse nouvelle.
from flask import Flask, request, render_template
from joblib import load
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer, WordNetLemmatizer
import string stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer() clf = load('model.joblib')
vectorizer = load('vectorizer.joblib')
def preprocess_text(text): # Lowercase the text text = text.lower() # Remove punctuation and digits text = text.translate(str.maketrans('', '', string.punctuation + string.digits)) # Tokenize the text words = word_tokenize(text) # Remove stop words words = [word for word in words if word not in stop_words] # Stem or lemmatize the words words = [stemmer.stem(word) for word in words] # Join the words back into a string text = ' '.join(words) return text app = Flask(__name__) @app.route('/')
def home(): return render_template('home.html') @app.route('/predict', methods=['POST'])
def predict(): text = request.form['text'] preprocessed_text = preprocess_text(text) X = vectorizer.transform([preprocessed_text]) y_pred = clf.predict(X) if y_pred[0]== 1: result = 'real' else: result = 'fake' return render_template('result.html', result=result, text=text) if __name__ == '__main__': app.run(debug=True)
Nous pouvons enregistrer le code ci-dessus dans un fichier nommé « app.py ». Nous devons également créer deux modèles HTML, « home.html » et « result.html », contenant le code HTML de la page d'accueil et de la page de résultats, respectivement.
home.html
<!DOCTYPE html>
<html>
<head> <title>Real or Fake News</title>
</head>
<body> <h1>Real or Fake News</h1> <form action="/fr/predict" method="post"> <label for="text">Enter text:</label><br> <textarea name="text" rows="10" cols="50"></textarea><br> <input type="submit" value="Submit"> </form>
</body>
</html>résultat.html
<!DOCTYPE html>
<html>
<head> <title>Real or Fake News</title>
</head>
<body> <h1>Real or Fake News</h1> <p>The text you entered:</p> <p>{{ text }}</p> <p>The model predicts that this text is:</p> <p>{{ result }}</p>
</body>
</html>
Nous pouvons maintenant exécuter l'application Flask en utilisant la commande python app.py dans la ligne de commande. L'application doit être accessible sur http://localhost:5000.
Page d’Accueil:

Page de prédiction :
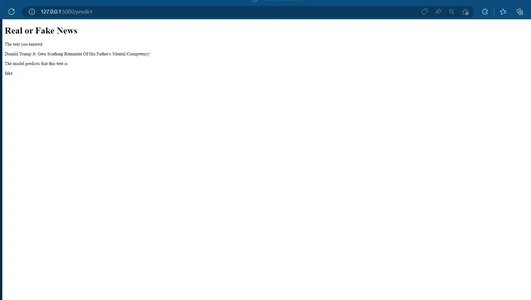
Conclusion
- Le prétraitement est une étape essentielle dans les tâches de traitement des langues naturelles telles que la classification de texte, et des techniques telles que la mise en minuscules, la suppression des mots vides et la radicalisation/lemmatisation peuvent améliorer considérablement les performances des modèles.
- CountVectorizer est un outil puissant pour convertir des données textuelles en une représentation numérique pouvant être utilisée dans des modèles d'apprentissage automatique.
- Le choix d’un algorithme d’apprentissage automatique peut avoir un impact significatif sur les performances d’une tâche de classification de texte. Dans ce projet, nous avons comparé les performances des machines de régression logistique et des machines à vecteurs de support et avons constaté que la régression logistique avait les meilleures performances.
- L'évaluation du modèle est essentielle pour comprendre les performances d'un modèle d'apprentissage automatique et identifier les domaines à améliorer. Dans ce projet, nous avons utilisé des mesures telles que l'exactitude, la précision, le rappel et le score F1 pour évaluer nos modèles.
- Enfin, ce projet démontre le potentiel de l’apprentissage automatique pour la détection automatisée des fausses nouvelles et ses applications potentielles dans l’industrie des médias et au-delà.
Dans cet article de blog, nous avons appris comment former un modèle de régression logistique simple pour classer les articles d'actualité comme réels ou faux et comment déployer le modèle en tant qu'application Web à l'aide du framework Flask. Nous avons utilisé la bibliothèque sklearn pour prétraiter et modéliser les données et créé un formulaire Web simple en utilisant HTML et Flask.
L'ensemble de données que nous avons utilisé pour ce projet était le Ensemble de données d'actualités fausses et réelles de Kaggle, qui contient 23481 21417 vrais articles d’actualité et 99 XNUMX faux articles d’actualité. Nous avons prétraité le texte en supprimant les mots vides, la ponctuation et les chiffres, puis avons utilisé une approche par sac de mots pour représenter chaque article comme un vecteur de fréquences de mots. Nous avons formé un classificateur de régression logistique sur ces données et avons obtenu une précision de plus de XNUMX %.
Dans l'ensemble, ce projet démontre comment l'apprentissage automatique peut être utilisé pour résoudre le problème des fausses nouvelles, qui devient un problème de plus en plus important dans la société actuelle.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/02/tackling-fake-news-with-machine-learning/

