Qu'est-ce qu'un Knowledge Graph ?
A graphe de connaissance est une représentation structurée des connaissances qui décrit entités et les relations entre eux.
Les graphes de connaissances font partie de «représentation des connaissances», un domaine de l'intelligence artificielle (IA) qui traite de la présentation des données de manière à permettre aux machines de raisonner, de résoudre des problèmes, de prendre des décisions et de faire des inférences.
La polyvalence des graphes de connaissances s'étend à divers domaines, avec des cas d'utilisation qui incluent :
Les graphiques de connaissances permettent aux machines d'extraire des connaissances significatives à partir des données en présentant les informations dans un format lisible par machine.
Mais saviez-vous que vous pouvez également créer un graphe de connaissances « contenu » particulièrement utile pour les initiatives SEO ? Bien que structuré comme un graphe de connaissances générales, un graphe de connaissances de contenu fonctionne comme une représentation du contenu de votre site Web.
Ce graphique peut être publié en externe pour que les moteurs de recherche puissent l'utiliser, être utilisé pour des projets d'IA internes ou être utilisé pour identifier les lacunes de contenu.
De plus, ces graphiques établissent une base solide pour développer des graphiques de connaissances marketing plus approfondis si vous disposez de sources de données supplémentaires que vous souhaitez intégrer.
Mais avant d'entrer dans le vif du sujet, cet article explorera les composants de base d'un graphe de connaissances pour vous permettre de développer votre propre graphe de connaissances de contenu en utilisant le contenu de votre site Web.
Anatomie d'un Knowledge Graph de contenu
Dans sa forme la plus simple, un graphe de connaissances se compose essentiellement de nœuds et d’arêtes.
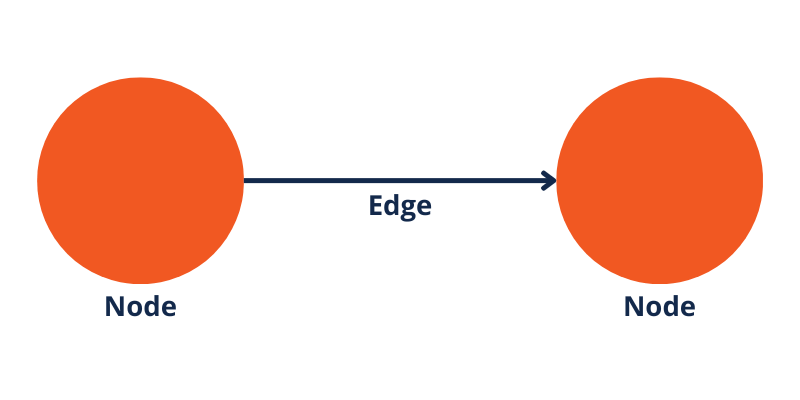
Nodes représenter des entités dans un graphe de connaissances, et bords interconnecter ces nœuds, délimitant les relations entre eux.
Pour bien comprendre le fonctionnement d'un graphe de connaissances, il est important de connaître les technologies nécessaires à sa création.
Notre objectif dans cette section est de vous guider à travers la terminologie et les fonctions clés qui sont essentielles au développement d'un graphe de connaissances de contenu robuste.
Identificateur de ressource uniforme (URI)
Dans le domaine des graphes de connaissances, l'URI (Uniform Resource Identifier) joue un rôle crucial dans l'identification unique des entités. Un URI est une chaîne de caractères distinctive conçue pour distinguer et lever l'ambiguïté d'une ressource spécifique sur le Web.

Semblables aux plaques d’immatriculation des voitures qui permettent une identification individuelle même si de nombreuses personnes partagent la même marque et le même modèle, les URI remplissent une fonction similaire en garantissant l’identification unique de diverses ressources au sein de la vaste étendue d’Internet.
Chez Schema App, nous générons des URI HTTPS pour les entités définies dans votre balisage de schéma, comme le montre l'image ci-dessous. Ces URI apparaissent dans l'attribut @id. Ils vous permettent de lier les entités de votre site au sein de votre balisage et permettent aux moteurs de recherche d'identifier les entités dans votre graphe de connaissances.
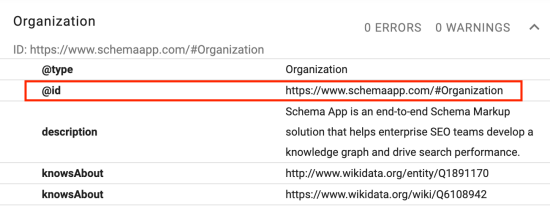
Cette identification systématique permet une communication et un accès efficaces aux ressources sur différentes plates-formes et technologies. Dans le contexte d'un graphe de connaissances, les URI représentent des entités.
Entités
An entité, tel que défini par Google, désigne une chose ou une idée unique, unique, bien définie et distinguable. Il possède des caractéristiques ou des attributs déterminants tels que la taille, la couleur et la durée. Cependant, la véritable signification d'une entité apparaît lorsqu'elle est décrite par rapport à d'autres entités, lui donnant ainsi une signification contextuelle.
C'est là que les RDF Triples jouent un rôle central, fournissant le cadre pour représenter ces relations interconnectées entre les entités au sein d'un graphe de connaissances. Mais d’abord, qu’est-ce que RDF ?
RDF
RDF, qui signifie Resource Description Framework, est une méthode standardisée pour exprimer des données sous la forme d'un graphe orienté à l'aide d'instructions sujet-prédicat-objet, communément appelées « triples ».
Triples RDF
L'unité fondamentale d'un graphe de connaissances est le triple. Il comprend deux nœuds qui représentent des entités reliées par un seul bord pour articuler leur relation. Représenté sous forme d'instructions « sujet-prédicat-objet », un triplet illustre comment une entité (sujet) est liée à une autre entité ou à une valeur simple (objet) via une propriété spécifique (prédicat).
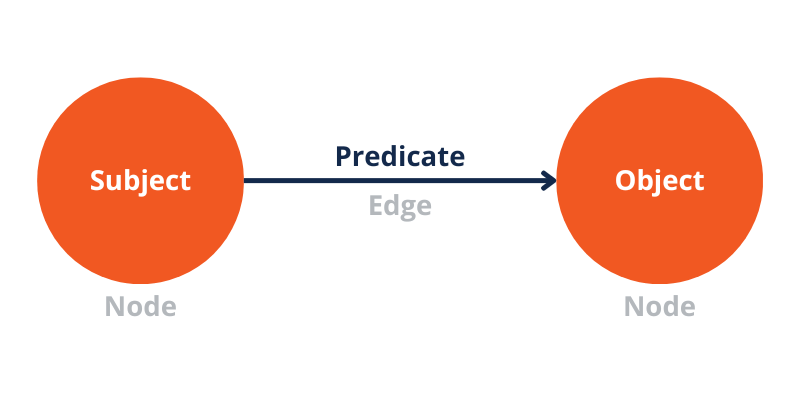
Lorsque ces triplets se combinent, ils forment des graphiques de ressources interconnectés, jetant ainsi les bases d’un graphe de connaissances complet. Cependant, pour donner du sens à la machine, vous devez exprimer ces triplets dans un format lisible par la machine.
Vous pouvez exprimer des triplets RDF dans une variété de formats, notamment :
- Tortue
- RDF/XML
- Et JSON-LD
Le format le plus largement adopté est JSON-LD, que nous utilisons ici chez Schema App.
JSON-LD
JSON-LD, ou JSON pour Linked Data, est un format de sérialisation permettant d'exprimer des triplets RDF. Il est relativement facile pour les humains de lire et d’écrire, ainsi que pour les machines de consommer. Il s’agit également du format de balisage de schéma préféré des moteurs de recherche comme Google.
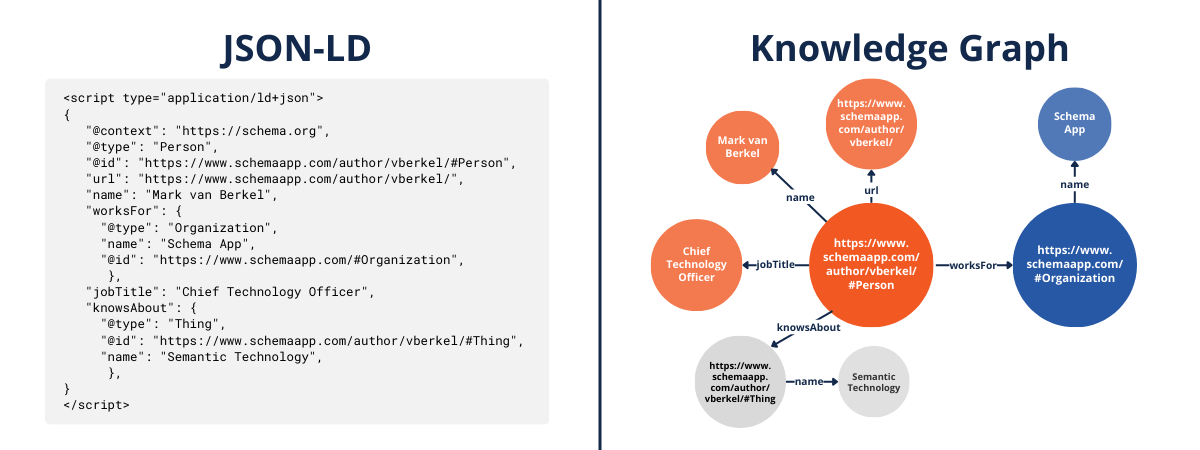
Le code JSON-LD permet aux machines de comprendre les instructions RDF sur les entités.
Par exemple, Mark van Berkel est l'auteur du blog Schema App et sa page d'auteur indique qu'il travaille pour l'organisation Schema App. Sur la gauche se trouve le balisage de schéma exprimé en JSON-LD indiquant aux machines que Mark van Berkel (personne) travaille pour Schema App (organisation). A droite se trouve ce même code visualisé sous forme d'un triple RDF, représentant ces mêmes entités et illustrant les relations entre elles.

Les ontologies
Le dernier composant d’un graphe de connaissances est une ontologie.
En sciences de l’information, une ontologie est un «spécification formelle et explicite d’une conceptualisation partagée», servant essentiellement de modèle pour définir ce qui existe dans un modèle de données (c'est-à-dire la méthode de description du contenu dans une base de données).
Ce modèle comprend généralement trois éléments clés.
Premièrement, nous avons les classes, également appelés types, représentant des catégories d'entités telles qu'un organisation, un événementou personne.
D'autre part, attributs, alias propriétés, sont utilisés pour décrire une entité. Par exemple, une entité Personne peut posséder un nom comme l'un de ses attributs.
Enfin, le des relations, qui sont également représentés par des propriétés, délimitent la manière dont une entité se connecte à une autre. Ceux-ci sont similaires aux attributs dans le sens où ils décrivent une entité, mais plus spécifiquement, ils décrivent comment une entité connecte à une autre entité.
Par exemple, une personne peut avoir un mère, enfantou collègue relation avec une autre Personne qui aura ses propres attributs.
Une grande variété d'ontologies, de vocabulaires et de glossaires existent pour catégoriser et relier les données, avec Schema.org se distinguant comme l’un des plus utilisés en référencement. Bien qu'il s'agisse techniquement d'un vocabulaire et non d'une ontologie stricte, Schema.org remplit efficacement le rôle de description des catégories de choses et des relations entre elles.
Création d'un graphique de connaissances de contenu avec Schema.org
Fondée en 2011 par Google, Bing, Yahoo et Yandex, Schema.org est né d'un effort collaboratif visant à améliorer le Web en introduisant un vocabulaire standardisé. Cette initiative visait à transformer le langage humain en un langage structuré et lisible par machine.
Tous les principaux moteurs de recherche prendraient en charge ce langage, améliorant ainsi leur capacité à faire correspondre les requêtes de recherche avec des résultats pertinents, ce qui le rendrait bénéfique à des fins de référencement.
Bien que les stratégies de référencement utilisent généralement Schema.org, son utilité s'étend au-delà ; il peut également servir d’outil robuste pour construire un graphe de connaissances.
Tirer parti du vocabulaire Schema.org vous permet d'organiser le contenu de votre site Web dans un graphique d'entités interconnectées. Pour y parvenir, vous pouvez utiliser les types et propriétés définis par Schema.org pour exprimer les triples RDF dans un format lisible par machine comme JSON-LD, tout en représentant vos entités avec des URI.
Voyez-vous comment tous ces termes se rejoignent ?
Cette fusion d'éléments crée efficacement un graphe de connaissances de contenu pour votre organisation.

Construisez un graphique de connaissances de contenu pour votre organisation
Développer votre propre graphe de connaissances de contenu est essentiel pour optimiser votre référencement sémantique stratégie. Il prépare votre contenu pour l'avenir de la recherche et génère un trafic de meilleure qualité vers votre site.
Les graphiques de connaissances permettent aux moteurs de recherche de déduire des connaissances grâce à des informations contextuelles supplémentaires, comblant ainsi les lacunes pour des résultats plus pertinents. En tant que telle, cette compréhension plus approfondie devrait générer un trafic plus qualifié vers votre site et augmenter le CTR des pages pertinentes.
Chez Schema App, nous sommes spécialisés dans la création et gestion des graphiques de connaissances de contenu grâce à l’utilisation du Schema Markup. Nos solutions de création dynamique garantissent que votre balisage de schéma est toujours descriptif, interconnecté et à jour.
Que vous intégriez Schema Markup dans votre stratégie de référencement ou que vous aspiriez à transformer votre contenu en une couche de données réutilisable, Schema App est là pour vous.
Vous souhaitez créer un graphique de connaissances de contenu pour votre propre organisation, mais vous ne savez pas par où commencer ? Schema App gère les aspects techniques, vous permettant de profiter des avantages d'un graphe de connaissances de contenu bien construit sans imposer la charge technique à vos équipes internes.
Contactez notre équipe dès aujourd'hui pour commencer.

Jasmine est la chef de produit chez Schema App. Schema App est une solution de balisage de schéma de bout en bout qui aide les équipes SEO d'entreprise à créer, déployer et gérer Schema Markup pour se démarquer dans la recherche.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.schemaapp.com/schema-markup/the-anatomy-of-a-content-knowledge-graph/

