À mesure que les entreprises se développent, la demande d'adresses IP au sein du réseau d'entreprise dépasse souvent l'offre. Le réseau d'une organisation est souvent conçu avec une certaine anticipation des exigences futures, mais à mesure que les entreprises évoluent, leurs besoins en technologies de l'information (TI) dépassent le réseau précédemment conçu. Les entreprises peuvent se retrouver confrontées à des difficultés pour gérer le nombre limité d'adresses IP.
Pour les charges de travail d'ingénierie des données lorsque Colle AWS est utilisé dans une configuration réseau aussi limitée, votre équipe peut parfois être confrontée à des obstacles pour exécuter plusieurs tâches simultanément. Cela se produit parce que vous ne disposez peut-être pas de suffisamment d’adresses IP pour prendre en charge les connexions requises aux bases de données. Pour surmonter cette pénurie, l'équipe peut obtenir davantage d'adresses IP auprès de votre pool de réseaux d'entreprise. Ces adresses IP obtenues peuvent être uniques (sans chevauchement) ou se chevaucher lorsque les adresses IP sont réutilisées dans votre réseau d'entreprise.
Lorsque vous utilisez des adresses IP qui se chevauchent, vous avez besoin d'une gestion de réseau supplémentaire pour établir la connectivité. Les solutions de mise en réseau peuvent inclure des options telles que passerelles privées de traduction d'adresses réseau (NAT), Lien privé AWS, ou des appareils NAT autogérés pour traduire les adresses IP.
Dans cet article, nous aborderons deux stratégies pour faire évoluer les tâches AWS Glue :
- Optimisation de la consommation d'adresses IP en dimensionnant correctement les unités de traitement de données (DPU), à l'aide de la fonctionnalité Auto Scaling d'AWS Glue et en affinant les tâches.
- Extension de la capacité du réseau à l'aide d'une plage CIDR (Classless Inter-Domain Routing) supplémentaire non routable avec une passerelle NAT privée.
Avant d'approfondir ces solutions, comprenons comment AWS Glue utilise Interface réseau élastique (ENI) pour établir la connectivité. Pour activer l'accès aux magasins de données à l'intérieur d'un VPC, vous devez créer une connexion AWS Glue attachée à votre VPC. Lorsqu'une tâche AWS Glue s'exécute dans votre VPC, la tâche crée une ENI dans le VPC configuré pour chaque connexion de données, et cette ENI utilise une adresse IP dans le VPC spécifié. Ces ENI sont de courte durée et actifs jusqu'à ce que le travail soit terminé.
Examinons maintenant la première solution qui explique l'optimisation de la consommation des adresses IP AWS Glue.
Stratégies pour une consommation efficace des adresses IP
Dans AWS Glue, le nombre de nœuds de calcul utilisés par une tâche détermine le nombre d'adresses IP utilisées à partir de votre sous-réseau VPC. En effet, chaque travailleur nécessite une adresse IP correspondant à une ENI. Lorsque vous ne disposez pas d'une plage CIDR suffisante allouée au sous-réseau AWS Glue, vous pouvez observer des erreurs d'épuisement d'adresse IP. Voici quelques bonnes pratiques pour optimiser la consommation des adresses IP AWS Glue :
- Dimensionner correctement les DPU de la tâche – AWS Glue est un moteur de traitement distribué. Il fonctionne efficacement lorsqu'il peut exécuter des tâches en parallèle. Si une tâche contient plus de DPU que nécessaire, elle ne s'exécute pas toujours plus rapidement. Ainsi, trouver le bon nombre de DPU garantira que vous utilisez les adresses IP de manière optimale. En créant une observabilité dans le système et en analysant les performances du travail, vous pouvez obtenir des informations sur les tendances de consommation d'ENI, puis configurer la capacité appropriée sur le travail pour la bonne taille. Pour plus de détails, reportez-vous à Surveillance pour la planification de la capacité DPU. L'interface utilisateur Spark est un outil utile pour surveiller l'utilisation des travailleurs des tâches AWS Glue. Pour plus de détails, reportez-vous à Surveillance des tâches à l'aide de l'interface utilisateur Web d'Apache Spark.
- AWS Glue Auto Scaling – Il est souvent difficile de prédire à l'avance les besoins en capacité d'une tâche. L'activation de la fonctionnalité Auto Scaling d'AWS Glue déchargera une partie de cette responsabilité sur AWS. Au moment de l'exécution, en fonction des exigences de la charge de travail, la tâche met automatiquement à l'échelle les nœuds de travail jusqu'à la configuration maximale définie. S'il n'y a pas de besoin supplémentaire, AWS Glue ne surprovisionnera pas les travailleurs, économisant ainsi les ressources et réduisant les coûts. La fonctionnalité Auto Scaling est disponible dans AWS Glue 3.0 et versions ultérieures. Pour plus d'informations, reportez-vous à Présentation d'AWS Glue Auto Scaling : redimensionnez automatiquement les ressources informatiques sans serveur à moindre coût avec Apache Spark optimisé.
- Optimisation au niveau du travail – Identifiez les optimisations au niveau du travail en utilisant Métriques de tâche AWS Glue , et appliquer les meilleures pratiques de Bonnes pratiques pour l'optimisation des performances des tâches AWS Glue pour Apache Spark.
Examinons ensuite la deuxième solution qui élabore l'expansion de la capacité du réseau.
Solutions pour l'extension de la taille du réseau (adresse IP)
Dans cette section, nous aborderons plus en détail deux solutions possibles pour étendre la taille du réseau.
Étendez les plages CIDR de VPC avec des adresses routables
Une solution consiste à ajouter davantage de plages CIDR IPv4 privées à partir de RFC 1918 à votre VPC. Théoriquement, chaque compte AWS peut être attribué à tout ou partie de ces CIDR d'adresses IP. Votre équipe de gestion des adresses IP (IPAM) gère souvent l'attribution des adresses IP que chaque unité commerciale peut utiliser à partir de la RFC1918 pour éviter le chevauchement des adresses IP sur plusieurs comptes AWS ou unités commerciales. Si votre quota d'adresses IP routables actuel alloué par l'équipe IPAM n'est pas suffisant, vous pouvez en demander davantage.
Si votre équipe IPAM vous délivre une plage CIDR supplémentaire sans chevauchement, vous pouvez soit l'ajouter en tant que CIDR secondaire à votre VPC existant, soit créer un nouveau VPC avec celui-ci. Si vous envisagez de créer un nouveau VPC, vous pouvez interconnecter les VPC via Appairage de VPC or Passerelle de transit AWS.
Si cette capacité supplémentaire est suffisante pour exécuter tous vos travaux dans les délais définis, il s'agit alors d'une solution simple et rentable. Sinon, vous pouvez envisager d'adopter des adresses IP qui se chevauchent avec une passerelle NAT privée, comme décrit dans la section suivante. Avec la solution suivante, vous devez utiliser Transit Gateway pour connecter les VPC, car l'appairage de VPC n'est pas possible lorsque des plages CIDR se chevauchent dans ces deux VPC.
Configurer le CIDR non routable avec une passerelle NAT privée
Comme décrit dans le livre blanc AWS Création d'une infrastructure réseau AWS multi-VPC évolutive et sécurisée, vous pouvez étendre la capacité de votre réseau en créant un sous-réseau d'adresses IP non routable et en utilisant une passerelle NAT privée située dans un espace d'adresses IP routable (sans chevauchement) pour acheminer le trafic. Une passerelle NAT privée traduit et achemine le trafic entre les adresses IP non routables et les adresses IP routables. Le diagramme suivant illustre la solution en référence à AWS Glue.
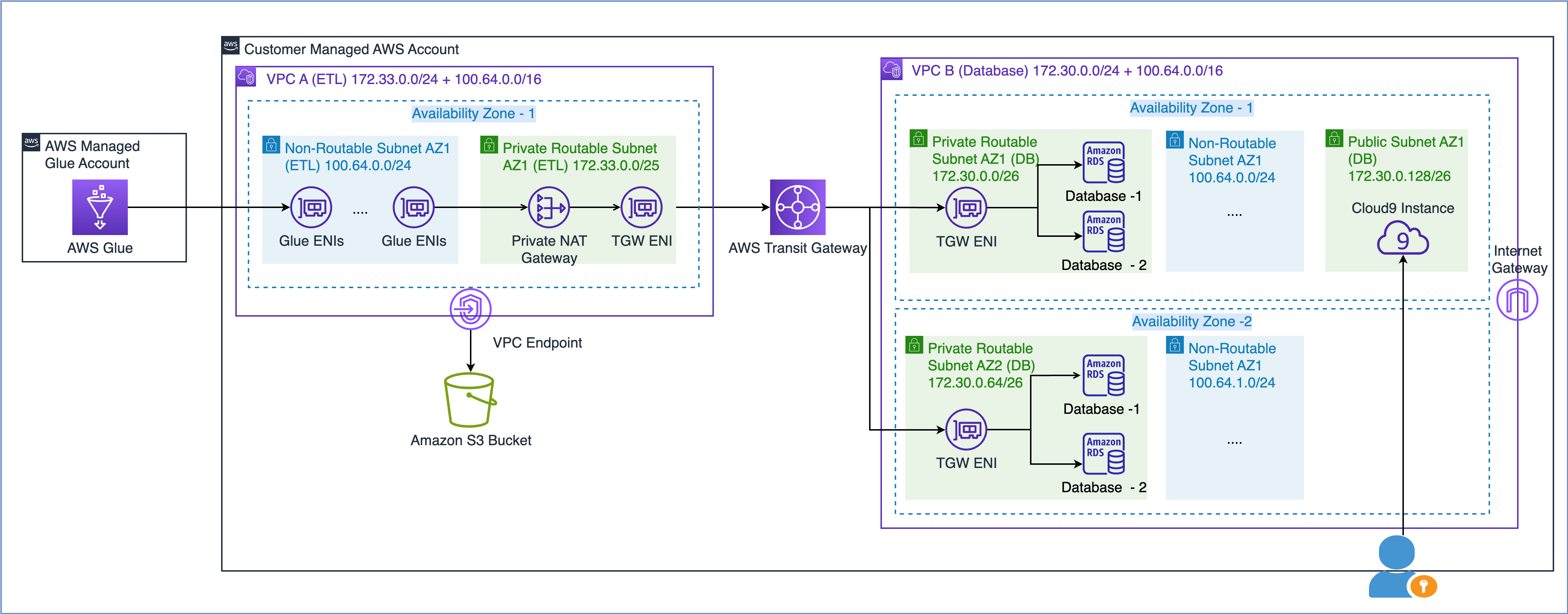
Comme vous pouvez le voir dans le diagramme ci-dessus, le VPC A (ETL) est associé à deux plages CIDR. La plus petite plage CIDR 172.33.0.0/24 est routable car elle n'est réutilisée nulle part, tandis que la plus grande plage CIDR 100.64.0.0/16 n'est pas routable car elle est réutilisée dans le VPC de base de données.
Dans le VPC B (base de données), nous avons hébergé deux bases de données dans les sous-réseaux routables 172.30.0.0/26 et 172.30.0.64/26. Ces deux sous-réseaux se trouvent dans deux zones de disponibilité distinctes pour une haute disponibilité. Nous disposons également de deux sous-réseaux supplémentaires inutilisés, 100.64.0.0/24 et 100.64.1.0/24, pour simuler une configuration non routable.
Vous pouvez choisir la taille de la plage CIDR non routable en fonction de vos besoins en capacité. Puisque vous pouvez réutiliser les adresses IP, vous pouvez créer un très grand sous-réseau selon vos besoins. Par exemple, un masque CIDR de /16 vous donnerait environ 65,000 4 adresses IPvXNUMX. Vous pouvez travailler avec votre équipe d'ingénierie réseau et dimensionner les sous-réseaux.
En bref, vous pouvez configurer les tâches AWS Glue pour utiliser des sous-réseaux routables et non routables dans votre VPC afin de maximiser le pool d'adresses IP disponible.
Voyons maintenant comment les ENI Glue qui se trouvent dans un sous-réseau non routable communiquent avec les sources de données d'un autre VPC.
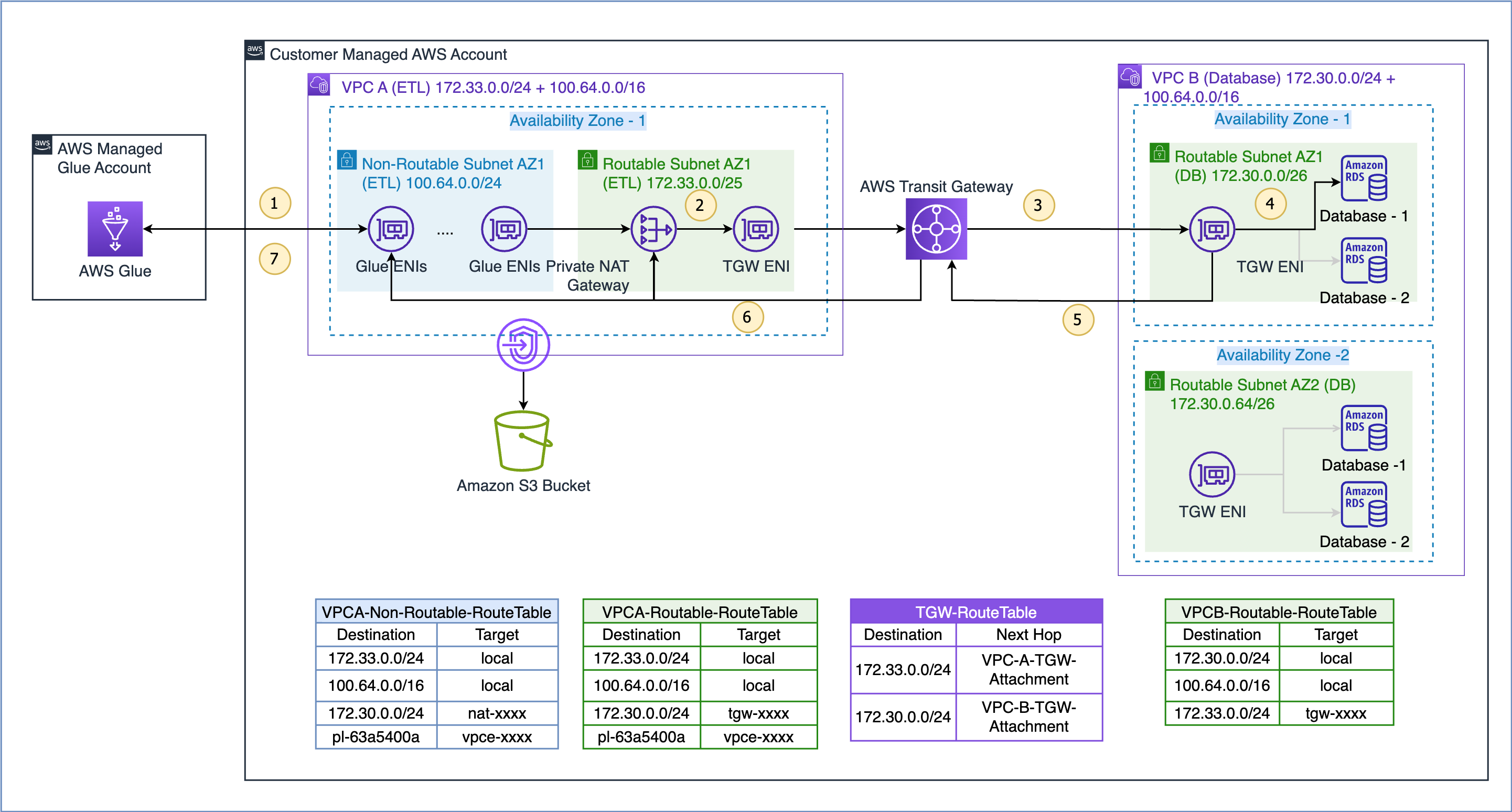
Le flux de données pour le cas d'utilisation illustré ici est le suivant (en référence aux étapes numérotées de la figure ci-dessus) :
- Lorsqu'une tâche AWS Glue doit accéder à une source de données, elle utilise d'abord la connexion AWS Glue sur la tâche et crée les ENI dans le sous-réseau non routable 100.64.0.0/24 dans le VPC A. Plus tard, AWS Glue utilise la configuration de connexion à la base de données et tente de se connecter à la base de données dans le VPC B 172.30.0.0/24.
- Selon la table de routage
VPCA-Non-Routable-RouteTablela destination 172.30.0.0/24 est configurée pour une passerelle NAT privée. La demande est envoyée à la passerelle NAT, qui traduit ensuite l'adresse IP source d'une adresse IP non routable en une adresse IP routable. Le trafic est ensuite envoyé vers le rattachement de passerelle de transit dans le VPC A car il est associé auVPCA-Routable-RouteTabletable de routage dans le VPC A. - Transit Gateway utilise la route 172.30.0.0/24 et envoie le trafic à la pièce jointe de la passerelle de transit VPC B.
- La passerelle de transit ENI dans le VPC B utilise la route locale du VPC B pour se connecter au point de terminaison de la base de données et interroger les données.
- Une fois la requête terminée, la réponse est renvoyée au VPC A. Le trafic de réponse est acheminé vers l'attachement de passerelle de transit dans le VPC B, puis Transit Gateway utilise la route 172.33.0.0/24 et envoie le trafic vers l'attachement de passerelle de transit du VPC A. .
- La passerelle de transit ENI dans le VPC A utilise la route locale pour transférer le trafic vers la passerelle NAT privée, qui traduit l'adresse IP de destination en celle des ENI dans un sous-réseau non routable.
- Enfin, la tâche AWS Glue reçoit les données et poursuit le traitement.
La solution de passerelle NAT privée est une option si vous avez besoin d'adresses IP supplémentaires lorsque vous ne pouvez pas les obtenir à partir d'un réseau routable de votre organisation. Parfois, chaque service supplémentaire entraîne un coût supplémentaire, et ce compromis est nécessaire pour atteindre vos objectifs. Reportez-vous à la section Tarifs de la passerelle NAT sur le Page de tarification d'Amazon VPC pour plus d'information.
Pré-requis
Pour terminer la présentation de la solution de passerelle NAT privée, vous avez besoin des éléments suivants :
Déployez la solution
Pour implémenter la solution, procédez comme suit:
- Connectez-vous à votre console de gestion AWS.
- Déployez la solution en cliquant sur
 . Cette pile est par défaut
. Cette pile est par défaut us-east-1, vous pouvez sélectionner la région souhaitée. - Cliquez next puis spécifiez les détails de la pile. Vous pouvez conserver les paramètres d'entrée avec les valeurs par défaut préremplies ou les modifier si nécessaire.
- Pour
DatabaseUserPassword, saisissez un mot de passe alphanumérique de votre choix et veillez à le noter pour une utilisation ultérieure. - Pour
S3BucketName, saisissez un nom unique Service de stockage simple Amazon (Amazon S3) nom du compartiment. Ce compartiment stocke le script de tâche AWS Glue qui sera copié à partir d'un référentiel de code public AWS.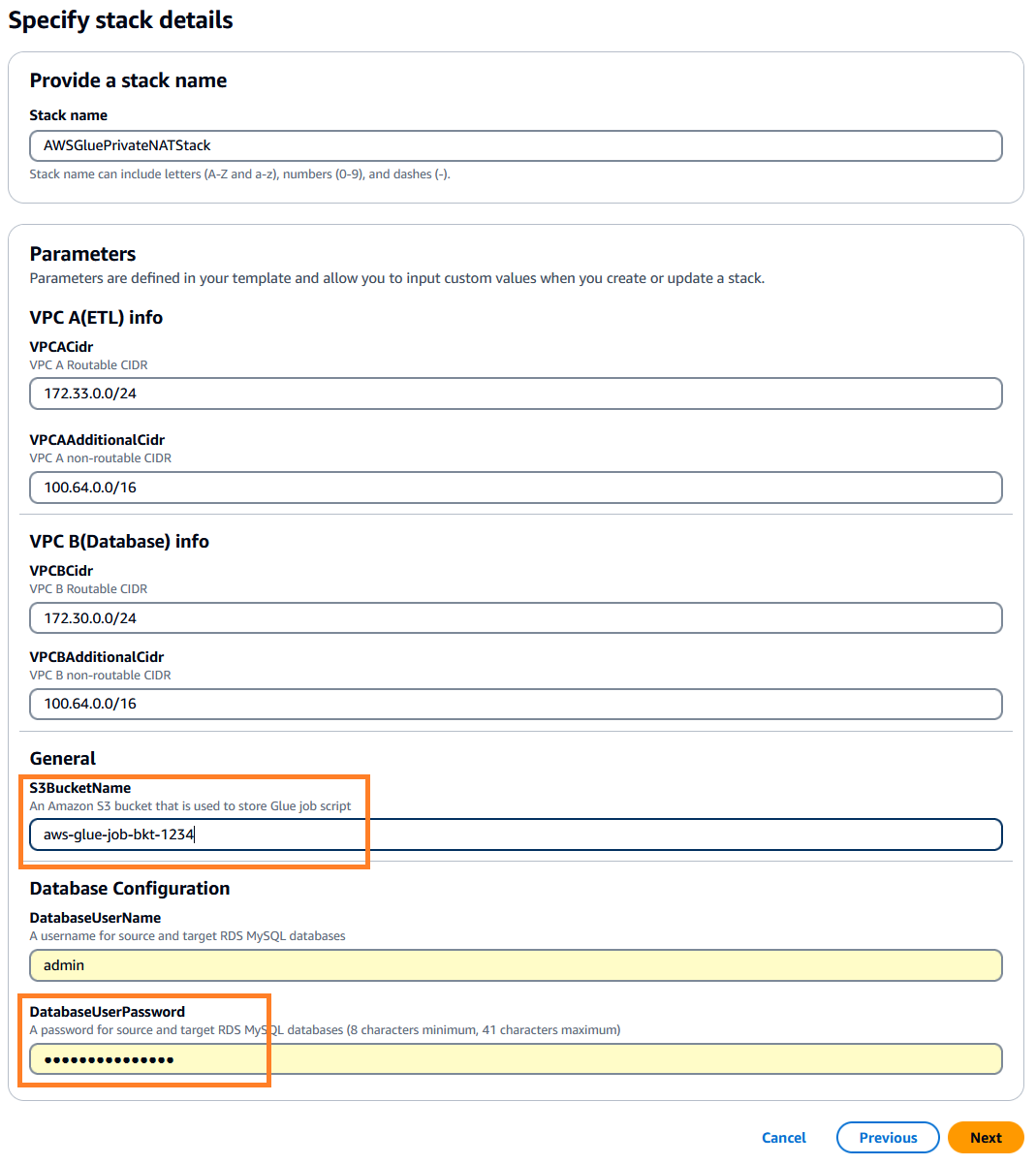
- Cliquez next.
- Laissez les valeurs par défaut et cliquez sur next nouveau.
- Vérifiez les détails, confirmez la création des ressources IAM et cliquez sur soumettre pour démarrer le déploiement.
Vous pouvez surveiller les événements pour voir les ressources créées sur la console AWS CloudFormation. La création des ressources de la pile peut prendre environ 20 minutes.
Une fois la création de la pile terminée, accédez à l'onglet Sorties sur la console AWS CloudFormation et notez les valeurs suivantes pour une utilisation ultérieure :
DBSourceDBTargetSourceCrawlerTargetCrawler
Connectez-vous à une instance AWS Cloud9
Ensuite, nous devons préparer les tables Amazon RDS source et cible pour MySQL à l'aide d'un AWSCloud9 exemple. Effectuez les étapes suivantes :
- Sur la page de la console AWS Cloud9, recherchez le
aws-glue-cloud9environnement. - Dans la colonne Cloud9 IDE, cliquez sur Ouvert pour lancer votre instance AWS Cloud9 dans un nouveau navigateur Web.
Préparer la table MySQL source
Effectuez les étapes suivantes pour préparer votre table source :
- Depuis le terminal AWS Cloud9, installez le client MySQL à l'aide de la commande suivante :
sudo yum update -y && sudo yum install -y mysql - Connectez-vous à la base de données source à l'aide de la commande suivante. Remplacez le nom d'hôte source par la valeur DBSource que vous avez capturée précédemment. Lorsque vous y êtes invité, entrez le mot de passe de la base de données que vous avez spécifié lors de la création de la pile.
mysql -h <Source Hostname> -P 3306 -u admin -p - Exécutez les scripts suivants pour créer la source
emptable et chargez les données de test :-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Vérifiez la provenance
emple nombre de tables à l'aide de la requête SQL ci-dessous (vous en aurez besoin ultérieurement pour vérification).select count(*) from emp; - Exécutez la commande suivante pour quitter l'utilitaire client MySQL et revenir au terminal de l'instance AWS Cloud9 :
quit;
Préparez la table MySQL cible
Effectuez les étapes suivantes pour préparer la table cible :
- Connectez-vous à la base de données cible à l'aide de la commande suivante. Remplacez le nom d'hôte cible par la valeur DBTarget que vous avez capturée précédemment. Lorsque vous y êtes invité, entrez le mot de passe de la base de données que vous avez spécifié lors de la création de la pile.
mysql -h <Target Hostname> -P 3306 -u admin -p - Exécutez les scripts suivants pour créer la cible
emptableau. Cette table sera chargée par la tâche AWS Glue à l'étape suivante.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Vérifiez la configuration réseau (facultatif)
Les étapes suivantes sont utiles pour comprendre la passerelle NAT, les tables de routage et les configurations de passerelle de transit de la solution de passerelle NAT privée. Ces composants ont été créés lors de la création de la pile CloudFormation.
- Sur la page de la console Amazon VPC, accédez à la section Cloud privé virtuel et localisez les passerelles NAT.
- Rechercher une passerelle NAT avec son nom
Glue-OverlappingCIDR-NATGWet explorez-le davantage. Comme vous pouvez le voir dans la capture d'écran suivante, la passerelle NAT a été créée dans le VPC A (ETL) sur le sous-réseau routable.
- Dans le volet de navigation de gauche, accédez aux Tables de routage sous la section Cloud privé virtuel.
- Rechercher
VPCA-Non-Routable-RouteTableet explorez-le davantage. Vous pouvez voir que la table de routage est configurée pour traduire le trafic du CIDR qui se chevauche à l'aide de la passerelle NAT.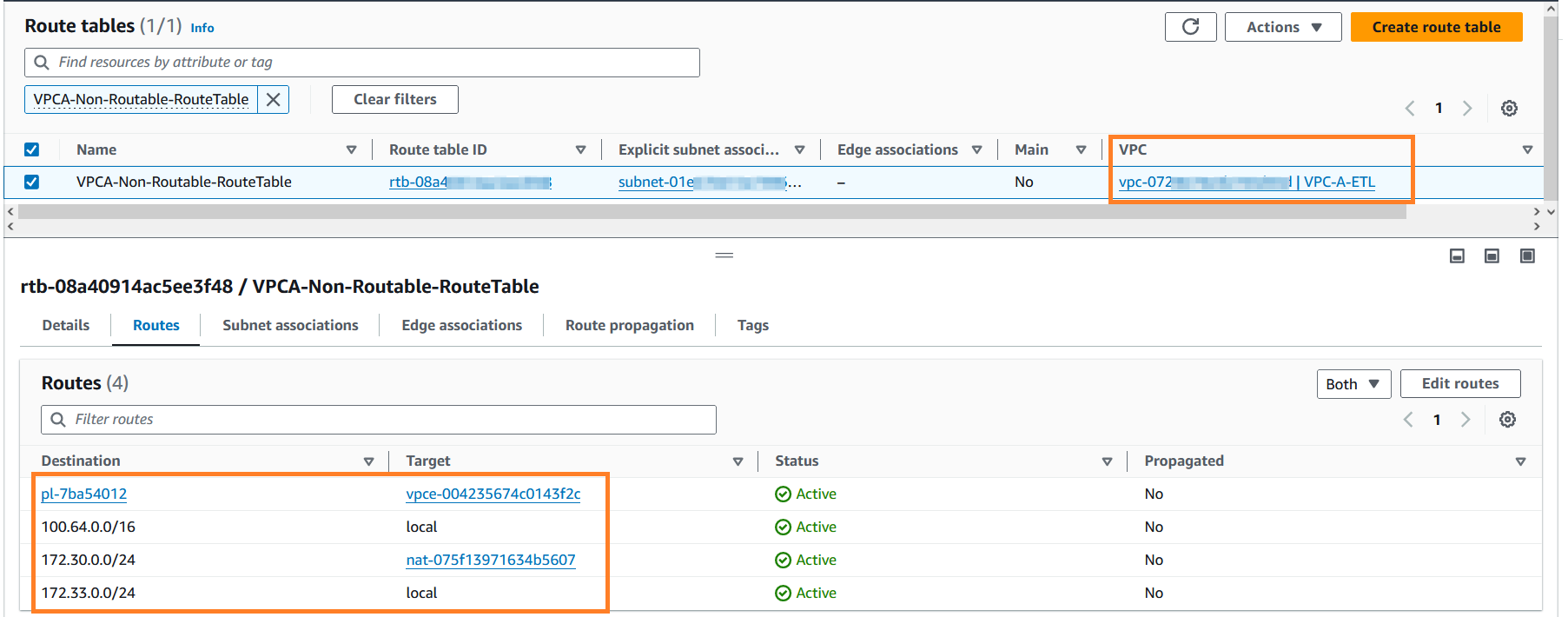
- Dans le volet de navigation de gauche, accédez à la section Passerelles de transit et cliquez sur Pièces jointes de la passerelle de transit. Entrer
VPC-dans la zone de recherche et localisez les deux pièces jointes de transit gateway nouvellement créées. - Vous pouvez explorer davantage ces pièces jointes pour connaître leurs configurations.
Exécutez les robots d'exploration AWS Glue
Effectuez les étapes suivantes pour exécuter les robots d'exploration AWS Glue requis pour cataloguer la source et la cible. emp les tables. Il s'agit d'une étape préalable à l'exécution de la tâche AWS Glue.
- Sur la page AWS Glue Console, sous la section Data Catalog dans le volet de navigation, cliquez sur Rampeurs.
- Localisez les robots d'exploration source et cible que vous avez notés précédemment.
- Sélectionnez ces robots et cliquez sur Courir pour créer les tables AWS Glue Data Catalog respectives.
- Vous pouvez surveiller la réussite des robots d'exploration AWS Glue. L'exécution des deux robots peut prendre environ 3 à 4 minutes. Une fois l'opération terminée, l'état de la dernière exécution de la tâche passe à Réussi, et vous pouvez également voir que deux tables de catalogue AWS Glue ont été créées à partir de cette exécution.

Exécutez la tâche AWS Glue ETL
Après avoir configuré les tables et effectué les étapes préalables, vous êtes maintenant prêt à exécuter la tâche AWS Glue que vous avez créée à l'aide du modèle CloudFormation. Cette tâche se connecte à la base de données RDS pour MySQL source, extrait les données et charge les données dans la base de données RDS pour MySQL cible. Ce travail lit les données d'une table MySQL source et les charge dans la table MySQL cible à l'aide d'une solution de passerelle NAT privée. Pour exécuter la tâche AWS Glue, procédez comme suit :
- Sur la console AWS Glue, cliquez sur Emplois ETL dans le volet de navigation.
- Cliquez sur le poste
glue-private-nat-job. - Cliquez Courir pour le démarrer.
Voici le script PySpark pour cette tâche ETL :
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
En fonction de la configuration DPU de la tâche, AWS Glue crée un ensemble d'ENI dans le sous-réseau non routable configuré sur la connexion AWS Glue. Vous pouvez surveiller ces ENI sur la page Interfaces réseau du Cloud de calcul élastique Amazon (Amazon EC2).
La capture d'écran ci-dessous montre les 10 ENI qui ont été créés pour l'exécution du travail afin de correspondre au nombre demandé de travailleurs configurés dans les paramètres du travail. Comme prévu, les ENI ont été créées dans le sous-réseau non routable du VPC A, permettant l'évolutivité des adresses IP. Une fois la tâche terminée, ces ENI seront automatiquement publiées par AWS Glue.
Lorsque la tâche AWS Glue est en cours d'exécution, vous pouvez surveiller son état. Une fois terminé, le statut de la tâche passe à Réussi.
Vérifier les résultats
Une fois la tâche AWS Glue terminée, connectez-vous à la base de données MySQL cible. Vérifiez si le nombre d'enregistrements cible correspond à la source. Vous pouvez utiliser la requête SQL ci-dessous dans le terminal AWS Cloud9.
USE targetdb;
SELECT count(*) from emp;Enfin, quittez l'utilitaire client MySQL à l'aide de la commande suivante et revenez au terminal AWS Cloud9 : quit;
Vous pouvez maintenant confirmer qu'AWS Glue a terminé avec succès une tâche de chargement de données dans une base de données cible à l'aide des adresses IP d'un sous-réseau non routable. Ceci conclut les tests de bout en bout de la solution de passerelle NAT privée.
Nettoyer
Pour éviter d'encourir des frais futurs, supprimez la ressource créée via la pile CloudFormation en procédant comme suit :
- Sur la console AWS CloudFormation, cliquez sur Piles dans le volet de navigation.
- Sélectionnez la pile
AWSGluePrivateNATStack. - Cliquez sur Supprimer pour supprimer la pile. Lorsque vous y êtes invité, confirmez la suppression de la pile.
Conclusion
Dans cet article, nous avons montré comment vous pouvez faire évoluer les tâches AWS Glue en optimisant la consommation d'adresses IP et en augmentant la capacité de votre réseau à l'aide d'une solution de passerelle NAT privée. Cette double approche vous aide à vous débloquer dans un environnement soumis à des contraintes de capacité d'adresse IP. Les options abordées dans la section Optimisation des adresses IP AWS Glue sont complémentaires aux solutions d'extension d'adresses IP, et vous pouvez créer de manière itérative pour faire évoluer votre plate-forme de données.
Apprenez-en davantage sur les techniques d'optimisation des tâches AWS Glue à partir de Surveiller et optimiser les coûts sur AWS Glue pour Apache Spark ainsi que Meilleures pratiques pour mettre à l'échelle les tâches Apache Spark et partitionner les données avec AWS Glue.
À propos des auteurs
 Sushanth Kothapally est architecte de solutions chez Amazon Web Services qui soutient les clients de l'automobile et de la fabrication. Il est passionné par la conception de solutions technologiques pour atteindre les objectifs commerciaux et s'intéresse vivement aux architectures sans serveur et basées sur les événements.
Sushanth Kothapally est architecte de solutions chez Amazon Web Services qui soutient les clients de l'automobile et de la fabrication. Il est passionné par la conception de solutions technologiques pour atteindre les objectifs commerciaux et s'intéresse vivement aux architectures sans serveur et basées sur les événements.
 Senthil Kamala Rathinam est architecte de solutions chez Amazon Web Services, spécialisé dans les données et l'analyse. Il se passionne pour aider les clients à concevoir et à construire des plateformes de données modernes. Pendant son temps libre, Senthil aime passer du temps avec sa famille et jouer au badminton.
Senthil Kamala Rathinam est architecte de solutions chez Amazon Web Services, spécialisé dans les données et l'analyse. Il se passionne pour aider les clients à concevoir et à construire des plateformes de données modernes. Pendant son temps libre, Senthil aime passer du temps avec sa famille et jouer au badminton.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

