Nous avons récemment introduit une nouvelle capacité dans le SDK Amazon SageMaker Python qui permet aux scientifiques des données d'exécuter leur code d'apprentissage automatique (ML) créé dans leur environnement de développement intégré (IDE) préféré et leurs blocs-notes, ainsi que les dépendances d'exécution associées, comme Amazon Sage Maker tâches de formation avec des modifications de code minimales à l'expérimentation effectuée localement. Les scientifiques des données effectuent généralement plusieurs itérations d'expérimentation dans le traitement des données et les modèles de formation tout en travaillant sur n'importe quel problème de ML. Ils veulent exécuter ce code ML et effectuer l'expérimentation avec une facilité d'utilisation et un changement de code minimal. Formation sur le modèle Amazon SageMaker aide les data scientists à exécuter des tâches de formation à grande échelle entièrement gérées sur l'infrastructure de calcul d'AWS. La formation SageMaker aide également les data scientists avec des outils avancés tels que Débogueur Amazon SageMaker et Profiler pour déboguer et analyser leurs tâches de formation à grande échelle.
Pour les clients avec de petits budgets, de petites équipes et des délais serrés, chaque nouveau concept et ligne de code réécrit pour s'exécuter sur SageMaker les rend moins productifs pour leurs tâches principales, à savoir le traitement des données et la formation de modèles ML. Ils veulent écrire du code une seule fois dans le cadre de leur choix et pouvoir passer en toute transparence de l'exécution de code sur leurs ordinateurs portables ou portables à l'exécution de code à grande échelle à l'aide des fonctionnalités de SageMaker.
Grâce à cette nouvelle fonctionnalité du SDK SageMaker Python, les scientifiques des données peuvent intégrer leur code ML à la plateforme de formation SageMaker en quelques minutes. Il vous suffit d'ajouter une seule ligne de code à votre code ML, et SageMaker comprend intelligemment votre code ainsi que les ensembles de données et la configuration de l'environnement d'espace de travail et l'exécute comme une tâche de formation SageMaker. Vous pouvez ensuite tirer parti des fonctionnalités clés de la plate-forme de formation SageMaker, telles que la possibilité de faire évoluer facilement les tâches, et d'autres outils associés tels que Debugger et Profiler. Dans cette version, vous pouvez exécuter votre code Python de machine learning (ML) local en tant que tâche de formation Amazon SageMaker à nœud unique ou plusieurs tâches parallèles. Les tâches de formation distribuées (sur plusieurs nœuds) ne sont pas prises en charge par les fonctions distantes.
Dans cet article, nous vous montrons comment utiliser cette nouvelle fonctionnalité pour exécuter du code ML local en tant que tâche de formation SageMaker.
Vue d'ensemble de la solution
Vous pouvez maintenant exécuter votre code ML écrit dans votre IDE ou votre bloc-notes en tant que tâche de formation SageMaker en annotant la fonction, qui agit comme un point d'entrée dans la base de code de l'utilisateur, avec un simple décorateur. Lors de l'appel, cette fonctionnalité prend automatiquement un instantané de toutes les variables, fonctions, packages, variables d'environnement et autres exigences d'exécution associées à partir de votre code ML, les sérialise et les soumet en tant que tâche de formation SageMaker. Il s'intègre avec le récemment annoncé Fonction SageMaker Python SDK pour définir les valeurs par défaut des paramètres. Cette fonctionnalité simplifie les constructions SageMaker que vous devez apprendre pour pouvoir exécuter du code à l'aide de la formation SageMaker. Les scientifiques des données peuvent écrire, déboguer et itérer leur code dans n'importe quel IDE préféré (tel que Amazon SageMakerStudio, notebooks, VS Code ou PyCharm). Lorsque vous êtes prêt, vous pouvez annoter votre fonction Python avec le @remote decorator et exécutez-le en tant que tâche SageMaker à grande échelle.
Cette fonctionnalité utilise des objets Python open source familiers comme arguments et sorties. De plus, vous n'avez pas besoin de comprendre la gestion du cycle de vie des conteneurs et vous pouvez simplement exécuter vos charges de travail dans différents contextes de calcul (tels qu'un IDE local, Studio ou des tâches de formation) avec des frais généraux de configuration minimes. Pour exécuter n'importe quel code local en tant que tâche de formation SageMaker, cette fonctionnalité déduit les configurations requises pour exécuter les tâches, telles que Gestion des identités et des accès AWS (IAM), la clé de chiffrement et la configuration réseau, à partir des paramètres Studio ou IDE (qui peuvent être paramètres par défaut) et les transmet à la plateforme par défaut. Vous avez la possibilité de personnaliser votre environnement d'exécution dans l'infrastructure gérée SageMaker à l'aide de la configuration déduite ou de les remplacer au niveau du SDK en les transmettant en tant qu'arguments au décorateur.
Cette nouvelle fonctionnalité du SDK Python SageMaker transforme votre code ML dans un environnement d'espace de travail existant et tout code de traitement de données et ensembles de données associés en une tâche de formation SageMaker. Cette fonctionnalité recherche le code ML encapsulé dans un @remote décorateur et le traduit automatiquement en une tâche qui s'exécute dans Studio ou dans un IDE local tel que PyCharm.
Dans les sections suivantes, nous passons en revue les fonctionnalités de cette nouvelle fonctionnalité et comment lancer des fonctions Python en tant que tâches de formation SageMaker.
Pré-requis
Pour utiliser cette nouvelle fonctionnalité du SDK Python SageMaker et exécuter le code associé à cet article, vous avez besoin des prérequis suivants :
- Un compte AWS qui contiendra toutes vos ressources AWS
- Un rôle IAM pour accéder à SageMaker
- Accès à Studio ou à une instance de notebook SageMaker ou à un IDE tel que PyCharm
Utiliser le SDK des notebooks Studio et SageMaker
Vous pouvez utiliser cette fonctionnalité à partir de Studio en lançant un bloc-notes et en enveloppant votre code avec un @remote décorateur à l'intérieur du cahier. Vous devez d'abord importer la fonction distante à l'aide du code suivant :
from sagemaker.remote_function import remoteLorsque vous utilisez la fonction de décorateur, cette fonctionnalité interprète automatiquement la fonction de votre code et l'exécute en tant que tâche de formation SageMaker.
Vous pouvez également utiliser cette fonctionnalité à partir d'une instance de bloc-notes SageMaker. Vous devez d'abord démarrer une instance de bloc-notes, ouvrir Jupyter ou Jupyter Lab dessus et lancer un bloc-notes. Ensuite, importez la fonction distante comme indiqué dans le code précédent et enveloppez votre code avec le @remote décorateur. Nous incluons un exemple d'utilisation de la fonction de décorateur et des paramètres associés plus loin dans cet article.
Utiliser le SDK depuis votre environnement local
Vous pouvez également utiliser cette fonctionnalité à partir de votre IDE local. Comme prérequis, vous devez avoir le Interface de ligne de commande AWS (AWS CLI), SDK SageMaker Python et AWS SDK pour Python (Boto3) installé dans votre environnement local. Vous devez importer ces bibliothèques dans votre code, définir la session SageMaker, spécifier les paramètres et décorer votre fonction avec le @remote décorateur. Dans l'exemple de code suivant, nous exécutons une fonction de division simple en tant que tâche de formation SageMaker :
import boto3
import sagemaker
from sagemaker.remote_function import remote sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
settings = dict(
sagemaker_session=sm_session,
role=<IAM_ROLE_NAME>
instance_type="ml.m5.xlarge",
)
@remote(**settings)
def divide(x, y):
return x / y
if __name__ == "__main__":
print(divide(2, 3.0))Nous pouvons utiliser une méthodologie similaire pour exécuter des fonctions avancées en tant que tâches d'entraînement, comme indiqué dans la section suivante.
Lancer des fonctions Python en tant que tâches SageMaker
La nouvelle fonctionnalité SageMaker Python SDK vous permet d'exécuter des fonctions Python comme Emplois Formation SageMaker. Tout code Python, code de formation ML développé par des scientifiques des données à l'aide de leurs IDE locaux préférés (PyCharm, VS Code), des blocs-notes SageMaker ou des blocs-notes Studio peut être lancé en tant que tâche SageMaker gérée.
Dans les charges de travail ML utilisant cette fonctionnalité, les ensembles de données, les dépendances et les configurations d'environnement d'espace de travail associés sont sérialisés à l'aide du code ML et exécutés en tant que tâche SageMaker de manière synchrone et asynchrone.
Vous pouvez ajouter un @remote annotation de décorateur à tout code Python, y compris une fonction de traitement ou de formation ML locale pour le lancer en tant que tâche de formation SageMaker gérée, tirant ainsi parti de l'échelle, des performances et des avantages de SageMaker en termes de coûts. Cela peut être réalisé avec des modifications de code minimales en ajoutant un décorateur au code de la fonction Python. L'appel à la fonction décorée est exécuté de manière synchrone et l'exécution de la fonction attend que le travail SageMaker soit terminé.
Dans l'exemple suivant, nous utilisons le @remote décorateur pour lancer les tâches SageMaker en mode décorateur à l'aide d'une instance ml.m5.large. SageMaker utilise des tâches de formation pour lancer cette fonction en tant que tâche gérée.
from sagemaker.remote_function import remote
from numpy as np @remote(instance_type="ml.m5.large")
def matrix_multiply(a, b): return np.matmul(a, b) a = np.array([[1, 0], [0, 1]])
b = np.array([1, 2]) assert matrix_multiply(a, b) == np.array([1,2])Vous pouvez également utiliser le mode décorateur pour lancer des tâches SageMaker, des packages Python et des dépendances. Vous pouvez inclure des variables d'environnement telles que VPC, des sous-réseaux et des groupes de sécurité pour lancer des tâches de formation SageMaker dans le environment.yml déposer. Cela permet aux ingénieurs ML et aux administrateurs de configurer ces variables d'environnement afin que les scientifiques des données puissent se concentrer sur la création de modèles ML et itérer plus rapidement. Voir le code suivant :
from sagemaker.remote_function import remote @remote(instance_type="ml.g4dn.xlarge",dependencies = "./environment.yml")
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
... <TRUCNATED>
return os.path.join(s3_output_path, model_dir), eval_resultVous pouvez utiliser RemoteExecutor pour lancer des fonctions Python en tant que tâches SageMaker de manière asynchrone. L'exécuteur interroge de manière asynchrone les tâches de formation SageMaker pour mettre à jour l'état de la tâche. Le RemoteExecutor classe est une implémentation de la concurrent.futures.exécuteur, qui est utilisé pour soumettre des tâches de formation SageMaker de manière asynchrone. Voir le code suivant :
from sagemaker.remote_function import RemoteExecutor def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
...<TRUNCATED>
return os.path.join(s3_output_path, model_dir), eval_result with RemoteExecutor(instance_type="ml.g4dn.xlarge", dependencies = './requirements.txt') as e:
future = e.submit(train_hf_model, train_input_path,test_input_path,s3_output_path,
epochs, train_batch_size, eval_batch_size,warmup_steps,learning_rate)Personnaliser l'environnement d'exécution
Mode décorateur et RemoteExecutor vous permettent de définir et de personnaliser les environnements d'exécution pour le travail SageMaker. Les dépendances d'exécution, y compris les packages Python et les variables d'environnement pour les tâches SageMaker, peuvent être spécifiées pour personnaliser l'exécution. Afin d'exécuter du code Python local en tant que tâches gérées par SageMaker, le package Python et les dépendances doivent être mis à la disposition de SageMaker. Les ingénieurs ML ou les administrateurs de science des données peuvent configurer des configurations de réseau et de sécurité telles que VPC, des sous-réseaux et des groupes de sécurité pour les travaux SageMaker, afin que les scientifiques des données puissent utiliser ces configurations gérées de manière centralisée lors du lancement des travaux SageMaker. Vous pouvez utiliser soit un requirements.txt Un fichier ou un Conda environment.yaml fichier.
Lorsque les dépendances sont définies avec requirements.txt, les packages seront installés à l'aide de pip dans l'exécution du travail. Si l'image utilisée pour exécuter la tâche est fournie avec des environnements Conda, les packages seront installés dans l'environnement Conda déclaré à utiliser pour les tâches. Le code suivant montre un exemple requirements.txt fichier:
datasets
transformers
torch
scikit-learn
s3fs==0.4.2
sagemaker>=2.148.0Vous pouvez passer votre Conda environment.yaml fichier pour créer l'environnement Conda dans lequel vous souhaitez que votre code s'exécute pendant la tâche d'entraînement. Si l'image utilisée pour exécuter le travail déclare un environnement Conda sous lequel exécuter le code, nous mettrons à jour l'environnement Conda déclaré avec la spécification donnée. Le code suivant est un exemple de Conda environment.yaml fichier:
name: sagemaker_example
channels: - conda-forge
dependencies: - python=3.10 - pandas - pip: - sagemakerAlternativement, vous pouvez définir dependencies=”auto_capture” pour laisser le SDK Python SageMaker capturer les dépendances installées dans l'environnement Conda actif. Vous devez avoir un environnement Conda actif pour auto_capture travailler. Notez qu'il y a des prérequis pour auto_capture travailler; nous vous recommandons de transmettre vos dépendances en tant que requirement.txt or Conda environment.yml fichier comme décrit dans la section précédente.
Pour plus de détails, reportez-vous à Exécutez votre code local en tant que tâche de formation SageMaker.
Configurations pour les tâches SageMaker
Les paramètres liés à l'infrastructure peuvent être déchargés dans un fichier de configuration que les utilisateurs administrateurs peuvent aider à configurer. Vous n'avez besoin de le configurer qu'une seule fois. Les paramètres d'infrastructure couvrent la configuration du réseau, les rôles IAM, Service de stockage simple Amazon (Amazon S3) pour les données d'entrée, de sortie et les balises. Faire référence à Configuration et utilisation des valeurs par défaut avec le SDK SageMaker Python pour plus de détails.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: path/to/requirements.txt
EnvironmentVariables: {"EnvVarKey": "EnvVarValue"}
ImageUri: 366666666666.dkr.ecr.us-west-2.amazonaws.com/my-image:latest
InstanceType: ml.m5.large
RoleArn: arn:aws:iam::366666666666:role/MyRole
S3KmsKeyId: somekmskeyid
S3RootUri: s3://my-bucket/my-project
SecurityGroupIds:
- sg123
Subnets:
- subnet-1234
Tags:
- {"Key": "someTagKey", "Value": "someTagValue"}
VolumeKmsKeyId: somekmskeyidImplémentation
Les modèles d'apprentissage en profondeur tels que PyTorch ou TensorFlow peuvent également être exécutés dans Studio en exécutant le code en tant que tâche d'entraînement dans le notebook. Pour présenter cette fonctionnalité dans Studio, vous pouvez cloner ce référentiel dans votre Studio et exécuter le notebook situé dans le GitHub dépôt.
Cet exemple illustre un cas d'utilisation de classification de texte binaire de bout en bout. Nous utilisons la bibliothèque de transformateurs et d'ensembles de données Hugging Face pour affiner un transformateur pré-formé sur la classification de texte binaire. En particulier, le modèle pré-entraîné sera affiné à l'aide de la Jeu de données IMDb.
Lorsque vous clonez le dépôt, vous devez localiser les fichiers suivants :
- config.yaml - La plupart des arguments du décorateur peuvent être déchargés dans le fichier de configuration afin de séparer les paramètres liés à l'infrastructure de la base de code
- câlinface.ipynb – Ceci contient le code pour former un modèle HuggingFace pré-formé, qui sera affiné à l'aide de l'ensemble de données IMDB
- conditions.txt – Ce fichier contient toutes les dépendances pour exécuter la fonction qui sera utilisée dans ce notebook pour exécuter le code et exécuter la formation à distance dans une instance GPU en tant que tâche de formation
Lorsque vous ouvrez le bloc-notes, vous serez invité à configurer l'environnement du bloc-notes. Vous pouvez sélectionner l'image Data Science 3.0 avec le noyau Python 3 et ml.m5.large comme type d'instance de lancement rapide pour exécuter le code du bloc-notes. Ce type d'instance est beaucoup plus rapide pour faire tourner un environnement.
La tâche d'entraînement sera exécutée dans une instance ml.g4dn.xlarge telle que définie dans le config.yaml fichier:
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn: <IAM_ROLE_ARN>
InstanceType: ml.g4dn.xlarge
Dependencies: ./requirements.txtLa requirements.txt les dépendances de fichiers pour exécuter la fonction d'entraînement du modèle Hugging Face incluent les éléments suivants :
datasets
transformers
torch
scikit-learn
# lock s3fs to this specific version as more recent ones introduce dependency on aiobotocore, which is not compatible with botocore
s3fs==0.4.2
sagemaker>=2.148.0,<3Le bloc-notes Hugging Face montre comment exécuter la formation à distance via le @remote fonction, qui est exécutée de manière synchrone. Par conséquent, la fonction exécutée pour former le modèle attendra que la tâche de formation SageMaker soit terminée. La formation sera exécutée à distance avec une instance GPU dans laquelle le type d'instance est défini dans le fichier de configuration précédent.
Après avoir exécuté la tâche d'entraînement, vous pouvez exécuter le reste des cellules du bloc-notes pour inspecter les métriques d'évaluation et classer le texte sur notre modèle entraîné.
Vous pouvez également afficher l'état de la tâche de formation qui a été déclenchée à distance dans l'instance GPU sur le tableau de bord SageMaker en revenant à la console SageMaker.
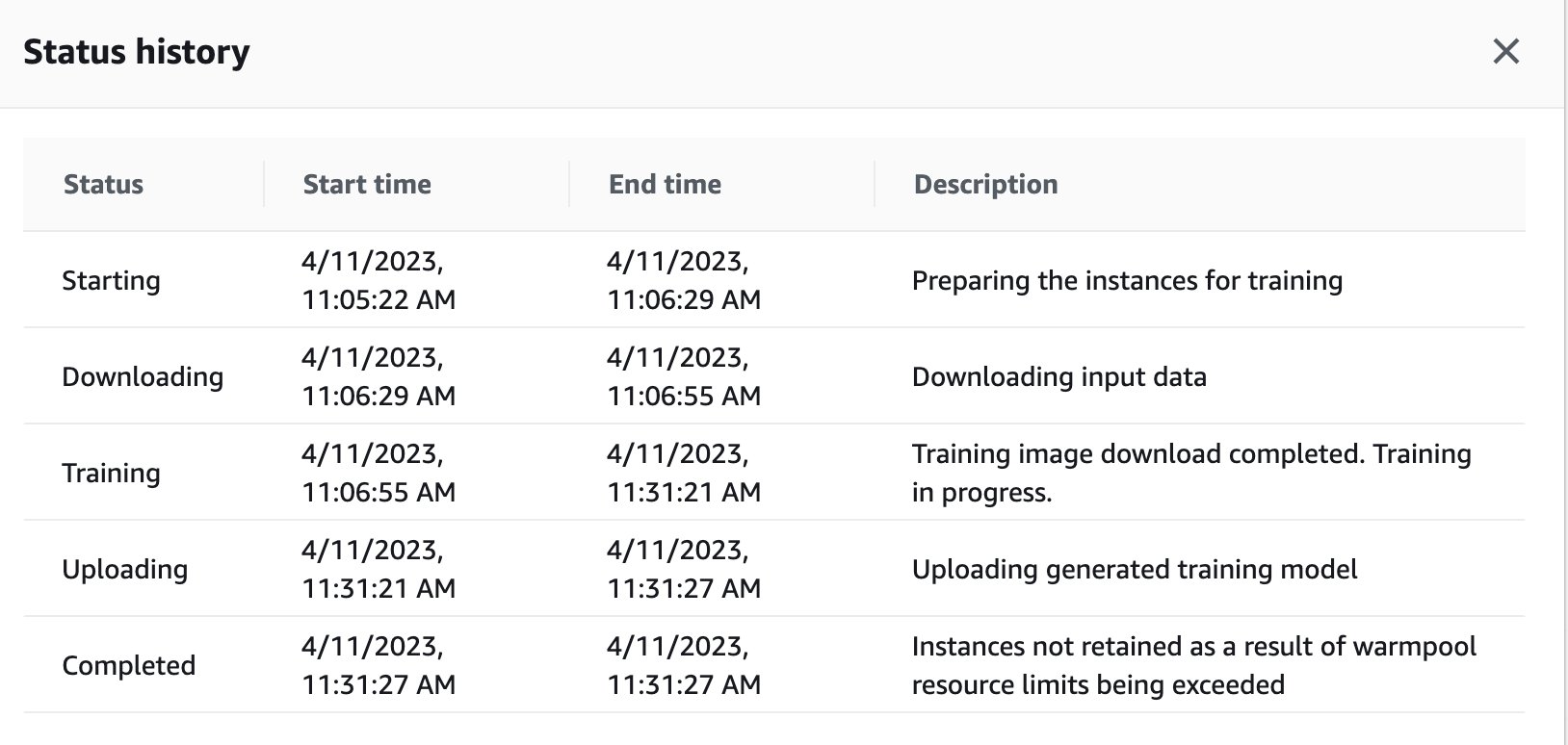
Dès que la tâche d'entraînement est terminée, elle continue d'exécuter les instructions du bloc-notes à des fins d'évaluation et de classification. Des tâches similaires peuvent être formées et exécutées via la fonction d'exécuteur à distance intégrée dans les notebooks Studio pour effectuer les exécutions de manière asynchrone.
Intégration avec les expériences SageMaker dans une fonction @remote
Vous pouvez transmettre votre nom d'expérience, votre nom d'exécution et d'autres paramètres dans votre fonction distante pour créer une exécution d'expériences SageMaker. L'exemple de code suivant importe le nom de l'expérience, le nom de l'exécution et les paramètres à consigner pour chaque exécution :
from sagemaker.remote_function import remote
from sagemaker.experiments.run import Run
# Define your remote function
@remote
def train(value_1, value_2, exp_name, run_name):
...
...
#Creates the experiment
with Run( experiment_name=exp_name, run_name=run_name, sagemaker_session=sagemaker_session
) as run:
...
...
#Define values for the parameters to log
run.log_parameter("param_1", value_1)
run.log_parameter("param_2", value_2)
...
...
#Define metrics to log
run.log_metric("metric_a", 0.5)
run.log_metric("metric_b", 0.1) # Invoke your remote function
train(1.0, 2.0, "my-exp-name", "my-run-name") Dans l'exemple précédent, les paramètres p1 ainsi que p2 sont enregistrés au fil du temps à l'intérieur d'une boucle d'entraînement. Les paramètres communs peuvent inclure la taille du lot ou les époques. Dans l'exemple, les métriques A ainsi que B sont enregistrés pour une course au fil du temps à l'intérieur d'une boucle d'entraînement. Les métriques courantes peuvent inclure la précision ou la perte. Pour plus d'informations, voir Créer une expérience Amazon SageMaker.
Conclusion
Dans cet article, nous avons introduit une nouvelle fonctionnalité SageMaker Python SDK qui permet aux data scientists d'exécuter leur code ML dans leur IDE préféré en tant que tâches de formation SageMaker. Nous avons discuté des conditions préalables nécessaires pour utiliser cette capacité ainsi que de ses fonctionnalités. Nous avons également montré comment utiliser cette fonctionnalité dans Studio, les instances de bloc-notes SageMaker et votre IDE local. En outre, nous avons fourni des exemples de code pour montrer comment utiliser cette fonctionnalité. À l'étape suivante, nous vous recommandons d'essayer cette fonctionnalité dans votre IDE ou SageMaker en suivant les exemples de code référencé dans ce billet.
À propos des auteurs
 Patro Dipankar est ingénieur en développement logiciel chez AWS SageMaker, innovant et créant des solutions MLOps pour aider les clients à adopter des solutions AI/ML à grande échelle. Il est titulaire d'une maîtrise en informatique et ses domaines d'intérêt sont la sécurité informatique, les systèmes distribués et l'IA/ML.
Patro Dipankar est ingénieur en développement logiciel chez AWS SageMaker, innovant et créant des solutions MLOps pour aider les clients à adopter des solutions AI/ML à grande échelle. Il est titulaire d'une maîtrise en informatique et ses domaines d'intérêt sont la sécurité informatique, les systèmes distribués et l'IA/ML.
 Farouq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
Farouq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
 Manoj Ravi est chef de produit senior pour Amazon SageMaker. Il est passionné par la création de produits d'IA de nouvelle génération et travaille sur des logiciels et des outils pour faciliter l'apprentissage automatique à grande échelle pour les clients. Il est titulaire d'un MBA de la Haas School of Business et d'une maîtrise en gestion des systèmes d'information de l'Université Carnegie Mellon. Dans ses temps libres, Manoj aime jouer au tennis et poursuivre la photographie de paysage.
Manoj Ravi est chef de produit senior pour Amazon SageMaker. Il est passionné par la création de produits d'IA de nouvelle génération et travaille sur des logiciels et des outils pour faciliter l'apprentissage automatique à grande échelle pour les clients. Il est titulaire d'un MBA de la Haas School of Business et d'une maîtrise en gestion des systèmes d'information de l'Université Carnegie Mellon. Dans ses temps libres, Manoj aime jouer au tennis et poursuivre la photographie de paysage.
 Shikhar Kwatra est un architecte de solutions spécialisé AI/ML chez Amazon Web Services, travaillant avec un intégrateur de systèmes mondial de premier plan. Il a obtenu le titre de l'un des plus jeunes maîtres inventeurs indiens avec plus de 500 brevets dans les domaines AI/ML et IoT. Shikhar aide à l'architecture, à la création et à la maintenance d'environnements cloud rentables et évolutifs pour l'organisation, et aide le partenaire GSI à créer des solutions sectorielles stratégiques sur AWS. Shikhar aime jouer de la guitare, composer de la musique et pratiquer la pleine conscience pendant son temps libre.
Shikhar Kwatra est un architecte de solutions spécialisé AI/ML chez Amazon Web Services, travaillant avec un intégrateur de systèmes mondial de premier plan. Il a obtenu le titre de l'un des plus jeunes maîtres inventeurs indiens avec plus de 500 brevets dans les domaines AI/ML et IoT. Shikhar aide à l'architecture, à la création et à la maintenance d'environnements cloud rentables et évolutifs pour l'organisation, et aide le partenaire GSI à créer des solutions sectorielles stratégiques sur AWS. Shikhar aime jouer de la guitare, composer de la musique et pratiquer la pleine conscience pendant son temps libre.
 Vikram Elango est un architecte de solutions spécialisé AI/ML chez AWS, basé en Virginie, aux États-Unis. Il se concentre actuellement sur l'IA générative, les LLM, l'ingénierie rapide, l'optimisation de l'inférence de grands modèles et la mise à l'échelle du ML dans les entreprises. Vikram aide les clients des secteurs de la finance et de l'assurance en matière de conception et de leadership éclairé pour créer et déployer des applications d'apprentissage automatique à grande échelle. Dans ses temps libres, il aime voyager, faire de la randonnée, cuisiner et camper.
Vikram Elango est un architecte de solutions spécialisé AI/ML chez AWS, basé en Virginie, aux États-Unis. Il se concentre actuellement sur l'IA générative, les LLM, l'ingénierie rapide, l'optimisation de l'inférence de grands modèles et la mise à l'échelle du ML dans les entreprises. Vikram aide les clients des secteurs de la finance et de l'assurance en matière de conception et de leadership éclairé pour créer et déployer des applications d'apprentissage automatique à grande échelle. Dans ses temps libres, il aime voyager, faire de la randonnée, cuisiner et camper.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/run-your-local-machine-learning-code-as-amazon-sagemaker-training-jobs-with-minimal-code-changes/

