L’essor de la recherche contextuelle et sémantique a rendu la recherche des entreprises de commerce électronique et de vente au détail simple pour ses consommateurs. Les moteurs de recherche et les systèmes de recommandation alimentés par l’IA générative peuvent améliorer l’expérience de recherche de produits de manière exponentielle en comprenant les requêtes en langage naturel et en renvoyant des résultats plus précis. Cela améliore l'expérience utilisateur globale, aidant les clients à trouver exactement ce qu'ils recherchent.
Service Amazon OpenSearch soutient maintenant le similitude cosinus métrique pour les indices k-NN. La similarité cosinus mesure le cosinus de l'angle entre deux vecteurs, où un angle cosinus plus petit indique une similarité plus élevée entre les vecteurs. Avec la similarité cosinus, vous pouvez mesurer l'orientation entre deux vecteurs, ce qui en fait un bon choix pour certaines applications de recherche sémantique spécifiques.
Dans cet article, nous montrons comment créer un moteur de recherche contextuel de texte et d'images pour les recommandations de produits à l'aide de l'outil Modèle d'intégration multimodale Amazon Titan, Disponible dans Socle amazonien, avec Amazon OpenSearch sans serveur.
Un modèle d'intégration multimodale est conçu pour apprendre des représentations conjointes de différentes modalités telles que le texte, les images et l'audio. En s'entraînant sur des ensembles de données à grande échelle contenant des images et leurs légendes correspondantes, un modèle d'intégration multimodale apprend à intégrer des images et des textes dans un espace latent partagé. Voici un aperçu général de son fonctionnement conceptuel :
- Encodeurs séparés – Ces modèles disposent d'encodeurs distincts pour chaque modalité : un encodeur de texte pour le texte (par exemple, BERT ou RoBERTa), un encodeur d'image pour les images (par exemple, CNN pour les images) et des encodeurs audio pour l'audio (par exemple, des modèles comme Wav2Vec). . Chaque encodeur génère des intégrations capturant les caractéristiques sémantiques de leurs modalités respectives
- Fusion de modalités – Les intégrations des codeurs unimodaux sont combinées à l'aide de couches de réseau neuronal supplémentaires. L'objectif est d'apprendre les interactions et les corrélations entre les modalités. Les approches de fusion courantes incluent la concaténation, les opérations par éléments, la mise en commun et les mécanismes d'attention.
- Espace de représentation partagé – Les couches de fusion aident à projeter les modalités individuelles dans un espace de représentation partagé. En s'entraînant sur des ensembles de données multimodaux, le modèle apprend un espace d'intégration commun où les intégrations de chaque modalité qui représentent le même contenu sémantique sous-jacent sont plus proches les unes des autres.
- Tâches en aval – Les intégrations multimodales conjointes générées peuvent ensuite être utilisées pour diverses tâches en aval telles que la récupération multimodale, la classification ou la traduction. Le modèle utilise des corrélations entre les modalités pour améliorer les performances de ces tâches par rapport aux intégrations modales individuelles. Le principal avantage est la capacité de comprendre les interactions et la sémantique entre des modalités telles que le texte, les images et l'audio grâce à une modélisation conjointe.
Vue d'ensemble de la solution
La solution fournit une implémentation pour créer un prototype de moteur de recherche alimenté par un grand modèle de langage (LLM) afin de récupérer et de recommander des produits sur la base de requêtes de texte ou d'images. Nous détaillons les étapes pour utiliser un Intégrations multimodales Amazon Titan modèle pour encoder des images et du texte dans des intégrations, ingérer des intégrations dans un index OpenSearch Service et interroger l'index à l'aide d'OpenSearch Service Fonctionnalité des k-voisins les plus proches (k-NN).
Cette solution comprend les composants suivants :
- Modèle d'intégration multimodale Amazon Titan – Ce modèle de fondation (FM) génère des intégrations des images de produits utilisées dans cet article. Avec Amazon Titan Multimodal Embeddings, vous pouvez générer des intégrations pour votre contenu et les stocker dans une base de données vectorielle. Lorsqu'un utilisateur final soumet une combinaison de texte et d'image en tant que requête de recherche, le modèle génère des intégrations pour la requête de recherche et les associe aux intégrations stockées pour fournir des résultats de recherche et de recommandations pertinents aux utilisateurs finaux. Vous pouvez personnaliser davantage le modèle pour améliorer sa compréhension de votre contenu unique et fournir des résultats plus significatifs en utilisant des paires image-texte pour un réglage précis. Par défaut, le modèle génère des vecteurs (plongements) de 1,024 XNUMX dimensions et est accessible via Amazon Bedrock. Vous pouvez également générer des dimensions plus petites pour optimiser la vitesse et les performances.
- Amazon OpenSearch sans serveur – Il s’agit d’une configuration sans serveur à la demande pour OpenSearch Service. Nous utilisons Amazon OpenSearch Serverless comme base de données vectorielle pour stocker les intégrations générées par le modèle Amazon Titan Multimodal Embeddings. Un index créé dans la collection Amazon OpenSearch Serverless sert de magasin de vecteurs pour notre solution Retrieval Augmented Generation (RAG).
- Amazon SageMakerStudio – Il s’agit d’un environnement de développement intégré (IDE) pour l’apprentissage automatique (ML). Les praticiens du ML peuvent effectuer toutes les étapes de développement du ML, de la préparation de vos données à la création, la formation et le déploiement de modèles de ML.
La conception de la solution se compose de deux parties : l'indexation des données et la recherche contextuelle. Lors de l'indexation des données, vous traitez les images de produits pour générer des intégrations pour ces images, puis vous remplissez le magasin de données vectorielles. Ces étapes sont terminées avant les étapes d'interaction avec l'utilisateur.
Dans la phase de recherche contextuelle, une requête de recherche (texte ou image) de l'utilisateur est convertie en intégrations et une recherche de similarité est exécutée sur la base de données vectorielles pour trouver les images de produits similaires sur la base de la recherche de similarité. Vous affichez ensuite les meilleurs résultats similaires. Tout le code de cet article est disponible dans le GitHub repo.
Le diagramme suivant illustre l'architecture de la solution.
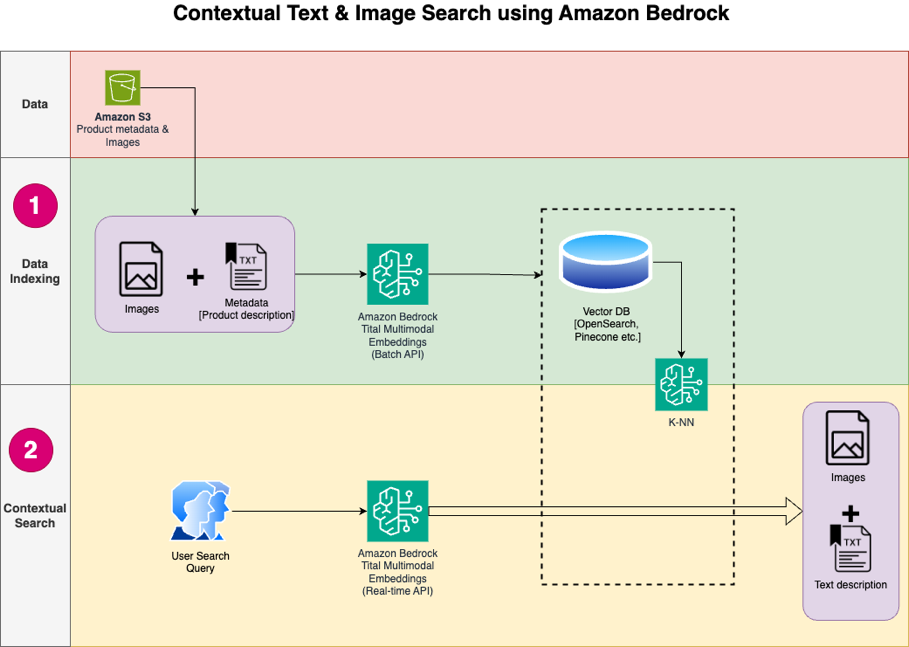
Voici les étapes du flux de travail de la solution :
- Téléchargez le texte de description du produit et les images du public Service de stockage simple Amazon (Amazon S3) seau.
- Examinez et préparez l’ensemble de données.
- Générez des intégrations pour les images de produits à l'aide du modèle Amazon Titan Multimodal Embeddings (amazon.titan-embed-image-v1). Si vous disposez d'un grand nombre d'images et de descriptions, vous pouvez éventuellement utiliser le Inférence par lots pour Amazon Bedrock.
- Stockez les intégrations dans le Amazon OpenSearch sans serveur comme moteur de recherche.
- Enfin, récupérez la requête de l'utilisateur en langage naturel, convertissez-la en intégrations à l'aide du modèle Amazon Titan Multimodal Embeddings et effectuez une recherche k-NN pour obtenir les résultats de recherche pertinents.
Nous utilisons SageMaker Studio (non illustré dans le diagramme) comme IDE pour développer la solution.
Ces étapes sont abordées en détail dans les sections suivantes. Nous incluons également des captures d'écran et des détails de la sortie.
Pré-requis
Pour mettre en œuvre la solution fournie dans cet article, vous devez disposer des éléments suivants :
- An Compte AWS et familiarité avec les FM, Amazon Bedrock, Amazon Sage Makeret le service OpenSearch.
- Le modèle Amazon Titan Multimodal Embeddings activé dans Amazon Bedrock. Vous pouvez confirmer qu'il est activé sur le Accès au modèle page de la console Amazon Bedrock. Si Amazon Titan Multimodal Embeddings est activé, l'état d'accès s'affichera comme suit : Accès accordé, comme illustré dans la capture d'écran suivante.

Si le modèle n'est pas disponible, activez l'accès au modèle en choisissant Gérer l'accès au modèle, En sélectionnant Intégrations multimodales Amazon Titan G1et choisir Demander l'accès au modèle. Le modèle est activé pour une utilisation immédiate.

Configurer la solution
Une fois les étapes préalables terminées, vous êtes prêt à configurer la solution :
- Dans votre compte AWS, ouvrez la console SageMaker et choisissez Studio dans le volet de navigation.
- Choisissez votre domaine et votre profil utilisateur, puis choisissez Open Studio.
Votre nom de domaine et votre nom de profil utilisateur peuvent être différents.

- Selectionnez Terminal système sous Utilitaires et fichiers.
- Exécutez la commande suivante pour cloner le GitHub repo à l'instance de SageMaker Studio :
- Accédez à la
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2edossier. - Ouvrez le
titan_mm_embed_search_blog.ipynbcarnet.
Exécutez la solution
Ouvrez le fichier titan_mm_embed_search_blog.ipynb et utilisez le noyau Data Science Python 3. Sur le Courir menu, choisissez Exécuter toutes les cellules pour exécuter le code dans ce notebook.
Ce bloc-notes effectue les étapes suivantes :
- Installez les packages et bibliothèques requis pour cette solution.
- Charger le fichier accessible au public Ensemble de données d'objets Amazon Berkeley et des métadonnées dans une trame de données pandas.
L'ensemble de données est une collection de 147,702 398,212 listes de produits avec des métadonnées multilingues et 1,600 XNUMX images de catalogue uniques. Pour cet article, vous utilisez uniquement les images et les noms des articles en anglais américain. Vous utilisez environ XNUMX XNUMX produits.

- Générez des intégrations pour les images d'articles à l'aide du modèle Amazon Titan Multimodal Embeddings à l'aide de l'outil
get_titan_multomodal_embedding()fonction. Par souci d'abstraction, nous avons défini toutes les fonctions importantes utilisées dans ce cahier dans leutils.pyfichier.

Ensuite, vous créez et configurez un magasin de vecteurs Amazon OpenSearch Serverless (collection et index).
- Avant de créer la nouvelle collection et l'index de recherche vectorielle, vous devez d'abord créer trois stratégies OpenSearch Service associées : la stratégie de sécurité de chiffrement, la stratégie de sécurité réseau et la stratégie d'accès aux données.

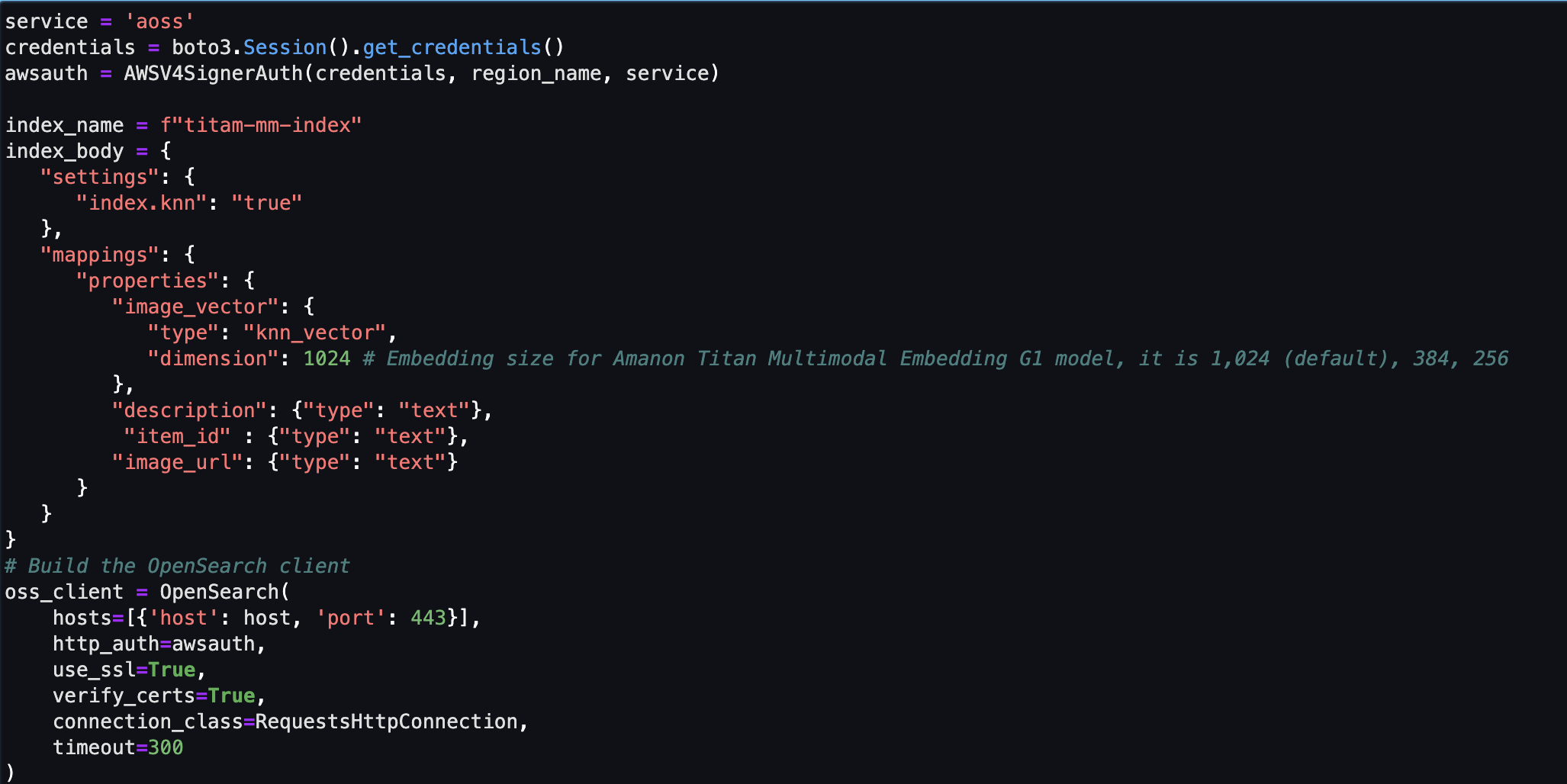
- Enfin, ingérez l’image intégrée dans l’index vectoriel.
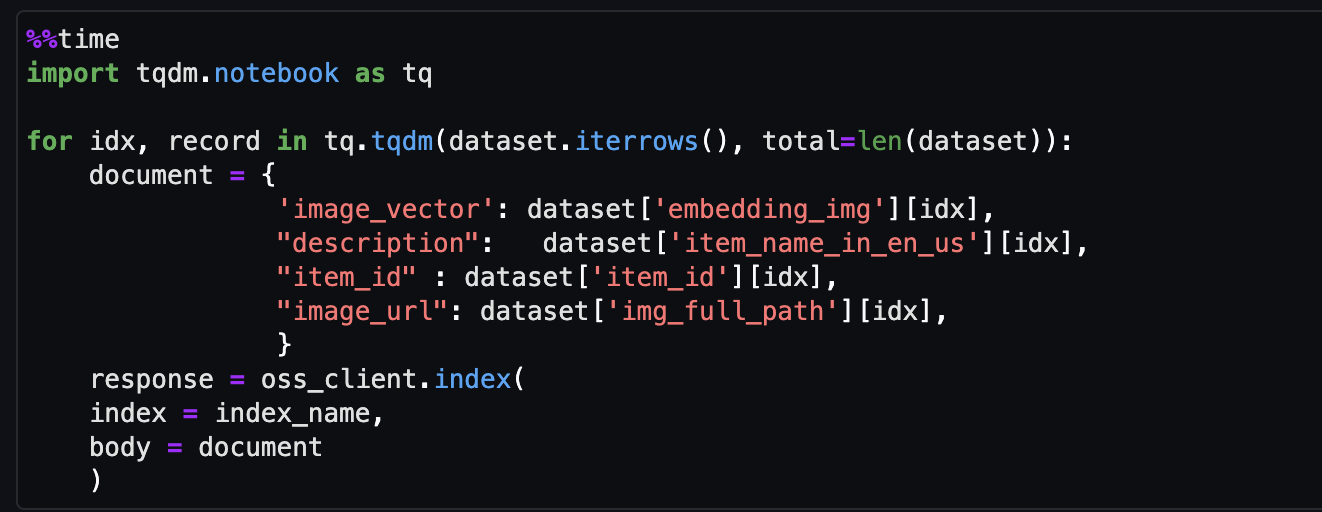
Vous pouvez désormais effectuer une recherche multimodale en temps réel.
Effectuer une recherche contextuelle
Dans cette section, nous montrons les résultats d'une recherche contextuelle basée sur une requête de texte ou d'image.
Tout d’abord, effectuons une recherche d’images basée sur la saisie de texte. Dans l'exemple suivant, nous utilisons la saisie de texte « verre à boisson » et l'envoyons au moteur de recherche pour trouver des articles similaires.
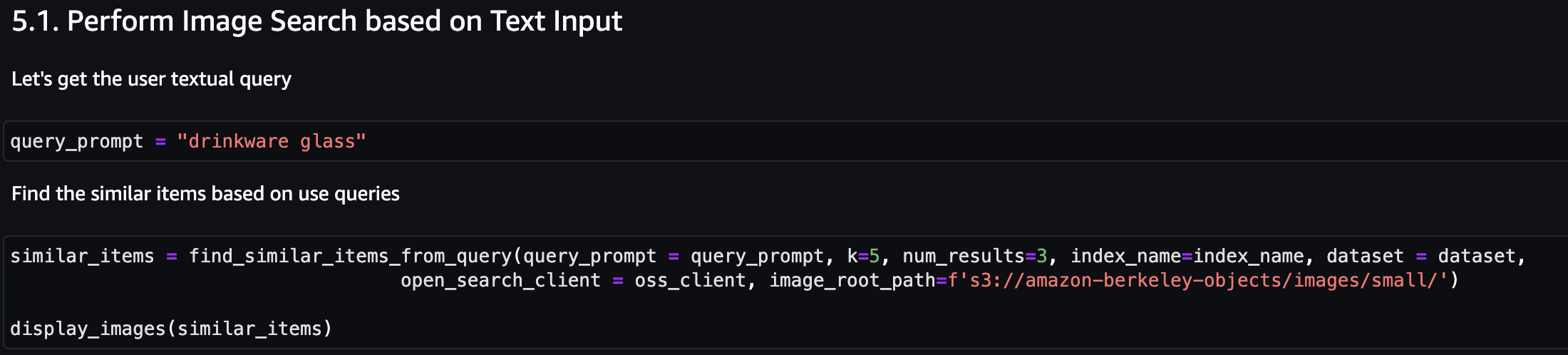
La capture d'écran suivante montre les résultats.

Examinons maintenant les résultats basés sur une image simple. L'image d'entrée est convertie en intégrations vectorielles et, sur la base de la recherche de similarité, le modèle renvoie le résultat.
Vous pouvez utiliser n'importe quelle image, mais pour l'exemple suivant, nous utilisons une image aléatoire de l'ensemble de données en fonction de l'ID de l'élément (par exemple, item_id = « B07JCDQWM6 »), puis envoyez cette image au moteur de recherche pour trouver des éléments similaires.

La capture d'écran suivante montre les résultats.

Nettoyer
Pour éviter d'encourir des frais futurs, supprimez les ressources utilisées dans cette solution. Vous pouvez le faire en exécutant la section de nettoyage du bloc-notes.

Conclusion
Cet article présente une présentation pas à pas de l'utilisation du modèle Amazon Titan Multimodal Embeddings dans Amazon Bedrock pour créer de puissantes applications de recherche contextuelle. En particulier, nous avons présenté un exemple d’application de recherche de listes de produits. Nous avons vu comment le modèle d'intégration permet une découverte efficace et précise d'informations à partir d'images et de données textuelles, améliorant ainsi l'expérience utilisateur lors de la recherche des éléments pertinents.
Amazon Titan Multimodal Embeddings vous aide à proposer des expériences de recherche, de recommandation et de personnalisation multimodales plus précises et contextuellement pertinentes pour les utilisateurs finaux. Par exemple, une société de photographie possédant des centaines de millions d'images peut utiliser le modèle pour alimenter sa fonctionnalité de recherche, afin que les utilisateurs puissent rechercher des images à l'aide d'une phrase, d'une image ou d'une combinaison d'image et de texte.
Le modèle Amazon Titan Multimodal Embeddings dans Amazon Bedrock est désormais disponible dans les régions AWS USA Est (Virginie du Nord) et USA Ouest (Oregon). Pour en savoir plus, reportez-vous à Le générateur d'images Amazon Titan, les intégrations multimodales et les modèles de texte sont désormais disponibles dans Amazon Bedrock, Page produit Amazon Titan, et le Guide de l'utilisateur d'Amazon Bedrock. Pour démarrer avec les intégrations multimodales Amazon Titan dans Amazon Bedrock, visitez le Console Amazon Bedrock.
Commencez à créer avec le modèle Amazon Titan Multimodal Embeddings dans Socle amazonien dès aujourd’hui.
À propos des auteurs
 Sandeep Singh est Senior Generative AI Data Scientist chez Amazon Web Services, aidant les entreprises à innover grâce à l'IA générative. Il se spécialise dans l'IA générative, l'intelligence artificielle, l'apprentissage automatique et la conception de systèmes. Il est passionné par le développement de solutions de pointe basées sur l'IA/ML pour résoudre des problèmes commerciaux complexes pour diverses industries, en optimisant l'efficacité et l'évolutivité.
Sandeep Singh est Senior Generative AI Data Scientist chez Amazon Web Services, aidant les entreprises à innover grâce à l'IA générative. Il se spécialise dans l'IA générative, l'intelligence artificielle, l'apprentissage automatique et la conception de systèmes. Il est passionné par le développement de solutions de pointe basées sur l'IA/ML pour résoudre des problèmes commerciaux complexes pour diverses industries, en optimisant l'efficacité et l'évolutivité.
 Mani Khanouja est responsable technique – Spécialistes de l'IA générative, auteur du livre Applied Machine Learning and High Performance Computing sur AWS, et membre du conseil d'administration de la Women in Manufacturing Education Foundation. Elle dirige des projets d'apprentissage automatique dans divers domaines tels que la vision par ordinateur, le traitement du langage naturel et l'IA générative. Elle prend la parole lors de conférences internes et externes telles qu'AWS re:Invent, Women in Manufacturing West, les webinaires YouTube et GHC 23. Pendant son temps libre, elle aime faire de longues courses le long de la plage.
Mani Khanouja est responsable technique – Spécialistes de l'IA générative, auteur du livre Applied Machine Learning and High Performance Computing sur AWS, et membre du conseil d'administration de la Women in Manufacturing Education Foundation. Elle dirige des projets d'apprentissage automatique dans divers domaines tels que la vision par ordinateur, le traitement du langage naturel et l'IA générative. Elle prend la parole lors de conférences internes et externes telles qu'AWS re:Invent, Women in Manufacturing West, les webinaires YouTube et GHC 23. Pendant son temps libre, elle aime faire de longues courses le long de la plage.
 Rupinder Grewal est un architecte de solutions spécialisé senior en IA/ML chez AWS. Il se concentre actuellement sur le service de modèles et de MLOps sur Amazon SageMaker. Avant d'occuper ce poste, il a travaillé en tant qu'ingénieur en apprentissage automatique pour créer et héberger des modèles. En dehors du travail, il aime jouer au tennis et faire du vélo sur les sentiers de montagne.
Rupinder Grewal est un architecte de solutions spécialisé senior en IA/ML chez AWS. Il se concentre actuellement sur le service de modèles et de MLOps sur Amazon SageMaker. Avant d'occuper ce poste, il a travaillé en tant qu'ingénieur en apprentissage automatique pour créer et héberger des modèles. En dehors du travail, il aime jouer au tennis et faire du vélo sur les sentiers de montagne.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

