Trill est un moteur de requête SQL distribué open source conçu pour les charges de travail analytiques interactives. Sur AWS, vous pouvez exécuter Trino sur Amazon DME, où vous avez la possibilité d'exécuter votre version préférée de Trino open source sur Cloud de calcul élastique Amazon (Amazon EC2) que vous gérez, ou sur Amazone Athéna pour une expérience sans serveur. Lorsque vous utilisez Trino sur Amazon EMR ou Athena, vous bénéficiez des dernières innovations de la communauté open source ainsi que des optimisations propriétaires développées par AWS.
À partir d'Amazon EMR 6.8.0 et de la version 2 du moteur Athena, AWS a développé des optimisations du plan de requête et du comportement du moteur qui améliorent les performances des requêtes sur Trino. Dans cet article, nous comparons Amazon EMR 6.15.0 avec Trino 426 open source et montrons que les requêtes TPC-DS ont été exécutées jusqu'à 2.7 fois plus rapidement sur Amazon EMR 6.15.0 Trino 426 par rapport à Amazon EMR XNUMX Trino XNUMX. Trino 426 open source. Nous expliquons plus tard quelques-unes des optimisations de performances développées par AWS qui contribuent à ces résultats.
Configuration de référence
Lors de nos tests, nous avons utilisé l'ensemble de données de 3 To stocké dans Amazon S3 au format Parquet compressé et les métadonnées des bases de données et des tables sont stockées dans le format Parquet compressé. Colle AWS Catalogue de données. Ce test utilise un schéma de données et des relations de table TPC-DS non modifiés. Les tables de faits sont partitionnées sur la colonne de date et contiennent 200 à 2100 XNUMX partitions. Les statistiques des tables et des colonnes n’étaient présentes pour aucune des tables. Nous avons utilisé les requêtes TPC-DS du logiciel open source Trino Github référentiel sans modification. Les requêtes de référence ont été exécutées séquentiellement sur deux clusters Amazon EMR 6.15.0 différents : l'un avec Amazon EMR Trino 426 et l'autre avec Trino 426 open source. Les deux clusters utilisaient 1 coordinateur r5.4xlarge et 20 instances de travail r5.4xlarge.
Résultats observés
Nos tests montrent des performances constamment meilleures avec Trino sur Amazon EMR 6.15.0 par rapport à Trino open source. Le temps d'exécution total des requêtes de Trino sur Amazon EMR était 2.7 fois plus rapide que celui de l'open source. Le graphique suivant montre les améliorations de performances mesurées par la durée totale d'exécution des requêtes (en secondes) pour les requêtes de référence.
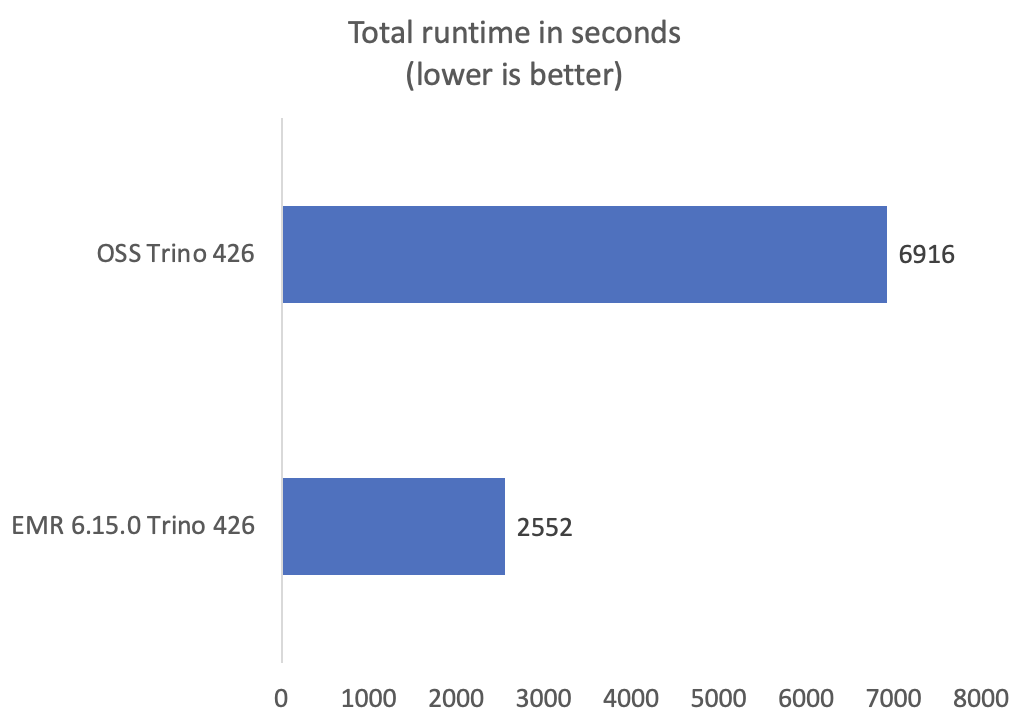
De nombreuses requêtes TPC-DS ont démontré des gains de performances cinq fois plus rapides par rapport à Trino open source. Certaines requêtes ont montré des performances encore plus élevées, comme la requête 72 qui s'est améliorée de 160 fois. Le graphique suivant montre les 10 principales requêtes TPC-DS présentant la plus grande amélioration du temps d'exécution. Pour une représentation succincte et pour éviter toute asymétrie des améliorations de performances dans le graphique, nous avons exclu q72.

Améliorations de la performance
Maintenant que nous comprenons les gains de performances obtenus avec Trino sur Amazon EMR, approfondissons certaines des innovations clés développées par l'ingénierie AWS qui contribuent à ces améliorations.
Le choix d'un meilleur ordre de jointure et d'un meilleur type de jointure est essentiel pour améliorer les performances des requêtes, car cela peut affecter la quantité de données lues à partir d'une table particulière, la quantité de données transférées vers les étapes intermédiaires via le réseau et la quantité de mémoire nécessaire à la création. une table de hachage pour faciliter une jointure. Les décisions relatives à l'ordre de jointure et à l'algorithme de jointure sont généralement une fonction exécutée par des optimiseurs basés sur les coûts, qui utilisent des statistiques pour améliorer les plans de requête en décidant de la manière dont les tables et les sous-requêtes sont jointes.
Cependant, les statistiques des tableaux sont souvent indisponibles, obsolètes ou trop coûteuses à collecter sur de grands tableaux. Lorsque les statistiques ne sont pas disponibles, Amazon EMR et Athena utilisent les métadonnées des fichiers S3 pour optimiser les plans de requête. Les métadonnées du fichier S3 sont utilisées pour déduire de petites sous-requêtes et tables dans la requête tout en déterminant l'ordre de jointure ou le type de jointure. Par exemple, considérons la requête suivante :
L'ordre de jointure syntaxique est store_sales jointures store_returns jointures call_center. Grâce au type de jointure Amazon EMR et aux règles d'optimisation de la sélection d'ordre, l'ordre de jointure optimal est déterminé même si ces tables ne disposent pas de statistiques. Pour la requête précédente si call_center est considéré comme une petite table après avoir estimé la taille approximative via les métadonnées du fichier S3, les règles d'optimisation de jointure d'EMR rejoindront store_sales avec call_center d'abord et convertissez la jointure en jointure de diffusion, accélérant ainsi la requête et réduisant la consommation de mémoire. La réorganisation des jointures minimise la taille des résultats intermédiaires, ce qui contribue à réduire davantage la durée d'exécution globale des requêtes.
Avec Amazon EMR 6.10.0 et versions ultérieures, les optimisations de jointure basées sur les métadonnées des fichiers S3 sont activées par défaut. Si vous utilisez Amazon EMR 6.8.0 ou 6.9.0, vous pouvez activer ces optimisations en définissant les propriétés de session des clients Trino ou en ajoutant les propriétés suivantes à la classification trino-config lors de la création de votre cluster. Faire référence à Configurer les applications pour plus de détails sur la façon de remplacer les configurations par défaut d'une application.
Configuration pour la sélection du type de jointure :
Configuration pour la réorganisation des jointures :
Conclusion
Avec Amazon EMR 6.8.0 et versions ultérieures, vous pouvez exécuter des requêtes sur Trino beaucoup plus rapidement que sur Trino open source. Comme le montre cet article de blog, notre benchmark TPC-DS a montré une amélioration de 2.7 fois du temps d'exécution total des requêtes avec Trino sur Amazon EMR 6.15.0. Les optimisations abordées dans cet article, et bien d'autres, sont également disponibles lors de l'exécution de requêtes Trino sur Athena, où des améliorations de performances similaires sont observées. Pour en savoir plus, reportez-vous au Exécutez des requêtes 3 fois plus rapidement avec jusqu'à 70 % d'économies sur le dernier moteur Amazon Athena.
Dans notre mission d'innover au nom des clients, Amazon EMR et Athena publient fréquemment des améliorations de performances et de fiabilité sur leurs dernières versions. Vérifier la Amazon DME ainsi que Amazone Athéna pages de version pour en savoir plus sur les nouvelles fonctionnalités et améliorations.
À propos des auteurs
 Bhargavi Sagi est ingénieur en développement logiciel sur Amazon Athena. Elle a rejoint AWS en 2020 et a travaillé sur différents domaines d'Amazon EMR et du moteur Athena V3, notamment la mise à niveau du moteur, la fiabilité et les performances du moteur.
Bhargavi Sagi est ingénieur en développement logiciel sur Amazon Athena. Elle a rejoint AWS en 2020 et a travaillé sur différents domaines d'Amazon EMR et du moteur Athena V3, notamment la mise à niveau du moteur, la fiabilité et les performances du moteur.
 Sushil Kumar Shivashankar est le responsable de l'ingénierie pour l'équipe EMR Trino et Athena Query Engine. Il se concentre sur le domaine de l'analyse du Big Data depuis 2014.
Sushil Kumar Shivashankar est le responsable de l'ingénierie pour l'équipe EMR Trino et Athena Query Engine. Il se concentre sur le domaine de l'analyse du Big Data depuis 2014.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/run-trino-queries-2-7-times-faster-with-amazon-emr-6-15-0/

