Service de base de données relationnelle Amazon (Amazon RDS) pour MySQL intégration zéro ETL avec Redshift d'Amazon était annoncé en avant-première sur AWS re:Invent 2023 pour Amazon RDS pour MySQL version 8.0.28 ou supérieure. Dans cet article, nous fournissons des conseils étape par étape sur la façon de démarrer avec des analyses opérationnelles en temps quasi réel à l'aide de cette fonctionnalité. Cet article est une continuation de la série zéro-ETL qui a commencé avec Guide de démarrage pour l'analyse opérationnelle en temps quasi réel à l'aide de l'intégration Amazon Aurora zéro ETL avec Amazon Redshift.
Défis
Les clients de tous les secteurs cherchent aujourd'hui à utiliser les données à leur avantage concurrentiel et à augmenter leurs revenus et l'engagement des clients en mettant en œuvre des cas d'utilisation d'analyses en temps quasi réel tels que des stratégies de personnalisation, la détection des fraudes, la surveillance des stocks et bien d'autres. Il existe deux grandes approches pour analyser les données opérationnelles pour ces cas d’utilisation :
- Analysez les données en place dans la base de données opérationnelle (telles que les réplicas en lecture, les requêtes fédérées et les accélérateurs d'analyse)
- Déplacez les données vers un magasin de données optimisé pour exécuter des requêtes spécifiques à un cas d'utilisation, tel qu'un entrepôt de données.
L'intégration zéro ETL vise à simplifier cette dernière approche.
Le processus d'extraction, de transformation et de chargement (ETL) est un modèle courant pour déplacer des données d'une base de données opérationnelle vers un entrepôt de données analytiques. ELT est l'endroit où les données extraites sont d'abord chargées telles quelles dans la cible, puis transformées. Les pipelines ETL et ELT peuvent être coûteux à construire et complexes à gérer. Avec plusieurs points de contact, des erreurs intermittentes dans les pipelines ETL et ELT peuvent entraîner de longs retards, laissant les applications d'entrepôt de données avec des données obsolètes ou manquantes, conduisant ainsi à des opportunités commerciales manquées.
Alternativement, les solutions qui analysent les données sur place peuvent très bien fonctionner pour accélérer les requêtes sur une seule base de données, mais ces solutions ne sont pas capables de regrouper les données de plusieurs bases de données opérationnelles pour les clients qui ont besoin d'exécuter des analyses unifiées.
Zéro-ETL
Contrairement aux systèmes traditionnels où les données sont cloisonnées dans une seule base de données et où l'utilisateur doit faire un compromis entre analyse unifiée et performances, les ingénieurs de données peuvent désormais répliquer les données de plusieurs bases de données RDS pour MySQL dans un seul entrepôt de données Redshift pour en tirer des informations globales. de nombreuses applications ou partitions. Les mises à jour des bases de données transactionnelles sont automatiquement et continuellement propagées vers Amazon Redshift afin que les ingénieurs de données disposent des informations les plus récentes en temps quasi réel. Il n'y a aucune infrastructure à gérer et l'intégration peut automatiquement augmenter et diminuer en fonction du volume de données.
Chez AWS, nous avons fait des progrès constants pour apporter notre vision zéro ETL vivre. Les sources suivantes sont actuellement prises en charge pour les intégrations zéro ETL :
Lorsque vous créez une intégration ETL zéro pour Amazon Redshift, vous continuez à payer pour la base de données source sous-jacente et l'utilisation cible de la base de données Redshift. Faire référence à Coûts d'intégration ETL nuls (préversion) pour plus de détails
Avec l'intégration zéro ETL avec Amazon Redshift, l'intégration réplique les données de la base de données source vers l'entrepôt de données cible. Les données deviennent disponibles dans Amazon Redshift en quelques secondes, vous permettant d'utiliser les fonctionnalités d'analyse d'Amazon Redshift et des fonctionnalités telles que le partage de données, l'optimisation autonome de la charge de travail, la mise à l'échelle de la concurrence, l'apprentissage automatique et bien d'autres. Vous pouvez poursuivre le traitement de vos transactions sur Amazon RDS ou Amazon Aurora tout en utilisant simultanément Amazon Redshift pour les charges de travail d'analyse telles que les rapports et les tableaux de bord.
Le diagramme suivant illustre cette architecture.
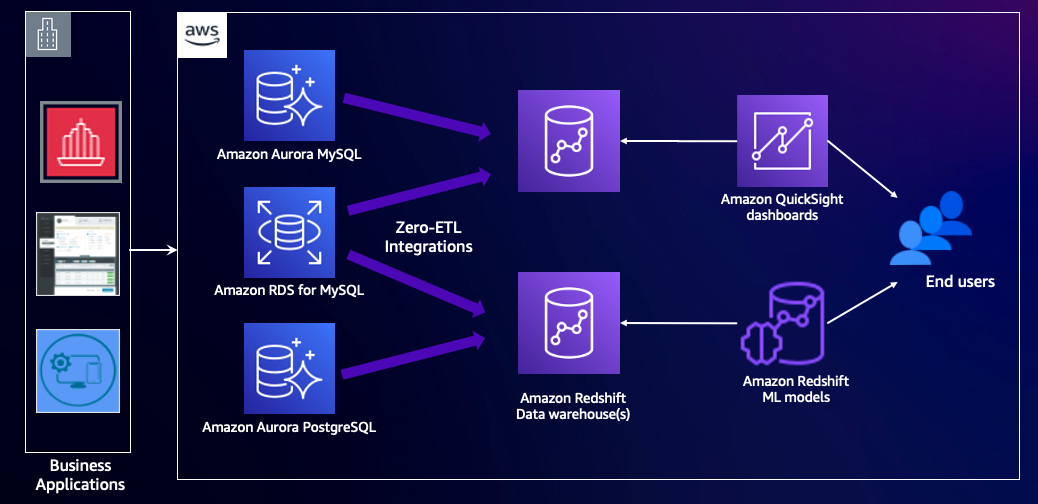
Vue d'ensemble de la solution
Considérons BILLET, un site Web fictif sur lequel les utilisateurs achètent et vendent des billets en ligne pour des événements sportifs, des spectacles et des concerts. Les données transactionnelles de ce site Web sont chargées dans une base de données Amazon RDS pour MySQL 8.0.28 (ou version supérieure). Les analystes commerciaux de la société souhaitent générer des mesures permettant d'identifier le mouvement des billets au fil du temps, les taux de réussite des vendeurs, ainsi que les événements, lieux et saisons les plus vendus. Ils aimeraient obtenir ces métriques en temps quasi réel en utilisant une intégration zéro ETL.
L'intégration est mise en place entre Amazon RDS pour MySQL (source) et Amazon Redshift (destination). Les données transactionnelles de la source sont actualisées quasiment en temps réel sur la destination, qui traite les requêtes analytiques.
Vous pouvez utiliser soit l'option sans serveur, soit un cluster RA3 chiffré pour Amazon Redshift. Pour cet article, nous utilisons une base de données RDS provisionnée et un entrepôt de données provisionné par Redshift.
Le schéma suivant illustre l'architecture de haut niveau.
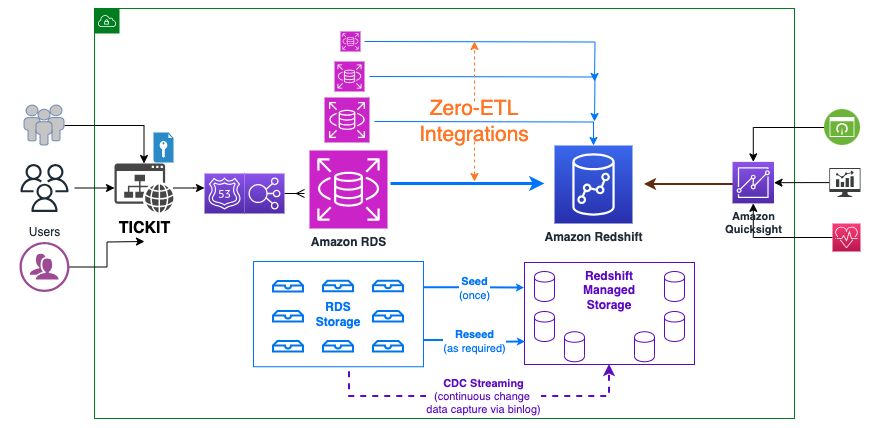
Voici les étapes nécessaires pour configurer l’intégration zéro ETL. Ces étapes peuvent être effectuées automatiquement par l'assistant zéro ETL, mais vous devrez redémarrer si l'assistant modifie le paramètre pour Amazon RDS ou Amazon Redshift. Vous pouvez effectuer ces étapes manuellement, si ce n'est déjà fait, et effectuer les redémarrages à votre convenance. Pour les guides de démarrage complets, reportez-vous à Utilisation des intégrations Amazon RDS zéro ETL avec Amazon Redshift (préversion) ainsi que Travailler avec des intégrations zéro ETL.
- Configurez la source RDS pour MySQL avec un groupe de paramètres de base de données personnalisé.
- Configurez le cluster Redshift pour activer les identifiants sensibles à la casse.
- Configurez les autorisations requises.
- Créez l'intégration zéro ETL.
- Créez une base de données à partir de l'intégration dans Amazon Redshift.
Configurez la source RDS pour MySQL avec un groupe de paramètres de base de données personnalisé
Pour créer une base de données RDS pour MySQL, procédez comme suit :
- Sur la console Amazon RDS, créez un groupe de paramètres de base de données appelé
zero-etl-custom-pg.
L'intégration Zero-ETL fonctionne en utilisant des journaux binaires (binlogs) générés par la base de données MySQL. Pour activer les binlogs sur Amazon RDS pour MySQL, un ensemble spécifique de paramètres doit être activé.
- Définissez les paramètres de cluster binlog suivants :
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
De plus, assurez-vous que le binlog_row_value_options le paramètre n’est pas réglé sur PARTIAL_JSON. Par défaut, ce paramètre n'est pas défini.
- Selectionnez Bases de données dans le volet de navigation, puis choisissez Créer une base de données.
- Pour Version du moteur, choisissez MySQL 8.0.28 (ou plus).

- Pour Gabarits, sélectionnez Vidéo.
- Pour Disponibilité et durabilité, sélectionnez soit Instance de base de données multi-AZ or Instance de base de données unique (Les clusters de bases de données multi-AZ ne sont pas pris en charge au moment d'écrire ces lignes).
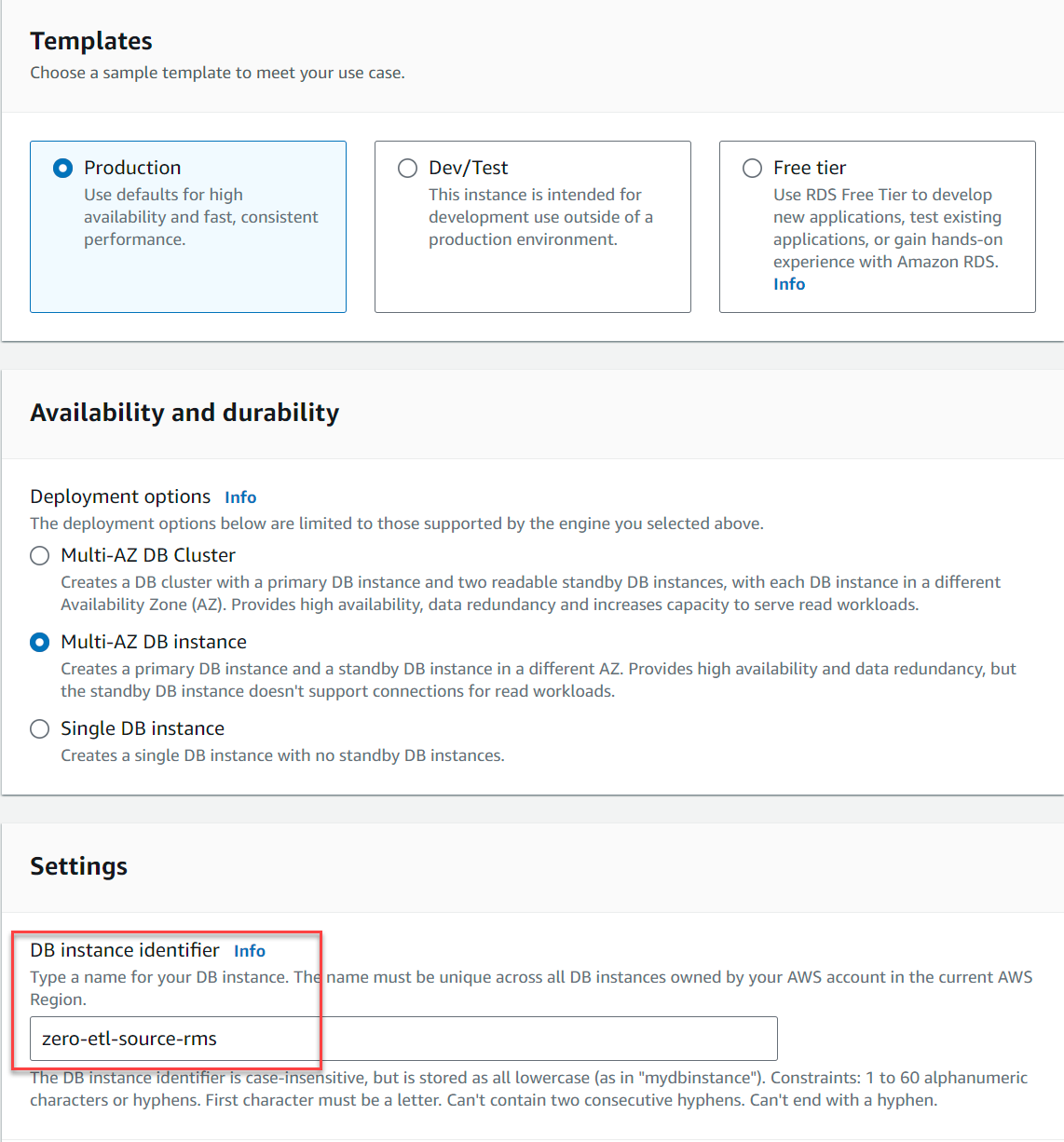
- Pour Identificateur d'instance de base de données, Entrer
zero-etl-source-rms.
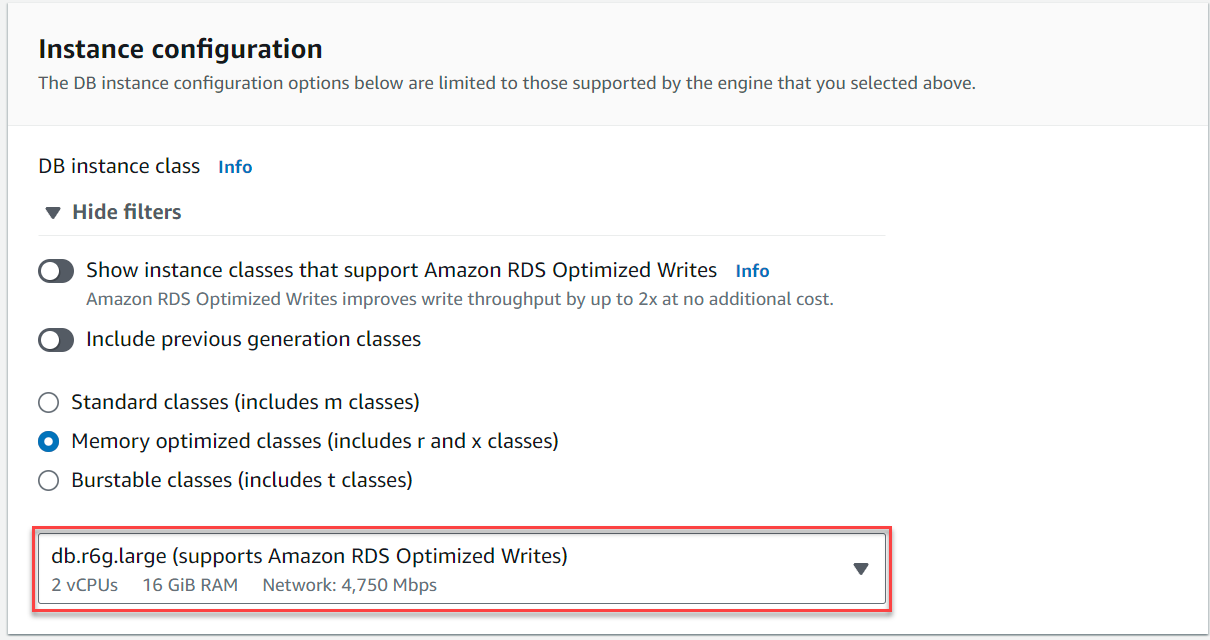
- Sous Configuration des instances, sélectionnez Classes optimisées en mémoire et choisissez l'instance
db.r6g.large, ce qui devrait être suffisant pour le cas d'utilisation de TICKIT.
- Sous Configuration supplémentaire, Pour Groupe de paramètres de cluster de base de données, choisissez le groupe de paramètres que vous avez créé précédemment (
zero-etl-custom-pg).
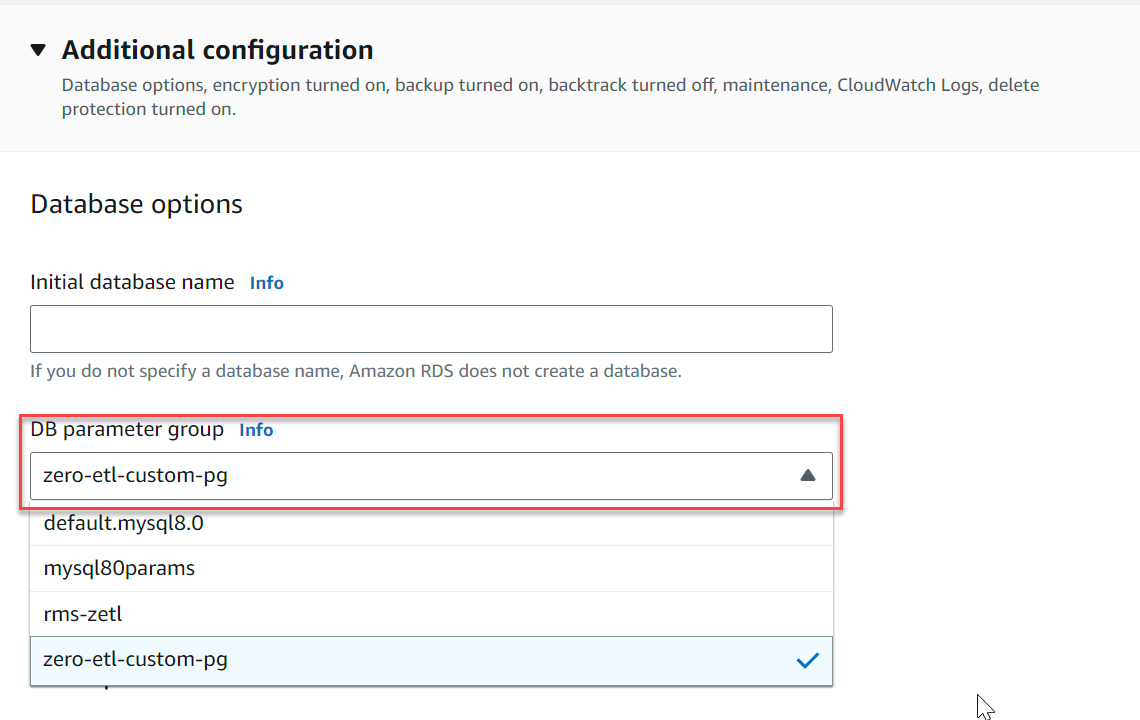
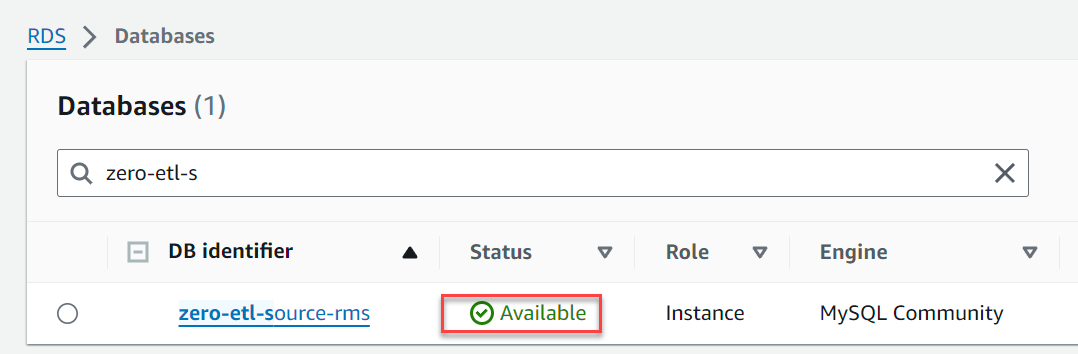
- Selectionnez Créer une base de données.
Dans quelques minutes, il devrait créer une base de données RDS pour MySQL comme source d'intégration zéro ETL.
Configurer la destination Redshift
Après avoir créé votre cluster de base de données source, vous devez créer et configurer un entrepôt de données cible dans Amazon Redshift. L'entrepôt de données doit répondre aux exigences suivantes :
- Utilisation d'un type de nœud RA3 (
ra3.16xlarge,ra3.4xlargeoura3.xlplus) ou Amazon Redshift sans serveur - Chiffré (si vous utilisez un cluster provisionné)
Pour notre cas d'utilisation, créez un cluster Redshift en procédant comme suit :
- Sur la console Amazon Redshift, choisissez Configurations puis choisissez Gestion de la charge de travail.
- Dans la section groupe de paramètres, choisissez Création.
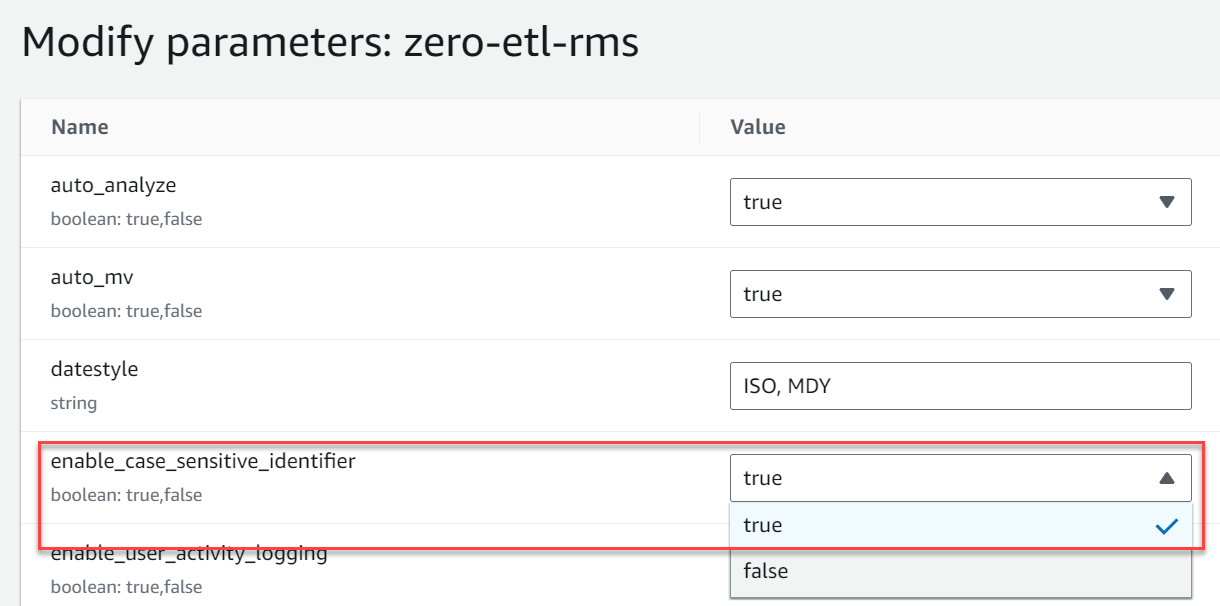
- Créez un nouveau groupe de paramètres nommé
zero-etl-rms. - Selectionnez Modifier les paramètres et changer la valeur de
enable_case_sensitive_identifieràTrue. - Selectionnez Épargnez.
Vous pouvez également utiliser la Interface de ligne de commande AWS (AWS CLI) commande groupe de travail de mise à jour pour Redshift sans serveur :
- Selectionnez Tableau de bord des clusters provisionnés.
En haut de la fenêtre de votre console, vous verrez un Essayez les nouvelles fonctionnalités d'Amazon Redshift en avant-première bannière.
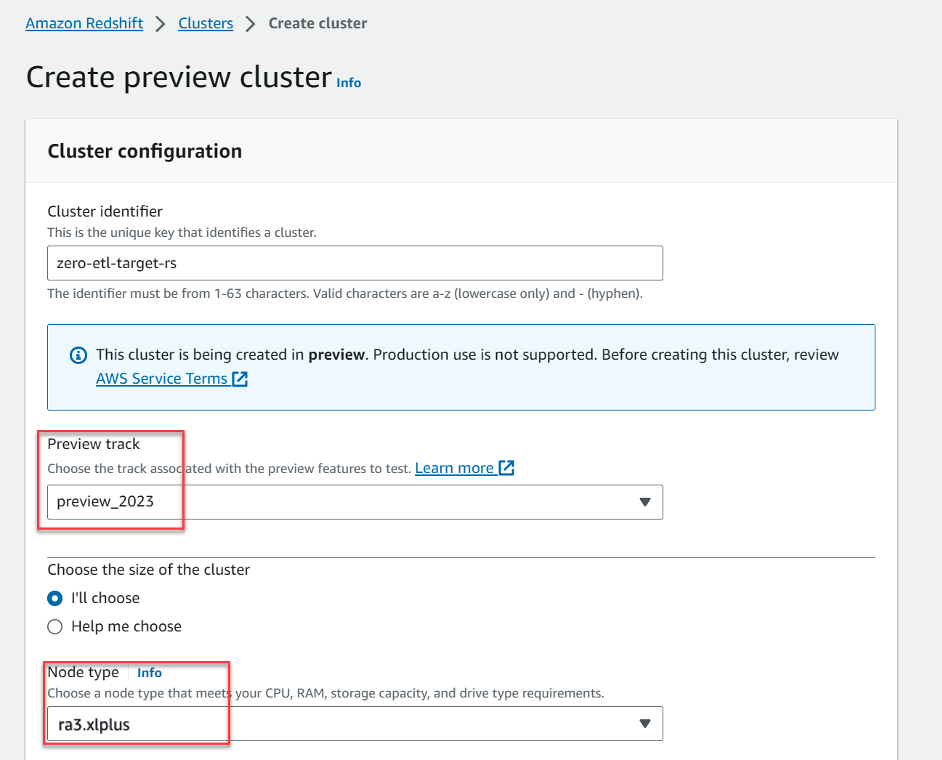
- Selectionnez Créer un cluster d'aperçu.

- Pour Aperçu de la piste, a choisi
preview_2023. - Pour Type de nœud, choisissez l'un des types de nœuds pris en charge (pour cet article, nous utilisons
ra3.xlplus).
- Sous Configurations supplémentaires, développer Configurations de base de données.
- Pour Groupes de paramètres, choisissez
zero-etl-rms. - Pour Chiffrement, sélectionnez Utiliser le service de gestion de clés AWS.
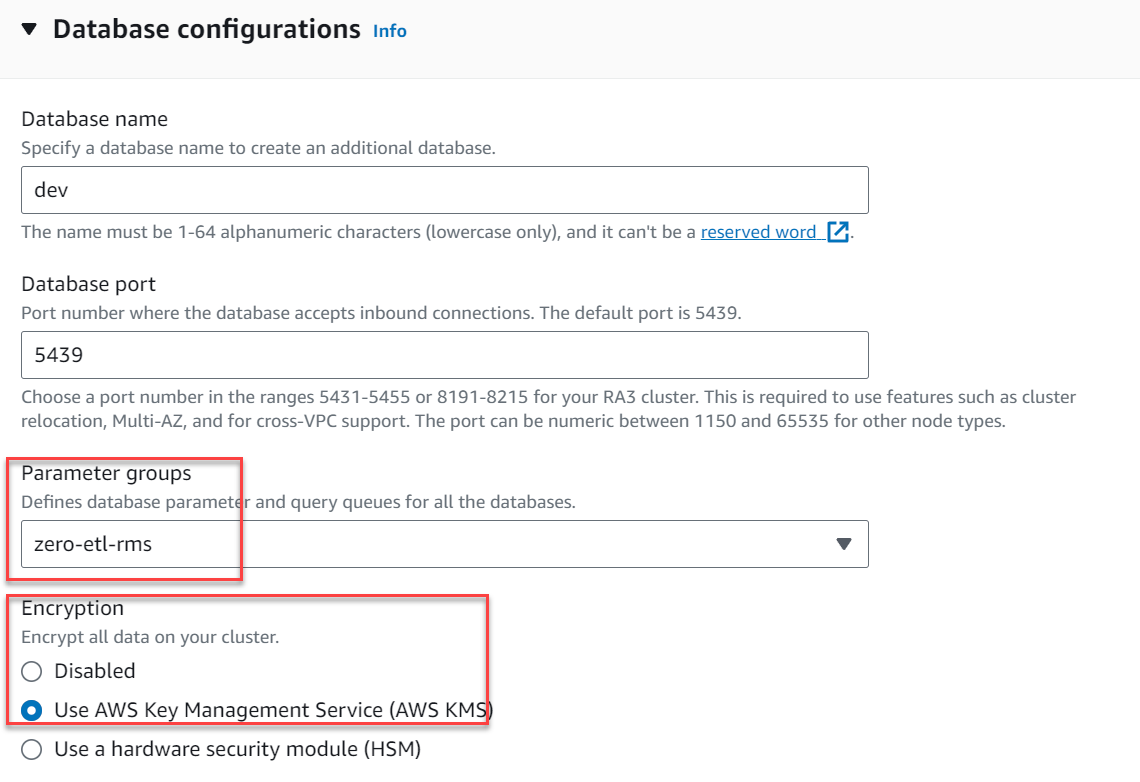
- Selectionnez Créer un cluster.
Le cluster devrait devenir Disponible Dans quelques minutes.

- Accédez à l'espace de noms
zero-etl-target-rs-nsEt choisissez le Politique de ressources languette. - Selectionnez Ajouter des mandants autorisés.
- Saisissez soit le nom de ressource Amazon (ARN) de l'utilisateur ou du rôle AWS, soit l'ID de compte AWS (mandants IAM) autorisés à créer des intégrations.
Un ID de compte est stocké en tant qu'ARN avec l'utilisateur root.
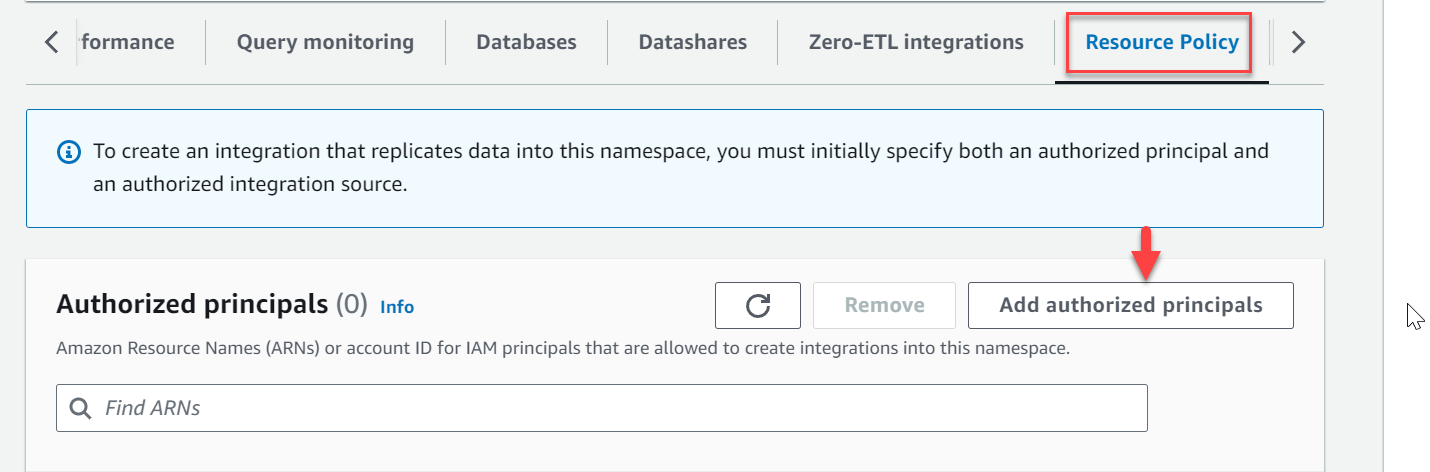
- Dans le Sources d'intégration autorisées section, choisissez Ajouter une source d'intégration autorisée pour ajouter l'ARN de l'instance de base de données RDS pour MySQL qui est la source de données pour l'intégration zéro-ETL.
Vous pouvez trouver cette valeur en accédant à la console Amazon RDS et en accédant à configuration onglet du zero-etl-source-rms Instance de base de données.

Votre politique de ressources doit ressembler à la capture d'écran suivante.
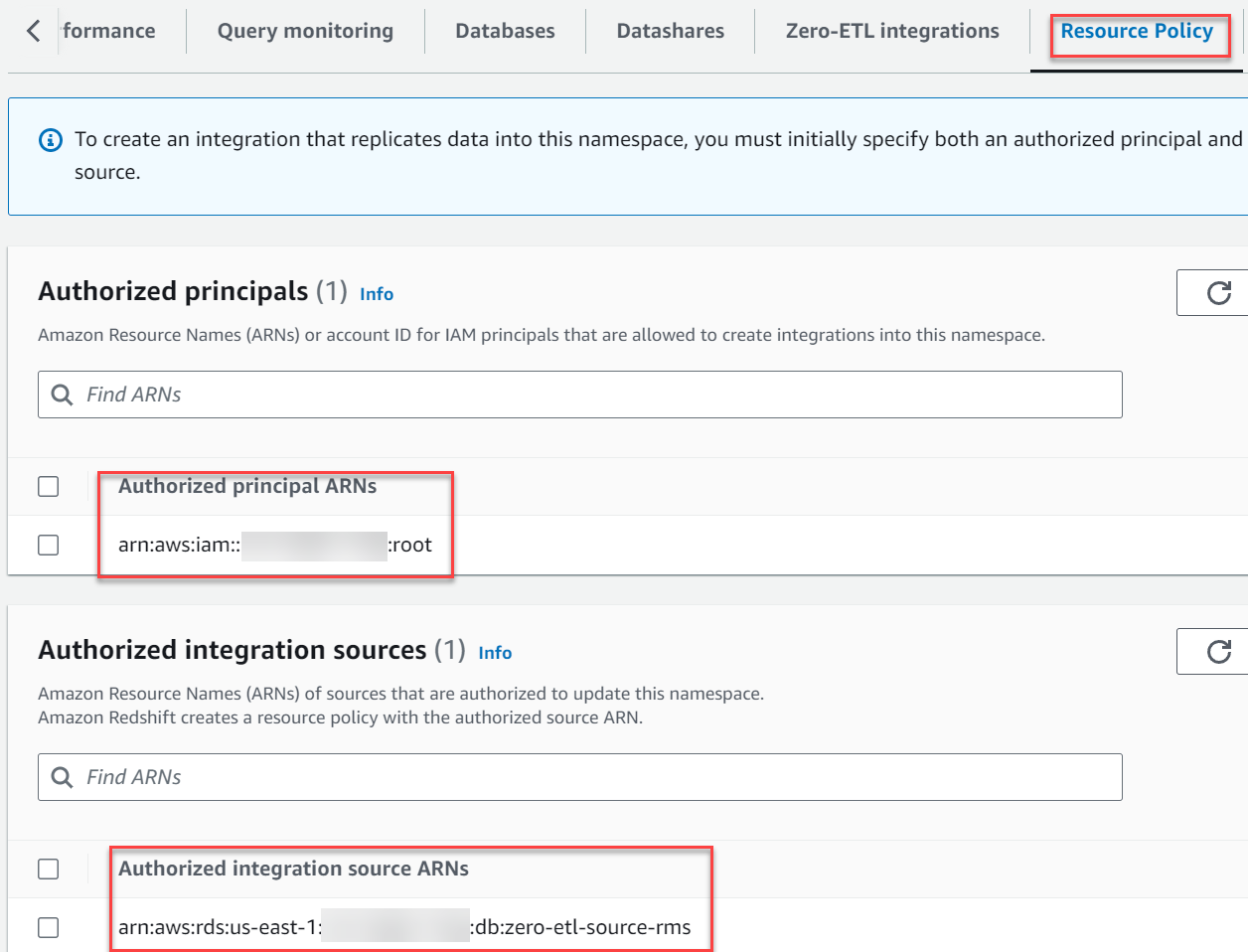
Configurer les autorisations requises
Pour créer une intégration sans ETL, votre utilisateur ou votre rôle doit avoir un lien politique basée sur l'identité avec le bon Gestion des identités et des accès AWS (IAM). Un propriétaire de compte AWS peut configurer les autorisations requises pour les utilisateurs ou les rôles susceptibles de créer des intégrations zéro ETL. L'exemple de stratégie permet au mandataire associé d'effectuer les actions suivantes :
- Créez des intégrations zéro ETL pour l'instance de base de données RDS source pour MySQL.
- Affichez et supprimez toutes les intégrations sans ETL.
- Créez des intégrations entrantes dans l'entrepôt de données cible. Cette autorisation n'est pas requise si le même compte possède l'entrepôt de données Redshift et que ce compte est un mandataire autorisé pour cet entrepôt de données. Notez également qu'Amazon Redshift a un format ARN différent pour les clusters provisionnés et sans serveur :
- Provisionné -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Sans serveur -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Provisionné -
Effectuez les étapes suivantes pour configurer les autorisations :
- Sur la console IAM, choisissez Politiques internes dans le volet de navigation.
- Selectionnez Créer une politique.
- Créez une nouvelle stratégie appelée
rds-integrationsen utilisant le JSON suivant (remplacerregionainsi queaccount-idavec vos valeurs réelles):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Attachez la stratégie que vous avez créée à vos autorisations d'utilisateur ou de rôle IAM.
Créer l'intégration zéro ETL
Pour créer l'intégration sans ETL, procédez comme suit :
- Sur la console Amazon RDS, choisissez Intégrations sans ETL dans le volet de navigation.
- Selectionnez Créer une intégration sans ETL.

- Pour Identifiant d'intégration, entrez un nom, par exemple
zero-etl-demo.
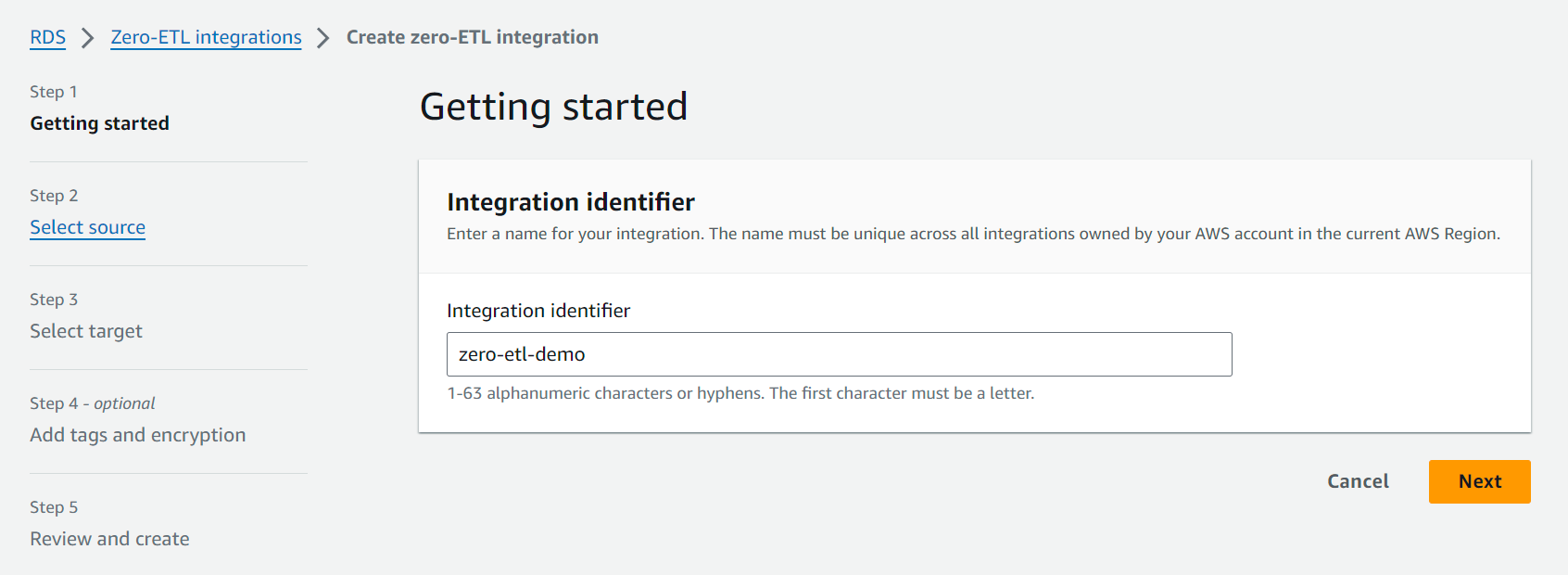
- Pour Base de données source, choisissez Parcourir les bases de données RDS et choisissez le cluster source
zero-etl-source-rms. - Selectionnez Suivant.

- Sous Target, Pour Entrepôt de données Amazon Redshift, choisissez Parcourir les entrepôts de données Redshift et choisissez l'entrepôt de données Redshift (
zero-etl-target-rs). - Selectionnez Suivant.
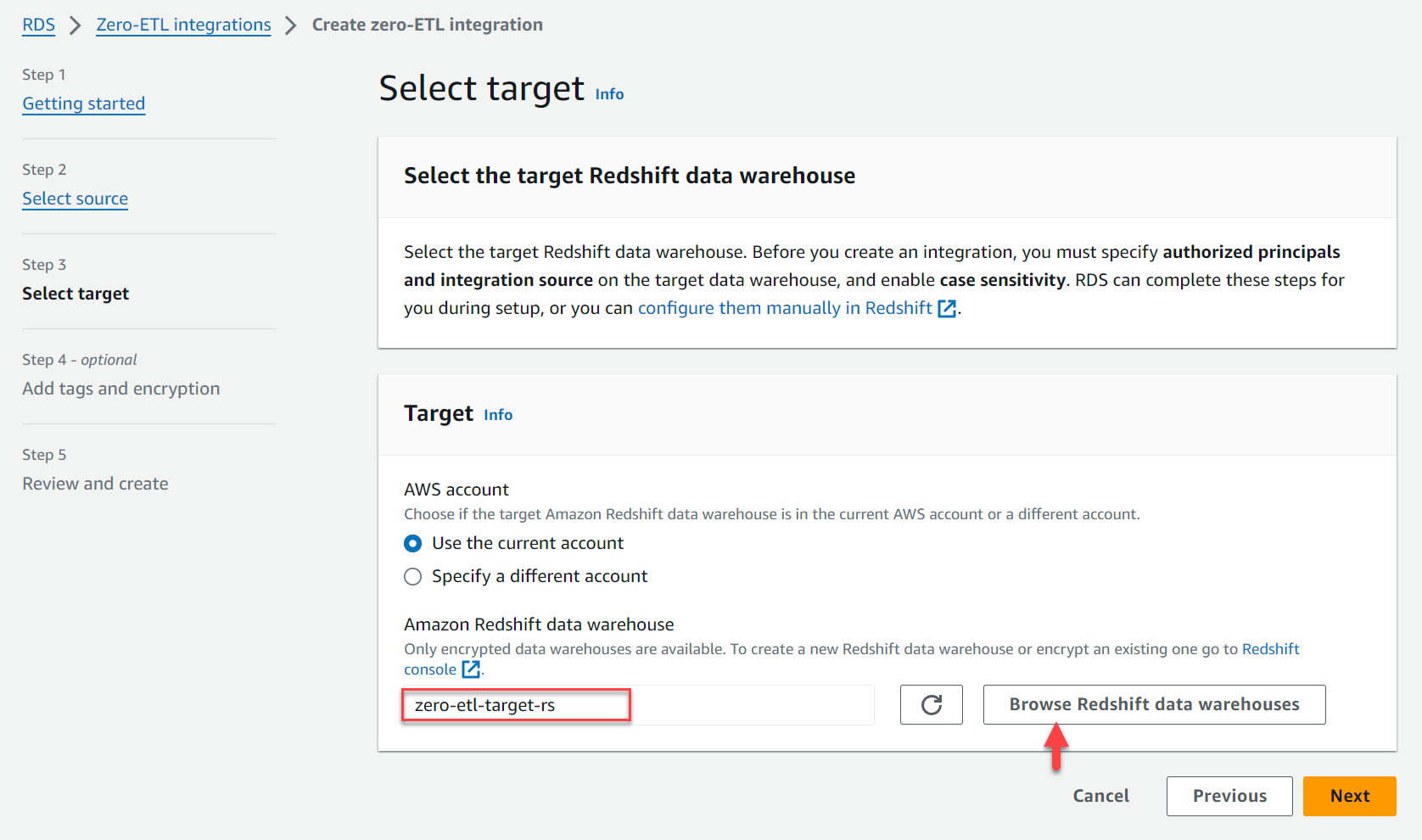
- Ajoutez des balises et un cryptage, le cas échéant.
- Selectionnez Suivant.
- Vérifiez le nom de l'intégration, la source, la cible et d'autres paramètres.
- Selectionnez Créer une intégration sans ETL.
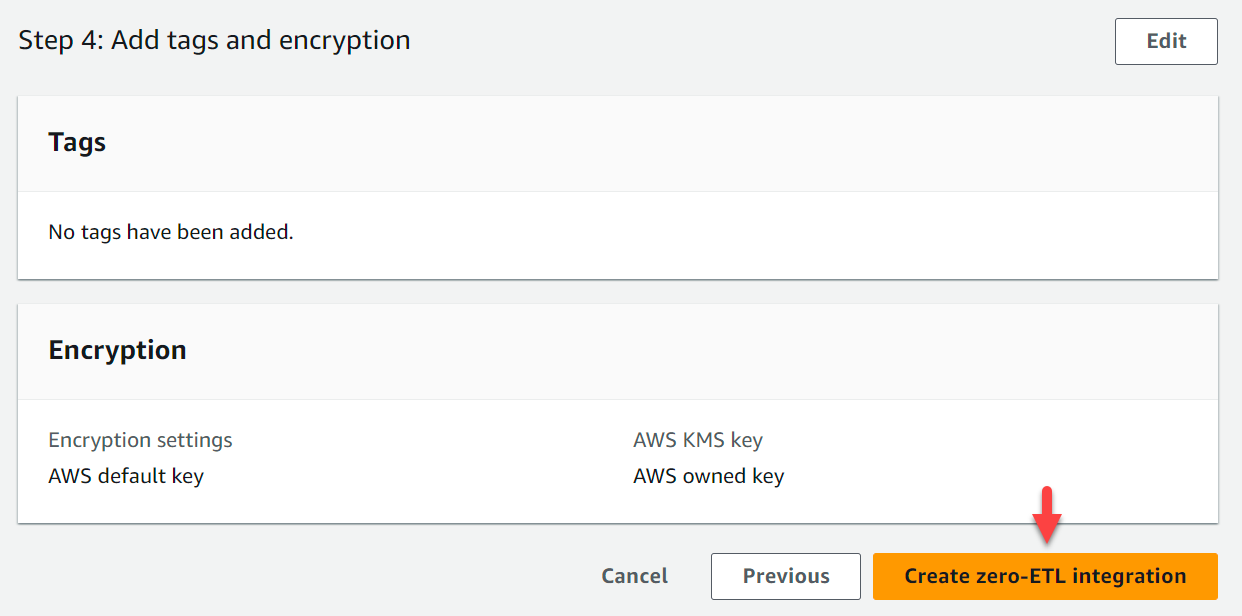
Vous pouvez choisir l'intégration pour afficher les détails et suivre sa progression. Il a fallu environ 30 minutes pour que le statut passe de La création à Actif.

La durée varie en fonction de la taille de votre ensemble de données dans la source.
Créer une base de données à partir de l'intégration dans Amazon Redshift
Pour créer votre base de données à partir de l'intégration zéro ETL, procédez comme suit :
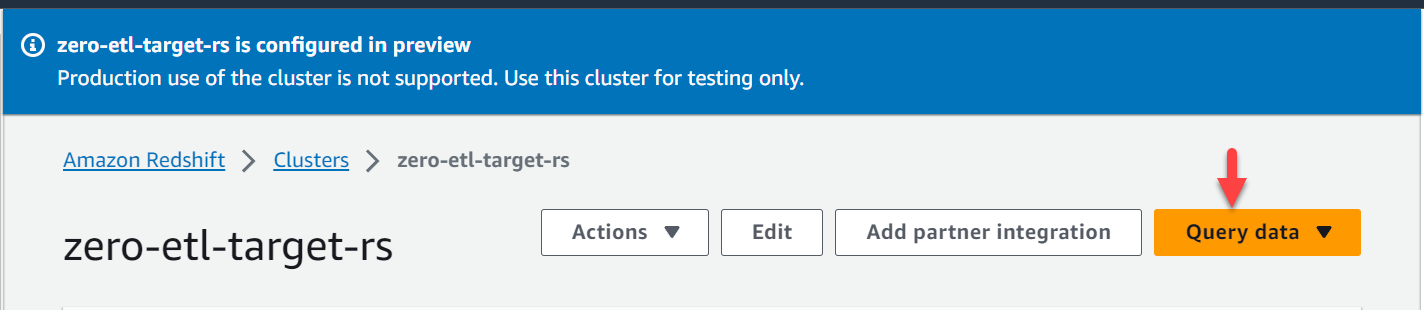
- Sur la console Amazon Redshift, choisissez Clusters dans le volet de navigation.
- Ouvrez le
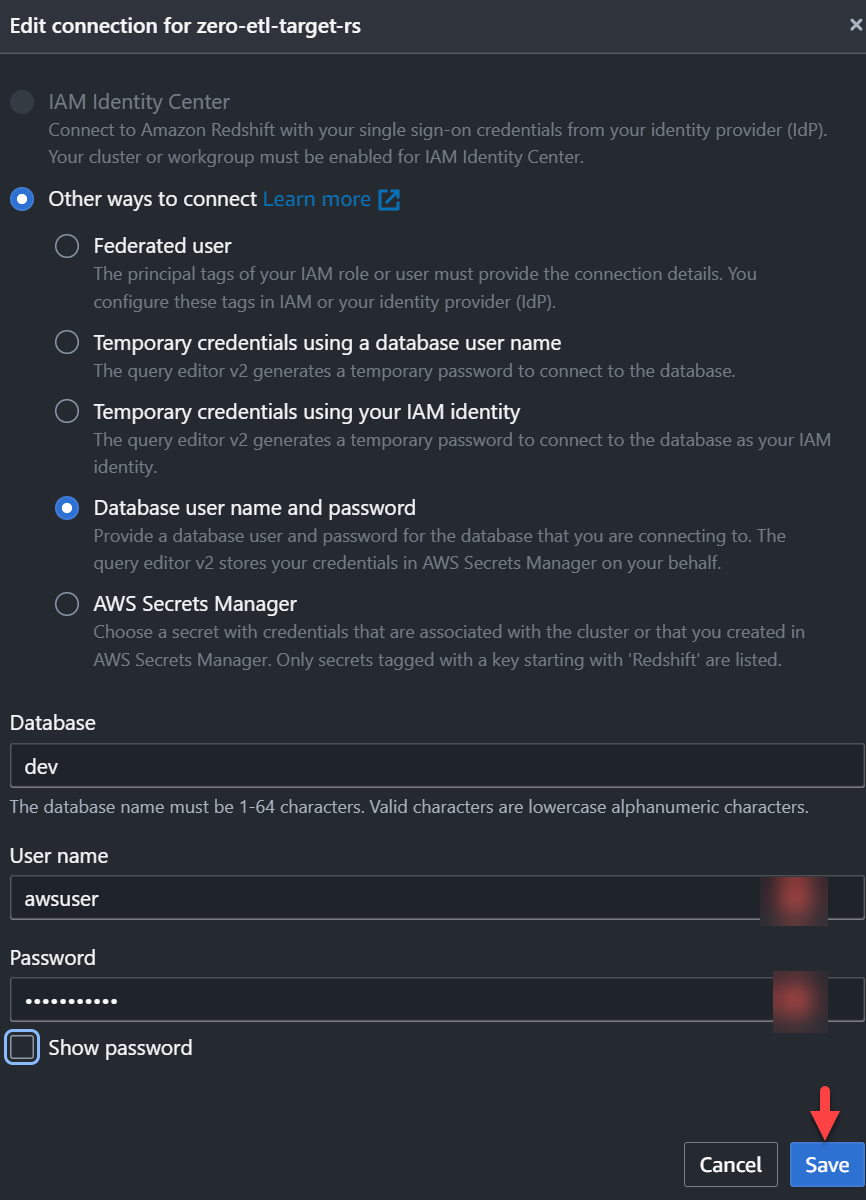
zero-etl-target-rs. - Selectionnez Données de requête pour ouvrir l'éditeur de requêtes v2.
- Connectez-vous à l'entrepôt de données Redshift en choisissant Épargnez.
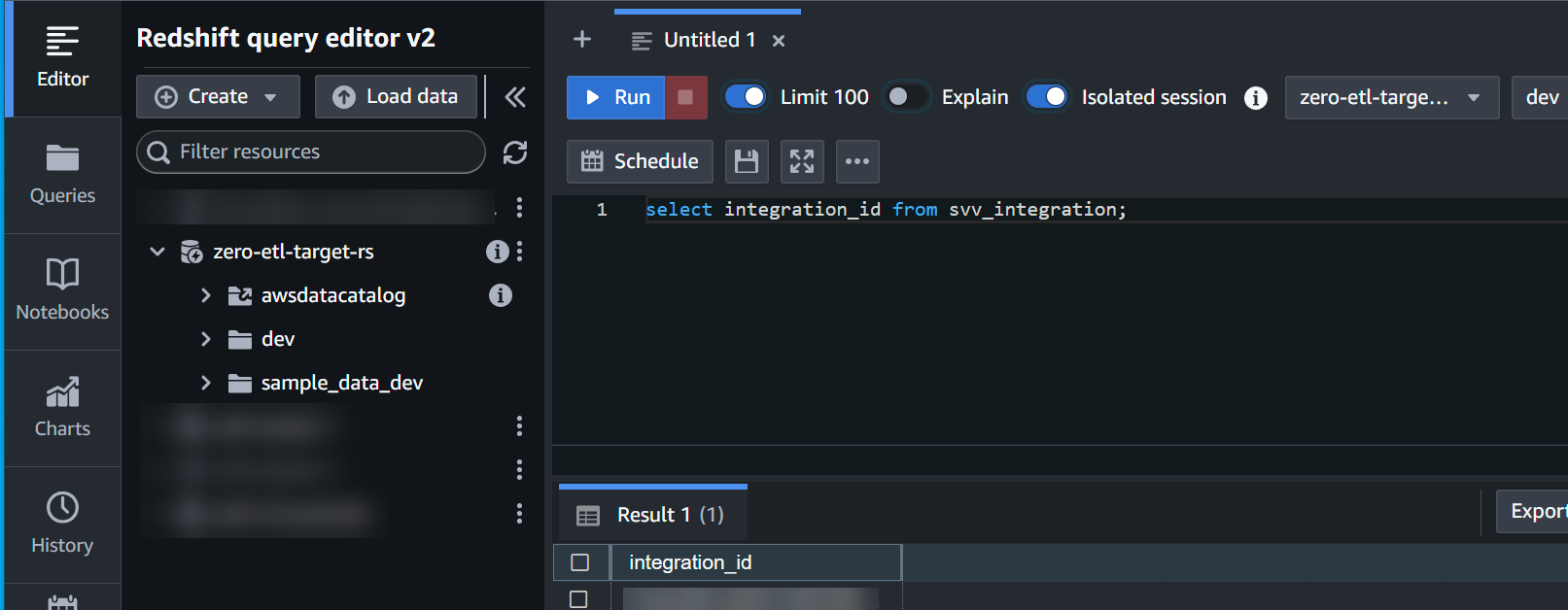
- Obtenez le
integration_iddusvv_integrationtableau système :
select integration_id from svv_integration; -- copy this result, use in the next sql
- Utilisez l'option
integration_idde l'étape précédente pour créer une nouvelle base de données à partir de l'intégration :
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
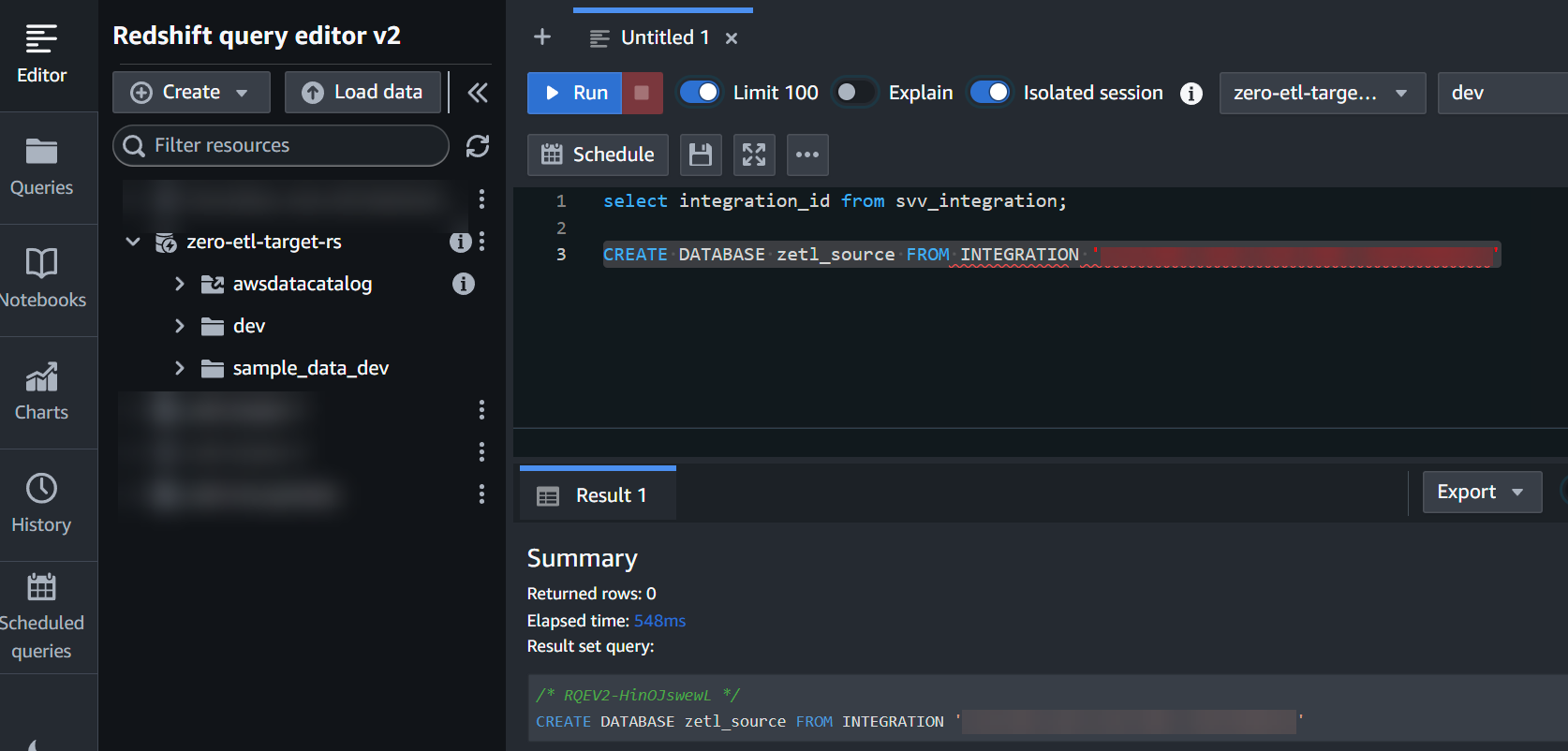
L'intégration est maintenant terminée et un instantané complet de la source sera reflété tel quel dans la destination. Les modifications en cours seront synchronisées presque en temps réel.
Analyser les données transactionnelles en temps quasi réel
Nous pouvons maintenant exécuter des analyses sur les données opérationnelles de TICKIT.
Remplir les données TICKIT source
Pour renseigner les données source, procédez comme suit :
- Copiez les fichiers de données d'entrée CSV dans un répertoire local. Voici un exemple de commande :
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
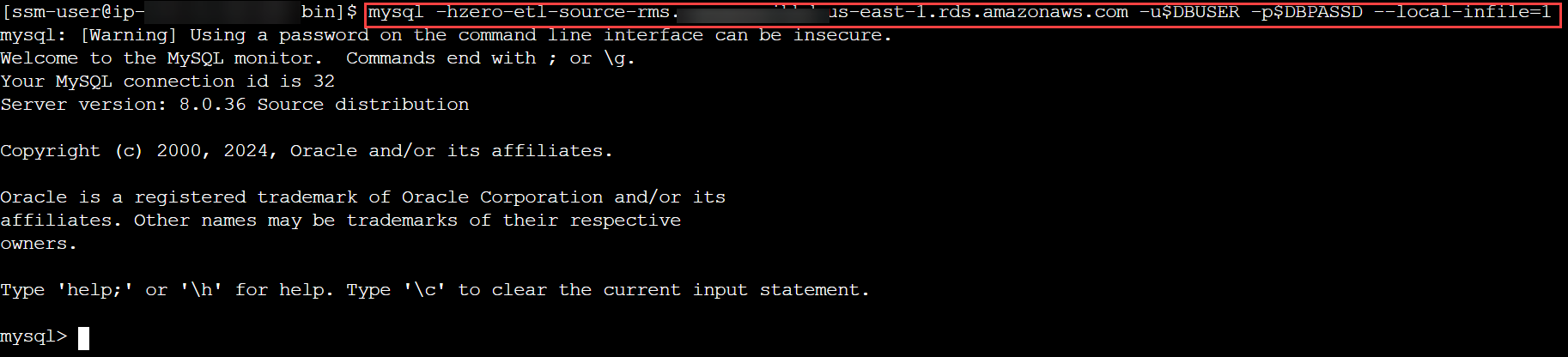
- Connectez-vous à votre cluster RDS pour MySQL et créez une base de données ou un schéma pour le modèle de données TICKIT, vérifiez que les tables de ce schéma ont une clé primaire et lancez le processus de chargement :
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Utilisez le suivant Commandes CRÉER TABLE.
- Chargez les données à partir de fichiers locaux à l'aide de la commande LOAD DATA.
Ce qui suit est un exemple. Notez que le fichier CSV d'entrée est divisé en plusieurs fichiers. Cette commande doit être exécutée pour chaque fichier si vous souhaitez charger toutes les données. À des fins de démonstration, un chargement partiel de données devrait également fonctionner.

Analyser les données TICKIT source dans la destination
Sur la console Amazon Redshift, ouvrez l'éditeur de requêtes v2 à l'aide de la base de données que vous avez créée dans le cadre de la configuration de l'intégration. Utilisez le code suivant pour valider l’activité seed ou CDC :

Vous pouvez désormais appliquer votre logique métier pour les transformations directement sur les données qui ont été répliquées dans l'entrepôt de données. Vous pouvez également utiliser des techniques d'optimisation des performances, telles que la création d'une vue matérialisée Redshift qui joint les tables répliquées et d'autres tables locales pour améliorer les performances de vos requêtes analytiques.
Le Monitoring
Vous pouvez interroger les vues système et les tables suivantes dans Amazon Redshift pour obtenir des informations sur vos intégrations zéro ETL avec Amazon Redshift :
Pour afficher les métriques liées à l'intégration publiées sur Amazon Cloud Watch, ouvrez la console Amazon Redshift. Choisir Intégrations sans ETL dans le volet de navigation et choisissez l’intégration pour afficher les métriques d’activité.
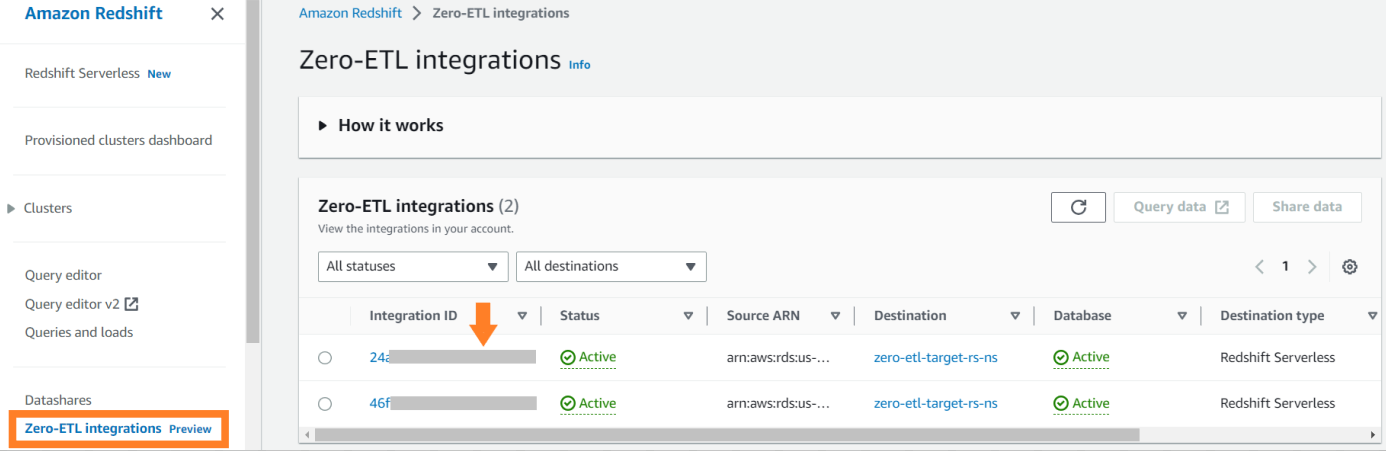
Les métriques disponibles sur la console Amazon Redshift sont des métriques d'intégration et des statistiques de table, les statistiques de table fournissant des détails sur chaque table répliquée d'Amazon RDS for MySQL vers Amazon Redshift.

Les métriques d'intégration contiennent le nombre de réussites et d'échecs de la réplication de table ainsi que les détails du décalage.
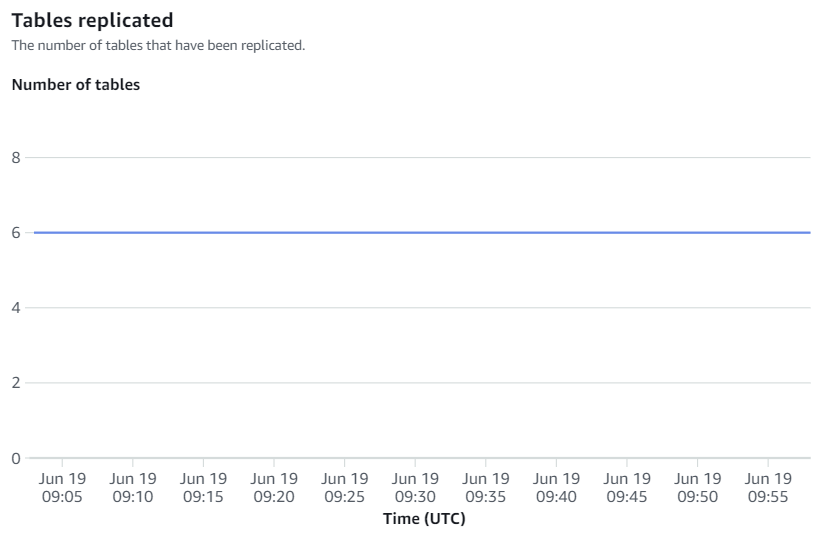
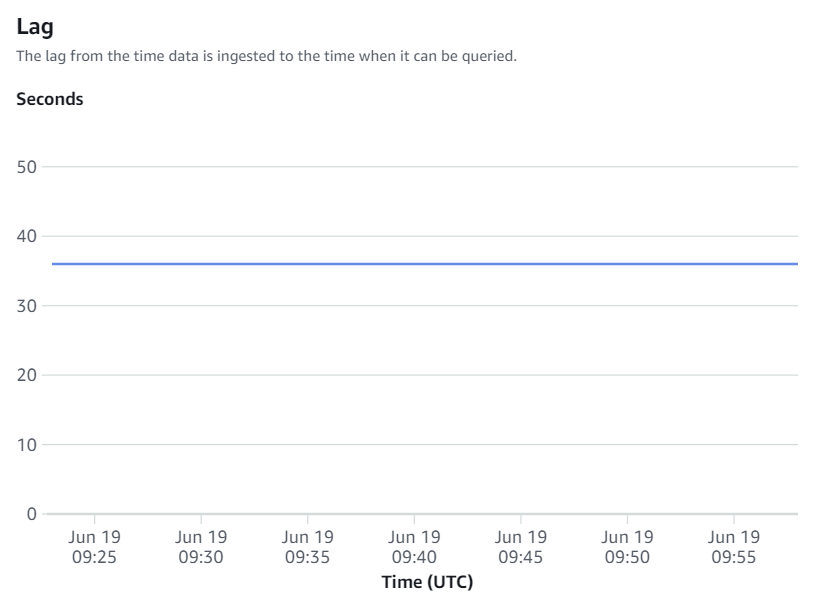
Resynchronisations manuelles
L'intégration zéro ETL lancera automatiquement une resynchronisation si l'état de synchronisation d'une table indique un échec ou une resynchronisation requise. Mais en cas d'échec de la resynchronisation automatique, vous pouvez lancer une resynchronisation avec une granularité au niveau de la table :
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
Une table peut entrer dans un état d'échec pour plusieurs raisons :
- La clé primaire a été supprimée de la table. Dans de tels cas, vous devez rajouter la clé primaire et exécuter la commande ALTER mentionnée précédemment.
- Une valeur non valide est rencontrée lors de la réplication ou une nouvelle colonne est ajoutée à la table avec un type de données non pris en charge. Dans de tels cas, vous devez supprimer la colonne avec le type de données non pris en charge et exécuter la commande ALTER mentionnée précédemment.
- Dans de rares cas, une erreur interne peut entraîner un échec de la table. La commande ALTER devrait résoudre le problème.
Nettoyer
Lorsque vous supprimez une intégration zéro ETL, vos données transactionnelles ne sont pas supprimées des bases de données RDS source ou Redshift cible, mais Amazon RDS n'envoie aucune nouvelle modification à Amazon Redshift.
Pour supprimer une intégration sans ETL, procédez comme suit :
- Sur la console Amazon RDS, choisissez Intégrations sans ETL dans le volet de navigation.
- Sélectionnez l'intégration zéro-ETL que vous souhaitez supprimer et choisissez Supprimer.
- Pour confirmer la suppression, choisissez Supprimer.

Conclusion
Dans cet article, nous vous avons montré comment configurer une intégration zéro ETL d'Amazon RDS pour MySQL vers Amazon Redshift. Cela minimise le besoin de maintenir des pipelines de données complexes et permet des analyses en temps quasi réel sur les données transactionnelles et opérationnelles.
Pour en savoir plus sur l'intégration d'Amazon RDS zéro ETL avec Amazon Redshift, reportez-vous à Utilisation des intégrations Amazon RDS zéro ETL avec Amazon Redshift (préversion).
À propos des auteurs
 Milind Oké est un architecte de solutions spécialisé chez Redshift qui travaille chez Amazon Web Services depuis trois ans. Il est titulaire des certifications SA Associate, Security Specialty et Analytics Specialty certifiées AWS, basé dans le Queens, New York.
Milind Oké est un architecte de solutions spécialisé chez Redshift qui travaille chez Amazon Web Services depuis trois ans. Il est titulaire des certifications SA Associate, Security Specialty et Analytics Specialty certifiées AWS, basé dans le Queens, New York.
 Aditya Samant est un vétéran du secteur des bases de données relationnelles avec plus de 2 ans d'expérience dans le domaine des bases de données commerciales et open source. Il travaille actuellement chez Amazon Web Services en tant qu'architecte principal de solutions spécialisées en bases de données. Dans le cadre de son rôle, il passe du temps à travailler avec des clients pour concevoir des architectures cloud natives évolutives, sécurisées et robustes. Aditya travaille en étroite collaboration avec les équipes de service et collabore à la conception et à la livraison des nouvelles fonctionnalités pour les bases de données gérées par Amazon.
Aditya Samant est un vétéran du secteur des bases de données relationnelles avec plus de 2 ans d'expérience dans le domaine des bases de données commerciales et open source. Il travaille actuellement chez Amazon Web Services en tant qu'architecte principal de solutions spécialisées en bases de données. Dans le cadre de son rôle, il passe du temps à travailler avec des clients pour concevoir des architectures cloud natives évolutives, sécurisées et robustes. Aditya travaille en étroite collaboration avec les équipes de service et collabore à la conception et à la livraison des nouvelles fonctionnalités pour les bases de données gérées par Amazon.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

