Les modèles de base (FM) sont de grands modèles d'apprentissage automatique (ML) formés sur un large spectre d'ensembles de données non étiquetés et généralisés. Les FM, comme leur nom l'indique, constituent la base permettant de créer des applications en aval plus spécialisées et sont uniques par leur adaptabilité. Ils peuvent effectuer un large éventail de tâches différentes, telles que le traitement du langage naturel, la classification des images, la prévision des tendances, l'analyse des sentiments et la réponse aux questions. Cette échelle et cette adaptabilité à usage général sont ce qui différencie les FM des modèles ML traditionnels. Les FM sont multimodaux ; ils fonctionnent avec différents types de données tels que le texte, la vidéo, l'audio et les images. Les grands modèles de langage (LLM) sont un type de FM et sont pré-entraînés sur de grandes quantités de données textuelles et ont généralement des utilisations applicatives telles que la génération de texte, les chatbots intelligents ou la synthèse.
Les données en streaming facilitent le flux constant d'informations diverses et à jour, améliorant ainsi la capacité des modèles à s'adapter et à générer des résultats plus précis et contextuellement pertinents. Cette intégration dynamique des données en streaming permet IA générative applications pour répondre rapidement aux conditions changeantes, améliorant ainsi leur adaptabilité et leurs performances globales dans diverses tâches.
Pour mieux comprendre cela, imaginez un chatbot qui aide les voyageurs à réserver leur voyage. Dans ce scénario, le chatbot a besoin d'un accès en temps réel à l'inventaire des compagnies aériennes, au statut des vols, à l'inventaire des hôtels, aux dernières modifications de prix, etc. Ces données proviennent généralement de tiers et les développeurs doivent trouver un moyen d'ingérer ces données et de traiter les modifications des données au fur et à mesure qu'elles se produisent.
Le traitement par lots n’est pas la meilleure solution dans ce scénario. Lorsque les données changent rapidement, leur traitement par lots peut entraîner l'utilisation de données obsolètes par le chatbot, fournissant ainsi des informations inexactes au client, ce qui a un impact sur l'expérience client globale. Cependant, le traitement des flux peut permettre au chatbot d'accéder aux données en temps réel et de s'adapter aux changements de disponibilité et de prix, fournissant ainsi les meilleurs conseils au client et améliorant son expérience.
Un autre exemple est une solution d'observabilité et de surveillance basée sur l'IA, dans laquelle les FM surveillent les mesures internes d'un système en temps réel et produisent des alertes. Lorsque le modèle détecte une anomalie ou une valeur métrique anormale, il doit immédiatement produire une alerte et en informer l'opérateur. Cependant, la valeur de données aussi importantes diminue considérablement avec le temps. Ces notifications devraient idéalement être reçues en quelques secondes ou même pendant qu'elles se produisent. Si les opérateurs reçoivent ces notifications quelques minutes ou heures après leur apparition, ces informations ne peuvent pas être exploitées et ont potentiellement perdu de leur valeur. Vous pouvez trouver des cas d’utilisation similaires dans d’autres secteurs tels que la vente au détail, la construction automobile, l’énergie et le secteur financier.
Dans cet article, nous expliquons pourquoi le streaming de données est un élément crucial des applications d'IA générative en raison de sa nature en temps réel. Nous discutons de la valeur des services de streaming de données AWS tels que Amazon Managed Streaming pour Apache Kafka (AmazonMSK), Flux de données Amazon Kinesis, Service géré Amazon pour Apache Flinket Firehose de données Amazon Kinesis dans la création d'applications d'IA générative.
Apprentissage en contexte
Les LLM sont formés avec des données ponctuelles et n'ont aucune capacité inhérente à accéder à de nouvelles données au moment de l'inférence. À mesure que de nouvelles données apparaissent, vous devrez continuellement affiner ou entraîner davantage le modèle. Il s’agit non seulement d’une opération coûteuse, mais également très contraignante en pratique, car la vitesse de génération de nouvelles données dépasse de loin la vitesse de réglage fin. De plus, les LLM manquent de compréhension contextuelle et s'appuient uniquement sur leurs données de formation, et sont donc sujets aux hallucinations. Cela signifie qu’ils peuvent générer une réponse fluide, cohérente et syntaxiquement correcte, mais factuellement incorrecte. Ils sont également dépourvus de pertinence, de personnalisation et de contexte.
Les LLM, cependant, ont la capacité d'apprendre des données qu'ils reçoivent du contexte pour répondre avec plus de précision sans modifier les pondérations du modèle. C'est appelé apprentissage en contexte, et peut être utilisé pour produire des réponses personnalisées ou fournir une réponse précise dans le contexte des politiques de l'organisation.
Par exemple, dans un chatbot, les événements de données peuvent concerner un inventaire de vols et d'hôtels ou des changements de prix qui sont constamment ingérés dans un moteur de stockage en continu. De plus, les événements de données sont filtrés, enrichis et transformés dans un format consommable à l'aide d'un processeur de flux. Le résultat est mis à la disposition de l'application en interrogeant le dernier instantané. L'instantané est constamment mis à jour via le traitement du flux ; par conséquent, les données à jour sont fournies dans le contexte d'une invite utilisateur au modèle. Cela permet au modèle de s'adapter aux dernières modifications de prix et de disponibilité. Le diagramme suivant illustre un flux de travail d'apprentissage en contexte de base.
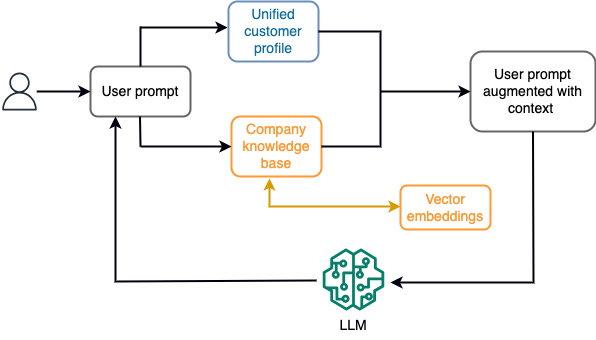
Une approche d’apprentissage en contexte couramment utilisée consiste à utiliser une technique appelée Retrieval Augmented Generation (RAG). Dans RAG, vous fournissez les informations pertinentes telles que la politique la plus pertinente et les enregistrements client ainsi que la question de l'utilisateur à l'invite. De cette façon, le LLM génère une réponse à la question de l'utilisateur en utilisant des informations supplémentaires fournies comme contexte. Pour en savoir plus sur RAG, reportez-vous à Réponse aux questions à l'aide de Retrieval Augmented Generation avec des modèles de base dans Amazon SageMaker JumpStart.
Une application d'IA générative basée sur RAG ne peut produire que des réponses génériques basées sur ses données de formation et les documents pertinents de la base de connaissances. Cette solution ne répond pas aux attentes lorsqu’une réponse personnalisée en temps quasi réel est attendue de la part de l’application. Par exemple, un chatbot de voyage devrait prendre en compte les réservations en cours de l'utilisateur, l'inventaire des hôtels et des vols disponibles, etc. De plus, les données personnelles pertinentes du client (communément appelées profil client unifié) est généralement sujet à changement. Si un processus par lots est utilisé pour mettre à jour la base de données de profils utilisateur de l'IA générative, le client peut recevoir des réponses insatisfaisantes basées sur d'anciennes données.
Dans cet article, nous discutons de l'application du traitement de flux pour améliorer une solution RAG utilisée pour créer des agents de réponse aux questions avec un contexte allant de l'accès en temps réel aux profils clients unifiés et à la base de connaissances organisationnelles.
Mises à jour du profil client en temps quasi réel
Les enregistrements clients sont généralement répartis dans les magasins de données au sein d'une organisation. Pour que votre application d'IA générative fournisse un profil client pertinent, précis et à jour, il est essentiel de créer des pipelines de données en streaming capables d'effectuer la résolution d'identité et l'agrégation de profils dans les magasins de données distribués. Les tâches de streaming ingèrent constamment de nouvelles données à synchroniser entre les systèmes et peuvent effectuer plus efficacement des enrichissements, des transformations, des jointures et des agrégations sur plusieurs fenêtres de temps. Les événements de capture de données modifiées (CDC) contiennent des informations sur l'enregistrement source, les mises à jour et les métadonnées telles que l'heure, la source, la classification (insertion, mise à jour ou suppression) et l'initiateur de la modification.
Le diagramme suivant illustre un exemple de flux de travail pour l'ingestion et le traitement du streaming CDC pour les profils clients unifiés.

Dans cette section, nous discutons des principaux composants d'un modèle de streaming CDC requis pour prendre en charge les applications d'IA générative basées sur RAG.
Ingestion de streaming CDC
Un réplicateur CDC est un processus qui collecte les modifications de données à partir d'un système source (généralement en lisant les journaux de transactions ou les binlogs) et écrit les événements CDC avec exactement le même ordre dans lequel ils se sont produits dans un flux de données ou un sujet en streaming. Cela implique une capture basée sur les journaux avec des outils tels que Service de migration de base de données AWS (AWS DMS) ou des connecteurs open source tels que Debezium pour Apache Kafka connect. Apache Kafka Connect fait partie de l'environnement Apache Kafka, permettant aux données d'être ingérées à partir de diverses sources et livrées vers diverses destinations. Vous pouvez exécuter votre connecteur Apache Kafka sur Connexion Amazon MSK en quelques minutes sans vous soucier de la configuration, de l'installation et du fonctionnement d'un cluster Apache Kafka. Il vous suffit de télécharger le code compilé de votre connecteur sur Service de stockage simple Amazon (Amazon S3) et configurez votre connecteur avec la configuration spécifique de votre charge de travail.
Il existe également d'autres méthodes pour capturer les modifications des données. Par exemple, Amazon DynamoDB fournit une fonctionnalité permettant de diffuser des données CDC vers Flux Amazon DynamoDB ou Flux de données Kinesis. Amazon S3 fournit un déclencheur pour appeler un AWS Lambda fonction lorsqu’un nouveau document est stocké.
Stockage en streaming
Le stockage en streaming fonctionne comme un tampon intermédiaire pour stocker les événements CDC avant qu'ils ne soient traités. Le stockage en streaming fournit un stockage fiable pour les données en streaming. De par sa conception, il est hautement disponible et résilient aux pannes matérielles ou de nœuds et maintient l'ordre des événements au fur et à mesure de leur écriture. Le stockage en streaming peut stocker des événements de données de manière permanente ou pendant une période de temps définie. Cela permet aux processeurs de flux de lire une partie du flux en cas de panne ou de besoin de retraitement. Kinesis Data Streams est un service de données en streaming sans serveur qui facilite la capture, le traitement et le stockage des flux de données à grande échelle. Amazon MSK est un service entièrement géré, hautement disponible et sécurisé fourni par AWS pour exécuter Apache Kafka.
Traitement de flux
Les systèmes de traitement de flux doivent être conçus pour le parallélisme afin de gérer un débit de données élevé. Ils doivent partitionner le flux d’entrée entre plusieurs tâches exécutées sur plusieurs nœuds de calcul. Les tâches doivent pouvoir envoyer le résultat d'une opération à la suivante sur le réseau, permettant ainsi de traiter les données en parallèle tout en effectuant des opérations telles que les jointures, le filtrage, l'enrichissement et les agrégations. Les applications de traitement de flux doivent être capables de traiter les événements en fonction de l'heure de l'événement pour les cas d'utilisation où les événements pourraient arriver en retard ou où le calcul correct repose sur l'heure à laquelle les événements se produisent plutôt que sur l'heure du système. Pour plus d'informations, reportez-vous à Notions de temps : temps d'événement et temps de traitement.
Les processus de flux produisent en permanence des résultats sous la forme d'événements de données qui doivent être transmis à un système cible. Un système cible peut être n’importe quel système pouvant s’intégrer directement au processus ou via un stockage en streaming comme intermédiaire. En fonction du framework que vous choisissez pour le traitement des flux, vous disposerez de différentes options pour les systèmes cibles en fonction des connecteurs récepteurs disponibles. Si vous décidez d'écrire les résultats sur un stockage de streaming intermédiaire, vous pouvez créer un processus distinct qui lit les événements et applique les modifications au système cible, par exemple en exécutant un connecteur récepteur Apache Kafka. Quelle que soit l’option que vous choisissez, les données CDC nécessitent un traitement supplémentaire en raison de leur nature. Étant donné que les événements CDC contiennent des informations sur les mises à jour ou les suppressions, il est important qu'ils fusionnent dans le système cible dans le bon ordre. Si les modifications sont appliquées dans le mauvais ordre, le système cible ne sera pas synchronisé avec sa source.
Apache Flink est un puissant framework de traitement de flux connu pour sa faible latence et ses capacités à haut débit. Il prend en charge le traitement de l'heure des événements, la sémantique du traitement exactement une fois et une tolérance élevée aux pannes. De plus, il fournit une prise en charge native des données CDC via une structure spéciale appelée tableaux dynamiques. Les tables dynamiques imitent les tables de la base de données source et fournissent une représentation en colonnes des données en streaming. Les données des tables dynamiques changent à chaque événement traité. De nouveaux enregistrements peuvent être ajoutés, mis à jour ou supprimés à tout moment. Les tables dynamiques éliminent la logique supplémentaire que vous devez implémenter pour chaque opération d'enregistrement (insertion, mise à jour, suppression) séparément. Pour plus d'informations, reportez-vous à Tableaux dynamiques.
Avec Service géré Amazon pour Apache Flink, vous pouvez exécuter des tâches Apache Flink et intégrer d'autres services AWS. Il n'y a pas de serveurs ni de clusters à gérer, et il n'y a pas d'infrastructure de calcul et de stockage à mettre en place.
Colle AWS est un service d'extraction, de transformation et de chargement (ETL) entièrement géré, ce qui signifie qu'AWS gère le provisionnement, la mise à l'échelle et la maintenance de l'infrastructure pour vous. Bien qu'il soit principalement connu pour ses capacités ETL, AWS Glue peut également être utilisé pour les applications de streaming Spark. AWS Glue peut interagir avec des services de données en streaming tels que Kinesis Data Streams et Amazon MSK pour traiter et transformer les données CDC. AWS Glue peut également s'intégrer de manière transparente à d'autres services AWS tels que Lambda, Fonctions d'étape AWS, et DynamoDB, vous offrant un écosystème complet pour créer et gérer des pipelines de traitement de données.
Profil client unifié
Surmonter l’unification du profil client sur une variété de systèmes sources nécessite le développement de pipelines de données robustes. Vous avez besoin de pipelines de données capables de regrouper et de synchroniser tous les enregistrements dans un seul magasin de données. Ce magasin de données fournit à votre organisation la vue holistique des dossiers clients nécessaire à l'efficacité opérationnelle des applications d'IA générative basées sur RAG. Pour créer un tel magasin de données, un magasin de données non structuré serait préférable.
Un graphique d'identité est une structure utile pour créer un profil client unifié car il consolide et intègre les données client provenant de diverses sources, garantit l'exactitude et la déduplication des données, offre des mises à jour en temps réel, connecte les informations inter-systèmes, permet la personnalisation, améliore l'expérience client et prend en charge la conformité réglementaire. Ce profil client unifié permet à l'application d'IA générative de comprendre et d'interagir efficacement avec les clients, et de respecter les réglementations en matière de confidentialité des données, améliorant ainsi l'expérience client et stimulant la croissance de l'entreprise. Vous pouvez créer votre solution de graphique d'identité en utilisant Amazone Neptune, un service de base de données graphique rapide, fiable et entièrement géré.
AWS propose quelques autres offres de services de stockage NoSQL gérés et sans serveur pour les objets clé-valeur non structurés. Amazon DocumentDB (avec compatibilité MongoDB) est une entreprise rapide, évolutive, hautement disponible et entièrement gérée base de données documentaire service qui prend en charge les charges de travail JSON natives. DynamoDB est un service de base de données NoSQL entièrement géré qui offre des performances rapides et prévisibles avec une évolutivité transparente.
Mises à jour de la base de connaissances organisationnelles en temps quasi réel
À l’instar des dossiers clients, les référentiels de connaissances internes tels que les politiques de l’entreprise et les documents organisationnels sont cloisonnés entre les systèmes de stockage. Il s’agit généralement de données non structurées et mises à jour de manière non incrémentielle. L'utilisation de données non structurées pour les applications d'IA est efficace grâce aux intégrations vectorielles, qui est une technique permettant de représenter des données de grande dimension telles que des fichiers texte, des images et des fichiers audio sous forme numérique multidimensionnelle.
AWS propose plusieurs services de moteurs vectoriels tels que Amazon OpenSearch sans serveur, Amazone Kendraet Édition compatible Amazon Aurora PostgreSQL avec l'extension pgvector pour stocker les intégrations vectorielles. Les applications d'IA générative peuvent améliorer l'expérience utilisateur en transformant l'invite utilisateur en vecteur et en l'utilisant pour interroger le moteur vectoriel afin de récupérer des informations contextuellement pertinentes. L'invite et les données vectorielles récupérées sont ensuite transmises au LLM pour recevoir une réponse plus précise et personnalisée.
Le diagramme suivant illustre un exemple de flux de travail de traitement de flux pour les intégrations vectorielles.
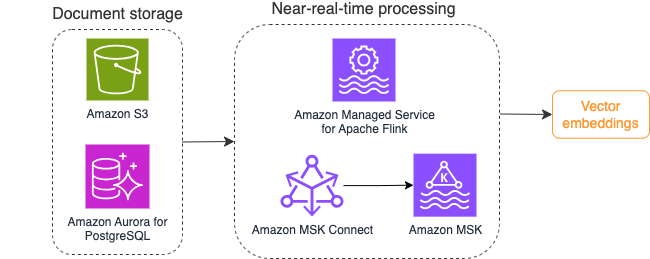
Le contenu de la base de connaissances doit être converti en intégrations vectorielles avant d'être écrit dans le magasin de données vectorielles. Socle amazonien or Amazon Sage Maker peut vous aider à accéder au modèle de votre choix et à exposer un point de terminaison privé pour cette conversion. De plus, vous pouvez utiliser des bibliothèques telles que LangChain pour intégrer ces points de terminaison. La création d'un processus par lots peut vous aider à convertir le contenu de votre base de connaissances en données vectorielles et à le stocker initialement dans une base de données vectorielle. Cependant, vous devez compter sur un intervalle pour retraiter les documents afin de synchroniser votre base de données vectorielles avec les modifications apportées au contenu de votre base de connaissances. Avec un grand nombre de documents, ce processus peut s’avérer inefficace. Entre ces intervalles, les utilisateurs de votre application d'IA générative recevront des réponses selon l'ancien contenu, ou recevront une réponse inexacte car le nouveau contenu n'est pas encore vectorisé.
Le traitement de flux est une solution idéale pour relever ces défis. Il produit initialement des événements selon les documents existants, surveille ensuite le système source et crée un événement de modification de document dès qu'ils se produisent. Ces événements peuvent être stockés dans un stockage de streaming et attendre d'être traités par une tâche de streaming. Une tâche de streaming lit ces événements, charge le contenu du document et transforme le contenu en un tableau de jetons de mots associés. Chaque jeton se transforme ensuite en données vectorielles via un appel API à un FM intégré. Les résultats sont envoyés pour stockage au stockage vectoriel via un opérateur de puits.
Si vous utilisez Amazon S3 pour stocker vos documents, vous pouvez créer une architecture de source d'événements basée sur des déclencheurs de modification d'objet S3 pour Lambda. Une fonction Lambda peut créer un événement au format souhaité et l'écrire sur votre stockage de streaming.
Vous pouvez également utiliser Apache Flink pour exécuter une tâche de streaming. Apache Flink fournit le connecteur source natif FileSystem, qui peut découvrir les fichiers existants et lire initialement leur contenu. Après cela, il peut surveiller en permanence votre système de fichiers pour détecter de nouveaux fichiers et capturer leur contenu. Le connecteur prend en charge la lecture d'un ensemble de fichiers à partir de systèmes de fichiers distribués tels qu'Amazon S3 ou HDFS avec un format de texte brut, Avro, CSV, Parquet, etc., et produit un enregistrement en streaming. En tant que service entièrement géré, Managed Service pour Apache Flink supprime les frais opérationnels liés au déploiement et à la maintenance des tâches Flink, vous permettant ainsi de vous concentrer sur la création et la mise à l'échelle de vos applications de streaming. Grâce à une intégration transparente dans les services de streaming AWS tels qu'Amazon MSK ou Kinesis Data Streams, il fournit des fonctionnalités telles que la mise à l'échelle automatique, la sécurité et la résilience, fournissant ainsi des applications Flink fiables et efficaces pour gérer les données de streaming en temps réel.
En fonction de vos préférences DevOps, vous pouvez choisir entre Kinesis Data Streams ou Amazon MSK pour stocker les enregistrements de streaming. Kinesis Data Streams simplifie les complexités liées à la création et à la gestion d'applications de données de streaming personnalisées, vous permettant de vous concentrer sur l'extraction d'informations à partir de vos données plutôt que sur la maintenance de l'infrastructure. Les clients utilisant Apache Kafka optent souvent pour Amazon MSK en raison de sa simplicité, de son évolutivité et de sa fiabilité dans la supervision des clusters Apache Kafka dans l'environnement AWS. En tant que service entièrement géré, Amazon MSK prend en charge les complexités opérationnelles associées au déploiement et à la maintenance des clusters Apache Kafka, vous permettant ainsi de vous concentrer sur la création et l'extension de vos applications de streaming.
Étant donné qu'une intégration d'API RESTful convient à la nature de ce processus, vous avez besoin d'un cadre qui prend en charge un modèle d'enrichissement avec état via des appels d'API RESTful pour suivre les échecs et réessayer pour la demande ayant échoué. Apache Flink est encore une fois un framework capable d'effectuer des opérations avec état à une vitesse en mémoire. Pour comprendre les meilleures façons d'effectuer des appels API via Apache Flink, reportez-vous à Modèles courants d'enrichissement des données de streaming dans Amazon Kinesis Data Analytics pour Apache Flink.
Apache Flink fournit des connecteurs récepteurs natifs pour écrire des données dans des banques de données vectorielles telles qu'Amazon Aurora pour PostgreSQL avec pgvector ou Service Amazon OpenSearch avec VectorDB. Vous pouvez également organiser la sortie de la tâche Flink (données vectorisées) dans une rubrique MSK ou un flux de données Kinesis. OpenSearch Service prend en charge l'ingestion native à partir de flux de données Kinesis ou de sujets MSK. Pour plus d'informations, reportez-vous à Présentation d'Amazon MSK en tant que source pour l'ingestion Amazon OpenSearch ainsi que Chargement de données en streaming à partir d'Amazon Kinesis Data Streams.
Analyse des commentaires et réglage fin
Il est important que les responsables des opérations de données et les développeurs d'IA/ML aient un aperçu des performances de l'application d'IA générative et des FM utilisés. Pour y parvenir, vous devez créer des pipelines de données qui calculent des données importantes sur les indicateurs de performance clés (KPI) en fonction des commentaires des utilisateurs et de la variété des journaux et des mesures des applications. Ces informations sont utiles aux parties prenantes pour obtenir un aperçu en temps réel des performances du FM, de l'application et de la satisfaction globale des utilisateurs quant à la qualité du support qu'ils reçoivent de votre application. Vous devez également collecter et stocker l'historique des conversations pour affiner davantage vos FM afin d'améliorer leur capacité à effectuer des tâches spécifiques à un domaine.
Ce cas d’utilisation s’intègre très bien dans le domaine de l’analyse de streaming. Votre application doit stocker chaque conversation dans un stockage de streaming. Votre application peut demander aux utilisateurs leur évaluation de l'exactitude de chaque réponse et leur satisfaction globale. Ces données peuvent être sous un format de choix binaire ou sous forme de texte libre. Ces données peuvent être stockées dans un flux de données Kinesis ou une rubrique MSK et traitées pour générer des KPI en temps réel. Vous pouvez utiliser les FM pour analyser les sentiments des utilisateurs. Les FM peuvent analyser chaque réponse et attribuer une catégorie de satisfaction des utilisateurs.
L'architecture d'Apache Flink permet une agrégation de données complexe sur des fenêtres temporelles. Il prend également en charge les requêtes SQL sur un flux d'événements de données. Par conséquent, en utilisant Apache Flink, vous pouvez analyser rapidement les entrées brutes des utilisateurs et générer des KPI en temps réel en écrivant des requêtes SQL familières. Pour plus d'informations, reportez-vous à API de tableaux et SQL.
Avec Service géré Amazon pour Apache Flink Studio, vous pouvez créer et exécuter des applications de traitement de flux Apache Flink à l'aide de SQL standard, Python et Scala dans un bloc-notes interactif. Les notebooks Studio sont alimentés par Apache Zeppelin et utilisent Apache Flink comme moteur de traitement de flux. Les notebooks Studio combinent de manière transparente ces technologies pour rendre les analyses avancées sur les flux de données accessibles aux développeurs de toutes compétences. Avec la prise en charge des fonctions définies par l'utilisateur (UDF), Apache Flink permet de créer des opérateurs personnalisés à intégrer à des ressources externes telles que les FM pour effectuer des tâches complexes telles que l'analyse des sentiments. Vous pouvez utiliser les UDF pour calculer diverses mesures ou enrichir les données brutes des commentaires des utilisateurs avec des informations supplémentaires telles que le sentiment des utilisateurs. Pour en savoir plus sur ce modèle, reportez-vous à Répondre de manière proactive aux préoccupations des clients en temps réel avec GenAI, Flink, Apache Kafka et Kinesis.
Avec Managed Service pour Apache Flink Studio, vous pouvez déployer votre notebook Studio en tant que tâche de streaming en un seul clic. Vous pouvez utiliser les connecteurs récepteurs natifs fournis par Apache Flink pour envoyer la sortie au stockage de votre choix ou la préparer dans un flux de données Kinesis ou une rubrique MSK. Redshift d'Amazon et OpenSearch Service sont tous deux idéaux pour stocker des données analytiques. Les deux moteurs fournissent une prise en charge native de l'ingestion depuis Kinesis Data Streams et Amazon MSK via un pipeline de streaming distinct vers un lac de données ou un entrepôt de données à des fins d'analyse.
Amazon Redshift utilise SQL pour analyser les données structurées et semi-structurées dans les entrepôts de données et les lacs de données, en utilisant le matériel conçu par AWS et l'apprentissage automatique pour offrir le meilleur rapport qualité-prix à grande échelle. OpenSearch Service offre des fonctionnalités de visualisation optimisées par OpenSearch Dashboards et Kibana (versions 1.5 à 7.10).
Vous pouvez utiliser le résultat d'une telle analyse combiné aux données d'invite de l'utilisateur pour affiner le FM lorsque cela est nécessaire. SageMaker est le moyen le plus simple d'affiner vos FM. L'utilisation d'Amazon S3 avec SageMaker offre une intégration puissante et transparente pour affiner vos modèles. Amazon S3 sert de solution de stockage d'objets évolutive et durable, permettant un stockage et une récupération simples d'ensembles de données volumineux, de données de formation et d'artefacts de modèle. SageMaker est un service ML entièrement géré qui simplifie l'ensemble du cycle de vie du ML. En utilisant Amazon S3 comme backend de stockage pour SageMaker, vous pouvez bénéficier de l'évolutivité, de la fiabilité et de la rentabilité d'Amazon S3, tout en l'intégrant de manière transparente aux capacités de formation et de déploiement de SageMaker. Cette combinaison permet une gestion efficace des données, facilite le développement de modèles collaboratifs et garantit que les flux de travail de ML sont rationalisés et évolutifs, améliorant ainsi l'agilité et les performances globales du processus de ML. Pour plus d'informations, reportez-vous à Affinez Falcon 7B et d'autres LLM sur Amazon SageMaker avec @remote decorator.
Grâce à un connecteur récepteur de système de fichiers, les tâches Apache Flink peuvent fournir des données à Amazon S3 dans des fichiers au format ouvert (tels que JSON, Avro, Parquet, etc.) en tant qu'objets de données. Si vous préférez gérer votre lac de données à l'aide d'un framework de lac de données transactionnel (tel qu'Apache Hudi, Apache Iceberg ou Delta Lake), tous ces frameworks fournissent un connecteur personnalisé pour Apache Flink. Pour plus de détails, reportez-vous à Créez un pipeline source à lac de données à faible latence à l'aide d'Amazon MSK Connect, d'Apache Flink et d'Apache Hudi.
Résumé
Pour une application d'IA générative basée sur un modèle RAG, vous devez envisager de créer deux systèmes de stockage de données et vous devez créer des opérations de données qui les maintiennent à jour avec tous les systèmes sources. Les tâches par lots traditionnelles ne suffisent pas pour traiter la taille et la diversité des données que vous devez intégrer à votre application d'IA générative. Les retards dans le traitement des modifications dans les systèmes sources entraînent une réponse inexacte et réduisent l'efficacité de votre application d'IA générative. Le streaming de données vous permet d'ingérer des données provenant de diverses bases de données sur différents systèmes. Il vous permet également de transformer, d'enrichir, de joindre et d'agréger efficacement des données provenant de nombreuses sources en temps quasi réel. Le streaming de données fournit une architecture de données simplifiée pour collecter et transformer les réactions ou commentaires en temps réel des utilisateurs sur les réponses de l'application, vous aidant ainsi à fournir et à stocker les résultats dans un lac de données pour un réglage précis du modèle. Le streaming de données vous aide également à optimiser les pipelines de données en traitant uniquement les événements de modification, ce qui vous permet de répondre plus rapidement et plus efficacement aux modifications de données.
En savoir plus sur Services de streaming de données AWS et commencez à créer votre propre solution de streaming de données.
À propos des auteurs
 Ali Alémi est un architecte de solutions spécialiste du streaming chez AWS. Ali conseille les clients AWS sur les meilleures pratiques architecturales et les aide à concevoir des systèmes de données d'analyse en temps réel fiables, sécurisés, efficaces et rentables. Il travaille à partir des cas d'utilisation des clients et conçoit des solutions de données pour résoudre leurs problèmes commerciaux. Avant de rejoindre AWS, Ali a accompagné plusieurs clients du secteur public et partenaires de conseil AWS dans leur parcours de modernisation des applications et de migration vers le cloud.
Ali Alémi est un architecte de solutions spécialiste du streaming chez AWS. Ali conseille les clients AWS sur les meilleures pratiques architecturales et les aide à concevoir des systèmes de données d'analyse en temps réel fiables, sécurisés, efficaces et rentables. Il travaille à partir des cas d'utilisation des clients et conçoit des solutions de données pour résoudre leurs problèmes commerciaux. Avant de rejoindre AWS, Ali a accompagné plusieurs clients du secteur public et partenaires de conseil AWS dans leur parcours de modernisation des applications et de migration vers le cloud.
 Imtiaz (Taz) Sayed est le leader technologique mondial pour l'analyse chez AWS. Il aime interagir avec la communauté sur tout ce qui concerne les données et l'analyse. Il est joignable via LinkedIn.
Imtiaz (Taz) Sayed est le leader technologique mondial pour l'analyse chez AWS. Il aime interagir avec la communauté sur tout ce qui concerne les données et l'analyse. Il est joignable via LinkedIn.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

