At AWS re: Invent 2023, nous avons annoncé la disponibilité générale de Bases de connaissances pour Amazon Bedrock. Avec les bases de connaissances pour Amazon Bedrock, vous pouvez connecter en toute sécurité des modèles de fondation (FM) dans Socle amazonien aux données de votre entreprise à l'aide d'un modèle de génération augmentée de récupération (RAG) entièrement géré.
Pour les applications basées sur RAG, la précision des réponses générées par les FM dépend du contexte fourni au modèle. Les contextes sont récupérés à partir des magasins de vecteurs sur la base des requêtes des utilisateurs. Dans la fonctionnalité récemment publiée pour les bases de connaissances pour Amazon Bedrock, recherche hybride, vous pouvez combiner la recherche sémantique avec la recherche par mots clés. Cependant, dans de nombreuses situations, vous devrez peut-être récupérer des documents créés au cours d'une période définie ou étiquetés avec certaines catégories. Pour affiner les résultats de recherche, vous pouvez filtrer en fonction des métadonnées du document afin d'améliorer la précision de la récupération, ce qui conduit à des générations FM plus pertinentes et adaptées à vos intérêts.
Dans cet article, nous discutons de la nouvelle fonctionnalité de filtrage des métadonnées personnalisées dans les bases de connaissances pour Amazon Bedrock, que vous pouvez utiliser pour améliorer les résultats de recherche en pré-filtrant vos récupérations à partir des magasins de vecteurs.
Présentation du filtrage des métadonnées
Avant la publication du filtrage des métadonnées, tous les morceaux sémantiquement pertinents jusqu'au maximum prédéfini seraient renvoyés comme contexte que le FM pourrait utiliser pour générer une réponse. Désormais, grâce aux filtres de métadonnées, vous pouvez récupérer non seulement des fragments sémantiquement pertinents, mais également un sous-ensemble bien défini de ces fragments pertinents en fonction des filtres de métadonnées appliqués et des valeurs associées.
Grâce à cette fonctionnalité, vous pouvez désormais fournir un fichier de métadonnées personnalisé (jusqu'à 10 Ko chacun) pour chaque document de la base de connaissances. Vous pouvez appliquer des filtres à vos récupérations, en demandant au magasin de vecteurs de pré-filtrer en fonction des métadonnées du document, puis de rechercher les documents pertinents. De cette façon, vous contrôlez les documents récupérés, surtout si vos requêtes sont ambiguës. Par exemple, vous pouvez utiliser des documents juridiques contenant des termes similaires pour différents contextes, ou des films dont l'intrigue est similaire et sortis au cours d'années différentes. De plus, en réduisant le nombre de fragments recherchés, vous obtenez des avantages en termes de performances, tels qu'une réduction des cycles de processeur et du coût d'interrogation du magasin de vecteurs, en plus d'une amélioration de la précision.

Pour utiliser la fonctionnalité de filtrage des métadonnées, vous devez fournir des fichiers de métadonnées à côté des fichiers de données source portant le même nom que le fichier de données source et .metadata.json suffixe. Les métadonnées peuvent être une chaîne, un nombre ou un booléen. Voici un exemple du contenu du fichier de métadonnées :
La fonctionnalité de filtrage des métadonnées des bases de connaissances pour Amazon Bedrock est disponible dans les régions AWS USA Est (Virginie du Nord) et USA Ouest (Oregon).
Voici les cas d'utilisation courants du filtrage des métadonnées :
- Chatbot de documents pour un éditeur de logiciels – Cela permet aux utilisateurs de trouver des informations sur le produit et des guides de dépannage. Des filtres sur le système d'exploitation ou la version de l'application, par exemple, peuvent permettre d'éviter de récupérer des documents obsolètes ou non pertinents.
- Recherche conversationnelle de candidature d'une organisation – Cela permet aux utilisateurs de rechercher dans des documents, des kanbans, des transcriptions d'enregistrement de réunions et d'autres actifs. En utilisant des filtres de métadonnées sur les groupes de travail, les unités commerciales ou les ID de projet, vous pouvez personnaliser l'expérience de chat et améliorer la collaboration. Un exemple serait « Quel est l'état du projet Sphinx et les risques soulevés », où les utilisateurs peuvent filtrer les documents pour un projet ou un type de source spécifique (tel qu'un courrier électronique ou des documents de réunion).
- Recherche intelligente de développeurs de logiciels – Cela permet aux développeurs de rechercher des informations sur une version spécifique. Les filtres sur la version, le type de document (tel que le code, la référence API ou le problème) peuvent aider à identifier les documents pertinents.
Vue d'ensemble de la solution
Dans les sections suivantes, nous montrons comment préparer un ensemble de données à utiliser comme base de connaissances, puis interroger avec le filtrage des métadonnées. Vous pouvez interroger en utilisant soit le Console de gestion AWS ou SDK.
Préparer un ensemble de données pour les bases de connaissances pour Amazon Bedrock
Pour cet article, nous utilisons un exemple de jeu de données sur les jeux vidéo fictifs pour illustrer comment ingérer et récupérer des métadonnées à l'aide des bases de connaissances pour Amazon Bedrock. Si vous souhaitez suivre votre propre compte AWS, téléchargez le fichier.
Si vous souhaitez ajouter des métadonnées à vos documents dans une base de connaissances existante, créez les fichiers de métadonnées avec le nom de fichier et le schéma attendus, puis passez à l'étape de synchronisation de vos données avec la base de connaissances pour démarrer l'ingestion incrémentielle.
Dans notre exemple d'ensemble de données, le document de chaque jeu est un fichier CSV distinct (par exemple, s3://$bucket_name/video_game/$game_id.csv) avec les colonnes suivantes :
title, description, genres, year, publisher, score
Les métadonnées de chaque jeu portent le suffixe .metadata.json (par exemple, s3://$bucket_name/video_game/$game_id.csv.metadata.json) avec le schéma suivant :
Créer une base de connaissances pour Amazon Bedrock
Pour obtenir des instructions sur la création d'une nouvelle base de connaissances, voir Créer une base de connaissances. Pour cet exemple, nous utilisons les paramètres suivants :
- Sur le Configurer la source de données page, sous Stratégie de regroupement, sélectionnez Pas de découpage, car vous avez déjà prétraité les documents à l'étape précédente.
- Dans le Modèle d'intégration section, choisissez Intégrations Titan G1 – Texte.
- Dans le Base de données vectorielle section, choisissez Créez rapidement un nouveau magasin de vecteurs. La fonctionnalité de filtrage des métadonnées est disponible pour tous les magasins de vecteurs pris en charge.
Synchronisez l'ensemble de données avec la base de connaissances
Une fois que vous avez créé la base de connaissances et que vos fichiers de données et de métadonnées se trouvent dans un Service de stockage simple Amazon (Amazon S3), vous pouvez démarrer l'ingestion incrémentielle. Pour les instructions, voir Synchronisez pour ingérer vos sources de données dans la base de connaissances.
Requête avec filtrage des métadonnées sur la console Amazon Bedrock
Pour utiliser les options de filtrage des métadonnées sur la console Amazon Bedrock, procédez comme suit :
- Sur la console Amazon Bedrock, choisissez Bases de connaissances dans le volet de navigation.
- Choisissez la base de connaissances que vous avez créée.
- Selectionnez Tester la base de connaissances.
- Choisissez le Configurations icône, puis développez Filtre(s).
- Saisissez une condition au format : clé = valeur (par exemple, genres = Stratégie) et appuyez sur Entrer.
- Pour modifier la clé, la valeur ou l'opérateur, choisissez la condition.
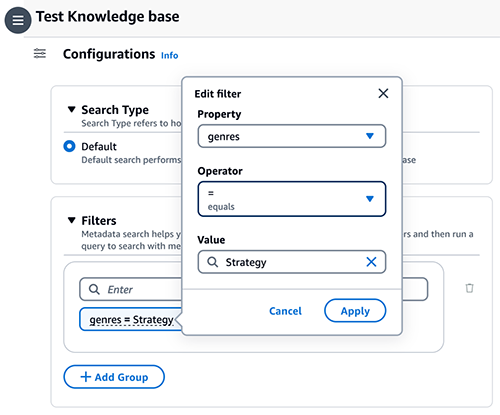
- Continuez avec les conditions restantes (par exemple, (genres = Stratégie ET année >= 2023) OU (note >= 9))

- Une fois terminé, saisissez votre requête dans la zone de message, puis choisissez Courir.
Pour cet article, nous saisissons la requête « Un jeu de stratégie avec des graphismes sympas sorti après 2023 ».
Requête avec filtrage des métadonnées à l'aide du SDK
Pour utiliser le SDK, créez d'abord le client pour le Agents pour le substrat rocheux d’Amazonie Durée:
Construisez ensuite le filtre (voici quelques exemples) :
Passez le filtre à retrievalConfiguration des API de récupération or Récupérer et générer API:
Le tableau suivant répertorie quelques réponses avec différentes conditions de filtrage des métadonnées.
| Question | Filtrage des métadonnées | Documents récupérés | Observations |
| "Un jeu de stratégie avec des graphismes sympas sorti après 2023" | de |
* Viking Saga : The Sea Raider, année : 2023, genres : Stratégie * Château Médiéval : Siège et Conquête, année :2022, genres : Stratégie * Révolution Cybernétique : L'Ascension des Machines, année :2022, genres : Stratégie |
2/5 jeux remplissent la condition (genres = Stratégie et année >= 2023) |
| On | * Viking Saga : The Sea Raider, année : 2023, genres : Stratégie * Fantasy Kingdoms : Chronicles of Eldoria, année : 2023, genres : Stratégie |
2/2 jeux remplissent la condition (genres = Stratégie et année >= 2023) |
En plus des métadonnées personnalisées, vous pouvez également filtrer à l'aide des préfixes S3 (qui sont des métadonnées intégrées, vous n'avez donc pas besoin de fournir de fichiers de métadonnées). Par exemple, si vous organisez les documents du jeu en préfixes par éditeur (par exemple, s3://$bucket_name/video_game/$publisher/$game_id.csv), vous pouvez filtrer en fonction de l'éditeur spécifique (par exemple, neo_tokyo_games) en utilisant la syntaxe suivante :
Nettoyer
Pour nettoyer vos ressources, procédez comme suit:
- Supprimez la base de connaissances :
- Sur la console Amazon Bedrock, choisissez Bases de connaissances sous Orchestration dans le volet de navigation.
- Choisissez la base de connaissances que vous avez créée.
- Prenez note de la Gestion des identités et des accès AWS (IAM) nom du rôle de service dans le Aperçu de la base de connaissances .
- Dans le Base de données vectorielle section, prenez note de l’ARN de la collection.
- Selectionnez Supprimer, puis saisissez Supprimer pour confirmer.
- Supprimez la base de données vectorielles :
- Sur le Service Amazon OpenSearch console, choisissez Collections sous Sans serveur dans le volet de navigation.
- Entrez l'ARN de collection que vous avez enregistré dans la barre de recherche.
- Sélectionnez la collection et choisissez Supprimer.
- Entrez confirmer dans l'invite de confirmation, puis choisissez Supprimer.
- Supprimez le rôle de service IAM :
- Sur la console IAM, choisissez Rôles dans le volet de navigation.
- Recherchez le nom de rôle que vous avez noté plus tôt.
- Sélectionnez le rôle et choisissez Supprimer.
- Entrez le nom du rôle dans l'invite de confirmation et supprimez le rôle.
- Supprimez l'exemple d'ensemble de données :
- Sur la console Amazon S3, accédez au compartiment S3 que vous avez utilisé.
- Sélectionnez le préfixe et les fichiers, puis choisissez Supprimer.
- Entrez définitivement supprimer dans l’invite de confirmation pour supprimer.
Conclusion
Dans cet article, nous avons couvert la fonctionnalité de filtrage des métadonnées dans les bases de connaissances pour Amazon Bedrock. Vous avez appris à ajouter des métadonnées personnalisées aux documents et à les utiliser comme filtres lors de la récupération et de l'interrogation des documents à l'aide de la console Amazon Bedrock et du SDK. Cela contribue à améliorer la précision du contexte, rendant les réponses aux requêtes encore plus pertinentes tout en réduisant le coût d'interrogation de la base de données vectorielles.
Pour des ressources supplémentaires, reportez-vous à ce qui suit :
À propos des auteurs
 Corvus Lee est un architecte de solutions senior de GenAI Labs basé à Londres. Il est passionné par la conception et le développement de prototypes utilisant l'IA générative pour résoudre les problèmes des clients. Il se tient également au courant des derniers développements en matière d’IA générative et de techniques de récupération en les appliquant à des scénarios du monde réel.
Corvus Lee est un architecte de solutions senior de GenAI Labs basé à Londres. Il est passionné par la conception et le développement de prototypes utilisant l'IA générative pour résoudre les problèmes des clients. Il se tient également au courant des derniers développements en matière d’IA générative et de techniques de récupération en les appliquant à des scénarios du monde réel.
 Ahmed Ewis est architecte de solutions senior chez AWS GenAI Labs, aidant les clients à créer des prototypes d'IA générative pour résoudre des problèmes commerciaux. Lorsqu'il ne collabore pas avec les clients, il aime jouer avec ses enfants et cuisiner.
Ahmed Ewis est architecte de solutions senior chez AWS GenAI Labs, aidant les clients à créer des prototypes d'IA générative pour résoudre des problèmes commerciaux. Lorsqu'il ne collabore pas avec les clients, il aime jouer avec ses enfants et cuisiner.
 Chris Pecora est un data scientist IA générative chez Amazon Web Services. Il est passionné par la création de produits et de solutions innovants tout en se concentrant également sur la science obsédée par le client. Lorsqu'il ne mène pas d'expériences et ne se tient pas au courant des derniers développements de GenAI, il adore passer du temps avec ses enfants.
Chris Pecora est un data scientist IA générative chez Amazon Web Services. Il est passionné par la création de produits et de solutions innovants tout en se concentrant également sur la science obsédée par le client. Lorsqu'il ne mène pas d'expériences et ne se tient pas au courant des derniers développements de GenAI, il adore passer du temps avec ses enfants.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

