De nombreux clients ont besoin d'un lac de données de transaction ACID (atomique, cohérent, isolé, durable) qui peut enregistrer la capture de données modifiées (CDC) à partir de sources de données opérationnelles. Il existe également une demande pour fusionner des données en temps réel dans des données par lots. Le framework Delta Lake fournit ces deux fonctionnalités. Dans cet article, nous expliquons comment gérer les UPSERT (mises à jour et insertions) des données opérationnelles à l'aide de Delta Lake intégré nativement avec Colle AWS, et interrogez le lac Delta à l'aide de Amazone Athéna.
Nous examinons une organisation d'assurance hypothétique qui émet des polices commerciales pour les petites et moyennes entreprises. Les prix des assurances varient en fonction de plusieurs critères, tels que l'emplacement de l'entreprise, le type d'entreprise, la couverture contre les tremblements de terre ou les inondations, etc. Cette organisation envisage de créer une plate-forme d'analyse de données, et les données des polices d'assurance sont l'une des entrées de cette plate-forme. Parce que l'entreprise se développe, des centaines et des milliers de nouvelles polices d'assurance sont souscrites et renouvelées chaque mois. Par conséquent, toutes ces données opérationnelles doivent être envoyées à Delta Lake en temps quasi réel afin que l'organisation puisse effectuer diverses analyses et créer des modèles d'apprentissage automatique (ML) pour servir ses clients de manière plus efficace et plus rentable.
Vue d'ensemble de la solution
Les données peuvent provenir de n'importe quelle source, mais les clients souhaitent généralement apporter des données opérationnelles aux lacs de données pour effectuer des analyses de données. Une des solutions est d'amener les données relationnelles en utilisant Service de migration de base de données AWS (AWS DMS). Les tâches AWS DMS peuvent être configurées pour copier la charge complète ainsi que les modifications en cours (CDC). La charge complète et la charge CDC peuvent être transférées dans les couches de stockage brutes et organisées (Delta Lake) du lac de données. Pour faire simple, dans cet article, nous désactivons les sources de données et la couche d'ingestion ; l'hypothèse est que les données sont déjà copiées dans le bucket brut sous la forme de fichiers CSV. Une tâche ETL AWS Glue effectue la transformation nécessaire et copie les données dans la couche Delta Lake. La couche Delta Lake garantit la conformité ACID des données source.
Le diagramme suivant illustre l'architecture de la solution.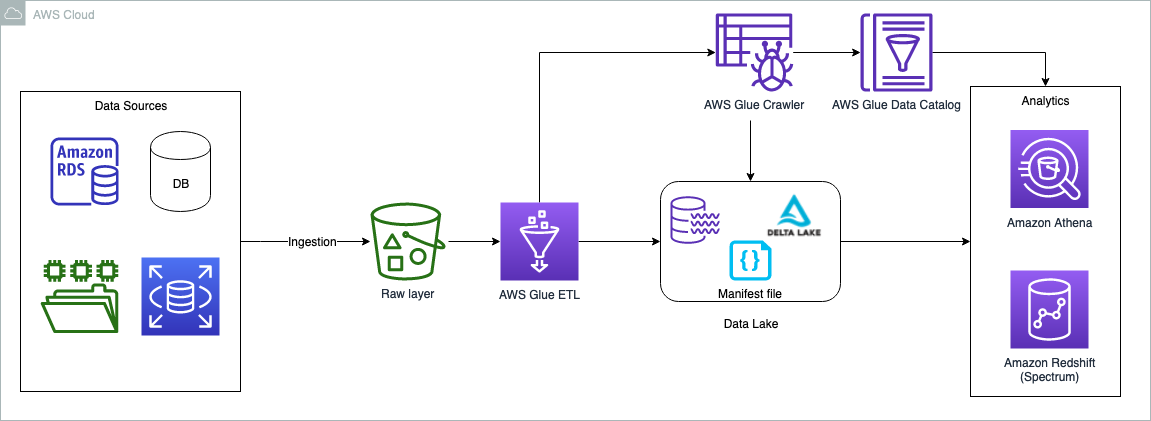
Le cas d'utilisation que nous utilisons dans cet article concerne une compagnie d'assurance commerciale. Nous utilisons un jeu de données simple qui contient les colonnes suivantes :
- Politique – Numéro de police, saisi sous forme de texte
- Expiration – Date d'expiration de la police
- Localisation – Type d'emplacement (urbain ou rural)
- Région - Nom de l'état où se trouve la propriété
- Région – Région géographique où se situe le bien
- Valeur assurée - Valeur de la propriété
- Type d'entreprise – Type d'utilisation commerciale de la propriété, comme l'agriculture ou la vente au détail
- Tremblement de terre – La couverture sismique est-elle incluse (O ou N)
- Inondation – La couverture contre les inondations est-elle incluse (O ou N)
L'ensemble de données contient un échantillon de 25 polices d'assurance. Dans le cas d'un jeu de données de production, il peut contenir des millions d'enregistrements.
Dans les sections suivantes, nous passons en revue les étapes pour effectuer les opérations Delta Lake UPSERT. Nous utilisons le Console de gestion AWS pour effectuer toutes les étapes. Cependant, vous pouvez également automatiser ces étapes à l'aide d'outils tels que AWS CloudFormation, Kit de développement AWS Cloud (AWS CDK), Terraforms, etc.
Pré-requis
Ce poste est destiné aux architectes, ingénieurs, développeurs et scientifiques des données qui créent, conçoivent et créent des solutions analytiques sur AWS. Nous attendons une compréhension de base de la console, AWS Glue, Service de stockage simple Amazon (Amazon S3) et Athéna. De plus, le personnage est capable de créer Gestion des identités et des accès AWS (IAM) des stratégies et des rôles, créer et exécuter des tâches et des robots AWS Glue, et est capable de travailler avec l'éditeur de requêtes Athena.
Utilisez la version 3 du moteur de requête Athena pour interroger les tables de lac delta, plus loin dans la section "Interroger la charge complète à l'aide d'Athena".
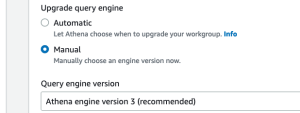
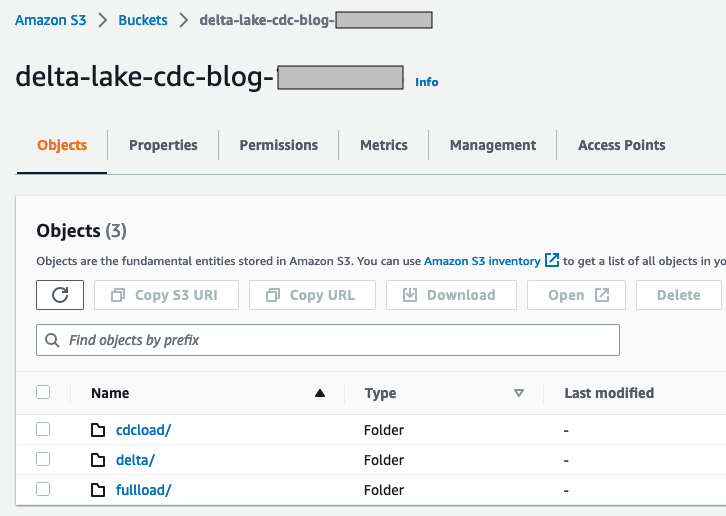
Configurer un compartiment S3 pour les flux de données de chargement complet et CDC
Pour configurer votre bucket S3, procédez comme suit :
- Connectez-vous à votre compte AWS et choisissez une région la plus proche de vous.
- Sur la console Amazon S3, créez un nouveau compartiment. Assurez-vous que le nom est unique (par exemple,
delta-lake-cdc-blog-<some random number>). - Créez les dossiers suivants :
- $bucket_name/chargement complet – Ce dossier est utilisé pour un chargement complet unique à partir de la source de données en amont
- $bucket_name/cdcload – Ce dossier est utilisé pour copier les modifications de données en amont
- $bucket_name/delta – Ce dossier contient les fichiers de données Delta Lake
- Copiez l'exemple de jeu de données et enregistrez-le dans un fichier appelé
full-load.csvà votre machine locale. - Téléchargez le fichier à l'aide de la console Amazon S3 dans le dossier
$bucket_name/fullload.
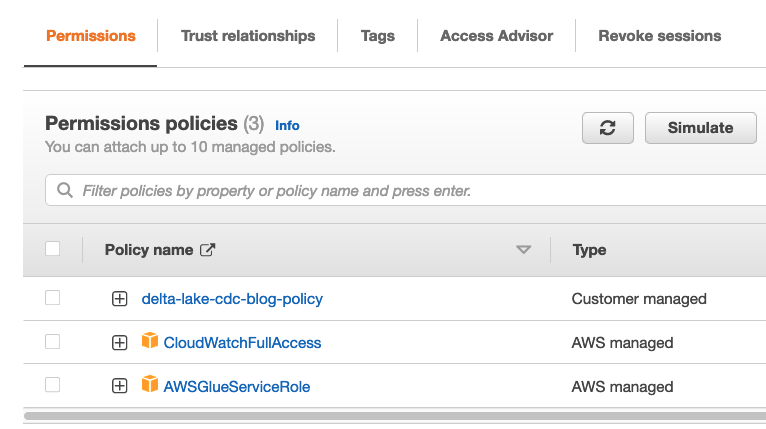
Configurer une stratégie et un rôle IAM
Dans cette section, nous créons une stratégie IAM pour l'accès au compartiment S3 et un rôle pour les tâches AWS Glue à exécuter, et utilisons également le même rôle pour interroger le Delta Lake à l'aide d'Athena.
- Sur la console IAM, choisissez Politiques dans le volet de navigation.
- Selectionnez Créer une politique.
- Sélectionnez JSON et collez le code de stratégie suivant. Remplace le
{bucket_name}que vous avez créé à l'étape précédente.
- Nommer la politique
delta-lake-cdc-blog-policyet sélectionnez Créer une politique. - Sur la console IAM, choisissez Rôles dans le volet de navigation.
- Selectionnez Créer un rôle.
- Sélectionnez AWS Glue comme entité de confiance et choisissez Suivant.
- Sélectionnez la stratégie que vous venez de créer, et avec deux stratégies gérées AWS supplémentaires :
delta-lake-cdc-blog-policyAWSGlueServiceRoleCloudWatchFullAccess
- Selectionnez Suivant.
- Donnez un nom au rôle (par exemple,
delta-lake-cdc-blog-role).
Configurer des tâches AWS Glue
Dans cette section, nous configurons deux tâches AWS Glue : une pour le chargement complet et une pour le chargement CDC. Commençons par le travail de chargement complet.
- Sur la console AWS Glue, sous Intégration de données et ETL dans le volet de navigation, choisissez Emplois. AWS Glue Studio s'ouvre dans un nouvel onglet.
- Sélectionnez Éditeur de script Spark et choisissez Création.
- Dans l'éditeur de script, remplacez le code par l'extrait de code suivant
- Accédez à la Détails du poste languette.
- Indiquez un nom pour la tâche (par exemple,
Full-Load-Job). - Pour Rôle IAM¸ choisissez le rôle
delta-lake-cdc-blog-roleque vous avez créé plus tôt. - Pour Type de travailleur¸ choisissez G 2X.
- Pour Signet d'emploi, choisissez Désactiver.
- Ensemble Nombre de tentatives à 0.
- Sous Propriétés avancées¸ conserver les valeurs par défaut, mais fournir le chemin du fichier JAR delta core pour Chemin de la bibliothèque Python et les Chemin des fichiers JAR dépendants.
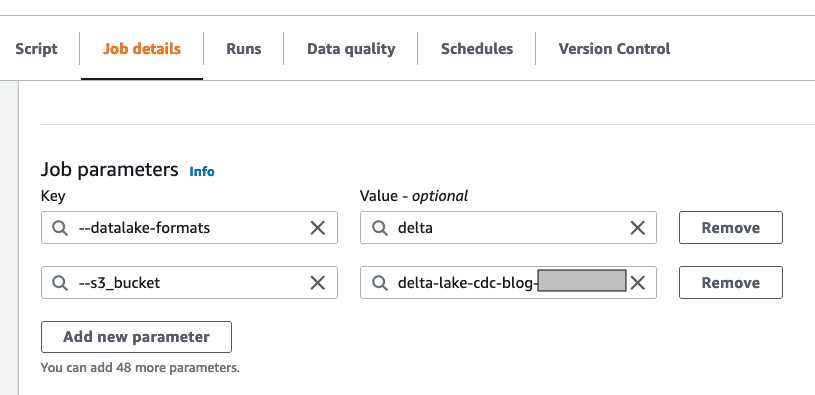
- Sous Paramètres de la tâche :
- Ajouter la clé
--s3_bucketavec le nom de compartiment que vous avez créé précédemment comme valeur. - Ajouter la clé
--datalake-formatset donner la valeurdelta
- Ajouter la clé
- Conservez les valeurs par défaut restantes et choisissez Épargnez.
Créons maintenant la tâche de chargement CDC.
- Créez une deuxième tâche appelée
CDC-Load-Job. - Suivez les étapes sur le Détails du poste onglet comme pour le travail précédent.
- Alternativement, vous pouvez choisir l'option "Travail de clonage" dans le travail à chargement complet, cela contiendra tous les détails du travail à partir du travail à chargement complet.
- Dans l'éditeur de script, saisissez l'extrait de code suivant pour la logique CDC :
import sys
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.sql.session import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.functions import expr ## For Delta lake
from delta.tables import DeltaTable ## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME','s3_bucket']) # Initialize Spark Session with Delta Lake
spark = SparkSession .builder .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") .getOrCreate() # Read the CDC load
cdc_df = spark.read.csv("s3://"+ args['s3_bucket']+"/cdcload")
cdc_df.show(5,True) # now read the full load (latest data) as delta table
delta_df = DeltaTable.forPath(spark, "s3://"+ args['s3_bucket']+"/delta/insurance/")
delta_df.toDF().show(5,True) # UPSERT process if matches on the condition the update else insert
# if there is no keyword then create a data set with Insert, Update and Delete flag and do it separately.
# for delete it has to run in loop with delete condition, this script do not handle deletes. final_df = delta_df.alias("prev_df").merge( source = cdc_df.alias("append_df"), #matching on primarykey
condition = expr("prev_df.policy_id = append_df._c1"))
.whenMatchedUpdate(set= { "prev_df.expiry_date" : col("append_df._c2"), "prev_df.location_name" : col("append_df._c3"), "prev_df.state_code" : col("append_df._c4"), "prev_df.region_name" : col("append_df._c5"), "prev_df.insured_value" : col("append_df._c6"), "prev_df.business_type" : col("append_df._c7"), "prev_df.earthquake_coverage" : col("append_df._c8"), "prev_df.flood_coverage" : col("append_df._c9")} )
.whenNotMatchedInsert(values =
#inserting a new row to Delta table
{ "prev_df.policy_id" : col("append_df._c1"), "prev_df.expiry_date" : col("append_df._c2"), "prev_df.location_name" : col("append_df._c3"), "prev_df.state_code" : col("append_df._c4"), "prev_df.region_name" : col("append_df._c5"), "prev_df.insured_value" : col("append_df._c6"), "prev_df.business_type" : col("append_df._c7"), "prev_df.earthquake_coverage" : col("append_df._c8"), "prev_df.flood_coverage" : col("append_df._c9")
})
.execute()
Exécuter la tâche de chargement complet
Sur la console AWS Glue, ouvrez full-load-job et choisissez Courir. La tâche prend environ 2 minutes pour se terminer et l'état d'exécution de la tâche passe à Réussi. Aller à $bucket_name et ouvrez le delta dossier, qui contient le dossier d'assurance. Vous pouvez y noter les fichiers Delta Lake. 
Créer et exécuter le robot d'exploration AWS Glue
Dans cette étape, nous créons un robot d'exploration AWS Glue avec Delta Lake comme type de source de données. Après avoir exécuté avec succès le robot d'exploration, nous inspectons les données à l'aide d'Athena.
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Selectionnez Créer un robot.
- Indiquez un nom (par exemple,
delta-lake-crawler) et choisissez Suivant. - Selectionnez Ajouter une source de données et choisissez Delta Lake comme source de données.
- Copiez l'URI de votre dossier delta (par exemple,
s3://delta-lake-cdc-blog-123456789/delta/insurance) et entrez l'emplacement du chemin de la table Delta Lake. - Conserver la sélection par défaut Créer des tables nativeset choisissez Ajouter une source de données Delta Lake.
- Selectionnez Suivant.
- Choisissez le rôle IAM que vous avez créé précédemment, puis choisissez Suivant.
- Sélectionnez le
defaultbase de données cible et fournirdelta_pour le préfixe du nom de table. Sinondefaultbase de données existe, vous pouvez en créer une. - Selectionnez Suivant.
- Selectionnez Créer un robot.
- Exécutez le robot d'exploration nouvellement créé. Une fois le robot d'exploration terminé, le
delta_insurancele tableau est disponible sousDatabases/Tables. - Ouvrez le tableau pour vérifier l'aperçu du tableau.
Vous pouvez observer neuf colonnes et leurs types de données. 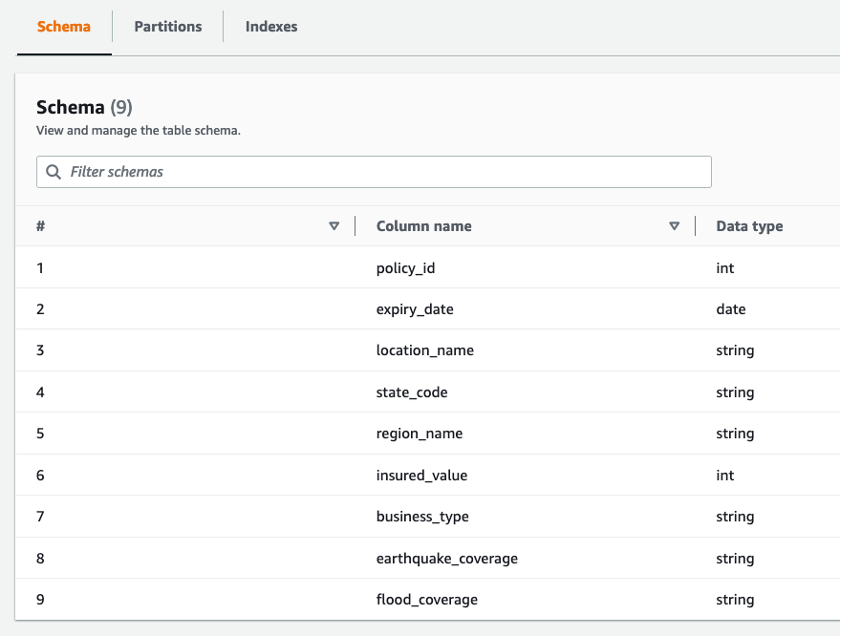
Interroger la charge complète à l'aide d'Athena
Dans l'étape précédente, nous avons créé le delta_insurance table en exécutant un robot sur l'emplacement de Delta Lake. Dans cette section, nous interrogeons les delta_insurance table à l'aide d'Athéna. Notez que si vous utilisez Athena pour la première fois, définissez le dossier de sortie de la requête pour stocker les résultats de la requête Athena (par exemple, s3://<your-s3-bucket>/query-output/).
- Sur la console Athena, ouvrez l'éditeur de requête.
- Conservez les sélections par défaut pour Source de données et Base de données.
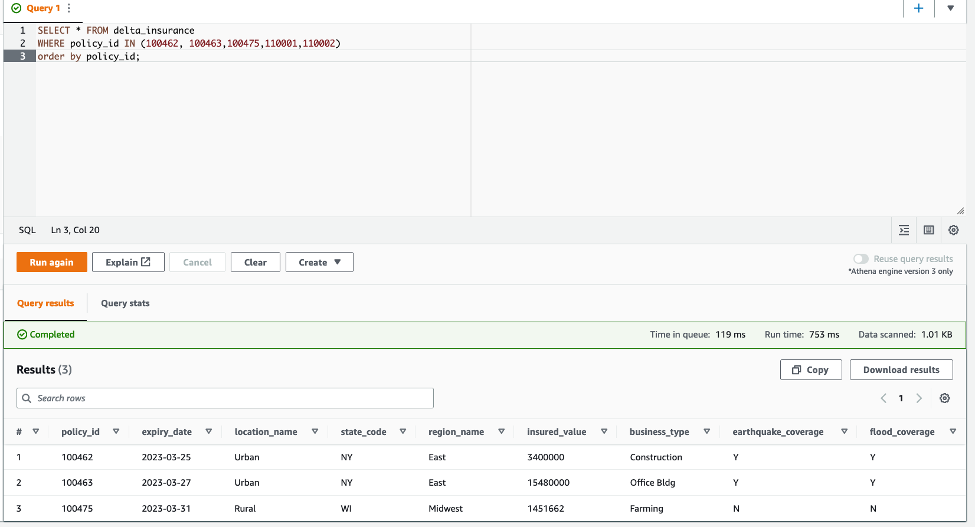
- Exécuter la requête
SELECT * FROM delta_insurance;. Cette requête renvoie un total de 25 lignes, ce qui correspond à ce qui se trouvait dans le flux de données à chargement complet. - Pour la comparaison CDC, exécutez la requête suivante et stockez les résultats dans un emplacement où vous pourrez comparer ces résultats ultérieurement :
La capture d'écran suivante montre le résultat de la requête Athena.
Téléchargez le flux de données CDC et exécutez la tâche CDC
Dans cette section, nous mettons à jour trois polices d'assurance et insérons deux nouvelles polices.
- Copiez les données de police d'assurance suivantes et enregistrez-les localement sous
cdc-load.csv:
La première colonne du flux CDC décrit les opérations UPSERT. U sert à mettre à jour un enregistrement existant, et I sert à insérer un nouvel enregistrement.
- Téléchargez le fichier cdc-load.csv sur le
$bucket_name/cdcload/dossier. - Sur la console AWS Glue, exécutez
CDC-Load-Job. Ce travail s'occupe de mettre à jour le Delta Lake en conséquence.
Les détails du changement sont les suivants :
- 100462 – La date d'expiration passe au 12/31/2024
- 100463 – La valeur assurée passe à 1 million
- 100475 – Cette politique est maintenant sous une nouvelle zone inondable
- 110001 et 110002 – Nouvelles politiques ajoutées au tableau
- Exécutez à nouveau la requête :
Comme illustré dans la capture d'écran suivante, les modifications apportées au flux de données CDC sont reflétées dans les résultats de la requête Athena.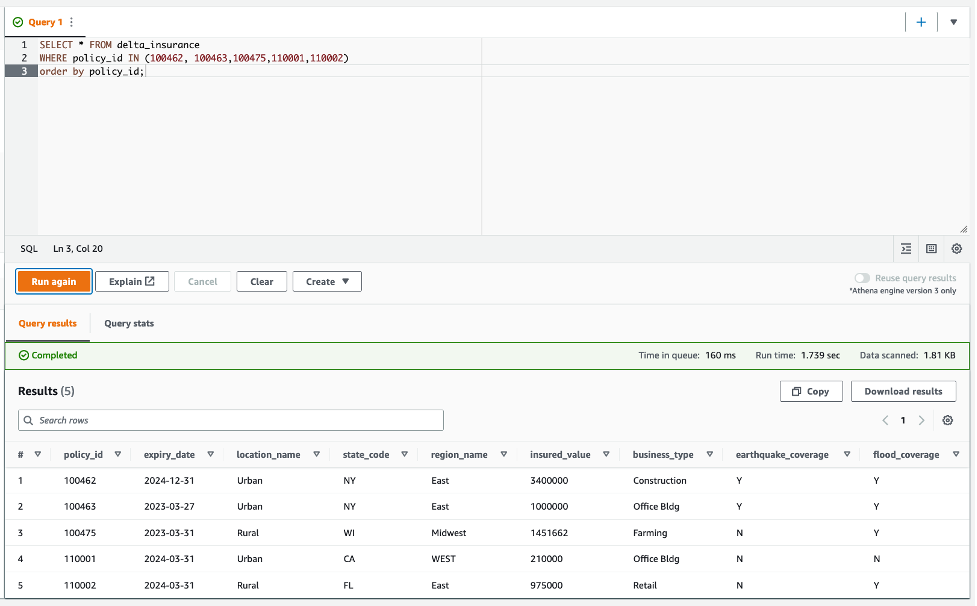
Nettoyer
Dans cette solution, nous avons utilisé tous les services gérés, et il n'y a aucun coût si les tâches AWS Glue ne sont pas en cours d'exécution. Toutefois, si vous souhaitez nettoyer les tâches, vous pouvez supprimer les deux tâches AWS Glue, la table AWS Glue et le compartiment S3.
Conclusion
Les organisations recherchent en permanence des solutions analytiques hautes performances, rentables et évolutives pour extraire la valeur de leurs sources de données opérationnelles en temps quasi réel. La plate-forme d'analyse doit être prête à recevoir les modifications des données opérationnelles dès qu'elles se produisent. Les solutions typiques de lac de données sont confrontées à des défis pour gérer les changements dans les données source ; le cadre Delta Lake peut combler cette lacune. Cet article a montré comment créer des lacs de données pour les opérations UPSERT à l'aide d'AWS Glue et des tables Delta Lake natives, et comment interroger les tables AWS Glue à partir d'Athena. Vous pouvez mettre en œuvre vos opérations de données UPSERT à grande échelle à l'aide d'AWS Glue, Delta Lake et effectuer des analyses à l'aide d'Amazon Athena.
Bibliographie
À propos des auteurs
 Praveen Allam est architecte de solutions chez AWS. Il aide les clients à concevoir des applications d'entreprise évolutives et plus rentables à l'aide du cloud AWS. Il développe des solutions pour aider les organisations à prendre des décisions basées sur les données.
Praveen Allam est architecte de solutions chez AWS. Il aide les clients à concevoir des applications d'entreprise évolutives et plus rentables à l'aide du cloud AWS. Il développe des solutions pour aider les organisations à prendre des décisions basées sur les données.
 Vivek Singh est architecte de solutions senior au sein de l'équipe AWS Data Lab. Il aide les clients à débloquer leur parcours de données sur l'écosystème AWS. Ses domaines d'intérêt sont l'automatisation des pipelines de données, la qualité et la gouvernance des données, les lacs de données et les architectures Lake House.
Vivek Singh est architecte de solutions senior au sein de l'équipe AWS Data Lab. Il aide les clients à débloquer leur parcours de données sur l'écosystème AWS. Ses domaines d'intérêt sont l'automatisation des pipelines de données, la qualité et la gouvernance des données, les lacs de données et les architectures Lake House.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/handle-upsert-data-operations-using-open-source-delta-lake-and-aws-glue/

