Il y a eu d'énormes progrès dans le domaine de l'apprentissage profond distribué pour les grands modèles de langage (LLM), en particulier après la sortie de ChatGPT en décembre 2022. Les LLM continuent de croître en taille avec des milliards, voire des milliards de paramètres, et ils ne le feront souvent pas. s'intégrer dans un seul périphérique accélérateur tel qu'un GPU ou même dans un seul nœud tel que ml.p5.32xlarge en raison des limitations de mémoire. Les clients qui forment des LLM doivent souvent répartir leur charge de travail sur des centaines, voire des milliers de GPU. Permettre une formation à une telle échelle reste un défi dans la formation distribuée, et une formation efficace dans un système aussi vaste est un autre problème tout aussi important. Au cours des dernières années, la communauté de la formation distribuée a introduit le parallélisme 3D (parallélisme des données, parallélisme des pipelines et parallélisme tensoriel) et d'autres techniques (telles que le parallélisme des séquences et le parallélisme expert) pour relever ces défis.
En décembre 2023, Amazon a annoncé la sortie du Bibliothèque parallèle de modèles SageMaker 2.0 (SMP), qui atteint une efficacité de pointe dans la formation de grands modèles, ainsi que le Bibliothèque de parallélisme de données distribuées SageMaker (SMDDP). Cette version est une mise à jour importante par rapport à la version 1.x : SMP est désormais intégré à PyTorch open source Données entièrement partagées en parallèle (FSDP), qui vous permettent d'utiliser une interface familière lors de la formation de grands modèles et sont compatibles avec Moteur de transformateur (TE), déverrouillant pour la première fois les techniques de parallélisme tensoriel aux côtés de FSDP. Pour en savoir plus sur la version, reportez-vous à La bibliothèque parallèle de modèles Amazon SageMaker accélère désormais les charges de travail PyTorch FSDP jusqu'à 20 %.
Dans cet article, nous explorons les avantages en termes de performances de Amazon Sage Maker (y compris SMP et SMDDP), et comment utiliser la bibliothèque pour former efficacement de grands modèles sur SageMaker. Nous démontrons les performances de SageMaker avec des benchmarks sur des clusters ml.p4d.24xlarge jusqu'à 128 instances et une précision mixte FSDP avec bfloat16 pour le modèle Llama 2. Nous commençons par une démonstration de l'efficacité de la mise à l'échelle quasi linéaire pour SageMaker, suivie de l'analyse des contributions de chaque fonctionnalité pour un débit optimal, et terminons par un entraînement efficace avec différentes longueurs de séquence jusqu'à 32,768 XNUMX via le parallélisme tensoriel.
Mise à l'échelle quasi linéaire avec SageMaker
Pour réduire le temps global de formation des modèles LLM, il est crucial de préserver un débit élevé lors de la mise à l'échelle vers de grands clusters (des milliers de GPU), compte tenu de la surcharge de communication entre les nœuds. Dans cet article, nous démontrons l'efficacité d'une mise à l'échelle robuste et quasi linéaire (en faisant varier le nombre de GPU pour une taille totale de problème fixe) sur les instances p4d appelant à la fois SMP et SMDDP.
Dans cette section, nous démontrons les performances de mise à l'échelle quasi linéaire de SMP. Ici, nous formons des modèles Llama 2 de différentes tailles (paramètres 7B, 13B et 70B) en utilisant une longueur de séquence fixe de 4,096 4, le backend SMDDP pour la communication collective, activé TE, une taille de lot globale de 16 millions, avec 128 à 4 nœuds pXNUMXd. . Le tableau suivant résume notre configuration optimale et nos performances d'entraînement (modèle TFLOP par seconde).
| Taille du modèle | Nombre de nœuds | TFLOP* | sdp* | tp* | décharger* | Efficacité de mise à l'échelle |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13M | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70M | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Pour la taille du modèle, la longueur de séquence et le nombre de nœuds donnés, nous montrons le débit et les configurations globalement optimaux après avoir exploré diverses combinaisons de déchargement sdp, tp et d'activation.
Le tableau précédent résume les chiffres de débit optimaux soumis au degré de parallèle de données partagées (sdp) (généralement en utilisant le partage hybride FSDP au lieu du partage complet, avec plus de détails dans la section suivante), le degré de parallèle de tenseur (tp) et les changements de valeur de déchargement d'activation. démontrant une mise à l'échelle presque linéaire pour SMP avec SMDDP. Par exemple, étant donné la taille du modèle Llama 2 7B et la longueur de séquence 4,096 97.0, il atteint globalement des efficacités de mise à l'échelle de 91.6 %, 84.1 % et 16 % (par rapport à 32 nœuds) à 64, 128 et XNUMX nœuds, respectivement. Les efficacités de mise à l’échelle sont stables sur différentes tailles de modèle et augmentent légèrement à mesure que la taille du modèle augmente.
SMP et SMDDP démontrent également des efficacités de mise à l'échelle similaires pour d'autres longueurs de séquence telles que 2,048 8,192 et XNUMX XNUMX.
Performances de la bibliothèque parallèle de modèles SageMaker 2.0 : Llama 2 70B
La taille des modèles a continué de croître au cours des dernières années, parallèlement aux fréquentes mises à jour des performances de pointe dans la communauté LLM. Dans cette section, nous illustrons les performances dans SageMaker pour le modèle Llama 2 en utilisant une taille de modèle fixe de 70B, une longueur de séquence de 4,096 4 et une taille de lot globale de XNUMX millions. Pour comparer avec la configuration et le débit globalement optimaux du tableau précédent (avec le backend SMDDP, généralement le partitionnement hybride FSDP et TE), le tableau suivant s'étend à d'autres débits optimaux (potentiellement avec le parallélisme tensoriel) avec des spécifications supplémentaires sur le backend distribué (NCCL et SMDDP) , stratégies de partitionnement FSDP (partitionnement complet et partitionnement hybride) et activation ou non de TE (par défaut).
| Taille du modèle | Nombre de nœuds | TFLOPS | Configuration TFLOP #3 | Amélioration des TFLOP par rapport à la référence | ||||||||
| . | . | Partitionnement complet NCCL : #0 | Partitionnement complet SMDDP : #1 | Partitionnement hybride SMDDP : #2 | Partage hybride SMDDP avec TE : #3 | sdp* | tp* | décharger* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70M | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Pour la taille du modèle, la longueur de séquence et le nombre de nœuds donnés, nous montrons le débit et la configuration globalement optimaux après avoir exploré diverses combinaisons de déchargement sdp, tp et d'activation.
La dernière version de SMP et SMDDP prend en charge plusieurs fonctionnalités, notamment le FSDP PyTorch natif, le partitionnement hybride étendu et plus flexible, l'intégration du moteur de transformateur, le parallélisme tensoriel et un fonctionnement collectif optimisé. Pour mieux comprendre comment SageMaker réalise une formation distribuée efficace pour les LLM, nous explorons les contributions incrémentielles du SMDDP et du SMP suivant CARACTERISTIQUES de base:
- Amélioration SMDDP par rapport à NCCL avec partitionnement complet FSDP
- Remplacement du partitionnement complet FSDP par un partitionnement hybride, qui réduit les coûts de communication pour améliorer le débit
- Une augmentation supplémentaire du débit avec TE, même lorsque le parallélisme tensoriel est désactivé
- Avec des paramètres de ressources inférieurs, le déchargement d'activation pourrait permettre une formation qui serait autrement irréalisable ou très lente en raison d'une pression mémoire élevée.
Partitionnement complet FSDP : amélioration SMDDP par rapport à NCCL
Comme le montre le tableau précédent, lorsque les modèles sont entièrement partitionnés avec FSDP, bien que les débits NCCL (TFLOPs #0) et SMDDP (TFLOPs #1) soient comparables à 32 ou 64 nœuds, il y a une énorme amélioration de 50.4 % de NCCL à SMDDP. à 128 nœuds.
Pour des modèles de plus petite taille, nous observons des améliorations constantes et significatives avec SMDDP par rapport à NCCL, en commençant par des tailles de cluster plus petites, car SMDDP est capable d'atténuer efficacement les goulots d'étranglement de la communication.
Sharding hybride FSDP pour réduire les coûts de communication
Dans SMP 1.0, nous avons lancé parallélisme des données partagées, une technique de formation distribuée optimisée par Amazon en interne MiCS technologie. Dans SMP 2.0, nous introduisons le partitionnement hybride SMP, une technique de partitionnement hybride extensible et plus flexible qui permet de partager les modèles entre un sous-ensemble de GPU, au lieu de tous les GPU d'entraînement, ce qui est le cas pour le partitionnement complet FSDP. Il est utile pour les modèles de taille moyenne qui n'ont pas besoin d'être partagés sur l'ensemble du cluster afin de satisfaire aux contraintes de mémoire par GPU. Cela conduit les clusters à avoir plus d'une réplique de modèle et chaque GPU communique avec moins de pairs au moment de l'exécution.
Le partitionnement hybride de SMP permet un partitionnement de modèle efficace sur une plage plus large, du plus petit degré de partition sans problème de mémoire insuffisante jusqu'à la taille totale du cluster (ce qui équivaut à un partitionnement complet).
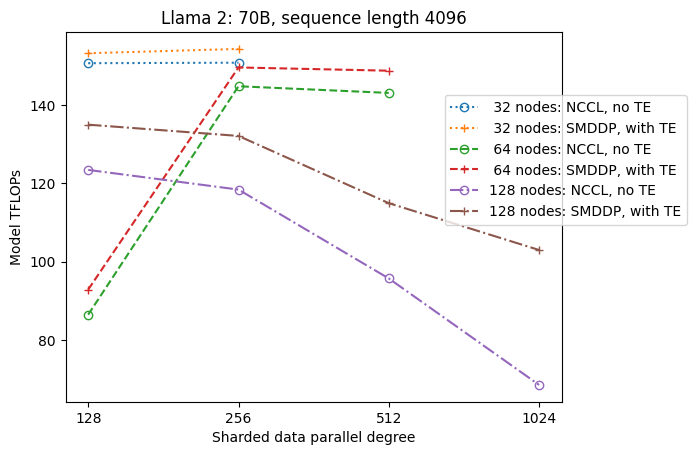
La figure suivante illustre la dépendance du débit par rapport à sdp à tp = 1 pour plus de simplicité. Bien qu'elle ne soit pas nécessairement la même que la valeur tp optimale pour le partitionnement complet NCCL ou SMDDP dans le tableau précédent, les chiffres sont assez proches. Il valide clairement l'intérêt du passage du partitionnement complet au partitionnement hybride sur une grande taille de cluster de 128 nœuds, ce qui est applicable à la fois à NCCL et à SMDDP. Pour les modèles de plus petite taille, les améliorations significatives du partitionnement hybride commencent avec des tailles de cluster plus petites, et la différence continue d'augmenter avec la taille du cluster.
Améliorations avec TE
TE est conçu pour accélérer la formation LLM sur les GPU NVIDIA. Même si FP8 n'est pas utilisé car il n'est pas pris en charge sur les instances p4d, nous constatons toujours une accélération significative avec TE sur p4d.
En plus de MiCS formé avec le backend SMDDP, TE introduit une augmentation constante du débit sur toutes les tailles de cluster (la seule exception est le partitionnement complet à 128 nœuds), même lorsque le parallélisme du tenseur est désactivé (le degré de parallèle du tenseur est de 1).
Pour les modèles de plus petite taille ou les différentes longueurs de séquence, le boost TE est stable et non trivial, compris entre environ 3 et 7.6 %.
Déchargement d'activation avec des paramètres de ressources faibles
Avec des paramètres de ressources faibles (étant donné un petit nombre de nœuds), FSDP peut subir une pression de mémoire élevée (ou même une mémoire insuffisante dans le pire des cas) lorsque les points de contrôle d'activation sont activés. Pour de tels scénarios goulots d'étranglement par la mémoire, l'activation du déchargement d'activation est potentiellement une option pour améliorer les performances.
Par exemple, comme nous l'avons vu précédemment, bien que le Llama 2 avec une taille de modèle 13B et une longueur de séquence de 4,096 32 soit capable de s'entraîner de manière optimale avec au moins 16 nœuds avec points de contrôle d'activation et sans déchargement d'activation, il atteint le meilleur débit avec déchargement d'activation lorsqu'il est limité à XNUMX. nœuds.
Permettre l'entraînement avec de longues séquences : parallélisme tenseur SMP
Des séquences plus longues sont souhaitées pour les conversations et le contexte longs, et suscitent davantage d'attention dans la communauté LLM. Par conséquent, nous rapportons divers débits de séquences longues dans le tableau suivant. Le tableau montre les débits optimaux pour la formation Llama 2 sur SageMaker, avec différentes longueurs de séquence allant de 2,048 32,768 à 32,768 32. Avec une longueur de séquence de 4 XNUMX, la formation FSDP native est irréalisable avec XNUMX nœuds pour une taille de lot globale de XNUMX millions.
| . | . | . | TFLOPS | ||
| Taille du modèle | Longueur de séquence | Nombre de nœuds | FSDP natif et NCCL | SMP et SMDDP | Amélioration du SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | N / A | 82.87 | . | |
| 13M | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | N / A | 92.38 | . | |
| * : maximum | . | . | . | . | 8.3% |
| * : médiane | . | . | . | . | 5.8% |
Lorsque la taille du cluster est grande et compte tenu d'une taille de lot globale fixe, certaines formations de modèles peuvent être irréalisables avec PyTorch FSDP natif, faute de pipeline intégré ou de prise en charge du parallélisme tensoriel. Dans le tableau précédent, étant donné une taille de lot globale de 4 millions, 32 nœuds et une longueur de séquence de 32,768 0.5, la taille de lot effective par GPU est de 2 (par exemple, tp = 1 avec une taille de lot de XNUMX), ce qui serait autrement irréalisable sans introduire parallélisme tensoriel.
Conclusion
Dans cet article, nous avons démontré une formation LLM efficace avec SMP et SMDDP sur les instances p4d, attribuant des contributions à plusieurs fonctionnalités clés, telles que l'amélioration SMDDP par rapport à NCCL, le partitionnement hybride FSDP flexible au lieu du partitionnement complet, l'intégration TE et l'activation du parallélisme tensoriel en faveur de de longues séquences. Après avoir été testé sur une large gamme de paramètres avec différents modèles, tailles de modèles et longueurs de séquence, il présente de robustes efficacités de mise à l'échelle quasi linéaire, jusqu'à 128 instances p4d sur SageMaker. En résumé, SageMaker continue d'être un outil puissant pour les chercheurs et praticiens LLM.
Pour en savoir plus, consultez Bibliothèque de parallélisme de modèles SageMaker v2, ou contactez l'équipe SMP au sm-model-parallel-feedback@amazon.com.
Remerciements
Nous tenons à remercier Robert Van Dusen, Ben Snyder, Gautam Kumar et Luis Quintela pour leurs commentaires et discussions constructifs.
À propos des auteurs

Xinle Sheila Liu est un SDE dans Amazon SageMaker. Dans ses temps libres, elle aime lire et faire des sports de plein air.
 Suhit Kodgule est ingénieur en développement logiciel au sein du groupe AWS Artificial Intelligence travaillant sur des frameworks d'apprentissage en profondeur. Dans ses temps libres, il aime faire de la randonnée, voyager et cuisiner.
Suhit Kodgule est ingénieur en développement logiciel au sein du groupe AWS Artificial Intelligence travaillant sur des frameworks d'apprentissage en profondeur. Dans ses temps libres, il aime faire de la randonnée, voyager et cuisiner.
 Victor Zhu est ingénieur logiciel en Deep Learning distribué chez Amazon Web Services. On le trouve en train de profiter de la randonnée et des jeux de société dans la région de la baie de SF.
Victor Zhu est ingénieur logiciel en Deep Learning distribué chez Amazon Web Services. On le trouve en train de profiter de la randonnée et des jeux de société dans la région de la baie de SF.
 Derya Cavdar travaille comme ingénieur logiciel chez AWS. Ses intérêts incluent l'apprentissage profond et l'optimisation de la formation distribuée.
Derya Cavdar travaille comme ingénieur logiciel chez AWS. Ses intérêts incluent l'apprentissage profond et l'optimisation de la formation distribuée.
 Teng Xu est ingénieur en développement logiciel dans le groupe de formation distribuée d'AWS AI. Il aime lire.
Teng Xu est ingénieur en développement logiciel dans le groupe de formation distribuée d'AWS AI. Il aime lire.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

