Partie 1 de cette série en deux parties décrit comment créer un service de pseudonymisation qui convertit les attributs de données en texte brut en pseudonyme ou vice versa. Un service de pseudonymisation centralisé fournit une architecture unique et universellement reconnue pour générer des pseudonymes. Par conséquent, une organisation peut mettre en place un processus standard pour gérer les données sensibles sur toutes les plateformes. De plus, cela élimine toute complexité et expertise nécessaires pour comprendre et mettre en œuvre diverses exigences de conformité aux équipes de développement et aux utilisateurs analytiques, leur permettant ainsi de se concentrer sur leurs résultats commerciaux.
Suivre une approche découplée basée sur les services signifie qu'en tant qu'organisation, vous êtes impartial quant à l'utilisation de technologies spécifiques pour résoudre vos problèmes commerciaux. Quelle que soit la technologie préférée des équipes individuelles, elles peuvent faire appel au service de pseudonymisation pour pseudonymiser les données sensibles.
Dans cet article, nous nous concentrons sur les modèles de consommation courants d’extraction, de transformation et de chargement (ETL) qui peuvent utiliser le service de pseudonymisation. Nous expliquons comment utiliser le service de pseudonymisation dans vos tâches ETL sur Amazon DME (À L'Aide De Amazon EMR sur EC2) pour les cas d'utilisation en streaming et par lots. De plus, vous pouvez trouver un Amazone Athéna ainsi que Colle AWS modèle de consommation basé sur GitHub repo de la solution.
Vue d'ensemble de la solution
Le diagramme suivant décrit l'architecture de la solution.

Le compte de droite héberge le service de pseudonymisation, que vous pouvez déployer à l'aide des instructions fournies dans la première partie de cette série.
Le compte de gauche est celui que vous avez créé dans le cadre de cet article, représentant la plateforme ETL basée sur Amazon EMR utilisant le service de pseudonymisation.
Vous pouvez déployer le service de pseudonymisation et la plateforme ETL sur le même compte.
Amazon EMR vous permet de créer, d'exploiter et de faire évoluer des infrastructures Big Data telles qu'Apache Spark de manière rapide et rentable.
Dans cette solution, nous montrons comment utiliser le service de pseudonymisation sur Amazon DME comprenant Apache Spark pour les cas d’utilisation par lots et en streaming. L'application par lots lit les données d'un Service de stockage simple Amazon (Amazon S3), et l'application de streaming consomme les enregistrements de Flux de données Amazon Kinesis.
Code PySpark utilisé dans les tâches par lots et en streaming
Les deux applications utilisent une fonction utilitaire commune qui effectue des appels HTTP POST sur la passerelle API liée à la pseudonymisation. AWS Lambda fonction. Les appels d'API REST sont effectués par partition Spark à l'aide du Spark RDD mapPartitions fonction. Le corps de la requête POST contient la liste des valeurs uniques pour une colonne d'entrée donnée. La réponse à la requête POST contient les valeurs pseudonymisées correspondantes. Le code échange les valeurs sensibles avec celles pseudonymisées pour un ensemble de données donné. Le résultat est enregistré sur Amazon S3 et le Colle AWS Catalogue de données, utilisant Apache Iceberg format de tableau.
Iceberg est un format de table ouverte qui prend en charge les transactions ACID, l'évolution des schémas et les requêtes de voyage dans le temps. Vous pouvez utiliser ces fonctionnalités pour implémenter le droit à l'oubli (ou d'effacement de données) utilisant des instructions SQL ou des interfaces de programmation. Iceberg est pris en charge par Amazon EMR à partir de la version 6.5.0, AWS Glue et Athena. Les modèles de lots et de streaming utilisent Iceberg comme format cible. Pour un aperçu de la façon de créer un lac de données conforme à ACID à l'aide d'Iceberg, reportez-vous à Créez un lac de données évolutif hautes performances conforme à ACID à l'aide d'Apache Iceberg sur Amazon EMR.
Pré-requis
Vous devez avoir les prérequis suivants :
- An Compte AWS.
- An Gestion des identités et des accès AWS (IAM) principal avec des privilèges pour déployer le AWS CloudFormation pile et ressources associées.
- La Interface de ligne de commande AWS (AWS CLI) installé sur la machine de développement ou de déploiement que vous utiliserez pour exécuter les scripts fournis.
- Un compartiment S3 dans le même compte et la même région AWS où la solution doit être déployée.
- Python3 installé sur la machine locale sur laquelle les commandes sont exécutées.
- PyYAML installé à l'aide pépin.
- Un terminal bash pour exécuter des scripts bash qui déploient des piles CloudFormation.
- Un compartiment S3 supplémentaire contenant l'ensemble de données d'entrée dans des fichiers Parquet (uniquement pour les applications par lots). Copiez le exemple de jeu de données au compartiment S3.
- Une copie du dernier référentiel de code sur la machine locale en utilisant
git cloneou l'option de téléchargement.
Ouvrez un nouveau terminal bash et accédez au dossier racine du référentiel cloné.
Le code source des modèles proposés se trouve dans le référentiel cloné. Il utilise les paramètres suivants :
- ARTEFACT_S3_BUCKET – Le bucket S3 où sera stocké le code de l’infrastructure. Le compartiment doit être créé dans le même compte et la même région où se trouve la solution.
- AWS_REGION – La Région où la solution sera déployée.
- AWS_PROFILE – Le profil nommé qui sera appliqué au Commande AWS CLI. Celui-ci doit contenir les informations d'identification d'un principal IAM disposant de privilèges pour déployer la pile CloudFormation de ressources associées.
- SUBNET_ID – L'ID du sous-réseau sur lequel le cluster EMR sera lancé. Le sous-réseau est préexistant et à des fins de démonstration, nous utilisons l'ID de sous-réseau par défaut du VPC par défaut.
- EP_URL – L'URL du point de terminaison du service de pseudonymisation. Récupérez-le à partir de la solution déployée en tant que Partie 1 de cette série.
- API_SECRET - Un Passerelle d'API Amazon key qui sera stocké dans AWS Secrets Manager. La clé API est générée à partir du déploiement décrit dans Partie 1 de cette série.
- S3_INPUT_PATH – L'URI S3 pointant vers le dossier contenant l'ensemble de données d'entrée sous forme de fichiers Parquet.
- KINESIS_DATA_STREAM_NAME - Nom du flux de données Kinesis déployé avec la pile CloudFormation.
- TAILLE DU LOT - Nombre d'enregistrements à transmettre au flux de données par lot.
- THREADS_NUM - Nombre de threads parallèles utilisés sur la machine locale pour télécharger des données vers le flux de données. Plus de fils de discussion correspondent à un volume de messages plus élevé.
- EMR_CLUSTER_ID – L'ID du cluster EMR où le code sera exécuté (le cluster EMR a été créé par la pile CloudFormation).
- STACK_NAME – Le nom de la pile CloudFormation, qui est attribué dans le script de déploiement.
Étapes de déploiement par lots
Comme décrit dans les prérequis, avant de déployer la solution, téléchargez les fichiers Parquet du ensemble de données de test vers Amazon S3. Fournissez ensuite le chemin S3 du dossier contenant les fichiers en paramètre <S3_INPUT_PATH>.
Nous créons les ressources de la solution via AWS CloudFormation. Vous pouvez déployer la solution en exécutant le déployer_1.sh script, qui se trouve à l'intérieur du deployment_scripts dossier.
Une fois les conditions préalables au déploiement remplies, entrez la commande suivante pour déployer la solution :
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>Le résultat devrait ressembler à la capture d’écran suivante.

Les paramètres requis pour la commande de nettoyage sont imprimés à la fin de l'exécution du deploy_1.sh scénario. Assurez-vous de noter ces valeurs.
Testez la solution batch
Dans le modèle CloudFormation déployé à l'aide de deploy_1.sh script, l'étape EMR contenant le Application par lots Spark est ajouté à la fin de la configuration du cluster EMR.
Pour vérifier les résultats, vérifiez le compartiment S3 identifié dans les sorties de la pile CloudFormation avec la variable SparkOutputLocation.

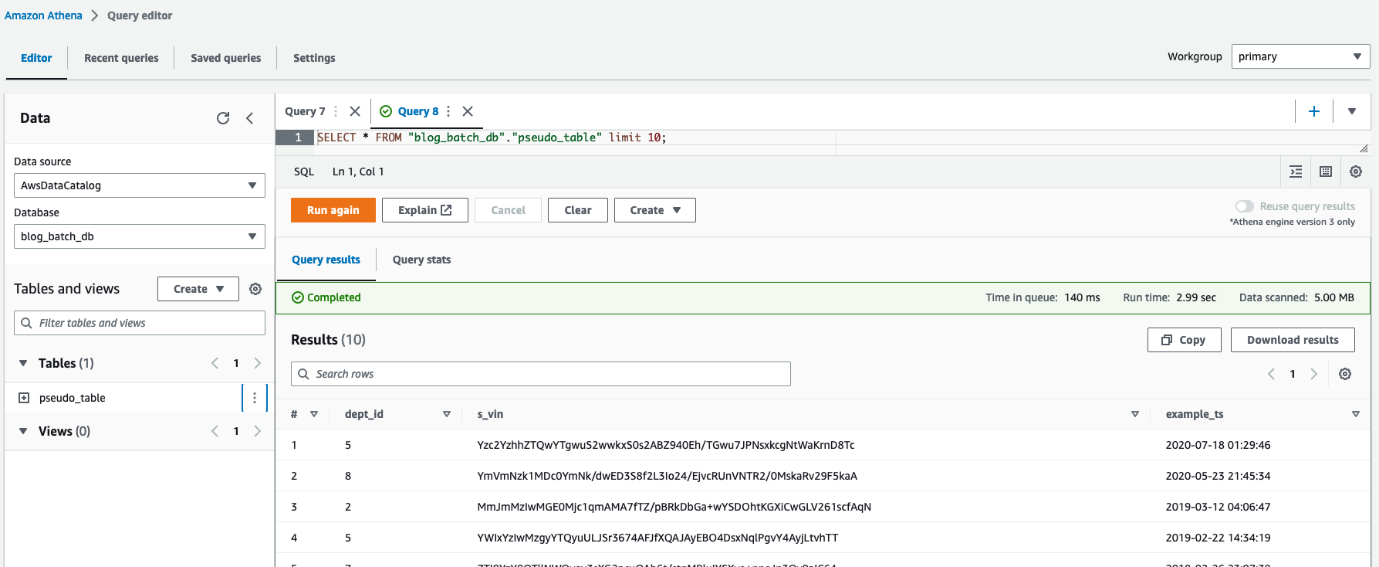
Vous pouvez également utiliser Athéna pour interroger la table pseudo_table dans la base de données blog_batch_db.
Nettoyer les ressources par lots
Pour détruire les ressources créées dans le cadre de cet exercice,
dans un terminal bash, accédez au dossier racine du référentiel cloné. Entrez la commande de nettoyage affichée comme sortie de l'exécution précédente déployer_1.sh script:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Le résultat devrait ressembler à la capture d’écran suivante.

Étapes de déploiement du streaming
Nous créons les ressources de la solution via AWS CloudFormation. Vous pouvez déployer la solution en exécutant le déployer_2.sh script, qui se trouve à l'intérieur du deployment_scripts dossier. Le modèle de pile CloudFormation pour ce modèle est disponible dans le GitHub repo.
Une fois les conditions préalables au déploiement remplies, entrez la commande suivante pour déployer la solution :
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>Le résultat devrait ressembler à la capture d’écran suivante.
Les paramètres requis pour la commande de nettoyage sont imprimés à la fin de la sortie du déployer_2.sh scénario. Assurez-vous de sauvegarder ces valeurs pour les utiliser plus tard.
Testez la solution de streaming
Dans le modèle CloudFormation déployé à l'aide de deploy_2.sh script, l'étape EMR contenant le Application de diffusion en continu Spark est ajouté à la fin de la configuration du cluster EMR. Pour tester le pipeline de bout en bout, vous devez transférer les enregistrements vers le flux de données Kinesis déployé. Avec les commandes suivantes dans un terminal bash, vous pouvez activer un producteur Kinesis qui placera en permanence les enregistrements dans le flux, jusqu'à ce que le processus soit arrêté manuellement. Vous pouvez contrôler le volume des messages du producteur en modifiant le BATCH_SIZE et par THREADS_NUM variables.


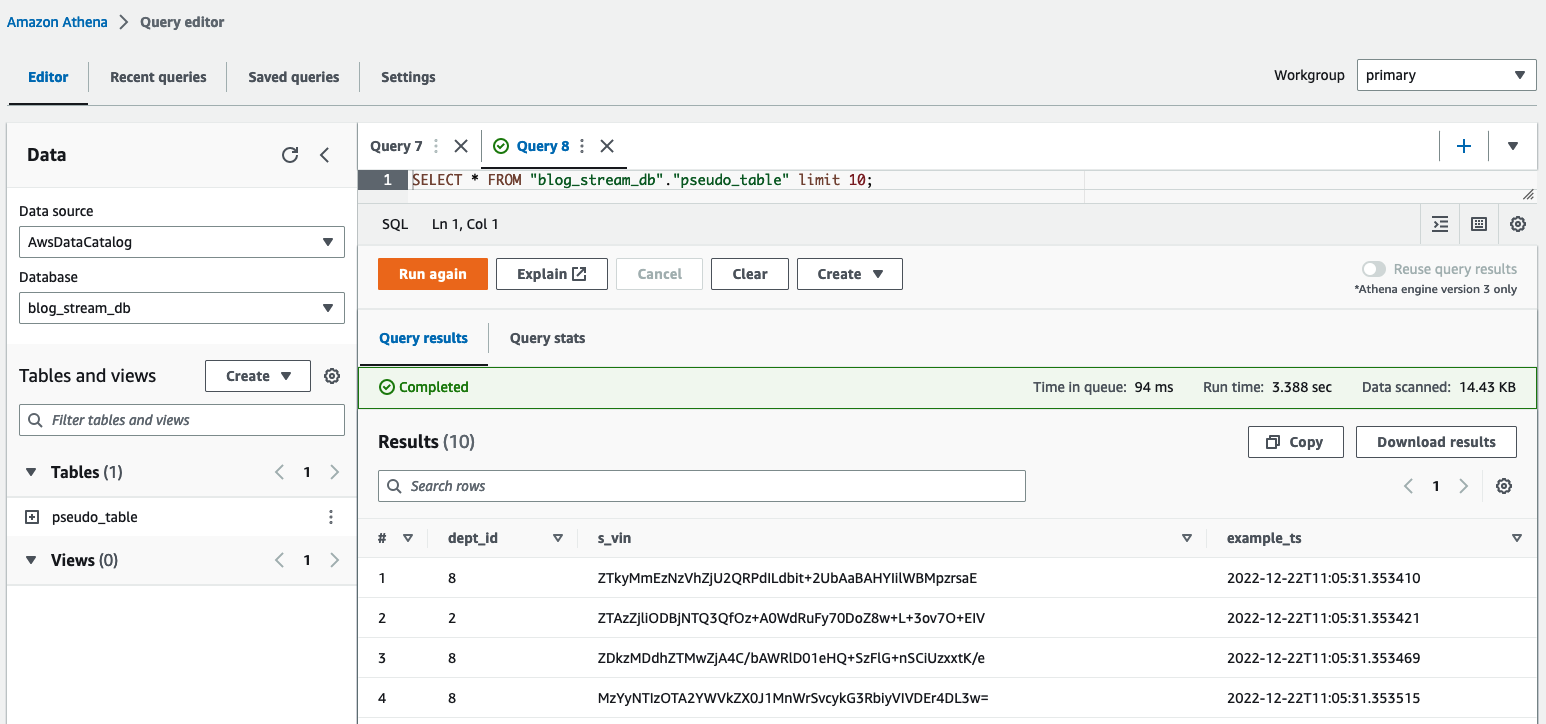
Dans l'éditeur de requêtes Athena, vérifiez les résultats en interrogeant le table pseudo_table dans la base de données blog_stream_db.
Nettoyer les ressources de streaming
Pour détruire les ressources créées dans le cadre de cet exercice, procédez comme suit :
- Arrêtez le producteur Python Kinesis qui a été lancé dans un terminal bash dans la section précédente.
- Entrez la commande suivante:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Le résultat devrait ressembler à la capture d’écran suivante.

Détails des performances
Les cas d'utilisation peuvent différer en termes d'exigences en termes de taille des données, de capacité de calcul et de coût. Nous avons fourni des analyses comparatives et des facteurs susceptibles d'influencer les performances ; cependant, nous vous conseillons fortement de valider la solution dans des environnements inférieurs pour voir si elle répond à vos exigences particulières.
Vous pouvez influencer les performances de la solution proposée (qui vise à pseudonymiser un ensemble de données à l'aide d'Amazon EMR) par le nombre maximum d'appels parallèles au service de pseudonymisation et la taille de la charge utile pour chaque appel. En termes d'appels parallèles, les facteurs à considérer sont le Limite d'appels GetSecretValue à partir de Secrets Manager (10.000 1,000 par seconde, limite stricte) et le parallélisme de concurrence par défaut Lambda (XNUMX XNUMX par défaut ; peut être augmenté par demande de quota). Vous pouvez contrôler le parallélisme maximum en ajustant le nombre d'exécuteurs, le nombre de partitions composant l'ensemble de données et la configuration du cluster (nombre et type de nœuds). En termes de taille de charge utile pour chaque appel, les facteurs à prendre en compte sont les suivants : Taille maximale de la charge utile d'API Gateway (6 Mo) et la durée d'exécution maximale de la fonction Lambda (15 minutes). Vous pouvez contrôler la taille de la charge utile et le temps d'exécution de la fonction Lambda en ajustant la valeur de la taille du lot, qui est un paramètre du script PySpark qui détermine le nombre d'éléments à pseudonymiser pour chaque appel d'API. Pour capturer l'influence de tous ces facteurs et évaluer les performances des modèles de consommation à l'aide d'Amazon EMR, nous avons conçu et surveillé les scénarios suivants.
Performances du modèle de consommation par lots
Pour évaluer les performances du modèle de consommation par lots, nous avons exécuté l'application de pseudonymisation avec trois ensembles de données d'entrée composés de 1, 10 et 100 fichiers Parquet de 97.7 Mo chacun. Nous avons généré les fichiers d'entrée en utilisant le dataset_generator.py scripts.
Les nœuds de capacité du cluster étaient de 1 principal (m5.4xlarge) et de 15 cœurs (m5d.8xlarge). Cette configuration de cluster est restée la même pour les trois scénarios et a permis à l'application Spark d'utiliser jusqu'à 100 exécuteurs. Le batch_size, qui était également le même pour les trois scénarios, était défini sur 900 VIN par appel d'API, et la taille maximale du VIN était de 5 octets.
Le tableau suivant capture les informations des trois scénarios.
| ID d'exécution | Répartition | Taille de l'ensemble de données | Nombre d'exécuteurs | Cœurs par exécuteur | Mémoire de l'exécuteur | Runtime |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11 minutes, 10 secondes |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8 minutes, 36 secondes |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7 minutes, 56 secondes |
Comme nous pouvons le constater, bien paralléliser les appels à notre service de pseudonymisation nous permet de contrôler le temps d'exécution global.
Dans les exemples suivants, nous analysons trois métriques Lambda importantes pour le service de pseudonymisation : Invocations, ConcurrentExecutionset Duration.
Le graphique suivant illustre le Invocations métrique, avec la statistique SUM en orange et RUNNING SUM en bleu.

En calculant la différence entre le point de début et le point de fin des appels cumulés, nous pouvons extraire le nombre d'appels effectués au cours de chaque exécution.
| ID d'exécution | Taille de l'ensemble de données | Nombre total d'appels |
| A | 9.53 GB | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 - 1.631.000 = 14.500 |
Comme prévu, le nombre d'invocations augmente proportionnellement de 10 avec la taille de l'ensemble de données.
Le graphique suivant représente le total ConcurrentExecutions métrique, avec la statistique MAX en bleu.
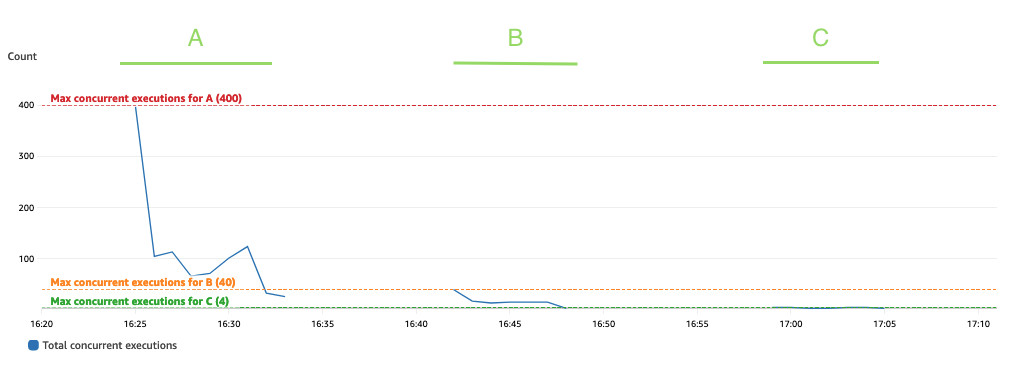
L'application est conçue de telle sorte que le nombre maximum d'exécutions simultanées de fonctions Lambda dépend du nombre de tâches Spark (partitions de l'ensemble de données Spark) qui peuvent être traitées en parallèle. Ce nombre peut être calculé comme MIN (exécuteurs testamentaires x executor_cores, Partitions de l'ensemble de données Spark).
Dans le test, exécutez A traité 800 partitions, en utilisant 100 exécuteurs dotés de quatre cœurs chacun. Cela fait 400 tâches traitées en parallèle, de sorte que les exécutions simultanées de la fonction Lambda ne peuvent pas être supérieures à 400. La même logique a été appliquée pour les exécutions B et C. Nous pouvons voir cela reflété dans le graphique précédent, où le nombre d'exécutions simultanées ne dépasse jamais le nombre d'exécutions simultanées. 400, 40 et 4 valeurs.
Pour éviter toute limitation, assurez-vous que le nombre de tâches Spark pouvant être traitées en parallèle ne dépasse pas la limite de simultanéité de la fonction Lambda. Si tel est le cas, vous devez soit augmenter la limite de simultanéité de la fonction Lambda (si vous souhaitez maintenir les performances), soit réduire le nombre de partitions ou le nombre d'exécuteurs disponibles (ce qui a un impact sur les performances de l'application).
Le graphique suivant représente le Lambda Duration métrique, avec la statistique AVG en orange et MAX en vert.
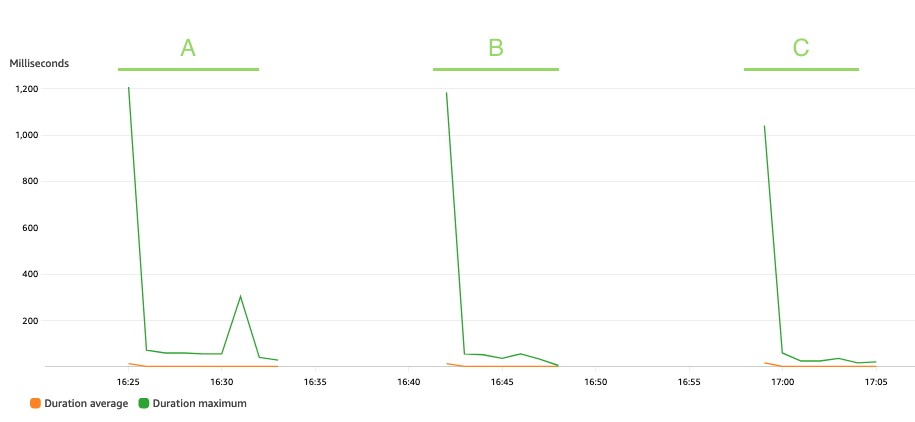
Comme prévu, la taille de l'ensemble de données n'affecte pas la durée d'exécution de la fonction de pseudonymisation, qui, hormis quelques invocations initiales confrontées à des démarrages à froid, reste constante à une moyenne de 3 millisecondes tout au long des trois scénarios. En effet, le nombre maximum d'enregistrements inclus dans chaque appel de pseudonymisation est constant (batch_size valeur).
Lambda est facturé en fonction du nombre d'appels et du temps nécessaire à l'exécution de votre code (durée). Vous pouvez utiliser les mesures de durée moyenne et d’appels pour estimer le coût du service de pseudonymisation.
Performances du modèle de consommation de streaming
Pour évaluer les performances du modèle de consommation de streaming, nous avons exécuté la producteur.py , qui définit un producteur de données Kinesis qui transmet les enregistrements par lots au flux de données Kinesis.
L'application de streaming a été laissée en marche pendant 15 minutes et elle a été configurée avec un batch_interval de 1 minute, qui est l'intervalle de temps pendant lequel les données diffusées en continu seront divisées en lots. Le tableau suivant résume les facteurs pertinents.
| Répartition | Nœuds de capacité de cluster | Nombre d'exécuteurs | Mémoire de l'exécuteur | Fenêtre de lot | Taille du lot | Taille du NIV |
| 17 |
1 Primaire (m5.xlarge), 3 cœurs (m5.2xlarge) |
6 | 9 GiB | en 60 secondes | 900 VIN/appel API. | 5 octets/VIN |
Les graphiques suivants illustrent les métriques Kinesis Data Streams PutRecords (en bleu) et GetRecords (en orange) agrégé avec une période de 1 minute et utilisant la statistique SUM. Le premier graphique montre la métrique en octets, qui culmine à 6.8 Mo par minute. Le deuxième graphique montre la mesure du nombre d’enregistrements culminant à 85,000 XNUMX enregistrements par minute.
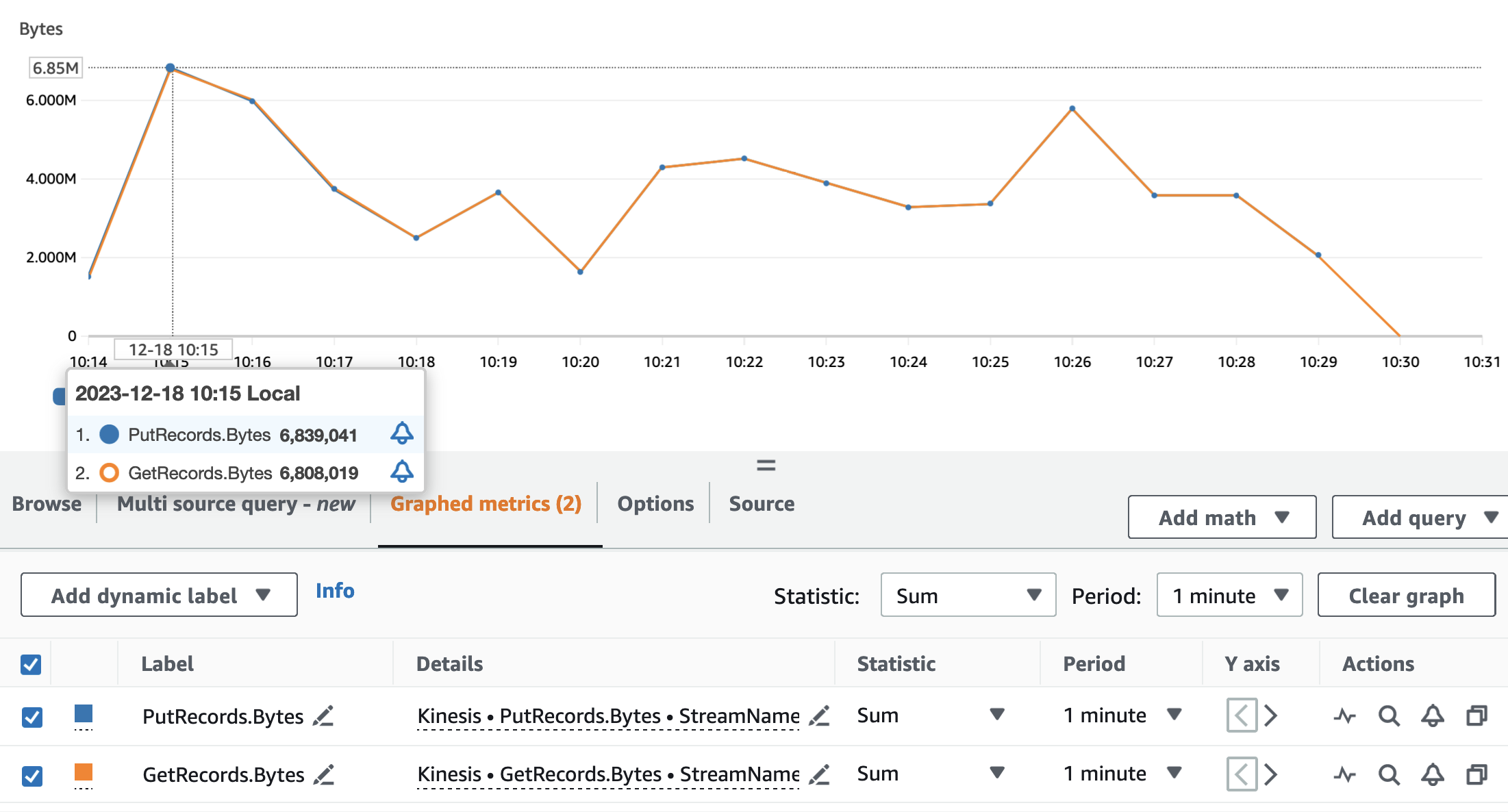

Nous pouvons voir que les métriques GetRecords ainsi que PutRecords ont des valeurs qui se chevauchent pour presque toute l'exécution de l'application. Cela signifie que l’application de streaming a pu suivre la charge du flux.
Ensuite, nous analysons les métriques Lambda pertinentes pour le service de pseudonymisation : Invocations, ConcurrentExecutionset Duration.
Le graphique suivant illustre le Invocations métrique, avec la statistique SUM (en orange) et RUNNING SUM en bleu.
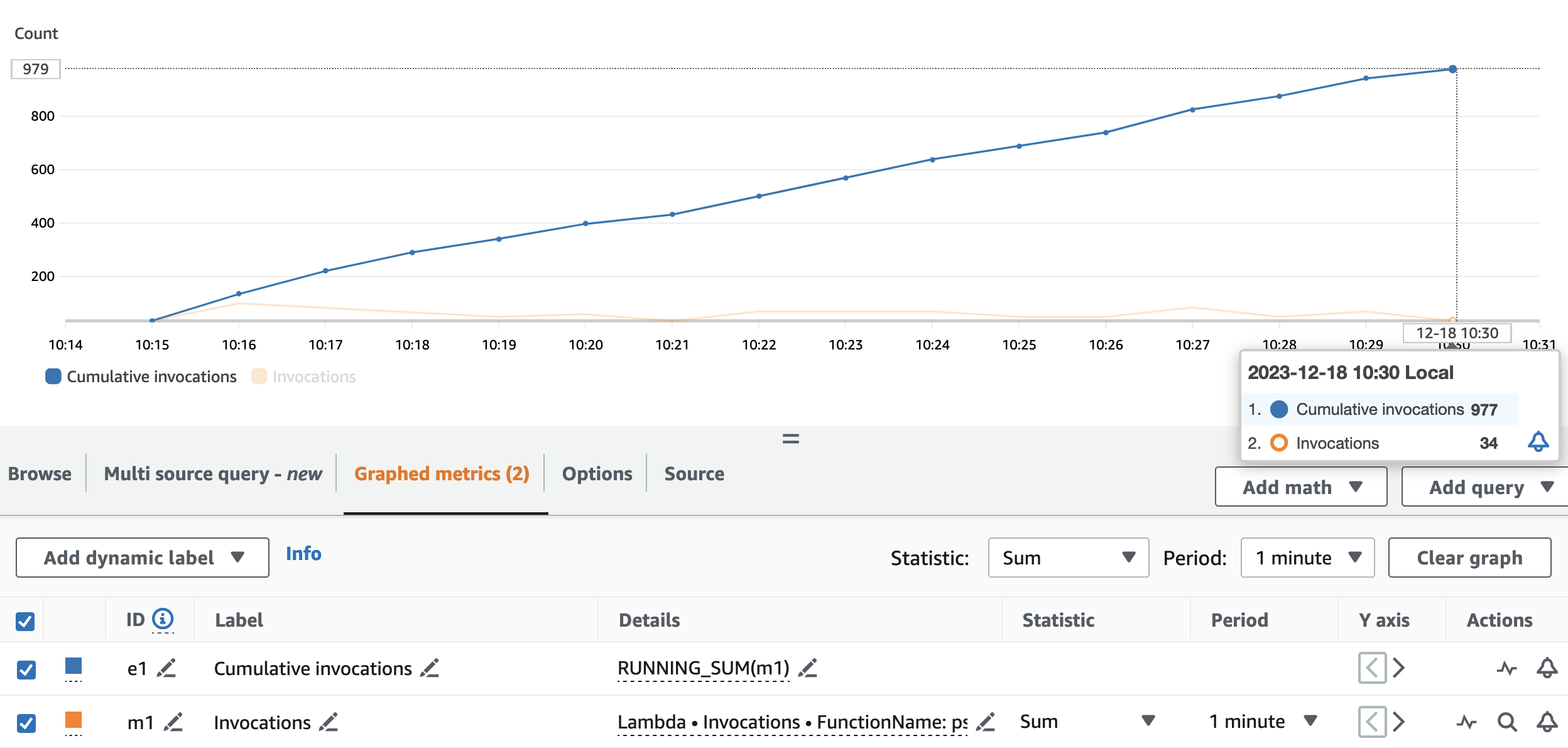
En calculant la différence entre le point de début et le point de fin des appels cumulés, nous pouvons extraire le nombre d'appels effectués pendant l'exécution. Concrètement, en 15 minutes, l'application de streaming a invoqué l'API de pseudonymisation 977 fois, soit environ 65 appels par minute.
Le graphique suivant représente le total ConcurrentExecutions métrique, avec la statistique MAX en bleu.
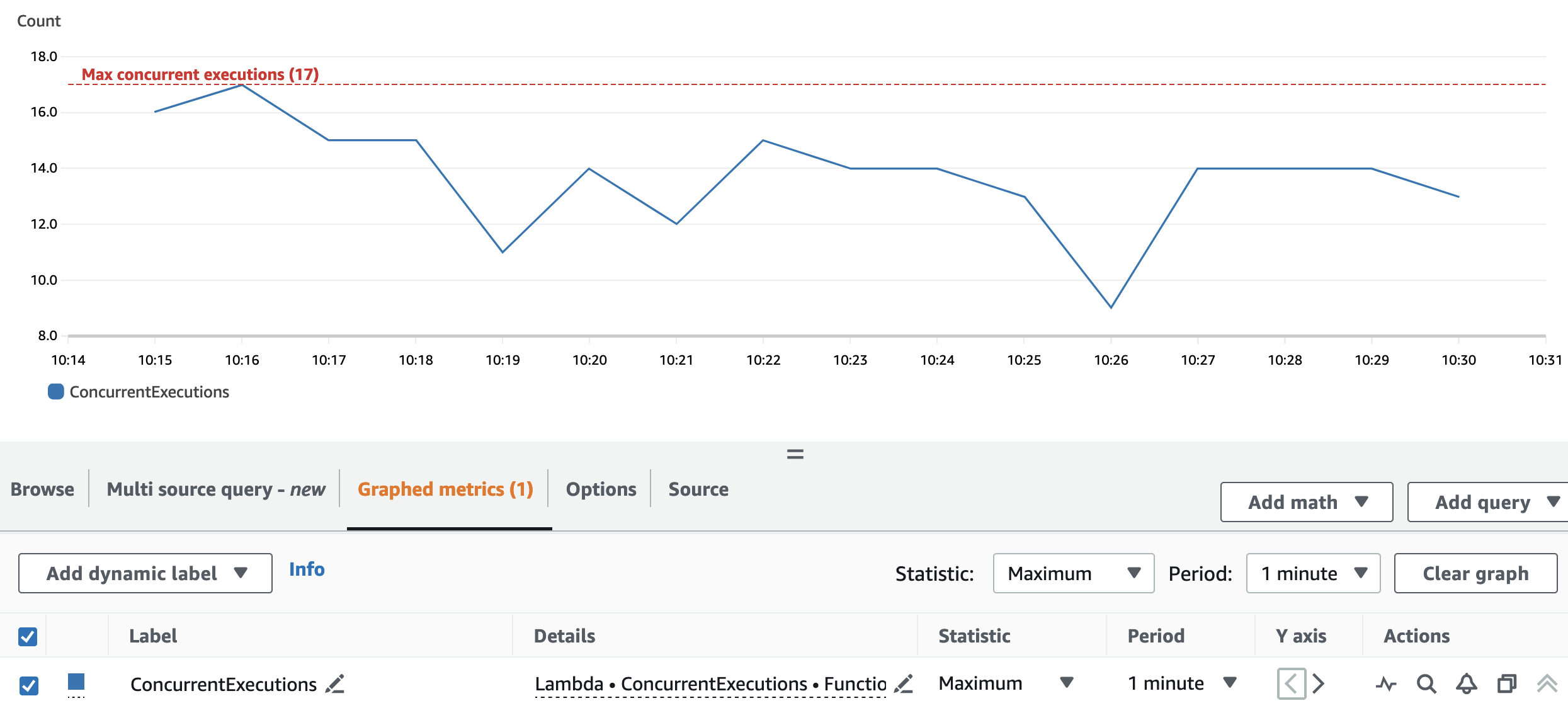
La répartition et la configuration du cluster permettent à l'application de traiter toutes les partitions Spark RDD en parallèle. Par conséquent, les exécutions simultanées de la fonction Lambda sont toujours égales ou inférieures au numéro de répartition, qui est 17.
Pour éviter toute limitation, assurez-vous que le nombre de tâches Spark pouvant être traitées en parallèle ne dépasse pas la limite de simultanéité de la fonction Lambda. Pour cet aspect, les mêmes suggestions que pour le cas d’utilisation batch sont valables.
Le graphique suivant représente le Lambda Duration métrique, avec la statistique AVG en bleu et MAX en orange.
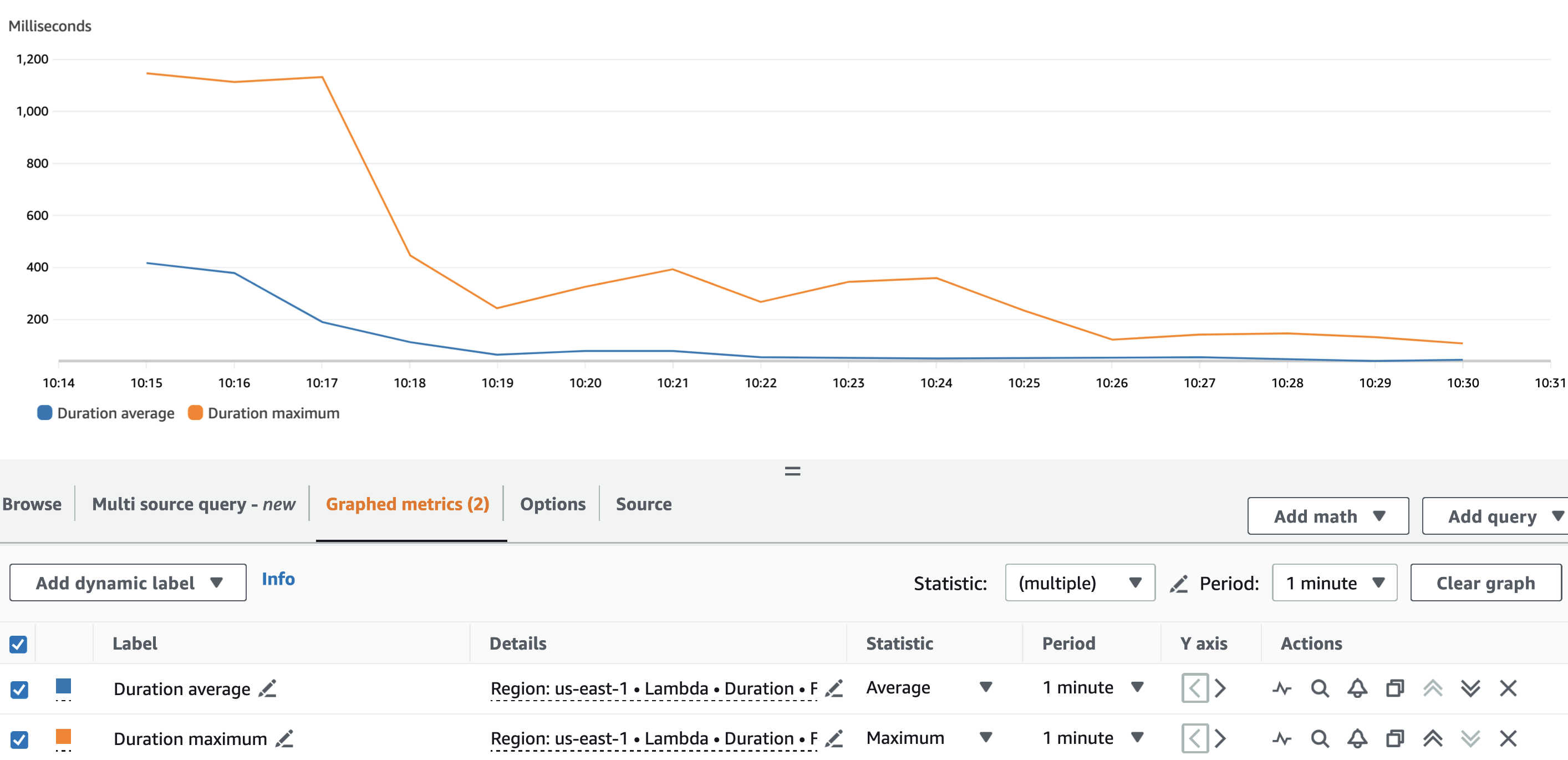
Comme prévu, mis à part le démarrage à froid de la fonction Lambda, la durée moyenne de la fonction de pseudonymisation était plus ou moins constante tout au long de l'exécution. Ceci parce que le batch_size La valeur, qui définit le nombre de VIN à pseudonymiser par appel, a été fixée et est restée constante à 900.
Le taux d'ingestion du flux de données Kinesis et le taux de consommation de notre application de streaming sont des facteurs qui influencent le nombre d'appels API effectués vers le service de pseudonymisation et donc le coût associé.
Le graphique suivant représente le Lambda Invocations métrique, avec la statistique SUM en orange et les flux de données Kinesis GetRecords.Records métrique, avec la statistique SUM en bleu. Nous pouvons voir qu'il existe une corrélation entre la quantité d'enregistrements récupérés du flux par minute et le nombre d'appels de fonctions Lambda, ce qui a un impact sur le coût de l'exécution du streaming.

En plus de la batch_interval, nous pouvons contrôler le taux de consommation de l'application de streaming en utilisant Propriétés du streaming Spark comme spark.streaming.receiver.maxRate ainsi que spark.streaming.blockInterval. Pour plus de détails, reportez-vous à Intégration Spark Streaming + Kinesis ainsi que Guide de programmation du streaming Spark.
Conclusion
Naviguer dans les règles et réglementations des lois sur la confidentialité des données peut être difficile. La pseudonymisation des attributs PII est l’un des nombreux points à prendre en compte lors du traitement des données sensibles.
Dans cette série en deux parties, nous avons exploré comment vous pouvez créer et utiliser un service de pseudonymisation à l'aide de divers services AWS dotés de fonctionnalités pour vous aider à créer une plate-forme de données robuste. Dans Partie 1, nous avons jeté les bases en montrant comment créer un service de pseudonymisation. Dans cet article, nous avons présenté les différents modèles permettant d'utiliser le service de pseudonymisation de manière rentable et performante. Vérifiez GitHub référentiel de modes de consommation supplémentaires.
À propos des auteurs
 Edvin Hallvaxhiu est architecte senior en sécurité mondiale chez AWS Professional Services et passionné par la cybersécurité et l'automatisation. Il aide les clients à créer des solutions sécurisées et conformes dans le cloud. En dehors du travail, il aime voyager et faire du sport.
Edvin Hallvaxhiu est architecte senior en sécurité mondiale chez AWS Professional Services et passionné par la cybersécurité et l'automatisation. Il aide les clients à créer des solutions sécurisées et conformes dans le cloud. En dehors du travail, il aime voyager et faire du sport.
 Rahul Shaurya est architecte principal Big Data chez AWS Professional Services. Il aide et travaille en étroite collaboration avec les clients qui créent des plateformes de données et des applications analytiques sur AWS. En dehors du travail, Rahul adore faire de longues promenades avec son chien Barney.
Rahul Shaurya est architecte principal Big Data chez AWS Professional Services. Il aide et travaille en étroite collaboration avec les clients qui créent des plateformes de données et des applications analytiques sur AWS. En dehors du travail, Rahul adore faire de longues promenades avec son chien Barney.
 Andréa Montanari est un architecte Big Data senior chez AWS Professional Services. Il soutient activement les clients et les partenaires dans la création de solutions d'analyse à grande échelle sur AWS.
Andréa Montanari est un architecte Big Data senior chez AWS Professional Services. Il soutient activement les clients et les partenaires dans la création de solutions d'analyse à grande échelle sur AWS.
 Maria Guerra est un architecte Big Data avec AWS Professional Services. Maria a une formation en analyse de données et en génie mécanique. Elle aide les clients à concevoir et à développer des charges de travail liées aux données dans le cloud.
Maria Guerra est un architecte Big Data avec AWS Professional Services. Maria a une formation en analyse de données et en génie mécanique. Elle aide les clients à concevoir et à développer des charges de travail liées aux données dans le cloud.
 Pushpraj Sing est un architecte de données senior chez AWS Professional Services. Il est passionné par l'ingénierie Data et DevOps. Il aide les clients à créer des applications basées sur les données à grande échelle.
Pushpraj Sing est un architecte de données senior chez AWS Professional Services. Il est passionné par l'ingénierie Data et DevOps. Il aide les clients à créer des applications basées sur les données à grande échelle.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

