Auteur : Vitalik Buterin via le Blog de Vitalik Buterin
Un merci spécial aux équipes Worldcoin et Modulus Labs, Xinyuan Sun, Martin Koeppelmann et Illia Polosukhin pour leurs commentaires et discussions.
Au fil des années, de nombreuses personnes m'ont posé une question similaire : quels sont les carrefours entre crypto et IA que je considère comme la plus fructueuse ? C'est une question raisonnable : la cryptographie et l'IA sont les deux principales tendances technologiques (logicielles) profondes de la dernière décennie, et on a l'impression que c'est là must être une sorte de lien entre les deux. Il est facile de trouver des synergies à un niveau superficiel : la décentralisation cryptographique peut équilibrer la centralisation de l’IA, L'IA est opaque et la crypto apporte de la transparence, l'IA a besoin de données et les blockchains sont bonnes pour stocker et suivre les données. Mais au fil des années, lorsque les gens me demandaient d'approfondir et de parler d'applications spécifiques, ma réponse était décevante : « oui, il y a quelques choses mais pas tant que ça ».
Au cours des trois dernières années, avec la montée en puissance d’une IA beaucoup plus puissante sous la forme d’appareils modernes LLM, et l'essor d'une cryptographie beaucoup plus puissante sous la forme non seulement de solutions de mise à l'échelle de la blockchain, mais également ZKP, FHE, (bipartite et N-party) MPC, je commence à voir ce changement. Il existe en effet des applications prometteuses de l’IA au sein des écosystèmes blockchain, ou L'IA et la cryptographie, même s’il est important de faire attention à la manière dont l’IA est appliquée. Un défi particulier est le suivant : en cryptographie, l'open source est le seul moyen de sécuriser quelque chose, mais en IA, un modèle (ou même ses données d'entraînement) étant ouvert augmente considérablement sa vulnérabilité à apprentissage automatique contradictoire attaques. Cet article passera en revue une classification des différentes manières dont la crypto + l’IA pourraient se croiser, ainsi que les perspectives et les défis de chaque catégorie.
Les quatre grandes catégories
L'IA est un concept très large : vous pouvez considérer « l'IA » comme étant l'ensemble d'algorithmes que vous créez non pas en les spécifiant explicitement, mais plutôt en remuant une grande soupe informatique et en appliquant une sorte de pression d'optimisation qui pousse la soupe vers produire des algorithmes avec les propriétés que vous souhaitez. Cette description ne doit en aucun cas être prise avec dédain : elle inclut le processus qui créée nous les humains en premier lieu ! Mais cela signifie que les algorithmes d’IA ont certaines propriétés communes : leur capacité à faire des choses extrêmement puissantes, ainsi que des limites dans notre capacité à savoir ou à comprendre ce qui se passe sous le capot.
Il existe de nombreuses façons de catégoriser l’IA ; pour les besoins de cet article, qui parle des interactions entre l'IA et les blockchains (qui ont été décrites comme une plateforme pour créer des « jeux »), je vais le classer comme suit :
- L'IA en tant que joueur dans un jeu [viabilité la plus élevée] : Les IA participent à des mécanismes où la source ultime des incitations provient d'un protocole avec des apports humains.
- L'IA comme interface avec le jeu [à fort potentiel, mais avec des risques] : Les IA aident les utilisateurs à comprendre le monde cryptographique qui les entoure et à garantir que leur comportement (c'est-à-dire les messages et transactions signés) correspond à leurs intentions et qu'ils ne se font pas tromper ou arnaquer.
- L'IA comme règle du jeu [faites très attention] : blockchains, DAO et mécanismes similaires appelant directement les IA. Pensez par exemple. « Juges de l’IA »
- L'IA comme objectif du jeu [à plus long terme mais intrigant] : concevoir des blockchains, des DAO et des mécanismes similaires dans le but de construire et de maintenir une IA qui pourrait être utilisée à d'autres fins, en utilisant les bits cryptographiques soit pour mieux encourager la formation, soit pour empêcher l'IA de divulguer des données privées ou d'être utilisée à mauvais escient.
Passons-les en revue un par un.
L'IA en tant que joueur dans un jeu
Il s’agit en fait d’une catégorie qui existe depuis près d’une décennie, du moins depuis échanges décentralisés en chaîne (DEX) a commencé à voir une utilisation significative. Chaque fois qu’il y a un échange, il existe une opportunité de gagner de l’argent grâce à l’arbitrage, et les robots peuvent faire de l’arbitrage bien mieux que les humains. Ce cas d’usage existe depuis longtemps, même avec des IA bien plus simples que ce que nous avons aujourd’hui, mais il s’agit finalement d’une intersection IA + crypto bien réelle. Plus récemment, nous avons vu des robots d'arbitrage MEV s'exploitant souvent les uns les autres. Chaque fois que vous disposez d’une application blockchain qui implique des enchères ou des échanges, vous aurez des robots d’arbitrage.
Mais les robots d’arbitrage IA ne sont que le premier exemple d’une catégorie beaucoup plus vaste, qui, je l’espère, commencera bientôt à inclure de nombreuses autres applications. Rencontrez AIOmen, un démo d'un marché de prédiction où les IA sont acteurs:
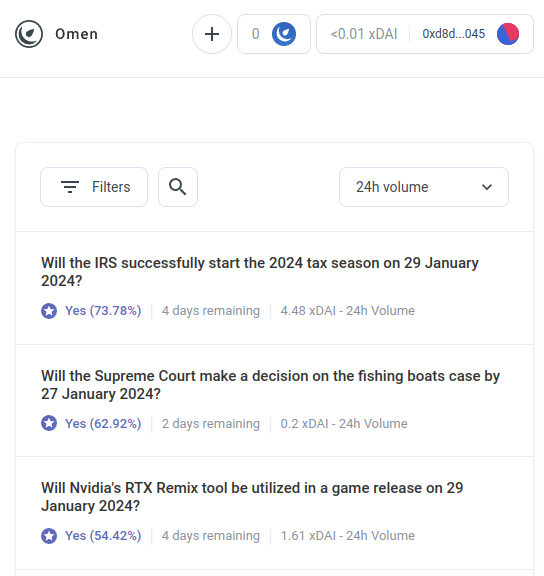
Une réponse à cela est de souligner les améliorations continues de l'UX dans Polymarché ou d'autres nouveaux marchés de prédiction, et j'espère qu'ils réussiront là où les itérations précédentes ont échoué. Après tout, raconte l'histoire, les gens sont prêts à parier des dizaines de milliards pour le sport, alors pourquoi les gens ne dépenseraient-ils pas assez d'argent pour parier sur les élections américaines ou LK99 qu'il commence à avoir du sens pour que les joueurs sérieux commencent à arriver ? Mais cet argument doit être confronté au fait que les itérations précédentes avons n'a pas réussi à atteindre ce niveau d'échelle (du moins par rapport aux rêves de leurs partisans), et il semble donc que vous ayez besoin Quelque chose de nouveau pour faire réussir les marchés de prédiction. Une réponse différente consiste donc à souligner une caractéristique spécifique des écosystèmes de marché de prédiction que nous pouvons nous attendre à voir dans les années 2020 et que nous n’avons pas vue dans les années 2010 : la possibilité d’une participation omniprésente des IA.
Les IA sont prêtes à travailler pour moins d'un dollar de l'heure et possèdent les connaissances d'une encyclopédie. Et si cela ne suffit pas, elles peuvent même être intégrées à une capacité de recherche sur le Web en temps réel. Si vous créez un marché et accordez une subvention de liquidité de 1 $, les humains ne se soucieront pas suffisamment d'enchérir, mais des milliers d'IA se rueront facilement sur la question et feront la meilleure estimation possible. L’incitation à faire du bon travail sur une question donnée est peut-être minime, mais l’incitation à créer une IA capable de faire de bonnes prédictions en général peut-être en millions. Notez que potentiellement, vous n'avez même pas besoin des humains pour trancher la plupart des questions: vous pouvez utiliser un système de litige à plusieurs tours similaire à Augure ou Kleros, où les IA seraient également celles qui participeraient aux tours précédents. Les humains n’auraient besoin de réagir que dans les rares cas où une série d’escalades aurait eu lieu et où d’importantes sommes d’argent auraient été engagées par les deux parties.
Il s’agit d’une primitive puissante, car une fois qu’un « marché de prédiction » peut fonctionner à une échelle aussi microscopique, vous pouvez réutiliser la primitive « marché de prédiction » pour de nombreux autres types de questions :
- Cette publication sur les réseaux sociaux est-elle acceptable selon les [conditions d'utilisation] ?
- Qu'adviendra-t-il du prix de l'action X (par exemple, voir Numerai)
- Ce compte qui m'envoie actuellement des messages est-il réellement Elon Musk ?
- Cette soumission de travail sur un marché de tâches en ligne est-elle acceptable ?
- Le dapp sur https://examplefinance.network est-il une arnaque ?
- Is
0x1b54....98c3en fait l'adresse du token ERC20 « Casinu Inu » ?
Vous remarquerez peut-être que beaucoup de ces idées vont dans le sens de ce que j’appelle «défense de l'information" dans . Au sens large, la question est la suivante : comment pouvons-nous aider les utilisateurs à distinguer les informations vraies des fausses informations et à détecter les escroqueries, sans donner à une autorité centralisée le pouvoir de décider qui pourrait alors abuser de cette position ? Au niveau micro, la réponse peut être « IA ». Mais au niveau macro, la question est : qui construit l’IA ? L’IA est le reflet du processus qui l’a créée et ne peut donc éviter d’avoir des préjugés. Par conséquent, il existe un besoin pour un jeu de niveau supérieur qui évalue les performances des différentes IA, dans lequel les IA peuvent participer en tant que joueurs au jeu..
Cette utilisation de l'IA, où les IA participent à un mécanisme dans lequel elles sont finalement récompensées ou pénalisées (de manière probabiliste) par un mécanisme en chaîne qui rassemble les contributions des humains (appelons cela décentralisé basé sur le marché). RLHF?), c'est quelque chose qui, à mon avis, mérite vraiment d'être étudié. C’est le bon moment pour examiner davantage des cas d’utilisation comme celui-ci, car la mise à l’échelle de la blockchain réussit enfin, rendant tout « micro » enfin viable sur la chaîne alors que ce n’était souvent pas le cas auparavant.
Une catégorie d’applications connexe va dans le sens d’agents hautement autonomes utiliser les blockchains pour mieux coopérer, que ce soit via des paiements ou en utilisant des contrats intelligents pour prendre des engagements crédibles.
L'IA comme interface du jeu
Une idée que j'ai évoquée dans mon écrits sur est l'idée qu'il existe une opportunité de marché pour écrire un logiciel destiné à l'utilisateur qui protégerait les intérêts des utilisateurs en interprétant et en identifiant les dangers dans le monde en ligne dans lequel l'utilisateur navigue. Un exemple déjà existant est la fonctionnalité de détection d'arnaque de Metamask :
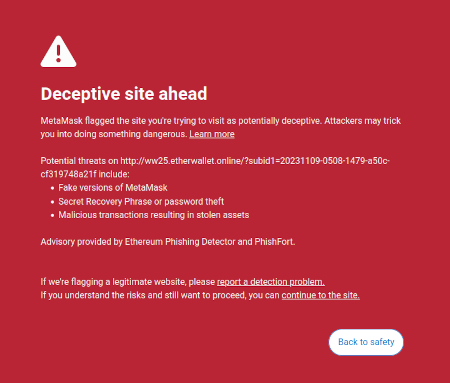
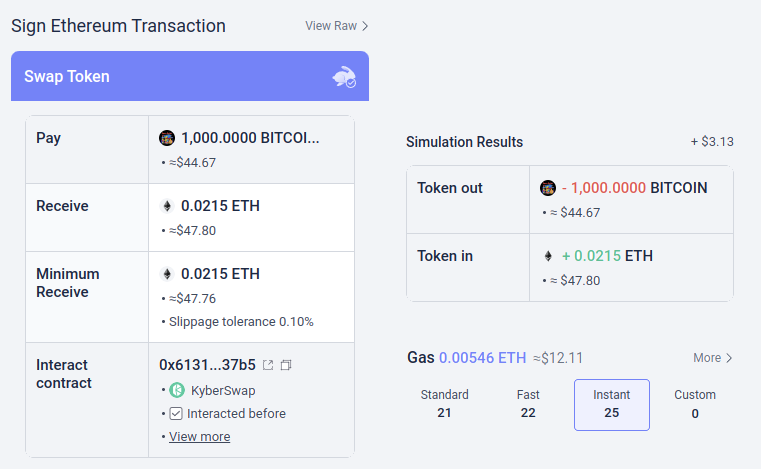
Potentiellement, ces types d’outils pourraient être dotés d’IA. L'IA pourrait donner une explication beaucoup plus riche et conviviale du type de dapp auquel vous participez, des conséquences des opérations plus compliquées auxquelles vous signez, de l'authenticité ou non d'un jeton particulier (par exemple. BITCOIN n'est pas seulement une chaîne de caractères, c'est le nom d'une véritable crypto-monnaie, qui n'est pas un jeton ERC20 et qui a un prix bien supérieur à 0.045 $, et un LLM moderne le saurait), et ainsi de suite. Il y a des projets qui commencent à aller jusqu'au bout dans ce sens (par exemple le Portefeuille LangChain, qui utilise l'IA comme primaire interface). Ma propre opinion est que les interfaces purement IA sont probablement trop risquées pour le moment car elles augmentent le risque de autre types d'erreurs, mais l’IA complétant une interface plus conventionnelle devient très viable.
Il y a un risque particulier qui mérite d’être mentionné. J'y reviendrai plus en détail dans la section « L'IA comme règle du jeu » ci-dessous, mais le problème général est l'apprentissage automatique contradictoire : si un utilisateur a accès à un assistant IA dans un portefeuille open source, les méchants auront également accès à cet assistant IA, et auront ainsi une possibilité illimitée d'optimiser leurs escroqueries pour ne pas se déclencher. les défenses de ce portefeuille. Toutes les IA modernes ont des bugs quelque part, et ce n'est pas trop difficile pour un processus de formation, même avec seulement accès limité au modèle, pour les trouver.
C'est là que « les IA participant aux micro-marchés en chaîne » fonctionnent mieux : chaque IA individuelle est vulnérable aux mêmes risques, mais vous créez intentionnellement un écosystème ouvert de dizaines de personnes qui les itèrent et les améliorent constamment. De plus, chaque IA individuelle est fermée : la sécurité du système vient de l'ouverture des règles du système. jeu, pas le fonctionnement interne de chacun joueur.
Résumé : L'IA peut aider les utilisateurs à comprendre ce qui se passe dans un langage simple, elle peut servir de tuteur en temps réel, elle peut protéger les utilisateurs contre les erreurs, mais soyez averti lorsque vous essayez de l'utiliser directement contre des désinformateurs malveillants et des escrocs.
L'IA comme règle du jeu
Venons-en maintenant à l’application qui passionne beaucoup de gens, mais qui, à mon avis, est la plus risquée et sur laquelle nous devons avancer avec le plus de prudence : ce que j’appelle les IA faisant partie des règles du jeu. Cela est lié à l’enthousiasme des élites politiques dominantes à l’égard des « juges de l’IA » (par exemple, voir cet article sur le site du « World Government Summit »), et il existe des analogues de ces désirs dans les applications blockchain. Si un contrat intelligent basé sur une blockchain ou un DAO doit prendre une décision subjective (par exemple, un produit de travail particulier est-il acceptable dans un contrat de travail contre rémunération ? Quelle est la bonne interprétation d'une constitution en langage naturel comme l'Optimisme Loi des chaînes?), pourriez-vous faire en sorte qu'une IA fasse simplement partie du contrat ou du DAO pour aider à faire appliquer ces règles ?
C'est ici que apprentissage automatique contradictoire va être un défi extrêmement difficile. L’argument de base en deux phrases pourquoi est le suivant :
Si un modèle d'IA qui joue un rôle clé dans un mécanisme est fermé, vous ne pouvez pas vérifier son fonctionnement interne et ce n'est donc pas mieux qu'une application centralisée. Si le modèle d'IA est ouvert, un attaquant peut le télécharger et le simuler localement, et concevoir des attaques fortement optimisées pour tromper le modèle, qu'il peut ensuite rejouer sur le réseau en direct.

Maintenant, les lecteurs fréquents de ce blog (ou les habitants du cryptoverse) sont peut-être déjà en avance sur moi et pensent : mais attendez ! Nous avons des preuves sophistiquées de connaissance zéro et d'autres formes de cryptographie vraiment intéressantes. Nous pouvons sûrement faire de la crypto-magie et cacher le fonctionnement interne du modèle afin que les attaquants ne puissent pas optimiser les attaques, mais en même temps prouver que le modèle est exécuté correctement et a été construit à l'aide d'un processus de formation raisonnable sur un ensemble raisonnable de données sous-jacentes !
Normalement, c'est exactement le type de pensée que je prône à la fois sur ce blog et dans mes autres écrits. Mais dans le cas du calcul lié à l’IA, il y a deux objections majeures :
- Surcharge cryptographique: il est beaucoup moins efficace de faire quelque chose à l'intérieur d'un SNARK (ou MPC ou…) que de le faire « en clair ». Étant donné que l’IA nécessite déjà beaucoup de calculs, est-il même viable sur le plan informatique de faire de l’IA à l’intérieur de boîtes noires cryptographiques ?
- Attaques d’apprentissage automatique contradictoires en boîte noire: il existe des moyens d'optimiser les attaques contre les modèles d'IA même sans savoir grand chose sur le fonctionnement interne du modèle. Et si tu te caches trop, vous risquez de rendre trop facile à celui qui choisit les données d'entraînement de corrompre le modèle avec empoisonnement attaques.
Ces deux cas sont des terriers de lapin compliqués, alors examinons chacun d’eux tour à tour.
Surcharge cryptographique
Les gadgets cryptographiques, en particulier ceux à usage général comme les ZK-SNARK et les MPC, ont une surcharge élevée. Un bloc Ethereum prend quelques centaines de millisecondes à un client pour le vérifier directement, mais générer un ZK-SNARK pour prouver l'exactitude d'un tel bloc peut prendre des heures. La surcharge typique d’autres gadgets cryptographiques, comme MPC, peut être encore pire. Le calcul de l’IA est déjà coûteux : les LLM les plus puissants peuvent produire des mots individuels à peine un peu plus vite que les êtres humains ne peuvent les lire, sans parler des coûts de calcul souvent de plusieurs millions de dollars. Formation Les modèles. La différence de qualité entre les modèles haut de gamme et les modèles qui tentent d'économiser beaucoup plus coût de la formation or nombre de paramètres est large. À première vue, c’est une très bonne raison de se méfier de l’ensemble du projet consistant à tenter d’ajouter des garanties à l’IA en l’enveloppant dans la cryptographie.
Heureusement, cependant, L'IA est un type très spécifique de calcul, ce qui le rend propice à toutes sortes d'optimisations dont les types de calcul plus « non structurés » comme les ZK-EVM ne peuvent pas bénéficier. Examinons la structure de base d'un modèle d'IA :

y = max(x, 0)). Asymptotiquement, les multiplications matricielles occupent la majeure partie du travail : multiplier deux N*N Matrices prend �(�2.8) temps, alors que le nombre d’opérations non linéaires est beaucoup plus petit. C'est vraiment pratique pour la cryptographie, car de nombreuses formes de cryptographie peuvent effectuer des opérations linéaires (ce que sont les multiplications matricielles, du moins si vous chiffrez le modèle mais pas ses entrées) presque « gratuitement »..
Si vous êtes cryptographe, vous avez probablement déjà entendu parler d'un phénomène similaire dans le cadre de cryptage homomorphique: performant ajouts sur les textes chiffrés est vraiment simple, mais multiplications sont incroyablement difficiles et nous n'avons trouvé aucun moyen de le faire avec une profondeur illimitée jusqu'en 2009.
Pour les ZK-SNARK, l'équivalent est des protocoles comme celui-ci de 2013, qui montrent un moins de 4x surcharge sur la preuve des multiplications matricielles. Malheureusement, la surcharge sur les couches non linéaires finit toujours par être importante, et les meilleures implémentations en pratique affichent une surcharge d'environ 200x. Mais on espère que cela pourra être considérablement réduit grâce à des recherches plus approfondies ; voir cette présentation de Ryan Cao pour une approche récente basée sur GKR, et la mienne explication simplifiée du fonctionnement du composant principal de GKR.
Mais pour de nombreuses applications, nous ne souhaitons pas seulement prouver qu'une sortie AI a été calculée correctement, nous voulons également cacher le modèle. Il existe des approches naïves à ce sujet : vous pouvez diviser le modèle de manière à ce qu'un ensemble différent de serveurs stocke chaque couche de manière redondante, et espérer que certains des serveurs qui fuient certaines couches ne divulguent pas trop de données. Mais il existe aussi des formes étonnamment efficaces de calcul multipartite spécialisé.
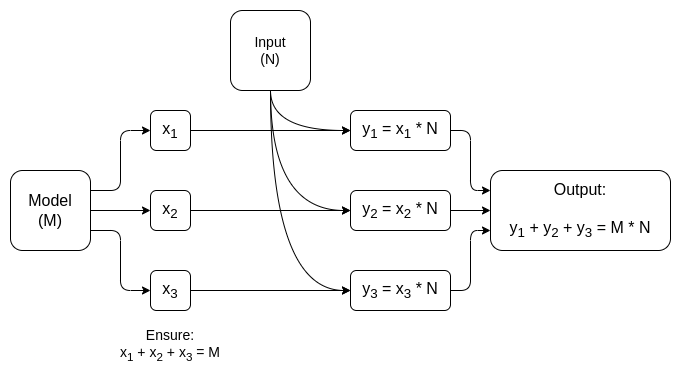
Dans les deux cas, la morale de l’histoire est la même : la plus grande partie d'un calcul d'IA est constituée de multiplications matricielles, pour lesquelles il est possible de faire très efficace ZK-SNARK ou MPC (ou même FHE), et donc la surcharge totale liée à l'insertion de l'IA dans des boîtes cryptographiques est étonnamment faible.. Généralement, ce sont les couches non linéaires qui constituent le plus grand goulot d'étranglement malgré leur plus petite taille ; peut-être des techniques plus récentes comme arguments de recherche peut aider.
Apprentissage automatique contradictoire en boîte noire
Passons maintenant à l'autre gros problème : les types d'attaques que vous pouvez effectuer même si le contenu du modèle reste privé et vous n’avez qu’un « accès API » au modèle. Citant un papier de 2016:
De nombreux modèles d'apprentissage automatique sont vulnérables aux exemples contradictoires : des entrées spécialement conçues pour amener un modèle d'apprentissage automatique à produire une sortie incorrecte. Les exemples contradictoires qui affectent un modèle affectent souvent un autre modèle, même si les deux modèles ont des architectures différentes ou ont été formés sur des ensembles de formation différents, à condition que les deux modèles aient été formés pour effectuer la même tâche.. Un attaquant peut donc entraîner son propre modèle de remplacement, créer des exemples contradictoires contre le substitut et les transférer vers un modèle de victime, avec très peu d'informations sur la victime.
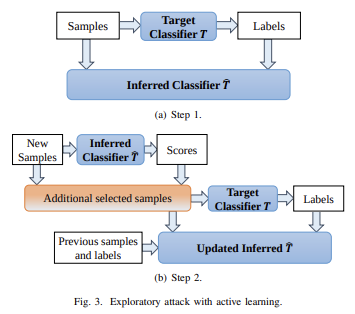
Potentiellement, vous pouvez même créer des attaques en sachant juste les données d'entraînement, même si vous avez un accès très limité, voire inexistant, au modèle que vous essayez d'attaquer. Depuis 2023, ce type d’attaques reste un problème majeur.
Pour limiter efficacement ce type d’attaques par boîte noire, nous devons faire deux choses :
- Vraiment limiter qui ou quoi peut interroger le modèle et combien. Les boîtes noires avec un accès illimité aux API ne sont pas sécurisées ; des boîtes noires avec un accès API très restreint peuvent l'être.
- Masquer les données d'entraînement, tout en préservant la confiance que le processus utilisé pour créer les données de formation n'est pas corrompu.
Le projet qui a le plus fait sur le premier est peut-être Worldcoin, dont j'analyse longuement une version antérieure (entre autres protocoles) ici. Worldcoin utilise largement des modèles d'IA au niveau du protocole, pour (i) convertir les scans d'iris en courts « codes d'iris » faciles à comparer pour leur similarité, et (ii) vérifier que la chose qu'il scanne est bien un être humain. La principale défense sur laquelle Worldcoin s'appuie est le fait que il ne s'agit pas de laisser quiconque simplement appeler le modèle IA : il utilise plutôt un matériel fiable pour garantir que le modèle n'accepte que les entrées signées numériquement par la caméra de l'orbe..
Cette approche n'est pas garantie de fonctionner : il s'avère que vous pouvez lancer des attaques contradictoires contre l'IA biométrique qui se présentent sous la forme de des patchs physiques ou des bijoux que vous pouvez mettre sur votre visage:

Mais l'espoir est que si vous combiner toutes les défenses ensemble, cachant le modèle d'IA lui-même, limitant considérablement le nombre de requêtes et exigeant que chaque requête soit authentifiée d'une manière ou d'une autre, vous pouvez lancer des attaques contradictoires suffisamment difficiles pour que le système puisse être sécurisé.
Et cela nous amène à la deuxième partie : comment pouvons-nous masquer les données d’entraînement ? C'est ici que « Des DAO pour gouverner démocratiquement l’IA » pourraient en fait avoir du sens: nous pouvons créer un DAO en chaîne qui régit le processus permettant de savoir qui est autorisé à soumettre des données de formation (et quelles attestations sont requises sur les données elles-mêmes), qui est autorisé à effectuer des requêtes, et combien, et à utiliser des techniques cryptographiques comme MPC. pour chiffrer l'intégralité du pipeline de création et d'exécution de l'IA, depuis l'entrée de formation de chaque utilisateur jusqu'à la sortie finale de chaque requête. Ce DAO pourrait simultanément satisfaire l’objectif très populaire de rémunérer les personnes qui soumettent des données.
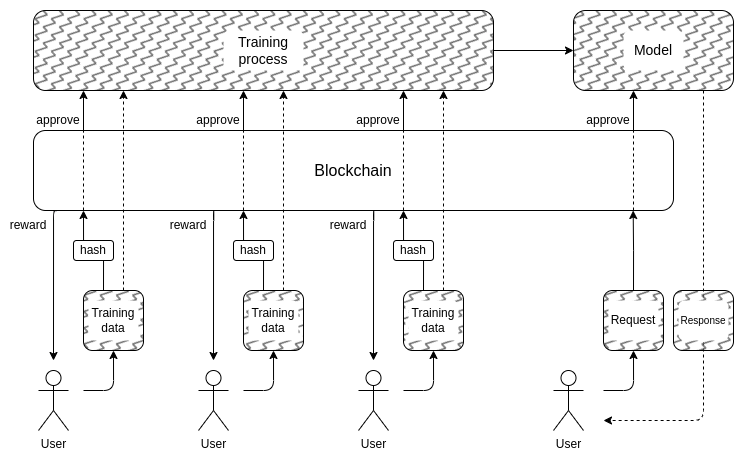
- La surcharge cryptographique pourrait encore s’avérer trop élevée pour que ce type d’architecture entièrement noire soit compétitif par rapport aux approches fermées traditionnelles « faites-moi confiance ».
- Il se pourrait que il n'existe pas de bon moyen de décentraliser le processus de soumission des données de formation ainsi que protégé contre les attaques d'empoisonnement.
- Les gadgets informatiques multipartites pourraient tomber en panne leurs garanties de sécurité ou de confidentialité en raison de participants en collusion: après tout, cela s'est produit avec les ponts de crypto-monnaie inter-chaînes encore ainsi que encore.
L’une des raisons pour lesquelles je n’ai pas commencé cette section avec d’autres grandes étiquettes d’avertissement rouges disant « NE FAITES PAS DE JUGES D’IA, C’EST DYSTOPIEN », est que notre société est déjà fortement dépendante de juges d’IA centralisés et irresponsables : les algorithmes qui déterminent quels types d’IA sont jugés. les publications et les opinions politiques sont renforcées et déboostées, voire censurées, sur les réseaux sociaux. Je pense qu'élargir cette tendance plus à ce stade, c'est une très mauvaise idée, mais je ne pense pas qu'il y ait une grande chance que cela la communauté blockchain expérimente davantage les IA sera ce qui contribuera à aggraver la situation.
En fait, il existe des moyens assez basiques et à faible risque par lesquels la technologie de cryptographie peut améliorer même ces systèmes centralisés existants et dans lesquels je suis assez confiant. Une technique simple consiste à IA vérifiée avec publication retardée: lorsqu'un site de réseau social effectue un classement des publications basé sur l'IA, il peut publier un ZK-SNARK prouvant le hachage du modèle qui a généré ce classement. Le site pourrait s'engager à révéler ses modèles d'IA après, par exemple. un délai d'un an. Une fois qu'un modèle est révélé, les utilisateurs peuvent vérifier le hachage pour vérifier que le bon modèle a été publié, et la communauté peut effectuer des tests sur le modèle pour vérifier son équité. Le retard de publication garantirait qu’au moment où le modèle est révélé, il est déjà obsolète.
Alors par rapport à la centralisée monde, la question n'est pas if nous pouvons faire mieux, mais de combien. Pour l' monde décentralisé, il est cependant important d'être prudent : si quelqu'un construit par exemple. un marché de prédiction ou un stablecoin qui utilise un oracle IA, et il s'avère que l'oracle est attaquable, c'est une énorme somme d'argent qui pourrait disparaître en un instant.
L'IA comme objectif du jeu
Si les techniques ci-dessus pour créer une IA privée décentralisée et évolutive, dont le contenu est une boîte noire inconnue de tous, peuvent réellement fonctionner, elles pourraient également être utilisées pour créer des IA dont l’utilité va au-delà des blockchains. L'équipe du protocole NEAR en fait un objectif principal de leur travail en cours.
Il y a deux raisons de le faire :
- Si vous vous faire "des IA de type boîte noire dignes de confiance"En exécutant le processus de formation et d'inférence en utilisant une combinaison de blockchains et de MPC, de nombreuses applications où les utilisateurs craignent que le système ne soit biaisé ou les trompe pourraient en bénéficier. De nombreuses personnes ont exprimé le désir de la gouvernance démocratique des IA d’importance systémique dont nous dépendrons; les techniques cryptographiques et basées sur la blockchain pourraient être une voie à suivre pour y parvenir.
- D'un Sécurité de l'IA De ce point de vue, il s’agirait d’une technique permettant de créer une IA décentralisée dotée également d’un kill switch naturel et qui pourrait limiter les requêtes cherchant à utiliser l’IA à des fins malveillantes.
Il convient également de noter que « l’utilisation d’incitations cryptographiques pour encourager une meilleure IA » peut être réalisée sans avoir à recourir à la cryptographie pour la chiffrer complètement : des approches telles que Tenseur de bits tombent dans cette catégorie.
Conclusions
Maintenant que les blockchains et les IA deviennent plus puissantes, il existe un nombre croissant de cas d’utilisation à l’intersection des deux domaines. Cependant, certains de ces cas d’utilisation ont beaucoup plus de sens et sont bien plus robustes que d’autres. En général, les cas d'utilisation dans lesquels le mécanisme sous-jacent continue d'être conçu à peu près comme avant, mais où l'individu joueurs devenir des IA, permettant au mécanisme de fonctionner efficacement à une échelle beaucoup plus micro, sont les plus immédiatement prometteuses et les plus faciles à mettre en œuvre.
Les plus difficiles à mettre en œuvre sont les applications qui tentent d’utiliser des chaînes de blocs et des techniques cryptographiques pour créer un « singleton » : une seule IA de confiance décentralisée sur laquelle certaines applications s’appuieraient dans un certain but. Ces applications sont prometteuses, tant en termes de fonctionnalité que d’amélioration de la sécurité de l’IA de manière à éviter les risques de centralisation associés aux approches plus traditionnelles de ce problème. Mais les hypothèses sous-jacentes pourraient également échouer de nombreuses manières ; il convient donc d’y aller avec prudence, en particulier lors du déploiement de ces applications dans des contextes à forte valeur ajoutée et à haut risque.
J’attends avec impatience de voir davantage de tentatives de cas d’utilisation constructive de l’IA dans tous ces domaines, afin que nous puissions voir lesquels d’entre eux sont vraiment viables à grande échelle.
Auteur : Vitalik Buterin
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: Intelligence de données Platon.

