Introduction
En vision par ordinateur, différentes techniques de détection d'objets vivants existent, notamment Faster R-CNN, SSDet YOLO. Chaque technique a ses limites et ses avantages. Bien que Faster R-CNN puisse exceller en termes de précision, il peut ne pas fonctionner aussi bien dans des scénarios en temps réel, ce qui entraîne une évolution vers le Algorithme YOLO.
La détection d'objets est fondamentale en vision par ordinateur, permettant aux machines d'identifier et de localiser des objets dans un cadre ou un écran. Au fil des années, divers algorithmes de détection d’objets ont été développés, YOLO étant devenu l’un des plus performants. Récemment, YOLOv8 a été introduit, améliorant encore les capacités de l'algorithme.
Dans ce guide complet, nous explorons trois algorithmes de détection d'objets importants : Faster R-CNN, SSD (Single Shot MultiBox Detector) et YOLOv8. Nous discutons des aspects pratiques de la mise en œuvre de ces algorithmes, notamment la mise en place d'un environnement virtuel et le développement d'une application Streamlit.
Objectif d'apprentissage
- Comprenez Faster R-CNN, SSD et YOLO et analysez les différences entre eux.
- Acquérez une expérience pratique dans la mise en œuvre de systèmes de détection d'objets vivants à l'aide d'OpenCV, de Supervision et de YOLOv8.
- Comprendre le modèle de segmentation d'image à l'aide de l'annotation Roboflow.
- Créez une application Streamlit pour une interface utilisateur simple.
Explorons comment effectuer une segmentation d'images avec YOLOv8 !
Table des matières
Cet article a été publié dans le cadre du Blogathon sur la science des données.
R-CNN plus rapide
Faster R-CNN (Faster Region-based Convolutional Neural Network) est un algorithme de détection d'objets basé sur l'apprentissage en profondeur. Il est évalué à l'aide des frameworks R-CNN et Fast R-CNN et peut être considéré comme une extension de Fast R-CNN.
Cet algorithme introduit le Region Proposal Network (RPN) pour générer des propositions de région, remplaçant la recherche sélective utilisée dans R-CNN. Le RPN partage des couches convolutives avec le réseau de détection, permettant une formation efficace de bout en bout.
Les propositions de régions générées sont ensuite introduites dans un réseau Fast R-CNN pour le raffinement du cadre de délimitation et la classification des objets.
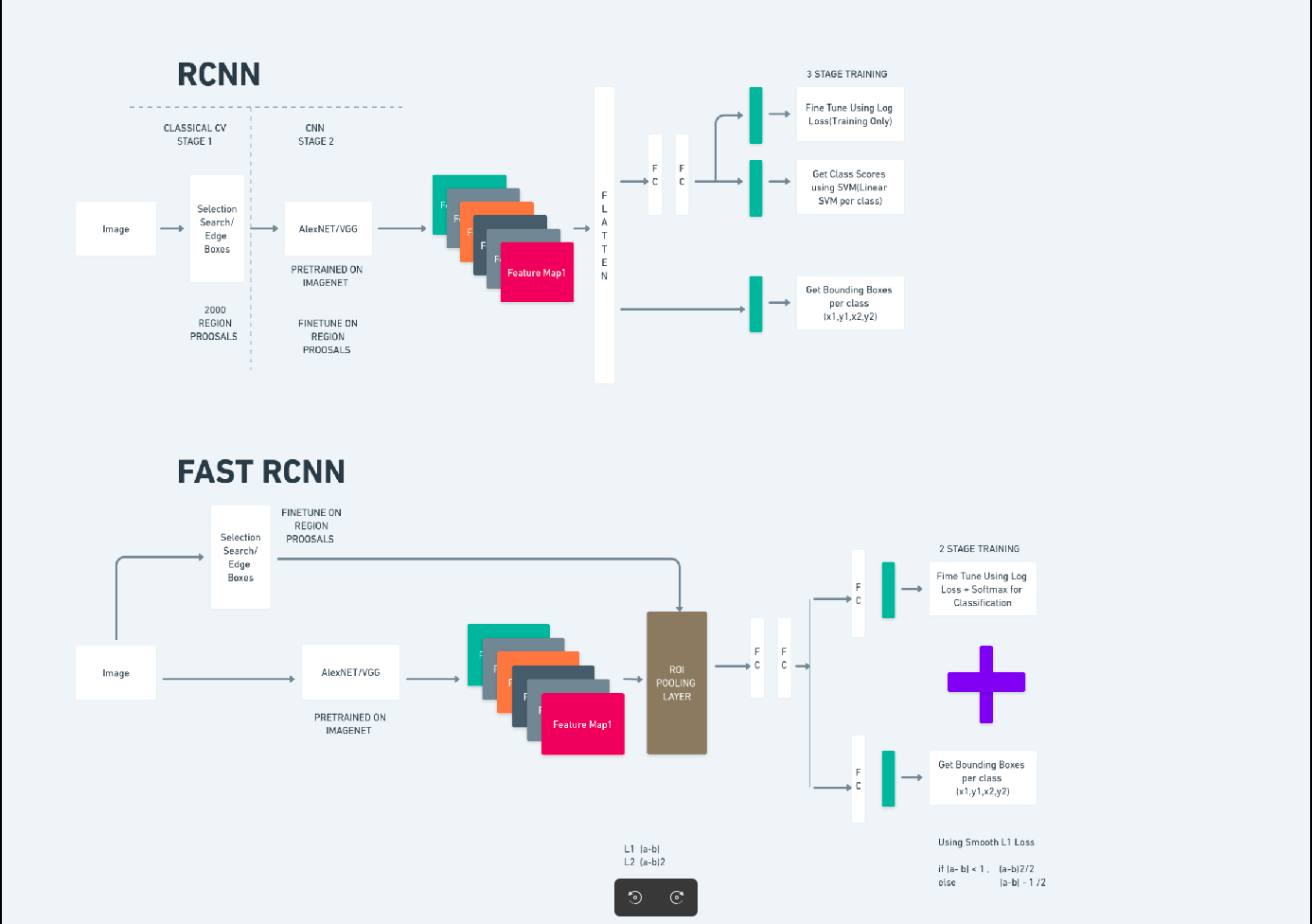
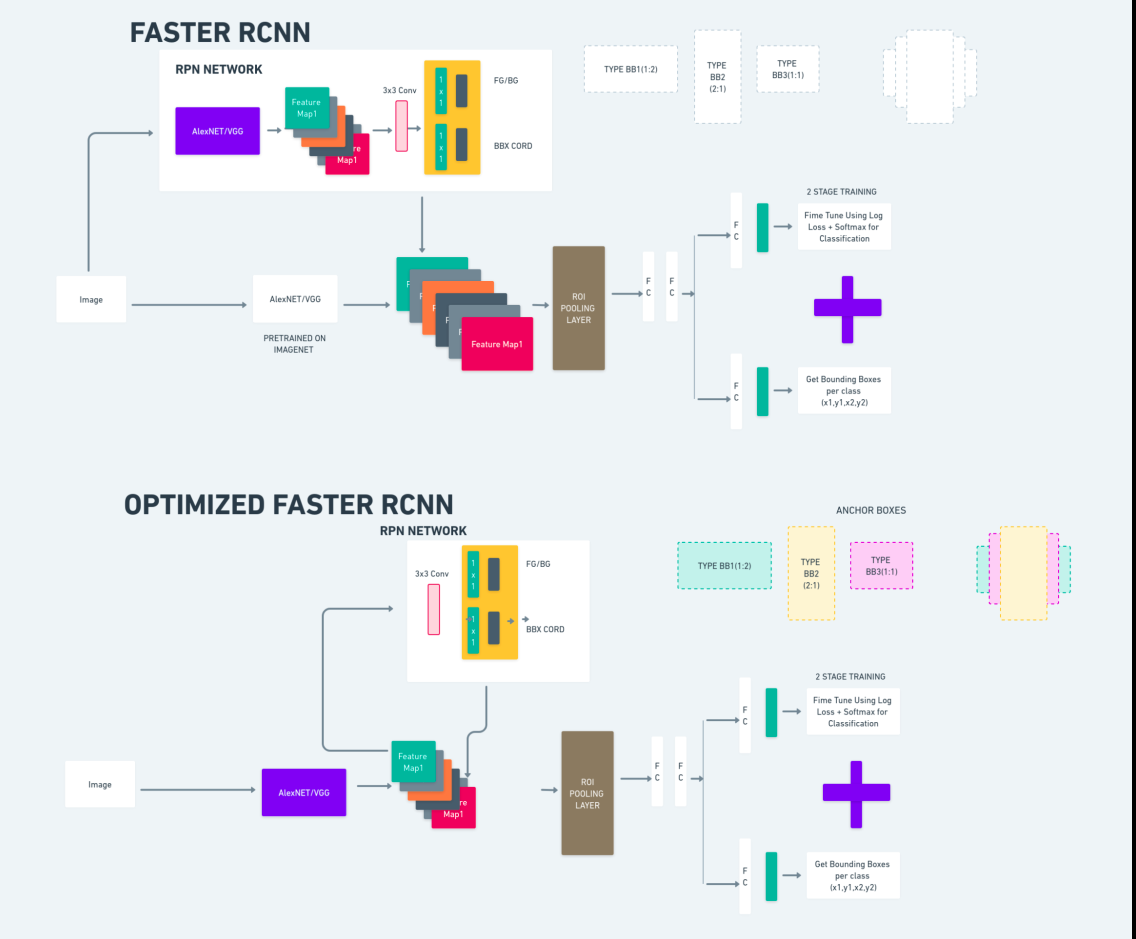
Le diagramme ci-dessus illustre de manière exhaustive la famille Faster R-CNN et est facile à comprendre pour évaluer chaque algorithme.
Détecteur MultiBox à prise unique (SSD)
La Détecteur MultiBox à prise unique (SSD) est populaire dans la détection d'objets et principalement utilisé dans les tâches de vision par ordinateur. Dans la méthode précédente, Faster R-CNN, nous avons suivi deux étapes : la première étape impliquait la partie détection et la seconde impliquait la régression. Cependant, avec le SSD, nous n’effectuons qu’une seule étape de détection. Le SSD a été introduit en 2016 pour répondre au besoin d'un modèle de détection d'objets rapide et précis.

Le SSD présente plusieurs avantages par rapport aux méthodes de détection d'objets antérieures telles que Faster R-CNN :
- Efficacité : SSD est un détecteur à un seul étage, ce qui signifie qu'il prédit directement les cadres de délimitation et les scores des classes sans nécessiter une étape distincte de génération de propositions. Cela le rend plus rapide par rapport aux détecteurs à deux étages comme Faster R-CNN.
- Formation de bout en bout : le SSD peut être formé de bout en bout, optimisant ainsi à la fois le réseau de base et la tête de détection, ce qui simplifie le processus de formation.
- Fusion de fonctionnalités à plusieurs échelles : SSD fonctionne sur des cartes de fonctionnalités à plusieurs échelles, ce qui lui permet de détecter plus efficacement des objets de différentes tailles.
Le SSD offre un bon équilibre entre vitesse et précision, ce qui le rend adapté aux applications en temps réel où les performances et l'efficacité sont essentielles.
On ne regarde qu'une fois (YOLOv8)
En 2015, You Only Look Once (YOLO) a été présenté comme algorithme de détection d'objets dans un article de recherche de Joseph Redmon, Santosh Divvala, Ross Girshick et Ali Farhadi. YOLO est un algorithme à un seul coup qui classe directement un objet en un seul passage en ayant un seul réseau neuronal prédisant les cadres de délimitation et les probabilités de classe en utilisant une image complète comme entrée.
Comprenons maintenant YOLOv8 comme des avancées de pointe en matière de détection d'objets en temps réel avec une précision et une vitesse améliorées. YOLOv8 vous permet d'exploiter des modèles pré-entraînés, qui sont déjà formés sur un vaste ensemble de données tel que COCO (Common Objects in Context). La segmentation d'image fournit des informations au niveau des pixels sur chaque objet, permettant une analyse et une compréhension plus détaillées du contenu de l'image.
Bien que la segmentation d'images puisse être coûteuse en termes de calcul, YOLOv8 intègre cette méthode dans son architecture de réseau neuronal, permettant une segmentation d'objets efficace et précise.
Principe de fonctionnement de YOLOv8
YOLOv8 fonctionne en divisant d’abord l’image d’entrée en cellules de grille. En utilisant ces cellules de grille, YOLOv8 prédit les boîtes englobantes (bbox) avec des probabilités de classe.
Ensuite, YOLOv8 utilise l'algorithme NMS pour réduire le chevauchement. Par exemple, si plusieurs voitures sont présentes dans l'image, ce qui entraîne un chevauchement des cadres de délimitation, l'algorithme NMS aide à réduire ce chevauchement.
Différence entre les variantes de Yolo V8 : YOLOv8 est disponible en trois variantes : YOLOv8, YOLOv8-L et YOLOv8-X. La principale différence entre les variantes réside dans la taille du réseau fédérateur. YOLOv8 possède le plus petit réseau fédérateur, tandis que YOLOv8-X possède le plus grand réseau fédérateur.
La différence entre R-CNN, SSD et YOLO plus rapides
| Aspect | R-CNN plus rapide | SSD | YOLO |
|---|---|---|---|
| Architecture | Détecteur à deux étages avec RPN et Fast R-CNN | Détecteur à un étage | Détecteur à un étage |
| Propositions régionales | Oui | Non | Non |
| Vitesse de détection | Plus lent que SSD et YOLO | Plus rapide que Faster R-CNN, plus lent que YOLO | Très rapide |
| Précision | Précision généralement plus élevée | Précision et vitesse équilibrées | Précision décente, en particulier pour les applications en temps réel |
| Flexibilité | Flexible, peut gérer différentes tailles d'objets et formats d'image | Peut gérer plusieurs échelles d’objets | Peut avoir du mal à localiser avec précision de petits objets |
| Détection unifiée | Non | Non | Oui |
| Compromis entre vitesse et précision | Sacrifie généralement la vitesse pour la précision | Équilibre vitesse et précision | Donne la priorité à la vitesse tout en conservant une précision décente |
Qu'est-ce que la segmentation ?
Comme nous le savons, la segmentation signifie que nous divisons la grande image en groupes plus petits en fonction de certaines caractéristiques. Comprenons la segmentation d'image qui est la technique de vision par ordinateur utilisée pour partitionner une image en différents segments ou régions multiples. Comme les images sont constituées de pixels et dans la segmentation d'image, les pixels sont regroupés en fonction de la similitude de couleur, d'intensité, de texture ou d'autres propriétés visuelles.
Par exemple, si une image contient des arbres, des voitures ou des personnes, la segmentation de l'image va diviser l'image en différentes classes qui représentent des objets ou des parties significatives de l'image. La segmentation d'images est largement utilisée dans différents domaines comme l'imagerie médicale, l'analyse d'images satellite, la reconnaissance d'objets en vision par ordinateur, etc.

Dans la partie segmentation, nous créons initialement le premier modèle de segmentation YOLOv8 à l'aide de Robflow. Ensuite, nous importons le modèle de segmentation pour effectuer la tâche de segmentation. La question se pose : pourquoi crée-t-on le modèle de segmentation alors que la tâche pourrait être accomplie avec un seul algorithme de détection ?
La segmentation nous permet d'obtenir l'image corporelle complète d'une classe. Alors que les algorithmes de détection se concentrent sur la détection de la présence d’objets, la segmentation permet une compréhension plus précise en délimitant les limites exactes des objets. Cela conduit à une localisation et une compréhension plus précises des objets présents dans l’image.
Cependant, la segmentation implique généralement une complexité temporelle plus élevée que les algorithmes de détection, car elle nécessite des étapes supplémentaires telles que la séparation des annotations et la création du modèle. Malgré cet inconvénient, la précision accrue offerte par la segmentation peut compenser le coût de calcul dans les tâches où une délimitation précise des objets est cruciale.
Détection en direct étape par étape et segmentation d'image avec YOLOv8
Dans ce concept, nous explorons les étapes de création d'un environnement virtuel à l'aide de conda, d'activation de venv et d'installation des packages d'exigences à l'aide de pip. nous créons d’abord le script python normal, puis nous créons l’application rationalisée.
Étape 1 : Créer un environnement virtuel à l'aide de Conda
conda create -p ./venv python=3.8 -yÉtape 2 : activer l'environnement virtuel
conda activate ./venv
Étape 3 : Créer des exigences.txt
Ouvrez le terminal et collez le script ci-dessous :
touch requirements.txtÉtape 4 : utilisez la commande Nano et modifiez le fichier conditions.txt
Après avoir créé le fichier Requirements.txt, écrivez la commande suivante pour modifier le fichier Requirements.txt
nano requirements.txtAprès avoir exécuté le script ci-dessus, vous pouvez voir cette interface utilisateur.
Écrivez-lui les packages requis.
ultralytics==8.0.32
supervision==0.2.1
streamlitPuis appuyez sur "ctrl+o"(cette commande sauvegardant la partie d'édition) puis appuyez sur la touche "Entrer"
Après avoir appuyé sur "Ctrl+x”. vous pouvez quitter le fichier. et aller vers le chemin principal.
Étape 5 : Installation du fichierRequirements.txt
pip install -r requirements.txtÉtape 6 : Créer le script Python
Dans le terminal, écrivez le script suivant ou nous pouvons dire commande.
touch main.pyAprès avoir créé main.py, ouvrez le code vs que vous utilisez la commande write in terminal,
code Étape 7 : écriture du script Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Après avoir exécuté cette commande, vous pouvez voir que votre caméra est ouverte et détecte une partie de vous. comme les parties de genre et d’arrière-plan.
Étape 7 : Créer une application simplifiée
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
Dans ce script, nous créons l'application simplifiée et créons le bouton de sorte qu'après avoir appuyé sur le bouton, la caméra de votre appareil soit ouverte et détecte la partie dans le cadre.
Exécutez ce script à l'aide de cette commande.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Après avoir exécuté la commande ci-dessus, supposons que vous ayez une erreur de contact telle que :
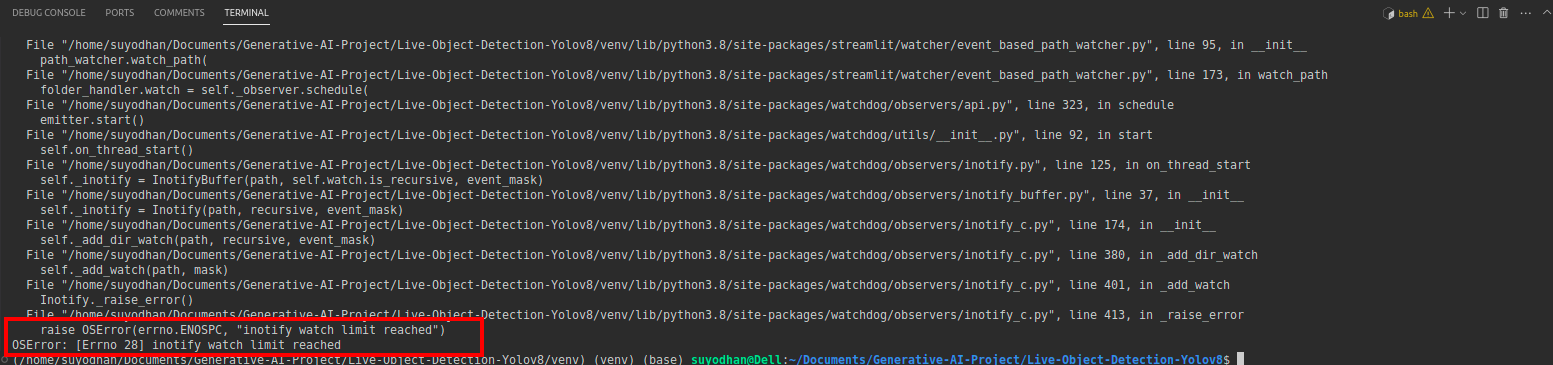
puis appuyez sur cette commande,
sudo sysctl fs.inotify.max_user_watches=524288Après avoir appuyé sur la commande avec laquelle vous souhaitez écrire votre mot de passe car nous utilisons la commande sudo sudo is god :)
Exécutez à nouveau le script. et vous pouvez voir l'application simplifiée.
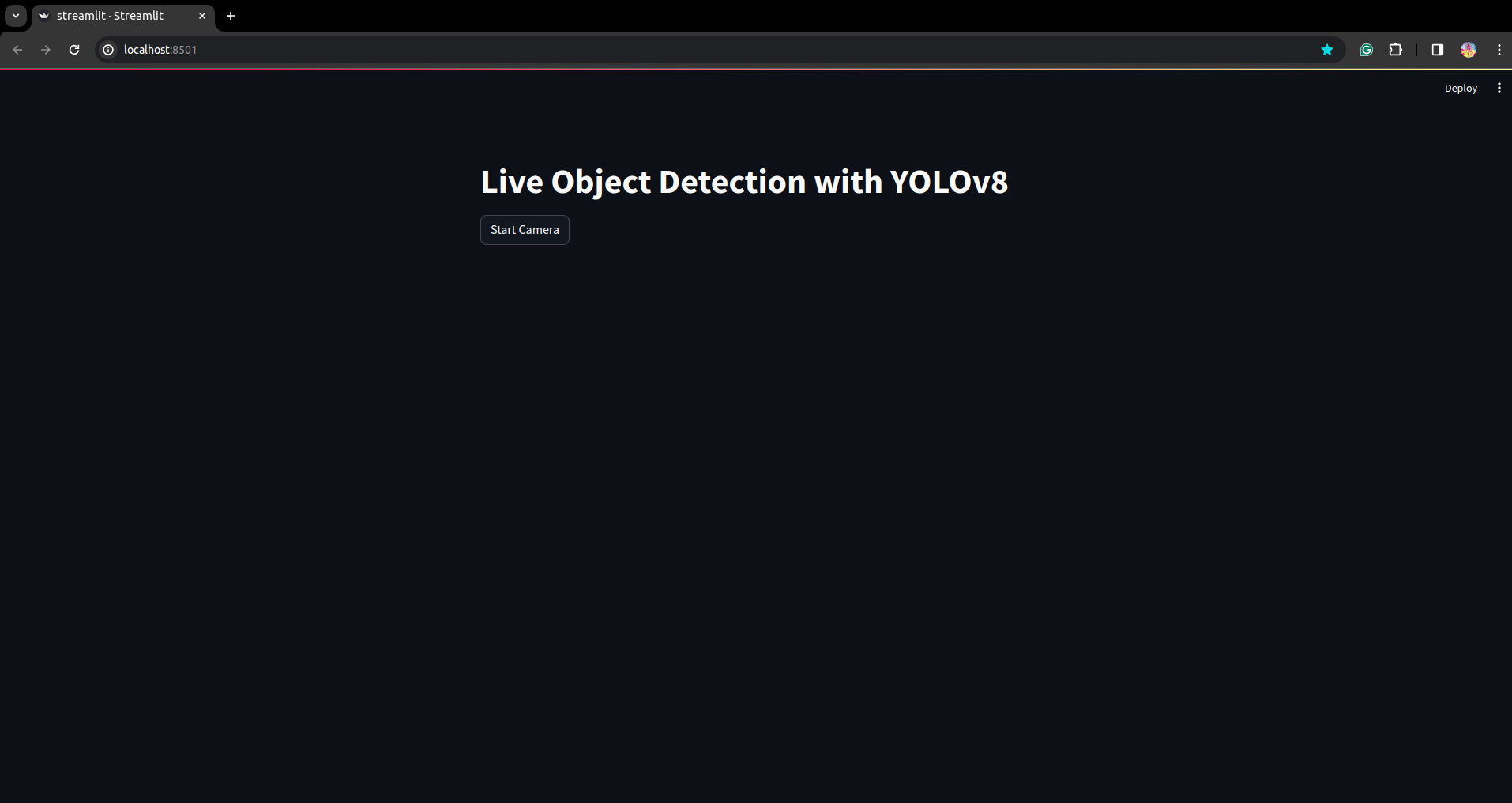
Ici, nous pouvons créer une application de détection en direct réussie. Dans la partie suivante, nous verrons la partie segmentation.
Étapes pour l'annotation
Étape 1 : Configuration de Roboflow
Après avoir signé le «Créer un projet ». ici, vous pouvez créer le projet et le groupe d'annotations.

Étape 2 : Téléchargement de l'ensemble de données
Ici, nous considérons l'exemple simple, mais vous souhaitez l'utiliser dans votre énoncé de problème, j'utilise donc ici l'ensemble de données de canard.
Allez-y lien et téléchargez l'ensemble de données sur les canards.

Extrayez le dossier là-bas, vous pouvez voir les trois dossiers : former, tester et val.
Étape 3 : Téléchargement de l'ensemble de données sur roboflow
Après avoir créé le projet dans Roboflow, vous pouvez voir cette interface utilisateur ici, vous pouvez télécharger votre ensemble de données, donc téléchargez uniquement les images des pièces de train, sélectionnez le "sélectionner le dossier" option.
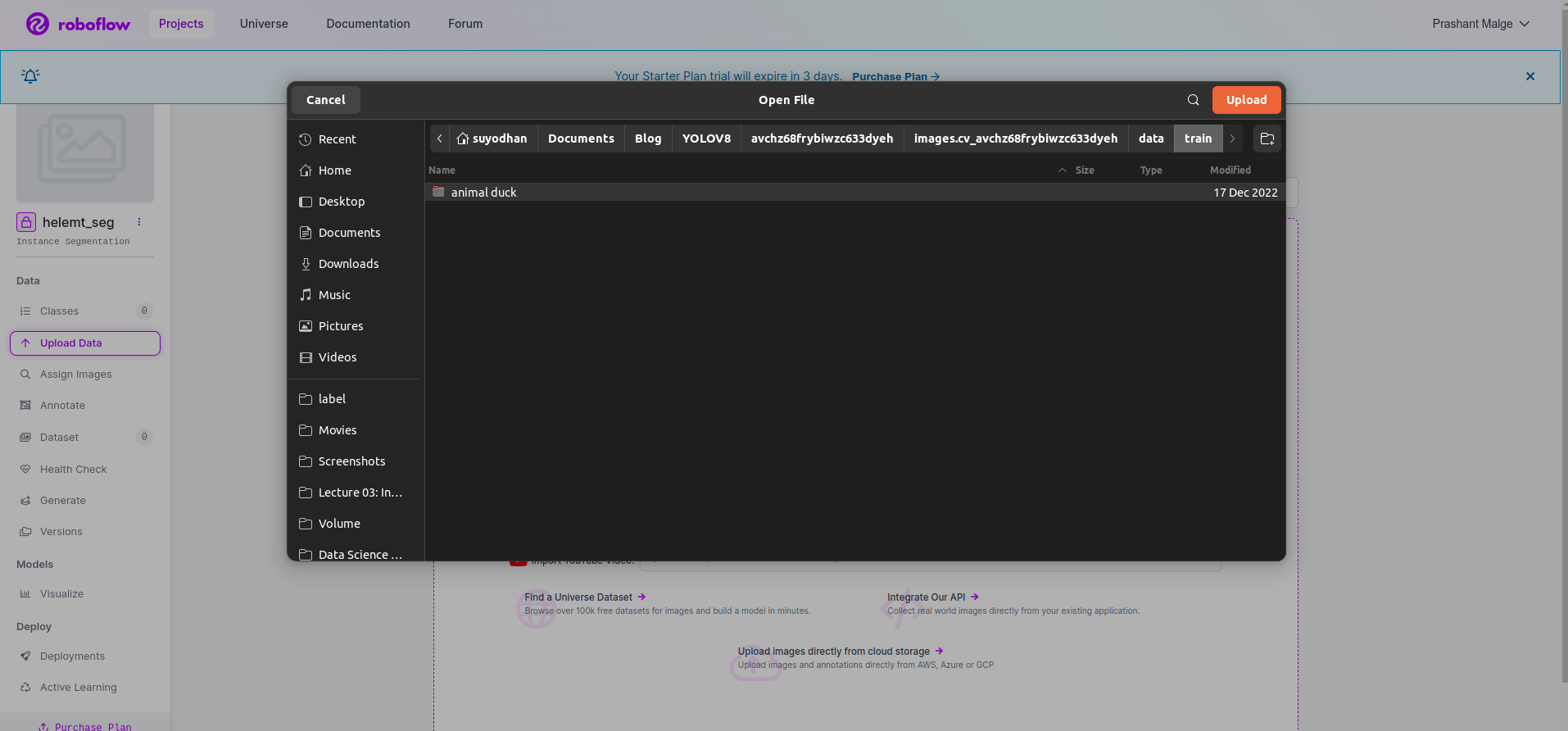
Cliquez ensuite sur "Sauvegarder et continuer" option comme je le marque dans une case rectangulaire rouge
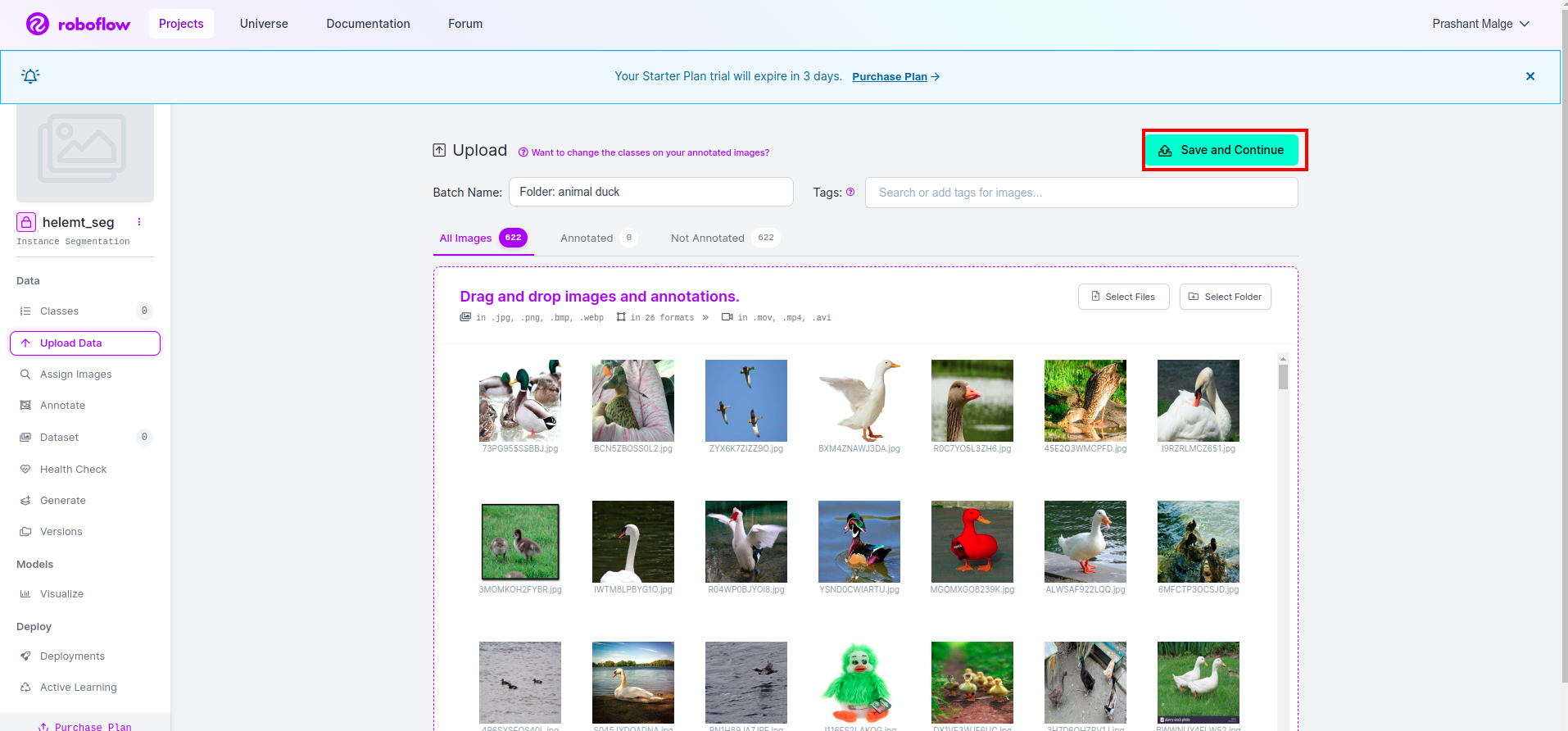
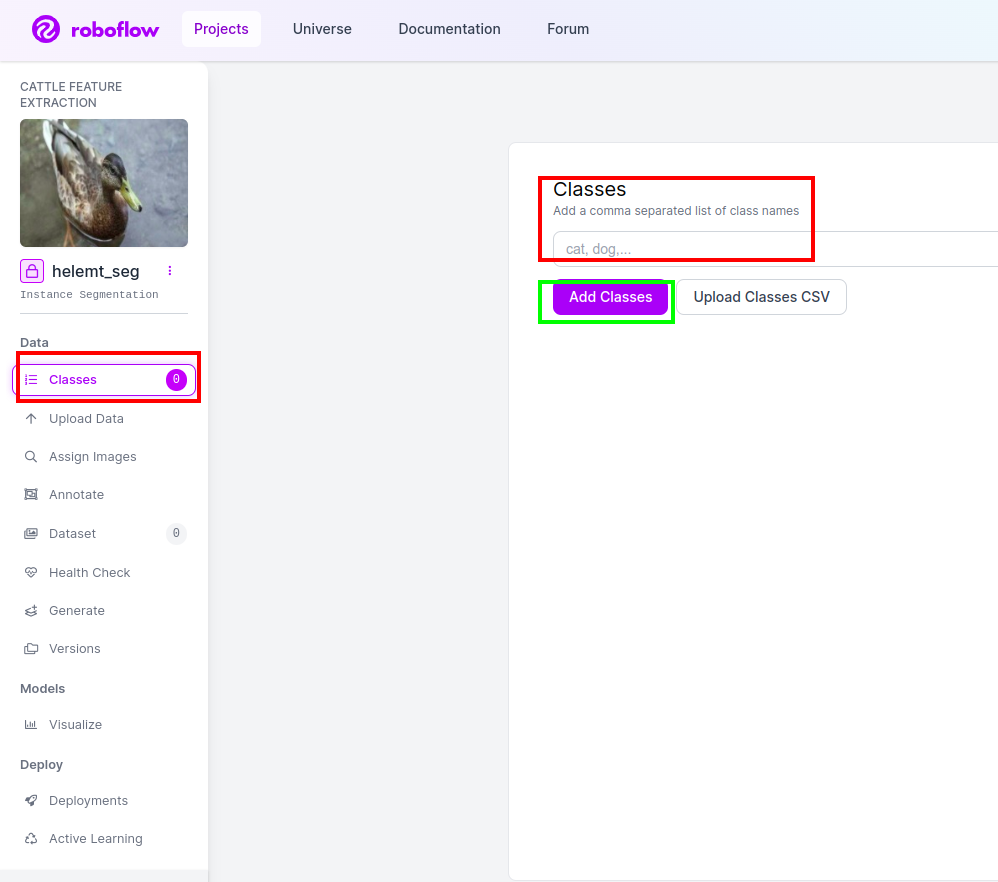
Étape 4 : ajoutez le nom de la classe
Ensuite, allez à la partie de classe sur le côté gauche de cochez la case rouge. et écrivez le nom de la classe comme canard, après avoir cliqué sur la case verte.
Maintenant, notre configuration est terminée et la partie suivante, comme la partie annotation, est également simple.
Étape 5 : Démarrez le partie d'annotation
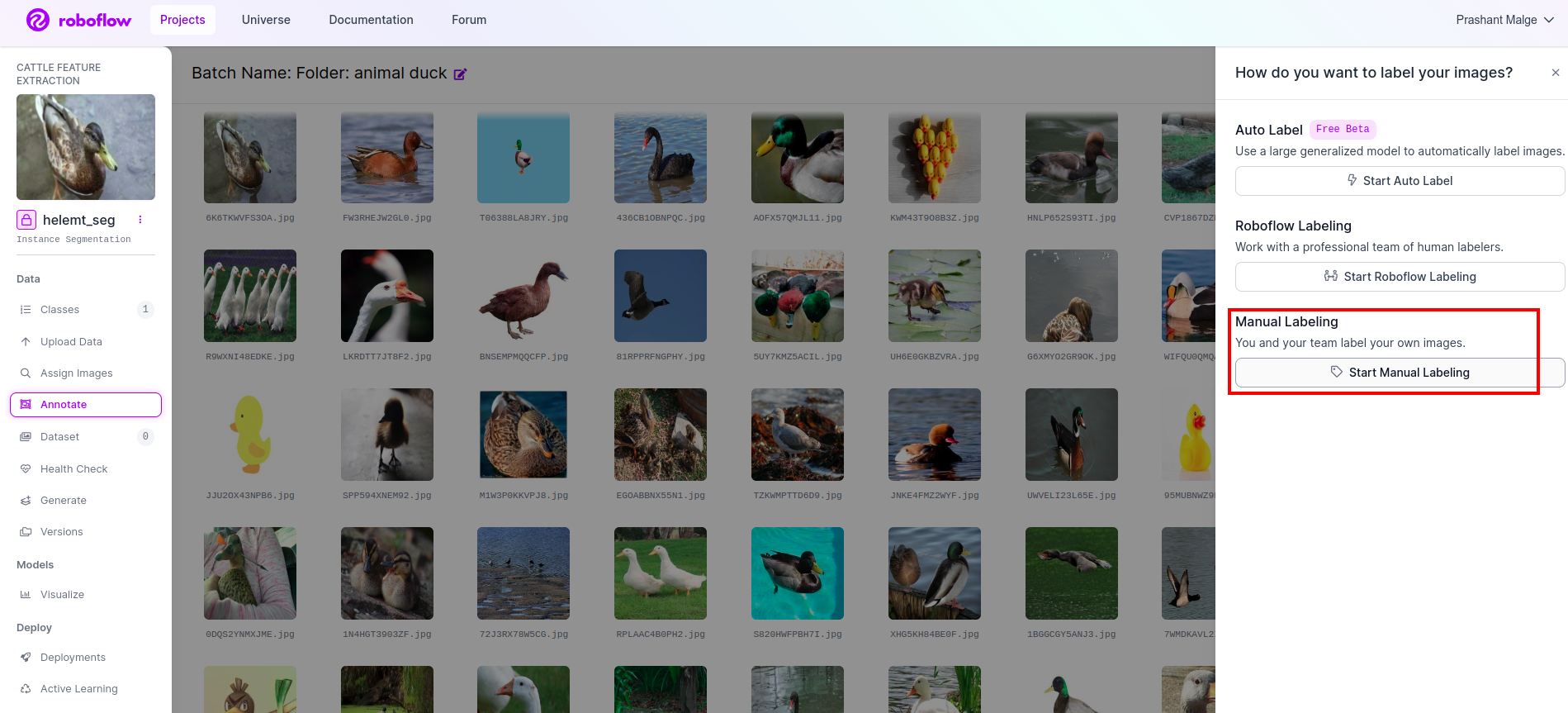
Allez à option d'annotation J'ai marqué dans la case rouge, puis j'ai cliqué sur démarrer la partie annotation comme j'ai marqué dans la case verte.
Cliquez sur la première image pour voir cette interface utilisateur. Après avoir vu cela, cliquez sur l'option d'annotation manuelle.
Ajoutez ensuite votre identifiant de messagerie ou le nom de votre coéquipier afin de pouvoir attribuer la tâche.
Cliquez sur la première image pour voir cette interface utilisateur. cliquez ici sur la case rouge pour pouvoir sélectionner le modèle multi-polynomial.
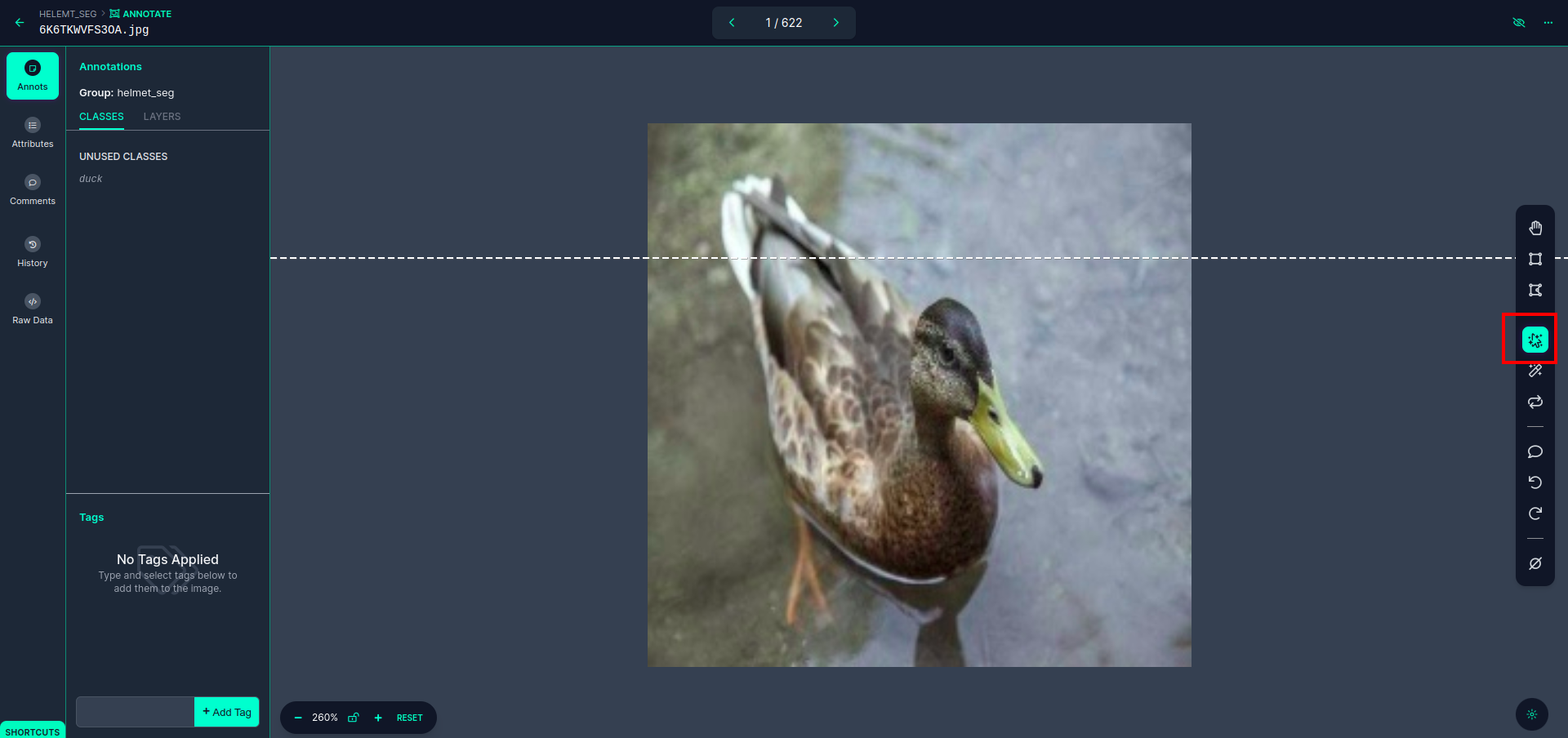
Après avoir cliqué sur la case rouge, sélectionnez le modèle par défaut et cliquez sur l'objet canard. Cela segmentera automatiquement l'image. Ensuite, cliquez sur la partie suivante et enregistrez-la. Vous verrez alors le côté gauche marqué dans une case rouge, où vous pourrez voir le nom de la classe.
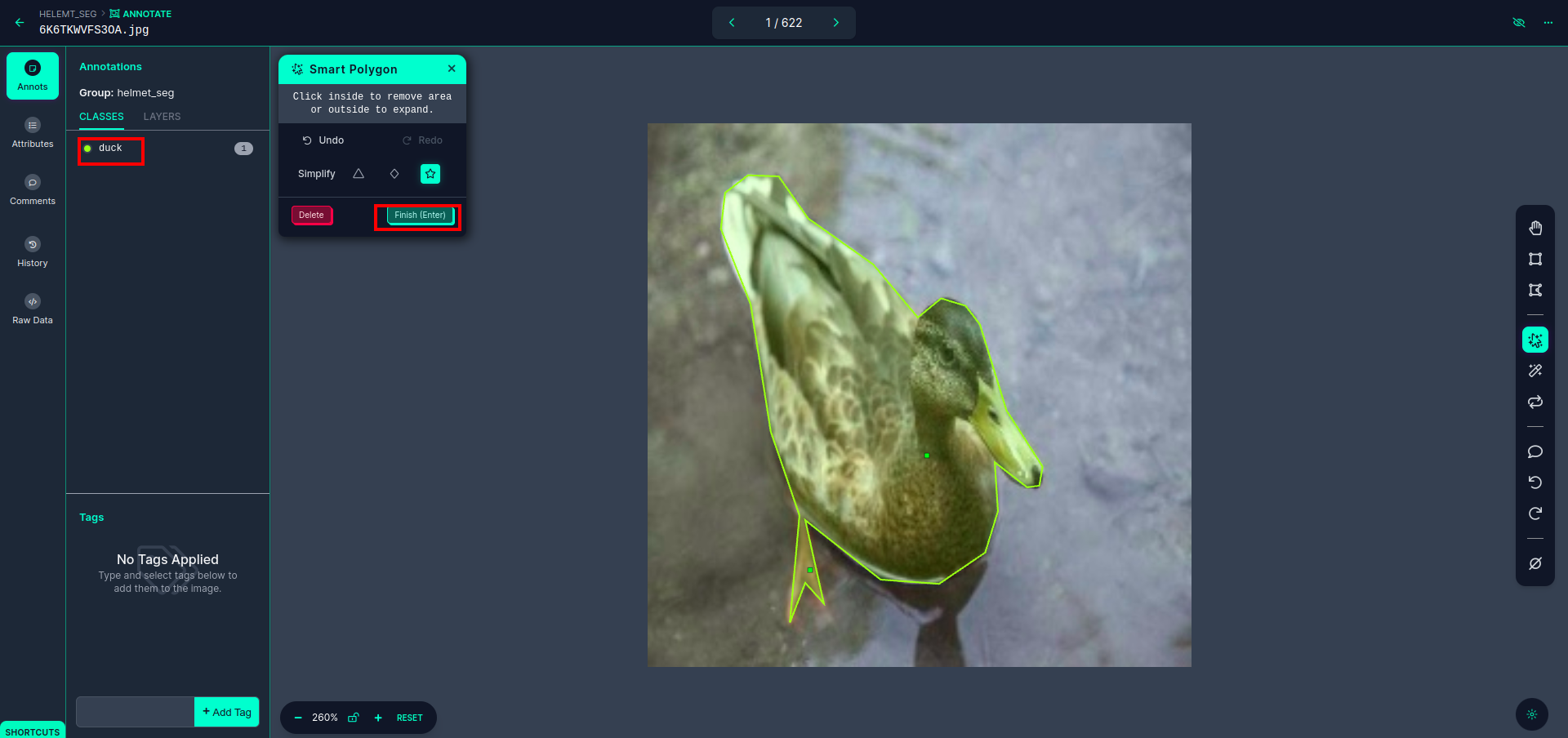
Cliquez enregistrer et saisir option. annoter toutes les images.
Ajoutez les images au format YOLOv8. Sur le côté droit, vous verrez l'option permettant d'ajouter des images dans la section d'annotation. Ici, deux parties sont créées : une pour les images annotées et une pour les images non annotées.
- Tout d’abord, cliquez sur le côté gauche «annoter" option alors ajouter les images à l’ensemble de données.
- Cliquez ensuite sur le suivant "Ajouter des images" .
Enfin, nous créons l'ensemble de données, alors cliquez sur l'option « Générer » sur le côté gauche, puis cochez l'option et appuyez sur l'option Continuer.
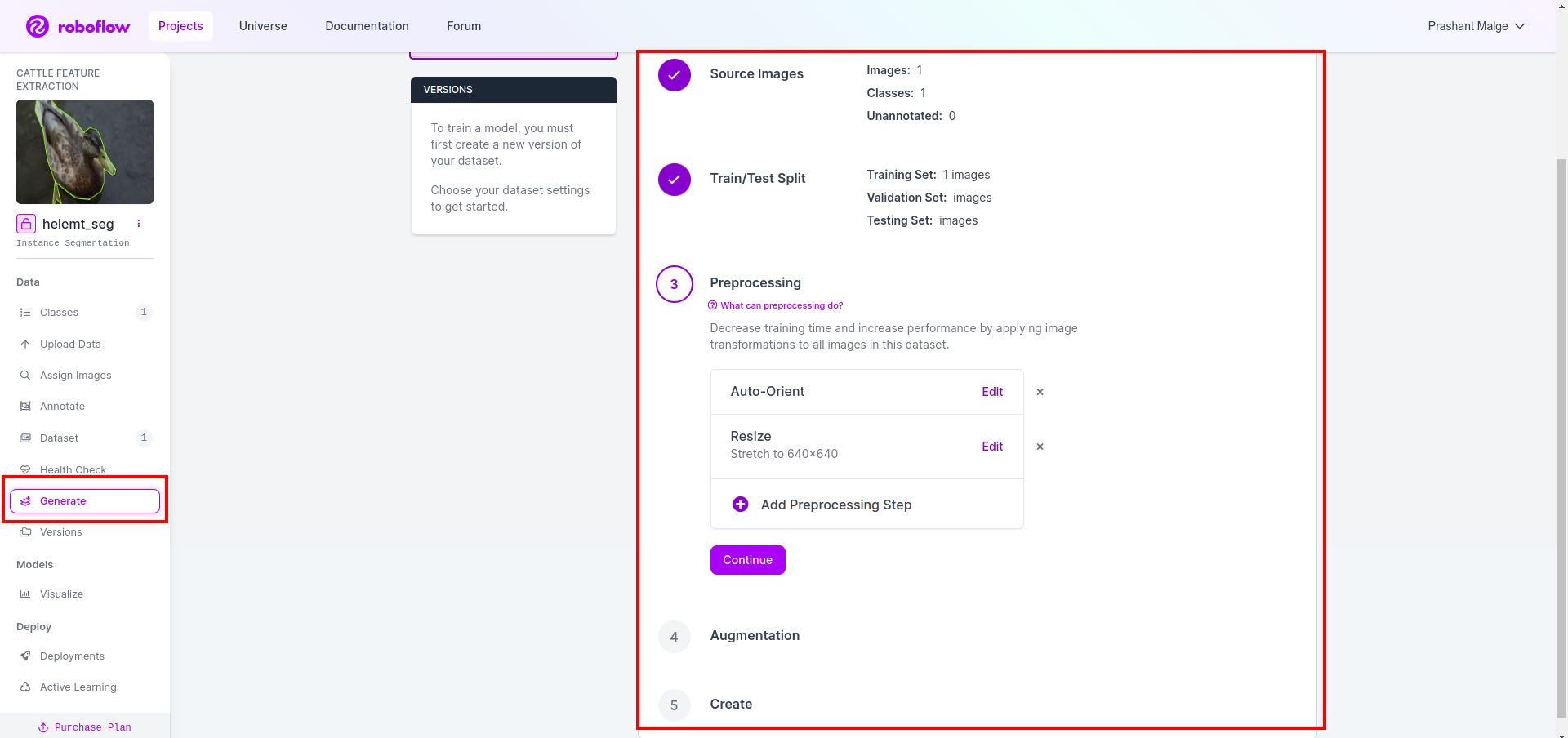
Ensuite, vous obtenez l'interface utilisateur de l'option de fractionnement de l'ensemble de données ici, vous pouvez vérifier les dossiers train, test et val dont les images sont automatiquement divisées. et cliquez sur la case rouge ci-dessus Option d'exportation de l'ensemble de données et téléchargez le fichier zip. la structure des dossiers de fichiers zip est comme…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Étape 6 : Écrivez le script pour entraîner le modèle de segmentation d'image
Dans cette partie, vous créez d'abord le fichier Google Collab à l'aide de Drive, puis téléchargez votre ensemble de données. et connectez Google Drive à l'aide de Google Collab.
1. Utilisez cette commande pour Monter Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Définir le répertoire de données Utilisez la variable Constante.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Installation du package requis, Installer des ultralytiques
!pip install ultralytics4. Importation des bibliothèques
import os
from ultralytics import YOLO5. Charger YOLOv8 pré-entraîné modèle (ici, nous avons différents modèles, consultez également la documentation officielle, vous pouvez voir les différents modèles)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Former le modèle
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Non, vérifiez votre lecteur. Le dossier du nom du modèle est créé et le modèle est enregistré pour la prédiction que nous voulons pour ce modèle.
7. Prédire le modèle
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Ici, vous pouvez voir que l'image de segmentation est enregistrée.

Nous pouvons enfin créer des modèles de détection en direct et de segmentation d'images.
Conclusion
Dans ce blog, nous explorons la détection d'objets en direct et la segmentation d'images avec YOLOv8. Pour la détection en direct, nous importons un modèle YOLOv8 pré-entraîné et utilisons la bibliothèque de vision par ordinateur, OpenCV, pour ouvrir la caméra et détecter les objets. De plus, nous créons une application Streamlit pour une interface utilisateur attrayante.
Ensuite, nous nous penchons sur la segmentation d'images avec YOLOv8. Nous importons un modèle pré-entraîné et effectuons un apprentissage par transfert sur un ensemble de données personnalisé. Avant cela, nous avons exploré Roboflow pour l'annotation d'ensembles de données, offrant une alternative facile à utiliser aux outils tels que ÉtiquetteImg.
Enfin, nous prédisons une image contenant un canard. Bien que l’objet dans l’image semble être un oiseau, nous spécifions le nom de la classe comme suit : »canard» à des fins de démonstration.
Faits marquants
- En savoir plus sur les modèles de détection d'objets tels que Faster R-CNN, SSD et le dernier YOLOv8.
- Comprendre l'outil d'annotation Roboflow et son rôle dans la création d'ensembles de données pour les modèles de segmentation YOLOv8.
- Explorer la détection d'objets vivants à l'aide d'OpenCV (cv2) et de supervision, améliorant ainsi les compétences pratiques.
- Formation et déploiement d'un modèle de segmentation à l'aide de YOLOv8, acquérant une expérience pratique.
Foire aux Questions
A. La détection d'objets implique l'identification et la localisation de plusieurs objets dans une image, généralement en dessinant des cadres de délimitation autour d'eux. La segmentation d'image, quant à elle, divise une image en segments ou régions en fonction de la similarité des pixels, offrant ainsi une compréhension plus détaillée des limites des objets.
A. YOLOv8 améliore les versions précédentes en intégrant des avancées dans l'architecture réseau, les techniques de formation et l'optimisation. Il peut offrir une meilleure précision, vitesse et efficacité par rapport à YOLOv3.
R. YOLOv8 peut être utilisé pour la détection d'objets en temps réel sur les appareils embarqués, en fonction des capacités matérielles et de l'optimisation du modèle. Cependant, cela peut nécessiter des optimisations telles que l'élagage du modèle ou la quantification pour obtenir des performances en temps réel sur des appareils aux ressources limitées.
R. Roboflow propose des outils d'annotation intuitifs, des fonctionnalités de gestion d'ensembles de données et la prise en charge de divers formats d'annotation. Il rationalise le processus d'annotation, permet la collaboration et fournit un contrôle de version, facilitant ainsi la création et la gestion d'ensembles de données pour les projets de vision par ordinateur.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

