Les données sont au cœur de l'apprentissage automatique (ML). L'inclusion de données pertinentes pour représenter de manière exhaustive votre problème commercial garantit que vous capturez efficacement les tendances et les relations afin que vous puissiez en tirer les informations nécessaires pour prendre des décisions commerciales. Avec Toile Amazon SageMaker, vous pouvez désormais importer des données depuis plus de 40 sources de données à utiliser pour le ML sans code. Canvas élargit l'accès au ML en fournissant aux analystes commerciaux une interface visuelle qui leur permet de générer eux-mêmes des prédictions ML précises, sans nécessiter d'expérience en ML ni avoir à écrire une seule ligne de code. Désormais, vous pouvez importer des données dans l'application à partir de magasins de données relationnelles populaires tels que Amazone Athéna ainsi que des plates-formes tierces de logiciel en tant que service (SaaS) prises en charge par Flux d'application Amazon tels que Salesforce, SAP OData et Google Analytics.
Le processus de collecte de données de haute qualité pour le ML peut être complexe et prendre du temps, car la prolifération des applications SaaS et des services de stockage de données a créé une propagation des données sur une multitude de systèmes. Par exemple, vous devrez peut-être effectuer une analyse de l'attrition des clients à l'aide des données client de Salesforce, des données financières de SAP et des données logistiques de Snowflake. Pour créer un ensemble de données à travers ces sources, vous devez vous connecter à chaque application individuellement, sélectionner les données souhaitées et les exporter localement, où elles peuvent ensuite être agrégées à l'aide d'un outil différent. Cet ensemble de données doit ensuite être importé dans une application distincte pour ML.
Avec ce lancement, Canvas vous permet de tirer parti des données stockées dans des sources disparates en prenant en charge l'importation et l'agrégation de données dans l'application à partir de plus de 40 sources de données. Cette fonctionnalité est rendue possible grâce à de nouveaux connecteurs natifs vers Athena et vers Amazon AppFlow via le Colle AWS Catalogue de données. Amazon AppFlow est un service géré qui vous permet de transférer en toute sécurité des données depuis des applications SaaS tierces vers Service de stockage simple Amazon (Amazon S3) et cataloguez les données avec le catalogue de données en quelques clics. Une fois vos données transférées, vous pouvez simplement accéder à la source de données dans Canvas, où vous pouvez afficher les schémas de table, joindre des tables dans ou entre des sources de données, écrire des requêtes Athena et prévisualiser et importer vos données. Une fois vos données importées, vous pouvez utiliser les fonctionnalités existantes de Canvas, telles que la création d'un modèle ML, l'affichage des données d'impact des colonnes ou la génération de prédictions. Vous pouvez automatiser le processus de transfert de données dans Amazon AppFlow pour l'activer selon un calendrier afin de vous assurer que vous avez toujours accès aux dernières données dans Canvas.
Vue d'ensemble de la solution
Les étapes décrites dans cet article fournissent deux exemples d'importation de données dans Canvas pour le ML sans code. Dans le premier exemple, nous montrons comment importer des données via Athena. Dans le deuxième exemple, nous montrons comment importer des données depuis une application SaaS tierce via Amazon AppFlow.
Importer des données depuis Athena
Dans cette section, nous montrons un exemple d'importation de données dans Canvas à partir d'Athena pour effectuer une analyse de segmentation de la clientèle. Nous créons un modèle de classification ML pour classer notre clientèle en quatre classes différentes, dans le but final d'utiliser le modèle pour prédire dans quelle classe un nouveau client appartiendra. Nous suivons trois étapes principales : importer les données, former un modèle et générer des prédictions. Commençons.
Importez les données
Pour importer des données depuis Athena, procédez comme suit :
- Sur la console Canvas, choisissez Jeux de données dans le volet de navigation, puis choisissez L’.
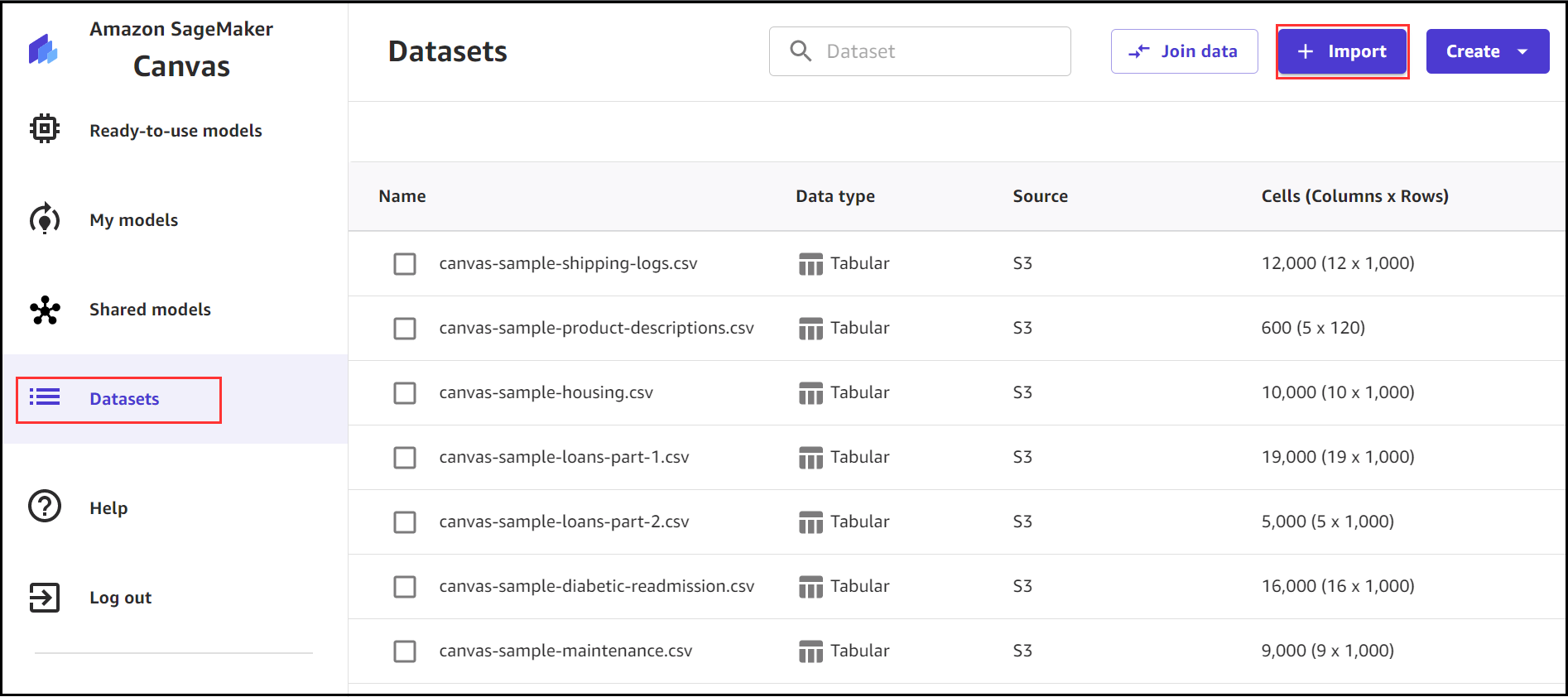
- Élargir la La source de données menu et choisissez Athena.

- Choisissez la base de données et la table correctes à partir desquelles vous souhaitez importer. Vous pouvez éventuellement prévisualiser le tableau en choisissant l'icône d'aperçu.

La capture d'écran suivante montre un exemple de tableau d'aperçu.

Dans notre exemple, nous segmentons les clients en fonction du canal marketing par lequel ils ont fait appel à nos services. Ceci est spécifié par la colonne segmentation, où A représente la presse écrite, B le mobile, C les promotions en magasin et D la télévision.
- Lorsque vous êtes satisfait d'avoir le bon tableau, faites glisser le tableau souhaité dans le Faites glisser et déposez des ensembles de données pour les joindre .

- Vous pouvez désormais sélectionner ou désélectionner des colonnes, joindre des tables en faisant glisser une autre table dans le Faites glisser et déposez des ensembles de données pour les joindre ou écrivez des requêtes SQL pour spécifier votre tranche de données. Pour cet article, nous utilisons toutes les données du tableau.
- Pour importer les données, choisissez Importer des données.

Vos données sont importées dans Canvas en tant qu'ensemble de données à partir de la table spécifique dans Athena.
Former un mannequin
Une fois vos données importées, elles s'affichent sur le Jeux de données page. A ce stade, vous pouvez construire un modèle. Pour ce faire, procédez comme suit :
- Sélectionnez votre ensemble de données et choisissez Créer un modèle.

- Pour Nom du modèle, entrez le nom de votre modèle (pour ce poste,
my_first_model). - Canvas vous permet de créer des modèles pour l'analyse prédictive, l'analyse d'images et l'analyse de texte. Parce que nous voulons catégoriser les clients, sélectionnez Analyse prédictive en Type de problème.
- Pour continuer, choisissez Création.

Sur le Développer , vous pouvez voir des statistiques sur votre ensemble de données, telles que le pourcentage de valeurs manquantes et la moyenne des données.
- Pour Colonne cible, choisissez une colonne (pour cet article,
segmentation).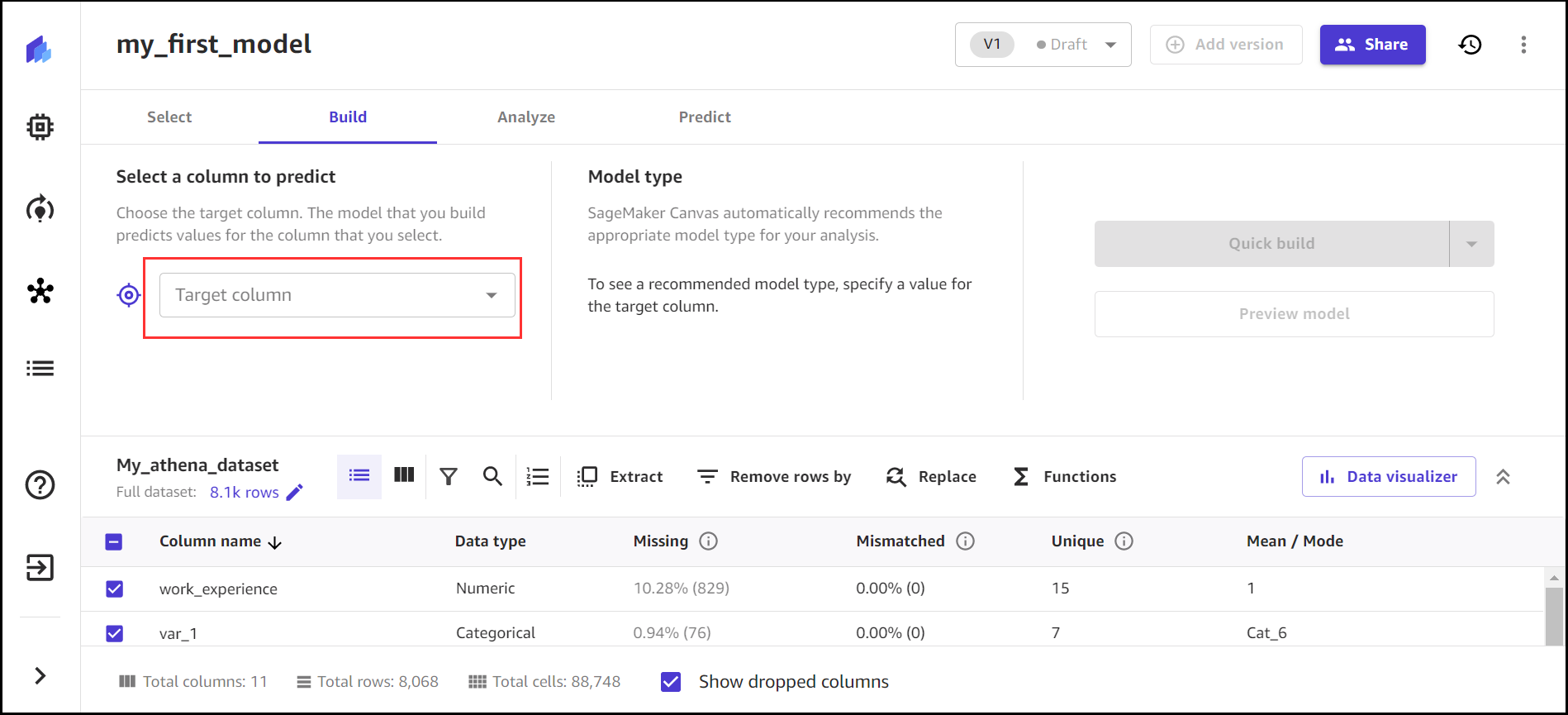
Canvas propose deux types de modèles pouvant générer des prédictions. La construction rapide privilégie la vitesse à la précision, fournissant un modèle en 2 à 15 minutes. La construction standard privilégie la précision à la vitesse, fournissant un modèle en 2 à 4 heures.
- Pour ce poste, choisissez Construction rapide.
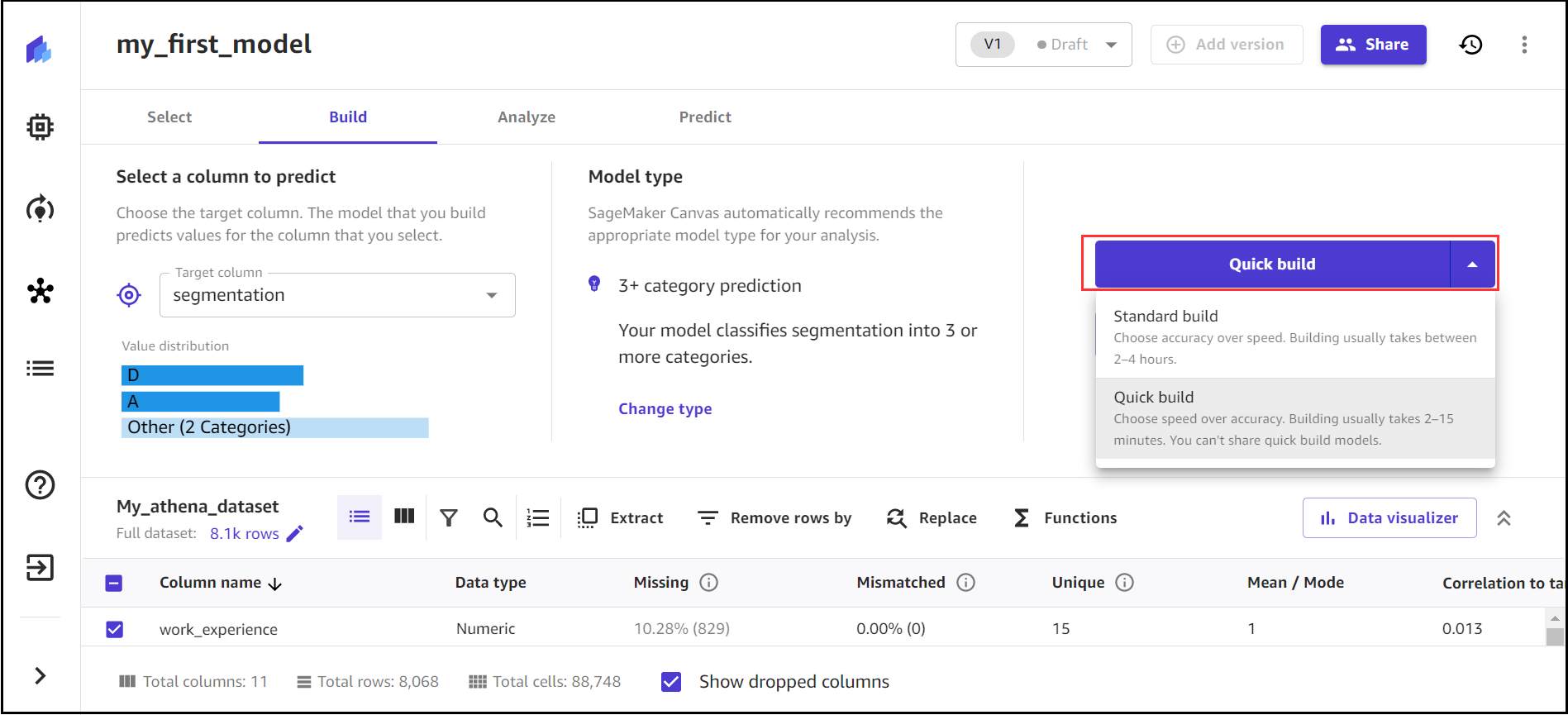
- Une fois le modèle formé, vous pouvez analyser la précision du modèle.
Le modèle suivant catégorise correctement les clients 94.67 % du temps.

- Vous pouvez éventuellement également afficher l'impact de chaque colonne sur la catégorisation. Dans cet exemple, à mesure qu'un client vieillit, la colonne a moins d'influence sur la catégorisation. Pour générer des prédictions avec votre nouveau modèle, choisissez Prédire.

Générer des prédictions
Sur le Prédire , vous pouvez générer à la fois des prédictions par lots et des prédictions uniques. Effectuez les étapes suivantes :
- Pour ce poste, choisissez Prédiction unique pour comprendre quelle segmentation de la clientèle en résultera pour un nouveau client.

Pour notre prédiction, nous voulons comprendre quelle sera la segmentation d'un client s'il a 32 ans et qu'il est avocat de profession.
- Remplacez les valeurs correspondantes par ces entrées.
- Selectionnez Mises à jour.

La prédiction mise à jour s'affiche dans la fenêtre de prédiction. Dans cet exemple, un avocat de 32 ans est classé dans le segment D.

Importer des données d'une application SaaS tierce vers AWS
Pour importer des données d'applications SaaS tierces dans Canvas pour le ML sans code, vous devez d'abord transférer les données de l'application vers Amazon S3 via Amazon AppFlow. Dans cet exemple, nous transférons des données de fabrication depuis SAP OData.
Pour transférer vos données, procédez comme suit :
- Sur la console Amazon AppFlow, choisissez Créer un flux.

- Pour Nom du flux, entrez un nom.
- Selectionnez Suivant.

- Pour Nom de la source, choisissez l'application SaaS tierce de votre choix (pour cet article, SAP OData).
- Selectionnez Créer une nouvelle connexion.

- Dans le Connectez-vous à SAP OData fenêtre pop-up, remplissez les détails d'authentification et choisissez NOUS CONTACTER.

- Pour Objet SAP OData, choisissez l'objet contenant vos données dans SAP OData.
- Pour Nom de la destination, choisissez Amazon S3.
- Pour Détails du seau, spécifiez les détails de votre compartiment S3.
- Sélectionnez Cataloguez vos données dans le catalogue de données AWS Glue.
- Pour Rôle d'utilisateur, choisir la Gestion des identités et des accès AWS (IAM) que l'utilisateur Canvas utilisera pour accéder aux données depuis.
- Pour Déclencheur de débit, sélectionnez Fonctionne à la demande.
Alternativement, vous pouvez automatiser le transfert de flux en sélectionnant Exécuter le flux dans les délais.
- Selectionnez Suivant.

- Choisissez comment mapper les champs et terminez le mappage des champs. Pour cet article, comme il n'y a pas de base de données de destination correspondante à mapper, il n'est pas nécessaire de spécifier le mappage.
- Selectionnez Suivant.

- Ajoutez éventuellement des filtres si nécessaire pour restreindre les données transférées.
- Selectionnez Suivant.

- Vérifiez vos informations et choisissez Créer un flux.

Lorsque le flux est créé, un ruban vert apparaîtra en haut de la page indiquant qu'il a été mis à jour avec succès.
- Selectionnez Flux d'exécution.

À ce stade, vous avez réussi à transférer vos données de SAP OData vers Amazon S3.
Vous pouvez maintenant importer les données depuis l'application Canvas. Pour importer vos données depuis Canvas, suivez le même ensemble d'étapes que celles décrites dans le Importation de données section plus haut dans cet article. Pour cet exemple, sur le La source de données menu déroulant sur le Importation de données page, vous pouvez voir SAP OData listé.

Vous pouvez désormais utiliser toutes les fonctionnalités existantes de Canvas, telles que le nettoyage de vos données, la création d'un modèle ML, l'affichage des données d'impact des colonnes et la génération de prédictions.
Nettoyer
Pour nettoyer les ressources provisionnées, déconnectez-vous de l'application Canvas en choisissant Déconnexion dans le volet de navigation.
Conclusion
Avec Canvas, vous pouvez désormais importer des données pour le ML sans code à partir de 47 sources de données via des connecteurs natifs avec Athena et Amazon AppFlow via le catalogue de données AWS Glue. Ce processus vous permet d'accéder directement aux données et de les agréger sur toutes les sources de données dans Canvas après le transfert des données via Amazon AppFlow. Vous pouvez automatiser le transfert de données pour l'activer selon un calendrier, ce qui signifie que vous n'avez pas à recommencer le processus pour actualiser vos données. Avec ce processus, vous pouvez créer de nouveaux ensembles de données avec vos dernières données sans avoir à quitter l'application Canvas. Cette fonctionnalité est désormais disponible dans toutes les régions AWS où Canvas est disponible. Pour commencer à importer vos données, accédez à la console Canvas et suivez les étapes décrites dans cet article. Pour en savoir plus, consultez Connectez-vous aux sources de données.
À propos des auteurs
 Brandon Naire est chef de produit senior pour Amazon SageMaker Canvas. Son intérêt professionnel réside dans la création de services et d'applications d'apprentissage automatique évolutifs. En dehors du travail, on peut le trouver en train d'explorer les parcs nationaux, de perfectionner son swing de golf ou de planifier un voyage d'aventure.
Brandon Naire est chef de produit senior pour Amazon SageMaker Canvas. Son intérêt professionnel réside dans la création de services et d'applications d'apprentissage automatique évolutifs. En dehors du travail, on peut le trouver en train d'explorer les parcs nationaux, de perfectionner son swing de golf ou de planifier un voyage d'aventure.
 Sanjana Kambalapally est responsable du développement logiciel pour AWS Sagemaker Canvas, qui vise à démocratiser l'apprentissage automatique en créant des applications ML sans code.
Sanjana Kambalapally est responsable du développement logiciel pour AWS Sagemaker Canvas, qui vise à démocratiser l'apprentissage automatique en créant des applications ML sans code.
 Xin Xu est ingénieur en développement logiciel dans l'équipe Canvas, où il travaille sur la préparation des données, entre autres aspects dans les produits d'apprentissage automatique sans code. Dans ses temps libres, il aime faire du jogging, lire et regarder des films.
Xin Xu est ingénieur en développement logiciel dans l'équipe Canvas, où il travaille sur la préparation des données, entre autres aspects dans les produits d'apprentissage automatique sans code. Dans ses temps libres, il aime faire du jogging, lire et regarder des films.
 Volcan Unsal est Sr. Frontend Engineer dans l'équipe Canvas, où il construit des produits sans code pour rendre l'intelligence artificielle accessible aux humains. Dans ses temps libres, il aime courir, lire, regarder des sports électroniques et des arts martiaux.
Volcan Unsal est Sr. Frontend Engineer dans l'équipe Canvas, où il construit des produits sans code pour rendre l'intelligence artificielle accessible aux humains. Dans ses temps libres, il aime courir, lire, regarder des sports électroniques et des arts martiaux.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/import-data-from-over-40-data-sources-for-no-code-machine-learning-with-amazon-sagemaker-canvas/

