Les clients sont confrontés à des menaces de sécurité et à des vulnérabilités croissantes au niveau de l’infrastructure et des ressources applicatives à mesure que leur empreinte numérique s’étend et que l’impact commercial de ces actifs numériques s’accroît. Un défi commun en matière de cybersécurité est double :
- Consommer des journaux provenant de ressources numériques disponibles dans différents formats et schémas et automatiser l'analyse des découvertes de menaces basées sur ces journaux.
- Que les journaux proviennent d'Amazon Web Services (AWS), d'autres fournisseurs de cloud, d'appareils sur site ou en périphérie, les clients doivent centraliser et standardiser les données de sécurité.
En outre, les analyses permettant d’identifier les menaces de sécurité doivent être capables d’évoluer pour s’adapter à un paysage changeant d’acteurs de menace, de vecteurs de sécurité et d’actifs numériques.
Une nouvelle approche pour résoudre ce scénario complexe d'analyse de sécurité combine l'ingestion et le stockage de données de sécurité à l'aide de Lac de sécurité Amazon et analyser les données de sécurité avec l'apprentissage automatique (ML) à l'aide Amazon Sage Maker. Amazon Security Lake est un service spécialement conçu qui centralise automatiquement les données de sécurité d'une organisation provenant de sources cloud et sur site dans un lac de données spécialement conçu et stocké dans votre compte AWS. Amazon Security Lake automatise la gestion centrale des données de sécurité, normalise les journaux des services AWS intégrés et des services tiers, gère le cycle de vie des données avec une conservation personnalisable et automatise également la hiérarchisation du stockage. Amazon Security Lake ingère les fichiers journaux dans le Cadre de schéma de cybersécurité ouvert (OCSF), avec prise en charge de partenaires tels que Cisco Security, CrowdStrike, Palo Alto Networks et les journaux OCSF provenant de ressources extérieures à votre environnement AWS. Ce schéma unifié rationalise la consommation et l'analyse en aval, car les données suivent un schéma standardisé et de nouvelles sources peuvent être ajoutées avec un minimum de modifications du pipeline de données. Une fois les données du journal de sécurité stockées dans Amazon Security Lake, la question se pose de savoir comment les analyser. Une approche efficace pour analyser les données des journaux de sécurité consiste à utiliser le ML ; plus précisément, la détection des anomalies, qui examine les données d'activité et de trafic et les compare à une référence. La ligne de base définit quelle activité est statistiquement normale pour cet environnement. La détection des anomalies s'étend au-delà d'une signature d'événement individuelle et peut évoluer avec un recyclage périodique ; le trafic classé comme anormal ou anormal peut alors faire l’objet d’une action prioritaire et urgente. Amazon SageMaker est un service entièrement géré qui permet aux clients de préparer des données et de créer, former et déployer des modèles de ML pour n'importe quel cas d'utilisation avec une infrastructure, des outils et des flux de travail entièrement gérés, y compris des offres sans code pour les analystes commerciaux. SageMaker prend en charge deux algorithmes de détection d'anomalies intégrés : Informations sur la propriété intellectuelle ainsi que Forêt coupée au hasard. Vous pouvez également utiliser SageMaker pour créer votre propre modèle de détection des valeurs aberrantes personnalisé à l'aide de algorithmes provenant de plusieurs frameworks ML.
Dans cet article, vous apprendrez à préparer des données provenant d'Amazon Security Lake, puis à former et déployer un modèle ML à l'aide d'un algorithme IP Insights dans SageMaker. Ce modèle identifie le trafic ou le comportement réseau anormal qui peut ensuite être intégré dans le cadre d'une solution de sécurité de bout en bout plus vaste. Une telle solution pourrait invoquer une vérification d'authentification multifacteur (MFA) si un utilisateur se connecte à partir d'un serveur inhabituel ou à une heure inhabituelle, avertir le personnel en cas d'analyse réseau suspecte provenant de nouvelles adresses IP, alerter les administrateurs en cas d'analyse réseau inhabituelle. protocoles ou ports sont utilisés, ou enrichissez le résultat de la classification IP Insights avec d'autres sources de données telles que Service de garde Amazon et les scores de réputation IP pour classer les découvertes de menaces.
Vue d'ensemble de la solution
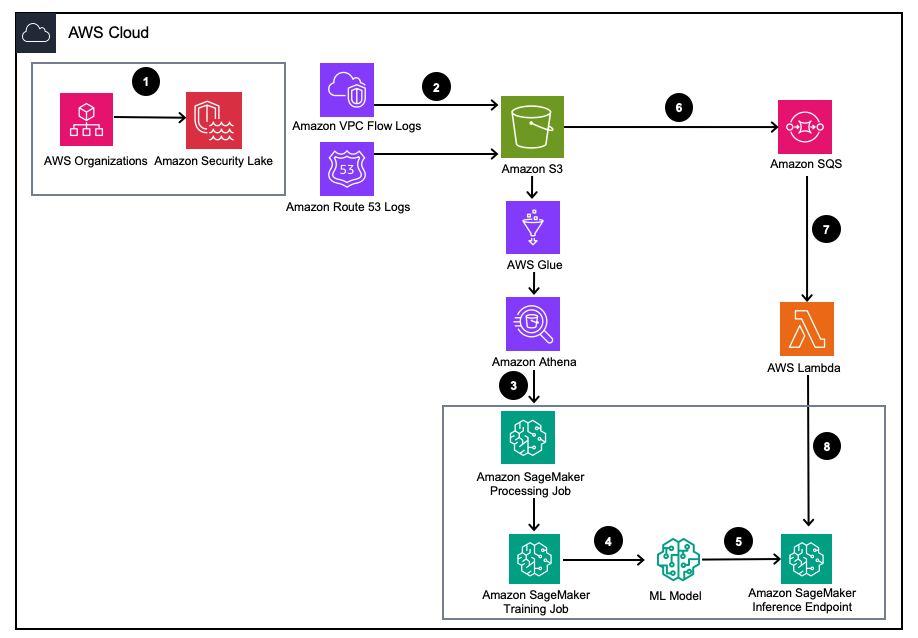
Figure 1 – Architecture de la solution
- Activez Amazon Security Lake avec Organisations AWS pour les comptes AWS, les régions AWS et les environnements informatiques externes.
- Configurer les sources Security Lake à partir de Cloud privé virtuel Amazon (Amazon VPC) Journaux de flux et AmazonRoute53 Journaux DNS dans le compartiment Amazon Security Lake S3.
- Traitez les données des journaux Amazon Security Lake à l'aide d'une tâche de traitement SageMaker pour concevoir des fonctionnalités. Utiliser Amazone Athéna pour interroger les données du journal OCSF structuré à partir de Service de stockage simple Amazon (Amazon S3) à travers Colle AWS tables gérées par AWS LakeFormation.
- Entraînez un modèle SageMaker ML à l'aide d'une tâche de formation SageMaker qui consomme les journaux Amazon Security Lake traités.
- Déployez le modèle ML formé sur un point de terminaison d'inférence SageMaker.
- Stockez les nouveaux journaux de sécurité dans un compartiment S3 et mettez les événements en file d'attente dans Service Amazon Simple Queue (Amazon SQS).
- Abonnez-vous à un AWS Lambda fonction à la file d’attente SQS.
- Appelez le point de terminaison d'inférence SageMaker à l'aide d'une fonction Lambda pour classer les journaux de sécurité comme anomalies en temps réel.
Pré-requis
Pour déployer la solution, vous devez d'abord remplir les prérequis suivants :
- Activer Amazon Security Lake au sein de votre organisation ou sur un compte unique avec les journaux de flux VPC et les journaux de résolution Route 53 activés.
- Veillez à ce que Gestion des identités et des accès AWS (IAM) Le rôle utilisé par SageMaker traitant les tâches et les notebooks a reçu une stratégie IAM comprenant le Autorisation d'accès aux requêtes des abonnés Amazon Security Lake pour la base de données Amazon Security Lake gérée et les tables gérées par AWS Lake Formation. Cette tâche de traitement doit être exécutée à partir d'un compte d'outils d'analyse ou de sécurité pour rester conforme aux Architecture de référence de sécurité AWS (AWS SRA).
- Assurez-vous que le rôle IAM utilisé par la fonction Lambda dispose d'une stratégie IAM incluant le Autorisation d'accès aux données des abonnés Amazon Security Lake.
Déployez la solution
Pour configurer l'environnement, procédez comme suit:
- Lancer un Studio SageMaker ou un notebook SageMaker Jupyter avec un
ml.m5.largeexemple. Remarque: La taille de l'instance dépend des ensembles de données que vous utilisez. - Cloner le GitHub dépôt.
- Ouvrez le cahier
01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy. - Mettre en œuvre le fourni la stratégie IAM ainsi que stratégie d'approbation IAM correspondante pour que votre instance SageMaker Studio Notebook accède à toutes les données nécessaires dans S3, Lake Formation et Athena.
Ce blog passe en revue la partie pertinente du code du notebook après son déploiement dans votre environnement.
Installez les dépendances et importez la bibliothèque requise
Utilisez le code suivant pour installer les dépendances, importer les bibliothèques requises et créer le compartiment SageMaker S3 nécessaire au traitement des données et à la formation du modèle. Une des bibliothèques requises, awswrangler, est un Kit SDK AWS pour la trame de données Pandas qui est utilisé pour interroger les tables pertinentes dans le catalogue de données AWS Glue et stocker les résultats localement dans une trame de données.
Interroger la table du journal de flux VPC Amazon Security Lake
Cette partie du code utilise le kit AWS SDK pour pandas pour interroger la table AWS Glue liée aux journaux de flux VPC. Comme mentionné dans les conditions préalables, les tables Amazon Security Lake sont gérées par Formation AWS Lake, toutes les autorisations appropriées doivent donc être accordées au rôle utilisé par le bloc-notes SageMaker. Cette requête extraira plusieurs jours de trafic du journal de flux VPC. L'ensemble de données utilisé lors du développement de ce blog était petit. En fonction de l'ampleur de votre cas d'utilisation, vous devez être conscient des limites du kit AWS SDK pour pandas. Lorsque vous envisagez une échelle de téraoctets, vous devez envisager la prise en charge du SDK AWS pour pandas pour Modine.
Lorsque vous affichez le bloc de données, vous verrez une sortie d'une seule colonne avec des champs communs qui peuvent être trouvés dans le Activité réseau (4001) classe de l’OCSF.
Normalisez les données des journaux de flux Amazon Security Lake VPC dans le format de formation requis pour IP Insights.
L'algorithme IP Insights nécessite que les données de formation soient au format CSV et contiennent deux colonnes. La première colonne doit être une chaîne opaque qui correspond à l’identifiant unique d’une entité. La deuxième colonne doit être l’adresse IPv4 de l’événement d’accès de l’entité en notation décimale. Dans l'exemple d'ensemble de données de ce blog, l'identifiant unique correspond aux ID d'instance des instances EC2 associées au instance_id valeur dans le dataframe. L'adresse IPv4 sera dérivée du src_endpoint. Selon la façon dont la requête Amazon Athena a été créée, les données importées sont déjà dans le format correct pour la formation d'un modèle IP Insights, donc aucune ingénierie de fonctionnalités supplémentaire n'est requise. Si vous modifiez la requête d'une autre manière, vous devrez peut-être intégrer une ingénierie de fonctionnalités supplémentaire.
Interroger et normaliser la table du journal du résolveur Amazon Security Lake Route 53
Tout comme vous l'avez fait ci-dessus, l'étape suivante du bloc-notes exécute une requête similaire sur la table de résolution Amazon Security Lake Route 53. Étant donné que vous utiliserez toutes les données compatibles OCSF dans ce bloc-notes, toutes les tâches d'ingénierie des fonctionnalités restent les mêmes pour les journaux du résolveur Route 53 que pour les journaux de flux VPC. Vous combinez ensuite les deux trames de données en une seule trame de données utilisée pour la formation. Étant donné que la requête Amazon Athena charge les données localement dans le format correct, aucune autre ingénierie de fonctionnalités n'est requise.
Obtenez l'image de formation IP Insights et entraînez le modèle avec les données OCSF
Dans cette partie suivante du bloc-notes, vous entraînerez un modèle ML basé sur l'algorithme IP Insights et utiliserez le modèle consolidé. dataframe d'OCSF à partir de différents types de journaux. Une liste des hyperparamètres IP Insights peut être trouvée ici. Dans l'exemple ci-dessous, nous avons sélectionné les hyperparamètres qui ont généré le modèle le plus performant, par exemple 5 pour l'époque et 128 pour vector_dim. Étant donné que l'ensemble de données de formation pour notre échantillon était relativement petit, nous avons utilisé un ml.m5.large exemple. Les hyperparamètres et vos configurations de formation, tels que le nombre d'instances et le type d'instance, doivent être choisis en fonction de vos métriques objectives et de la taille de vos données de formation. Amazon SageMaker est une fonctionnalité que vous pouvez utiliser dans Amazon SageMaker pour trouver la meilleure version de votre modèle. réglage automatique du modèle qui recherche le meilleur modèle sur une plage de valeurs d'hyperparamètres.
Déployez le modèle formé et testez avec un trafic valide et anormal
Une fois le modèle formé, vous déployez le modèle sur un point de terminaison SageMaker et envoyez une série de combinaisons d'identifiant unique et d'adresse IPv4 pour tester votre modèle. Cette partie du code suppose que vous avez enregistré des données de test dans votre compartiment S3. Les données de test sont un fichier .csv, où la première colonne correspond aux identifiants d'instance et la deuxième colonne aux adresses IP. Il est recommandé de tester les données valides et invalides pour voir les résultats du modèle. Le code suivant déploie votre point de terminaison.
Maintenant que votre point de terminaison est déployé, vous pouvez désormais soumettre des demandes d'inférence pour identifier si le trafic est potentiellement anormal. Vous trouverez ci-dessous un exemple de ce à quoi devraient ressembler vos données formatées. Dans ce cas, l'identifiant de la première colonne est un identifiant d'instance et la deuxième colonne est une adresse IP associée, comme indiqué dans ce qui suit :
Une fois que vous avez vos données au format CSV, vous pouvez soumettre les données pour inférence à l'aide du code en lisant votre fichier .csv à partir d'un compartiment S3. :
Le résultat d’un modèle IP Insights fournit une mesure du degré d’attente statistique d’une adresse IP et d’une ressource en ligne. La plage de cette adresse et de cette ressource est toutefois illimitée. Il convient donc de prendre en compte la manière dont vous déterminerez si une combinaison d'ID d'instance et d'adresse IP doit être considérée comme anormale.
Dans l’exemple précédent, quatre combinaisons différentes d’identifiant et d’adresse IP ont été soumises au modèle. Les deux premières combinaisons étaient des combinaisons valides d’ID d’instance et d’adresse IP attendues en fonction de l’ensemble de formation. La troisième combinaison possède l'identifiant unique correct mais une adresse IP différente au sein du même sous-réseau. Le modèle doit déterminer qu'il existe une légère anomalie, car l'intégration est légèrement différente des données d'entraînement. La quatrième combinaison a un identifiant unique valide mais une adresse IP d'un sous-réseau inexistant dans n'importe quel VPC de l'environnement.
Remarque: Les données de trafic normal et anormal changeront en fonction de votre cas d'utilisation spécifique, par exemple : si vous souhaitez surveiller le trafic externe et interne, vous aurez besoin d'un identifiant unique aligné sur chaque adresse IP et d'un schéma pour générer les identifiants externes.
Pour déterminer quel devrait être votre seuil afin de déterminer si le trafic est anormal, vous pouvez utiliser le trafic normal et anormal connu. Les étapes décrites dans cet exemple de cahier sont les suivants:
- Construisez un ensemble de tests pour représenter le trafic normal.
- Ajoutez un trafic anormal dans l'ensemble de données.
- Tracer la distribution de
dot_productscores pour le modèle sur le trafic normal et le trafic anormal. - Sélectionnez une valeur seuil qui distingue le sous-ensemble normal du sous-ensemble anormal. Cette valeur est basée sur votre tolérance aux faux positifs
Configurez une surveillance continue du nouveau trafic des journaux de flux VPC.
Pour démontrer comment ce nouveau modèle ML pourrait être utilisé de manière proactive avec Amazon Security Lake, nous configurerons une fonction Lambda à appeler sur chaque PutObject événement dans le compartiment géré Amazon Security Lake, en particulier les données du journal de flux VPC. Dans Amazon Security Lake, il existe le concept d'abonné qui consomme les journaux et les événements d'Amazon Security Lake. La fonction Lambda qui répond aux nouveaux événements doit disposer d'un abonnement d'accès aux données. Les abonnés à l'accès aux données sont informés des nouveaux objets Amazon S3 pour une source lorsque les objets sont écrits dans le compartiment Security Lake. Les abonnés peuvent accéder directement aux objets S3 et recevoir des notifications de nouveaux objets via un point de terminaison d'abonnement ou en interrogeant une file d'attente Amazon SQS.
- Ouvrez le Console du lac de sécurité.
- Dans le volet de navigation, sélectionnez Abonnés.
- Sur la page Abonnés, choisissez Créer un abonné.
- Pour les détails de l'abonné, entrez
inferencelambdaen Nom de l'abonné et une option Description. - La Région est automatiquement défini comme votre région AWS actuellement sélectionnée et ne peut pas être modifié.
- Pour Sources de journaux et d'événements, choisissez Sources de journaux et d'événements spécifiques et choisissez Journaux de flux VPC et journaux Route 53
- Pour Méthode d'accès aux données, choisissez S3.
- Pour Identifiants de l'abonné, fournissez votre ID de compte AWS du compte où résidera la fonction Lambda et un identifiant spécifié par l'utilisateur. identifiant externe.
Remarque: Si vous effectuez cela localement au sein d’un compte, vous n’avez pas besoin d’avoir un identifiant externe. - Selectionnez Création.
Créer la fonction Lambda
Pour créer et déployer la fonction Lambda, vous pouvez soit effectuer les étapes suivantes, soit déployer le modèle SAM prédéfini 01_ipinsights/01.02-ipcheck.yaml dans le dépôt GitHub. Le modèle SAM nécessite que vous fournissiez l'ARN SQS et le nom du point de terminaison SageMaker.
- Sur la console Lambda, choisissez Créer une fonction.
- Selectionnez Auteur à partir de zéro.
- Pour Nom de la fonction, Entrer
ipcheck. - Pour Runtime, choisissez Python 3.10.
- Pour Architecture, sélectionnez x86_64.
- Pour Rôle d'exécution, sélectionnez Créer un nouveau rôle avec des autorisations Lambda.
- Après avoir créé la fonction, entrez le contenu du ipcheck.py fichier du dépôt GitHub.
- Dans le volet de navigation, choisissez Variables d'environnement.
- Selectionnez Modifier.
- Selectionnez Ajouter une variable d'environnement.
- Pour la nouvelle variable d'environnement, entrez
ENDPOINT_NAMEet pour valeur, entrez l'ARN du point de terminaison qui a été généré lors du déploiement du point de terminaison SageMaker. - Sélectionnez Épargnez.
- Selectionnez Déployer.
- Dans le volet de navigation, choisissez configuration.
- Sélectionnez triggers.
- Sélectionnez Ajouter un déclencheur.
- Sous Sélectionnez une source, choisissez SQS.
- Sous file d'attente SQS, saisissez l'ARN de la file d'attente SQS principale créée par Security Lake.
- Cochez la case pour Activer le déclencheur.
- Sélectionnez Ajouter.
Valider les résultats Lambda
- Ouvrez le Console Amazon CloudWatch.
- Dans le volet de gauche, sélectionnez Groupes de journaux.
- Dans la barre de recherche, saisissez ipcheck, puis sélectionnez le groupe de journaux portant le nom
/aws/lambda/ipcheck. - Sélectionnez le flux de journaux le plus récent sous Flux de journaux.
- Dans les journaux, vous devriez voir des résultats ressemblant à ce qui suit pour chaque nouveau journal Amazon Security Lake :
{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
Cette fonction Lambda analyse en permanence le trafic réseau ingéré par Amazon Security Lake. Cela vous permet de créer des mécanismes pour avertir vos équipes de sécurité lorsqu'un seuil spécifié est violé, ce qui indiquerait un trafic anormal dans votre environnement.
Nettoyer
Lorsque vous avez fini d'expérimenter cette solution et pour éviter des frais sur votre compte, nettoyez vos ressources en supprimant le compartiment S3, le point de terminaison SageMaker, en arrêtant le calcul attaché au bloc-notes SageMaker Jupyter, en supprimant la fonction Lambda et en désactivant Amazon Security. Lac dans votre compte.
Conclusion
Dans cet article, vous avez appris à préparer les données de trafic réseau provenant d'Amazon Security Lake pour l'apprentissage automatique, puis à former et déployer un modèle ML à l'aide de l'algorithme IP Insights dans Amazon SageMaker. Toutes les étapes décrites dans le notebook Jupyter peuvent être répliquées dans un pipeline ML de bout en bout. Vous avez également implémenté une fonction AWS Lambda qui a consommé de nouveaux journaux Amazon Security Lake et soumis des inférences basées sur le modèle de détection d'anomalies entraîné. Les réponses du modèle ML reçues par AWS Lambda pourraient informer de manière proactive les équipes de sécurité d'un trafic anormal lorsque certains seuils sont atteints. L'amélioration continue du modèle peut être rendue possible en incluant votre équipe de sécurité dans les analyses en boucle pour déterminer si le trafic identifié comme anormal était un faux positif ou non. Cela pourrait ensuite être ajouté à votre ensemble de formation et également ajouté à votre Ordinaire ensemble de données de trafic lors de la détermination d’un seuil empirique. Ce modèle peut identifier un trafic réseau ou un comportement potentiellement anormal et peut être inclus dans le cadre d'une solution de sécurité plus large pour lancer une vérification MFA si un utilisateur se connecte à partir d'un serveur inhabituel ou à un moment inhabituel, alerter le personnel en cas de problème suspect. analysez le réseau à partir de nouvelles adresses IP, ou combinez le score d'informations IP avec d'autres sources telles qu'Amazon Guard Duty pour classer les découvertes de menaces. Ce modèle peut inclure des sources de journaux personnalisées telles que les journaux Azure Flow ou des journaux sur site en ajoutant des sources personnalisées à votre déploiement Amazon Security Lake.
Dans la deuxième partie de cette série d'articles de blog, vous apprendrez à créer un modèle de détection d'anomalies à l'aide de Forêt coupée au hasard algorithme formé avec des sources Amazon Security Lake supplémentaires qui intègrent les données des journaux de sécurité du réseau et de l'hôte et appliquent la classification des anomalies de sécurité dans le cadre d'une solution de surveillance de sécurité automatisée et complète.
À propos des auteurs
 Joe Morotti est un architecte de solutions chez Amazon Web Services (AWS), aidant les clients d'entreprise à travers le Midwest américain. Il a occupé un large éventail de rôles techniques et aime montrer l'art du possible du client. Pendant son temps libre, il aime passer du temps de qualité avec sa famille à explorer de nouveaux endroits et à suranalyser les performances de son équipe sportive.
Joe Morotti est un architecte de solutions chez Amazon Web Services (AWS), aidant les clients d'entreprise à travers le Midwest américain. Il a occupé un large éventail de rôles techniques et aime montrer l'art du possible du client. Pendant son temps libre, il aime passer du temps de qualité avec sa famille à explorer de nouveaux endroits et à suranalyser les performances de son équipe sportive.
 Bishr Tabba est architecte de solutions chez Amazon Web Services. Bishr se spécialise dans l'aide aux clients avec des applications d'apprentissage automatique, de sécurité et d'observabilité. En dehors du travail, il aime jouer au tennis, cuisiner et passer du temps avec sa famille.
Bishr Tabba est architecte de solutions chez Amazon Web Services. Bishr se spécialise dans l'aide aux clients avec des applications d'apprentissage automatique, de sécurité et d'observabilité. En dehors du travail, il aime jouer au tennis, cuisiner et passer du temps avec sa famille.
 Sriharsh Adari est architecte de solutions senior chez Amazon Web Services (AWS), où il aide les clients à travailler à rebours des résultats commerciaux pour développer des solutions innovantes sur AWS. Au fil des ans, il a aidé plusieurs clients à transformer des plateformes de données dans des secteurs verticaux de l'industrie. Son domaine d'expertise principal comprend la stratégie technologique, l'analyse de données et la science des données. Dans ses temps libres, il aime jouer au tennis, regarder des émissions de télévision et jouer au tabla.
Sriharsh Adari est architecte de solutions senior chez Amazon Web Services (AWS), où il aide les clients à travailler à rebours des résultats commerciaux pour développer des solutions innovantes sur AWS. Au fil des ans, il a aidé plusieurs clients à transformer des plateformes de données dans des secteurs verticaux de l'industrie. Son domaine d'expertise principal comprend la stratégie technologique, l'analyse de données et la science des données. Dans ses temps libres, il aime jouer au tennis, regarder des émissions de télévision et jouer au tabla.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/identify-cybersecurity-anomalies-in-your-amazon-security-lake-data-using-amazon-sagemaker/

