Avec l'utilisation du cloud computing, du big data et des outils d'apprentissage automatique (ML) tels que Amazone Athéna or Amazon Sage Maker sont devenus disponibles et utilisables par n’importe qui sans trop d’efforts de création et de maintenance. Les entreprises industrielles se tournent de plus en plus vers l'analyse des données et la prise de décision basée sur les données pour accroître l'efficacité des ressources sur l'ensemble de leur portefeuille, depuis les opérations jusqu'à la maintenance prédictive ou la planification.
En raison de la rapidité des changements dans le domaine informatique, les clients des secteurs traditionnels sont confrontés à un dilemme en matière de compétences. D'une part, les analystes et les experts du domaine ont une connaissance très approfondie des données en question et de leur interprétation, mais manquent souvent d'exposition aux outils de science des données et aux langages de programmation de haut niveau tels que Python. D’un autre côté, les experts en science des données manquent souvent d’expérience pour interpréter le contenu des données machine et le filtrer pour déterminer ce qui est pertinent. Ce dilemme entrave la création de modèles efficaces qui utilisent les données pour générer des informations pertinentes pour l'entreprise.
Toile Amazon SageMaker résout ce dilemme en fournissant aux experts du domaine une interface sans code pour créer de puissants modèles d'analyse et de ML, tels que des modèles de prévisions, de classification ou de régression. Il vous permet également de déployer et de partager ces modèles avec des spécialistes ML et MLOps après création.
Dans cet article, nous vous montrons comment utiliser SageMaker Canvas pour organiser et sélectionner les bonnes fonctionnalités dans vos données, puis former un modèle de prédiction pour la détection des anomalies, en utilisant la fonctionnalité sans code de SageMaker Canvas pour le réglage du modèle.
Détection d'anomalies pour l'industrie manufacturière
Au moment de la rédaction de cet article, SageMaker Canvas se concentre sur les cas d'utilisation métier typiques, tels que la prévision, la régression et la classification. Pour cet article, nous démontrons comment ces capacités peuvent également aider à détecter des points de données anormaux complexes. Ce cas d’usage est pertinent par exemple pour repérer des dysfonctionnements ou des fonctionnements inhabituels de machines industrielles.
La détection des anomalies est importante dans le domaine industriel, car les machines (des trains aux turbines) sont normalement très fiables, avec des délais entre pannes s'étendant sur plusieurs années. La plupart des données de ces machines, telles que les relevés des capteurs de température ou les messages d'état, décrivent le fonctionnement normal et ont une valeur limitée pour la prise de décision. Les ingénieurs recherchent des données anormales lorsqu'ils recherchent les causes profondes d'un défaut ou comme indicateurs d'avertissement de défauts futurs, et les responsables des performances examinent les données anormales pour identifier des améliorations potentielles. Par conséquent, la première étape typique pour évoluer vers une prise de décision basée sur les données repose sur la recherche de données pertinentes (anormales).
Dans cet article, nous utilisons SageMaker Canvas pour organiser et sélectionner les bonnes fonctionnalités dans les données, puis former un modèle de prédiction pour la détection des anomalies, en utilisant la fonctionnalité sans code de SageMaker Canvas pour le réglage du modèle. Ensuite, nous déployons le modèle en tant que point de terminaison SageMaker.
Vue d'ensemble de la solution
Pour notre cas d'utilisation de détection d'anomalies, nous formons un modèle de prédiction pour prédire une caractéristique du fonctionnement normal d'une machine, telle que la température du moteur indiquée dans une voiture, à partir de caractéristiques influentes, telles que la vitesse et le couple récent appliqué dans la voiture. . Pour la détection d'anomalies sur un nouvel échantillon de mesures, nous comparons les prédictions du modèle pour la caractéristique avec les observations fournies.
Pour l'exemple du moteur d'une voiture, un expert du domaine obtient des mesures de la température normale du moteur, du couple moteur récent, de la température ambiante et d'autres facteurs d'influence potentiels. Ceux-ci vous permettent d'entraîner un modèle pour prédire la température à partir des autres caractéristiques. Nous pouvons ensuite utiliser le modèle pour prédire régulièrement la température du moteur. Lorsque la température prévue pour ces données est similaire à la température observée dans ces données, le moteur fonctionne normalement ; une divergence indiquera une anomalie, telle qu'une panne du système de refroidissement ou un défaut du moteur.
Le diagramme suivant illustre l'architecture de la solution.
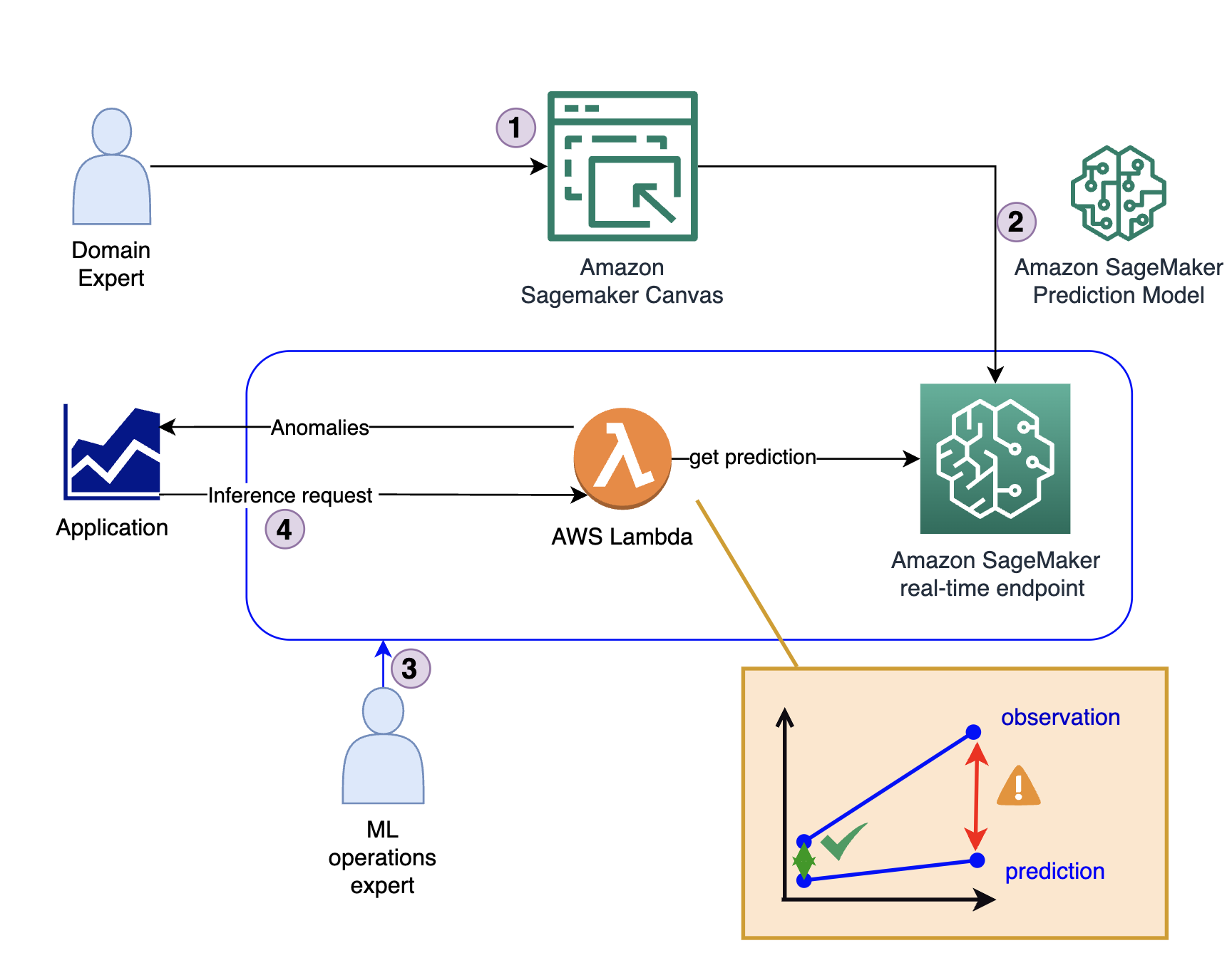
La solution se compose de quatre étapes clés :
- L'expert du domaine crée le modèle initial, y compris l'analyse des données et la curation des fonctionnalités à l'aide de SageMaker Canvas.
- L'expert du domaine partage le modèle via le Registre de modèles Amazon SageMaker ou le déploie directement en tant que point de terminaison en temps réel.
- Un expert MLOps crée l'infrastructure d'inférence et le code traduisant la sortie du modèle d'une prédiction en un indicateur d'anomalie. Ce code s'exécute généralement dans un AWS Lambda la fonction.
- Lorsqu'une application nécessite une détection d'anomalie, elle appelle la fonction Lambda, qui utilise le modèle pour l'inférence et fournit la réponse (qu'il s'agisse ou non d'une anomalie).
Pré-requis
Pour suivre cet article, vous devez remplir les prérequis suivants :
Créer le modèle à l'aide de SageMaker
Le processus de création de modèle suit les étapes standard pour créer un modèle de régression dans SageMaker Canvas. Pour plus d'informations, reportez-vous à Premiers pas avec Amazon SageMaker Canvas.
Tout d'abord, l'expert du domaine charge les données pertinentes dans SageMaker Canvas, telles qu'une série chronologique de mesures. Pour cet article, nous utilisons un fichier CSV contenant les mesures (générées synthétiquement) d'un moteur électrique. Pour plus de détails, reportez-vous à Importer des données dans Canvas. Les exemples de données utilisés sont disponibles en téléchargement sous forme de CSV.
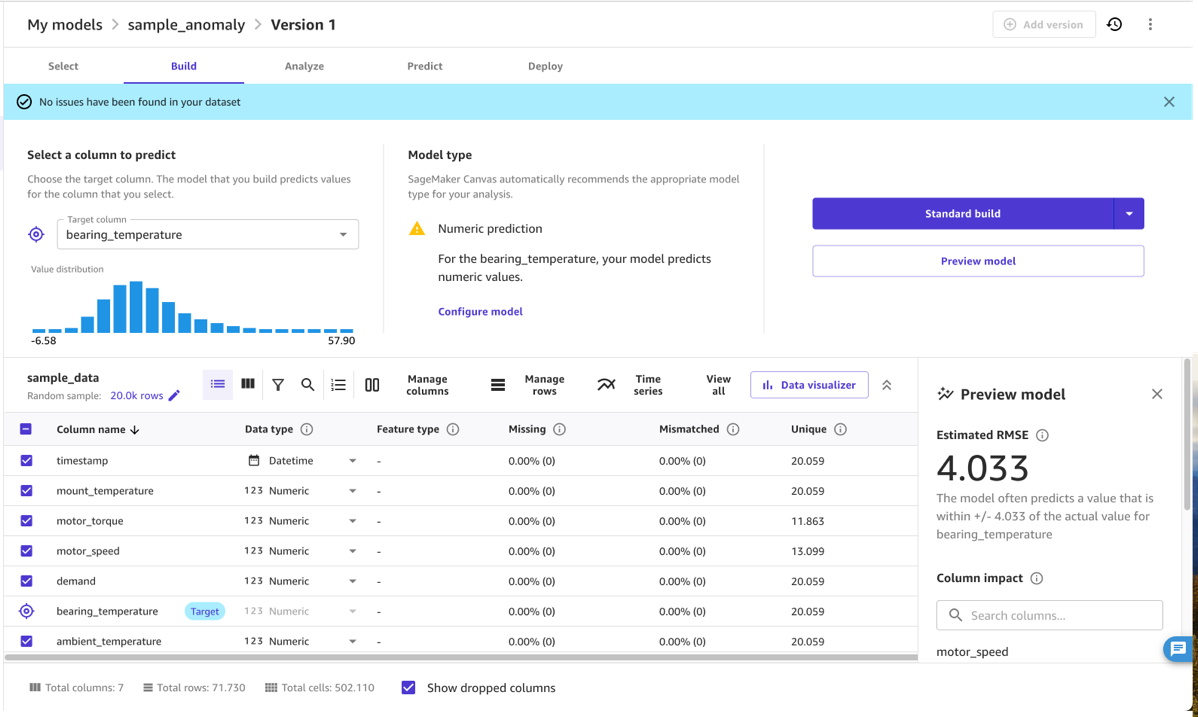
Organisez les données avec SageMaker Canvas
Une fois les données chargées, l'expert du domaine peut utiliser SageMaker Canvas pour organiser les données utilisées dans le modèle final. Pour cela, l'expert sélectionne les colonnes contenant des mesures caractéristiques du problème en question. Plus précisément, l'expert sélectionne les colonnes qui sont liées les unes aux autres, par exemple par une relation physique telle qu'une courbe pression-température, et pour lesquelles un changement dans cette relation constitue une anomalie pertinente pour son cas d'utilisation. Le modèle de détection d'anomalies apprendra la relation normale entre les colonnes sélectionnées et indiquera lorsque les données ne s'y conforment pas, comme une température anormalement élevée du moteur compte tenu de la charge actuelle du moteur.
En pratique, l'expert du domaine doit sélectionner un ensemble de colonnes d'entrée appropriées et une colonne cible. Les entrées sont généralement un ensemble de quantités (numériques ou catégorielles) qui déterminent le comportement d'une machine, depuis les paramètres de demande jusqu'à la charge, la vitesse ou la température ambiante. Le résultat est généralement une quantité numérique qui indique les performances de fonctionnement de la machine, comme une dissipation d'énergie mesurant la température ou une autre mesure de performance changeant lorsque la machine fonctionne dans des conditions sous-optimales.
Pour illustrer le concept des quantités à sélectionner pour l'entrée et la sortie, considérons quelques exemples :
- Pour les équipements tournants, tels que le modèle que nous construisons dans cet article, les entrées typiques sont la vitesse de rotation, le couple (courant et historique) et la température ambiante, et les cibles sont les températures résultantes des roulements ou du moteur indiquant de bonnes conditions de fonctionnement des rotations.
- Pour une éolienne, les entrées typiques sont l'historique actuel et récent de la vitesse du vent et des réglages des pales du rotor, et la quantité cible est la puissance produite ou la vitesse de rotation.
- Pour un processus chimique, les entrées typiques sont le pourcentage de différents ingrédients et la température ambiante, et les objectifs sont la chaleur produite ou la viscosité du produit final.
- Pour les équipements mobiles tels que les portes coulissantes, les entrées typiques sont la puissance absorbée par les moteurs et la valeur cible est la vitesse ou le temps d'exécution du mouvement.
- Pour un système CVC, les entrées typiques sont la différence de température obtenue et les réglages de charge, et la quantité cible est la consommation d'énergie mesurée.
En fin de compte, les bonnes entrées et cibles pour un équipement donné dépendront du cas d’utilisation et du comportement anormal à détecter, et sont mieux connues d’un expert du domaine familier avec les subtilités de l’ensemble de données spécifique.
Dans la plupart des cas, sélectionner les quantités d'entrée et cibles appropriées signifie sélectionner uniquement les colonnes de droite et marquer la colonne cible (pour cet exemple, bearing_temperature). Cependant, un expert du domaine peut également utiliser les fonctionnalités sans code de SageMaker Canvas pour transformer les colonnes et affiner ou agréger les données. Par exemple, vous pouvez extraire ou filtrer des dates ou des horodatages spécifiques des données qui ne sont pas pertinents. SageMaker Canvas prend en charge ce processus, affichant des statistiques sur les quantités sélectionnées, vous permettant de comprendre si une quantité présente des valeurs aberrantes et une répartition pouvant affecter les résultats du modèle.
Former, régler et évaluer le modèle
Une fois que l'expert du domaine a sélectionné les colonnes appropriées dans l'ensemble de données, il peut entraîner le modèle pour apprendre la relation entre les entrées et les sorties. Plus précisément, le modèle apprendra à prédire la valeur cible sélectionnée parmi les entrées.
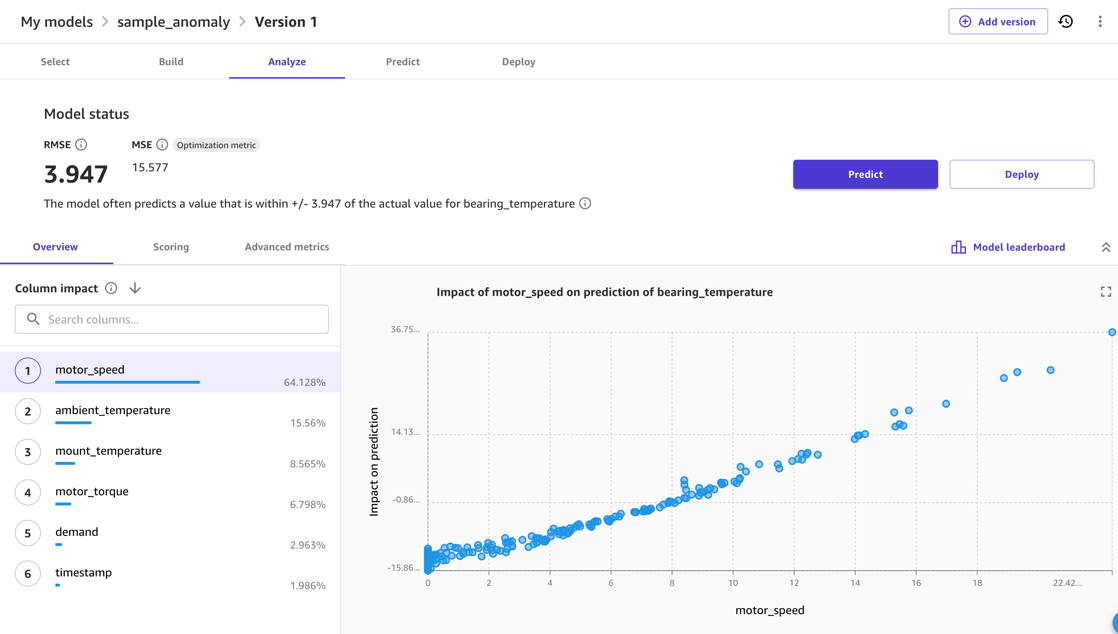
Normalement, vous pouvez utiliser SageMaker Canvas Aperçu du modèle option. Cela fournit une indication rapide de la qualité du modèle à attendre et vous permet d'étudier l'effet des différentes entrées sur la métrique de sortie. Par exemple, dans la capture d'écran suivante, le modèle est le plus affecté par le motor_speed ainsi que ambient_temperature métriques lors de la prévision bearing_temperature. C'est raisonnable, car ces températures sont étroitement liées. Dans le même temps, des frictions supplémentaires ou d’autres moyens de perte d’énergie sont susceptibles d’affecter ce résultat.
Pour la qualité du modèle, le RMSE du modèle est un indicateur de la capacité du modèle à apprendre le comportement normal des données d'entraînement et à reproduire les relations entre les mesures d'entrée et de sortie. Par exemple, dans le modèle suivant, le modèle devrait être capable de prédire le bon motor_bearing température inférieure à 3.67 degrés Celsius, nous pouvons donc considérer comme une anomalie un écart de la température réelle par rapport à une prévision du modèle qui est supérieur, par exemple, à 7.4 degrés. Le seuil réel que vous utiliserez dépendra toutefois de la sensibilité requise dans le scénario de déploiement.
Enfin, une fois l'évaluation et le réglage du modèle terminés, vous pouvez démarrer la formation complète du modèle qui créera le modèle à utiliser pour l'inférence.
Déployer le modèle
Bien que SageMaker Canvas puisse utiliser un modèle pour l'inférence, un déploiement productif pour la détection des anomalies nécessite que vous déployiez le modèle en dehors de SageMaker Canvas. Plus précisément, nous devons déployer le modèle en tant que point final.
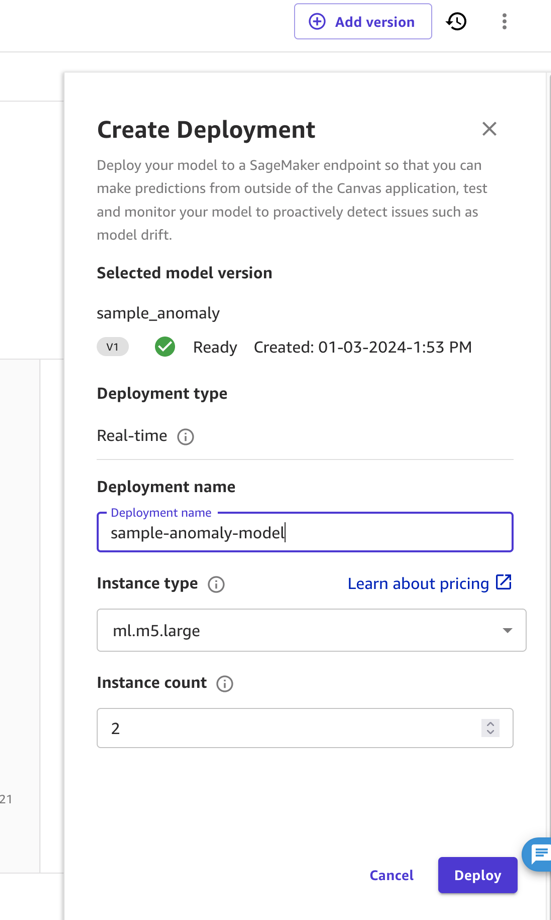
Dans cet article et par souci de simplicité, nous déployons le modèle en tant que point de terminaison directement depuis SageMaker Canvas. Pour obtenir des instructions, reportez-vous à Déployez vos modèles sur un point de terminaison. Assurez-vous de prendre note du nom du déploiement et de prendre en compte le prix du type d'instance sur lequel vous déployez (pour cet article, nous utilisons ml.m5.large). SageMaker Canvas créera ensuite un point de terminaison de modèle qui pourra être appelé pour obtenir des prédictions.
En milieu industriel, un modèle doit être soumis à des tests approfondis avant de pouvoir être déployé. Pour cela, l'expert du domaine ne le déploiera pas, mais partagera le modèle avec le registre de modèles SageMaker. Ici, un expert en opérations MLOps peut prendre le relais. En règle générale, cet expert testera le point de terminaison du modèle, évaluera la taille de l'équipement informatique requis pour l'application cible et déterminera le déploiement le plus rentable, tel que le déploiement pour l'inférence sans serveur ou l'inférence par lots. Ces étapes sont normalement automatisées (par exemple, en utilisant Pipelines Amazon Sagemaker au sein de l’ SDK Amazon).

Utiliser le modèle pour la détection des anomalies
À l'étape précédente, nous avons créé un déploiement de modèle dans SageMaker Canvas, appelé canvas-sample-anomaly-model. Nous pouvons l'utiliser pour obtenir des prédictions d'un bearing_temperature valeur basée sur les autres colonnes de l’ensemble de données. Maintenant, nous souhaitons utiliser ce point de terminaison pour détecter les anomalies.
Pour identifier les données anormales, notre modèle utilisera le point final du modèle de prédiction pour obtenir la valeur attendue de la métrique cible, puis comparera la valeur prédite à la valeur réelle dans les données. La valeur prédite indique la valeur attendue pour notre métrique cible en fonction des données d'entraînement. La différence de cette valeur est donc une mesure de l’anomalie des données réelles observées. Nous pouvons utiliser le code suivant :
Le code précédent effectue les actions suivantes :
- Les données d'entrée sont filtrées vers les bonnes caractéristiques (fonction "
input_transformer). - Le point de terminaison du modèle SageMaker est invoqué avec les données filtrées (fonction «
do_inference“), où nous gérons le formatage des entrées et des sorties selon l’exemple de code fourni lors de l’ouverture de la page de détails de notre déploiement dans SageMaker Canvas. - Le résultat de l'invocation est joint aux données d'entrée d'origine et la différence est stockée dans la colonne d'erreur (fonction «
output_transform).
Rechercher des anomalies et évaluer les événements anormaux
Dans une configuration typique, le code permettant d'obtenir des anomalies est exécuté dans une fonction Lambda. La fonction Lambda peut être appelée depuis une application ou Passerelle d'API Amazon. La fonction principale renvoie un score d'anomalie pour chaque ligne des données d'entrée, dans ce cas, une série chronologique d'un score d'anomalie.
Pour les tests, nous pouvons également exécuter le code dans un notebook SageMaker. Les graphiques suivants montrent les entrées et sorties de notre modèle lors de l'utilisation des exemples de données. Les pics d’écart entre les valeurs prédites et réelles (score d’anomalie, illustré dans le graphique inférieur) indiquent des anomalies. Par exemple, sur le graphique, nous pouvons voir trois pics distincts où le score d'anomalie (différence entre la température attendue et la température réelle) dépasse 7 degrés Celsius : le premier après une longue période d'inactivité, le second lors d'une forte baisse de température. bearing_temperature, et le dernier où bearing_temperature est élevé par rapport à motor_speed.
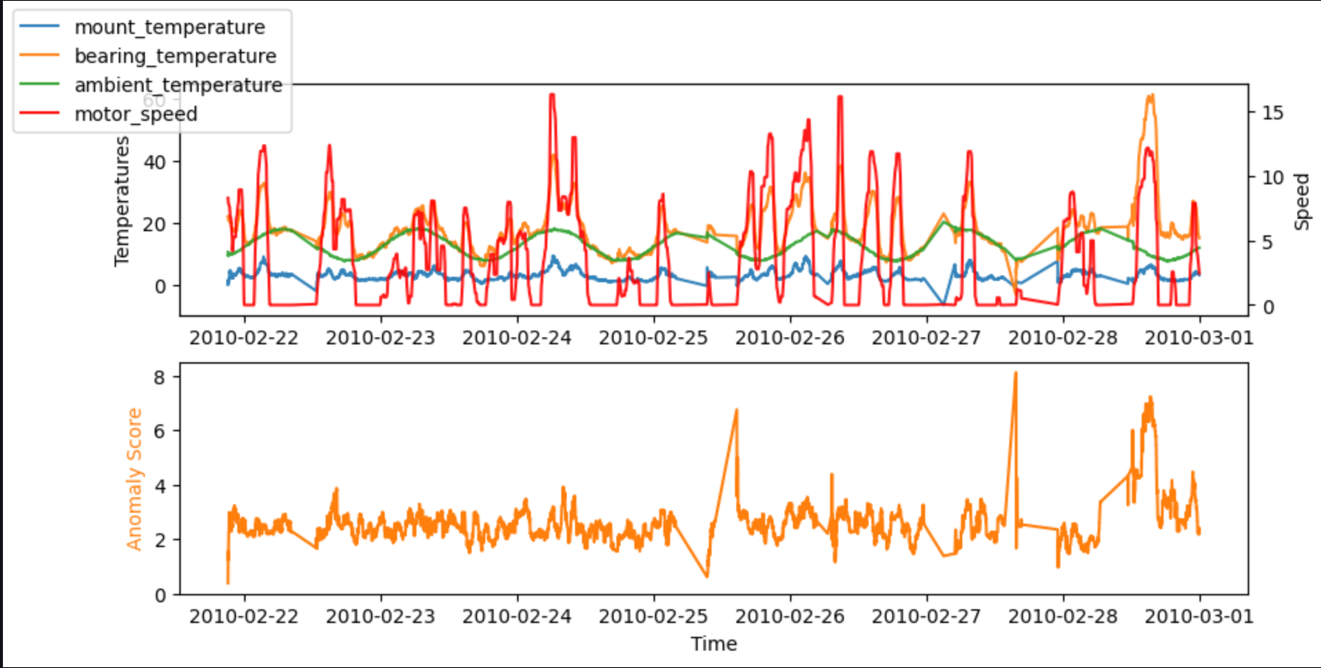
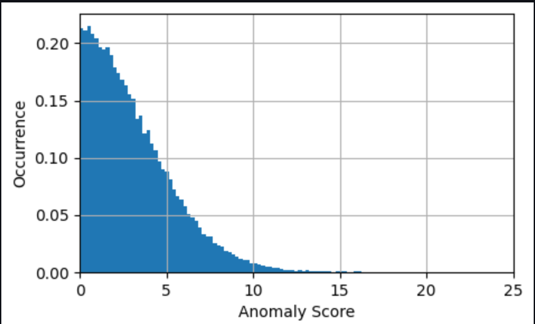
Dans de nombreux cas, connaître la série chronologique du score d’anomalie est déjà suffisant ; vous pouvez définir un seuil pour avertir d'une anomalie significative en fonction du besoin de sensibilité du modèle. Le score actuel indique alors qu’une machine présente un état anormal qui nécessite une enquête. Par exemple, pour notre modèle, la valeur absolue du score d'anomalie est distribuée comme le montre le graphique suivant. Cela confirme que la plupart des scores d'anomalies sont inférieurs aux (2xRMS=)8 degrés trouvés lors de la formation du modèle comme erreur typique. Le graphique peut vous aider à choisir manuellement un seuil, de sorte que le bon pourcentage des échantillons évalués soit marqué comme anomalie.
Si le résultat souhaité est constitué d'événements d'anomalies, les scores d'anomalies fournis par le modèle doivent être affinés pour être pertinents pour une utilisation commerciale. Pour cela, l'expert en ML ajoutera généralement un post-traitement pour supprimer le bruit ou les pics importants sur le score d'anomalie, comme l'ajout d'une moyenne glissante. De plus, l'expert évaluera généralement le score d'anomalie selon une logique similaire à l'augmentation d'un score d'anomalie. Amazon Cloud Watch d'alarme, comme par exemple la surveillance du franchissement d'un seuil sur une durée déterminée. Pour plus d'informations sur la configuration des alarmes, reportez-vous à Utilisation des alarmes Amazon CloudWatch. L'exécution de ces évaluations dans la fonction Lambda vous permet d'envoyer des avertissements, par exemple en publiant un avertissement à un Service de notification simple d'Amazon (Amazon SNS).
Nettoyer
Après avoir fini d’utiliser cette solution, vous devez faire le ménage pour éviter des coûts inutiles :
- Dans SageMaker Canvas, recherchez le déploiement de votre point de terminaison de modèle et supprimez-le.
- Déconnectez-vous de SageMaker Canvas pour éviter les frais liés à son fonctionnement inactif.
Résumé
Dans cet article, nous avons montré comment un expert du domaine peut évaluer les données d'entrée et créer un modèle ML à l'aide de SageMaker Canvas sans avoir besoin d'écrire du code. Nous avons ensuite montré comment utiliser ce modèle pour effectuer une détection d'anomalies en temps réel à l'aide de SageMaker et Lambda via un flux de travail simple. Cette combinaison permet aux experts du domaine d'utiliser leurs connaissances pour créer de puissants modèles de ML sans formation supplémentaire en science des données, et permet aux experts MLOps d'utiliser ces modèles et de les rendre disponibles pour l'inférence de manière flexible et efficace.
Un niveau gratuit de 2 mois est disponible pour SageMaker Canvas, et vous ne payez ensuite que ce que vous utilisez. Commencez à expérimenter dès aujourd'hui et ajoutez le ML pour tirer le meilleur parti de vos données.
A propos de l'auteure
 Helge Aufderheide est passionné par l'idée de rendre les données utilisables dans le monde réel, avec un fort accent sur l'automatisation, l'analyse et l'apprentissage automatique dans les applications industrielles, telles que la fabrication et la mobilité.
Helge Aufderheide est passionné par l'idée de rendre les données utilisables dans le monde réel, avec un fort accent sur l'automatisation, l'analyse et l'apprentissage automatique dans les applications industrielles, telles que la fabrication et la mobilité.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/

