Introduction
Cet article présentera le concept de modélisation des données, un processus crucial qui décrit comment les données sont stockées, organisées et accessibles au sein d'une base de données ou d'un système de données. Cela implique de convertir les besoins commerciaux réels en un format logique et structuré pouvant être réalisé dans une base de données ou un entrepôt de données. Nous explorerons comment la modélisation des données crée un cadre conceptuel pour comprendre les relations et les interconnexions des données au sein d'une organisation ou d'un domaine spécifique. De plus, nous discuterons de l'importance de concevoir des structures et des relations de données pour garantir un stockage, une récupération et une manipulation efficaces des données.

Cas d'utilisation de la modélisation des données
La modélisation des données est fondamentale pour gérer et utiliser efficacement les données dans divers scénarios. Voici quelques cas d’utilisation typiques de la modélisation de données, chacun expliqué en détail :
Acquisition de données
Dans la modélisation des données, l'acquisition de données implique de définir la manière dont les données sont collectées ou générées à partir de diverses sources. Cette phase comprend l'établissement de la structure de données nécessaire pour contenir les données entrantes, garantissant qu'elles peuvent être intégrées et stockées efficacement. En modélisant les données à ce stade, les organisations peuvent garantir que les données collectées sont structurées pour s'aligner sur leurs besoins analytiques et leurs processus métier. Il permet d'identifier le type de données nécessaires, le format dans lequel elles doivent être et la manière dont elles seront traitées pour une utilisation ultérieure.
Chargement des données
Une fois les données acquises, elles doivent être chargées dans le système cible, tel qu'une base de données, entrepôt de données, ou lac de données. La modélisation des données joue ici un rôle crucial en définissant le schéma ou la structure dans laquelle les données seront insérées. Cela inclut la spécification de la manière dont les données provenant de différentes sources seront mappées aux tables et colonnes de la base de données et la configuration des relations entre les différentes entités de données. Une modélisation appropriée des données garantit que les données sont chargées de manière optimale, facilitant ainsi l'efficacité du stockage, de l'accès et des performances des requêtes.
Calcul d'entreprise
La modélisation des données fait partie intégrante de la mise en place des cadres de calculs commerciaux. Ces calculs génèrent des informations, des mesures et des indicateurs de performance clés (KPI) à partir des données stockées. En établissant un modèle de données clair, les organisations peuvent définir comment les données provenant de diverses sources peuvent être agrégées, transformées et analysées pour effectuer des calculs commerciaux complexes. Cela garantit que les données sous-jacentes soutiennent la dérivation de données significatives et précises. l'intelligence d'entreprise, qui peut guider la prise de décision et la planification stratégique.
Distribution
La phase de distribution met les données traitées à la disposition des utilisateurs finaux ou d'autres systèmes à des fins d'analyse, de reporting et de prise de décision. À ce stade, la modélisation des données vise à garantir que les données sont structurées et formatées de manière à ce qu'elles soient accessibles et compréhensibles pour le public visé. Cela pourrait impliquer la modélisation des données dans des schémas dimensionnels à utiliser dans des outils de business intelligence, la création d'API pour l'accès par programmation ou la définition de formats d'exportation pour le partage de données. Une modélisation efficace des données garantit que les données peuvent être facilement distribuées et consommées sur différentes plates-formes et par diverses parties prenantes, améliorant ainsi leur utilité et leur valeur.
Chacun de ces cas d'utilisation illustre l'importance de l'ensemble du cycle de vie des données, de la collecte et du stockage à l'analyse et à la distribution. En concevant soigneusement les structures et les relations de données à chaque étape, les organisations peuvent garantir que leur architecture de données répond de manière efficace et efficiente à leurs besoins opérationnels et analytiques.
Ingénieurs/modélisateurs de données
Ingénieurs de données et les modélisateurs de données jouent un rôle central dans la gestion et l'analyse des données, chacun apportant des compétences et une expertise uniques pour exploiter la puissance des données au sein d'une organisation. Comprendre les rôles et responsabilités de chacun peut aider à clarifier la manière dont ils travaillent ensemble pour construire et maintenir des infrastructures de données robustes.
Ingénieurs de données
Les ingénieurs de données sont responsables de la conception, de la construction et de la maintenance des systèmes et des architectures qui permettent une gestion efficace et l'accessibilité des données. Leur rôle implique souvent :
- Création et maintenance de pipelines de données : Ils créent l'infrastructure pour extraire, transformer et charger des données (ETL) à partir de diverses sources.
- Stockage et gestion des données : Ils conçoivent et mettent en œuvre des systèmes de bases de données, des lacs de données et d'autres solutions de stockage pour garder les données organisées et accessibles.
- Optimisation des performances: Les ingénieurs de données veillent à ce que les processus de données fonctionnent efficacement, souvent en optimisant le stockage des données et l'exécution des requêtes.
- Collaboration avec les parties prenantes : Ils travaillent en étroite collaboration avec des analystes commerciaux, des data scientists et d'autres utilisateurs pour comprendre les besoins en données et mettre en œuvre des solutions qui permettent une prise de décision basée sur les données.
- Assurer la qualité et l’intégrité des données : Ils mettent en œuvre des systèmes et des processus pour surveiller, valider et nettoyer les données, garantissant ainsi que les utilisateurs ont accès à des informations fiables et précises.
Modélisateurs de données
Les modélisateurs de données se concentrent sur la conception du plan pour systèmes de gestion de données. Leur travail consiste à comprendre les exigences de l'entreprise et à les traduire en structures de données qui prennent en charge un stockage, une récupération et une analyse efficaces des données. Les principales responsabilités comprennent :
- Développer des modèles de données conceptuels, logiques et physiques : Ils créent des modèles qui définissent la manière dont les données sont liées et comment elles seront stockées dans les bases de données.
- Définition des entités de données et des relations : Les modélisateurs de données identifient les entités clés que le système de données d'une organisation doit représenter et définissent la manière dont ces entités sont liées les unes aux autres.
- Assurer la cohérence et la standardisation des données : Ils établissent des conventions de dénomination et des normes pour les éléments de données afin de garantir la cohérence dans l'ensemble de l'organisation.
- Collaboration avec les ingénieurs et architectes de données : Les modélisateurs de données travaillent en étroite collaboration avec les ingénieurs de données pour garantir que l'architecture de données prend en charge efficacement les modèles conçus.
- Gouvernance et stratégie des données : Ils jouent souvent un rôle dans la gouvernance des données, en aidant à définir des politiques et des normes de gestion des données au sein de l'organisation.
Bien qu'il existe un certain chevauchement dans les compétences et les tâches des Data Engineers et des Data Modelers, les deux rôles se complètent. Les ingénieurs de données se concentrent sur la création et la maintenance de l'infrastructure qui prend en charge le stockage et l'accès aux données, tandis que les modélisateurs de données conçoivent la structure et l'organisation des données au sein de ces systèmes. Ils garantissent que l'architecture de données d'une organisation est robuste, évolutive et alignée sur les objectifs commerciaux, permettant ainsi une prise de décision efficace basée sur les données.
Composants clés de la modélisation des données
La modélisation des données est un processus critique dans la conception et la mise en œuvre de bases de données et de systèmes de données efficaces, évolutifs et capables de répondre aux exigences de diverses applications. Les composants clés incluent les entités, les attributs, les relations et les clés. Comprendre ces composants est essentiel pour créer un modèle de données cohérent et fonctionnel.
Entités
Une entité représente un objet ou un concept du monde réel qui peut être clairement identifié. Dans une base de données, une entité se traduit souvent par une table. Les entités sont utilisées pour catégoriser les informations que nous souhaitons stocker. Par exemple, dans un système de gestion de la relation client (CRM), les entités typiques peuvent inclure « Client », « Commande » et Product.
Attributs
Les attributs sont les propriétés ou les caractéristiques d'une entité. Ils fournissent des détails sur l’entité, aidant ainsi à la décrire plus complètement. Dans une table de base de données, les attributs représentent les colonnes. Pour l'entité « Client », les attributs peuvent inclure « CustomerID », « Nom », « Adresse », « Numéro de téléphone », etc. Les attributs définissent le type de données (tel qu'un entier, une chaîne, une date, etc.) stocké pour chaque entité. exemple.
Les relations
Les relations décrivent comment les entités d'un système sont connectées les unes aux autres, représentant leurs interactions. Il existe plusieurs types de relations :
- En tête-à-tête (1:1) : Chaque instance de l'Entité A est liée à une et une seule instance de l'Entité B, et vice versa.
- Un à plusieurs (1:N) : Chaque instance de l'entité A peut être associée à zéro, une ou plusieurs instances de l'entité B, mais chaque instance de l'entité B n'est liée qu'à une seule instance de l'entité A.
- Plusieurs à plusieurs (M:N) : Chaque instance de l'entité A peut être associée à zéro, une ou plusieurs instances de l'entité B, et chaque instance de l'entité B peut être associée à zéro, une ou plusieurs instances de l'entité A.
Les relations sont cruciales pour relier les données stockées dans différentes entités, facilitant ainsi la récupération des données et la création de rapports sur plusieurs tables.
Clés / Key
Les clés sont des attributs spécifiques utilisés pour identifier de manière unique les enregistrements dans une table et établir des relations entre les tables. Il existe plusieurs types de clés :
- Clé primaire: Une colonne, ou un ensemble de colonnes, identifie de manière unique chaque enregistrement de table. Deux enregistrements ne peuvent pas avoir la même valeur de clé primaire dans une table.
- Clé étrangère: Colonne, ou ensemble de colonnes, dans une table qui fait référence à la clé primaire d'une autre table. Les clés étrangères sont utilisées pour établir et appliquer des relations entre les tables.
- Clé composée : Combinaison de deux colonnes ou plus dans une table qui peut être utilisée pour identifier chaque enregistrement de la table de manière unique.
- Clé du candidat : Toute colonne ou ensemble de colonnes pouvant être considérée comme une clé primaire dans la table.
Comprendre et mettre en œuvre correctement ces composants clés est fondamental pour créer des systèmes efficaces de stockage, de récupération et de gestion des données. Une modélisation appropriée des données conduit à des bases de données bien organisées et optimisées en termes de performances et d'évolutivité, répondant aux besoins des développeurs et des utilisateurs finaux.
Phases des modèles de données
La modélisation des données se déroule généralement en trois phases principales : le modèle de données conceptuel, le modèle de données logique et le modèle de données physique. Chaque phase répond à un objectif spécifique et s'appuie sur la précédente pour transformer progressivement des idées abstraites en une conception concrète de base de données. Comprendre ces phases est crucial pour quiconque crée ou gère des systèmes de données.
Modèle de données conceptuel
Le modèle conceptuel de données est le niveau le plus abstrait de modélisation de données. Cette phase se concentre sur la définition des entités de haut niveau et des relations entre elles sans entrer dans les détails de la manière dont les données seront stockées. L'objectif principal est de décrire les principaux objets de données pertinents pour le domaine métier et leurs interactions d'une manière que les parties prenantes non techniques comprennent. Ce modèle est souvent utilisé pour la planification et la communication initiales, reliant les exigences commerciales et la mise en œuvre technique.
Les caractéristiques clés incluent
- Identification des entités importantes et de leurs relations.
- Haut niveau, utilisant souvent la terminologie commerciale.
- Indépendant de tout système de gestion de base de données (SGBD) ou technologie.
Modèle de données logique
Le modèle logique de données ajoute plus de détails au modèle conceptuel, en spécifiant la structure des éléments de données et en définissant les relations entre eux. Il comprend la définition des entités, les attributs de chaque entité, les clés primaires et les clés étrangères. Cependant, cela reste indépendant de la technologie qui sera utilisée pour sa mise en œuvre. Le modèle logique est plus détaillé et structuré que le modèle conceptuel et commence à introduire des règles et des contraintes qui régissent les données.
Les caractéristiques clés incluent
- Définition détaillée des entités, des relations et des attributs.
- L'inclusion de clés primaires et de clés étrangères est nécessaire pour établir des relations.
- Des processus de normalisation sont appliqués pour garantir l’intégrité des données et réduire la redondance.
- Toujours indépendant de la technologie SGBD spécifique.
Modèle de données physique
Le modèle physique de données est la phase la plus détaillée et implique la mise en œuvre du modèle de données au sein d'un système de gestion de base de données spécifique. Ce modèle traduit le modèle logique de données en un schéma détaillé qui peut être implémenté dans une base de données. Il comprend tous les détails nécessaires à la mise en œuvre, tels que les tables, les colonnes, les types de données, les contraintes, les index, les déclencheurs et d'autres fonctionnalités spécifiques à la base de données.
Les principales caractéristiques comprennent
- Spécifique à un SGBD particulier et inclut une optimisation spécifique à la base de données.
- Spécifications détaillées des tables, colonnes, types de données et contraintes.
- Prise en compte des options de stockage physique, des stratégies d'indexation et de l'optimisation des performances.
La transition à travers ces phases permet la planification et la conception méticuleuses d'un système de données aligné sur les exigences de l'entreprise et optimisé pour les performances dans un environnement technique spécifique. Le modèle conceptuel garantit que la structure globale s'aligne sur les objectifs commerciaux, le modèle logique comble le fossé entre la planification conceptuelle et la mise en œuvre physique, et le modèle physique garantit que la base de données est optimisée pour une utilisation réelle.
Exemple d'ensemble de données scolaires
Entités : étudiants, enseignants et classes.
Modèle de données conceptuel
Ce modèle de données conceptuel décrit un système de base de données pour la gestion des dossiers scolaires, comprenant trois entités principales : l'élève, l'enseignant et la classe. Dans ce modèle, les étudiants peuvent être associés à plusieurs enseignants et classes, tandis que les enseignants peuvent instruire plusieurs étudiants et diriger diverses classes. Chaque classe accueille de nombreux élèves mais est dispensée par un seul professeur. La conception vise à simplifier la compréhension des relations entre les entités pour les parties prenantes techniques et non techniques, en fournissant un aperçu clair et intuitif de la structure du système. Commencer par un modèle conceptuel permet l’intégration progressive d’éléments plus détaillés, établissant ainsi une base solide pour le développement de modèles de bases de données sophistiqués.
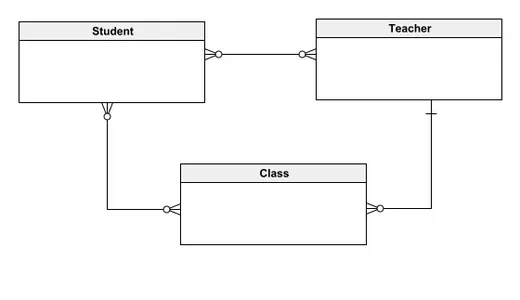
Modèle de données logique
Le modèle de données logique, très apprécié pour son équilibre entre clarté et détail, intègre des entités, des relations, des attributs, des CLÉS PRIMAIRES et des CLÉS ÉTRANGÈRES. Il décrit méticuleusement la progression logique des données au sein d'une base de données, clarifiant les spécificités granulaires telles que sa composition ou les types de données utilisés. Le modèle de données logique fournit une base suffisante pour que le développement de logiciels puisse commencer la construction proprement dite de la base de données.
En partant du modèle de données conceptuel évoqué précédemment, examinons un modèle de données logique typique. Contrairement à son prédécesseur conceptuel, ce modèle est enrichi d'attributs et de clés primaires. Par exemple, l'entité Student se distingue par un StudentID comme clé primaire et identifiant unique, ainsi que par d'autres attributs essentiels tels que le nom et l'âge.
Cette approche est appliquée de manière cohérente à d'autres entités, telles que l'enseignant et la classe, en préservant les relations établies dans le modèle conceptuel tout en améliorant le modèle avec un schéma détaillé comprenant des attributs et des identifiants clés.
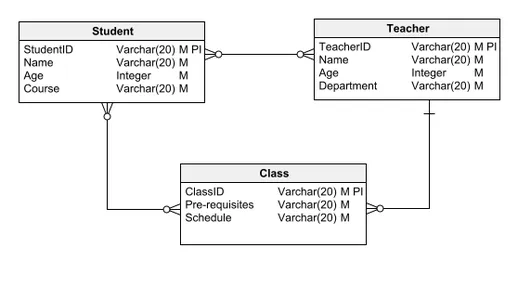
Modèle de données physique
Le modèle de données physique est le plus détaillé parmi les niveaux d'abstraction, intégrant des spécificités adaptées au système de gestion de base de données choisi, tel que PostgreSQL, Oracle ou MySQL. Dans ce modèle, les entités sont traduites en tables et les attributs deviennent des colonnes, reflétant la structure d'une base de données réelle. Chaque colonne se voit attribuer un type de données spécifique, par exemple INT pour les entiers, VARCHAR pour les chaînes de caractères variables ou DATE pour les dates.
Compte tenu de sa nature détaillée, le modèle de données physique approfondit les aspects techniques propres à la plateforme de base de données utilisée. Ces aspects englobants dépassent le cadre d’une vue d’ensemble de haut niveau. Cela inclut des considérations telles que l'allocation de stockage, les stratégies d'indexation et les contraintes de mise en œuvre, qui sont cruciales pour les performances et l'intégrité de la base de données, mais qui sont généralement trop granulaires pour une discussion préliminaire.

Phases de modélisation des données
- Comprendre les exigences de l'entreprise : Participez à des discussions détaillées avec les parties prenantes pour comprendre l’objectif commercial de la base de données. Les principales considérations incluent l’identification du domaine d’activité, des besoins en stockage de données et des problèmes que la base de données vise à résoudre. Concentrez-vous sur l’alignement de la conception de la base de données sur les objectifs commerciaux en matière de performances, de coûts et de sécurité.
- La collaboration d'équipe: Travailler en étroite collaboration avec d'autres équipes (par exemple, les concepteurs et développeurs UX/UI) pour garantir que la base de données prend en charge la solution plus large. Adaptez les formats et les types de données pour répondre aux exigences des applications, en mettant l'accent sur les compétences en matière de conception collaborative et de communication.
- Tirer parti des normes de l’industrie : Recherchez les modèles et les normes existants pour éviter de repartir de zéro. Utilisez les meilleures pratiques du secteur pour économiser du temps et des ressources, en concentrant vos efforts sur les aspects de votre base de données qui la différencient des modèles existants.
- Commencez la modélisation de la base de données : Avec une solide compréhension des besoins de l'entreprise, des contributions de l'équipe et des normes de l'industrie, commencez par la modélisation conceptuelle, passez à la logique et finalisez avec le modèle physique. Cette approche structurée garantit une compréhension complète des entités, attributs et relations requis, facilitant ainsi une mise en œuvre fluide de la base de données alignée sur les objectifs commerciaux.
Les outils de modélisation de données sont essentiels pour concevoir, maintenir et faire évoluer les structures de données organisationnelles. Ces outils offrent une gamme de fonctionnalités pour prendre en charge l’ensemble du cycle de vie de conception et de gestion des bases de données. Les principales fonctionnalités à rechercher dans les outils de modélisation de données incluent :
- Créer des modèles de données : Facilitez la création de modèles de données conceptuels, logiques et physiques, permettant une définition claire des entités, des attributs et des relations. Cette fonctionnalité de base prend en charge la conception initiale et continue de l'architecture de base de données.
- Collaboration et référentiel central : Permettez aux membres de l’équipe de collaborer à la conception et aux modifications du modèle de données. Un référentiel central garantit que les dernières versions sont accessibles à toutes les parties prenantes, favorisant ainsi la cohérence et l'efficacité du développement.
- Ingénierie inverse: Offre la possibilité d'importer des scripts SQL ou de se connecter à des bases de données existantes pour générer des modèles de données. Ceci est particulièrement utile pour comprendre et documenter les systèmes existants ou pour intégrer des bases de données existantes.
- Ingénierie avancée : Permet de générer des scripts SQL ou du code à partir du modèle de données. Cette fonctionnalité rationalise la mise en œuvre des modifications dans la structure de la base de données, garantissant que la base de données physique reflète le dernier modèle.
- Prise en charge de différents types de bases de données : Offrez une compatibilité avec plusieurs systèmes de gestion de bases de données (SGBD), tels que MySQL, PostgreSQL, Oracle, SQL Server, etc. Cette flexibilité garantit que l'outil peut être utilisé dans différents projets et environnements technologiques.
- Contrôle de version: Incluez ou intégrez des systèmes de contrôle de version pour suivre les modifications apportées aux modèles de données au fil du temps. Cette fonctionnalité est cruciale pour gérer les itérations de la structure de la base de données et faciliter le retour aux versions précédentes si nécessaire.
- Exportation de diagrammes dans différents formats : Permettez aux utilisateurs d'exporter des modèles de données et des diagrammes dans différents formats (par exemple PDF, PNG, XML), facilitant ainsi le partage et la documentation. Cela garantit que les parties prenantes non techniques peuvent également examiner et comprendre l’architecture des données.
Le choix d'un outil de modélisation de données doté de ces fonctionnalités peut améliorer considérablement l'efficacité, la précision et la collaboration des efforts de gestion des données au sein d'une organisation, garantissant que les bases de données sont bien conçues, à jour et alignées sur les besoins de l'entreprise.
ER / Studio

Offre des capacités de modélisation et des fonctionnalités de collaboration complètes et prend en charge diverses plates-formes de bases de données.
Architecte de données IBM InfoSphere

Fournit un environnement robuste pour la conception et la gestion de modèles de données avec prise en charge de l'intégration et de la synchronisation avec d'autres produits IBM.
Lien IBM InfoSphere Data Architect
Modélisateur de données Oracle SQL Developer

Un outil gratuit qui prend en charge l'ingénierie directe et inverse, le contrôle de version et la prise en charge de plusieurs bases de données.
Lien vers le modélisateur de données Oracle SQL Developer
PowerDesigner (SAP)

Offre des fonctionnalités de modélisation étendues, notamment la prise en charge des données, des informations et de l'architecture d'entreprise.
Modélisateur de données Navicat
Connu pour son interface conviviale et sa prise en charge d'un large éventail de bases de données, il permet l'ingénierie directe et inverse.
Lien vers le modélisateur de données Navicat
Ces outils rationalisent le processus de modélisation des données, améliorent la collaboration en équipe et garantissent la compatibilité entre les différents systèmes de bases de données.
A lire également: Questions d'entretien sur la modélisation des données
Conclusion
Cet article s'est penché sur la pratique essentielle de la modélisation des données, soulignant son rôle essentiel dans l'organisation, le stockage et l'accès aux données au sein des bases de données et des systèmes de données. En décomposant le processus en modèles conceptuels, logiques et physiques, nous avons illustré comment la modélisation des données traduit les besoins de l'entreprise en cadres de données structurés, facilitant ainsi une gestion efficace des données et une analyse approfondie.
Les principaux points à retenir incluent l'importance de comprendre les exigences de l'entreprise, la nature collaborative de la conception de bases de données impliquant diverses parties prenantes et l'utilisation stratégique d'outils de modélisation de données pour rationaliser le processus de développement. La modélisation des données garantit que les structures de données sont optimisées pour les besoins actuels et offrent une évolutivité pour la croissance future.
La modélisation des données est au cœur d'une gestion efficace des données, permettant aux organisations d'exploiter leurs données pour la prise de décision stratégique et l'efficacité opérationnelle.
Foire aux Questions
Rép. La modélisation des données représente visuellement les données d'un système, décrivant comment elles sont stockées, organisées et accessibles. Il est crucial pour traduire les exigences de l'entreprise dans un format de base de données structuré, permettant une utilisation efficace des données.
Rép. Les principaux cas d'utilisation incluent l'acquisition, le chargement, les calculs commerciaux et la distribution de données, garantissant ainsi que les données sont collectées, stockées et utilisées efficacement pour obtenir des informations commerciales.
Rép. Les ingénieurs de données construisent et maintiennent l'infrastructure de données, tandis que les modélisateurs de données conçoivent la structure et l'organisation des données pour soutenir les objectifs commerciaux et l'intégrité des données.
Rép. Le processus passe de la compréhension des exigences commerciales à la collaboration avec les équipes, en tirant parti des normes de l'industrie et en modélisant la base de données à travers des phases conceptuelles, logiques et physiques.
Rép. Ces outils facilitent la conception, la collaboration et l'évolution des modèles de données, prenant en charge différents types de bases de données et permettant l'ingénierie inverse et directe pour une gestion efficace des bases de données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

