Les données sont votre différenciateur d'IA générative et un succès IA générative la mise en œuvre dépend d’une stratégie de données robuste intégrant une gouvernance des données approche. Travailler avec des modèles de langage étendus (LLM) pour les cas d'utilisation en entreprise nécessite la mise en œuvre de considérations de qualité et de confidentialité pour conduire une IA responsable. Cependant, les données d'entreprise générées à partir de sources cloisonnées, combinées à l'absence de stratégie d'intégration des données, créent des défis pour la fourniture de données pour les applications d'IA générative. La nécessité d'un système de bout en bout stratégie de gestion des données et la gouvernance des données à chaque étape du parcours – depuis l'ingestion, le stockage et l'interrogation des données jusqu'à l'analyse, la visualisation et l'exécution de modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) – continue d'être d'une importance capitale pour les entreprises.
Dans cet article, nous discutons des besoins en matière de gouvernance des données des pipelines de données d'applications d'IA génératives, un élément essentiel pour régir les données utilisées par les LLM afin d'améliorer l'exactitude et la pertinence de leurs réponses aux invites des utilisateurs de manière sûre, sécurisée et transparente. Pour ce faire, les entreprises utilisent des données propriétaires avec des approches telles que la génération augmentée par récupération (RAG), le réglage fin et la pré-formation continue avec des modèles de base.
La gouvernance des données est un élément essentiel de toutes ces approches, et nous voyons émerger deux domaines d’intérêt. Premièrement, de nombreux cas d'utilisation LLM reposent sur des connaissances d'entreprise qui doivent être tirées de données non structurées telles que des documents, des transcriptions et des images, en plus des données structurées provenant d'entrepôts de données. Les données non structurées sont généralement stockées dans des systèmes cloisonnés dans différents formats et ne sont généralement pas gérées ou gouvernées avec le même niveau de rigueur que les données structurées. Deuxièmement, les applications d’IA générative introduisent un nombre plus élevé d’interactions de données que les applications conventionnelles, ce qui nécessite que les politiques de sécurité des données, de confidentialité et de contrôle d’accès soient mises en œuvre dans le cadre des flux de travail des utilisateurs d’IA générative.
Dans cet article, nous abordons la gouvernance des données pour la création d'applications d'IA générative sur AWS avec un point de vue sur les sources de connaissances d'entreprise structurées et non structurées, et le rôle de la gouvernance des données pendant les flux de travail demande-réponse des utilisateurs.
Présentation des cas d'utilisation
Explorons un exemple d'assistant IA de support client. La figure suivante montre le flux de travail conversationnel typique lancé avec une invite utilisateur.

Le workflow comprend les étapes clés de gouvernance des données suivantes :
- Politiques de contrôle d’accès et de sécurité des utilisateurs rapides.
- Accédez aux politiques pour extraire les autorisations en fonction des données pertinentes et filtrer les résultats en fonction du rôle et des autorisations de l'utilisateur invité.
- Appliquez des politiques de confidentialité des données telles que la suppression des informations personnelles identifiables (PII).
- Appliquez un contrôle d’accès précis.
- Accordez au rôle d'utilisateur des autorisations pour les informations sensibles et les politiques de conformité.
Pour fournir une réponse qui inclut le contexte de l'entreprise, chaque invite utilisateur doit être complétée par une combinaison d'informations issues des données structurées de l'entrepôt de données et des données non structurées du lac de données de l'entreprise. En back-end, les processus d'ingénierie des données par lots qui rafraîchissent le lac de données d'entreprise doivent s'étendre pour ingérer, transformer et gérer les données non structurées. Dans le cadre de la transformation, les objets doivent être traités pour garantir la confidentialité des données (par exemple, rédaction des informations personnelles). Enfin, les politiques de contrôle d'accès doivent également être étendues aux objets de données non structurés et aux magasins de données vectorielles.
Voyons comment la gouvernance des données peut être appliquée aux pipelines de données des sources de connaissances de l'entreprise et aux workflows de requête-réponse des utilisateurs.
Connaissance de l'entreprise : gestion des données
La figure suivante résume les considérations relatives à la gouvernance des données pour les pipelines de données et le flux de travail pour l'application de la gouvernance des données.
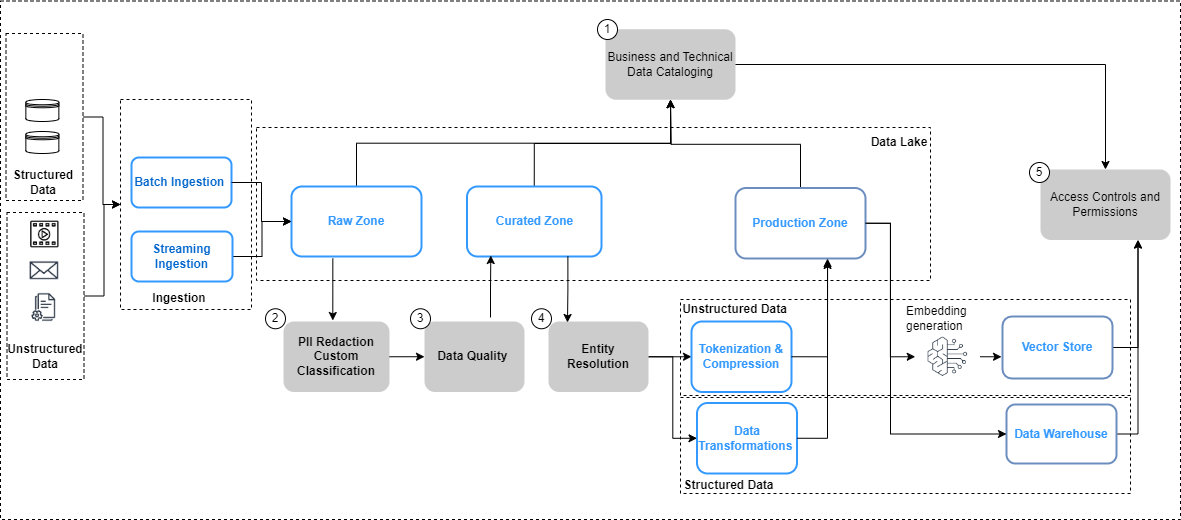
Dans la figure ci-dessus, les pipelines d'ingénierie des données incluent les étapes de gouvernance des données suivantes :
- Créer et mettre à jour un catalogue grâce à l'évolution des données.
- Mettre en œuvre des politiques de confidentialité des données.
- Mettez en œuvre la qualité des données par type de données et source.
- Reliez des ensembles de données structurés et non structurés.
- Implémentez des contrôles d’accès unifiés et précis pour les ensembles de données structurés et non structurés.
Examinons plus en détail certains des changements clés dans les pipelines de données, à savoir le catalogage des données, la qualité des données et la sécurité de l'intégration vectorielle.
Découverte des données
Contrairement aux données structurées, qui sont gérées dans des lignes et des colonnes bien définies, les données non structurées sont stockées sous forme d'objets. Pour que les utilisateurs puissent découvrir et comprendre les données, la première étape consiste à créer un catalogue complet à l'aide des métadonnées générées et capturées dans les systèmes sources. Cela commence par l'ingestion des objets (tels que les documents et les fichiers de transcription) depuis les systèmes sources concernés vers la zone brute du fichier. lac de données in Service de stockage simple Amazon (Amazon S3) dans leurs formats natifs respectifs (comme illustré dans la figure précédente). À partir de là, les métadonnées des objets (telles que le propriétaire du fichier, la date de création et le niveau de confidentialité) sont extrait et interrogé à l’aide des fonctionnalités d’Amazon S3. Les métadonnées peuvent varier selon la source de données et il est important d'examiner les champs et, le cas échéant, d'en dériver les champs nécessaires pour compléter toutes les métadonnées nécessaires. Par exemple, si un attribut tel que la confidentialité du contenu n'est pas balisé au niveau du document dans l'application source, il peut être nécessaire de le dériver dans le cadre du processus d'extraction des métadonnées et de l'ajouter en tant qu'attribut dans le catalogue de données. Le processus d'ingestion doit capturer les mises à jour des objets (modifications, suppressions) en plus des nouveaux objets de manière continue. Pour des conseils de mise en œuvre détaillés, reportez-vous à Gestion et gouvernance des données non structurées à l'aide des services AWS AI/ML et d'analyse. Pour simplifier davantage la découverte et l'introspection entre les glossaires métier et les catalogues de données techniques, vous pouvez utiliser Zone de données Amazon permettant aux utilisateurs professionnels de découvrir et de partager des données stockées dans des silos de données.
Confidentialité des données
Les sources de connaissances d'entreprise contiennent souvent des informations personnelles et d'autres données sensibles (telles que des adresses et des numéros de sécurité sociale). En fonction de vos politiques de confidentialité des données, ces éléments doivent être traités (masqués, tokenisés ou expurgés) à partir des sources avant de pouvoir être utilisés pour des cas d'utilisation en aval. À partir de la zone brute d'Amazon S3, les objets doivent être traités avant de pouvoir être consommés par des modèles d'IA génératifs en aval. Une exigence clé ici est Identification et rédaction des informations personnelles, que vous pouvez implémenter avec Amazon comprendre. Il est important de garder à l’esprit qu’il n’est pas toujours possible de supprimer toutes les données sensibles sans affecter le contexte des données. Contexte sémantique est l'un des facteurs clés qui déterminent l'exactitude et la pertinence des résultats du modèle d'IA génératif, et il est essentiel de revenir en arrière à partir du cas d'utilisation et de trouver l'équilibre nécessaire entre les contrôles de confidentialité et les performances du modèle.
L'enrichissement des données
De plus, des métadonnées supplémentaires peuvent devoir être extraites des objets. Amazon Comprehend fournit des fonctionnalités pour reconnaissance d'entité (par exemple, identifier des données spécifiques à un domaine telles que les numéros de police et les numéros de réclamation) et classement personnalisé (par exemple, catégoriser une transcription de discussion du service client en fonction de la description du problème). De plus, vous devrez peut-être combiner les données non structurées et structurées pour créer une image globale des entités clés, comme les clients. Par exemple, dans un scénario de fidélisation d'une compagnie aérienne, il serait très utile de lier la capture de données non structurées des interactions des clients (telles que les transcriptions de chat et les avis des clients) avec des signaux de données structurés (tels que les achats de billets et l'échange de miles) pour créer un système plus complet. profil client qui peut ensuite permettre de fournir des recommandations de voyage meilleures et plus pertinentes. Résolution d'entité AWS est un service ML qui aide à faire correspondre et lier les enregistrements. Ce service permet de relier des ensembles d'informations connexes pour créer des données plus approfondies et plus connectées sur des entités clés telles que les clients, les produits, etc., ce qui peut améliorer encore la qualité et la pertinence des résultats LLM. Ceci est disponible dans la zone transformée dans Amazon S3 et est prêt à être consommé en aval pour les magasins de vecteurs, le réglage fin ou la formation des LLM. Après ces transformations, les données peuvent être mises à disposition dans la zone organisée dans Amazon S3.
Qualité des données
Un facteur essentiel pour réaliser tout le potentiel de l’IA générative dépend de la qualité des données utilisées pour entraîner les modèles ainsi que des données utilisées pour augmenter et améliorer la réponse du modèle à une entrée de l’utilisateur. Comprendre les modèles et leurs résultats dans le contexte de l'exactitude, du biais et de la fiabilité est directement proportionnel à la qualité des données utilisées pour créer et entraîner les modèles.
Moniteur de modèle Amazon SageMaker fournit une détection proactive des écarts dans la dérive de la qualité des données du modèle et dans la dérive des métriques de qualité du modèle. Il surveille également la dérive des biais dans les prédictions de votre modèle et l'attribution des fonctionnalités. Pour plus de détails, reportez-vous à Surveillance des modèles ML en production à grande échelle à l'aide d'Amazon SageMaker Model Monitor. La détection des biais dans votre modèle est un élément fondamental d’une IA responsable, et Amazon SageMaker Clarifier aide à détecter les biais potentiels pouvant produire un résultat négatif ou moins précis. Pour en savoir plus, voir Découvrez comment Amazon SageMaker Clarify aide à détecter les biais.
Un domaine d'intérêt plus récent dans l'IA générative est l'utilisation et la qualité des données dans les invites provenant des magasins de données d'entreprise et propriétaires. Une bonne pratique émergente à considérer ici est shift-gauche, qui met fortement l’accent sur des mécanismes d’assurance qualité précoces et proactifs. Dans le contexte des pipelines de données conçus pour traiter les données pour les applications d’IA générative, cela implique d’identifier et de résoudre les problèmes de qualité des données plus tôt en amont afin d’atténuer l’impact potentiel des problèmes de qualité des données plus tard. Qualité des données AWS Glue non seulement mesure et surveille la qualité de vos données au repos dans vos lacs de données, entrepôts de données et bases de données transactionnelles, mais permet également la détection et la correction précoces des problèmes de qualité pour vos pipelines d'extraction, de transformation et de chargement (ETL) afin de garantir que vos données répond aux normes de qualité avant d’être consommé. Pour plus de détails, reportez-vous à Premiers pas avec AWS Glue Data Quality à partir du catalogue de données AWS Glue.
Gouvernance du magasin vectoriel
Intégrations dans des bases de données vectorielles élever l'intelligence et les capacités des applications d'IA générative en activant des fonctionnalités telles que la recherche sémantique et en réduisant les hallucinations. Les intégrations contiennent généralement des données privées et sensibles, et le chiffrement des données est une étape recommandée dans le flux de travail de saisie utilisateur. Amazon OpenSearch sans serveur stocke et recherche vos intégrations vectorielles, et crypte vos données au repos avec Service de gestion des clés AWS (AWS KMS). Pour plus de détails, voir Présentation du moteur vectoriel pour Amazon OpenSearch Serverless, désormais en avant-première. De même, des options de moteur vectoriel supplémentaires sur AWS, notamment Amazone Kendra ainsi que Amazon Aurora, chiffrez vos données au repos avec AWS KMS. Pour plus d'informations, reportez-vous à Chiffrement au repos ainsi que Protéger les données grâce au cryptage.
À mesure que les intégrations sont générées et stockées dans un magasin vectoriel, le contrôle de l'accès aux données avec le contrôle d'accès basé sur les rôles (RBAC) devient une exigence clé pour maintenir la sécurité globale. Service Amazon OpenSearch fournit contrôles d'accès précis (FGAC) fonctionnalités avec Gestion des identités et des accès AWS (IAM) règles pouvant être associées à Amazon Cognito utilisateurs. Les mécanismes de contrôle d'accès des utilisateurs correspondants sont également fournis par OpenSearch sans serveur, Amazone Kendra, et Aurore. Pour en savoir plus, reportez-vous à Contrôle d'accès aux données pour Amazon OpenSearch Serverless, Contrôler l'accès des utilisateurs aux documents avec des jetonset Gestion des identités et des accès pour Amazon Aurora, Respectivement.
Workflows demande-réponse des utilisateurs
Les contrôles au niveau de la gouvernance des données doivent être intégrés dans l'application d'IA générative dans le cadre de l'ensemble déploiement de solutions pour garantir le respect des politiques de sécurité des données (basées sur des contrôles d’accès basés sur les rôles) et de confidentialité des données (basées sur un accès basé sur les rôles aux données sensibles). La figure suivante illustre le flux de travail pour appliquer la gouvernance des données.
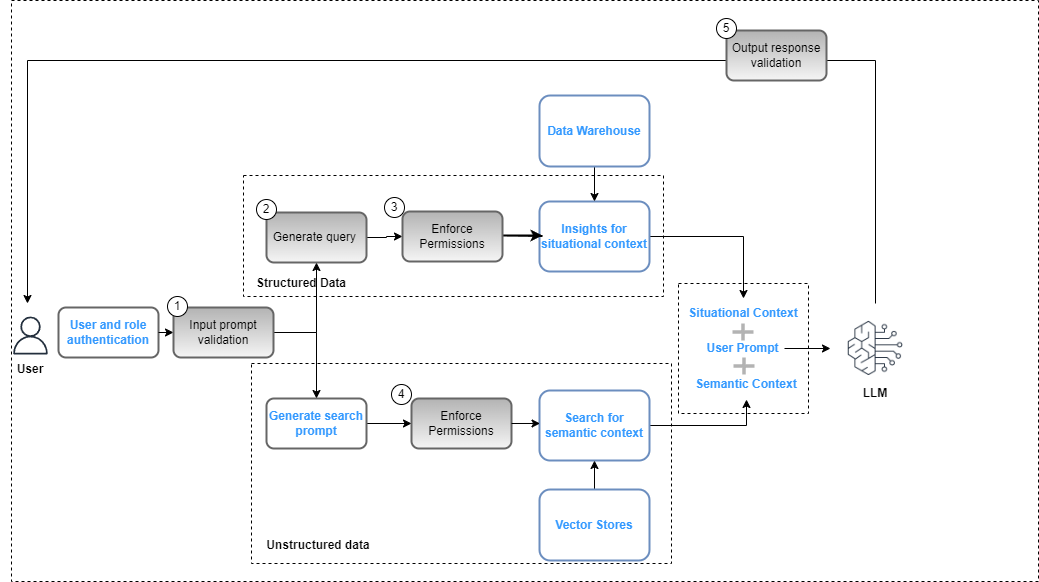
Le workflow comprend les étapes clés de gouvernance des données suivantes :
- Fournissez une invite de saisie valide pour l'alignement avec les politiques de conformité (par exemple, biais et toxicité).
- Générez une requête en mappant les mots-clés d'invite avec le catalogue de données.
- Appliquez les politiques FGAC en fonction du rôle de l'utilisateur.
- Appliquez les stratégies RBAC en fonction du rôle de l'utilisateur.
- Appliquez la rédaction des données et du contenu à la réponse en fonction des autorisations des rôles utilisateur et des politiques de conformité.
Dans le cadre du cycle d'invite, l'invite de l'utilisateur doit être analysée et les mots-clés extraits pour garantir l'alignement avec les politiques de conformité à l'aide d'un service tel qu'Amazon Comprehend (voir Nouveau pour Amazon Comprehend – Détection de toxicité) ou Garde-corps pour Amazon Bedrock (aperçu). Une fois cela validé, si l'invite nécessite l'extraction de données structurées, les mots-clés peuvent être utilisés sur le catalogue de données (métier ou technique) pour extraire les tables et champs de données pertinents et construire une requête à partir de l'entrepôt de données. Les autorisations des utilisateurs sont évaluées à l'aide de Formation AWS Lake pour filtrer les données pertinentes. Dans le cas de données non structurées, les résultats de la recherche sont restreints en fonction des politiques d'autorisation des utilisateurs mises en œuvre dans le magasin vectoriel. Dans une dernière étape, la réponse de sortie du LLM doit être évaluée par rapport aux autorisations des utilisateurs (pour garantir la confidentialité et la sécurité des données) et au respect des règles de sécurité (par exemple, les directives en matière de biais et de toxicité).
Bien que ce processus soit spécifique à une implémentation RAG et soit applicable à d'autres stratégies d'implémentation LLM, il existe des contrôles supplémentaires :
- Ingénierie rapide – L'accès aux modèles d'invite à invoquer doit être restreint en fonction de contrôles d'accès augmenté par la logique métier.
- Modèles de mise au point et modèles de base de formation – Dans les cas où des objets de la zone organisée dans Amazon S3 sont utilisés comme données de formation pour affiner les modèles de base, les stratégies d'autorisation doivent être configurées avec Gestion des identités et des accès Amazon S3 au niveau du compartiment ou de l'objet en fonction des exigences.
Résumé
La gouvernance des données est essentielle pour permettre aux organisations de créer des applications d’IA générative d’entreprise. À mesure que les cas d'utilisation en entreprise continuent d'évoluer, il sera nécessaire d'étendre l'infrastructure de données pour gouverner et gérer de nouveaux ensembles de données diversifiés et non structurés afin de garantir l'alignement avec les politiques de confidentialité, de sécurité et de qualité. Ces politiques doivent être mises en œuvre et gérées dans le cadre de l'ingestion, du stockage et de la gestion des données de la base de connaissances de l'entreprise, ainsi que des flux de travail d'interaction des utilisateurs. Cela garantit que les applications d’IA générative non seulement minimisent le risque de partage d’informations inexactes ou erronées, mais protègent également contre les préjugés et la toxicité pouvant conduire à des résultats préjudiciables ou diffamatoires. Pour en savoir plus sur la gouvernance des données sur AWS, consultez Qu'est-ce que la gouvernance des données?
Dans les articles suivants, nous fournirons des conseils de mise en œuvre sur la manière d'étendre la gouvernance de l'infrastructure de données pour prendre en charge les cas d'utilisation de l'IA générative.
À propos des auteurs
 Krishna Rupanagunta dirige une équipe de spécialistes des données et de l'IA chez AWS. Lui et son équipe travaillent avec les clients pour les aider à innover plus rapidement et à prendre de meilleures décisions en utilisant les données, l'analyse et l'IA/ML. Il est joignable via LinkedIn.
Krishna Rupanagunta dirige une équipe de spécialistes des données et de l'IA chez AWS. Lui et son équipe travaillent avec les clients pour les aider à innover plus rapidement et à prendre de meilleures décisions en utilisant les données, l'analyse et l'IA/ML. Il est joignable via LinkedIn.
 Imtiaz (Taz) Sayed est le leader technologique WW pour l'analyse chez AWS. Il aime interagir avec la communauté sur tout ce qui concerne les données et l'analyse. Il est joignable via LinkedIn.
Imtiaz (Taz) Sayed est le leader technologique WW pour l'analyse chez AWS. Il aime interagir avec la communauté sur tout ce qui concerne les données et l'analyse. Il est joignable via LinkedIn.
 Raghvender Arni (Arni) dirige l'équipe d'accélération client (CAT) au sein d'AWS Industries. Le CAT est une équipe interfonctionnelle mondiale composée d'architectes cloud, d'ingénieurs logiciels, de scientifiques des données, d'experts et de concepteurs IA/ML en contact avec les clients, qui stimule l'innovation via un prototypage avancé et favorise l'excellence opérationnelle du cloud via une expertise technique spécialisée.
Raghvender Arni (Arni) dirige l'équipe d'accélération client (CAT) au sein d'AWS Industries. Le CAT est une équipe interfonctionnelle mondiale composée d'architectes cloud, d'ingénieurs logiciels, de scientifiques des données, d'experts et de concepteurs IA/ML en contact avec les clients, qui stimule l'innovation via un prototypage avancé et favorise l'excellence opérationnelle du cloud via une expertise technique spécialisée.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

