Flux de travail géré par Amazon pour Apache Airflow (Amazon MWAA) est un service géré qui vous permet d'utiliser un Flux d'air Apache avec une évolutivité, une disponibilité et une sécurité améliorées pour améliorer et faire évoluer vos flux de travail d'entreprise sans la charge opérationnelle liée à la gestion de l'infrastructure sous-jacente. Dans le flux d'air, Graphes acycliques dirigés (DAG) sont définis comme du code Python. DAG dynamiques fait référence à la possibilité de générer des DAG à la volée pendant l'exécution, généralement en fonction de certaines conditions, configurations ou paramètres externes. Les DAG dynamiques vous aident à créer, planifier et exécuter des tâches au sein d'un DAG en fonction de données et de configurations qui peuvent changer au fil du temps.
Il existe différentes manières d'introduire du dynamisme dans les DAG Airflow (génération dynamique de DAG) en utilisant des variables d'environnement et des fichiers externes. Une des approches consiste à utiliser le Usine DAG Méthode de fichier de configuration basée sur YAML. Cette bibliothèque vise à faciliter la création et la configuration de nouveaux DAG en utilisant des paramètres déclaratifs en YAML. Il permet des personnalisations par défaut et est open source, ce qui simplifie la création et la personnalisation de nouvelles fonctionnalités.
Dans cet article, nous explorons le processus de création de DAG dynamiques avec des fichiers YAML, à l'aide de l'outil Usine DAG bibliothèque. Les DAG dynamiques offrent plusieurs avantages :
- Réutilisabilité améliorée du code – En structurant les DAG via des fichiers YAML, nous favorisons les composants réutilisables, réduisant ainsi la redondance dans vos définitions de workflow.
- Maintenance rationalisée – La génération de DAG basée sur YAML simplifie le processus de modification et de mise à jour des flux de travail, garantissant ainsi des procédures de maintenance plus fluides.
- Paramétrage flexible – Avec YAML, vous pouvez paramétrer les configurations DAG, facilitant ainsi les ajustements dynamiques des flux de travail en fonction de différentes exigences.
- Efficacité améliorée du planificateur – Les DAG dynamiques permettent une planification plus efficace, optimisant l'allocation des ressources et améliorant les exécutions globales du flux de travail
- Évolutivité améliorée – Les DAG pilotés par YAML permettent des exécutions parallèles, ce qui permet des flux de travail évolutifs capables de gérer efficacement des charges de travail accrues.
En exploitant la puissance des fichiers YAML et de la bibliothèque DAG Factory, nous proposons une approche polyvalente de création et de gestion de DAG, vous permettant de créer des pipelines de données robustes, évolutifs et maintenables.
Présentation de la solution
Dans cet article, nous utiliserons un exemple de fichier DAG conçu pour traiter un ensemble de données COVID-19. Le processus de workflow implique le traitement d'un ensemble de données open source proposé par OMS-COVID-19-Monde. Après avoir installé le Usine DAG Package Python, nous créons un fichier YAML contenant les définitions de diverses tâches. Nous traitons le décompte des décès par pays en passant Country en tant que variable, ce qui crée des DAG individuels par pays.
Le diagramme suivant illustre la solution globale ainsi que les flux de données au sein des blocs logiques.

Pré-requis
Pour cette procédure pas à pas, vous devez disposer des prérequis suivants:
De plus, effectuez les étapes suivantes (exécutez l'installation dans un Région AWS où Amazon MWAA est disponible) :
- Créer un Environnement Amazon MWAA (si vous n'en avez pas déjà un). Si c'est la première fois que vous utilisez Amazon MWAA, reportez-vous à Présentation d'Amazon Managed Workflows pour Apache Airflow (MWAA).
Assurez-vous que le Gestion des identités et des accès AWS L'utilisateur ou le rôle (IAM) utilisé pour configurer l'environnement est associé à des stratégies IAM pour les autorisations suivantes :
Les politiques d'accès mentionnées ici ne sont qu'à titre d'exemple dans cet article. Dans un environnement de production, fournissez uniquement les autorisations granulaires nécessaires en exerçant principes du moindre privilège.
- Créez un nom de compartiment Amazon S3 unique (au sein d'un compte) lors de la création de votre environnement Amazon MWAA et créez des dossiers appelés
dagsainsi querequirements.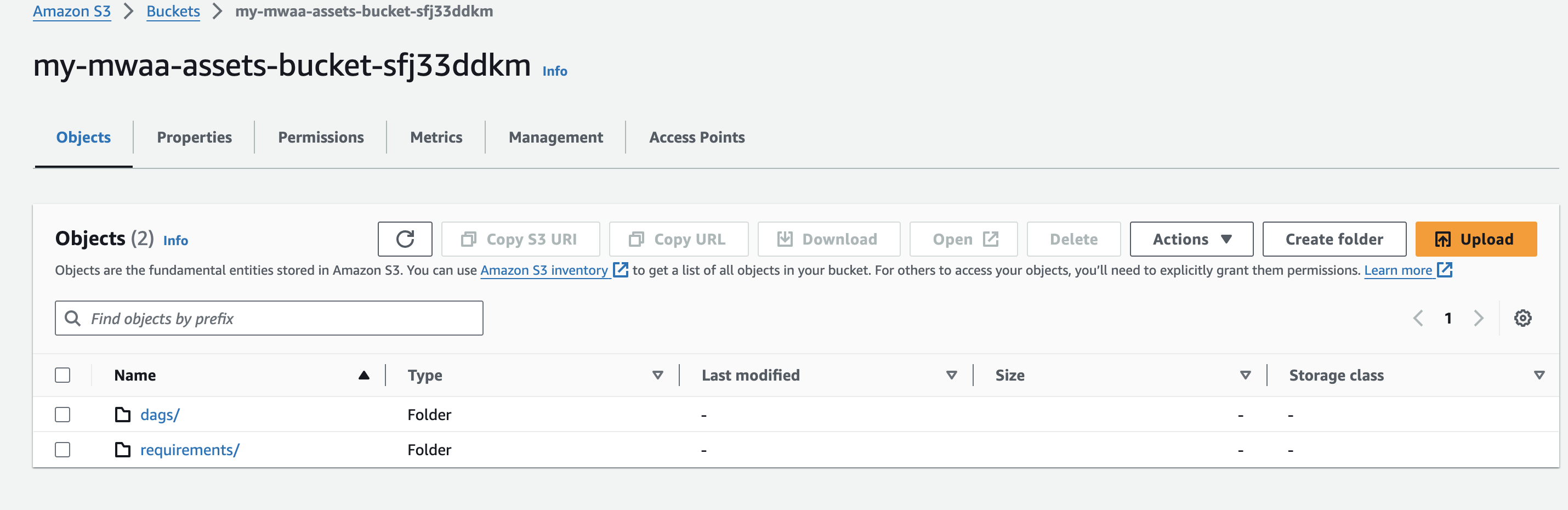
- Créer et télécharger un
requirements.txtfichier avec le contenu suivant dans lerequirementsdossier. Remplacer{environment-version}avec le numéro de version de votre environnement, et{Python-version}avec la version de Python compatible avec votre environnement :
Pandas est nécessaire uniquement pour l'exemple de cas d'utilisation décrit dans cet article, et dag-factory est le seul plug-in requis. Il est recommandé de vérifier la compatibilité de la dernière version de dag-factory avec Amazon MWAA. Le boto ainsi que psycopg2-binary les bibliothèques sont incluses avec l'installation de base d'Apache Airflow v2 et n'ont pas besoin d'être spécifiées dans votre requirements.txt fichier.
- Télécharger Fichier de données mondiales OMS-COVID-19 sur votre ordinateur local et téléchargez-le sous le
dagspréfixe de votre compartiment S3.
Assurez-vous que vous pointez vers la dernière version du compartiment AWS S3 de votre requirements.txt fichier pour que l'installation du package supplémentaire ait lieu. Cela devrait généralement prendre entre 15 et 20 minutes en fonction de la configuration de votre environnement.
Valider les DAG
Lorsque votre environnement Amazon MWAA s'affiche comme Disponible sur la console Amazon MWAA, accédez à l'interface utilisateur Airflow en choisissant Ouvrir l’interface utilisateur d’Airflow à côté de votre environnement.

Vérifiez les DAG existants en accédant à l’onglet DAG.
Configurez vos DAG
Effectuez les étapes suivantes:
- Créez des fichiers vides nommés
dynamic_dags.yml,example_dag_factory.pyainsi queprocess_s3_data.pysur votre machine locale. - Modifiez le
process_s3_data.pyfichier et enregistrez-le avec le contenu du code suivant, puis téléchargez à nouveau le fichier dans le compartiment Amazon S3dagsdossier. Nous effectuons quelques traitements de données de base dans le code :- Lire le fichier à partir d'un emplacement Amazon S3
- Renommez le
Country_codecolonne en fonction du pays. - Filtrer les données par pays donné.
- Écrivez les données finales traitées au format CSV et téléchargez-les vers le préfixe S3.
- Modifiez le
dynamic_dags.ymlet enregistrez-le avec le contenu du code suivant, puis téléchargez à nouveau le fichier sur ledagsdossier. Nous cousons différents DAG en fonction du pays comme suit :- Définissez les arguments par défaut transmis à tous les DAG.
- Créez une définition DAG pour chaque pays en passant
op_args - Cartographier le
process_s3_datafonctionner avecpython_callable_name. - Utilisez Opérateur Python pour traiter les données du fichier CSV stockées dans le compartiment Amazon S3.
- Nous avons mis
schedule_interval10 minutes, mais n'hésitez pas à ajuster cette valeur si nécessaire.
- Modifier le fichier
example_dag_factory.pyet enregistrez-le avec le contenu du code suivant, puis téléchargez à nouveau le fichier surdagsdossier. Le code nettoie les DAG existants et génèreclean_dags()méthode et la création de nouveaux DAG à l'aide de lagenerate_dags()méthode de laDagFactoryexemple.
- Après avoir téléchargé les fichiers, revenez à la console de l'interface utilisateur Airflow et accédez à l'onglet DAG, où vous trouverez de nouveaux DAG.
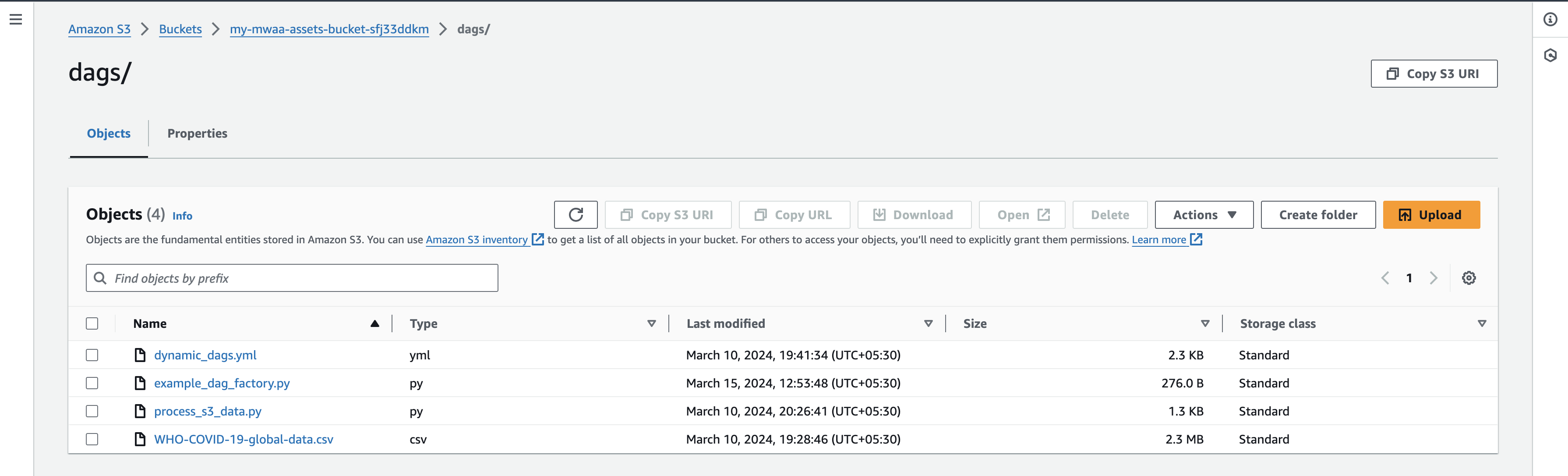
- Une fois que vous avez téléchargé les fichiers, revenez à la console de l'interface utilisateur Airflow et sous l'onglet DAG, vous constaterez que de nouveaux DAG apparaissent comme indiqué ci-dessous :

Vous pouvez activer les DAG en les rendant actifs et en les testant individuellement. Lors de l'activation, un fichier CSV supplémentaire nommé count_death_{COUNTRY_CODE}.csv est généré dans le dossier dags.
Nettoyer
L'utilisation des différents services AWS abordés dans cet article peut entraîner des coûts. Pour éviter d'encourir des frais futurs, supprimez l'environnement Amazon MWAA après avoir terminé les tâches décrites dans cet article, puis videz et supprimez le compartiment S3.
Conclusion
Dans cet article de blog, nous avons montré comment utiliser le usine-jour bibliothèque pour créer des DAG dynamiques. Les DAG dynamiques se caractérisent par leur capacité à générer des résultats à chaque analyse du fichier DAG en fonction des configurations. Envisagez d'utiliser des DAG dynamiques dans les scénarios suivants :
- Automatisation de la migration d'un système existant vers Airflow, où la flexibilité dans la génération de DAG est cruciale
- Situations où seul un paramètre change entre différents DAG, rationalisant ainsi le processus de gestion du flux de travail
- Gestion des DAG qui dépendent de la structure évolutive d'un système source, offrant une adaptabilité aux changements
- Établir des pratiques standardisées pour les DAG au sein de votre équipe ou organisation en créant ces plans, favorisant la cohérence et l'efficacité
- Adopter les déclarations basées sur YAML sur le codage Python complexe, simplifiant ainsi les processus de configuration et de maintenance du DAG
- Créer des flux de travail basés sur les données qui s'adaptent et évoluent en fonction des entrées de données, permettant une automatisation efficace
En incorporant des DAG dynamiques dans votre flux de travail, vous pouvez améliorer l'automatisation, l'adaptabilité et la standardisation, améliorant ainsi l'efficience et l'efficacité de la gestion de votre pipeline de données.
Pour en savoir plus sur Amazon MWAA DAG Factory, visitez Atelier Amazon MWAA pour Analytics : DAG Factory. Pour plus de détails et des exemples de code sur Amazon MWAA, visitez le Guide de l'utilisateur Amazon MWAA et par Exemples Amazon MWAA GitHub dépôt.
À propos des auteurs
 Jayesh Shindé est architecte d'applications principal chez AWS ProServe India. Il se spécialise dans la création de diverses solutions centrées sur le cloud en utilisant des pratiques de développement de logiciels modernes telles que le sans serveur, le DevOps et l'analyse.
Jayesh Shindé est architecte d'applications principal chez AWS ProServe India. Il se spécialise dans la création de diverses solutions centrées sur le cloud en utilisant des pratiques de développement de logiciels modernes telles que le sans serveur, le DevOps et l'analyse.
 Dur Yeola est Sr. Cloud Architect chez AWS ProServe India, aidant les clients à migrer et à moderniser leur infrastructure vers AWS. Il se spécialise dans la création de DevSecOps et d'infrastructures évolutives à l'aide de conteneurs, d'AIOP et d'outils et services de développement AWS.
Dur Yeola est Sr. Cloud Architect chez AWS ProServe India, aidant les clients à migrer et à moderniser leur infrastructure vers AWS. Il se spécialise dans la création de DevSecOps et d'infrastructures évolutives à l'aide de conteneurs, d'AIOP et d'outils et services de développement AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/dynamic-dag-generation-with-yaml-and-dag-factory-in-amazon-mwaa/

