Autre jour, autre algorithme classique : k-les voisins les plus proches. Comme le classificateur naïf de Bayes, c'est une méthode assez simple pour résoudre les problèmes de classification. L'algorithme est intuitif et a un temps de formation imbattable, ce qui en fait un excellent candidat à apprendre lorsque vous démarrez votre carrière en apprentissage automatique. Cela dit, faire des prédictions est extrêmement lent, en particulier pour les grands ensembles de données. Les performances des ensembles de données avec de nombreuses fonctionnalités peuvent également ne pas être écrasantes, en raison de la malédiction de la dimensionnalité.
Dans cet article, vous apprendrez
- comment l' k-le classificateur des voisins les plus proches fonctionne
- pourquoi il a été conçu comme ça
- pourquoi il a ces graves inconvénients et, bien sûr,
- comment l'implémenter en Python en utilisant NumPy.
Comme nous allons implémenter le classificateur d'une manière conforme à scikit learn, il vaut également la peine de consulter mon article Créez votre propre régression scikit-learn personnalisée. Cependant, la surcharge de scikit-learn est assez faible et vous devriez pouvoir suivre de toute façon.
Vous pouvez trouver le code sur mon Github.
L'idée principale de ce classificateur est incroyablement simple. Elle découle directement de la question fondamentale de la classification :
Étant donné un point de données x, quelle est la probabilité que x appartienne à une certaine classe c ?
En langage mathématique, on recherche la probabilité conditionnelle p(c|x). Tandis que le classificateur naïf de Bayes essaie de modéliser cette probabilité directement en utilisant certaines hypothèses, il existe une autre façon intuitive de calculer cette probabilité — la vision fréquentiste de la probabilité.
La vision naïve des probabilités
Ok, mais qu'est-ce que cela signifie maintenant? Considérons l'exemple simple suivant : vous lancez un dé à six faces, éventuellement truqué, et vous voulez calculer la probabilité d'obtenir un six, c'est-à-dire p(rouleau numéro 6). Comment faire cela ? Eh bien, vous lancez le dé n fois et notez combien de fois il a montré un six. Si vous avez vu le numéro six k fois, vous dites que la probabilité de voir un six est autour k/n. Rien de nouveau ou d'extraordinaire ici, n'est-ce pas ?
Maintenant, imaginons que nous voulions calculer une probabilité conditionnelle, par exemple
p(lancez le numéro 6 | lancez un nombre pair)
Vous n'avez pas besoin théorème de Bayes pour résoudre cela. Relancez simplement le dé et ignorez tous les lancers avec un nombre impair. C'est ce que fait le conditionnement : filtrer les résultats. Si vous avez lancé le dé n fois, ont vu m nombres pairs et k d'entre eux étaient un six, la probabilité ci-dessus est autour k/m au lieu de k/n.
Motiver les k-plus proches voisins
Revenons à notre problème. Nous voulons calculer p(c|x) où x est un vecteur contenant les caractéristiques et c est une certaine classe. Comme dans l'exemple du dé, nous
- besoin de beaucoup de points de données,
- filtrez ceux qui ont des fonctionnalités x ainsi que
- vérifier à quelle fréquence ces points de données appartiennent à la classe c.
La fréquence relative est notre supposition pour la probabilité p(c|x).
Voyez-vous le problème ici?
Habituellement, nous n'avons pas beaucoup de points de données avec les mêmes caractéristiques. Souvent un seul, peut-être deux. Par exemple, imaginez un ensemble de données avec deux caractéristiques : la taille (en cm) et le poids (en kg) des personnes. Les étiquettes sont mâle or femelle. Donc, x=(x?, x?) où x? est la hauteur et x? est le poids, et c peut prendre les valeurs masculines et féminines. Regardons quelques données factices :
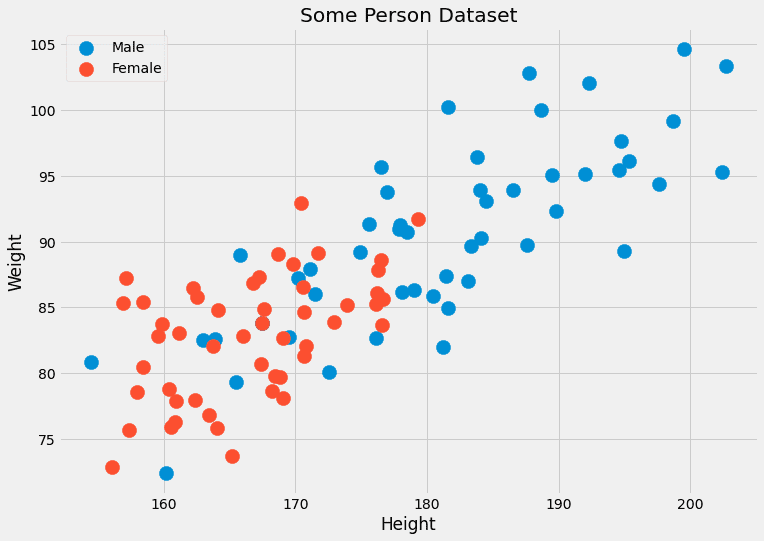
Image de l'auteur.
Étant donné que ces deux caractéristiques sont continues, la probabilité d'avoir deux, et encore moins plusieurs centaines, de points de données est négligeable.
Un autre problème: que se passe-t-il si nous voulons prédire le sexe d'un point de données avec des caractéristiques que nous n'avons jamais vues auparavant, telles que (190.1, 85.2) ? C'est de cela qu'il s'agit en réalité. C'est pourquoi cette approche naïve ne fonctionne pas. Qu'est-ce que le k-l'algorithme du voisin le plus proche fait à la place est le suivant :
Il essaie d'approximer la probabilité p(c|x) pas avec des points de données qui ont exactement les caractéristiques x, mais avec des points de données avec des caractéristiques proches de x.
C'est moins strict, en un sens. Au lieu d'attendre beaucoup de personnes avec une taille = 182.4 et un poids = 92.6, et de vérifier leur sexe, k-les voisins les plus proches permettent de considérer les gens close avoir ces caractéristiques. Le k dans l'algorithme est le nombre de personnes que nous considérons, c'est un hyperparamètre.
Ce sont des paramètres que nous ou un algorithme d'optimisation d'hyperparamètres tels que la recherche de grille devons choisir. Ils ne sont pas directement optimisés par l'algorithme d'apprentissage.
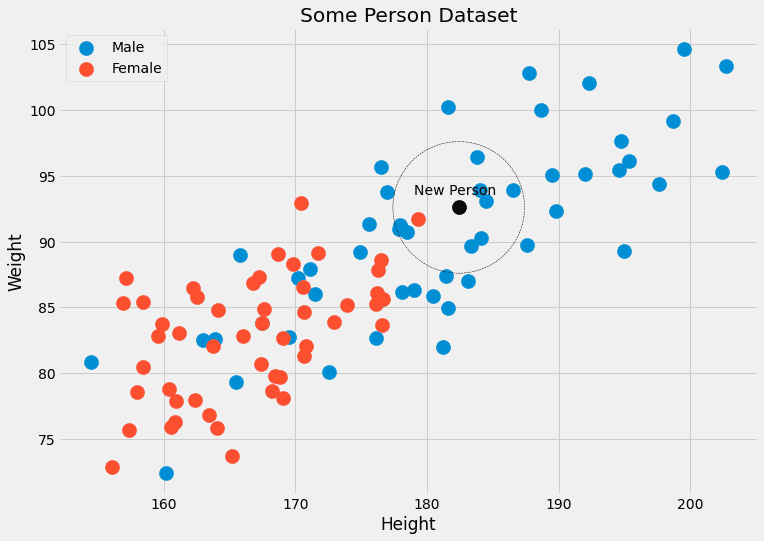
Image de l'auteur.
L'algorithme
Nous avons maintenant tout ce dont nous avons besoin pour décrire l'algorithme.
La formation
- Parce que les données d'entraînement d'une manière ou d'une autre. Pendant le temps de prédiction, cet ordre devrait permettre de nous donner la k points les plus proches pour un point de données donné x.
- C'est déjà ça ! 😉
Prédiction:
- Pour un nouveau point de données x, trouvez le k voisins les plus proches dans les données de formation organisées.
- Total les étiquettes de ces k voisins.
- Sortez l'étiquette/les probabilités.
Nous ne pouvons pas implémenter cela jusqu'à présent, car il y a beaucoup de blancs à remplir.
- Que signifie organiser ?
- Comment mesure-t-on la proximité ?
- Comment agréger ?
Outre la valeur de k, ce sont toutes des choses que nous pouvons choisir, et différentes décisions nous donnent différents algorithmes. Faisons simple et répondons aux questions comme suit :
- Organiser = enregistrez simplement l'ensemble de données d'entraînement tel qu'il est
- Proximité = distance euclidienne
- Agrégation = moyenne
Cela appelle un exemple. Vérifions à nouveau l'image avec les données de la personne.
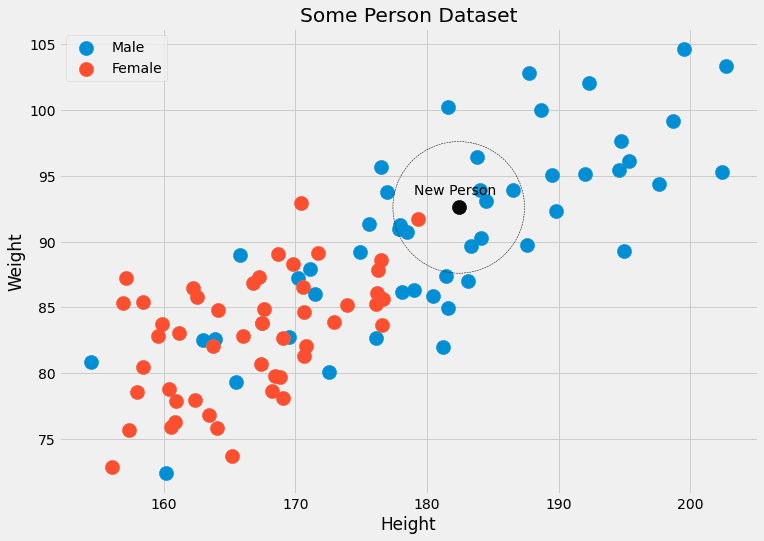
Nous pouvons voir que le k= 5 points de données les plus proches du noir ont 4 étiquettes mâles et une étiquette femelle. Ainsi, nous pourrions affirmer que la personne appartenant au point noir est, en fait, 4/5 = 80 % d'hommes et 1/5 = 20 % de femmes. Si nous préférons une seule classe en sortie, nous renverrons mâle. Aucun problème!
Maintenant, mettons-le en œuvre.
Le plus difficile est de trouver les voisins les plus proches d'un point.
Une introduction rapide
Faisons un petit exemple de la façon dont vous pouvez le faire en Python. On commence par
import numpy as np features = np.array([[1, 2], [3, 4], [1, 3], [0, 2]])
labels = np.array([0, 0, 1, 1]) new_point = np.array([1, 4])
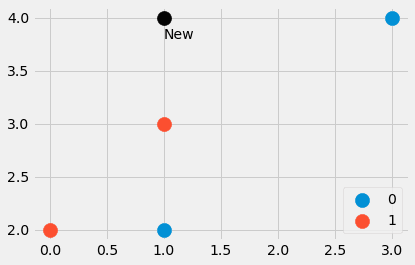
Image de l'auteur.
Nous avons créé un petit ensemble de données composé de quatre points de données, ainsi que d'un autre point. Quels sont les points les plus proches ? Et le nouveau point doit-il avoir l'étiquette 0 ou 1 ? Découvrons-le. Saisie
distances = ((features - new_point)**2).sum(axis=1)nous donne les quatre valeurs distances=[4, 4, 1, 5], qui est la au carré distance euclidienne de new_point à tous les autres points de features . Doux! Nous pouvons voir que le point numéro trois est le plus proche, suivi des points numéro un et deux. Le quatrième point est le plus éloigné.
Comment pouvons-nous extraire maintenant les points les plus proches du tableau [4, 4, 1, 5] ? UN distances.argsort() aide. Le résultat est [2, 0, 1, 3] qui nous indique que le point de données avec l'indice 2 est le plus petit (point numéro trois), puis le point avec l'indice 0, puis avec l'indice 1, et enfin le point avec l'indice 3 est le plus grand.
Notez que argsort mettre les 4 premiers distances avant le deuxième 4. Selon l'algorithme de tri, cela pourrait aussi être l'inverse, mais n'entrons pas dans ces détails pour cet article d'introduction.
Comment si nous voulons les trois voisins les plus proches, par exemple, nous pourrions les obtenir via
distances.argsort()[:3]et les étiquettes correspondent à ces points les plus proches via
labels[distances.argsort()[:3]]Nous obtenons [1, 0, 0], où 1 est l'étiquette du point le plus proche de (1, 4), et les zéros sont les étiquettes appartenant aux deux prochains points les plus proches.
C'est tout ce dont nous avons besoin, passons aux choses sérieuses.
Le dernier code
Vous devriez être assez familier avec le code. La seule nouvelle fonction est np.bincount qui compte les occurrences des étiquettes. Notez que j'ai implémenté un predict_proba première méthode pour calculer les probabilités. La méthode predict appelle simplement cette méthode et renvoie l'indice (= classe) avec la probabilité la plus élevée en utilisant un argmaxfonction. La classe attend les classes de 0 à C-1, où C est le nombre de classes.
Avertissement: Ce code n'est pas optimisé, il n'a qu'un but pédagogique.
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted class KNNClassifier(BaseEstimator, ClassifierMixin): def __init__(self, k=3): self.k = k def fit(self, X, y): X, y = check_X_y(X, y) self.X_ = np.copy(X) self.y_ = np.copy(y) self.n_classes_ = self.y_.max() + 1 return self def predict_proba(self, X): check_is_fitted(self) X = check_array(X) res = [] for x in X: distances = ((self.X_ - x)**2).sum(axis=1) smallest_distances = distances.argsort()[:self.k] closest_labels = self.y_[smallest_distances] count_labels = np.bincount( closest_labels, minlength=self.n_classes_ ) res.append(count_labels / count_labels.sum()) return np.array(res) def predict(self, X): check_is_fitted(self) X = check_array(X) res = self.predict_proba(X) return res.argmax(axis=1)Et c'est tout! On peut faire un petit test et voir s'il est d'accord avec le scikit-learn k-classificateur voisin le plus proche.
Tester le code
Créons un autre petit ensemble de données pour les tests.
from sklearn.datasets import make_blobs
import numpy as np X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)
X = np.vstack([X, np.array([[2, 4], [-1, 4], [1, 6]])])
y = np.append(y, [2, 1, 0])Il ressemble à ceci:
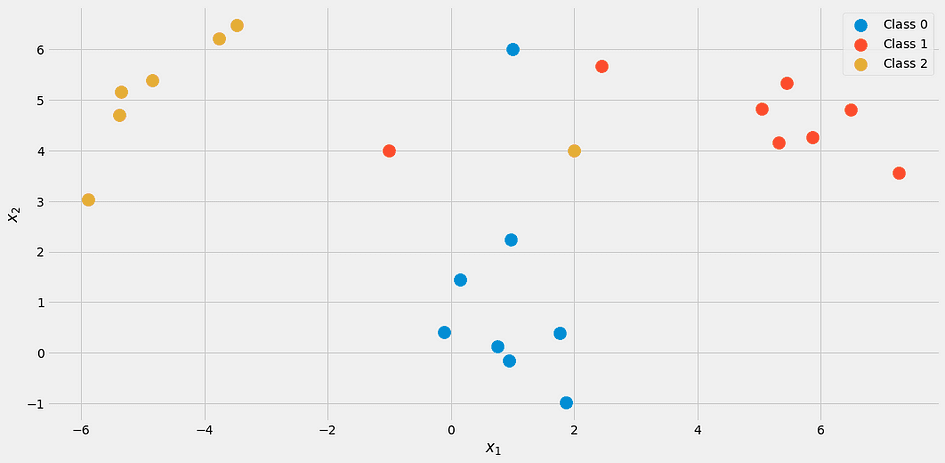
Image de l'auteur.
Utilisation de notre classifieur avec k = 3
my_knn = KNNClassifier(k=3)
my_knn.fit(X, y) my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])nous obtenons
array([[1. , 0. , 0. ], [0.33333333, 0.33333333, 0.33333333], [0. , 0.66666667, 0.33333333]])Lisez la sortie comme suit : Le premier point est de 100% appartenant à la classe 1, le deuxième point se situe dans chaque classe à parts égales avec 33%, et le troisième point est d'environ 67% de classe 2 et 33% de classe 3.
Si vous voulez des étiquettes concrètes, essayez
my_knn.predict([[0, 1], [0, 5], [3, 4]])qui sort [0, 0, 1]. Notez qu'en cas d'égalité, le modèle tel que nous l'avons implémenté produit la classe inférieure, c'est pourquoi le point (0, 5) est classé comme appartenant à la classe 0.
Si vous vérifiez l'image, cela a du sens. Mais rassurons-nous avec l'aide de scikit-learn.
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y) my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])Le résultat:
array([[1. , 0. , 0. ], [0.33333333, 0.33333333, 0.33333333], [0. , 0.66666667, 0.33333333]])Phew! Tout semble bon. Vérifions les limites de décision de l'algorithme, juste parce que c'est joli.
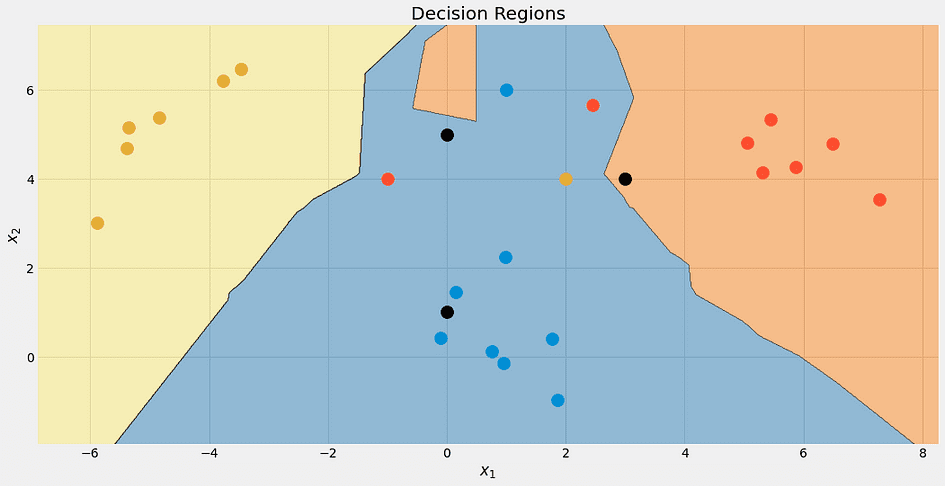
Image de l'auteur.
Encore une fois, le point noir supérieur n'est pas bleu à 100 %. C'est 33% bleu, rouge et jaune, mais l'algorithme décide de manière déterministe pour la classe la plus basse, qui est bleue.
Nous pouvons également vérifier les limites de décision pour différentes valeurs de k.
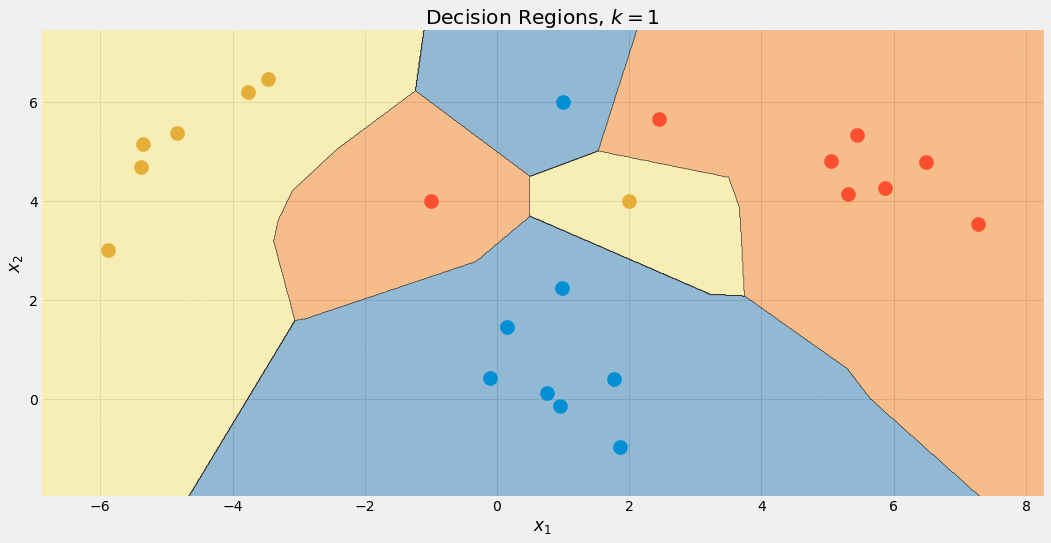
Image de l'auteur.
Notez que la région bleue s'agrandit à la fin, à cause de ce traitement préférentiel de cette classe. On peut aussi voir que pour k=1 les frontières sont un gâchis : le modèle est surajustement. De l'autre côté de l'extrême, k est aussi grande que la taille de l'ensemble de données, et tous les points sont utilisés pour l'étape d'agrégation. Ainsi, chaque point de données obtient la même prédiction : la classe majoritaire. Le modèle est sous-ajustement dans ce cas. Le sweet spot se situe quelque part entre les deux et peut être trouvé à l'aide de techniques d'optimisation d'hyperparamètres.
Avant d'arriver à la fin, voyons quels problèmes cet algorithme a.
Les problèmes sont les suivants :
- Trouver les voisins les plus proches prend beaucoup de temps, surtout avec notre implémentation naïve. Si nous voulons prédire la classe d'un nouveau point de données, nous devons le vérifier par rapport à tous les autres points de notre ensemble de données, ce qui est lent. Il existe de meilleures façons d'organiser les données à l'aide de structures de données avancées, mais le problème persiste.
- Suite au problème numéro 1 : Habituellement, vous formez des modèles sur des ordinateurs plus rapides et plus puissants et pouvez ensuite déployer le modèle sur des machines plus faibles. Pensez à l'apprentissage en profondeur, par exemple. Mais pour k-les plus proches voisins, le temps d'entraînement est facile et le gros du travail se fait pendant le temps de prédiction, ce qui n'est pas ce que nous souhaitons.
- Que se passe-t-il si les voisins les plus proches ne sont pas proches du tout ? Alors ils ne veulent rien dire. Cela peut déjà se produire dans des ensembles de données avec un petit nombre de fonctionnalités, mais avec encore plus de fonctionnalités, le risque de rencontrer ce problème augmente considérablement. C'est aussi ce que les gens appellent la malédiction de la dimensionnalité. Une belle visualisation peut être trouvée dans ce poste de Cassie Kozyrkov.
Surtout à cause du problème 2, vous ne voyez pas le k-classificateur voisin le plus proche dans la nature trop souvent. C'est toujours un bon algorithme que vous devriez connaître, et vous pouvez également l'utiliser pour de petits ensembles de données, rien de mal à cela. Mais si vous avez des millions de points de données avec des milliers de fonctionnalités, les choses deviennent difficiles.
Dans cet article, nous avons expliqué comment le k-le classificateur de voisin le plus proche fonctionne et pourquoi sa conception a du sens. Il essaie d'estimer la probabilité d'un point de données x appartenant à une classe c aussi bien que possible en utilisant les points de données les plus proches de x. C'est une approche très naturelle, et donc cet algorithme est généralement enseigné au début des cours d'apprentissage automatique.
Notez qu'il est très simple de construire un k-voisin le plus proche régresseur, aussi. Au lieu de compter les occurrences de classes, faites simplement la moyenne des étiquettes des voisins les plus proches pour obtenir une prédiction. Vous pouvez l'implémenter vous-même, ce n'est qu'un petit changement !
Nous l'avons ensuite implémenté de manière simple, en imitant l'API scikit-learn. Cela signifie que vous pouvez également utiliser cet estimateur dans les pipelines et les recherches de grille de scikit-learn. C'est un grand avantage puisque nous avons même l'hyperparamètre k que vous pouvez optimiser à l'aide de la recherche par grille, de la recherche aléatoire ou de l'optimisation bayésienne.
Cependant, cet algorithme présente de sérieux problèmes. Il ne convient pas aux grands ensembles de données et ne peut pas être déployé sur des machines plus faibles pour faire des prédictions. Avec la susceptibilité à la malédiction de la dimensionnalité, c'est un algorithme qui est théoriquement agréable mais qui ne peut être utilisé que pour des ensembles de données plus petits.
Dr Robert Kübler est Data Scientist chez METRO.digital et auteur chez Towards Data Science.
ORIGINALE. Republié avec permission.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://www.kdnuggets.com/2023/06/theory-practice-building-knearest-neighbors-classifier.html?utm_source=rss&utm_medium=rss&utm_campaign=from-theory-to-practice-building-a-k-nearest-neighbors-classifier

