Il s'agit d'un article invité co-écrit avec Scott Gutterman du PGA TOUR.
L’intelligence artificielle générative (IA générative) a ouvert de nouvelles possibilités pour créer des systèmes intelligents. Les améliorations récentes des grands modèles de langage (LLM) basés sur l'IA générative ont permis leur utilisation dans diverses applications liées à la récupération d'informations. Compte tenu des sources de données, les LLM ont fourni des outils qui nous permettraient de créer un chatbot de questions-réponses en quelques semaines, plutôt que ce qui aurait pu prendre des années auparavant, et probablement avec des performances moins bonnes. Nous avons formulé une solution de récupération-génération augmentée (RAG) qui permettrait au PGA TOUR de créer un prototype pour une future plateforme d'engagement des fans qui pourrait rendre ses données accessibles aux fans de manière interactive dans un format conversationnel.
L'utilisation de données structurées pour répondre à des questions nécessite un moyen d'extraire efficacement les données pertinentes par rapport à la requête d'un utilisateur. Nous avons formulé une approche texte vers SQL dans laquelle la requête en langage naturel d'un utilisateur est convertie en une instruction SQL à l'aide d'un LLM. Le SQL est exécuté par Amazone Athéna pour renvoyer les données pertinentes. Ces données sont à nouveau fournies à un LLM, qui est invité à répondre à la requête de l'utilisateur compte tenu des données.
L'utilisation de données textuelles nécessite un index qui peut être utilisé pour rechercher et fournir un contexte pertinent à un LLM afin de répondre à une requête de l'utilisateur. Pour permettre une récupération rapide des informations, nous utilisons Amazone Kendra comme index de ces documents. Lorsque les utilisateurs posent des questions, notre assistant virtuel recherche rapidement dans l'index Amazon Kendra pour trouver des informations pertinentes. Amazon Kendra utilise le traitement du langage naturel (NLP) pour comprendre les requêtes des utilisateurs et trouver les documents les plus pertinents. Les informations pertinentes sont ensuite fournies au LLM pour la génération de la réponse finale. Notre solution finale est une combinaison de ces approches texte-vers-SQL et texte-RAG.
Dans cet article, nous soulignons comment le Centre d'innovation AWS IA générative collaboré avec le Services professionnels AWS ainsi que PGA TOUR développer un prototype d'assistant virtuel utilisant Socle amazonien qui pourrait permettre aux fans d'extraire des informations sur n'importe quel événement, joueur, trou ou niveau de tir de manière interactive et transparente. Amazon Bedrock est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances provenant de grandes sociétés d'IA telles que AI21 Labs, Anthropic, Cohere, Meta, Stability AI et Amazon via une seule API, ainsi qu'un large ensemble de capacités dont vous avez besoin pour créer des applications d’IA générative avec sécurité, confidentialité et IA responsable.
Développement : préparer les données
Comme pour tout projet basé sur les données, les performances ne seront jamais aussi bonnes que les données. Nous avons traité les données pour permettre au LLM de pouvoir interroger et récupérer efficacement les données pertinentes.
Pour les données tabulaires de compétition, nous nous sommes concentrés sur un sous-ensemble de données pertinentes pour le plus grand nombre de requêtes d'utilisateurs et avons étiqueté les colonnes de manière intuitive, de manière à ce qu'elles soient plus faciles à comprendre pour les LLM. Nous avons également créé des colonnes auxiliaires pour aider le LLM à comprendre les concepts avec lesquels il pourrait autrement avoir des difficultés. Par exemple, si un golfeur tire un coup de moins que le par (par exemple, il réussit dans le trou en 3 coups sur un par 4 ou en 4 coups sur un par 5), cela est communément appelé un petit oiseau. Si un utilisateur demande : « Combien de birdies le joueur X a-t-il réalisé l'année dernière ? », il ne suffit pas d'avoir le score et le par dans le tableau. En conséquence, nous avons ajouté des colonnes pour indiquer les termes de golf courants, tels que bogey, birdie et eagle. De plus, nous avons lié les données du concours à une collection de vidéos distincte, en joignant une colonne pour un video_id, ce qui permettrait à notre application d'extraire la vidéo associée à un plan particulier dans les données du concours. Nous avons également permis de joindre les données textuelles aux données tabulaires, par exemple en ajoutant les biographies de chaque joueur sous forme de colonne de texte. Les figures suivantes montrent la procédure étape par étape de traitement d'une requête pour le pipeline texte vers SQL. Les chiffres indiquent la série d'étapes pour répondre à une requête.
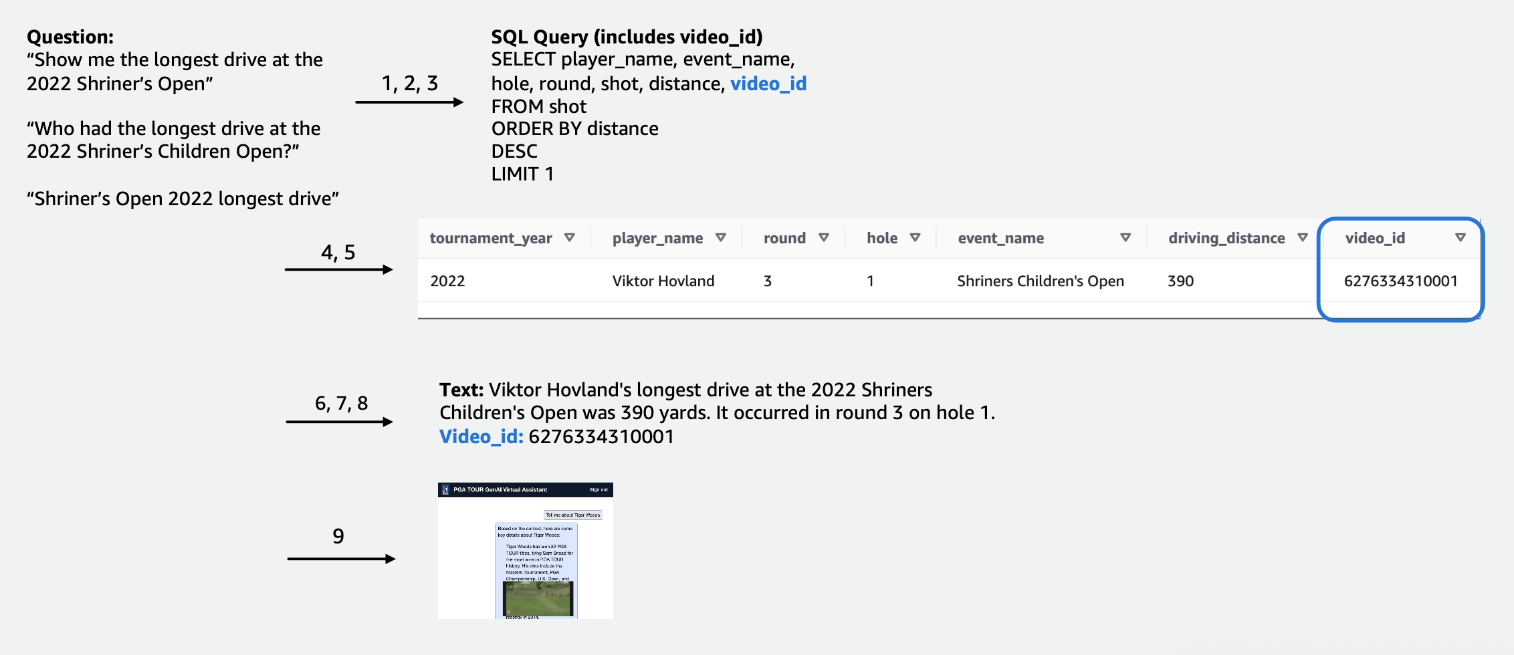
Dans la figure suivante, nous démontrons notre pipeline de bout en bout. Nous utilisons AWS Lambda en tant que fonction d'orchestration chargée d'interagir avec diverses sources de données, LLM et correction d'erreurs en fonction de la requête de l'utilisateur. Les étapes 1 à 8 sont similaires à celles illustrées dans la figure suivante. Il y a de légers changements pour les données non structurées, dont nous discuterons ensuite.
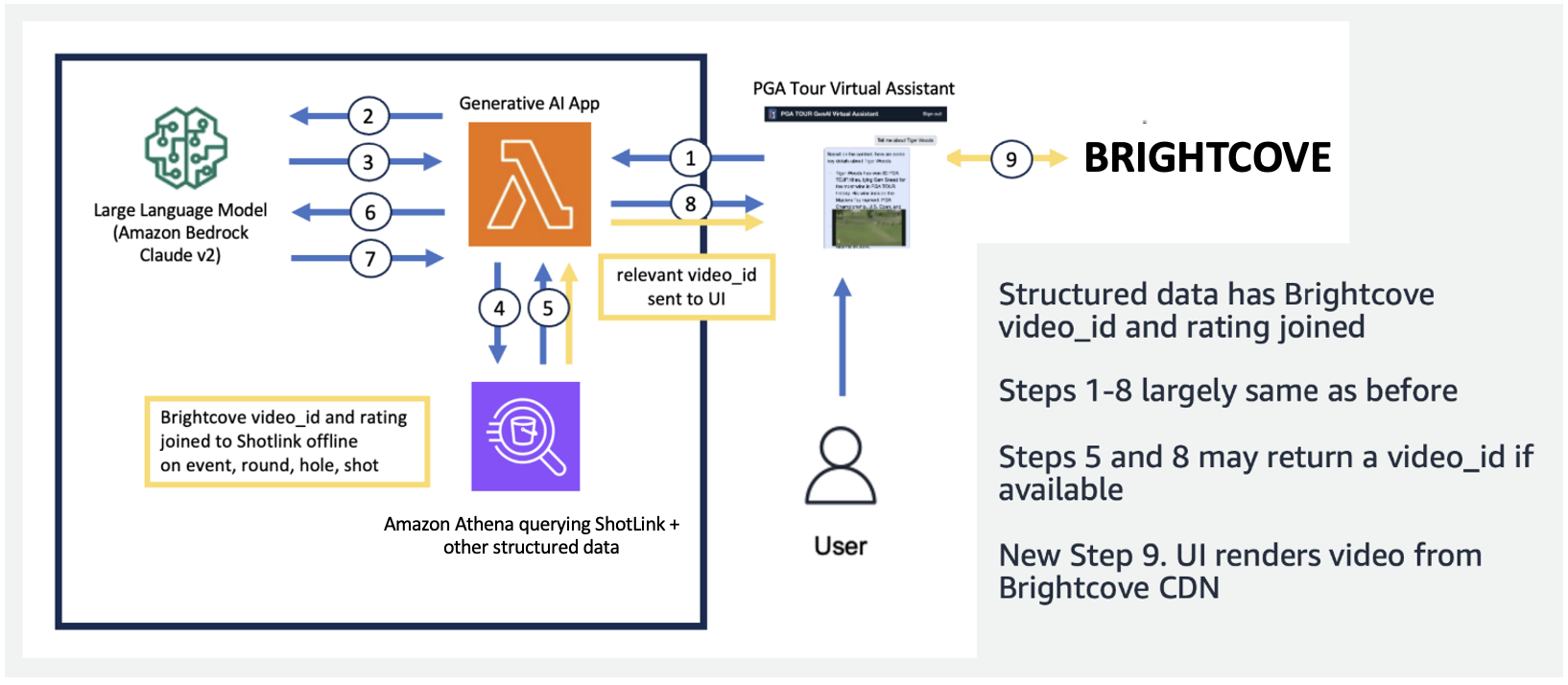
Les données textuelles nécessitent des étapes de traitement uniques qui décomposent (ou segmentent) les longs documents en parties digestibles par le LLM, tout en maintenant la cohérence du sujet. Nous avons expérimenté plusieurs approches et avons opté pour un système de segmentation au niveau de la page qui s'alignait bien avec le format des guides multimédias. Nous avons utilisé Amazon Kendra, qui est un service géré qui s'occupe de l'indexation des documents, sans nécessiter de spécification d'intégration, tout en fournissant une API simple pour la récupération. La figure suivante illustre cette architecture.

Le pipeline unifié et évolutif que nous avons développé permet au PGA TOUR de s'adapter à l'intégralité de son historique de données, dont certaines remontent aux années 1800. Il permet aux futures applications qui pourront s'appuyer sur le contexte du cours de créer de riches expériences en temps réel.
Développement : évaluation des LLM et développement d'applications d'IA générative
Nous avons soigneusement testé et évalué les LLM propriétaires et tiers disponibles dans Amazon Bedrock pour choisir le modèle le mieux adapté à notre pipeline et à notre cas d'utilisation. Nous avons sélectionné Claude v2 et Claude Instant d'Anthropic sur Amazon Bedrock. Pour notre pipeline de données final structuré et non structuré, nous observons que Claude 2 d'Anthropic sur Amazon Bedrock a généré de meilleurs résultats globaux pour notre pipeline de données final.
L'invite est un aspect essentiel pour amener les LLM à produire le texte comme souhaité. Nous avons passé beaucoup de temps à expérimenter différentes invites pour chacune des tâches. Par exemple, pour le pipeline texte vers SQL, nous avions plusieurs invites de secours, avec une spécificité croissante et des schémas de table progressivement simplifiés. Si une requête SQL n'était pas valide et entraînait une erreur d'Athena, nous avons développé une invite de correction d'erreur qui transmettrait l'erreur et le SQL incorrect au LLM et lui demanderait de la corriger. L'invite finale du pipeline texte vers SQL demande au LLM de prendre la sortie Athena, qui peut être fournie au format Markdown ou CSV, et de fournir une réponse à l'utilisateur. Pour le texte non structuré, nous avons développé des invites générales pour utiliser le contexte récupéré d'Amazon Kendra pour répondre à la question de l'utilisateur. L'invite comprenait des instructions pour utiliser uniquement les informations récupérées d'Amazon Kendra et ne pas s'appuyer sur les données de la pré-formation LLM.
La latence est souvent un problème dans les applications d’IA générative, et c’est également le cas ici. C'est particulièrement préoccupant pour le texte vers SQL, qui nécessite un invocation LLM de génération SQL initiale, suivie d'un invocation LLM de génération de réponse. Si nous utilisons un grand LLM, tel que Claude V2 d'Anthropic, cela double effectivement la latence d'une seule invocation de LLM. Nous avons expérimenté plusieurs configurations de LLM grands et petits pour évaluer le temps d'exécution ainsi que l'exactitude. Le tableau suivant montre un exemple pour une question ci-dessous qui démontre la latence, ainsi que les réponses générées avec Claude V2 et Claude Instant d'Anthropic sur Amazon Bedrock.

Prototype
Dans notre application, nous avons utilisé une fonction Lambda pour orchestrer les choix rapides et la communication entre Amazon Athena, Amazon Kendra et Amazon Bedrock. L'assistant virtuel dispose d'une interface conversationnelle, construite avec React et Cloudscape Design System, qui utilise du texte et des vidéos pour interagir avec les utilisateurs.
Notre assistant virtuel peut répondre à un large éventail de questions sur les événements du PGA TOUR, les joueurs, les statistiques, l'historique et bien plus encore. Par exemple, lorsqu'on l'interroge sur les plus longs drives de Tony Finau à l'Open Shriners pour enfants (l'un des événements phares du PGA TOUR), l'assistant peut interroger des données structurées pour extraire ses données de niveau de tir. Il peut extraire la distance exacte en yards, le numéro du tour et le trou au cours duquel il a atteint ce record à l'aide du pipeline texte vers SQL. L'assistant interprète ensuite ces données numériques pour générer une réponse finale. Le tableau suivant contient quelques exemples de réponses.
| Question | Réponse |
| Quel a été le drive le plus long réalisé par Tony Finau à l'Omnium Shriners pour enfants ? | Le plus long drive réussi par Tony Finau lors du Shriners Childrens Open était de 382 yards, qu'il a réussi lors du premier tour sur le trou numéro 4 en 2018. |
| Quel a été le drive le plus long de Collin Morikawa à l'Open Shriners pour enfants ? | Le plus long drive de Collin Morikawa au Shriners Childrens Open était de 334 verges. Cela s’est produit en 2019 lors du premier tour sur le trou numéro 15. |
| Quelqu’un a-t-il réussi un as à l’Omnium Shriners pour enfants 2022 ? | Oui, Adam Hadwin a réussi un trou d'un coup au trou 14 lors de la troisième ronde de l'Omnium Shriners pour enfants 3. |
La vidéo explicative suivante présente quelques exemples d'interaction avec l'assistant virtuel.
Lors des premiers tests, notre assistant virtuel PGA TOUR s’est montré très prometteur pour améliorer l’expérience des fans. En combinant des technologies d'IA telles que le texte vers SQL, la recherche sémantique et la génération de langage naturel, l'assistant fournit des réponses informatives et engageantes. Les fans ont la possibilité d’accéder sans effort à des données et à des récits auparavant difficiles à trouver.
Que nous réserve l’avenir?
Au fur et à mesure que nous poursuivons le développement, nous élargirons la gamme de questions que notre assistant virtuel peut traiter. Cela nécessitera des tests approfondis, grâce à la collaboration entre AWS et le PGA TOUR. Au fil du temps, nous visons à faire évoluer l’assistant vers une expérience personnalisée et omnicanal accessible sur les interfaces Web, mobiles et vocales.
La mise en place d'un assistant d'IA générative basé sur le cloud permet au PGA TOUR de présenter sa vaste source de données à de multiples parties prenantes internes et externes. À mesure que le paysage de l’IA générative sportive évolue, il permet la création de nouveaux contenus. Par exemple, vous pouvez utiliser l'IA et l'apprentissage automatique (ML) pour afficher le contenu que les fans souhaitent voir lorsqu'ils regardent un événement, ou lorsque les équipes de production recherchent des images de tournois précédents qui correspondent à un événement en cours. Par exemple, si Max Homa se prépare à tenter sa dernière chance au Championnat PGA TOUR depuis un endroit situé à 20 pieds du pin, le PGA TOUR peut utiliser l'IA et le ML pour identifier et présenter des clips de lui, avec des commentaires générés par l'IA. avoir tenté un tir similaire cinq fois auparavant. Ce type d'accès et de données permet à une équipe de production d'ajouter immédiatement de la valeur à la diffusion ou de permettre à un fan de personnaliser le type de données qu'il souhaite voir.
« Le PGA TOUR est le leader de l'industrie dans l'utilisation d'une technologie de pointe pour améliorer l'expérience des fans. L'IA est à la pointe de notre pile technologique, où elle nous permet de créer un environnement plus engageant et interactif pour les fans. C'est le début de notre parcours d'IA générative en collaboration avec l'AWS Generative AI Innovation Center pour une expérience client transformationnelle de bout en bout. Nous travaillons à exploiter Amazon Bedrock et nos données exclusives pour créer une expérience interactive permettant aux fans du PGA TOUR de trouver des informations intéressantes sur un événement, un joueur, des statistiques ou tout autre contenu de manière interactive.
– Scott Gutterman, vice-président directeur de la diffusion et des propriétés numériques chez PGA TOUR.
Conclusion
Le projet dont nous avons parlé dans cet article illustre comment des sources de données structurées et non structurées peuvent être fusionnées à l'aide de l'IA pour créer des assistants virtuels de nouvelle génération. Pour les organisations sportives, cette technologie permet un engagement plus immersif des fans et débloque des efficacités internes. Les données intelligentes que nous mettons en évidence aident les parties prenantes du PGA TOUR telles que les joueurs, les entraîneurs, les officiels, les partenaires et les médias à prendre plus rapidement des décisions éclairées. Au-delà du sport, notre méthodologie peut être reproduite dans n’importe quel secteur. Les mêmes principes s'appliquent aux assistants de construction qui engagent les clients, les employés, les étudiants, les patients et autres utilisateurs finaux. Grâce à une conception et des tests réfléchis, pratiquement n'importe quelle organisation peut bénéficier d'un système d'IA qui contextualise ses bases de données structurées, ses documents, ses images, ses vidéos et autres contenus.
Si vous souhaitez implémenter des fonctionnalités similaires, envisagez d'utiliser Agents pour le substrat rocheux d’Amazonie ainsi que Bases de connaissances pour Amazon Bedrock comme solution alternative entièrement gérée par AWS. Cette approche pourrait permettre d’étudier plus en détail la fourniture de capacités intelligentes d’automatisation et de recherche de données via des agents personnalisables. Ces agents pourraient potentiellement transformer les interactions des applications utilisateur pour les rendre plus naturelles, plus efficaces et plus efficientes.
À propos des auteurs
 Scott Gutterman est le vice-président directeur des opérations numériques du PGA TOUR. Il est responsable des opérations numériques globales du TOUR, du développement de produits et pilote leur stratégie GenAI.
Scott Gutterman est le vice-président directeur des opérations numériques du PGA TOUR. Il est responsable des opérations numériques globales du TOUR, du développement de produits et pilote leur stratégie GenAI.
 Ahsan Ali est un scientifique appliqué au Amazon Generative AI Innovation Center, où il travaille avec des clients de différents domaines pour résoudre leurs problèmes urgents et coûteux à l'aide de Generative AI.
Ahsan Ali est un scientifique appliqué au Amazon Generative AI Innovation Center, où il travaille avec des clients de différents domaines pour résoudre leurs problèmes urgents et coûteux à l'aide de Generative AI.
 Tahin Syed est un scientifique appliqué au sein de l'Amazon Generative AI Innovation Center, où il travaille avec des clients pour les aider à obtenir des résultats commerciaux grâce à des solutions d'IA générative. En dehors du travail, il aime essayer de nouveaux plats, voyager et enseigner le taekwondo.
Tahin Syed est un scientifique appliqué au sein de l'Amazon Generative AI Innovation Center, où il travaille avec des clients pour les aider à obtenir des résultats commerciaux grâce à des solutions d'IA générative. En dehors du travail, il aime essayer de nouveaux plats, voyager et enseigner le taekwondo.
 Grace Lang est un ingénieur associé en données et ML chez AWS Professional Services. Animée par la passion de relever des défis difficiles, Grace aide ses clients à atteindre leurs objectifs en développant des solutions basées sur l'apprentissage automatique.
Grace Lang est un ingénieur associé en données et ML chez AWS Professional Services. Animée par la passion de relever des défis difficiles, Grace aide ses clients à atteindre leurs objectifs en développant des solutions basées sur l'apprentissage automatique.
 Jae Lee est responsable de l'engagement principal dans le secteur vertical M&E de ProServe. Elle dirige et réalise des missions complexes, fait preuve de solides compétences en résolution de problèmes, gère les attentes des parties prenantes et organise des présentations au niveau de la direction. Elle aime travailler sur des projets axés sur le sport, l'IA générative et l'expérience client.
Jae Lee est responsable de l'engagement principal dans le secteur vertical M&E de ProServe. Elle dirige et réalise des missions complexes, fait preuve de solides compétences en résolution de problèmes, gère les attentes des parties prenantes et organise des présentations au niveau de la direction. Elle aime travailler sur des projets axés sur le sport, l'IA générative et l'expérience client.
 Karn Chahar est consultant en sécurité au sein de l'équipe de livraison partagée d'AWS. C'est un passionné de technologie qui aime travailler avec les clients pour résoudre leurs problèmes de sécurité et améliorer leur posture de sécurité dans le cloud.
Karn Chahar est consultant en sécurité au sein de l'équipe de livraison partagée d'AWS. C'est un passionné de technologie qui aime travailler avec les clients pour résoudre leurs problèmes de sécurité et améliorer leur posture de sécurité dans le cloud.
 Mike Amjadi est un ingénieur données et ML chez AWS ProServe dont l'objectif est de permettre aux clients de maximiser la valeur des données. Il se spécialise dans la conception, la création et l'optimisation de pipelines de données selon des principes bien architecturés. Mike est passionné par l'utilisation de la technologie pour résoudre des problèmes et s'engage à fournir les meilleurs résultats à nos clients.
Mike Amjadi est un ingénieur données et ML chez AWS ProServe dont l'objectif est de permettre aux clients de maximiser la valeur des données. Il se spécialise dans la conception, la création et l'optimisation de pipelines de données selon des principes bien architecturés. Mike est passionné par l'utilisation de la technologie pour résoudre des problèmes et s'engage à fournir les meilleurs résultats à nos clients.
 Vrushali Sawant est un ingénieur front-end chez Proserve. Elle est hautement compétente dans la création de sites Web réactifs. Elle aime travailler avec les clients, comprendre leurs besoins et leur fournir des solutions UI/UX évolutives et faciles à adopter.
Vrushali Sawant est un ingénieur front-end chez Proserve. Elle est hautement compétente dans la création de sites Web réactifs. Elle aime travailler avec les clients, comprendre leurs besoins et leur fournir des solutions UI/UX évolutives et faciles à adopter.
 Neelam Patel est responsable des solutions client chez AWS, dirigeant des initiatives clés d'IA générative et de modernisation du cloud. Neelam travaille avec des dirigeants clés et des propriétaires de technologies pour relever leurs défis de transformation du cloud et aide les clients à maximiser les avantages de l'adoption du cloud. Elle est titulaire d'un MBA de la Warwick Business School, au Royaume-Uni, et d'un baccalauréat en génie informatique, en Inde.
Neelam Patel est responsable des solutions client chez AWS, dirigeant des initiatives clés d'IA générative et de modernisation du cloud. Neelam travaille avec des dirigeants clés et des propriétaires de technologies pour relever leurs défis de transformation du cloud et aide les clients à maximiser les avantages de l'adoption du cloud. Elle est titulaire d'un MBA de la Warwick Business School, au Royaume-Uni, et d'un baccalauréat en génie informatique, en Inde.
 Dr Murali Baktha est Global Golf Solution Architect chez AWS, il dirige des initiatives cruciales impliquant l'IA générative, l'analyse de données et les technologies cloud de pointe. Murali travaille avec des dirigeants clés et des propriétaires de technologies pour comprendre les défis commerciaux des clients et conçoit des solutions pour relever ces défis. Il est titulaire d'un MBA en finance de l'UConn et d'un doctorat de l'Iowa State University.
Dr Murali Baktha est Global Golf Solution Architect chez AWS, il dirige des initiatives cruciales impliquant l'IA générative, l'analyse de données et les technologies cloud de pointe. Murali travaille avec des dirigeants clés et des propriétaires de technologies pour comprendre les défis commerciaux des clients et conçoit des solutions pour relever ces défis. Il est titulaire d'un MBA en finance de l'UConn et d'un doctorat de l'Iowa State University.
 Mehdi Nour est responsable des sciences appliquées au Generative Ai Innovation Center. Passionné par le rapprochement entre technologie et innovation, il aide les clients AWS à libérer le potentiel de l'IA générative, en transformant les défis potentiels en opportunités d'expérimentation et d'innovation rapides en se concentrant sur des utilisations évolutives, mesurables et percutantes des technologies avancées d'IA, et en rationalisant le chemin. à la production.
Mehdi Nour est responsable des sciences appliquées au Generative Ai Innovation Center. Passionné par le rapprochement entre technologie et innovation, il aide les clients AWS à libérer le potentiel de l'IA générative, en transformant les défis potentiels en opportunités d'expérimentation et d'innovation rapides en se concentrant sur des utilisations évolutives, mesurables et percutantes des technologies avancées d'IA, et en rationalisant le chemin. à la production.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/the-journey-of-pga-tours-generative-ai-virtual-assistant-from-concept-to-development-to-prototype/

