Cet article invité est co-écrit par Lydia Lihui Zhang, spécialiste du développement commercial, et Mansi Shah, ingénieur logiciel/data scientist, chez Planet Labs. Le analyse qui a inspiré ce post a été initialement écrit par Jennifer Reiber Kyle.
Fonctionnalités géospatiales d'Amazon SageMaker combiné avec PlanèteLes données satellite de peuvent être utilisées pour la segmentation des cultures, et cette analyse présente de nombreuses applications et avantages potentiels dans les domaines de l'agriculture et de la durabilité. Fin 2023, Planète a annoncé un partenariat avec AWS pour rendre ses données géospatiales disponibles via Amazon Sage Maker.
La segmentation des cultures est le processus de division d'une image satellite en régions de pixels, ou segments, présentant des caractéristiques de culture similaires. Dans cet article, nous illustrons comment utiliser un modèle d'apprentissage automatique (ML) de segmentation pour identifier les régions recadrées et non recadrées dans une image.
L'identification des régions cultivées est une étape essentielle vers l'obtention d'informations agricoles, et la combinaison de riches données géospatiales et de ML peut conduire à des informations qui guident les décisions et les actions. Par exemple:
- Prendre des décisions agricoles basées sur les données – En acquérant une meilleure compréhension spatiale des cultures, les agriculteurs et autres acteurs agricoles peuvent optimiser l’utilisation des ressources, de l’eau aux engrais en passant par d’autres produits chimiques, tout au long de la saison. Cela jette les bases de la réduction des déchets, de l’amélioration des pratiques agricoles durables dans la mesure du possible et de l’augmentation de la productivité tout en minimisant l’impact environnemental.
- Identifier les stress et les tendances liés au climat – Alors que le changement climatique continue d’affecter les températures mondiales et les précipitations, la segmentation des cultures peut être utilisée pour identifier les zones vulnérables au stress lié au climat pour les stratégies d’adaptation au climat. Par exemple, les archives d’images satellite peuvent être utilisées pour suivre les changements dans une région agricole au fil du temps. Il pourrait s'agir de changements physiques dans la taille et la répartition des terres cultivées. Il pourrait également s'agir des changements dans l'humidité du sol, la température du sol et la biomasse, dérivés des différents indices spectraux des données satellite, pour une analyse plus approfondie de la santé des cultures.
- Évaluer et atténuer les dommages – Enfin, la segmentation des cultures peut être utilisée pour identifier rapidement et précisément les zones endommagées en cas de catastrophe naturelle, ce qui peut aider à prioriser les efforts de secours. Par exemple, après une inondation, des images satellite à haute cadence peuvent être utilisées pour identifier les zones où les cultures ont été submergées ou détruites, permettant ainsi aux organisations humanitaires d'aider plus rapidement les agriculteurs touchés.
Dans cette analyse, nous utilisons un modèle K-plus proches voisins (KNN) pour effectuer la segmentation des cultures, et nous comparons ces résultats avec des images de vérité terrain sur une région agricole. Nos résultats révèlent que la classification du modèle KNN est plus représentative de l'état du champ de culture actuel en 2017 que les données de classification de la vérité terrain de 2015. Ces résultats témoignent de la puissance de l'imagerie géospatiale à haute cadence de Planet. Les champs agricoles changent souvent, parfois plusieurs fois par saison, et disposer d'images satellite à haute fréquence pour observer et analyser ces terres peut apporter une immense valeur à notre compréhension des terres agricoles et des environnements en évolution rapide.
Partenariat Planet et AWS sur le ML géospatial
Capacités géospatiales de SageMaker permettez aux data scientists et aux ingénieurs ML de créer, former et déployer des modèles à l'aide de données géospatiales. Les capacités géospatiales de SageMaker vous permettent de transformer ou d'enrichir efficacement des ensembles de données géospatiales à grande échelle, d'accélérer la création de modèles avec des modèles ML pré-entraînés et d'explorer les prédictions de modèles et les données géospatiales sur une carte interactive à l'aide de graphiques accélérés en 3D et d'outils de visualisation intégrés. Grâce aux capacités géospatiales de SageMaker, vous pouvez traiter de grands ensembles de données d'images satellite et d'autres données géospatiales pour créer des modèles ML précis pour diverses applications, y compris la segmentation des cultures, dont nous discutons dans cet article.
Planète Labs PBC est une société leader dans le domaine de l'imagerie de la Terre qui utilise quotidiennement sa vaste flotte de satellites pour capturer des images de la surface de la Terre. Les données de la planète constituent donc une ressource précieuse pour le ML géospatial. Ses images satellite à haute résolution peuvent être utilisées pour identifier diverses caractéristiques des cultures et leur état de santé au fil du temps, n'importe où sur Terre.
Le partenariat entre Planet et SageMaker permet aux clients d'accéder et d'analyser facilement les données satellite haute fréquence de Planet à l'aide des puissants outils ML d'AWS. Les data scientists peuvent apporter leurs propres données ou rechercher et s'abonner facilement aux données de Planet sans changer d'environnement.
Segmentation de recadrage dans un bloc-notes Amazon SageMaker Studio avec une image géospatiale
Dans cet exemple de flux de travail de ML géospatial, nous examinons comment importer les données de Planet avec la source de données de vérité terrain dans SageMaker, et comment former, déduire et déployer un modèle de segmentation des cultures avec un classificateur KNN. Enfin, nous évaluons l'exactitude de nos résultats et les comparons à notre classification de vérité terrain.
Le classificateur KNN utilisé a été formé dans un Bloc-notes Amazon SageMaker Studio avec une fonction géospatiale image et fournit un noyau de bloc-notes flexible et extensible pour travailler avec des données géospatiales.
La Amazon SageMakerStudio notebook with geospatial image est préinstallé avec des bibliothèques géospatiales couramment utilisées telles que GDAL, Fiona, GeoPandas, Shapely et Rasterio, qui permettent la visualisation et le traitement des données géospatiales directement dans un environnement de notebook Python. Les bibliothèques ML courantes telles que OpenCV ou scikit-learn sont également utilisées pour effectuer la segmentation des cultures à l'aide de la classification KNN, et elles sont également installées dans le noyau géospatial.
Sélection de données
Le champ agricole sur lequel nous zoomons est situé dans le comté de Sacramento, généralement ensoleillé, en Californie.
Pourquoi Sacramento ? La sélection de la zone et du temps pour ce type de problème est principalement définie par la disponibilité de données de vérité sur le terrain, et de telles données sur les types de cultures et les données sur les limites ne sont pas faciles à obtenir. Le Ensemble de données de l'enquête DWR sur l'utilisation des terres du comté de Sacramento 2015 est un ensemble de données accessible au public couvrant le comté de Sacramento cette année-là et fournit des limites ajustées manuellement.
La principale imagerie satellitaire que nous utilisons est l'imagerie à 4 bandes de la planète. Produit PSScène, qui contient les bandes bleue, verte, rouge et proche infrarouge et est corrigé radiométriquement en fonction de la radiance du capteur. Les coefficients de correction de la réflectance au niveau du capteur sont fournis dans les métadonnées de la scène, ce qui améliore encore la cohérence entre les images prises à différents moments.
Les satellites Planet's Dove qui ont produit ces images ont été lancés le 14 février 2017 (communiqué de presse), ils n'ont donc pas pris d'images du comté de Sacramento en 2015. Cependant, ils ont pris des images quotidiennes de la région depuis le lancement. Dans cet exemple, nous nous contentons de l’écart imparfait de 2 ans entre les données de vérité terrain et les images satellite. Cependant, les images Landsat 8 à plus basse résolution auraient pu servir de pont entre 2015 et 2017.
Accéder aux données de Planet
Pour aider les utilisateurs à obtenir plus rapidement des données précises et exploitables, Planet a également développé le kit de développement logiciel (SDK) Planet pour Python. Il s'agit d'un outil puissant pour les scientifiques et les développeurs de données qui souhaitent travailler avec des images satellite et d'autres données géospatiales. Avec ce SDK, vous pouvez rechercher et accéder à la vaste collection d'images satellite haute résolution de Planet, ainsi qu'à des données provenant d'autres sources comme OpenStreetMap. Le SDK fournit un client Python aux API de Planet, ainsi qu'une solution d'interface de ligne de commande (CLI) sans code, facilitant l'intégration d'images satellite et de données géospatiales dans les flux de travail Python. Cet exemple utilise le client Python pour identifier et télécharger les images nécessaires à l'analyse.
Vous pouvez installer le client Planet Python dans le notebook SageMaker Studio avec une image géospatiale à l'aide d'une simple commande :
Vous pouvez utiliser le client pour interroger des images satellite pertinentes et récupérer une liste de résultats disponibles en fonction de la zone d'intérêt, de la plage horaire et d'autres critères de recherche. Dans l'exemple suivant, nous commençons par demander combien Scènes PlanetScope (imagerie quotidienne de la planète) couvrent la même zone d'intérêt (AOI) que nous avons définie plus tôt grâce aux données au sol à Sacramento, compte tenu d'une certaine plage horaire entre le 1er juin et le 1er octobre 2017 ; ainsi qu'une certaine plage de couverture nuageuse maximale souhaitée de 10 % :
Les résultats renvoyés montrent le nombre de scènes correspondantes chevauchant notre zone d'intérêt. Il contient également les métadonnées de chaque scène, son identifiant d'image et une référence d'image d'aperçu.
Une fois qu'une scène particulière a été sélectionnée, avec des spécifications sur l'ID de la scène, le type d'article et les offres groupées de produits (documentation de référence), vous pouvez utiliser le code suivant pour télécharger l'image et ses métadonnées :
Ce code télécharge l'image satellite correspondante sur le Système de fichiers Amazon Elastic (Amazon EFS) pour SageMaker Studio.
Formation de modèle
Une fois les données téléchargées avec le client Planet Python, le modèle de segmentation peut être entraîné. Dans cet exemple, une combinaison de techniques de classification KNN et de segmentation d'images est utilisée pour identifier la zone de culture et créer des fonctionnalités géojson géoréférencées.
Les données Planet sont chargées et prétraitées à l'aide des bibliothèques et outils géospatiaux intégrés dans SageMaker pour les préparer à la formation du classificateur KNN. Les données de vérité terrain pour la formation sont l'ensemble de données de l'enquête DWR sur l'utilisation des terres du comté de Sacramento de 2015, et les données Planet de 2017 sont utilisées pour tester le modèle.
Convertir les caractéristiques de vérité terrain en contours
Pour entraîner le classificateur KNN, la classe de chaque pixel soit crop or non-crop doit être identifié. La classe est déterminée selon que le pixel est associé ou non à une caractéristique de culture dans les données de vérité terrain. Pour effectuer cette détermination, les données de vérité terrain sont d'abord converties en contours OpenCV, qui sont ensuite utilisés pour séparer crop de non-crop pixels. Les valeurs des pixels et leur classification sont ensuite utilisées pour entraîner le classificateur KNN.
Pour convertir les caractéristiques de vérité terrain en contours, les caractéristiques doivent d'abord être projetées dans le système de référence de coordonnées de l'image. Ensuite, les caractéristiques sont transformées en espace image, et enfin converties en contours. Pour garantir la précision des contours, ils sont visualisés en superposition sur l'image d'entrée, comme le montre l'exemple suivant.
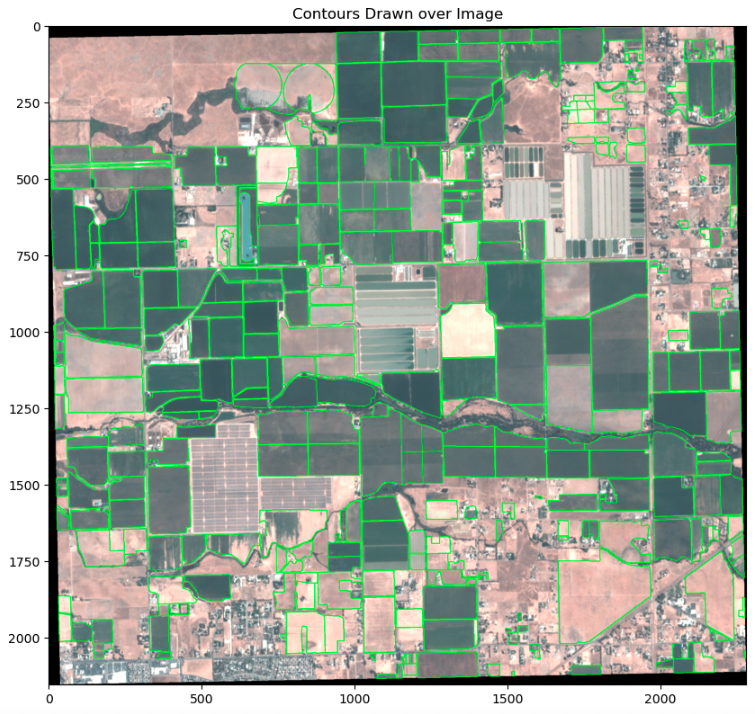
Pour entraîner le classificateur KNN, les pixels recadrés et non recadrés sont séparés en utilisant les contours des caractéristiques de recadrage comme masque.

L'entrée du classificateur KNN se compose de deux ensembles de données : X, un tableau 2D qui fournit les caractéristiques sur lesquelles classer ; et y, un tableau 1d qui fournit les classes (exemple). Ici, une seule bande classée est créée à partir des ensembles de données non recadrées et recadrées, où les valeurs de la bande indiquent la classe de pixels. Les valeurs de bande et de bande de pixels d'image sous-jacente sont ensuite converties en entrées X et y pour la fonction d'ajustement du classificateur.

Entraîner le classificateur sur les pixels recadrés et non recadrés
La classification KNN est effectuée avec le scikit-learn KNeighboursClassifier. Le nombre de voisins, un paramètre affectant grandement les performances de l'estimateur, est ajusté à l'aide de la validation croisée dans la validation croisée KNN. Le classificateur est ensuite entraîné à l'aide des ensembles de données préparés et du nombre ajusté de paramètres voisins. Voir le code suivant :
Pour évaluer les performances du classificateur sur ses données d'entrée, la classe de pixels est prédite à l'aide des valeurs de bande de pixels. Les performances du classificateur reposent principalement sur la précision des données d'entraînement et sur la séparation claire des classes de pixels en fonction des données d'entrée (valeurs de bande de pixels). Les paramètres du classificateur, tels que le nombre de voisins et la fonction de pondération de la distance, peuvent être ajustés pour compenser d'éventuelles imprécisions de cette dernière. Voir le code suivant :
Évaluer les prédictions du modèle
Le classificateur KNN formé est utilisé pour prédire les régions de culture dans les données de test. Ces données de test sont constituées de régions qui n'ont pas été exposées au modèle pendant la formation. En d’autres termes, le modèle n’a aucune connaissance de la zone avant son analyse et ces données peuvent donc être utilisées pour évaluer objectivement les performances du modèle. Nous commençons par inspecter visuellement plusieurs régions, en commençant par une région comparativement plus bruyante.

L’inspection visuelle révèle que les classes prédites sont pour la plupart cohérentes avec les classes de vérité terrain. Il existe quelques zones de déviation que nous inspectons plus en détail.

Après une enquête plus approfondie, nous avons découvert qu'une partie du bruit dans cette région était due aux données de vérité terrain manquant des détails présents dans l'image classifiée (en haut à droite par rapport au haut à gauche et en bas à gauche). Une découverte particulièrement intéressante est que le classificateur identifie les arbres le long de la rivière comme non-crop, alors que les données de vérité terrain les identifient à tort comme crop. Cette différence entre ces deux segmentations peut être due aux arbres qui ombragent la région au-dessus des cultures.
Ensuite, nous inspectons une autre région classée différemment entre les deux méthodes. Ces régions mises en évidence étaient auparavant marquées comme régions non cultivées dans les données de vérité sur le terrain en 2015 (en haut à droite), mais ont changé et sont clairement affichées comme des terres cultivées en 2017 à travers les scènes Planetscope (en haut à gauche et en bas à gauche). Elles ont également été classées en grande partie comme terres cultivées grâce au classificateur (en bas à droite).

Encore une fois, nous constatons que le classificateur KNN présente un résultat plus granulaire que la classe de vérité terrain, et qu'il capture également avec succès les changements qui se produisent dans les terres cultivées. Cet exemple témoigne également de la valeur des données satellite actualisées quotidiennement, car le monde évolue souvent beaucoup plus rapidement que les rapports annuels, et une méthode combinée avec le ML comme celle-ci peut nous aider à capter les changements au fur et à mesure qu'ils se produisent. Être capable de surveiller et de découvrir ces changements via des données satellite, en particulier dans les domaines agricoles en évolution, fournit des informations utiles aux agriculteurs pour optimiser leur travail et à tout acteur agricole de la chaîne de valeur pour avoir un meilleur pouls de la saison.
Évaluation du modèle
La comparaison visuelle des images des classes prédites avec les classes de vérité terrain peut être subjective et ne peut pas être généralisée pour évaluer l'exactitude des résultats de classification. Pour obtenir une évaluation quantitative, nous obtenons des métriques de classification en utilisant scikit-learn classification_report fonction:
La classification des pixels est utilisée pour créer un masque de segmentation des régions cultivées, ce qui rend la précision et le rappel des mesures importantes, et le score F1 est une bonne mesure globale pour prédire la précision. Nos résultats nous donnent des mesures pour les régions cultivées et non cultivées dans l'ensemble de données d'entraînement et de test. Cependant, pour simplifier les choses, examinons ces métriques de plus près dans le contexte des régions cultivées dans l'ensemble de données de test.
La précision est une mesure de la précision des prédictions positives de notre modèle. Dans ce cas, une précision de 0.94 pour les régions cultivées indique que notre modèle réussit très bien à identifier correctement les zones qui sont effectivement des régions cultivées, où les faux positifs (régions non cultivées réelles identifiées à tort comme régions cultivées) sont minimisées. Le rappel, quant à lui, mesure l’exhaustivité des prédictions positives. En d’autres termes, le rappel mesure la proportion de positifs réels qui ont été correctement identifiés. Dans notre cas, une valeur de rappel de 0.73 pour les régions cadrées signifie que 73 % de tous les pixels réels des régions cadrées sont correctement identifiés, minimisant ainsi le nombre de faux négatifs.
Idéalement, des valeurs élevées de précision et de rappel sont préférables, bien que cela puisse dépendre largement de l'application de l'étude de cas. Par exemple, si nous examinions ces résultats pour des agriculteurs cherchant à identifier des régions cultivées pour l'agriculture, nous voudrions privilégier un rappel plus élevé que la précision, afin de minimiser le nombre de faux négatifs (zones identifiées comme régions non cultivées qui sont en réalité des régions cultivées) afin d’optimiser l’utilisation des terres. Le score F1 sert de mesure de précision globale combinant à la fois la précision et le rappel, et mesurant l'équilibre entre les deux mesures. Un score F1 élevé, comme le nôtre pour les régions cultivées (0.82), indique un bon équilibre entre précision et rappel et une précision globale de classification élevée. Bien que le score F1 chute entre les ensembles de données de train et de test, cela est attendu car le classificateur a été formé sur l'ensemble de données de train. Un score F1 moyen pondéré global de 0.77 est prometteur et suffisamment adéquat pour essayer des schémas de segmentation sur les données classifiées.
Créer un masque de segmentation à partir du classificateur
La création d'un masque de segmentation à l'aide des prédictions du classificateur KNN sur l'ensemble de données de test implique de nettoyer la sortie prédite pour éviter les petits segments causés par le bruit de l'image. Pour supprimer le bruit de speckle, nous utilisons OpenCV filtre de flou médian. Ce filtre préserve mieux les délimitations routières entre les cultures que l'exploitation morphologique ouverte.

Pour appliquer la segmentation binaire à la sortie débruitée, nous devons d'abord convertir les données raster classées en entités vectorielles à l'aide d'OpenCV. trouverContours la fonction.

Enfin, les zones de culture segmentées réelles peuvent être calculées à l'aide des contours de culture segmentés.

Les régions cultivées segmentées produites à partir du classificateur KNN permettent une identification précise des régions cultivées dans l'ensemble de données de test. Ces régions segmentées peuvent être utilisées à diverses fins, telles que l'identification des limites des champs, la surveillance des cultures, l'estimation du rendement et l'allocation des ressources. Le score F1 obtenu de 0.77 est bon et prouve que le classificateur KNN est un outil efficace pour la segmentation des cultures dans les images de télédétection. Ces résultats peuvent être utilisés pour améliorer et affiner davantage les techniques de segmentation des cultures, conduisant potentiellement à une précision et une efficacité accrues dans l’analyse des cultures.
Conclusion
Cet article a montré comment vous pouvez utiliser la combinaison de La planète cadence élevée, imagerie satellite haute résolution et Capacités géospatiales de SageMaker pour effectuer une analyse de segmentation des cultures, libérant ainsi des informations précieuses qui peuvent améliorer l'efficacité agricole, la durabilité environnementale et la sécurité alimentaire. L'identification précise des régions cultivées permet une analyse plus approfondie de la croissance et de la productivité des cultures, la surveillance des changements d'utilisation des terres et la détection des risques potentiels pour la sécurité alimentaire.
De plus, la combinaison des données Planet et de SageMaker offre un large éventail de cas d'utilisation au-delà de la segmentation des cultures. Ces informations peuvent permettre de prendre des décisions basées sur des données sur la gestion des cultures, l'allocation des ressources et la planification des politiques agricoles uniquement. Avec différents modèles de données et de ML, l'offre combinée pourrait également s'étendre à d'autres secteurs et cas d'utilisation vers la transformation numérique, la transformation durable et la sécurité.
Pour commencer à utiliser les fonctionnalités géospatiales de SageMaker, consultez Démarrez avec les fonctionnalités géospatiales d'Amazon SageMaker.
Pour en savoir plus sur les spécifications d'imagerie de Planet et les documents de référence des développeurs, visitez Centre des développeurs de planètes. Pour obtenir de la documentation sur le SDK de Planet pour Python, voir SDK Planète pour Python. Pour plus d'informations sur Planet, y compris ses produits de données existants et les versions de produits à venir, visitez https://www.planet.com/.
Déclarations prospectives de Planet Labs PBC
À l'exception des informations historiques contenues dans le présent document, les questions exposées dans cet article de blog constituent des déclarations prospectives au sens des dispositions de « sphère de sécurité » de la loi Private Securities Litigation Reform Act de 1995, y compris, mais sans s'y limiter, Planet Labs. La capacité de PBC à saisir les opportunités du marché et à réaliser tous les avantages potentiels des améliorations de produits actuelles ou futures, des nouveaux produits ou des partenariats stratégiques et des collaborations avec les clients. Les déclarations prospectives sont basées sur les convictions de la direction de Planet Labs PBC, ainsi que sur les hypothèses formulées et les informations actuellement disponibles. Étant donné que ces déclarations sont basées sur des attentes quant à des événements et des résultats futurs et ne constituent pas des déclarations de fait, les résultats réels peuvent différer sensiblement de ceux projetés. Les facteurs qui peuvent faire en sorte que les résultats réels diffèrent sensiblement des attentes actuelles comprennent, sans s'y limiter, les facteurs de risque et autres informations sur Planet Labs PBC et ses activités incluses dans les rapports périodiques, les déclarations de procuration et autres documents d'information déposés de temps en temps par Planet Labs PBC. à temps avec la Securities and Exchange Commission (SEC) qui sont disponibles en ligne à l'adresse www.sec.gov, et sur le site Web de Planet Labs PBC à l'adresse www.planet.com. Toutes les déclarations prospectives reflètent les convictions et hypothèses de Planet Labs PBC uniquement à la date à laquelle ces déclarations sont faites. Planet Labs PBC ne s'engage aucunement à mettre à jour les déclarations prospectives pour refléter des événements ou des circonstances futurs.
À propos des auteurs
 Lydia Lihui Zhang est spécialiste du développement commercial chez Planet Labs PBC, où elle aide à connecter l'espace pour l'amélioration de la Terre dans divers secteurs et une myriade de cas d'utilisation. Auparavant, elle était data scientist chez McKinsey ACRE, une solution axée sur l'agriculture. Elle est titulaire d'une maîtrise ès sciences du programme de politique technologique du MIT, axée sur la politique spatiale. Les données géospatiales et leur impact plus large sur les affaires et le développement durable ont été son objectif de carrière.
Lydia Lihui Zhang est spécialiste du développement commercial chez Planet Labs PBC, où elle aide à connecter l'espace pour l'amélioration de la Terre dans divers secteurs et une myriade de cas d'utilisation. Auparavant, elle était data scientist chez McKinsey ACRE, une solution axée sur l'agriculture. Elle est titulaire d'une maîtrise ès sciences du programme de politique technologique du MIT, axée sur la politique spatiale. Les données géospatiales et leur impact plus large sur les affaires et le développement durable ont été son objectif de carrière.
 Mansi Shah est un ingénieur logiciel, un data scientist et un musicien dont le travail explore les espaces où se rencontrent rigueur artistique et curiosité technique. Elle croit que les données (comme l’art !) imitent la vie et s’intéresse aux histoires profondément humaines qui se cachent derrière les chiffres et les notes.
Mansi Shah est un ingénieur logiciel, un data scientist et un musicien dont le travail explore les espaces où se rencontrent rigueur artistique et curiosité technique. Elle croit que les données (comme l’art !) imitent la vie et s’intéresse aux histoires profondément humaines qui se cachent derrière les chiffres et les notes.
 Xiong Zhou est un scientifique appliqué senior chez AWS. Il dirige l'équipe scientifique chargée des capacités géospatiales d'Amazon SageMaker. Son domaine de recherche actuel comprend la vision par ordinateur et la formation efficace de modèles. Dans ses temps libres, il aime courir, jouer au basket-ball et passer du temps avec sa famille.
Xiong Zhou est un scientifique appliqué senior chez AWS. Il dirige l'équipe scientifique chargée des capacités géospatiales d'Amazon SageMaker. Son domaine de recherche actuel comprend la vision par ordinateur et la formation efficace de modèles. Dans ses temps libres, il aime courir, jouer au basket-ball et passer du temps avec sa famille.
 Janosch Woschitz est architecte de solutions senior chez AWS, spécialisé dans l'IA/ML géospatiale. Avec plus de 15 ans d'expérience, il aide ses clients du monde entier à tirer parti de l'IA et du ML pour des solutions innovantes qui capitalisent sur les données géospatiales. Son expertise couvre l'apprentissage automatique, l'ingénierie des données et les systèmes distribués évolutifs, complétée par une solide expérience en ingénierie logicielle et une expertise industrielle dans des domaines complexes tels que la conduite autonome.
Janosch Woschitz est architecte de solutions senior chez AWS, spécialisé dans l'IA/ML géospatiale. Avec plus de 15 ans d'expérience, il aide ses clients du monde entier à tirer parti de l'IA et du ML pour des solutions innovantes qui capitalisent sur les données géospatiales. Son expertise couvre l'apprentissage automatique, l'ingénierie des données et les systèmes distribués évolutifs, complétée par une solide expérience en ingénierie logicielle et une expertise industrielle dans des domaines complexes tels que la conduite autonome.
 Shital Dhakal est responsable de programme principal au sein de l'équipe géospatiale ML de SageMaker basée dans la région de la baie de San Francisco. Il a une formation en télédétection et en système d'information géographique (SIG). Il est passionné par la compréhension des problèmes des clients et par la création de produits géospatiaux pour les résoudre. Dans ses temps libres, il aime faire de la randonnée, voyager et jouer au tennis.
Shital Dhakal est responsable de programme principal au sein de l'équipe géospatiale ML de SageMaker basée dans la région de la baie de San Francisco. Il a une formation en télédétection et en système d'information géographique (SIG). Il est passionné par la compréhension des problèmes des clients et par la création de produits géospatiaux pour les résoudre. Dans ses temps libres, il aime faire de la randonnée, voyager et jouer au tennis.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/build-a-crop-segmentation-machine-learning-model-with-planet-data-and-amazon-sagemaker-geospatial-capabilities/

