Image par auteur
Il existe de nombreux cours et ressources disponibles sur l’apprentissage automatique et la science des données, mais très peu sur l’ingénierie des données. Cela soulève quelques questions. Est-ce un domaine difficile ? Offre-t-il des salaires bas ? N'est-il pas considéré comme aussi passionnant que d'autres rôles technologiques ? Cependant, la réalité est que de nombreuses entreprises recherchent activement des talents en ingénierie de données et proposent des salaires substantiels, dépassant parfois 200,000 XNUMX $ US. Les ingénieurs de données jouent un rôle crucial en tant qu'architectes des plates-formes de données, en concevant et en construisant les systèmes fondamentaux qui permettent aux scientifiques des données et aux experts en apprentissage automatique de fonctionner efficacement.
Pour combler cette lacune du secteur, DataTalkClub a introduit un bootcamp transformateur et gratuit, « Zoomcamp sur l'ingénierie des données« . Ce cours est conçu pour donner aux débutants ou aux professionnels souhaitant changer de carrière des compétences essentielles et une expérience pratique en ingénierie des données.
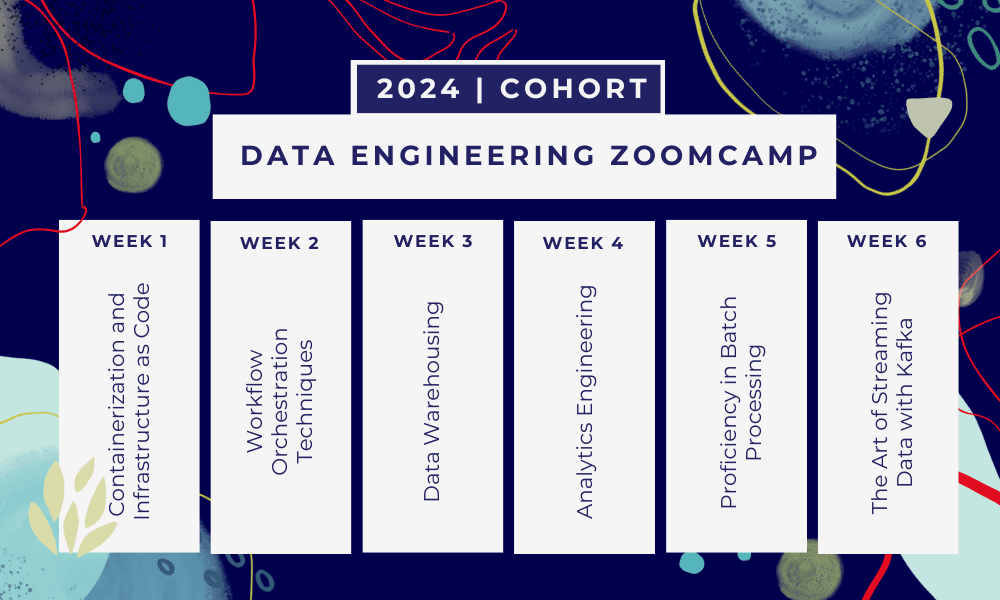
Il s'agit d'un Bootcamp de 6 semaines où vous apprendrez à travers plusieurs cours, matériels de lecture, ateliers et projets. À la fin de chaque module, vous recevrez des devoirs pour mettre en pratique ce que vous avez appris.
- Semaine 1: Introduction à GCP, Docker, Postgres, Terraform et à la configuration de l'environnement.
- Semaine 2: Orchestration du workflow avec Mage.
- Semaine 3: Entreposage de données avec BigQuery et machine learning avec BigQuery.
- Semaine 4: Ingénieur analytique avec dbt, Google Data Studio et Metabase.
- Semaine 5: Traitement par lots avec Spark.
- Semaine 6: Streaming avec Kafka.
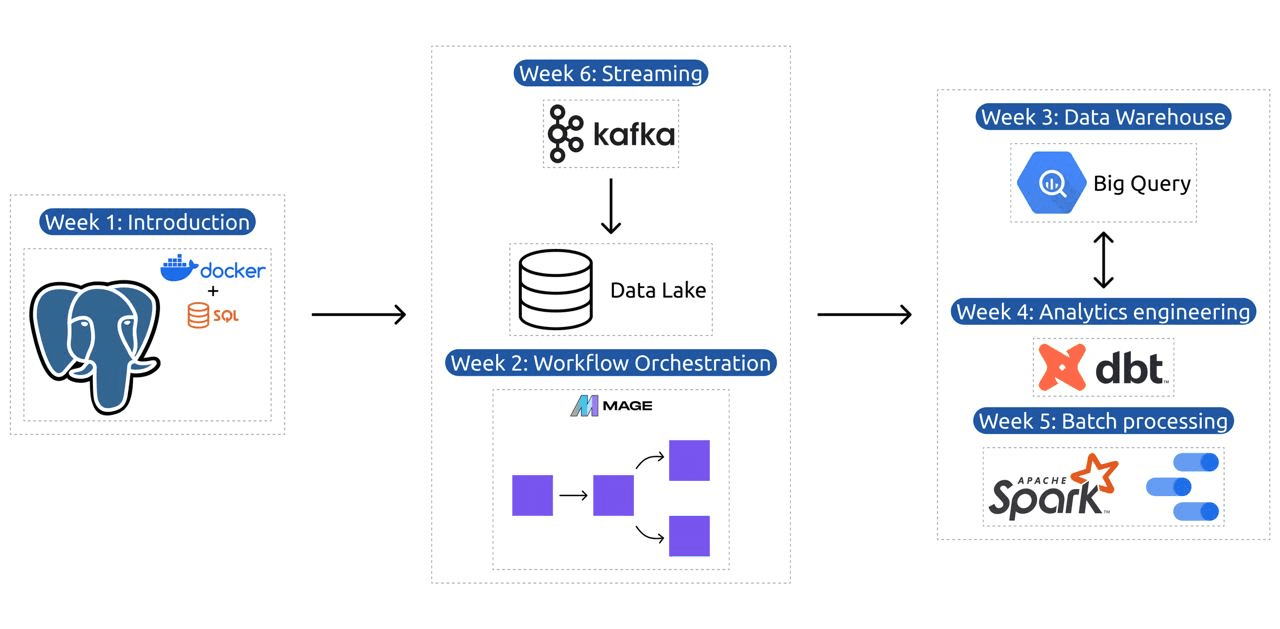
Image de DataTalksClub/data-engineering-zoomcamp
Le programme contient 6 modules, 2 ateliers et un projet qui couvre tout ce dont vous avez besoin pour devenir un ingénieur de données professionnel.
Module 1 : Maîtriser la conteneurisation et l'infrastructure en tant que code
Dans ce module, vous découvrirez Docker et Postgres, en commençant par les bases et en progressant à travers des didacticiels détaillés sur la création de pipelines de données, l'exécution de Postgres avec Docker, et plus encore.
Le module couvre également des outils essentiels tels que pgAdmin, Docker-compose et des sujets de mise à jour SQL, avec du contenu facultatif sur la mise en réseau Docker et une présentation spéciale pour les utilisateurs Linux du sous-système Windows. En fin de compte, le cours vous présente GCP et Terraform, offrant une compréhension globale de la conteneurisation et de l'infrastructure sous forme de code, essentielle pour les environnements cloud modernes.
Module 2 : Techniques d'orchestration des flux de travail
Le module propose une exploration approfondie de Mage, un framework hybride open source innovant pour la transformation et l'intégration de données. Ce module commence par les bases de l'orchestration des flux de travail, puis passe à des exercices pratiques avec Mage, notamment sa configuration via Docker et la création de pipelines ETL depuis l'API vers Postgres et Google Cloud Storage (GCS), puis vers BigQuery.
Le mélange de vidéos, de ressources et de tâches pratiques du module garantit une expérience d'apprentissage complète, dotant les apprenants des compétences nécessaires pour gérer des flux de travail de données sophistiqués à l'aide de Mage.
Atelier 1 : Stratégies d'ingestion de données
Dans le premier atelier, vous maîtriserez la création de pipelines d'ingestion de données efficaces. L'atelier se concentre sur les compétences essentielles telles que l'extraction de données à partir d'API et de fichiers, la normalisation et le chargement de données, ainsi que les techniques de chargement incrémentiel. Après avoir terminé cet atelier, vous serez en mesure de créer des pipelines de données efficaces comme un ingénieur de données senior.
Module 3 : Entreposage de données
Le module est une exploration approfondie du stockage et de l'analyse des données, en se concentrant sur l'entreposage de données à l'aide de BigQuery. Il couvre des concepts clés tels que le partitionnement et le clustering, et plonge dans les bonnes pratiques de BigQuery. Le module progresse vers des sujets avancés, en particulier l'intégration du Machine Learning (ML) avec BigQuery, mettant en évidence l'utilisation de SQL pour le ML et fournissant des ressources sur le réglage des hyperparamètres, le prétraitement des fonctionnalités et le déploiement de modèles.
Module 4 : Ingénierie analytique
Le module d'ingénierie analytique se concentre sur la construction d'un projet à l'aide de dbt (Data Build Tool) avec un entrepôt de données existant, BigQuery ou PostgreSQL.
Le module couvre la configuration de dbt dans les environnements cloud et locaux, l'introduction des concepts d'ingénierie analytique, ETL vs ELT et la modélisation des données. Il couvre également les fonctionnalités avancées de DBT telles que les modèles incrémentiels, les balises, les hooks et les instantanés.
En fin de compte, le module présente des techniques de visualisation des données transformées à l'aide d'outils tels que Google Data Studio et Metabase, et fournit des ressources pour le dépannage et le chargement efficace des données.
Module 5 : Maîtrise du traitement par lots
Ce module couvre le traitement par lots à l'aide d'Apache Spark, en commençant par les introductions au traitement par lots et à Spark, ainsi que les instructions d'installation pour Windows, Linux et MacOS.
Il comprend l'exploration de Spark SQL et des DataFrames, la préparation des données, l'exécution d'opérations SQL et la compréhension des composants internes de Spark. Enfin, il se termine par l'exécution de Spark dans le cloud et l'intégration de Spark à BigQuery.
Module 6 : L'art du streaming de données avec Kafka
Le module commence par une introduction aux concepts de traitement de flux, suivie d'une exploration approfondie de Kafka, y compris ses principes fondamentaux, son intégration avec Confluent Cloud et ses applications pratiques impliquant les producteurs et les consommateurs.
Le module couvre également la configuration et les flux de Kafka, abordant des sujets tels que les jointures de flux, les tests, le fenêtrage et l'utilisation de Kafka ksqldb & Connect. De plus, il étend son attention aux environnements Python et JVM, avec Faust pour le traitement de flux Python, Pyspark – Structured Streaming et des exemples Scala pour Kafka Streams.
Atelier 2 : Traitement de flux avec SQL
Vous apprendrez à traiter et à gérer des données en streaming avec RisingWave, qui fournit une solution rentable avec une expérience de style PostgreSQL pour renforcer vos applications de traitement de flux.
Projet : Application d'ingénierie de données réelles
L'objectif de ce projet est de mettre en œuvre tous les concepts que nous avons appris dans ce cours pour construire un pipeline de données de bout en bout. Vous allez créer un tableau de bord composé de deux vignettes en sélectionnant un ensemble de données, en créant un pipeline pour traiter les données et en les stockant dans un lac de données, en créant un pipeline pour transférer les données traitées du lac de données vers un entrepôt de données, en transformant les données dans l'entrepôt de données et les préparer pour le tableau de bord, et enfin créer un tableau de bord pour présenter les données visuellement.
Détails de la cohorte 2024
- Enregistrement: Inscrivez-vous maintenant
- Date de début : 15 janvier 2024, à 17h00 CET
- Apprentissage à votre rythme avec un accompagnement guidé
- Dossier de cohorte avec les devoirs et les délais
- interactif Communauté Slack pour l'apprentissage par les pairs
Pré-requis
- Compétences de base en codage et en ligne de commande
- Fondation en SQL
- Python : bénéfique mais pas obligatoire
Des instructeurs experts guident votre parcours
- Ankush Khanna
- Victoria Pérez Mola
- Alexeï Grigorev
- Palmier mat
- Luis Oliveira
- Michael Cordonnier
Rejoignez notre cohorte 2024 et commencez à apprendre avec une incroyable communauté d'ingénierie de données. Avec une formation dirigée par des experts, une expérience pratique et un programme adapté aux besoins de l'industrie, ce bootcamp vous dote non seulement des compétences nécessaires, mais vous place également à l'avant-garde d'un cheminement de carrière lucratif et en demande. Inscrivez-vous aujourd'hui et transformez vos aspirations en réalité !
Abid Ali Awan (@1abidaliawan) est un spécialiste des données certifié qui aime créer des modèles d'apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur les technologies d'apprentissage automatique et de science des données. Abid est titulaire d'une maîtrise en gestion de la technologie et d'un baccalauréat en génie des télécommunications. Sa vision est de créer un produit d'IA utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer

