L’IA générative a ouvert de nombreux potentiels dans le domaine de l’IA. Nous constatons de nombreuses utilisations, notamment la génération de texte, la génération de code, le résumé, la traduction, les chatbots, etc. L'un de ces domaines en évolution est l'utilisation du traitement du langage naturel (NLP) pour ouvrir de nouvelles opportunités d'accès aux données via des requêtes SQL intuitives. Au lieu de traiter un code technique complexe, les utilisateurs professionnels et les analystes de données peuvent poser des questions liées aux données et aux informations dans un langage simple. L'objectif principal est de générer automatiquement des requêtes SQL à partir de texte en langage naturel. Pour ce faire, le texte saisi est transformé en une représentation structurée, et à partir de cette représentation, une requête SQL pouvant être utilisée pour accéder à une base de données est créée.
Dans cet article, nous proposons une introduction au texte vers SQL (Text2SQL) et explorons les cas d'utilisation, les défis, les modèles de conception et les meilleures pratiques. Plus précisément, nous discutons des points suivants :
- Pourquoi avons-nous besoin de Text2SQL
- Composants clés pour Text to SQL
- Considérations d'ingénierie rapides pour le langage naturel ou Text to SQL
- Optimisations et bonnes pratiques
- Modèles architecturaux
Pourquoi avons-nous besoin de Text2SQL ?
Aujourd'hui, une grande quantité de données est disponible dans les analyses de données traditionnelles, l'entreposage de données et les bases de données, qui peuvent être difficiles à interroger ou à comprendre pour la majorité des membres de l'organisation. L'objectif principal de Text2SQL est de rendre les bases de données d'interrogation plus accessibles aux utilisateurs non techniques, qui peuvent fournir leurs requêtes en langage naturel.
NLP SQL permet aux utilisateurs professionnels d'analyser les données et d'obtenir des réponses en tapant ou en posant des questions en langage naturel, telles que les suivantes :
- "Afficher les ventes totales pour chaque produit le mois dernier"
- « Quels produits ont généré le plus de revenus ? »
- « Quel pourcentage de clients proviennent de chaque région ? »
Socle amazonien est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances via une seule API, permettant de créer et de faire évoluer facilement des applications Gen AI. Il peut être exploité pour générer des requêtes SQL basées sur des questions similaires à celles répertoriées ci-dessus, interroger des données structurées organisationnelles et générer des réponses en langage naturel à partir des données de réponse aux requêtes.
Composants clés pour le texte vers SQL
Les systèmes Text-to-SQL impliquent plusieurs étapes pour convertir les requêtes en langage naturel en SQL exécutable :
- Traitement du langage naturel :
- Analyser la requête de saisie de l'utilisateur
- Extraire les éléments clés et l'intention
- Convertir en format structuré
- Génération SQL :
- Mapper les détails extraits dans la syntaxe SQL
- Générer une requête SQL valide
- Requête de base de données :
- Exécutez la requête SQL générée par l'IA sur la base de données
- Récupérer les résultats
- Renvoie les résultats à l'utilisateur
Une capacité remarquable des grands modèles linguistiques (LLM) est la génération de code, y compris le langage de requête structuré (SQL) pour les bases de données. Ces LLM peuvent être exploités pour comprendre la question du langage naturel et générer une requête SQL correspondante en sortie. Les LLM bénéficieront de l’adoption de paramètres d’apprentissage et de réglage en contexte à mesure que davantage de données seront fournies.
Le diagramme suivant illustre un flux Text2SQL de base.

Considérations d'ingénierie rapides pour le langage naturel vers SQL
L'invite est cruciale lors de l'utilisation de LLM pour traduire le langage naturel en requêtes SQL, et il existe plusieurs considérations importantes pour l'ingénierie des invites.
Efficace ingénierie rapide est la clé du développement du langage naturel pour les systèmes SQL. Des invites claires et simples fournissent de meilleures instructions pour le modèle de langage. Fournir le contexte indiquant que l'utilisateur demande une requête SQL ainsi que les détails pertinents du schéma de base de données permet au modèle de traduire l'intention avec précision. L'inclusion de quelques exemples annotés d'invites en langage naturel et de requêtes SQL correspondantes aide à guider le modèle pour produire une sortie conforme à la syntaxe. De plus, l'intégration de la génération augmentée de récupération (RAG), dans laquelle le modèle récupère des exemples similaires pendant le traitement, améliore encore la précision de la cartographie. Des invites bien conçues qui donnent au modèle suffisamment d'instructions, de contexte, d'exemples et d'augmentation de la récupération sont essentielles pour traduire de manière fiable le langage naturel en requêtes SQL.
Ce qui suit est un exemple d'invite de base avec une représentation du code de la base de données du livre blanc Amélioration des capacités de conversion texte vers SQL des grands modèles de langage : une étude sur les stratégies de conception d'invites.
Comme illustré dans cet exemple, l'apprentissage en quelques étapes basé sur des invites fournit au modèle une poignée d'exemples annotés dans l'invite elle-même. Cela démontre le mappage cible entre le langage naturel et SQL pour le modèle. En règle générale, l'invite contient environ 2 à 3 paires affichant une requête en langage naturel et l'instruction SQL équivalente. Ces quelques exemples guident le modèle pour générer des requêtes SQL conformes à la syntaxe à partir d'un langage naturel sans nécessiter de données de formation approfondies.
Mise au point ou ingénierie rapide
Lors de la création d'un langage naturel pour les systèmes SQL, nous discutons souvent de la question de savoir si le réglage fin du modèle est la bonne technique ou si une ingénierie efficace des invites est la voie à suivre. Les deux approches pourraient être envisagées et sélectionnées en fonction du bon ensemble d’exigences :
-
- Réglage fin – Le modèle de base est pré-entraîné sur un grand corpus de texte général et peut ensuite utiliser réglage fin basé sur des instructions, qui utilise des exemples étiquetés pour améliorer les performances d'un modèle de base pré-entraîné sur text-SQL. Cela adapte le modèle à la tâche cible. Le réglage fin entraîne directement le modèle sur la tâche finale, mais nécessite de nombreux exemples texte-SQL. Vous pouvez utiliser le réglage fin supervisé basé sur votre LLM pour améliorer l'efficacité du texte vers SQL. Pour cela, vous pouvez utiliser plusieurs jeux de données comme Spider, WikiSQL, CHASSE, OISEAU-SQLou CoSQL.
- Ingénierie rapide – Le modèle est entraîné à compléter les invites conçues pour demander la syntaxe SQL cible. Lors de la génération de SQL à partir d'un langage naturel à l'aide de LLM, il est important de fournir des instructions claires dans l'invite pour contrôler la sortie du modèle. Dans l'invite, annotez différents composants, comme pointer vers des colonnes, un schéma, puis indiquez quel type de SQL créer. Celles-ci agissent comme des instructions qui indiquent au modèle comment formater la sortie SQL. L'invite suivante montre un exemple dans lequel vous pointez des colonnes de table et demandez à créer une requête MySQL :
Une approche efficace pour les modèles texte-SQL consiste à commencer par un LLM de base sans aucun réglage spécifique à la tâche. Des invites bien conçues peuvent ensuite être utilisées pour adapter et piloter le modèle de base afin de gérer le mappage texte vers SQL. Cette ingénierie rapide vous permet de développer la capacité sans avoir besoin de procéder à des réglages précis. Si l’ingénierie rapide sur le modèle de base n’atteint pas une précision suffisante, un réglage fin sur un petit ensemble d’exemples texte-SQL peut alors être exploré ainsi qu’une ingénierie rapide plus poussée.
La combinaison d'un réglage fin et d'une ingénierie rapide peut être nécessaire si l'ingénierie rapide sur le modèle brut pré-entraîné à elle seule ne répond pas aux exigences. Cependant, il est préférable de tenter dans un premier temps une ingénierie rapide sans réglage fin, car cela permet une itération rapide sans collecte de données. Si cela ne parvient pas à fournir des performances adéquates, un réglage fin parallèlement à une ingénierie rapide est une prochaine étape viable. Cette approche globale maximise l'efficacité tout en permettant la personnalisation si les méthodes purement basées sur des invites s'avèrent insuffisantes.
Optimisation et bonnes pratiques
L'optimisation et les meilleures pratiques sont essentielles pour améliorer l'efficacité et garantir que les ressources sont utilisées de manière optimale et que les bons résultats sont obtenus de la meilleure façon possible. Les techniques aident à améliorer les performances, à contrôler les coûts et à obtenir un résultat de meilleure qualité.
Lors du développement de systèmes texte-vers-SQL à l’aide de LLM, les techniques d’optimisation peuvent améliorer les performances et l’efficacité. Voici quelques domaines clés à considérer :
- Cache haute performance – Pour améliorer la latence, le contrôle des coûts et la standardisation, vous pouvez mettre en cache le SQL analysé et les invites de requête reconnues à partir du LLM texte vers SQL. Cela évite de retraiter des requêtes répétées.
- Le Monitoring – Les journaux et les métriques concernant l'analyse des requêtes, la reconnaissance rapide, la génération SQL et les résultats SQL doivent être collectés pour surveiller le système LLM texte vers SQL. Cela fournit une visibilité pour l'exemple d'optimisation mettant à jour l'invite ou revisitant le réglage fin avec un ensemble de données mis à jour.
- Vues matérialisées vs tables – Les vues matérialisées peuvent simplifier la génération SQL et améliorer les performances des requêtes texte vers SQL courantes. L'interrogation directe des tables peut entraîner un SQL complexe et également entraîner des problèmes de performances, notamment la création constante de techniques de performances telles que les index. De plus, vous pouvez éviter les problèmes de performances lorsque la même table est utilisée simultanément pour d’autres domaines d’application.
- Actualisation des données – Les vues matérialisées doivent être actualisées selon un calendrier afin de maintenir les données à jour pour les requêtes texte vers SQL. Vous pouvez utiliser des approches d’actualisation par lots ou incrémentielles pour équilibrer les frais généraux.
- Catalogue de données central – La création d’un catalogue de données centralisé fournit une vue d’ensemble unique des sources de données d’une organisation et aidera les LLM à sélectionner les tables et les schémas appropriés afin de fournir des réponses plus précises. Vecteur plongements créés à partir d'un catalogue de données central peuvent être fournis à un LLM avec les informations demandées pour générer des réponses SQL pertinentes et précises.
En appliquant les meilleures pratiques d'optimisation telles que la mise en cache, la surveillance, les vues matérialisées, l'actualisation programmée et un catalogue central, vous pouvez améliorer considérablement les performances et l'efficacité des systèmes texte-vers-SQL à l'aide des LLM.
Modèles architecturaux
Examinons quelques modèles d'architecture qui peuvent être implémentés pour un flux de travail texte vers SQL.
Ingénierie rapide
Le diagramme suivant illustre l'architecture de génération de requêtes avec un LLM à l'aide de l'ingénierie d'invite.
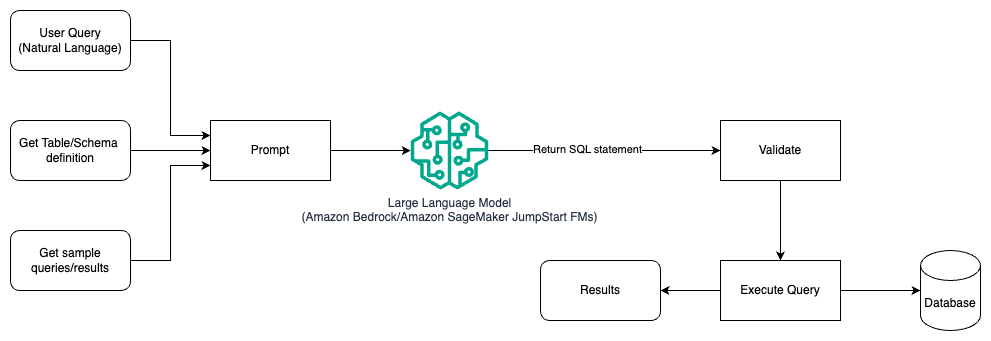
Dans ce modèle, l'utilisateur crée un apprentissage en quelques étapes basé sur des invites qui fournit au modèle des exemples annotés dans l'invite elle-même, qui incluent les détails de la table et du schéma ainsi que quelques exemples de requêtes avec ses résultats. Le LLM utilise l'invite fournie pour renvoyer le SQL généré par l'IA, qui est validé puis exécuté sur la base de données pour obtenir les résultats. Il s’agit du modèle le plus simple pour démarrer en utilisant l’ingénierie rapide. Pour cela, vous pouvez utiliser Socle amazonien or modèles de fondation in Amazon SageMaker JumpStart.
Dans ce modèle, l'utilisateur crée un apprentissage en quelques étapes basé sur une invite qui fournit au modèle des exemples annotés dans l'invite elle-même, qui inclut les détails de la table et du schéma ainsi que quelques exemples de requêtes avec ses résultats. Le LLM utilise l'invite fournie pour renvoyer le SQL généré par l'IA qui est validé et exécuté sur la base de données pour obtenir les résultats. Il s’agit du modèle le plus simple pour démarrer en utilisant l’ingénierie rapide. Pour cela, vous pouvez utiliser Socle amazonien qui est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances provenant de grandes sociétés d'IA via une API unique, ainsi qu'un large ensemble de fonctionnalités dont vous avez besoin pour créer des applications d'IA génératives avec sécurité, confidentialité et IA responsable ou Modèles de fondation JumpStart qui propose des modèles de base de pointe pour des cas d'utilisation tels que la rédaction de contenu, la génération de code, la réponse aux questions, la rédaction, le résumé, la classification, la récupération d'informations, etc.
Ingénierie et mise au point rapides
Le diagramme suivant illustre l'architecture permettant de générer des requêtes avec un LLM à l'aide d'une ingénierie et d'un réglage rapides.
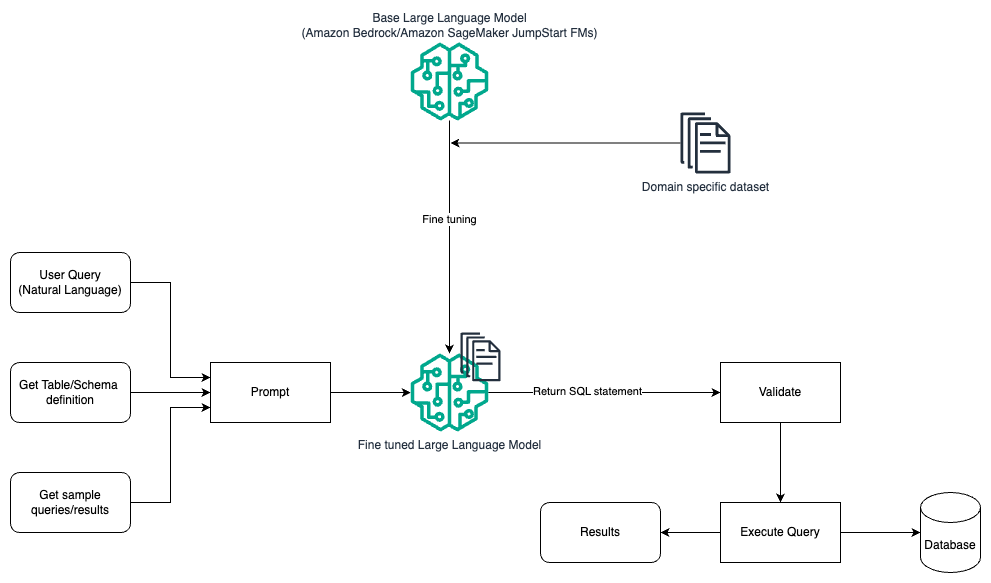
Ce flux est similaire au modèle précédent, qui repose principalement sur une ingénierie rapide, mais avec un flux supplémentaire de réglage fin sur l'ensemble de données spécifique au domaine. Le LLM affiné est utilisé pour générer les requêtes SQL avec une valeur contextuelle minimale pour l'invite. Pour cela, vous pouvez utiliser SageMaker JumpStart pour affiner un LLM sur un ensemble de données spécifique à un domaine de la même manière que vous entraîneriez et déploieriez n'importe quel modèle sur Amazon Sage Maker.
Ingénierie rapide et RAG
Le diagramme suivant illustre l'architecture permettant de générer des requêtes avec un LLM à l'aide de l'ingénierie d'invite et de RAG.
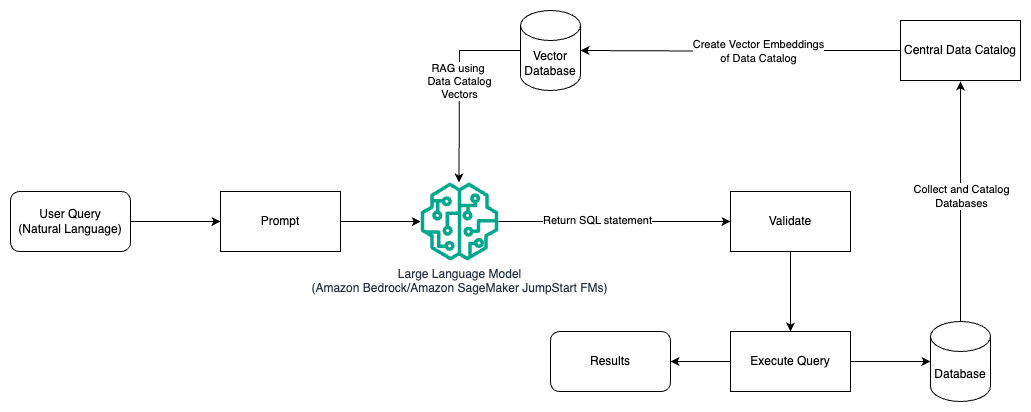
Dans ce modèle, nous utilisons Récupération Génération Augmentée en utilisant des magasins d'intégrations vectorielles, comme Intégrations Amazon Titan or Cohérer Intégrer, Sur Socle amazonien à partir d'un catalogue de données central, comme Colle AWS Catalogue de données, de bases de données au sein d’une organisation. Les représentations vectorielles sont stockées dans des bases de données vectorielles telles que Moteur vectoriel pour Amazon OpenSearch sans serveur, Amazon Relational Database Service (Amazon RDS) pour PostgreSQL les pgvecteur prolongation, ou Amazone Kendra. Les LLM utilisent les intégrations vectorielles pour sélectionner plus rapidement la bonne base de données, les tables et les colonnes des tables lors de la création de requêtes SQL. L'utilisation de RAG est utile lorsque les données et les informations pertinentes qui doivent être récupérées par les LLM sont stockées dans plusieurs systèmes de bases de données distincts et que le LLM doit être capable de rechercher ou d'interroger des données à partir de tous ces différents systèmes. C'est là que la fourniture d'intégrations vectorielles d'un catalogue de données centralisé ou unifié aux LLM permet d'obtenir des informations plus précises et plus complètes renvoyées par les LLM.
Conclusion
Dans cet article, nous avons expliqué comment générer de la valeur à partir des données d'entreprise en utilisant le langage naturel jusqu'à la génération SQL. Nous avons examiné les composants clés, l'optimisation et les meilleures pratiques. Nous avons également appris des modèles d'architecture, de l'ingénierie d'invite de base au réglage fin et au RAG. Pour en savoir plus, reportez-vous à Socle amazonien pour créer et faire évoluer facilement des applications d'IA générative avec des modèles de base
À propos des auteurs
 Randy DeFauw est architecte principal principal de solutions chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. In est entré dans l'espace Big Data en 2013 et continue d'explorer ce domaine. Il travaille activement sur des projets dans l'espace ML et a présenté de nombreuses conférences, notamment Strata et GlueCon.
Randy DeFauw est architecte principal principal de solutions chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. In est entré dans l'espace Big Data en 2013 et continue d'explorer ce domaine. Il travaille activement sur des projets dans l'espace ML et a présenté de nombreuses conférences, notamment Strata et GlueCon.
 Nitin Eusèbe est un architecte de solutions d'entreprise senior chez AWS, expérimenté en génie logiciel, en architecture d'entreprise et en IA/ML. Il est profondément passionné par l’exploration des possibilités de l’IA générative. Il collabore avec les clients pour les aider à créer des applications bien architecturées sur la plateforme AWS, et se consacre à résoudre les défis technologiques et à les accompagner dans leur transition vers le cloud.
Nitin Eusèbe est un architecte de solutions d'entreprise senior chez AWS, expérimenté en génie logiciel, en architecture d'entreprise et en IA/ML. Il est profondément passionné par l’exploration des possibilités de l’IA générative. Il collabore avec les clients pour les aider à créer des applications bien architecturées sur la plateforme AWS, et se consacre à résoudre les défis technologiques et à les accompagner dans leur transition vers le cloud.
 Arghya Banerjee est un architecte de solutions senior chez AWS dans la région de la baie de San Francisco, dont l'objectif est d'aider les clients à adopter et à utiliser le cloud AWS. Arghya se concentre sur les services et technologies Big Data, Data Lakes, Streaming, Batch Analytics et AI/ML.
Arghya Banerjee est un architecte de solutions senior chez AWS dans la région de la baie de San Francisco, dont l'objectif est d'aider les clients à adopter et à utiliser le cloud AWS. Arghya se concentre sur les services et technologies Big Data, Data Lakes, Streaming, Batch Analytics et AI/ML.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

