Introduction
La vision par ordinateur est une branche de l'IA qui fournit à une machine une compréhension de haut niveau d'une image et le pouvoir d'effectuer des tâches sur des images que même les humains ne peuvent pas effectuer. 2022 a été l'année du boom pour la vision par ordinateur. Jusqu'à présent, l'année a été la plus productive pour Computer Vision. De nombreuses nouvelles technologies ont été développées, des produits ont été lancés, de nouveaux modèles ont été formés et de nombreuses mises à jour ont eu lieu. Parmi toutes les innovations de cette année, j'ai sélectionné les 10 sujets les plus utiles, les plus puissants et les plus tendances de la vision par ordinateur en 2022.
Détection et suivi d'objets
La détection et le suivi d'objets sont un domaine de recherche principal en vision par ordinateur et figuraient parmi les meilleurs de la vision par ordinateur en 2022. Les premiers travaux en matière de détection d'objets remontent à 2000. Au cours des 20 années suivantes, ce domaine s'est considérablement amélioré et a réussi. Les chercheurs s'efforcent de créer de meilleurs algorithmes de détection d'objets. Il a un large éventail d'applications en vision par ordinateur, telles que les voitures autonomes, la sécurité et la surveillance, etc. Maintenant, nous allons essayer de comprendre la détection et le suivi d'objets.
Comme son nom l'indique, la détection d'objet identifie l'objet et son emplacement dans l'image. Dans le même temps, le suivi d'objet fait référence à la capacité d'identifier un objet particulier et son emplacement dans la vidéo. L'état de l'art (SOTA ) dans la détection d'objets jusqu'en 2021 était YOLOv5. En ce qui concerne le suivi d'objets, MOT et Deepsort sont des algorithmes de suivi largement utilisés. En ce qui concerne la vision par ordinateur en 2022, deux technologies ont explosé liées à la détection et au suivi d'objets.
YOLOv7
Yolov7 est une version récente de la famille YOLO. C'est l'état de l'art pour la détection d'objets à ce jour. Il a surpassé tous les autres algorithmes de détection d'objets en termes de vitesse et de précision.
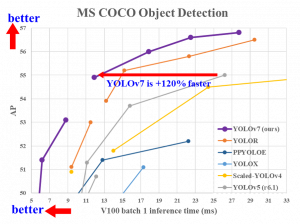
Source – github
On peut déduire de l'image ci-dessus que YOLOv7 fonctionne 120% plus rapidement que toutes les autres versions précédentes de YOLO.
OctetTrack
ByteTrack est un système de suivi multi-objets. Le suivi multi-objets (MOT) est un processus de suivi du chemin de plusieurs objets présents dans une seule image d'une vidéo. La plupart des algorithmes MOT fonctionnent sur les scores de confiance, le seuillage et les rejets objects qui ont des scores faibles. L'algorithme ByteTrack ne repose pas sur les valeurs de confiance de l'objet détecté. Au lieu de cela, il suit le chemin des objets à faible score et trouve des similitudes avec les autres images pour détecter le véritable objet et suivre le chemin en conséquence au lieu de rejeter les objets à faible score. Les objets à faible score sont mis en correspondance avec les tracklets et l'objet est détecté s'il existe vraiment. Le modèle ByteTrack fonctionne bien même pour les objets masqués (lorsque l'objet est caché derrière un autre objet).
Il atteint un total de 80.3 MOTA

Source – github
Vous pouvez en savoir plus sur ByteTrack ici - https://arxiv.org/abs/2110.06864
Génération d'images et de vidéos
La technologie a permis de générer des images et des vidéos basées sur une description textuelle de base d'une situation ou d'une image. Il s'agit d'une technologie de vision par ordinateur passionnante en 2022 car elle peut vous aider à visualiser ce que vous imaginez et à le montrer aux autres. La troncature douce, une technique de formation universelle de modèles de diffusion basés sur des scores, a obtenu des résultats de pointe dans la génération d'images jusqu'en 2021 sur les ensembles de données CIFAR-10, CelebA, CelebA-HQ 256 × 256 et STL-10. Il y a eu des progrès dans le domaine et de nombreuses grandes entreprises comme meta, google, OpenAI, etc., ont proposé différentes technologies et approches. Certains des outils et technologies lancés en 2022 sont décrits ci-dessous-
Image
Imagen, développé par Google et lancé en 2022, est un modèle de diffusion texte-image. Il prend une description d'une image et produit des images réalistes. Les modèles de diffusion sont des modèles génératifs qui produisent des images à haute résolution. Ces modèles fonctionnent en deux étapes. Dans la première étape, des bruits gaussiens aléatoires sont ajoutés à l'image, puis dans la deuxième étape, le modèle apprend à inverser le processus en supprimant le bruit, générant ainsi de nouvelles données.
Imagen encode le texte en encodages puis utilise le modèle de diffusion pour générer une image. Une série de modèles de diffusion sont utilisés pour produire des images à haute résolution. C'est une technologie vraiment intéressante car vous pouvez visualiser votre pensée créative simplement en décrivant une image et générer ce que vous voulez en quelques instants.
Description img - Une photo d'un chien Corgi faisant du vélo à Times Square. Il porte des lunettes de soleil et un chapeau de plage.
Sortie :

Source-Google
L'encodeur de texte encode la description du donné et produit des encodages à partir desquels le modèle de diffusion produit des images à haute résolution. Voici le document de recherche pour votre référence https://imagen.research.google/paper.pdf
Faire une vidéo
Quoi de plus intéressant que de générer une image à partir de la description ? Oui! Vous avez bien deviné ! Make-A-Video, lancé par Meta en 2022, permet de générer une vidéo basée sur la description de l'image. Le modèle utilise des images avec une description pour créer une vidéo en fonction de la description. Il utilise également des vidéos sans étiquette pour apprendre et améliorer la vidéo générée.
Le concept du modèle peut être expliqué en 3 étapes simples. La génération de texte en image, prenant des instances à partir d'un ensemble de séquences vidéo non supervisées, puis le réseau d'interpolation pour remplir les images et former une vidéo. Un tas de modèles est utilisé et leur combinaison pour générer des vidéos haute résolution. Le lien vers le document de recherche est donné ci-dessous si vous souhaitez en savoir plus sur la technologie.

Source – makeavideo.studio
Vous pouvez explorer cette invention étonnante et faire beaucoup de choses, comme ajouter du mouvement à un cadre statique et amener votre imagination à l'écran. Cette technologie est passionnante et mérite d'être explorée. Vous pouvez lire le document de recherche ici: https://arxiv.org/abs/2209.14792
DALL-E2
DALL-E2 est un système d'IA développé par OpenAI et lancé en 2022 qui peut créer des images réalistes et de l'art basé sur des descriptions textuelles. Nous avons déjà vu les mêmes technologies, mais ce système vaut également la peine d'être exploré et d'y consacrer du temps. J'ai trouvé DALL-E2 comme l'un des meilleurs modèles actuels, qui fonctionne sur la génération d'images.

Il utilise une version de GPT-3 modifiée pour générer des images et est formé sur des millions d'images provenant de partout sur Internet. DALL-E utilise une combinaison de techniques NLP pour comprendre la signification du texte saisi et de techniques de vision par ordinateur pour générer l'image. Il est formé sur un grand ensemble de données d'images et leurs descriptions textuelles associées, ce qui lui permet d'apprendre les relations entre les mots et les caractéristiques visuelles. DALL-E peut générer des images cohérentes avec le texte d'entrée en apprenant ces relations.
Voici le lien vers le document de recherche si vous êtes intéressé à lire en détail: https://arxiv.org/abs/2102.12092
FILM : interpolation d'image pour les grands mouvements
FILM est un autre modèle de génération vidéo développé par Google qui tourne des photos presque similaires et distantes de quelques images dans une vidéo au ralenti. Le modèle donne l'impression que la vidéo est capturée par une caméra au ralenti en interpolant les images entre les deux images. La distance entre les cadres s'avère être un problème, mais cela est pris en charge par l'extracteur de caractéristiques. D'autres concepts sont utilisés qui, peut-être, peuvent être repris dans un autre blog. Mais juste un aperçu pour l'instant.
Les codes et le modèle pré-formé sont présents sur le google-research GitHub pour référence ultérieure. Ce modèle peut produire la prise de vue comme une photo en direct dans un iPhone au ralenti. Cela peut être très intéressant et utile car parfois on peut rater un cliché parfait mais bon ! Il y a FILM pour s'en occuper….
Source – film-net.github.io
Voici le lien vers le document de recherche pour votre référence: https://arxiv.org/pdf/2202.04901.pdf
Infinite Nature Zero : génération de survols 3D à partir de photos fixes
Je suis sûr que vous avez vu ces plans fous dans les films et plus particulièrement dans les documentaires animaliers où la caméra survole le paysage produisant un plan malade de la nature ou un time-lapse du nuage, qui semble être très beau. L'équipe de recherche de Google a lancé le modèle Infinite Nature Zero en 2022 qui peut générer ces clichés étonnants à partir d'images fixes. Oui! Vous avez bien entendu, à partir d'images fixes. Il a zéro dans son nom car il nécessite 0 vidéos sur lesquelles s'entraîner pour produire des vidéos.
Le modèle utilise des GAN (réseaux antagonistes génératifs) pour générer les images. Le modèle utilise un modèle d'entraînement de génération de vues auto-supervisé en échantillonnant des vues similaires avec des angles de caméra et des trajectoires similaires. Le modèle peut générer des prises de vue fascinantes sans être alimenté par aucune vidéo.
Source - nature infinie-zéro.github.io
Vous pouvez consulter le document de recherche pour votre référence https://arxiv.org/abs/2207.11148
Application de transformateurs aux problèmes d'image
Les transformateurs sont des réseaux de neurones d'auto-attention qui fonctionnent sur le mécanisme de parallélisation. Il apprend la logique et la sémantique des phrases et peut être utilisé pour le traitement du langage naturel. Elle diffère des autres techniques de PNL car d'autres techniques peuvent traiter le texte en une seule fois ou en « parallèle ». En revanche, le transformateur peut s'avérer efficace car les mots éloignés les uns des autres peuvent également être comparés et analysés contextuellement, ce qui se traduit par de meilleures prédictions et le contexte du texte.

Source – wikipédia
Le transformateur de vision de type transformateur surpasse les sota CNN actuels qui sont largement utilisés dans les tâches de vision par ordinateur, mais il y a eu une augmentation de l'utilisation d'un transformateur dans ce domaine car il surpasse CNN en termes de précision et de vitesse.
Quelques technologies qui ont explosé en vision par ordinateur en 2022 :
Mise à l'échelle des transformateurs de vision
Vision Transformer (ViT) a obtenu des résultats de pointe sur de nombreux benchmarks de vision par ordinateur. Il atteint une précision totale de 90.45 % sur l'ensemble de données ImageNet qui est sota à ce jour. Le concept de mise à l'échelle est le concept principal qui aide le modèle à atteindre la hauteur de précision. Certaines expériences avec les données et la mise à l'échelle du modèle ont été effectuées et analysées, et l'architecture raffinée finale a été atteinte. Voici le lien vers le document de recherche si vous souhaitez en savoir plus sur la technologie : https://arxiv.org/abs/2106.04560
Pix2Seq : une nouvelle interface de langage pour la détection d'objets
Pix2Seq est un framework d'algorithmes de détection d'objets lancé par Google en 2022. Le framework suppose que la tâche de détection d'objet prédit le mot suivant dans NLP. Les boîtes englobantes sont considérées comme des jetons car la machine est entraînée à comprendre l'image et à générer des boîtes englobantes similaires. Le modèle atteint une précision notable sur l'ensemble de données COCO sans utiliser d'approches telles que l'augmentation des données et d'autres techniques utilisées par les autres algorithmes.
Apprentissage auto-supervisé
L'apprentissage auto-supervisé a été l'un des sujets les plus brûlants en 2022. L'algorithme d'apprentissage auto-supervisé ne nécessite pas d'étiquettes explicites en entrée. Au contraire, il apprend d'une partie des données elles-mêmes. L'algorithme d'apprentissage auto-supervisé résout le problème de notre dépendance excessive aux données étiquetées. La génération automatique des étiquettes fait passer le problème d'un problème d'apprentissage non supervisé à un problème d'apprentissage supervisé. Voici quelques techniques lancées en vision par ordinateur en 2022 pour un apprentissage auto-supervisé.
Données2vec
Data2Vec a été lancé plus tôt cette année en janvier 2022. Data2vec est utilisé dans les modèles d'apprentissage des données et utilise la même méthode d'apprentissage pour la parole, la PNL ou la vision par ordinateur. L'intuition derrière Data2Vec est que le modèle reçoit une vue brisée/masquée de l'entrée, comme l'image ci-dessous. Ainsi, le modèle ne reçoit que 20 % de données brutes et est invité à prédire la sortie en analysant les modèles et en apprenant la représentation abstraite dans les données sans être alimenté par des milliers d'images d'un chat comme les algorithmes traditionnels.

Le modèle peut reconstruire l'image comme indiqué ci-dessous

Le modèle présente des performances de pointe par rapport aux méthodes existantes. Vous pouvez consulter le document de recherche via ce lien: Document de recherche
Améliorer l'apprentissage par transfert
L'utilisation de l'apprentissage par transfert a facilité la vie des passionnés de science des données. L'apprentissage par transfert consiste à utiliser un modèle pré-formé tel que VGG-16 pour effectuer une tâche similaire sur un ensemble de données personnalisé. Les poids appris par le modèle sont réutilisés et recyclés sur les données pour lesquelles nous voulons effectuer la tâche similaire pour laquelle le modèle a été formé. Cela permet d'économiser beaucoup de temps et d'efforts car nous n'avons pas à former le modèle sur des millions d'images et à nous soucier de la précision du modèle et d'autres aspects.
Bien que l'apprentissage par transfert ait été rapide, il y a eu quelques améliorations en 2022, ce qui est mieux pour nous. Voici quelques technologies qui ont explosé en 2022.
Réglage fin robuste des modèles Zero-Shot
Les modèles Zero-Shot, comme leur nom l'indique, sont des modèles qui ne sont pas affinés sur un ensemble de données spécifique. Cette technologie s'est avérée précise sur une distribution particulière mais réduit la robustesse sous les changements de distribution. Le réglage fin robuste des modèles de tir zéro a amélioré la précision de ces modèles sous les changements de distribution. Le concept utilisé est l'utilisation harmonieuse des poids du modèle zéro-shot et du modèle affiné (WiSE-FT).
Cela améliore la précision sous les changements de distribution à 4-6% et 1.6 points de pourcentage sur l'ensemble de données ImageNet. En savoir plus sur le réglage fin robuste pour les modèles à tir zéro ici : https://arxiv.org/abs/2109.01903
Détection d'objets à quelques coups avec un transformateur entièrement croisé
La détection d'objets à quelques coups fait référence à la tâche dans laquelle le modèle détecte les classes invisibles avec très peu d'exemples d'entraînement. Cette méthode résout le problème de notre dépendance excessive à des milliers d'images annotées. Le sota précédent utilisait un réseau siamois à deux branches pour la détection d'objets à quelques coups. Il y avait quelques problèmes dans le réseau utilisé qui sont pris en charge par le modèle entièrement basé sur des transformateurs croisés.
Le concept derrière cette approche est qu'elle encode un ensemble de quelques images qui sont données comme exemples de formation. Il comprend des transformateurs croisés à la fois dans la dorsale et la tête de détection et utilise un SGD pour optimiser la formation afin de réduire les erreurs bentre classes réelles et classes erronées. En savoir plus sur la détection d'objets à quelques coups avec un transformateur entièrement croisé ici :
https://arxiv.org/abs/2203.15021
Conclusion
Cet article donne un aperçu des dernières technologies lancées et en plein essor dans la vision par ordinateur en 2022 ; il y a encore beaucoup à venir. Nous avons brièvement saisi quelques concepts qui sont utilisés dans ces technologies. La vision par ordinateur est un vaste domaine qui continue de progresser. Il y a beaucoup à découvrir et à explorer et de nombreuses opportunités dans un avenir proche. Je vous encourage à rechercher les sujets dont nous avons discuté et à plonger profondément dans la gloire de la vision par ordinateur. J'espère que vous avez aimé l'article et j'ai hâte de l'explorer.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2022/12/computer-vision-in-2022-a-quick-recap/

