Vous pouvez ingérer et intégrer des données provenant de plusieurs capteurs Internet des objets (IoT) pour obtenir des informations. Cependant, vous devrez peut-être intégrer les données de plusieurs capteurs IoT pour dériver des analyses telles que des informations sur l'état des équipements de tous les capteurs sur la base d'éléments de données communs. Chacun de ces capteurs pourrait transmettre des données avec des schémas uniques et des attributs différents.
Vous pouvez ingérer les données de tous vos capteurs IoT vers un emplacement central sur Service de stockage simple Amazon (Amazon S3). Évolution du schéma est une fonctionnalité dans laquelle le schéma d'une table de base de données peut évoluer pour s'adapter aux changements dans les attributs des fichiers ingérés. Avec la fonctionnalité d'évolution de schéma disponible dans Colle AWS, Spectre Amazon Redshift peut gérer automatiquement les modifications de schéma lorsque de nouveaux attributs sont ajoutés ou que des attributs existants sont supprimés. Ceci est réalisé avec un robot d'exploration AWS Glue en lisant les modifications de schéma basées sur les structures de fichiers S3. Le robot crée un schéma hybride qui fonctionne avec les anciens et les nouveaux ensembles de données. Vous pouvez lire tous les fichiers de données ingérés à un emplacement Amazon S3 spécifié avec différents schémas via un seul Spectre Amazon Redshift en vous référant au catalogue de métadonnées AWS Glue.
Dans cet article, nous montrons comment utiliser la fonctionnalité d'évolution de schéma AWS Glue pour lire plusieurs fichiers au format JSON avec différents schémas stockés dans un seul emplacement Amazon S3. Nous montrons également comment interroger ces données dans Amazon S3 avec Redshift Spectrum sans redéfinir le schéma ni charger les données dans les tables Redshift.
Vue d'ensemble de la solution
La solution comprend les étapes suivantes:
- Créer un Amazon Data Firehose flux de livraison avec Amazon S3 comme destination.
- Générez des exemples de données de flux à partir du Générateur de données Amazon Kinesis (KDG) avec le flux de livraison Firehose comme destination.
- Téléchargez les fichiers de données initiaux vers l'emplacement Amazon S3.
- Créez et exécutez un robot d'exploration AWS Glue pour remplir le catalogue de données avec une définition de table externe en lisant les fichiers de données d'Amazon S3.
- Créez le schéma externe appelé
iotdb_extdans Amazon Redshift et interrogez la table Data Catalog. - Interrogez la table externe de Redshift Spectrum pour lire les données du schéma initial.
- Ajoutez des éléments de données supplémentaires au modèle KDG et envoyez les données au flux de diffusion Firehose.
- Vérifiez que les fichiers de données supplémentaires sont chargés sur Amazon S3 avec des éléments de données supplémentaires.
- Exécutez un robot d'exploration AWS Glue pour mettre à jour les définitions de tables externes.
- Interrogez à nouveau la table externe de Redshift Spectrum pour lire l'ensemble de données combiné à partir de deux schémas différents.
- Supprimez un élément de données du modèle et envoyez les données au flux de diffusion Firehose.
- Vérifiez que les fichiers de données supplémentaires sont chargés sur Amazon S3 avec un élément de données en moins.
- Exécutez un robot d'exploration AWS Glue pour mettre à jour les définitions de tables externes.
- Interrogez la table externe de Redshift Spectrum pour lire l'ensemble de données combiné à partir de trois schémas différents.
Cette solution est illustrée dans le schéma d'architecture suivant.

Pré-requis
Cette solution nécessite les prérequis suivants :
Mettre en œuvre la solution
Effectuez les étapes suivantes pour créer la solution :
- Sur la console Kinesis, créez un flux de diffusion Firehose avec les paramètres suivants :
- Pour Identifier, choisissez PUT direct.
- Pour dentaire, choisissez Amazon S3.
- Pour Seau S3, entrez votre compartiment S3.
- Pour Partitionnement dynamique, sélectionnez Activé.

-
- Ajoutez les clés de partitionnement dynamique suivantes :
- Année clé avec expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - Mois clé avec expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - Journée clé avec expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - Heure clé avec expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- Année clé avec expression
- Ajoutez les clés de partitionnement dynamique suivantes :
-
- Pour Préfixe de compartiment S3, Entrer
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- Pour Préfixe de compartiment S3, Entrer

Vous pouvez consulter les détails de votre flux de diffusion sur la console Kinesis Data Firehose.
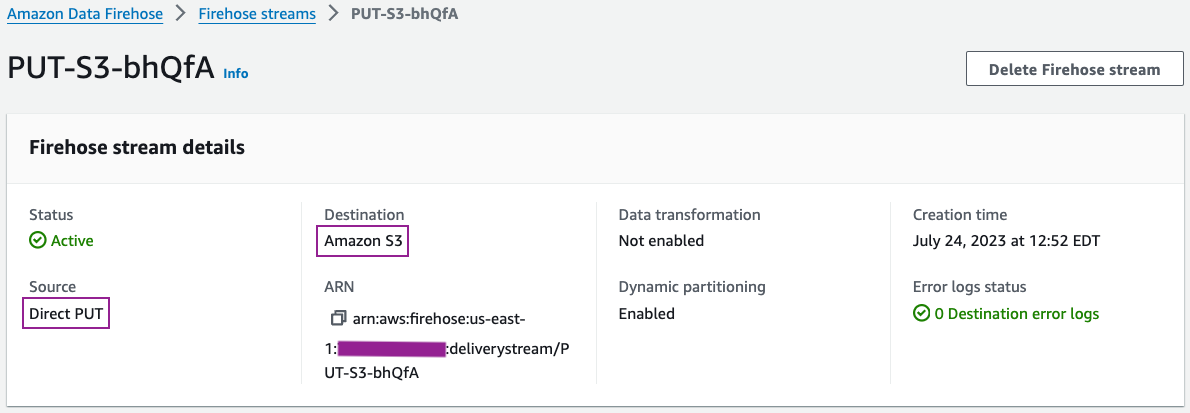
Les détails de configuration de votre flux de diffusion doivent être similaires à la capture d'écran suivante.

- Générez des exemples de données de flux à partir du KDG avec le flux de diffusion Firehose comme destination avec le modèle suivant :

- Sur la console Amazon S3, vérifiez que l'ensemble initial de fichiers a été chargé dans le compartiment S3.
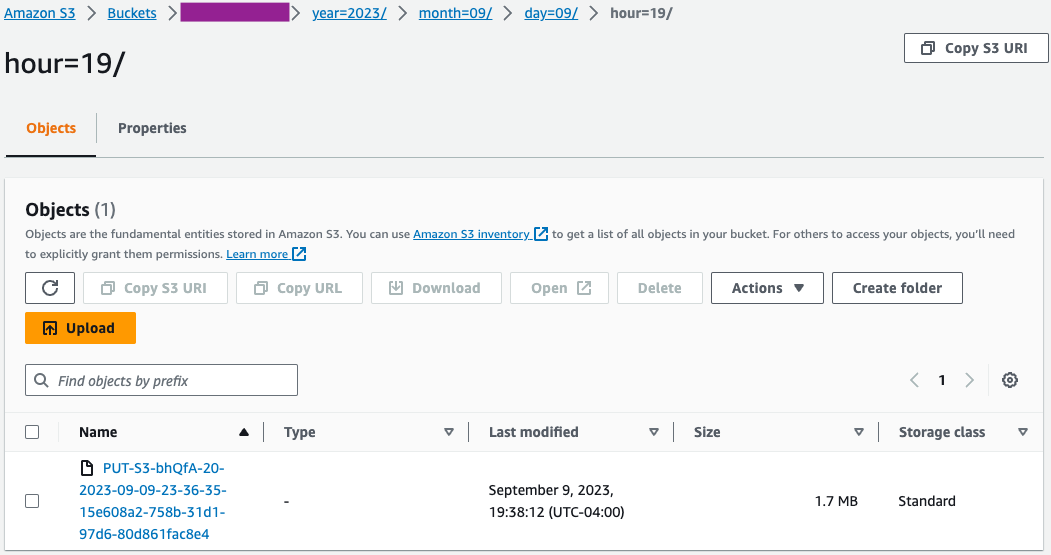
- Sur la console AWS Glue, créer et exécuter un AWS Glue Crawler avec la source de données comme compartiment S3 que vous avez utilisé à l'étape précédente.
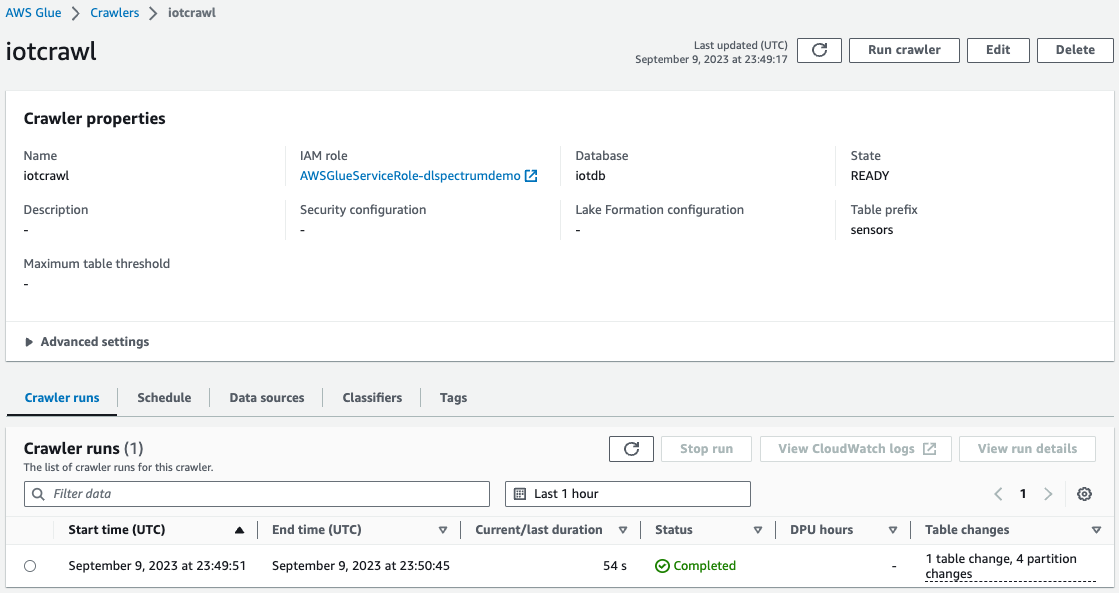
Une fois l'analyse terminée, vous pouvez vérifier que la table a été créée sur la console AWS Glue.

Dépannage
Si les données ne sont pas chargées dans Amazon S3 après leur envoi du modèle KDG vers le flux de diffusion Firehose, actualisez et assurez-vous que vous êtes connecté au KDG.
Nettoyer
Vous souhaiterez peut-être supprimer vos données S3 et votre cluster Redshift si vous ne prévoyez pas de les utiliser davantage afin d'éviter des coûts inutiles pour votre compte AWS.
Conclusion
Avec l’émergence des exigences en matière d’analyse prédictive et prescriptive basée sur le Big Data, il existe une demande croissante de solutions de données intégrant les données de plusieurs modèles de données hétérogènes avec un minimum d’effort. Dans cet article, nous avons montré comment dériver des métriques à partir d'éléments de données atomiques communs provenant de différentes sources de données avec des schémas uniques. Vous pouvez stocker les données de toutes les sources de données dans un emplacement S3 commun, soit dans le même dossier, soit dans plusieurs sous-dossiers pour chaque source de données. Vous pouvez définir et planifier l'exécution d'un robot d'exploration AWS Glue à la même fréquence que les exigences d'actualisation des données pour votre consommation de données. Avec cette solution, vous pouvez créer une table Redshift Spectrum à lire à partir d'un emplacement S3 avec différentes structures de fichiers à l'aide du catalogue de données AWS Glue et de la fonctionnalité d'évolution de schéma.
Si vous avez des questions ou des suggestions, veuillez laisser vos commentaires dans la section commentaires. Si vous avez besoin d'aide supplémentaire pour créer des solutions d'analyse avec les données de divers capteurs IoT, veuillez contacter l'équipe de votre compte AWS.
À propos des auteurs
 Swapna Bandla est architecte de solutions senior au sein de l'équipe AWS Analytics Specialist SA. Swapna a une passion pour la compréhension des besoins des clients en matière de données et d'analyse et pour leur permettre de développer des solutions cloud bien architecturées. En dehors du travail, elle aime passer du temps avec sa famille.
Swapna Bandla est architecte de solutions senior au sein de l'équipe AWS Analytics Specialist SA. Swapna a une passion pour la compréhension des besoins des clients en matière de données et d'analyse et pour leur permettre de développer des solutions cloud bien architecturées. En dehors du travail, elle aime passer du temps avec sa famille.
 Indira Balakrishnan est architecte principal de solutions au sein de l'équipe AWS Analytics Specialist SA. Elle se passionne pour aider les clients à créer des solutions d'analyse basées sur le cloud pour résoudre leurs problèmes commerciaux en utilisant des décisions basées sur les données. En dehors du travail, elle fait du bénévolat pour les activités de ses enfants et passe du temps avec sa famille.
Indira Balakrishnan est architecte principal de solutions au sein de l'équipe AWS Analytics Specialist SA. Elle se passionne pour aider les clients à créer des solutions d'analyse basées sur le cloud pour résoudre leurs problèmes commerciaux en utilisant des décisions basées sur les données. En dehors du travail, elle fait du bénévolat pour les activités de ses enfants et passe du temps avec sa famille.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

