Cet article de blog est co-écrit avec Caroline Chung de Veoneer.
Veoneer est une entreprise mondiale d'électronique automobile et un leader mondial des systèmes de sécurité électroniques automobiles. Ils offrent les meilleurs systèmes de contrôle de retenue de leur catégorie et ont livré plus d'un milliard d'unités de commande électroniques et de capteurs de collision aux constructeurs automobiles du monde entier. L'entreprise continue de s'appuyer sur 1 ans d'histoire dans le développement de la sécurité automobile, en se spécialisant dans le matériel et les systèmes de pointe qui préviennent les incidents de la circulation et atténuent les accidents.
La détection automobile en cabine (ICS) est un espace émergent qui utilise une combinaison de plusieurs types de capteurs tels que des caméras et des radars, ainsi que des algorithmes basés sur l'intelligence artificielle (IA) et l'apprentissage automatique (ML) pour améliorer la sécurité et l'expérience de conduite. Construire un tel système peut être une tâche complexe. Les développeurs doivent annoter manuellement de grands volumes d’images à des fins de formation et de tests. Cela prend beaucoup de temps et nécessite beaucoup de ressources. Le délai d’exécution pour une telle tâche est de plusieurs semaines. En outre, les entreprises doivent faire face à des problèmes tels que des étiquettes incohérentes dues à des erreurs humaines.
AWS s'efforce de vous aider à augmenter votre vitesse de développement et à réduire vos coûts de création de tels systèmes grâce à des analyses avancées telles que le ML. Notre vision est d'utiliser le ML pour l'annotation automatisée, permettant le recyclage des modèles de sécurité et garantissant des mesures de performances cohérentes et fiables. Dans cet article, nous expliquons comment, en collaborant avec l'organisation mondiale spécialisée d'Amazon et le Centre d'innovation en IA générative, nous avons développé un pipeline d'apprentissage actif pour les cadres de délimitation des têtes d'images en cabine et l'annotation des points clés. La solution réduit les coûts de plus de 90 %, accélère le processus d'annotation de quelques semaines à quelques heures en termes de délai d'exécution et permet la réutilisation pour des tâches similaires d'étiquetage des données ML.
Vue d'ensemble de la solution
L'apprentissage actif est une approche ML qui implique un processus itératif de sélection et d'annotation des données les plus informatives pour entraîner un modèle. Étant donné un petit ensemble de données étiquetées et un grand ensemble de données non étiquetées, l'apprentissage actif améliore les performances du modèle, réduit les efforts d'étiquetage et intègre l'expertise humaine pour des résultats robustes. Dans cet article, nous construisons un pipeline d'apprentissage actif pour les annotations d'images avec les services AWS.
Le diagramme suivant montre le cadre global de notre pipeline d’apprentissage actif. Le pipeline d'étiquetage prend des images à partir d'un Service de stockage simple Amazon (Amazon S3) et génère des images annotées avec la coopération de modèles ML et de l'expertise humaine. Le pipeline de formation prétraite les données et les utilise pour former des modèles ML. Le modèle initial est configuré et entraîné sur un petit ensemble de données étiquetées manuellement, et sera utilisé dans le pipeline d'étiquetage. Le pipeline d'étiquetage et le pipeline de formation peuvent être itérés progressivement avec davantage de données étiquetées pour améliorer les performances du modèle.
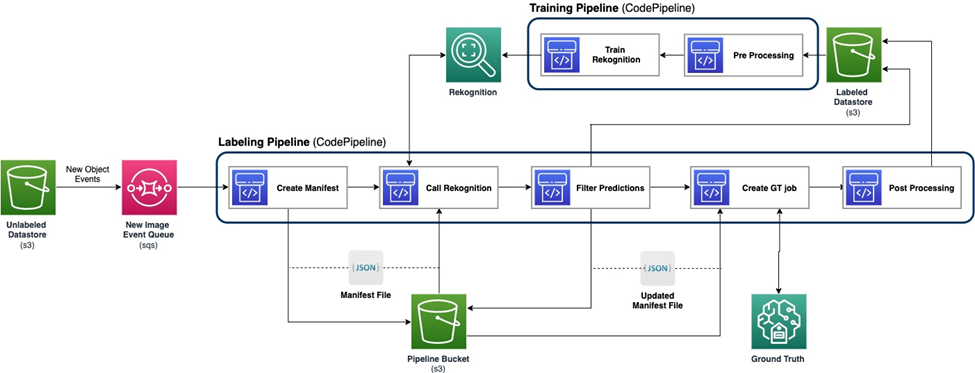
Dans le pipeline d'étiquetage, un Notification d'événement Amazon S3 est invoqué lorsqu'un nouveau lot d'images arrive dans le compartiment Unlabeled Datastore S3, activant le pipeline d'étiquetage. Le modèle produit les résultats d'inférence sur les nouvelles images. Une fonction de jugement personnalisée sélectionne des parties des données sur la base du score de confiance d'inférence ou d'autres fonctions définies par l'utilisateur. Ces données, avec leurs résultats d'inférence, sont envoyées pour un travail d'étiquetage humain sur Vérité au sol Amazon SageMaker créé par le pipeline. Le processus d'étiquetage humain permet d'annoter les données, et les résultats modifiés sont combinés avec les données auto-annotées restantes, qui peuvent être utilisées ultérieurement par le pipeline de formation.
Le recyclage du modèle se produit dans le pipeline de formation, où nous utilisons l'ensemble de données contenant les données étiquetées par l'homme pour recycler le modèle. Un fichier manifeste est produit pour décrire l'emplacement de stockage des fichiers, et le même modèle initial est recyclé sur les nouvelles données. Après le recyclage, le nouveau modèle remplace le modèle initial et la prochaine itération du pipeline d'apprentissage actif démarre.
Déploiement de modèle
Le pipeline d'étiquetage et le pipeline de formation sont déployés sur AWS CodePipeline. Création de code AWS les instances sont utilisées pour la mise en œuvre, qui est flexible et rapide pour une petite quantité de données. Lorsque la vitesse est nécessaire, nous utilisons Amazon Sage Maker points de terminaison basés sur l’instance GPU pour allouer plus de ressources pour prendre en charge et accélérer le processus.
Le pipeline de recyclage du modèle peut être invoqué lorsqu'un nouvel ensemble de données apparaît ou lorsque les performances du modèle doivent être améliorées. Une tâche essentielle dans le pipeline de recyclage consiste à disposer du système de contrôle de version pour les données de formation et le modèle. Bien que les services AWS tels que Amazon Reconnaissance disposent de la fonctionnalité de contrôle de version intégrée, ce qui rend le pipeline simple à mettre en œuvre, les modèles personnalisés nécessitent une journalisation des métadonnées ou des outils de contrôle de version supplémentaires.
L'ensemble du flux de travail est implémenté à l'aide du Kit de développement AWS Cloud (AWS CDK) pour créer les composants AWS nécessaires, notamment les suivants :
- Deux rôles pour les tâches CodePipeline et SageMaker
- Deux tâches CodePipeline, qui orchestrent le flux de travail
- Deux buckets S3 pour les artefacts de code des pipelines
- Un compartiment S3 pour étiqueter le manifeste de tâche, les ensembles de données et les modèles
- Prétraitement et post-traitement AWS Lambda fonctions pour les tâches d'étiquetage SageMaker Ground Truth
Les piles AWS CDK sont hautement modularisées et réutilisables pour différentes tâches. La formation, le code d'inférence et le modèle SageMaker Ground Truth peuvent être remplacés par tout scénario d'apprentissage actif similaire.
Formation de modèle
La formation du modèle comprend deux tâches : l'annotation du cadre de délimitation de la tête et l'annotation des points clés humains. Nous les présentons tous les deux dans cette section.
Annotation du cadre de délimitation de l'en-tête
L'annotation du cadre de délimitation de la tête est une tâche permettant de prédire l'emplacement d'un cadre de délimitation de la tête humaine dans une image. Nous utilisons un Étiquettes personnalisées Amazon Rekognition modèle pour les annotations de boîte englobante de tête. Ce qui suit exemple de cahier fournit un didacticiel étape par étape sur la façon de former un modèle d'étiquettes personnalisées Rekognition via SageMaker.
Nous devons d’abord préparer les données pour démarrer la formation. Nous générons un fichier manifeste pour la formation et un fichier manifeste pour l'ensemble de données de test. Un fichier manifeste contient plusieurs éléments, chacun étant destiné à une image. Voici un exemple de fichier manifeste, qui inclut le chemin d'accès, la taille et les informations d'annotation de l'image :
À l'aide des fichiers manifestes, nous pouvons charger des ensembles de données dans un modèle d'étiquettes personnalisées Rekognition à des fins de formation et de test. Nous avons itéré le modèle avec différentes quantités de données d'entraînement et l'avons testé sur les mêmes 239 images invisibles. Dans cet essai, le mAP_50 le score est passé de 0.33 avec 114 images d’entraînement à 0.95 avec 957 images d’entraînement. La capture d'écran suivante montre les mesures de performances du modèle final de Rekognition Custom Labels, qui offre d'excellentes performances en termes de score F1, de précision et de rappel.

Nous avons ensuite testé le modèle sur un ensemble de données retenues contenant 1,128 XNUMX images. Le modèle prédit systématiquement des prédictions précises de la boîte englobante sur les données invisibles, ce qui donne un résultat élevé. mAP_50 de 94.9%. L’exemple suivant montre une image annotée automatiquement avec un cadre de délimitation d’en-tête.

Annotation des points clés
L'annotation des points clés produit l'emplacement des points clés, notamment les yeux, les oreilles, le nez, la bouche, le cou, les épaules, les coudes, les poignets, les hanches et les chevilles. En plus de la prédiction de localisation, la visibilité de chaque point est nécessaire pour prédire dans cette tâche spécifique, pour laquelle nous concevons une nouvelle méthode.
Pour l'annotation des points clés, nous utilisons un Modèle Yolo 8 poses sur SageMaker comme modèle initial. Nous préparons d'abord les données pour la formation, notamment en générant des fichiers d'étiquettes et un fichier de configuration .yaml suivant les exigences de Yolo. Après avoir préparé les données, nous entraînons le modèle et enregistrons les artefacts, y compris le fichier de pondération du modèle. Avec le fichier de poids du modèle entraîné, nous pouvons annoter les nouvelles images.
Au cours de la phase de formation, tous les points étiquetés avec des emplacements, y compris les points visibles et les points masqués, sont utilisés pour la formation. Par conséquent, ce modèle fournit par défaut la localisation et la confiance de la prédiction. Dans la figure suivante, un seuil de confiance élevé (seuil principal) proche de 0.6 est capable de diviser les points visibles ou masqués par rapport aux points extérieurs aux points de vue de la caméra. Cependant, les points masqués et les points visibles ne sont pas séparés par le niveau de confiance, ce qui signifie que le niveau de confiance prédit n'est pas utile pour prédire la visibilité.

Pour obtenir la prédiction de la visibilité, nous introduisons un modèle supplémentaire entraîné sur l'ensemble de données contenant uniquement les points visibles, excluant les points obscurs et en dehors des points de vue de la caméra. La figure suivante montre la répartition des points avec une visibilité différente. Les points visibles et les autres points peuvent être séparés dans le modèle supplémentaire. On peut utiliser un seuil (seuil supplémentaire) proche de 0.6 pour obtenir les points visibles. En combinant ces deux modèles, nous concevons une méthode pour prédire l'emplacement et la visibilité.

Un point clé est d'abord prédit par le modèle principal avec emplacement et confiance principale, puis nous obtenons la prédiction de confiance supplémentaire du modèle supplémentaire. Sa visibilité est alors classée comme suit :
- Visible, si sa confiance principale est supérieure à son seuil principal, et sa confiance supplémentaire est supérieure au seuil supplémentaire
- Occlus, si sa confiance principale est supérieure à son seuil principal, et sa confiance supplémentaire est inférieure ou égale au seuil supplémentaire
- En dehors de l'examen de la caméra, si c'est le cas
Un exemple d'annotation de points clés est illustré dans l'image suivante, où les marques pleines sont des points visibles et les marques creuses sont des points masqués. En dehors des points de vue de la caméra, ils ne sont pas affichés.

Basé sur la norme OKS définition sur l'ensemble de données MS-COCO, notre méthode est capable d'atteindre un mAP_50 de 98.4 % sur l'ensemble de données de test invisible. En termes de visibilité, la méthode donne une précision de classification de 79.2 % sur le même ensemble de données.
Étiquetage et recyclage humains
Bien que les modèles atteignent d'excellentes performances sur les données de test, il existe toujours des possibilités de commettre des erreurs sur de nouvelles données du monde réel. L'étiquetage humain est le processus permettant de corriger ces erreurs afin d'améliorer les performances du modèle à l'aide du recyclage. Nous avons conçu une fonction de jugement qui combinait la valeur de confiance issue des modèles ML pour la sortie de toutes les boîtes englobantes principales ou points clés. Nous utilisons le score final pour identifier ces erreurs et les images mal étiquetées qui en résultent, qui doivent être envoyées au processus d'étiquetage humain.
En plus des images mal étiquetées, une petite partie des images est choisie au hasard pour un étiquetage humain. Ces images étiquetées par l'homme sont ajoutées à la version actuelle de l'ensemble de formation à des fins de recyclage, améliorant ainsi les performances du modèle et la précision globale des annotations.
Dans la mise en œuvre, nous utilisons SageMaker Ground Truth pour le étiquetage humain processus. SageMaker Ground Truth fournit une interface utilisateur conviviale et intuitive pour l'étiquetage des données. La capture d'écran suivante montre une tâche d'étiquetage SageMaker Ground Truth pour l'annotation du cadre de délimitation de la tête.

La capture d'écran suivante montre une tâche d'étiquetage SageMaker Ground Truth pour l'annotation des points clés.

Coût, rapidité et réutilisabilité
Le coût et la rapidité sont les principaux avantages de l'utilisation de notre solution par rapport à l'étiquetage humain, comme le montrent les tableaux suivants. Nous utilisons ces tableaux pour représenter les économies de coûts et les accélérations de vitesse. En utilisant l'instance GPU SageMaker accélérée ml.g4dn.xlarge, le coût total de formation et d'inférence sur 100,000 99 images est 10 % inférieur au coût de l'étiquetage humain, tandis que la vitesse est 10,000 à XNUMX XNUMX fois plus rapide que l'étiquetage humain, selon le tâche.
Le premier tableau résume les mesures de performance des coûts.
| Modèle | mAP_50 basé sur 1,128 XNUMX images de test | Coût de formation basé sur 100,000 XNUMX images | Coût d'inférence basé sur 100,000 XNUMX images | Réduction des coûts par rapport à l'annotation humaine | Temps d'inférence basé sur 100,000 XNUMX images | Accélération du temps par rapport à l'annotation humaine |
| Boîte englobante de la tête de reconnaissance | 0.949 | $4 | $22 | 99% de plastique en moins | 5.5 h | jours |
| Points clés de Yolo | 0.984 | $27.20 | * 10 $ | 99.9% de plastique en moins | minutes | Semaines |
Le tableau suivant résume les mesures de performances.
| Tâche d'annotation | mAP_50 (%) | Coût de la formation ($) | Coût d'inférence ($) | Temps d'inférence |
| Boîte englobante de tête | 94.9 | 4 | 22 | 5.5 heures |
| Points clés | 98.4 | 27 | 10 | 5 minutes |
De plus, notre solution permet une réutilisation pour des tâches similaires. Les développements de perception par caméra pour d'autres systèmes tels que le système avancé d'aide à la conduite (ADAS) et les systèmes en cabine peuvent également adopter notre solution.
Résumé
Dans cet article, nous avons montré comment créer un pipeline d'apprentissage actif pour l'annotation automatique des images en cabine à l'aide des services AWS. Nous démontrons la puissance du ML, qui vous permet d'automatiser et d'accélérer le processus d'annotation, ainsi que la flexibilité du framework qui utilise des modèles pris en charge par les services AWS ou personnalisés sur SageMaker. Avec Amazon S3, SageMaker, Lambda et SageMaker Ground Truth, vous pouvez rationaliser le stockage, l'annotation, la formation et le déploiement des données, et parvenir à une réutilisation tout en réduisant considérablement les coûts. En mettant en œuvre cette solution, les constructeurs automobiles peuvent devenir plus agiles et plus rentables en utilisant des analyses avancées basées sur le ML telles que l'annotation automatisée des images.
Commencez dès aujourd'hui et libérez la puissance de Services AWS et l'apprentissage automatique pour vos cas d'utilisation de détection automobile en cabine !
À propos des auteurs
 Yanxiang Yu est chercheur appliqué au Amazon Generative AI Innovation Center. Avec plus de 9 ans d'expérience dans la création de solutions d'IA et d'apprentissage automatique pour des applications industrielles, il se spécialise dans l'IA générative, la vision par ordinateur et la modélisation de séries chronologiques.
Yanxiang Yu est chercheur appliqué au Amazon Generative AI Innovation Center. Avec plus de 9 ans d'expérience dans la création de solutions d'IA et d'apprentissage automatique pour des applications industrielles, il se spécialise dans l'IA générative, la vision par ordinateur et la modélisation de séries chronologiques.
 Tianyi Mao est un scientifique appliqué chez AWS basé dans la région de Chicago. Il a plus de 5 ans d'expérience dans la création de solutions d'apprentissage automatique et d'apprentissage profond et se concentre sur la vision par ordinateur et l'apprentissage par renforcement avec des retours humains. Il aime travailler avec les clients pour comprendre leurs défis et les résoudre en créant des solutions innovantes utilisant les services AWS.
Tianyi Mao est un scientifique appliqué chez AWS basé dans la région de Chicago. Il a plus de 5 ans d'expérience dans la création de solutions d'apprentissage automatique et d'apprentissage profond et se concentre sur la vision par ordinateur et l'apprentissage par renforcement avec des retours humains. Il aime travailler avec les clients pour comprendre leurs défis et les résoudre en créant des solutions innovantes utilisant les services AWS.
 Yanru Xiao est un scientifique appliqué au Amazon Generative AI Innovation Center, où il crée des solutions d'IA/ML pour les problèmes commerciaux réels des clients. Il a travaillé dans plusieurs domaines, notamment l'industrie manufacturière, l'énergie et l'agriculture. Yanru a obtenu son doctorat. en informatique de l’Université Old Dominion.
Yanru Xiao est un scientifique appliqué au Amazon Generative AI Innovation Center, où il crée des solutions d'IA/ML pour les problèmes commerciaux réels des clients. Il a travaillé dans plusieurs domaines, notamment l'industrie manufacturière, l'énergie et l'agriculture. Yanru a obtenu son doctorat. en informatique de l’Université Old Dominion.
 Paul George est un chef de produit accompli avec plus de 15 ans d'expérience dans les technologies automobiles. Il est apte à diriger des équipes de gestion de produits, de stratégie, de mise sur le marché et d'ingénierie des systèmes. Il a incubé et lancé plusieurs nouveaux produits de détection et de perception à l'échelle mondiale. Chez AWS, il dirige la stratégie et la commercialisation des charges de travail des véhicules autonomes.
Paul George est un chef de produit accompli avec plus de 15 ans d'expérience dans les technologies automobiles. Il est apte à diriger des équipes de gestion de produits, de stratégie, de mise sur le marché et d'ingénierie des systèmes. Il a incubé et lancé plusieurs nouveaux produits de détection et de perception à l'échelle mondiale. Chez AWS, il dirige la stratégie et la commercialisation des charges de travail des véhicules autonomes.
 Caroline Chung est responsable de l'ingénierie chez Veoneer (acquise par Magna International), elle a plus de 14 ans d'expérience dans le développement de systèmes de détection et de perception. Elle dirige actuellement des programmes de pré-développement de détection intérieure chez Magna International, gérant une équipe d'ingénieurs en vision par ordinateur et de scientifiques des données.
Caroline Chung est responsable de l'ingénierie chez Veoneer (acquise par Magna International), elle a plus de 14 ans d'expérience dans le développement de systèmes de détection et de perception. Elle dirige actuellement des programmes de pré-développement de détection intérieure chez Magna International, gérant une équipe d'ingénieurs en vision par ordinateur et de scientifiques des données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

