Dans le paysage en évolution de l’industrie manufacturière, le pouvoir transformateur de l’IA et de l’apprentissage automatique (ML) est évident, conduisant à une révolution numérique qui rationalise les opérations et augmente la productivité. Cependant, ces progrès présentent des défis uniques pour les entreprises qui utilisent des solutions basées sur les données. Les installations industrielles sont aux prises avec de vastes volumes de données non structurées, provenant de capteurs, de systèmes de télémétrie et d'équipements dispersés sur les lignes de production. Les données en temps réel sont essentielles pour des applications telles que la maintenance prédictive et la détection d'anomalies, mais le développement de modèles ML personnalisés pour chaque cas d'utilisation industrielle avec de telles données de séries chronologiques demande beaucoup de temps et de ressources de la part des data scientists, ce qui entrave une adoption généralisée.
IA générative en utilisant de grands modèles de base (FM) pré-entraînés tels que Claude peut générer rapidement une variété de contenus allant du texte conversationnel au code informatique sur la base de simples invites textuelles, connues sous le nom de invite de tir zéro. Cela élimine le besoin pour les data scientists de développer manuellement des modèles de ML spécifiques pour chaque cas d'utilisation, et démocratise donc l'accès à l'IA, bénéficiant même aux petits fabricants. Les employés gagnent en productivité grâce aux informations générées par l'IA, les ingénieurs peuvent détecter les anomalies de manière proactive, les responsables de la chaîne d'approvisionnement optimisent les stocks et les dirigeants de l'usine prennent des décisions éclairées et basées sur les données.
Néanmoins, les FM autonomes sont confrontés à des limites dans le traitement de données industrielles complexes avec des contraintes de taille de contexte (généralement moins de 200,000 XNUMX jetons), ce qui pose des défis. Pour résoudre ce problème, vous pouvez utiliser la capacité du FM à générer du code en réponse à des requêtes en langage naturel (NLQ). Les agents aiment PandasIA entrent en jeu, en exécutant ce code sur des données de séries chronologiques haute résolution et en gérant les erreurs à l’aide des FM. PandasAI est une bibliothèque Python qui ajoute des capacités d'IA générative à pandas, l'outil populaire d'analyse et de manipulation de données.
Cependant, les NLQ complexes, tels que le traitement de données de séries chronologiques, l'agrégation multi-niveaux et les opérations de table pivot ou conjointe, peuvent produire une précision de script Python incohérente avec une invite de tir zéro.
Pour améliorer la précision de la génération de code, nous proposons de construire dynamiquement invites multi-shot pour les NLQ. Les invites multi-shots fournissent un contexte supplémentaire au FM en lui montrant plusieurs exemples de sorties souhaitées pour des invites similaires, améliorant ainsi la précision et la cohérence. Dans cet article, les invites multi-shots sont récupérées à partir d'une intégration contenant du code Python exécuté avec succès sur un type de données similaire (par exemple, des données de séries chronologiques haute résolution provenant d'appareils Internet des objets). L'invite multi-shot construite de manière dynamique fournit le contexte le plus pertinent au FM et renforce les capacités du FM en matière de calcul mathématique avancé, de traitement des données de séries chronologiques et de compréhension des acronymes de données. Cette réponse améliorée permet aux employés de l'entreprise et aux équipes opérationnelles d'interagir avec les données et d'en tirer des informations sans nécessiter de compétences approfondies en science des données.
Au-delà de l’analyse des données de séries chronologiques, les FM s’avèrent utiles dans diverses applications industrielles. Les équipes de maintenance évaluent l'état des actifs, capturent des images pour Amazon Reconnaissancedes résumés de fonctionnalités basés sur des fonctionnalités et une analyse des causes profondes des anomalies à l'aide de recherches intelligentes avec Récupération Génération Augmentée (CHIFFON). Pour simplifier ces flux de travail, AWS a introduit Socle amazonien, vous permettant de créer et de faire évoluer des applications d'IA générative avec des FM pré-entraînés de pointe comme Claude v2. Avec Bases de connaissances pour Amazon Bedrock, vous pouvez simplifier le processus de développement de RAG pour fournir une analyse plus précise des causes profondes des anomalies aux employés de l'usine. Notre article présente un assistant intelligent pour les cas d'utilisation industrielle optimisé par Amazon Bedrock, répondant aux défis NLQ, générant des résumés de pièces à partir d'images et améliorant les réponses FM pour le diagnostic des équipements grâce à l'approche RAG.
Vue d'ensemble de la solution
Le diagramme suivant illustre l'architecture de la solution.

Le workflow comprend trois cas d'utilisation distincts :
Cas d'utilisation 1 : NLQ avec des données de séries chronologiques
Le flux de travail pour NLQ avec des données de séries chronologiques comprend les étapes suivantes :
- Nous utilisons un système de surveillance des conditions doté de capacités ML pour la détection des anomalies, telles que AmazonMonitron, pour surveiller la santé des équipements industriels. Amazon Monitron est capable de détecter les pannes potentielles d'équipement à partir des mesures de vibration et de température de l'équipement.
- Nous collectons des données de séries chronologiques en traitant AmazonMonitron données via Flux de données Amazon Kinesis ainsi que Amazon Data Firehose, en le convertissant au format CSV tabulaire et en l'enregistrant dans un Service de stockage simple Amazon (Amazon S3) seau.
- L'utilisateur final peut commencer à discuter avec ses données de séries chronologiques dans Amazon S3 en envoyant une requête en langage naturel à l'application Streamlit.
- L'application Streamlit transmet les requêtes des utilisateurs au Modèle d'intégration de texte Amazon Bedrock Titan pour intégrer cette requête, et effectue une recherche de similarité au sein d'un Service Amazon OpenSearch index, qui contient les NLQ antérieurs et des exemples de codes.
- Après la recherche de similarité, les principaux exemples similaires, notamment les questions NLQ, le schéma de données et les codes Python, sont insérés dans une invite personnalisée.
- PandasAI envoie cette invite personnalisée au modèle Amazon Bedrock Claude v2.
- L'application utilise l'agent PandasAI pour interagir avec le modèle Amazon Bedrock Claude v2, générant du code Python pour l'analyse des données Amazon Monitron et les réponses NLQ.
- Une fois que le modèle Amazon Bedrock Claude v2 a renvoyé le code Python, PandasAI exécute la requête Python sur les données Amazon Monitron téléchargées depuis l'application, collectant les sorties de code et traitant toutes les tentatives nécessaires en cas d'échec d'exécution.
- L'application Streamlit collecte la réponse via PandasAI et fournit le résultat aux utilisateurs. Si le résultat est satisfaisant, l'utilisateur peut le marquer comme utile, en enregistrant le code Python généré par NLQ et Claude dans OpenSearch Service.
Cas d'utilisation 2 : Génération récapitulative des pièces défectueuses
Notre cas d'utilisation de génération de résumé comprend les étapes suivantes :
- Une fois que l'utilisateur sait quel actif industriel présente un comportement anormal, il peut télécharger des images de la pièce défectueuse pour identifier s'il y a un problème physique avec cette pièce en fonction de ses spécifications techniques et de son état de fonctionnement.
- L'utilisateur peut utiliser le API DetectText d'Amazon Recognition pour extraire des données textuelles de ces images.
- Les données textuelles extraites sont incluses dans l'invite du modèle Amazon Bedrock Claude v2, permettant au modèle de générer un résumé de 200 mots de la pièce défectueuse. L'utilisateur peut utiliser ces informations pour effectuer une inspection plus approfondie de la pièce.
Cas d'utilisation 3 : Diagnostic de la cause première
Notre cas d’utilisation du diagnostic des causes profondes comprend les étapes suivantes :
- L'utilisateur obtient des données d'entreprise dans divers formats de documents (PDF, TXT, etc.) liés aux actifs défectueux, et les télécharge dans un compartiment S3.
- Une base de connaissances de ces fichiers est générée dans Amazon Bedrock avec un modèle d'intégration de texte Titan et un magasin de vecteurs OpenSearch Service par défaut.
- L'utilisateur pose des questions liées au diagnostic de la cause profonde d'un équipement défectueux. Les réponses sont générées via la base de connaissances Amazon Bedrock avec une approche RAG.
Pré-requis
Pour suivre cet article, vous devez remplir les conditions préalables suivantes :
Déployer l'infrastructure de la solution
Pour configurer les ressources de votre solution, procédez comme suit :
- Déployez le AWS CloudFormation modèle opensearchsagemaker.yml, qui crée une collection et un index OpenSearch Service, Amazon Sage Maker instance de notebook et compartiment S3. Vous pouvez nommer cette pile AWS CloudFormation comme suit :
genai-sagemaker. - Ouvrez l'instance de notebook SageMaker dans JupyterLab. Vous trouverez ce qui suit GitHub repo déjà téléchargé sur cette instance : libérer-le-potentiel-de-l-IA-générative-dans-les-opérations-industrielles.
- Exécutez le notebook à partir du répertoire suivant dans ce référentiel : débloquer-le-potentiel-de-l'IA-générative-dans-les-opérations-industrielles/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Ce bloc-notes chargera l'index OpenSearch Service à l'aide du bloc-notes SageMaker pour stocker les paires clé-valeur du 23 exemples NLQ existants.
- Télécharger des documents à partir du dossier de données actifpartdoc dans le référentiel GitHub vers le compartiment S3 répertorié dans les sorties de la pile CloudFormation.

Ensuite, vous créez la base de connaissances pour les documents dans Amazon S3.
- Sur la console Amazon Bedrock, choisissez Base de connaissances dans le volet de navigation.
- Selectionnez Créer une base de connaissances.
- Pour Nom de la base de connaissances, entrez un nom.
- Pour Rôle d'exécution, sélectionnez Créer et utiliser un nouveau rôle de service.
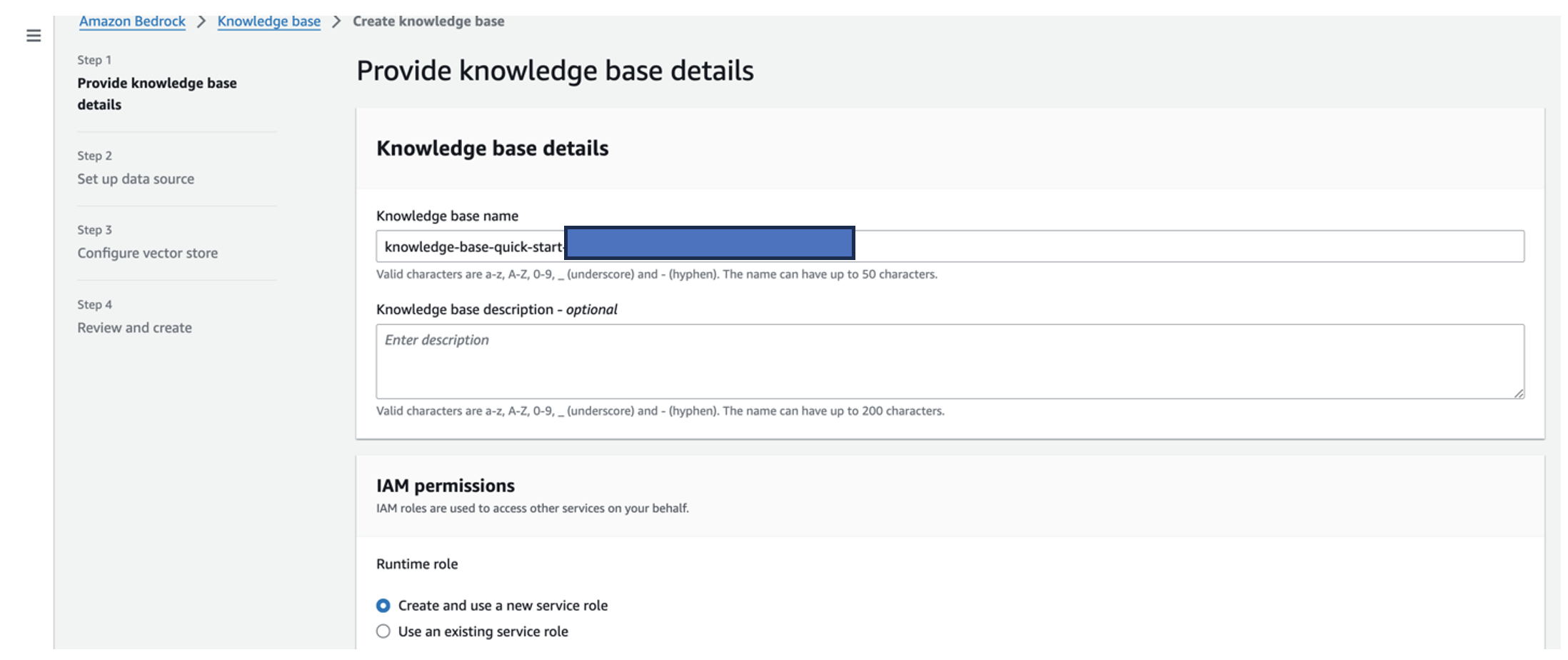
- Pour Nom de la source de données, saisissez le nom de votre source de données.
- Pour URI S3, entrez le chemin S3 du compartiment dans lequel vous avez téléchargé les documents de cause première.
- Selectionnez Suivant.
 Le modèle d'intégration Titan est automatiquement sélectionné.
Le modèle d'intégration Titan est automatiquement sélectionné. - Sélectionnez Créez rapidement un nouveau magasin de vecteurs.
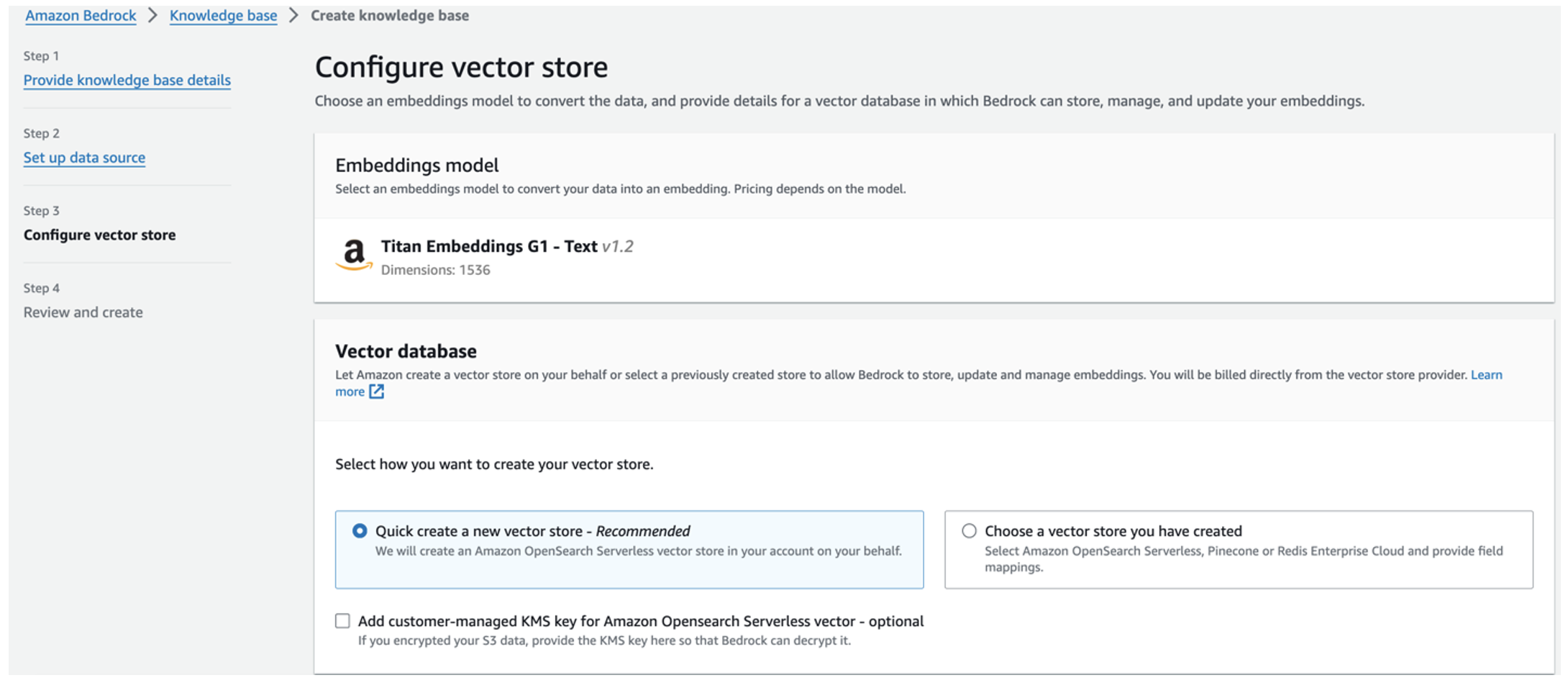
- Vérifiez vos paramètres et créez la base de connaissances en choisissant Créer une base de connaissances.
- Une fois la base de connaissances créée avec succès, choisissez Sync pour synchroniser le compartiment S3 avec la base de connaissances.

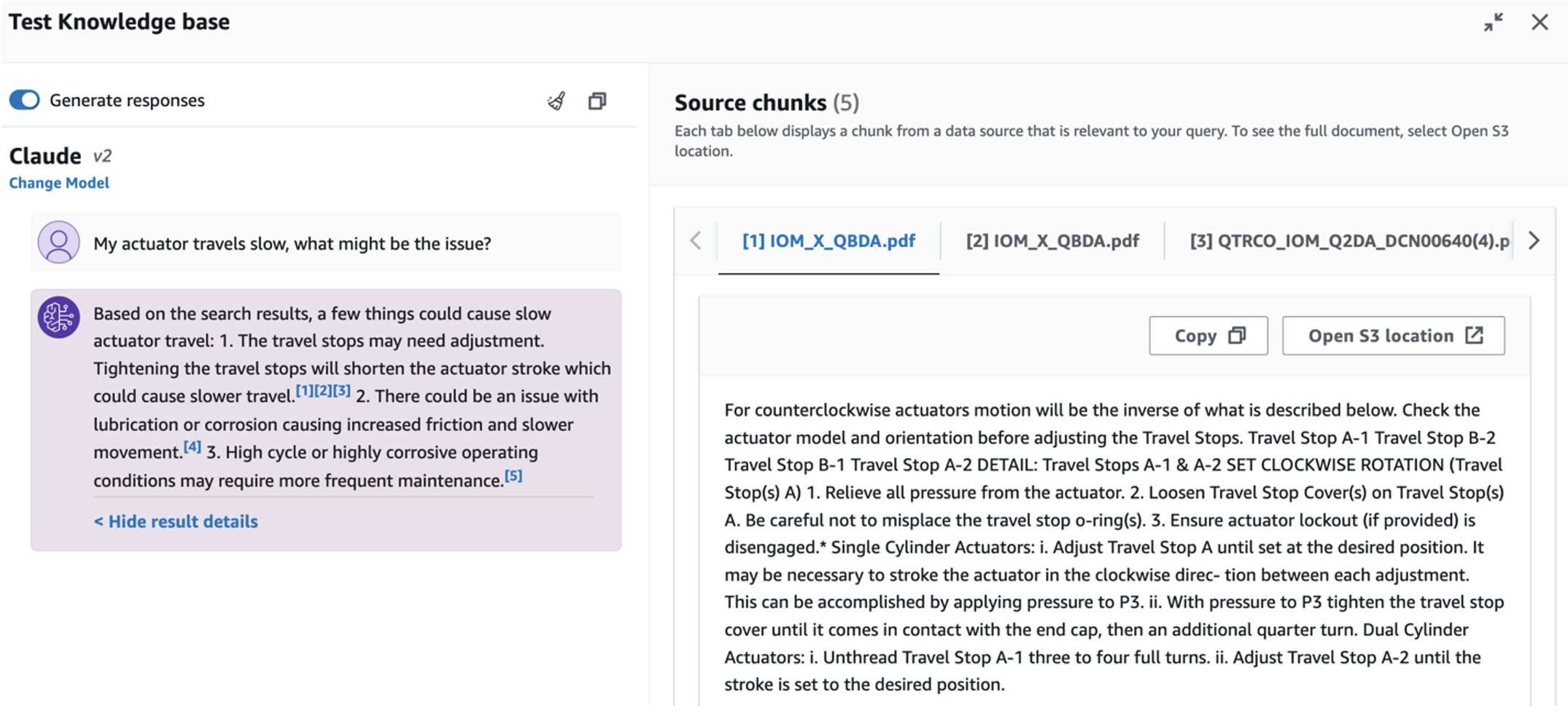
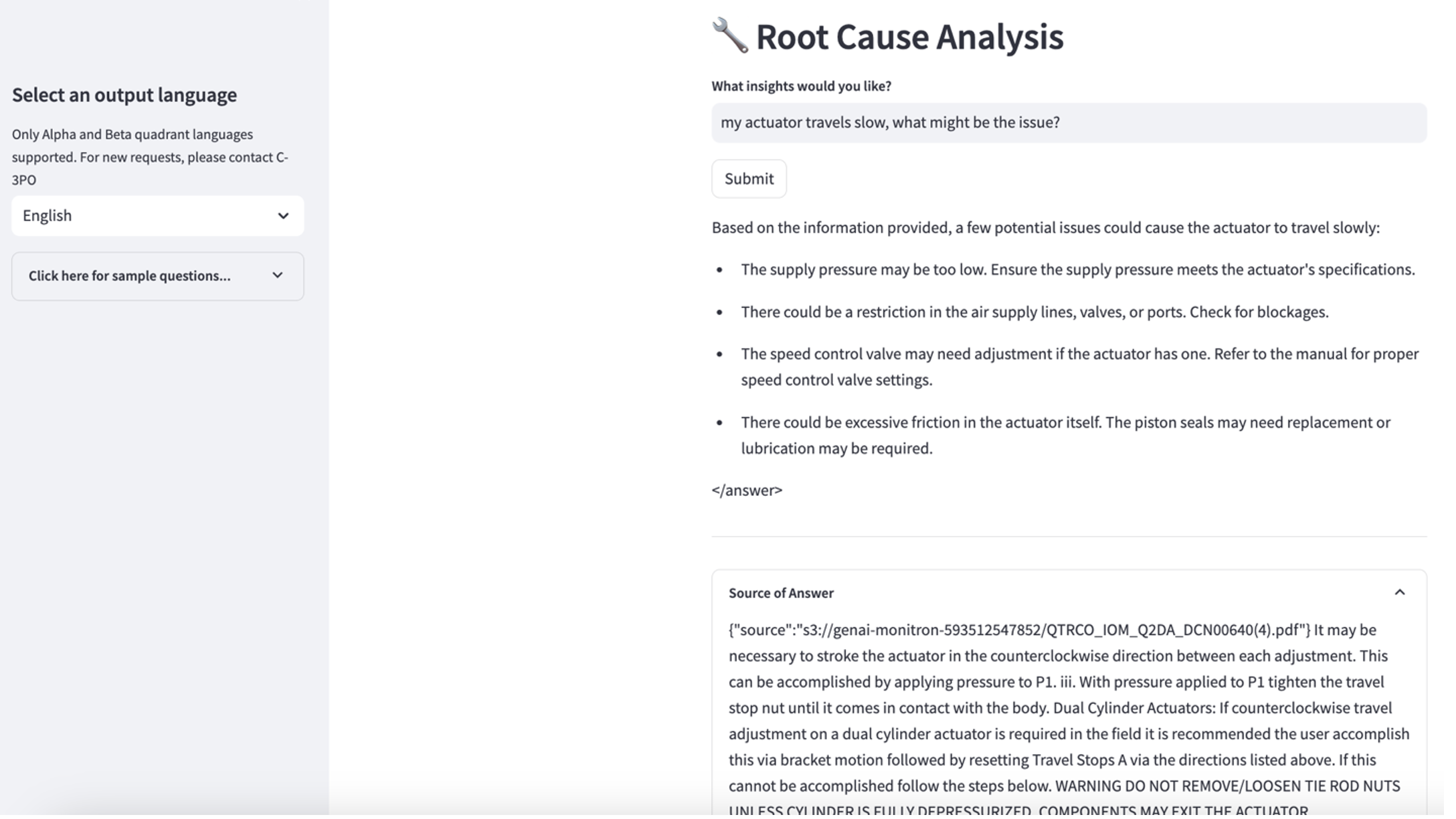
- Après avoir configuré la base de connaissances, vous pouvez tester l'approche RAG pour le diagnostic des causes profondes en posant des questions telles que « Mon actionneur se déplace lentement, quel pourrait être le problème ? »
L'étape suivante consiste à déployer l'application avec les packages de bibliothèque requis sur votre PC ou sur une instance EC2 (Ubuntu Server 22.04 LTS).
- Configurez vos informations d'identification AWS avec l'AWS CLI sur votre PC local. Pour plus de simplicité, vous pouvez utiliser le même rôle d'administrateur que celui que vous avez utilisé pour déployer la pile CloudFormation. Si vous utilisez Amazon EC2, attacher un rôle IAM approprié à l'instance.
- Cloner GitHub repo:
- Changez le répertoire en
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcet exécutez lesetup.shscript dans ce dossier pour installer les packages requis, notamment LangChain et PandasAI :cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Exécutez l'application Streamlit avec la commande suivante :
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Fournissez l'ARN de collection OpenSearch Service que vous avez créé dans Amazon Bedrock à partir de l'étape précédente.
Discutez avec votre assistant de santé des actifs
Une fois le déploiement de bout en bout terminé, vous pouvez accéder à l'application via localhost sur le port 8501, qui ouvre une fenêtre de navigateur avec l'interface Web. Si vous avez déployé l'application sur une instance EC2, autoriser l'accès au port 8501 via la règle entrante du groupe de sécurité. Vous pouvez accéder à différents onglets pour différents cas d'utilisation.
Explorer le cas d'utilisation 1
Pour explorer le premier cas d'utilisation, choisissez Aperçu des données et graphique. Commencez par télécharger vos données de séries chronologiques. Si vous ne disposez pas d'un fichier de données de séries chronologiques à utiliser, vous pouvez télécharger les éléments suivants exemple de fichier CSV avec des données anonymes du projet Amazon Monitron. Si vous disposez déjà d'un projet Amazon Monitron, reportez-vous à Générez des informations exploitables pour la gestion de la maintenance prédictive avec Amazon Monitron et Amazon Kinesis pour diffuser vos données Amazon Monitron sur Amazon S3 et utiliser vos données avec cette application.
Une fois le téléchargement terminé, saisissez une requête pour lancer une conversation avec vos données. La barre latérale gauche propose une gamme d’exemples de questions pour votre commodité. Les captures d'écran suivantes illustrent la réponse et le code Python générés par le FM lors de la saisie d'une question telle que « Dites-moi le nombre unique de capteurs pour chaque site affiché respectivement comme Avertissement ou Alarme ? » (une question difficile) ou "Pour les capteurs affichant un signal de température comme NON sain, pouvez-vous calculer la durée en jours pour chaque capteur affichant un signal de vibration anormal ?" (une question de niveau défi). L'application répondra à votre question et affichera également le script Python d'analyse des données qu'elle a effectué pour générer de tels résultats.


Si vous êtes satisfait de la réponse, vous pouvez la marquer comme Utile, en enregistrant le code Python généré par NLQ et Claude dans un index OpenSearch Service.

Explorer le cas d'utilisation 2
Pour explorer le deuxième cas d'utilisation, choisissez le Résumé de l'image capturée dans l'application Streamlit. Vous pouvez télécharger une image de votre actif industriel et l'application générera un résumé de 200 mots de ses spécifications techniques et de son état de fonctionnement sur la base des informations de l'image. La capture d'écran suivante montre le résumé généré à partir d'une image d'un entraînement par moteur à courroie. Pour tester cette fonctionnalité, s'il vous manque une image adaptée, vous pouvez utiliser ce qui suit exemple d'image.
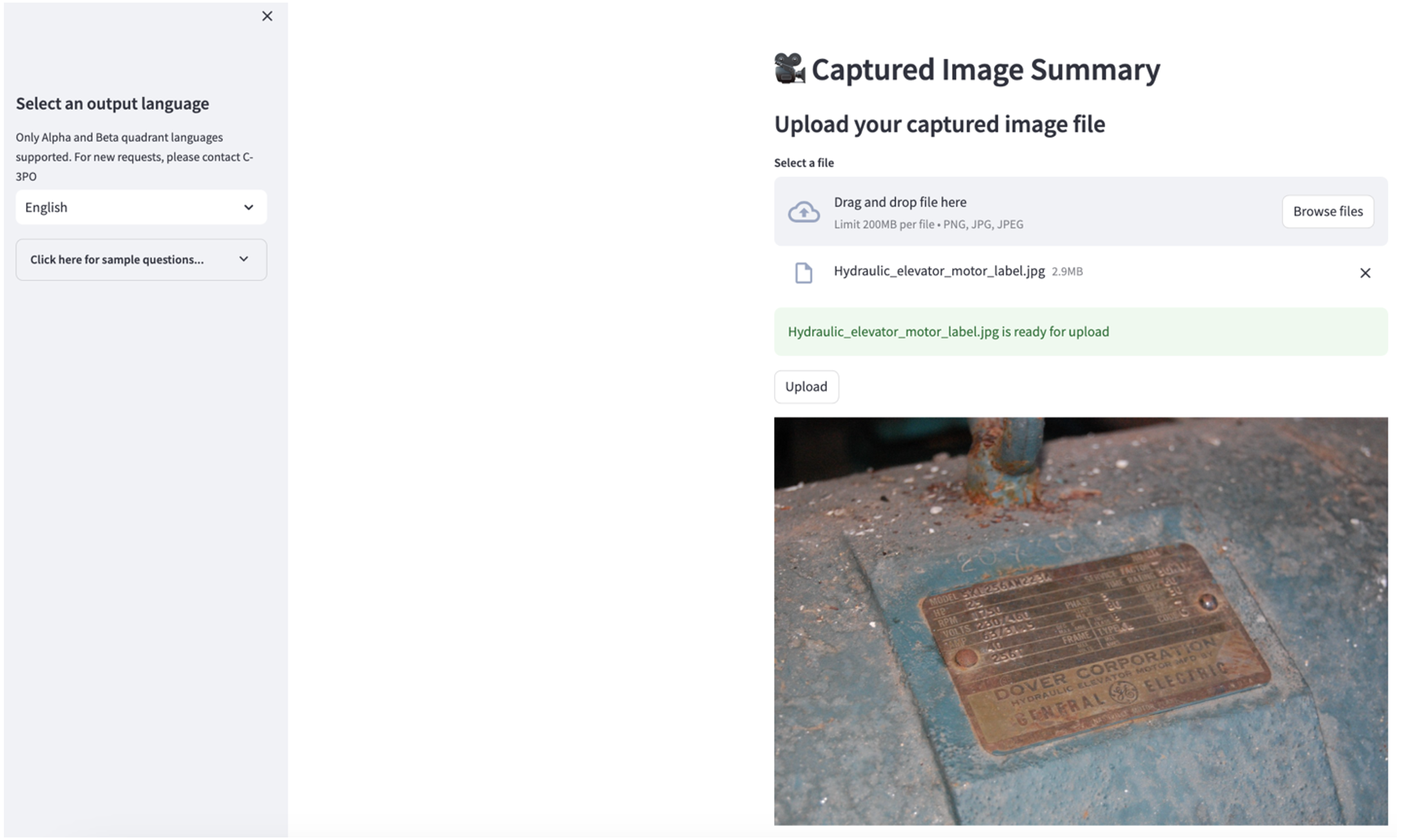
Étiquette de moteur d'ascenseur hydraulique» de Clarence Risher est sous licence CC BY-SA 2.0.

Explorer le cas d'utilisation 3
Pour explorer le troisième cas d'utilisation, choisissez le Diagnostic des causes profondes languette. Saisissez une requête relative à votre actif industriel en panne, telle que « Mon actionneur se déplace lentement, quel pourrait être le problème ? » Comme le montre la capture d'écran suivante, l'application fournit une réponse avec l'extrait du document source utilisé pour générer la réponse.
Cas d'utilisation 1 : détails de conception
Dans cette section, nous discutons des détails de conception du flux de travail de l'application pour le premier cas d'utilisation.
Création d'invites personnalisées
La requête en langage naturel de l'utilisateur comporte différents niveaux de difficulté : facile, difficile et défi.
Les questions simples peuvent inclure les demandes suivantes :
- Sélectionnez des valeurs uniques
- Compter le nombre total
- Trier les valeurs
Pour ces questions, PandasAI peut interagir directement avec le FM pour générer des scripts Python à traiter.
Les questions difficiles nécessitent une opération d’agrégation de base ou une analyse de séries chronologiques, telles que les suivantes :
- Sélectionnez d'abord la valeur et regroupez les résultats de manière hiérarchique
- Effectuer des statistiques après la sélection initiale des enregistrements
- Nombre d'horodatages (par exemple, min et max)
Pour les questions difficiles, un modèle d'invite avec des instructions détaillées étape par étape aide les FM à fournir des réponses précises.
Les questions de niveau défi nécessitent un calcul mathématique avancé et un traitement de séries chronologiques, tels que les suivants :
- Calculer la durée de l'anomalie pour chaque capteur
- Calculer les capteurs d'anomalies pour le site sur une base mensuelle
- Comparez les lectures du capteur dans des conditions de fonctionnement normales et anormales
Pour ces questions, vous pouvez utiliser plusieurs prises de vue dans une invite personnalisée pour améliorer la précision des réponses. De tels plans multiples montrent des exemples de traitement avancé de séries chronologiques et de calculs mathématiques, et fourniront au FM un contexte permettant d'effectuer des inférences pertinentes sur une analyse similaire. L'insertion dynamique des exemples les plus pertinents d'une banque de questions NLQ dans l'invite peut s'avérer un défi. Une solution consiste à créer des intégrations à partir d'échantillons de questions NLQ existants et à enregistrer ces intégrations dans un magasin de vecteurs comme OpenSearch Service. Lorsqu'une question est envoyée à l'application Streamlit, la question sera vectorisée par Substrat rocheuxIncrustations. Les N intégrations les plus pertinentes pour cette question sont récupérées à l'aide de opensearch_vector_search.similarity_search et inséré dans le modèle d'invite en tant qu'invite multi-shot.
Le diagramme suivant illustre ce flux de travail.
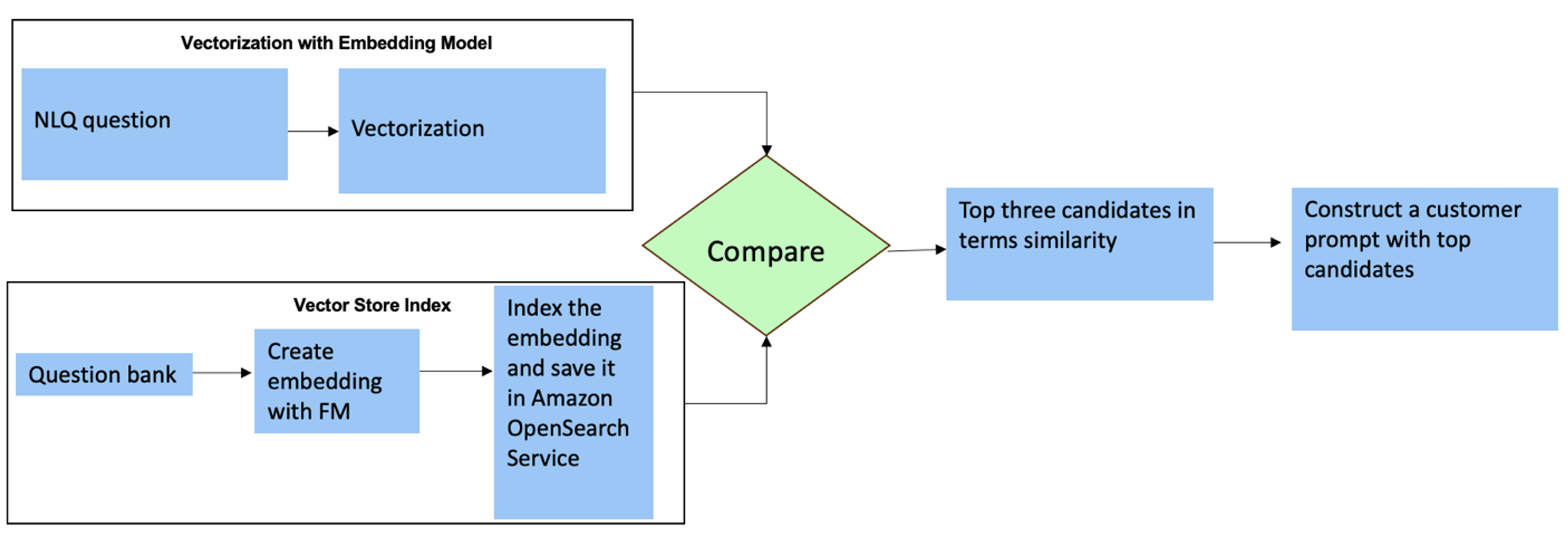
La couche d'intégration est construite à l'aide de trois outils clés :
- Modèle d'intégration – Nous utilisons Amazon Titan Embeddings disponibles via Amazon Bedrock (amazon.titan-embed-text-v1) pour générer des représentations numériques de documents textuels.
- Magasin de vecteurs – Pour notre magasin de vecteurs, nous utilisons OpenSearch Service via le framework LangChain, rationalisant le stockage des intégrations générées à partir des exemples NLQ dans ce notebook.
- Sommaire – L'index OpenSearch Service joue un rôle central dans la comparaison des intégrations d'entrées avec les intégrations de documents et dans la facilitation de la récupération des documents pertinents. Étant donné que les exemples de codes Python ont été enregistrés sous forme de fichier JSON, ils ont été indexés dans OpenSearch Service en tant que vecteurs via un OpenSearchVevtorSearch.fromtexts Appel API.
Collection continue d'exemples audités par des humains via Streamlit
Au début du développement de l'application, nous avons commencé avec seulement 23 exemples enregistrés dans l'index OpenSearch Service sous forme d'intégrations. Au fur et à mesure que l'application est mise en ligne sur le terrain, les utilisateurs commencent à saisir leurs NLQ via l'application. Cependant, en raison du nombre limité d'exemples disponibles dans le modèle, certains NLQ peuvent ne pas trouver d'invites similaires. Pour enrichir continuellement ces intégrations et proposer des invites utilisateur plus pertinentes, vous pouvez utiliser l'application Streamlit pour collecter des exemples audités par des humains.
Dans l'application, la fonction suivante sert à cet effet. Lorsque les utilisateurs finaux trouvent le résultat utile et sélectionnent Utile, l'application suit ces étapes :
- Utilisez la méthode de rappel de PandasAI pour collecter le script Python.
- Reformatez le script Python, la question de saisie et les métadonnées CSV en une chaîne.
- Vérifiez si cet exemple NLQ existe déjà dans l'index OpenSearch Service actuel en utilisant opensearch_vector_search.similarity_search_with_score.
- S'il n'existe pas d'exemple similaire, ce NLQ est ajouté à l'index OpenSearch Service en utilisant opensearch_vector_search.add_texts.
Dans le cas où un utilisateur sélectionne Inutile, aucune mesure n'est prise. Ce processus itératif garantit que le système s'améliore continuellement en incorporant des exemples fournis par les utilisateurs.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
En intégrant l'audit humain, la quantité d'exemples dans OpenSearch Service disponibles pour une intégration rapide augmente à mesure que l'application gagne en utilisation. Cet ensemble de données d'intégration élargi se traduit par une précision de recherche améliorée au fil du temps. Plus précisément, pour les NLQ difficiles, la précision des réponses du FM atteint environ 90 % lors de l'insertion dynamique d'exemples similaires pour créer des invites personnalisées pour chaque question NLQ. Cela représente une augmentation notable de 28 % par rapport aux scénarios sans invites à plusieurs prises de vue.
Cas d'utilisation 2 : détails de conception
Sur l'application Streamlit Résumé de l'image capturée onglet, vous pouvez directement télécharger un fichier image. Cela lance l'API Amazon Rekognition (détecter_text API), extrayant le texte de l'étiquette d'image détaillant les spécifications de la machine. Par la suite, les données textuelles extraites sont envoyées au modèle Amazon Bedrock Claude comme contexte d'invite, ce qui donne lieu à un résumé de 200 mots.
Du point de vue de l'expérience utilisateur, il est primordial d'activer la fonctionnalité de streaming pour une tâche de résumé de texte, car elle permet aux utilisateurs de lire le résumé généré par FM en petits morceaux plutôt que d'attendre la totalité du résultat. Amazon Bedrock facilite le streaming via son API (bedrock_runtime.invoke_model_with_response_stream).
Cas d'utilisation 3 : détails de conception
Dans ce scénario, nous avons développé une application de chatbot axée sur l'analyse des causes profondes, en utilisant l'approche RAG. Ce chatbot s'appuie sur plusieurs documents liés aux équipements de roulements pour faciliter l'analyse des causes profondes. Ce chatbot d'analyse des causes profondes basé sur RAG utilise des bases de connaissances pour générer des représentations textuelles vectorielles, ou intégrations. Les bases de connaissances pour Amazon Bedrock sont une fonctionnalité entièrement gérée qui vous aide à mettre en œuvre l'intégralité du flux de travail RAG, de l'ingestion à la récupération et à l'augmentation rapide, sans avoir à créer des intégrations personnalisées aux sources de données ou à gérer les flux de données et les détails de mise en œuvre de RAG.
Lorsque vous êtes satisfait de la réponse de la base de connaissances d'Amazon Bedrock, vous pouvez intégrer la réponse à la cause première de la base de connaissances à l'application Streamlit.
Nettoyer
Pour réduire les coûts, supprimez les ressources que vous avez créées dans cet article :
- Supprimez la base de connaissances d'Amazon Bedrock.
- Supprimez l’index du service OpenSearch.
- Supprimez la pile genai-sagemaker CloudFormation.
- Arrêtez l'instance EC2 si vous avez utilisé une instance EC2 pour exécuter l'application Streamlit.
Conclusion
Les applications d’IA générative ont déjà transformé divers processus métier, améliorant ainsi la productivité et les compétences des travailleurs. Cependant, les limites des FM dans le traitement de l’analyse des données de séries chronologiques ont entravé leur pleine utilisation par les clients industriels. Cette contrainte a entravé l’application de l’IA générative au type de données prédominant traité quotidiennement.
Dans cet article, nous avons présenté une solution d'application d'IA générative conçue pour atténuer ce défi pour les utilisateurs industriels. Cette application utilise un agent open source, PandasAI, pour renforcer la capacité d'analyse de séries chronologiques d'un FM. Plutôt que d'envoyer des données de séries chronologiques directement aux FM, l'application utilise PandasAI pour générer du code Python pour l'analyse des données de séries chronologiques non structurées. Pour améliorer la précision de la génération de code Python, un flux de travail de génération d'invites personnalisé avec audit humain a été mis en œuvre.
Grâce à des informations sur l'état de leurs actifs, les travailleurs industriels peuvent exploiter pleinement le potentiel de l'IA générative dans divers cas d'utilisation, notamment le diagnostic des causes profondes et la planification du remplacement des pièces. Avec les bases de connaissances pour Amazon Bedrock, la solution RAG est simple à créer et à gérer pour les développeurs.
La trajectoire de la gestion des données et des opérations d’entreprise évolue indéniablement vers une intégration plus profonde avec l’IA générative pour des informations complètes sur la santé opérationnelle. Ce changement, mené par Amazon Bedrock, est considérablement amplifié par la robustesse et le potentiel croissants des LLM comme Fond rocheux amazonien Claude 3 pour élever davantage les solutions. Pour en savoir plus, visitez consulter le Documentation sur le substrat rocheux d'Amazon, et mettez la main à la pâte avec le Atelier sur le substrat rocheux amazonien.
À propos des auteurs
 Julia Hu est architecte principal de solutions IA/ML chez Amazon Web Services. Elle est spécialisée en IA générative, en science des données appliquée et en architecture IoT. Actuellement, elle fait partie de l'équipe Amazon Q et est membre/mentor actif de la communauté technique de terrain d'apprentissage automatique. Elle travaille avec des clients, allant des start-ups aux entreprises, pour développer AWSome, des solutions d'IA générative. Elle est particulièrement passionnée par l’exploitation des grands modèles linguistiques pour l’analyse avancée des données et par l’exploration d’applications pratiques qui répondent aux défis du monde réel.
Julia Hu est architecte principal de solutions IA/ML chez Amazon Web Services. Elle est spécialisée en IA générative, en science des données appliquée et en architecture IoT. Actuellement, elle fait partie de l'équipe Amazon Q et est membre/mentor actif de la communauté technique de terrain d'apprentissage automatique. Elle travaille avec des clients, allant des start-ups aux entreprises, pour développer AWSome, des solutions d'IA générative. Elle est particulièrement passionnée par l’exploitation des grands modèles linguistiques pour l’analyse avancée des données et par l’exploration d’applications pratiques qui répondent aux défis du monde réel.
 Sudeesh Sasidharan est architecte de solutions senior chez AWS, au sein de l'équipe Energy. Sudeesh aime expérimenter de nouvelles technologies et créer des solutions innovantes qui résolvent des défis commerciaux complexes. Lorsqu'il n'est pas en train de concevoir des solutions ou de bricoler les dernières technologies, vous pouvez le trouver sur le court de tennis en train de travailler son revers.
Sudeesh Sasidharan est architecte de solutions senior chez AWS, au sein de l'équipe Energy. Sudeesh aime expérimenter de nouvelles technologies et créer des solutions innovantes qui résolvent des défis commerciaux complexes. Lorsqu'il n'est pas en train de concevoir des solutions ou de bricoler les dernières technologies, vous pouvez le trouver sur le court de tennis en train de travailler son revers.
 Neil Desaï est un responsable technologique avec plus de 20 ans d'expérience dans l'intelligence artificielle (IA), la science des données, le génie logiciel et l'architecture d'entreprise. Chez AWS, il dirige une équipe d'architectes de solutions spécialisés dans les services d'IA mondiaux qui aident les clients à créer des solutions innovantes basées sur l'IA générative, à partager les meilleures pratiques avec les clients et à élaborer une feuille de route des produits. Dans ses fonctions précédentes chez Vestas, Honeywell et Quest Diagnostics, Neil a occupé des postes de direction dans le développement et le lancement de produits et services innovants qui ont aidé les entreprises à améliorer leurs opérations, à réduire leurs coûts et à augmenter leurs revenus. Il est passionné par l’utilisation de la technologie pour résoudre des problèmes du monde réel et est un penseur stratégique qui a fait ses preuves.
Neil Desaï est un responsable technologique avec plus de 20 ans d'expérience dans l'intelligence artificielle (IA), la science des données, le génie logiciel et l'architecture d'entreprise. Chez AWS, il dirige une équipe d'architectes de solutions spécialisés dans les services d'IA mondiaux qui aident les clients à créer des solutions innovantes basées sur l'IA générative, à partager les meilleures pratiques avec les clients et à élaborer une feuille de route des produits. Dans ses fonctions précédentes chez Vestas, Honeywell et Quest Diagnostics, Neil a occupé des postes de direction dans le développement et le lancement de produits et services innovants qui ont aidé les entreprises à améliorer leurs opérations, à réduire leurs coûts et à augmenter leurs revenus. Il est passionné par l’utilisation de la technologie pour résoudre des problèmes du monde réel et est un penseur stratégique qui a fait ses preuves.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

