Pour créer une application d’IA générative, il est impératif d’enrichir les grands modèles de langage (LLM) avec de nouvelles données. C'est là qu'intervient la technique de Retrieval Augmented Generation (RAG). RAG est une architecture d'apprentissage automatique (ML) qui utilise des documents externes (comme Wikipédia) pour augmenter ses connaissances et obtenir des résultats de pointe sur des tâches à forte intensité de connaissances. . Pour ingérer ces sources de données externes, des bases de données vectorielles ont évolué, qui peuvent stocker des intégrations vectorielles de la source de données et permettre des recherches de similarité.
Dans cet article, nous montrons comment créer un pipeline d'ingestion RAG d'extraction, de transformation et de chargement (ETL) pour ingérer de grandes quantités de données dans un Service Amazon OpenSearch cluster et utilisation Amazon Relational Database Service (Amazon RDS) pour PostgreSQL avec l'extension pgvector comme magasin de données vectorielles. Chaque service implémente des algorithmes du k-voisin le plus proche (k-NN) ou du voisin le plus proche (ANN) et des mesures de distance pour calculer la similarité. Nous introduisons l'intégration de rayon dans le mécanisme de récupération de documents contextuels RAG. Ray est une bibliothèque informatique distribuée open source, Python, à usage général. Il permet au traitement de données distribué de générer et de stocker des intégrations pour une grande quantité de données, en les parallélisant sur plusieurs GPU. Nous utilisons un cluster Ray avec ces GPU pour exécuter une ingestion et une requête parallèles pour chaque service.
Dans cette expérience, nous tentons d'analyser les aspects suivants pour OpenSearch Service et l'extension pgvector sur Amazon RDS :
- En tant que magasin de vecteurs, possibilité de mettre à l'échelle et de gérer un vaste ensemble de données contenant des dizaines de millions d'enregistrements pour RAG.
- Goulots d'étranglement possibles dans le pipeline d'ingestion pour RAG
- Comment obtenir des performances optimales en termes de temps d'ingestion et de récupération des requêtes pour OpenSearch Service et Amazon RDS
Pour en savoir plus sur les magasins de données vectorielles et leur rôle dans la création d'applications d'IA générative, reportez-vous à Le rôle des banques de données vectorielles dans les applications d'IA générative.
Présentation du service OpenSearch
OpenSearch Service est un service géré pour l'analyse, la recherche et l'indexation sécurisées des données commerciales et opérationnelles. OpenSearch Service prend en charge les données à l'échelle du pétaoctet avec la possibilité de créer plusieurs index sur des données textuelles et vectorielles. Avec une configuration optimisée, il vise un rappel élevé pour les requêtes. OpenSearch Service prend en charge ANN ainsi que la recherche exacte k-NN. OpenSearch Service prend en charge une sélection d'algorithmes du NMSLIB, FAISSet Lucene bibliothèques pour alimenter la recherche k-NN. Nous avons créé l'index ANN pour OpenSearch avec l'algorithme Hierarchical Navigable Small World (HNSW), car il est considéré comme une meilleure méthode de recherche pour les grands ensembles de données. Pour plus d'informations sur le choix de l'algorithme d'indexation, reportez-vous à Choisissez l'algorithme k-NN pour votre cas d'utilisation à l'échelle d'un milliard avec OpenSearch.
Présentation d'Amazon RDS pour PostgreSQL avec pgvector
L'extension pgvector ajoute une recherche de similarité vectorielle open source à PostgreSQL. En utilisant l'extension pgvector, PostgreSQL peut effectuer des recherches de similarité sur les intégrations vectorielles, offrant ainsi aux entreprises une solution rapide et efficace. pgvector propose deux types de recherches de similarité vectorielle : le voisin le plus proche exact, qui aboutit à un rappel à 100 %, et le voisin le plus proche approximatif (ANN), qui offre de meilleures performances que la recherche exacte avec un compromis sur le rappel. Pour les recherches sur un index, vous pouvez choisir le nombre de centres à utiliser dans la recherche, un plus grand nombre de centres offrant un meilleur rappel avec un compromis en termes de performances.
Vue d'ensemble de la solution
Le diagramme suivant illustre l'architecture de la solution.

Examinons les composants clés plus en détail.
Ensemble de données
Nous utilisons les données OSCAR comme corpus et l'ensemble de données SQUAD pour fournir des exemples de questions. Ces ensembles de données sont d'abord convertis en fichiers Parquet. Ensuite, nous utilisons un cluster Ray pour convertir les données Parquet en intégrations. Les intégrations créées sont ingérées dans OpenSearch Service et Amazon RDS avec pgvector.
OSCAR (Open Super-large Crawled Aggregated corpus) est un immense corpus multilingue obtenu par classification linguistique et filtrage des Exploration commune corpus utilisant le impoli architecture. Les données sont distribuées par langue sous forme originale et dédupliquée. L'ensemble de données Oscar Corpus contient environ 609 millions d'enregistrements et occupe environ 4.5 To sous forme de fichiers JSONL bruts. Les fichiers JSONL sont ensuite convertis au format Parquet, ce qui minimise la taille totale à 1.8 To. Nous avons ensuite réduit l'ensemble de données à 25 millions d'enregistrements pour gagner du temps lors de l'ingestion.
SQuAD (Stanford Question Answering Dataset) est un ensemble de données de compréhension écrite composé de questions posées par des travailleurs participatifs sur un ensemble d'articles Wikipédia, où la réponse à chaque question est un segment de texte, ou envergure, du passage de lecture correspondant, sinon la question pourrait être sans réponse. Nous utilisons ÉQUIPE, autorisé comme CC-BY-SA 4.0, pour fournir des exemples de questions. Il contient environ 100,000 50,000 questions, dont plus de XNUMX XNUMX sans réponse, écrites par des travailleurs participatifs pour ressembler à celles auxquelles il est possible de répondre.
Cluster de rayons pour l'ingestion et la création d'intégrations vectorielles
Lors de nos tests, nous avons constaté que les GPU ont le plus grand impact sur les performances lors de la création des intégrations. Par conséquent, nous avons décidé d'utiliser un cluster Ray pour convertir notre texte brut et créer les intégrations. rayon est un framework de calcul unifié open source qui permet aux ingénieurs ML et aux développeurs Python de faire évoluer les applications Python et d'accélérer les charges de travail ML. Notre cluster était composé de 5 g4dn.12xlarge Cloud de calcul élastique Amazon (Amazon EC2). Chaque instance a été configurée avec 4 GPU NVIDIA T4 Tensor Core, 48 vCPU et 192 Go de mémoire. Pour nos enregistrements texte, nous avons fini par les diviser en 1,000 100 morceaux avec un chevauchement de 200 morceaux. Cela s'élève à environ XNUMX par enregistrement. Pour le modèle utilisé pour créer les intégrations, nous avons opté pour tout-mpnet-base-v2 pour créer un espace vectoriel de 768 dimensions.
Configuration des infrastructures
Nous avons utilisé les types d'instances RDS et les configurations de cluster de services OpenSearch suivants pour configurer notre infrastructure.
Voici nos propriétés de type d'instance RDS :
- Type d'instance : db.r7g.12xlarge
- Stockage alloué : 20 To
- Multi-AZ : vrai
- Stockage chiffré : Vrai
- Activer les informations sur les performances : vrai
- Rétention de Performance Insight : 7 jours
- Type de stockage : gp3
- IOPS provisionnées : 64,000 XNUMX
- Type d'index : FIV
- Nombre de listes : 5,000 XNUMX
- Fonction distance : L2
Voici nos propriétés de cluster OpenSearch Service :
- Version: 2.5
- Nœuds de données : 10
- Type d'instance de nœud de données : r6g.4xlarge
- Nœuds principaux : 3
- Type d'instance de nœud principal : r6g.xlarge
- Indice : Moteur HNSW :
nmslib - Intervalle de rafraîchissement : 30 secondes
ef_construction: 256- m : 16
- Fonction distance : L2
Nous avons utilisé des configurations volumineuses pour le cluster OpenSearch Service et les instances RDS afin d'éviter tout goulot d'étranglement en termes de performances.
Nous déployons la solution à l'aide d'un Kit de développement AWS Cloud (AWSCDK) empiler, comme indiqué dans la section suivante.
Déployer la pile AWS CDK
La pile AWS CDK nous permet de choisir OpenSearch Service ou Amazon RDS pour ingérer des données.
Pré-requis
Avant de procéder à l'installation, sous cdk, bin, src.tc, modifiez les valeurs booléennes d'Amazon RDS et d'OpenSearch Service sur true ou false selon vos préférences.
Vous avez également besoin d'un service lié Gestion des identités et des accès AWS (IAM) pour le domaine OpenSearch Service. Pour plus de détails, reportez-vous à Bibliothèque de constructions Amazon OpenSearch Service. Vous pouvez également exécuter la commande suivante pour créer le rôle :
Cette pile AWS CDK déploiera l'infrastructure suivante :
- Un VPC
- Un hôte de saut (à l'intérieur du VPC)
- Un cluster OpenSearch Service (si vous utilisez le service OpenSearch pour l'ingestion)
- Une instance RDS (si vous utilisez Amazon RDS pour l'ingestion)
- An Gestionnaire de systèmes AWS document de déploiement du cluster Ray
- An Service de stockage simple Amazon (Amazon S3) compartiment
- An Colle AWS travail de conversion des fichiers JSONL de l'ensemble de données OSCAR en fichiers Parquet
- Amazon Cloud Watch tableaux de bord
Télécharger les données
Exécutez les commandes suivantes à partir de l'hôte de saut :
Avant de cloner le dépôt git, assurez-vous d'avoir un profil Hugging Face et d'avoir accès au corpus de données OSCAR. Vous devez utiliser le nom d'utilisateur et le mot de passe pour cloner les données OSCAR :
Convertir des fichiers JSONL en Parquet
La pile AWS CDK a créé la tâche AWS Glue ETL oscar-jsonl-parquet pour convertir les données OSCAR du format JSONL au format Parquet.
Après avoir exécuté le oscar-jsonl-parquet travail, les fichiers au format Parquet doivent être disponibles dans le dossier parquet dans le compartiment S3.
Téléchargez les questions
Depuis votre hôte Jump, téléchargez les données des questions et téléchargez-les dans votre compartiment S3 :
Configurer le cluster Ray
Dans le cadre du déploiement de la pile AWS CDK, nous avons créé un document Systems Manager appelé CreateRayCluster.
Pour exécuter le document, procédez comme suit :
- Sur la console Systems Manager, sous DOCUMENTS dans le volet de navigation, choisissez Appartenant à moi.
- Ouvrez le
CreateRayClusterdocument. - Selectionnez Courir.
La page de commande d'exécution aura les valeurs par défaut renseignées pour le cluster.
La configuration par défaut demande 5 g4dn.12xlarge. Assurez-vous que votre compte a des limites pour prendre en charge cela. La limite de service pertinente est l'exécution d'instances G et VT à la demande. La valeur par défaut est 64, mais cette configuration nécessite 240 CPU.
- Après avoir examiné la configuration du cluster, sélectionnez l'hôte de saut comme cible de la commande d'exécution.
Cette commande effectuera les étapes suivantes :
- Copiez les fichiers du cluster Ray
- Configurer le cluster Ray
- Configurer les index du service OpenSearch
- Configurer les tables RDS
Vous pouvez surveiller le résultat des commandes sur la console Systems Manager. Ce processus prendra 10 à 15 minutes pour le lancement initial.
Exécuter l'ingestion
Depuis l'hôte de saut, connectez-vous au cluster Ray :
Lors de la première connexion à l'hôte, installez la configuration requise. Ces fichiers doivent déjà être présents sur le nœud principal.
Pour l’une ou l’autre des méthodes d’ingestion, si vous obtenez une erreur comme celle-ci, elle est liée à des informations d’identification expirées. La solution de contournement actuelle (au moment d'écrire ces lignes) consiste à placer les fichiers d'informations d'identification dans le nœud principal Ray. Pour éviter les risques de sécurité, n'utilisez pas les utilisateurs IAM pour l'authentification lorsque vous développez des logiciels spécialement conçus ou lorsque vous travaillez avec des données réelles. Utilisez plutôt la fédération avec un fournisseur d'identité tel que AWS IAM Identity Center (successeur d'AWS Single Sign-On).
Habituellement, les informations d'identification sont stockées dans le fichier ~/.aws/credentials sur les systèmes Linux et macOS, et %USERPROFILE%.awscredentials sous Windows, mais il s'agit d'informations d'identification à court terme avec un jeton de session. Vous ne pouvez pas non plus remplacer le fichier d'informations d'identification par défaut et vous devez donc créer des informations d'identification à long terme sans le jeton de session à l'aide d'un nouvel utilisateur IAM.
Pour créer des informations d'identification à long terme, vous devez générer une clé d'accès AWS et une clé d'accès secrète AWS. Vous pouvez le faire depuis la console IAM. Pour obtenir des instructions, reportez-vous à S'authentifier avec les identifiants de l'utilisateur IAM.
Après avoir créé les clés, connectez-vous à l'hôte de saut en utilisant Session Manager, une fonctionnalité de Systems Manager, et exécutez la commande suivante :
Vous pouvez désormais réexécuter les étapes d’ingestion.
Ingérer des données dans OpenSearch Service
Si vous utilisez le service OpenSearch, exécutez le script suivant pour ingérer les fichiers :
Une fois l'opération terminée, exécutez le script qui exécute les requêtes simulées :
Ingérer des données dans Amazon RDS
Si vous utilisez Amazon RDS, exécutez le script suivant pour ingérer les fichiers :
Une fois l'opération terminée, assurez-vous de faire un vide complet sur l'instance RDS.
Exécutez ensuite le script suivant pour exécuter des requêtes simulées :
Configurer le tableau de bord Ray
Avant de configurer le tableau de bord Ray, vous devez installer le Interface de ligne de commande AWS (AWS CLI) sur votre ordinateur local. Pour obtenir des instructions, reportez-vous à Installer ou mettre à jour la dernière version de l'AWS CLI.
Effectuez les étapes suivantes pour configurer le tableau de bord :
- Installez l' Plugin du gestionnaire de sessions pour l'AWS CLI.
- Dans le compte Isengard, copiez les informations d'identification temporaires pour bash/zsh et exécutez-les dans votre terminal local.
- Créez un fichier session.sh sur votre ordinateur et copiez le contenu suivant dans le fichier :
- Modifiez le répertoire dans lequel ce fichier session.sh est stocké.
- Exécuter la commande
Chmod +xpour donner l'autorisation exécutable au fichier. - Exécutez la commande suivante:
Par exemple :
Vous verrez un message comme celui-ci :
Ouvrez un nouvel onglet dans votre navigateur et saisissez localhost:8265.
Vous verrez le tableau de bord Ray et les statistiques des tâches et du cluster en cours d'exécution. Vous pouvez suivre les métriques à partir d’ici.
Par exemple, vous pouvez utiliser le tableau de bord Ray pour observer la charge sur le cluster. Comme le montre la capture d'écran suivante, lors de l'ingestion, les GPU fonctionnent à près de 100 % d'utilisation.
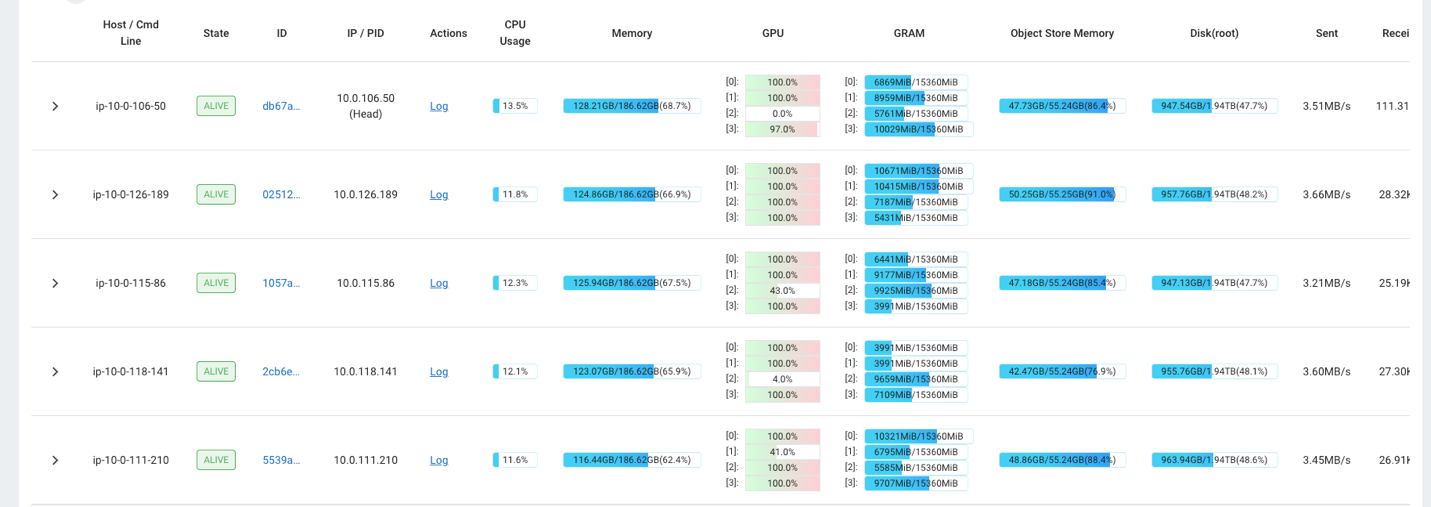
Vous pouvez également utiliser la RAG_Benchmarks Tableau de bord CloudWatch pour voir le taux d'ingestion et les temps de réponse aux requêtes.
Extensibilité de la solution
Vous pouvez étendre cette solution pour connecter d'autres magasins de vecteurs AWS ou tiers. Pour chaque nouveau magasin de vecteurs, vous devrez créer des scripts pour configurer le magasin de données ainsi que pour ingérer des données. Le reste du pipeline peut être réutilisé selon les besoins.
Conclusion
Dans cet article, nous avons partagé un pipeline ETL que vous pouvez utiliser pour placer des données RAG vectorisées dans OpenSearch Service ainsi que dans Amazon RDS avec l'extension pgvector en tant que banques de données vectorielles. La solution utilisait un cluster Ray pour fournir le parallélisme nécessaire pour ingérer un grand corpus de données. Vous pouvez utiliser cette méthodologie pour intégrer n'importe quelle base de données vectorielle de votre choix afin de créer des pipelines RAG.
À propos des auteurs
 Randy DeFauw est architecte principal de solutions senior chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. Il est entré dans l’espace du Big Data en 2013 et continue d’explorer ce domaine. Il travaille activement sur des projets dans le domaine du ML et a fait des présentations à de nombreuses conférences, notamment Strata et GlueCon.
Randy DeFauw est architecte principal de solutions senior chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. Il est entré dans l’espace du Big Data en 2013 et continue d’explorer ce domaine. Il travaille activement sur des projets dans le domaine du ML et a fait des présentations à de nombreuses conférences, notamment Strata et GlueCon.
 David Christian est un architecte de solutions principal basé en Californie du Sud. Il est titulaire d'un baccalauréat en sécurité de l'information et est passionné par l'automatisation. Ses domaines d'intervention sont la culture et la transformation DevOps, l'infrastructure en tant que code et la résilience. Avant de rejoindre AWS, il a occupé des postes dans les domaines de la sécurité, du DevOps et de l'ingénierie système, gérant des environnements de cloud privé et public à grande échelle.
David Christian est un architecte de solutions principal basé en Californie du Sud. Il est titulaire d'un baccalauréat en sécurité de l'information et est passionné par l'automatisation. Ses domaines d'intervention sont la culture et la transformation DevOps, l'infrastructure en tant que code et la résilience. Avant de rejoindre AWS, il a occupé des postes dans les domaines de la sécurité, du DevOps et de l'ingénierie système, gérant des environnements de cloud privé et public à grande échelle.
 Prachi Kulkarni est architecte de solutions senior chez AWS. Sa spécialisation est l'apprentissage automatique et elle travaille activement à la conception de solutions utilisant diverses offres AWS ML, Big Data et analytiques. Prachi possède de l'expérience dans plusieurs domaines, notamment les soins de santé, les avantages sociaux, la vente au détail et l'éducation, et a occupé divers postes dans les domaines de l'ingénierie et de l'architecture de produits, de la gestion et de la réussite des clients.
Prachi Kulkarni est architecte de solutions senior chez AWS. Sa spécialisation est l'apprentissage automatique et elle travaille activement à la conception de solutions utilisant diverses offres AWS ML, Big Data et analytiques. Prachi possède de l'expérience dans plusieurs domaines, notamment les soins de santé, les avantages sociaux, la vente au détail et l'éducation, et a occupé divers postes dans les domaines de l'ingénierie et de l'architecture de produits, de la gestion et de la réussite des clients.
 Richa Gupta est architecte de solutions chez AWS. Elle est passionnée par l'architecture de solutions de bout en bout pour les clients. Sa spécialisation est l'apprentissage automatique et la manière dont il peut être utilisé pour créer de nouvelles solutions menant à l'excellence opérationnelle et générant des revenus pour l'entreprise. Avant de rejoindre AWS, elle a travaillé en tant qu'ingénieur logiciel et architecte de solutions, créant des solutions pour de grands opérateurs de télécommunications. En dehors du travail, elle aime explorer de nouveaux endroits et adore les activités aventureuses.
Richa Gupta est architecte de solutions chez AWS. Elle est passionnée par l'architecture de solutions de bout en bout pour les clients. Sa spécialisation est l'apprentissage automatique et la manière dont il peut être utilisé pour créer de nouvelles solutions menant à l'excellence opérationnelle et générant des revenus pour l'entreprise. Avant de rejoindre AWS, elle a travaillé en tant qu'ingénieur logiciel et architecte de solutions, créant des solutions pour de grands opérateurs de télécommunications. En dehors du travail, elle aime explorer de nouveaux endroits et adore les activités aventureuses.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

