Krones fournit aux brasseries, aux embouteilleurs de boissons et aux producteurs de produits alimentaires du monde entier des machines individuelles et des lignes de production complètes. Chaque jour, des millions de bouteilles en verre, de canettes et de récipients en PET transitent par une ligne Krones. Les lignes de production sont des systèmes complexes avec de nombreuses erreurs possibles qui pourraient bloquer la ligne et diminuer le rendement de production. Krones souhaite détecter la panne le plus tôt possible (parfois même avant qu'elle ne se produise) et avertir les opérateurs de la ligne de production afin d'augmenter la fiabilité et le rendement. Alors comment détecter une panne ? Krones équipe ses lignes de capteurs pour la collecte de données, qui peuvent ensuite être évaluées par rapport à des règles. Krones, en tant que constructeur de la ligne, ainsi que l'exploitant de la ligne ont la possibilité de créer des règles de surveillance pour les machines. Ainsi, les embouteilleurs de boissons et autres opérateurs peuvent définir leur propre marge d’erreur pour la ligne. Dans le passé, Krones utilisait un système basé sur une base de données de séries chronologiques. Les principaux défis étaient que ce système était difficile à déboguer et que les requêtes représentaient également l'état actuel des machines mais pas les transitions d'état.
Cet article montre comment Krones a construit une solution de streaming pour surveiller ses lignes, basée sur Amazon Kinésis ainsi que Service géré Amazon pour Apache Flink. Ces services entièrement gérés réduisent la complexité de la création d'applications de streaming avec Apache Flink. Le service géré pour Apache Flink gère les composants Apache Flink sous-jacents qui fournissent un état d'application durable, des métriques, des journaux, etc., et Kinesis vous permet de traiter de manière rentable les données en streaming à n'importe quelle échelle. Si vous souhaitez démarrer avec votre propre application Apache Flink, consultez le GitHub référentiel pour des exemples utilisant les API Java, Python ou SQL de Flink.
Présentation de la solution
La surveillance des lignes de Krones fait partie du Conseils pour l'atelier Krones système. Il accompagne l'organisation, la priorisation, la gestion et la documentation de toutes les activités de l'entreprise. Il leur permet d'avertir un opérateur si la machine est arrêtée ou si des matériaux sont nécessaires, quel que soit l'endroit où se trouve l'opérateur dans la ligne. Des règles éprouvées de surveillance des conditions sont déjà intégrées mais peuvent également être définies par l'utilisateur via l'interface utilisateur. Par exemple, si un certain point de données surveillé viole un seuil, il peut y avoir un message texte ou un déclencheur pour une ordonnance de maintenance sur la ligne.
Le système de surveillance des conditions et d'évaluation des règles est construit sur AWS, à l'aide des services d'analyse AWS. Le diagramme suivant illustre l'architecture.
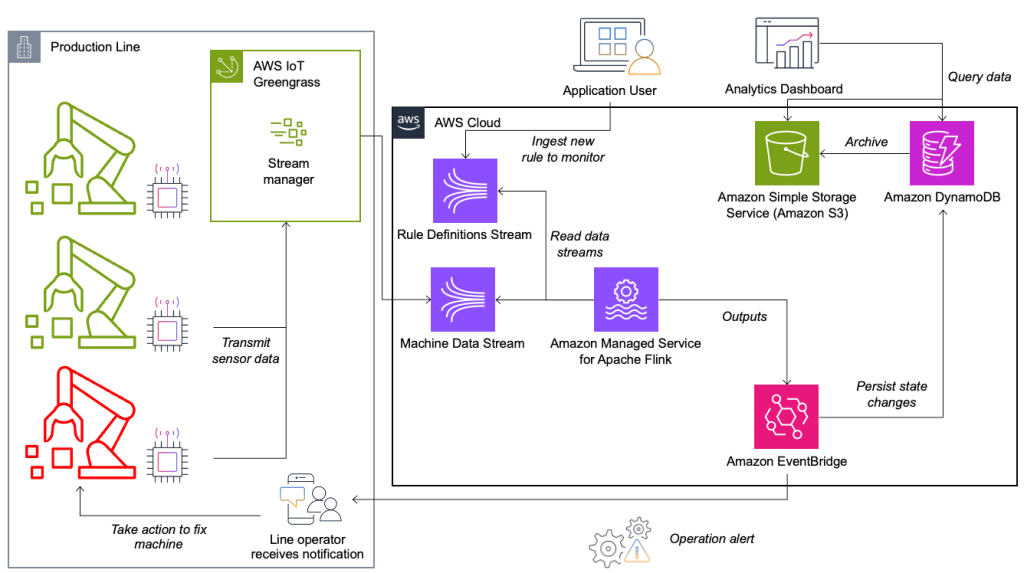
Presque toutes les applications de streaming de données se composent de cinq couches : source de données, ingestion de flux, stockage de flux, traitement de flux et une ou plusieurs destinations. Dans les sections suivantes, nous approfondissons chaque couche et comment la solution de surveillance de ligne, construite par Krones, fonctionne en détail.
La source de données
Les données sont collectées par un service exécuté sur un appareil Edge lisant plusieurs protocoles comme Siemens S7 ou OPC/UA. Les données brutes sont prétraitées pour créer une structure JSON unifiée, ce qui facilite leur traitement ultérieur dans le moteur de règles. Un exemple de charge utile convertie en JSON peut ressembler à ceci :
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Ingestion de flux
AWS IoT Greengrass est un environnement d'exécution et un service cloud open source pour l'Internet des objets (IoT). Cela vous permet d'agir sur les données localement et de regrouper et filtrer les données des appareils. AWS IoT Greengrass fournit des composants prédéfinis qui peuvent être déployés en périphérie. La solution de ligne de production utilise le composant Stream Manager, qui peut traiter les données et les transférer vers des destinations AWS telles que Analyse AWS IdO, Service de stockage simple Amazon (Amazon S3) et Kinesis. Le gestionnaire de flux met en mémoire tampon et regroupe les enregistrements, puis les envoie à un flux de données Kinesis.
Stockage de flux
Le travail du stockage de flux consiste à mettre en mémoire tampon les messages de manière tolérante aux pannes et à les rendre disponibles pour consommation par une ou plusieurs applications grand public. Pour y parvenir sur AWS, les technologies les plus courantes sont Kinesis et Amazon Managed Streaming pour Apache Kafka (Amazon MSK). Pour stocker les données de nos capteurs provenant des lignes de production, Krones a choisi Kinesis. Kinesis est un service de streaming de données sans serveur qui fonctionne à n'importe quelle échelle avec une faible latence. Les fragments d'un flux de données Kinesis sont une séquence d'enregistrements de données identifiée de manière unique, où un flux est composé d'un ou plusieurs fragments. Chaque partition a une capacité de lecture de 2 Mo/s et une capacité d'écriture de 1 Mo/s (avec un maximum de 1,000 XNUMX enregistrements/s). Pour éviter d’atteindre ces limites, les données doivent être réparties aussi uniformément que possible entre les fragments. Chaque enregistrement envoyé à Kinesis possède une clé de partition, qui est utilisée pour regrouper les données dans une partition. Par conséquent, vous souhaitez disposer d’un grand nombre de clés de partition pour répartir la charge uniformément. Le gestionnaire de flux exécuté sur AWS IoT Greengrass prend en charge les attributions aléatoires de clés de partition, ce qui signifie que tous les enregistrements se retrouvent dans une partition aléatoire et que la charge est répartie uniformément. Un inconvénient des attributions aléatoires de clés de partition est que les enregistrements ne sont pas stockés dans l'ordre dans Kinesis. Nous expliquons comment résoudre ce problème dans la section suivante, où nous parlons des filigranes.
Filigranes
A filigrane est un mécanisme utilisé pour suivre et mesurer la progression du temps d'un événement dans un flux de données. L'heure de l'événement est l'horodatage à partir du moment où l'événement a été créé à la source. Le filigrane indique la progression rapide de l'application de traitement de flux, de sorte que tous les événements avec un horodatage antérieur ou égal sont considérés comme traités. Ces informations sont essentielles pour que Flink avance l'heure de l'événement et déclenche les calculs pertinents, tels que les évaluations de fenêtres. Le décalage autorisé entre l'heure de l'événement et le filigrane peut être configuré pour déterminer combien de temps attendre les données tardives avant de considérer qu'une fenêtre est terminée et d'avancer le filigrane.
Krones dispose de systèmes partout dans le monde et devait gérer les arrivées tardives dues à des pertes de connexion ou à d'autres contraintes de réseau. Ils ont commencé par surveiller les arrivées tardives et en définissant la gestion des retards Flink par défaut à la valeur maximale qu'ils ont vue dans cette métrique. Ils ont rencontré des problèmes de synchronisation temporelle avec les appareils périphériques, ce qui les a conduits à utiliser une méthode de filigrane plus sophistiquée. Ils ont créé un filigrane global pour tous les expéditeurs et ont utilisé la valeur la plus basse comme filigrane. Les horodatages sont stockés dans un HashMap pour tous les événements entrants. Lorsque les filigranes sont émis périodiquement, la plus petite valeur de ce HashMap est utilisée. Pour éviter le blocage des filigranes en raison de données manquantes, ils ont configuré un idleTimeOut paramètre, qui ignore les horodatages plus anciens qu’un certain seuil. Cela augmente la latence mais donne une forte cohérence des données.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Traitement de flux
Une fois les données collectées à partir des capteurs et ingérées dans Kinesis, elles doivent être évaluées par un moteur de règles. Une règle dans ce système représente l’état d’une seule métrique (telle que la température) ou d’un ensemble de métriques. Pour interpréter une métrique, plusieurs points de données sont utilisés, ce qui constitue un calcul avec état. Dans cette section, nous approfondissons l'état de clé et l'état de diffusion dans Apache Flink et comment ils sont utilisés pour créer le moteur de règles Krones.
Flux de contrôle et modèle d’état de diffusion
Dans Apache Flink, Etat fait référence à la capacité du système à stocker et à gérer les informations de manière persistante au fil du temps et des opérations, permettant le traitement de données en continu avec prise en charge de calculs avec état.
La modèle d'état de diffusion permet la distribution d'un état à toutes les instances parallèles d'un opérateur. Par conséquent, tous les opérateurs ont le même état et les données peuvent être traitées en utilisant ce même état. Ces données en lecture seule peuvent être ingérées à l'aide d'un flux de contrôle. Un flux de contrôle est un flux de données régulier, mais généralement avec un débit de données beaucoup plus faible. Ce modèle vous permet de mettre à jour dynamiquement l'état de tous les opérateurs, permettant à l'utilisateur de modifier l'état et le comportement de l'application sans avoir besoin d'un redéploiement. Plus précisément, la répartition de l’état se fait par l’utilisation d’un flux de contrôle. En ajoutant un nouvel enregistrement dans le flux de contrôle, tous les opérateurs reçoivent cette mise à jour et utilisent le nouvel état pour le traitement des nouveaux messages.
Cela permet aux utilisateurs de l'application Krones d'ingérer de nouvelles règles dans l'application Flink sans la redémarrer. Cela évite les temps d'arrêt et offre une excellente expérience utilisateur car les changements se produisent en temps réel. Une règle couvre un scénario afin de détecter un écart de processus. Parfois, les données de la machine ne sont pas aussi faciles à interpréter qu’il y paraît à première vue. Si un capteur de température envoie des valeurs élevées, cela peut indiquer une erreur, mais également l'effet d'une procédure de maintenance en cours. Il est important de replacer les métriques dans leur contexte et de filtrer certaines valeurs. Ceci est réalisé par un concept appelé regroupement.
Regroupement de métriques
Le regroupement de données et de métriques permet de définir la pertinence des données entrantes et de produire des résultats précis. Passons en revue l'exemple de la figure suivante.
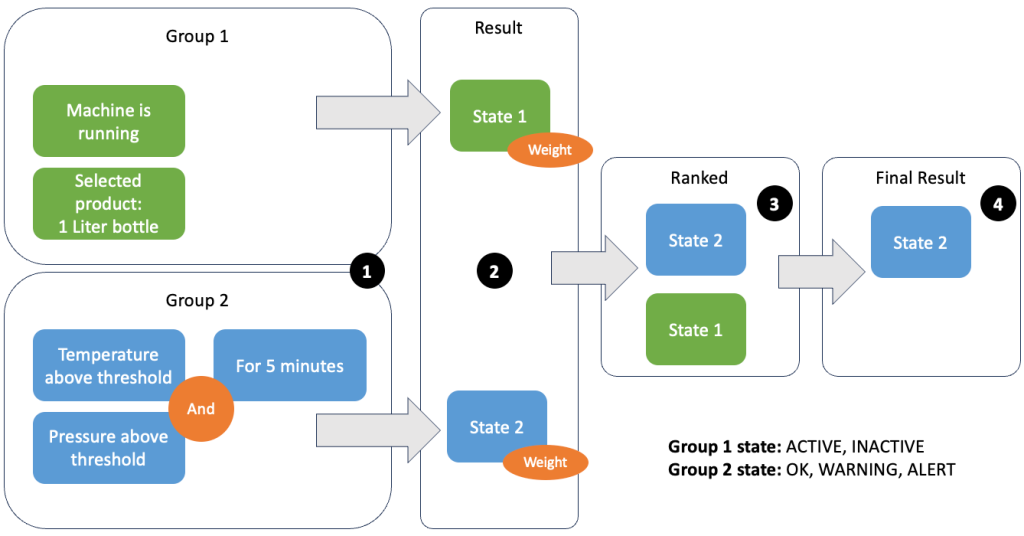
À l'étape 1, nous définissons deux groupes de conditions. Le groupe 1 collecte l'état de la machine et le produit qui passe par la ligne. Le groupe 2 utilise la valeur des capteurs de température et de pression. Un groupe de conditions peut avoir différents états en fonction des valeurs qu'il reçoit. Dans cet exemple, le groupe 1 reçoit les données indiquant que la machine est en marche et la bouteille d'un litre est sélectionnée comme produit ; cela donne à ce groupe l'état ACTIVE. Le groupe 2 contient des mesures de température et de pression ; les deux mesures sont au-dessus de leurs seuils pendant plus de 5 minutes. Il en résulte que le groupe 2 se trouve dans un WARNING État. Cela signifie que le groupe 1 rapporte que tout va bien et que le groupe 2 ne le fait pas. À l'étape 2, des poids sont ajoutés aux groupes. Cela est nécessaire dans certaines situations, car les groupes peuvent signaler des informations contradictoires. Dans ce scénario, le groupe 1 rapporte ACTIVE et rapports du groupe 2 WARNING, le système ne sait donc pas clairement quel est l'état de la ligne. Après avoir ajouté les poids, les États peuvent être classés, comme indiqué à l'étape 3. Enfin, l'État le mieux classé est choisi comme gagnant, comme indiqué à l'étape 4.
Une fois les règles évaluées et l’état final de la machine défini, les résultats seront traités davantage. L'action entreprise dépend de la configuration des règles ; il peut s'agir d'une notification à l'opérateur de la ligne pour réapprovisionner les matériaux, effectuer une maintenance ou simplement une mise à jour visuelle sur le tableau de bord. Cette partie du système, qui évalue les mesures et les règles et prend des mesures en fonction des résultats, est appelée moteur de règles.
Mise à l'échelle du moteur de règles
En permettant aux utilisateurs de créer leurs propres règles, le moteur de règles peut avoir un grand nombre de règles à évaluer, et certaines règles peuvent utiliser les mêmes données de capteur que d'autres règles. Flink est un système distribué qui évolue très bien horizontalement. Pour répartir un flux de données sur plusieurs tâches, vous pouvez utiliser l'outil keyBy() méthode. Cela vous permet de partitionner un flux de données de manière logique et d'envoyer des parties des données à différents gestionnaires de tâches. Cela se fait souvent en choisissant une clé arbitraire afin d'obtenir une charge uniformément répartie. Dans ce cas, Krones a ajouté un ruleId au point de données et l'a utilisé comme clé. Sinon, les points de données nécessaires sont traités par une autre tâche. Le flux de données chiffré peut être utilisé dans toutes les règles, tout comme une variable ordinaire.
Destinations
Lorsqu'une règle change d'état, les informations sont envoyées vers un flux Kinesis puis via Amazon Event Bridge aux consommateurs. L'un des consommateurs crée une notification de l'événement qui est transmise à la ligne de production et alerte le personnel pour qu'il agisse. Pour pouvoir analyser les changements d'état des règles, un autre service écrit les données dans un Amazon DynamoDB pour un accès rapide et un TTL est en place pour décharger l'historique à long terme vers Amazon S3 pour des rapports plus approfondis.
Conclusion
Dans cet article, nous vous avons montré comment Krones a construit un système de surveillance de ligne de production en temps réel sur AWS. Le service géré pour Apache Flink a permis à l'équipe Krones de démarrer rapidement en se concentrant sur le développement d'applications plutôt que sur l'infrastructure. Les capacités en temps réel de Flink ont permis à Krones de réduire les temps d'arrêt des machines de 10 % et d'augmenter l'efficacité jusqu'à 5 %.
Si vous souhaitez créer vos propres applications de streaming, consultez les exemples disponibles sur le GitHub référentiel. Si vous souhaitez étendre votre application Flink avec des connecteurs personnalisés, consultez Faciliter la création de connecteurs avec Apache Flink : présentation du récepteur asynchrone. Le récepteur asynchrone est disponible dans Apache Flink version 1.15.1 et versions ultérieures.
À propos des auteurs
 Florian Mair est architecte de solutions senior et expert en streaming de données chez AWS. C'est un technologue qui aide les clients européens à réussir et à innover en résolvant les défis commerciaux à l'aide des services AWS Cloud. En plus de travailler en tant qu'architecte de solutions, Florian est un alpiniste passionné et a gravi certaines des plus hautes montagnes d'Europe.
Florian Mair est architecte de solutions senior et expert en streaming de données chez AWS. C'est un technologue qui aide les clients européens à réussir et à innover en résolvant les défis commerciaux à l'aide des services AWS Cloud. En plus de travailler en tant qu'architecte de solutions, Florian est un alpiniste passionné et a gravi certaines des plus hautes montagnes d'Europe.
 Émile Dietl est un responsable technique senior chez Krones spécialisé dans l'ingénierie des données, avec un domaine clé dans Apache Flink et les microservices. Son travail implique souvent le développement et la maintenance de logiciels critiques. En dehors de sa vie professionnelle, il apprécie profondément passer du temps de qualité avec sa famille.
Émile Dietl est un responsable technique senior chez Krones spécialisé dans l'ingénierie des données, avec un domaine clé dans Apache Flink et les microservices. Son travail implique souvent le développement et la maintenance de logiciels critiques. En dehors de sa vie professionnelle, il apprécie profondément passer du temps de qualité avec sa famille.
 Simon Peyer est un architecte de solutions chez AWS basé en Suisse. C'est un homme pratique et passionné par la connexion de la technologie et des personnes utilisant les services AWS Cloud. Il se concentre particulièrement sur le streaming de données et les automatisations. Outre son travail, Simon aime sa famille, le plein air et les randonnées en montagne.
Simon Peyer est un architecte de solutions chez AWS basé en Suisse. C'est un homme pratique et passionné par la connexion de la technologie et des personnes utilisant les services AWS Cloud. Il se concentre particulièrement sur le streaming de données et les automatisations. Outre son travail, Simon aime sa famille, le plein air et les randonnées en montagne.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

