Cet article est co-écrit avec Jayadeep Pabbisetty, spécialiste senior en ingénierie des données chez Merck, et Prabakaran Mathaiyan, ingénieur senior en ML chez Tiger Analytics.
Le cycle de vie de développement de modèles d’apprentissage automatique (ML) à grande échelle nécessite un processus de publication de modèles évolutif similaire à celui du développement de logiciels. Les développeurs de modèles travaillent souvent ensemble pour développer des modèles ML et ont besoin d'une plate-forme MLOps robuste. Une plate-forme MLOps évolutive doit inclure un processus pour gérer le flux de travail du registre, de l'approbation et de la promotion des modèles ML au niveau d'environnement suivant (développement, test). , UAT ou production).
Un développeur de modèles commence généralement à travailler dans un environnement de développement ML individuel au sein Amazon Sage Maker. Lorsqu'un modèle est formé et prêt à être utilisé, il doit être approuvé après avoir été enregistré dans le Registre de modèles Amazon SageMaker. Dans cet article, nous expliquons comment l'équipe AWS AI/ML a collaboré avec l'équipe Merck Human Health IT MLOps pour créer une solution qui utilise un flux de travail automatisé pour l'approbation et la promotion du modèle ML avec une intervention humaine au milieu.
Présentation de la solution
Cet article se concentre sur une solution de workflow que le cycle de vie de développement du modèle ML peut utiliser entre le pipeline de formation et le pipeline d'inférence. La solution fournit un flux de travail évolutif pour les MLOps en prenant en charge le processus d'approbation et de promotion du modèle ML avec intervention humaine. Un modèle ML enregistré par un data scientist doit être examiné et approuvé par un approbateur avant d'être utilisé pour un pipeline d'inférence et dans le niveau d'environnement suivant (test, UAT ou production). La solution utilise AWS Lambda, Passerelle d'API Amazon, Amazon Event Bridge, et SageMaker pour automatiser le flux de travail avec une intervention d'approbation humaine au milieu. Le diagramme d'architecture suivant montre la conception globale du système, les services AWS utilisés et le flux de travail d'approbation et de promotion des modèles ML avec intervention humaine, du développement à la production.
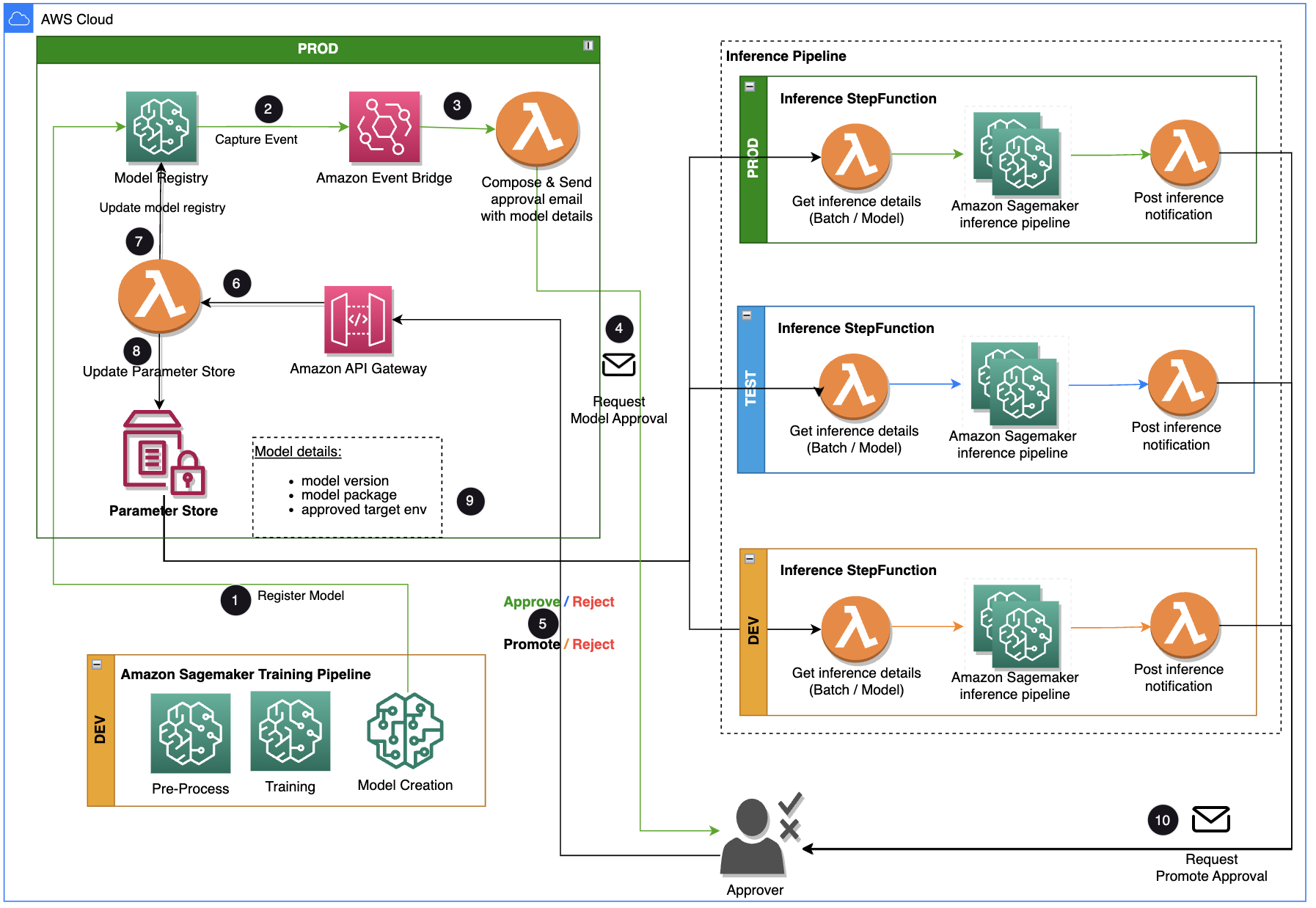
Le workflow comprend les étapes suivantes:
- Le pipeline de formation développe et enregistre un modèle dans le registre de modèles SageMaker. À ce stade, le statut du modèle est
PendingManualApproval. - EventBridge surveille les événements de changement de statut pour prendre automatiquement des mesures avec des règles simples.
- La règle d'événement d'enregistrement de modèle EventBridge appelle une fonction Lambda qui construit un e-mail avec un lien pour approuver ou rejeter le modèle enregistré.
- L'approbateur reçoit un e-mail avec le lien pour examiner et approuver ou rejeter le modèle.
- L'approbateur approuve le modèle en suivant le lien contenu dans l'e-mail vers un point de terminaison API Gateway.
- API Gateway appelle une fonction Lambda pour lancer les mises à jour du modèle.
- Le registre des modèles est mis à jour pour le statut du modèle (
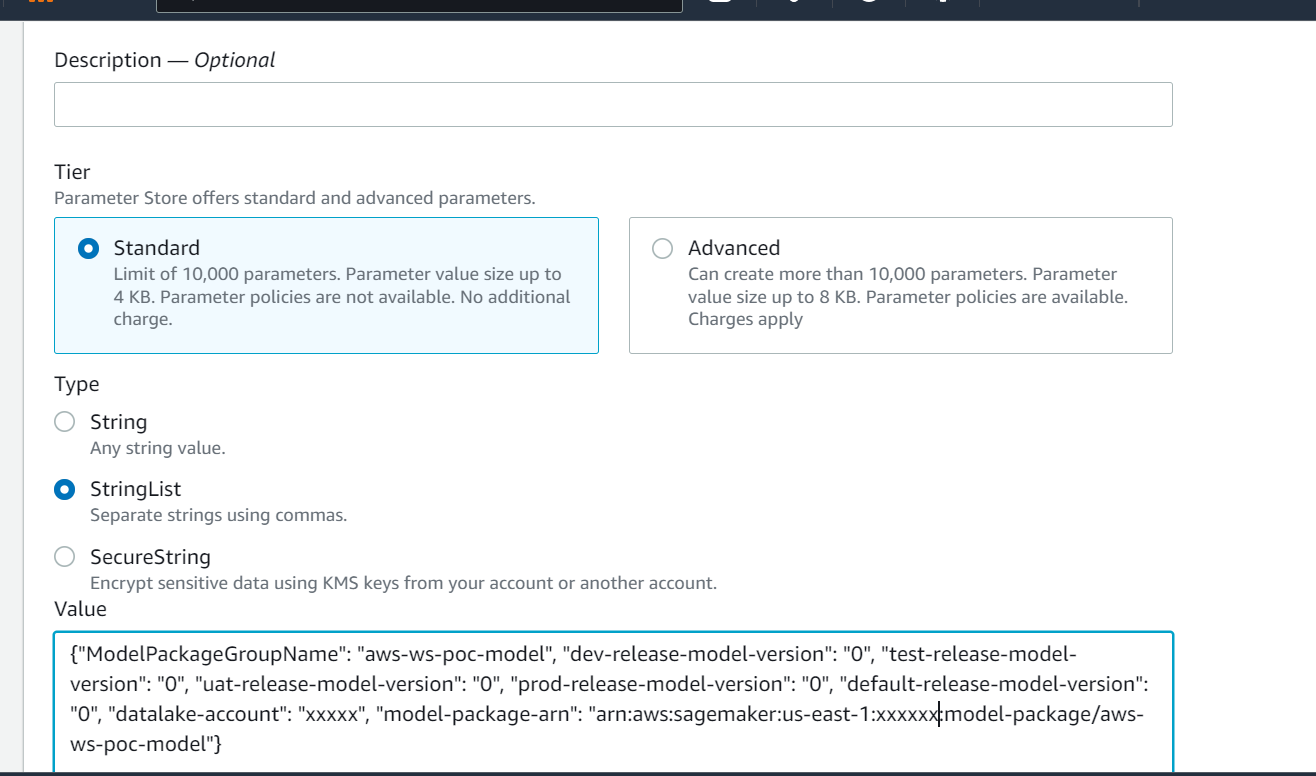
Approvedpour l'environnement de développement, maisPendingManualApprovalpour le test, l'UAT et la production). - Les détails du modèle sont stockés dans Magasin de paramètres AWS, une capacité de Gestionnaire de systèmes AWS, y compris la version du modèle, l'environnement cible approuvé et le package de modèle.
- Le pipeline d'inférence récupère le modèle approuvé pour l'environnement cible à partir de Parameter Store.
- La fonction Lambda de notification post-inférence collecte des métriques d'inférence par lots et envoie un e-mail à l'approbateur pour promouvoir le modèle dans l'environnement suivant.
Pré-requis
Le flux de travail de cet article suppose que l'environnement du pipeline de formation est configuré dans SageMaker, avec d'autres ressources. L’entrée du pipeline de formation est l’ensemble de données de fonctionnalités. Les détails de la génération de fonctionnalités ne sont pas inclus dans cet article, mais ils se concentrent sur le registre, l'approbation et la promotion des modèles ML après leur formation. Le modèle est enregistré dans le registre des modèles et est régi par un cadre de suivi en Moniteur de modèle Amazon SageMaker pour détecter toute dérive et procéder au recyclage en cas de dérive du modèle.
Détails du flux de travail
Le flux de travail d'approbation commence par un modèle développé à partir d'un pipeline de formation. Lorsque les data scientists développent un modèle, ils l'enregistrent dans le registre des modèles SageMaker avec le statut de modèle de PendingManualApproval. EventBridge surveille SageMaker pour l'événement d'enregistrement de modèle et déclenche une règle d'événement qui appelle une fonction Lambda. La fonction Lambda construit dynamiquement un e-mail pour l'approbation du modèle avec un lien vers un point de terminaison API Gateway vers une autre fonction Lambda. Lorsque l'approbateur suit le lien pour approuver le modèle, API Gateway transmet l'action d'approbation à la fonction Lambda, qui met à jour le registre de modèles SageMaker et les attributs du modèle dans Parameter Store. L'approbateur doit être authentifié et faire partie du groupe d'approbateurs géré par Active Directory. L'approbation initiale marque le modèle comme Approved pour les développeurs mais PendingManualApproval pour les tests, l'UAT et la production. Les attributs de modèle enregistrés dans Parameter Store incluent la version du modèle, le package de modèle et l'environnement cible approuvé.
Lorsqu'un pipeline d'inférence doit récupérer un modèle, il vérifie dans Parameter Store la dernière version du modèle approuvée pour l'environnement cible et obtient les détails de l'inférence. Lorsque le pipeline d'inférence est terminé, un e-mail de notification post-inférence est envoyé à une partie prenante demandant une approbation pour promouvoir le modèle au niveau d'environnement suivant. L'e-mail contient des détails sur le modèle et les métriques, ainsi qu'un lien d'approbation vers un point de terminaison API Gateway pour une fonction Lambda qui met à jour les attributs du modèle.
Voici la séquence d'événements et les étapes de mise en œuvre du flux de travail d'approbation/promotion du modèle ML, de la création du modèle à la production. Le modèle est promu depuis les environnements de développement jusqu'aux environnements de test, d'UAT et de production avec une approbation humaine explicite à chaque étape.
Nous commençons par le pipeline de formation, qui est prêt pour le développement du modèle. La version du modèle commence par 0 dans le registre des modèles SageMaker.
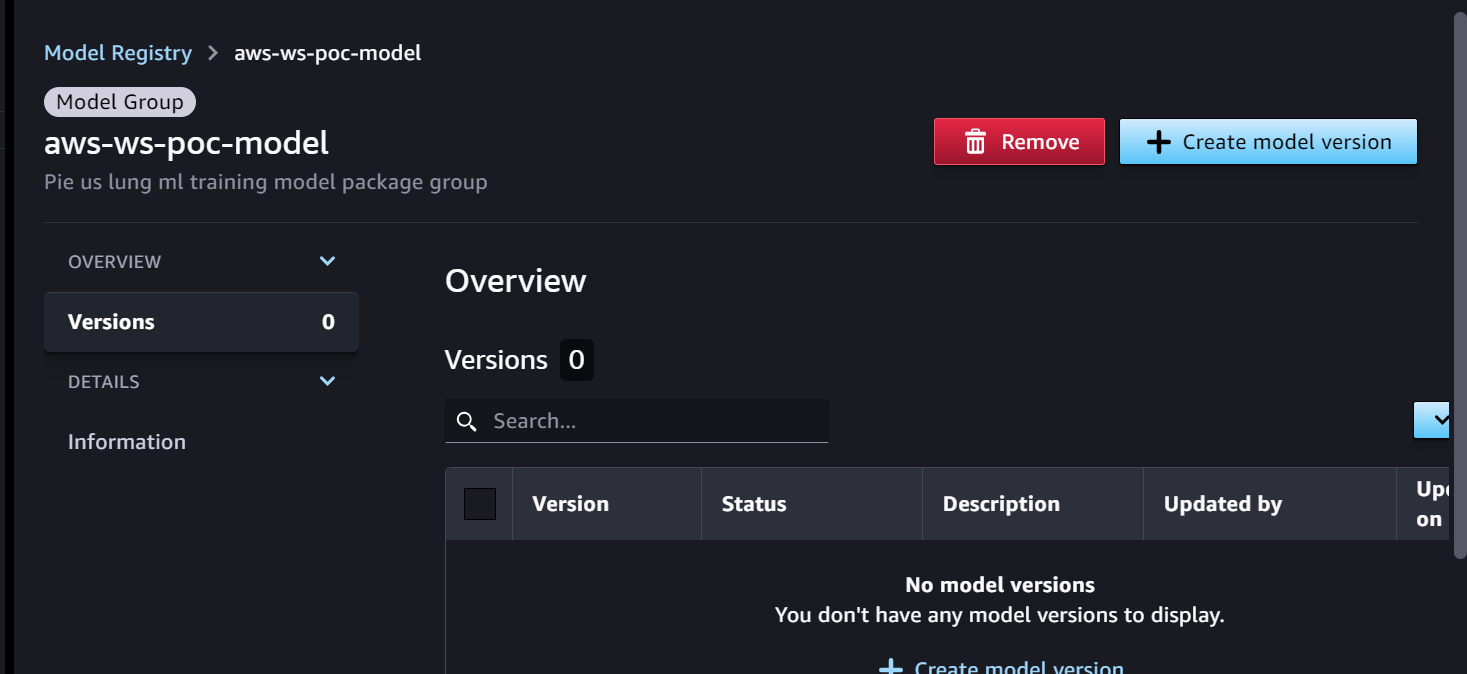
- Le pipeline de formation SageMaker développe et enregistre un modèle dans le registre des modèles SageMaker. La version 1 du modèle est enregistrée et commence par En attente d'approbation manuelle état.
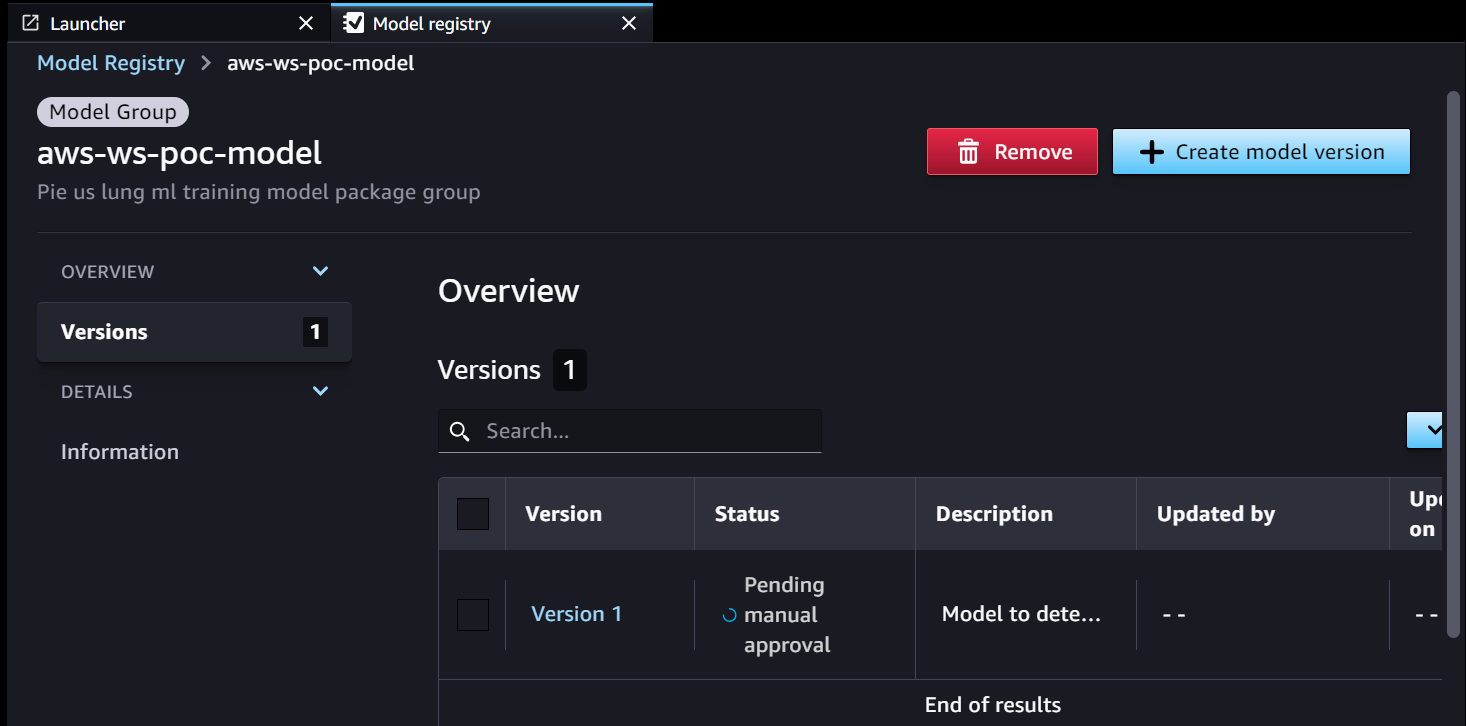 Les métadonnées du Model Registry comportent quatre champs personnalisés pour les environnements :
Les métadonnées du Model Registry comportent quatre champs personnalisés pour les environnements : dev, test, uatetprod.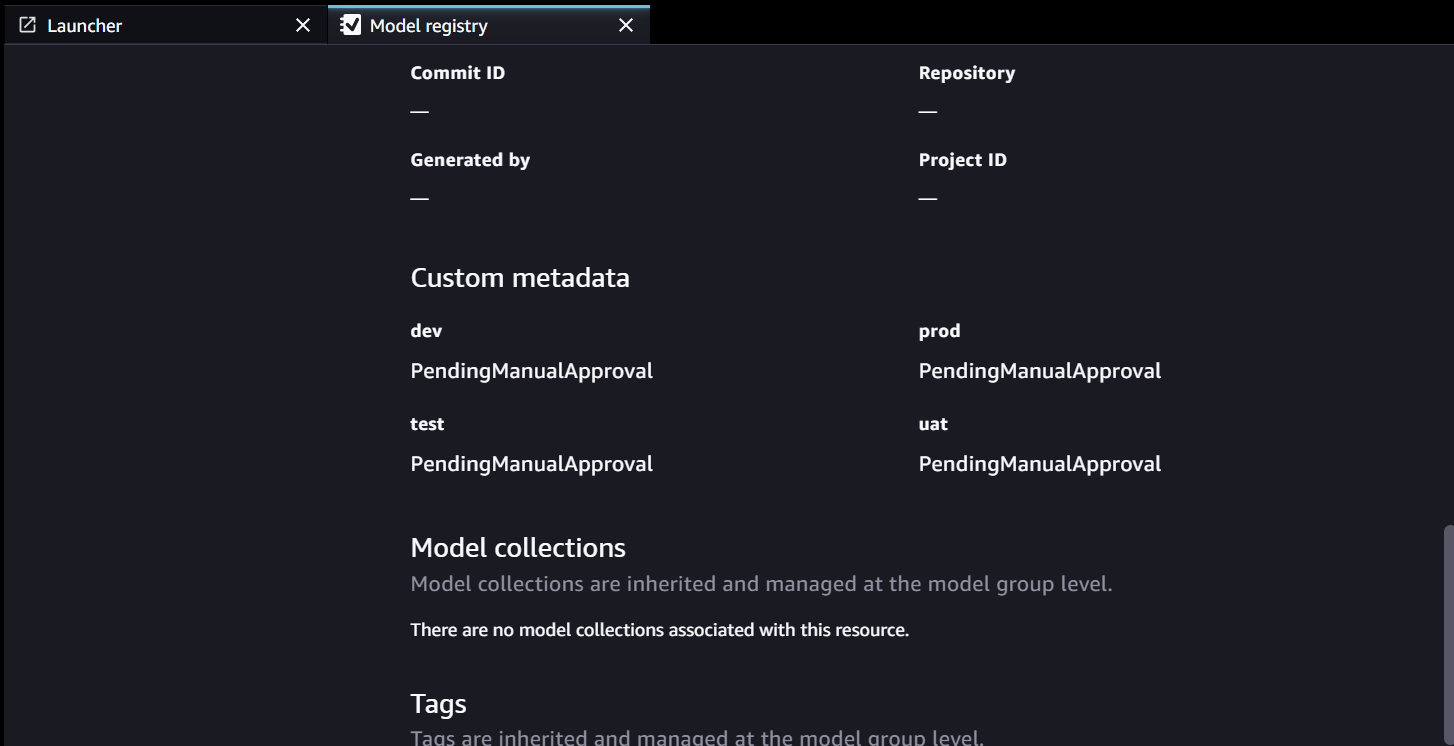
- EventBridge surveille le registre de modèles SageMaker pour détecter le changement de statut afin d'agir automatiquement avec des règles simples.
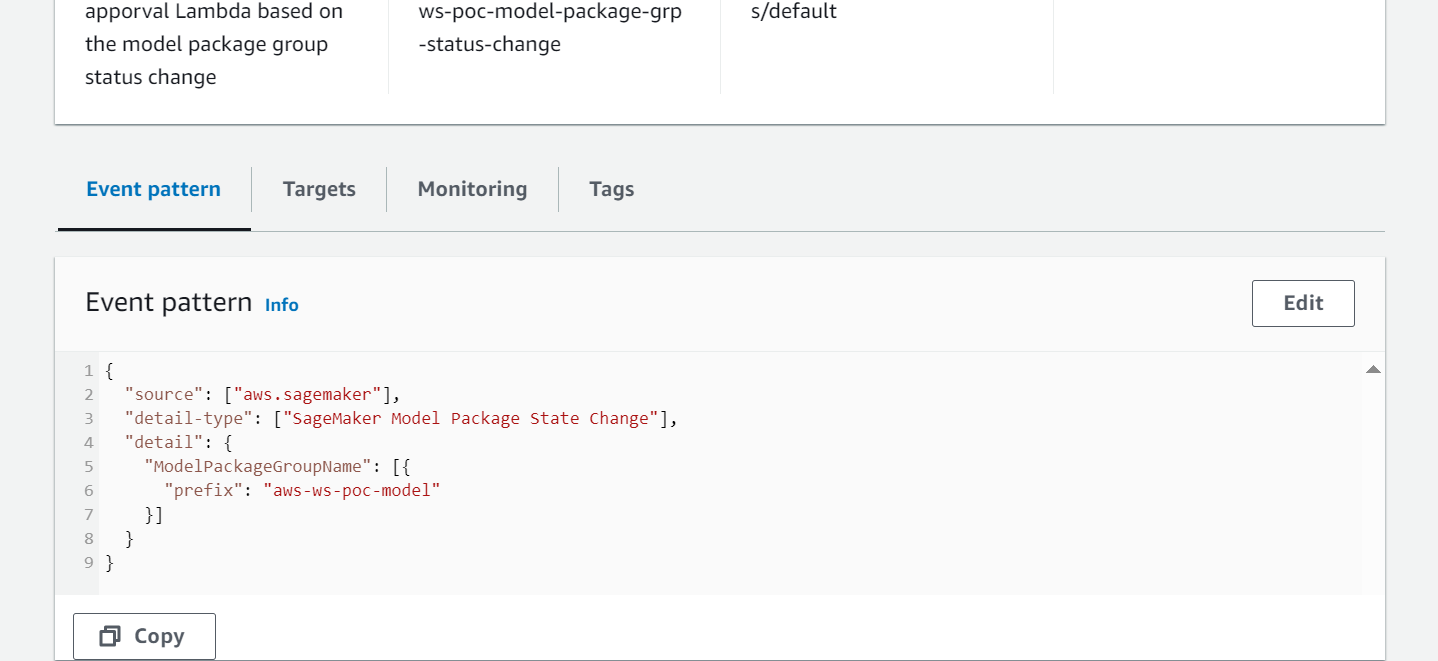
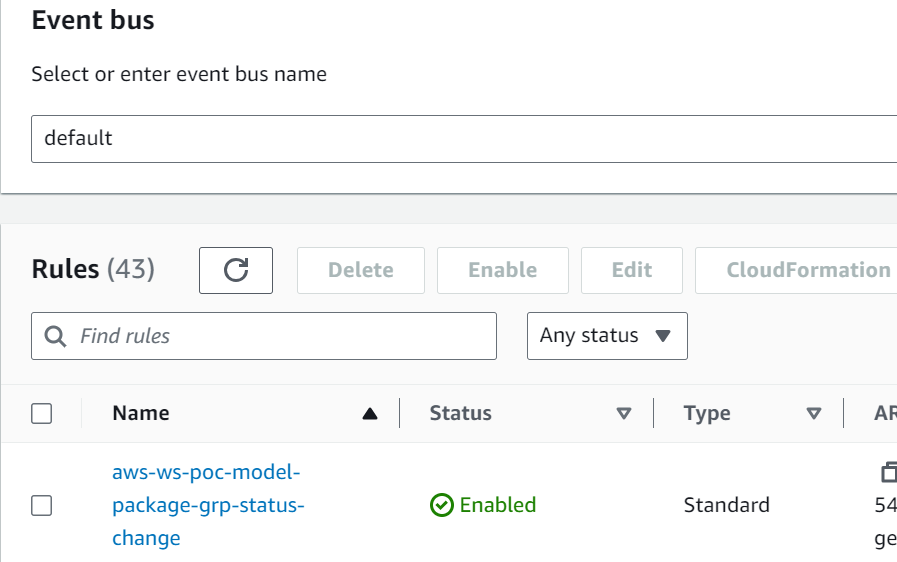
- La règle d'événement d'enregistrement de modèle appelle une fonction Lambda qui construit un e-mail avec le lien pour approuver ou rejeter le modèle enregistré.
- L'approbateur reçoit un e-mail avec le lien pour examiner et approuver (ou rejeter) le modèle.

- L'approbateur approuve le modèle en suivant le lien vers le point de terminaison API Gateway dans l'e-mail.
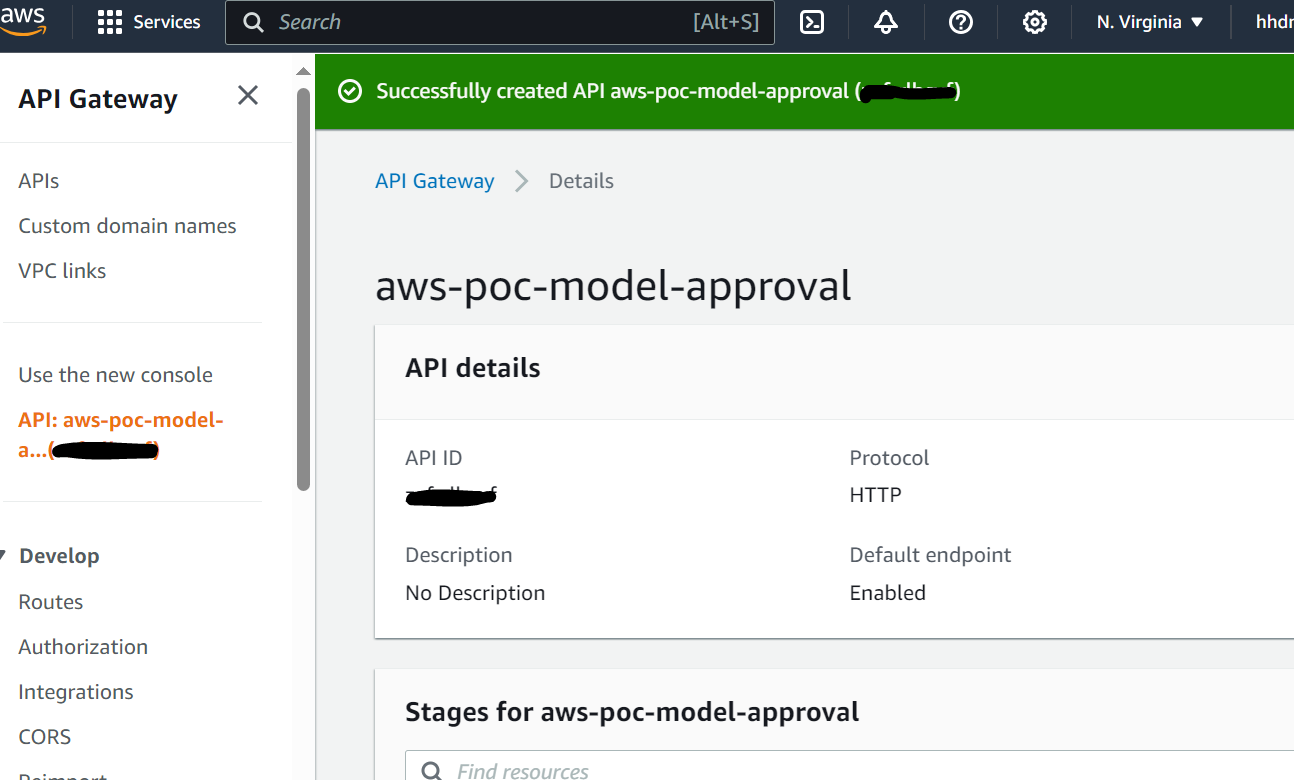
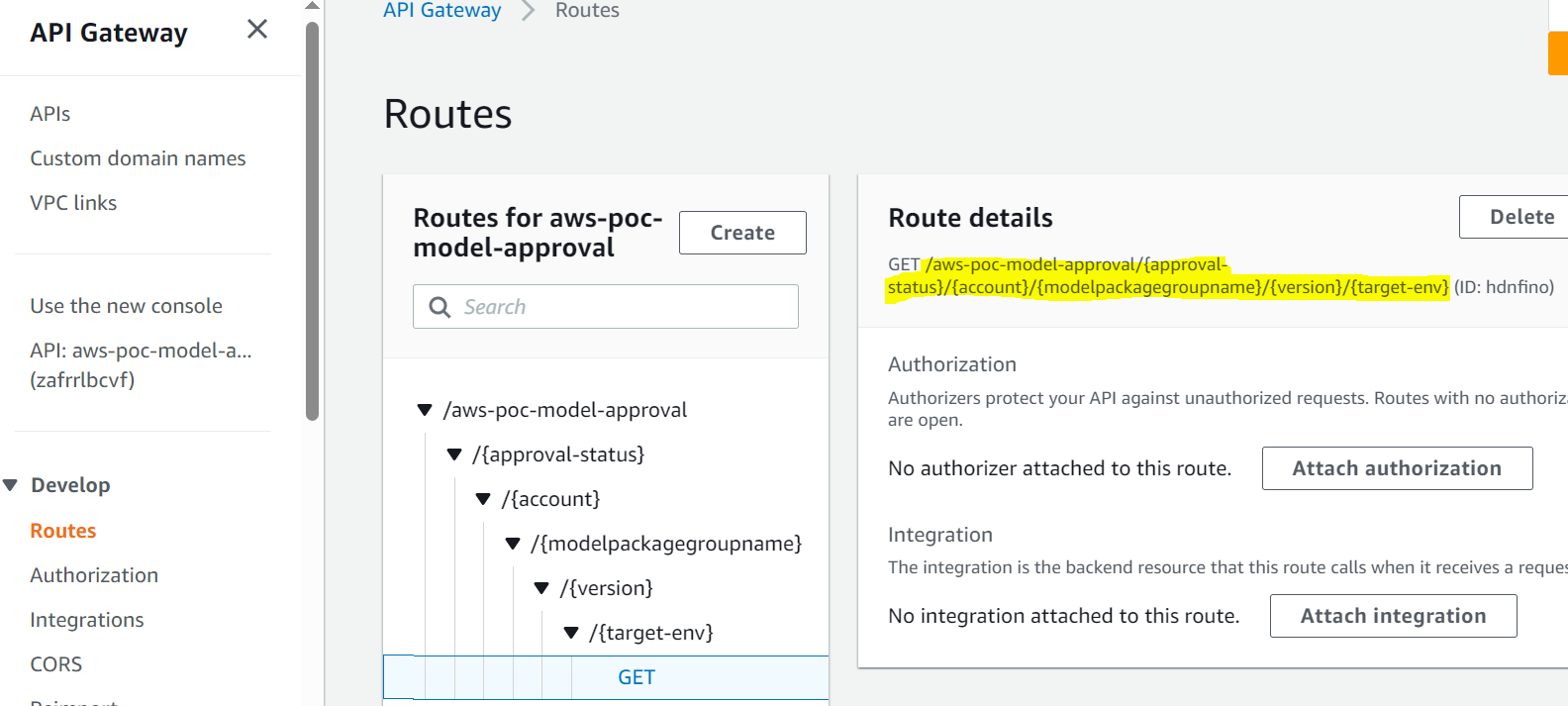
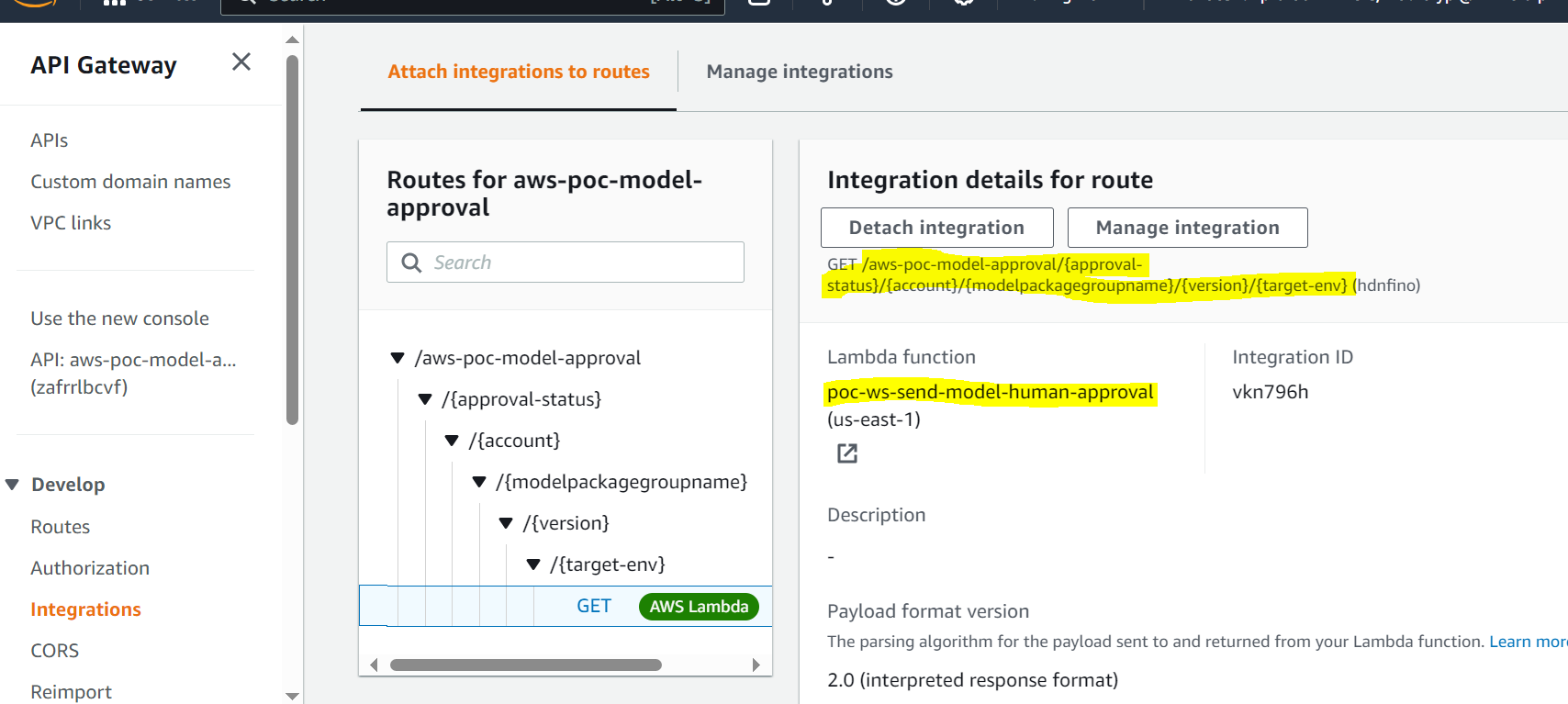
- API Gateway appelle la fonction Lambda pour lancer les mises à jour du modèle.
- Le registre des modèles SageMaker est mis à jour avec l'état du modèle.

- Les informations détaillées du modèle sont stockées dans Parameter Store, y compris la version du modèle, l'environnement cible approuvé et le package de modèle.
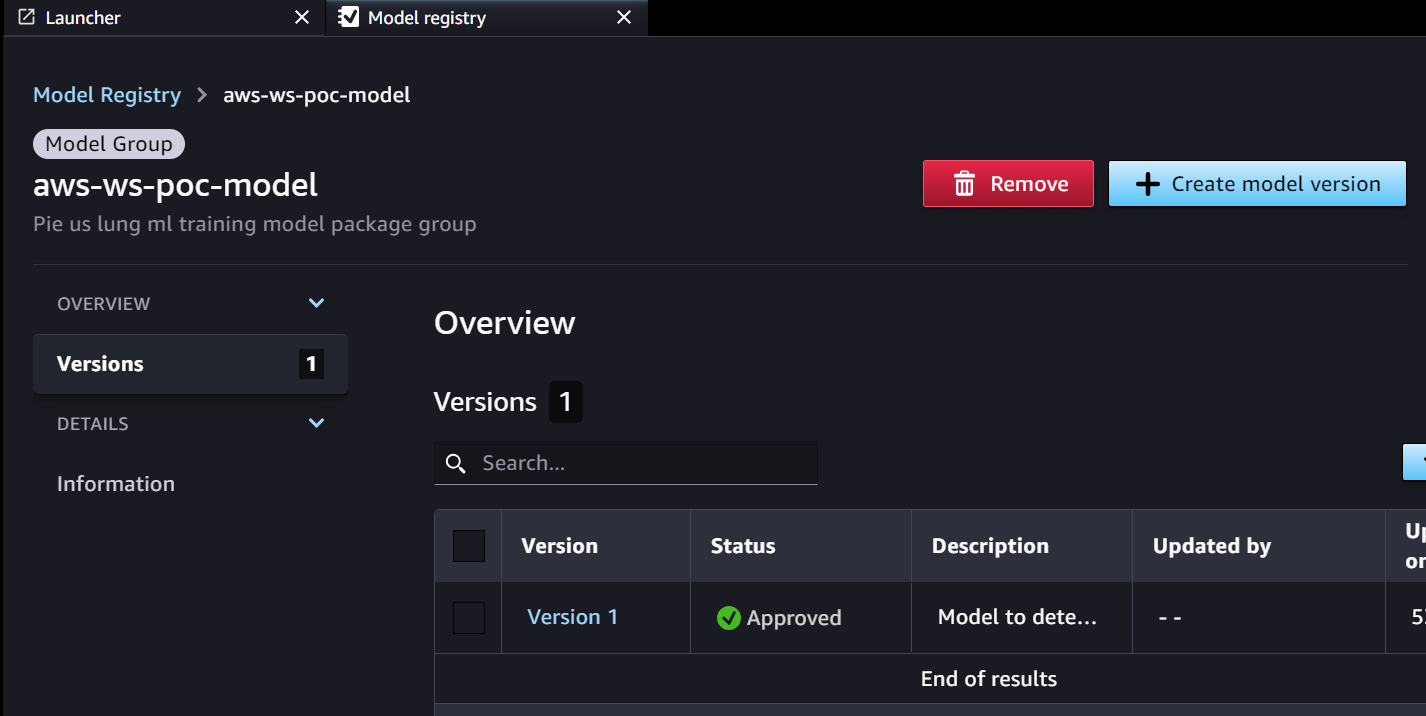

- Le pipeline d'inférence récupère le modèle approuvé pour l'environnement cible à partir de Parameter Store.
- La fonction Lambda de notification post-inférence collecte des métriques d'inférence par lots et envoie un e-mail à l'approbateur pour promouvoir le modèle dans l'environnement suivant.
- L'approbateur approuve la promotion du modèle au niveau suivant en suivant le lien vers le point de terminaison API Gateway, ce qui déclenche la fonction Lambda pour mettre à jour le registre de modèles et le magasin de paramètres SageMaker.
L'historique complet de la gestion des versions et de l'approbation du modèle est enregistré pour examen dans Parameter Store.

Conclusion
Le cycle de vie de développement d'un modèle ML à grande échelle nécessite un processus d'approbation du modèle ML évolutif. Dans cet article, nous avons partagé une implémentation d'un workflow de registre, d'approbation et de promotion de modèles ML avec intervention humaine à l'aide de SageMaker Model Registry, EventBridge, API Gateway et Lambda. Si vous envisagez un processus de développement de modèle ML évolutif pour votre plate-forme MLOps, vous pouvez suivre les étapes de cet article pour mettre en œuvre un flux de travail similaire.
À propos des auteurs
 Tom-Kim est architecte de solutions senior chez AWS, où il aide ses clients à atteindre leurs objectifs commerciaux en développant des solutions sur AWS. Il possède une vaste expérience de l'architecture et des opérations de systèmes d'entreprise dans plusieurs secteurs, en particulier dans les soins de santé et les sciences de la vie. Tom apprend toujours de nouvelles technologies qui conduisent aux résultats commerciaux souhaités pour les clients – par ex. IA/ML, GenAI et analyse de données. Il aime également voyager vers de nouveaux endroits et jouer sur de nouveaux terrains de golf chaque fois qu'il en trouve le temps.
Tom-Kim est architecte de solutions senior chez AWS, où il aide ses clients à atteindre leurs objectifs commerciaux en développant des solutions sur AWS. Il possède une vaste expérience de l'architecture et des opérations de systèmes d'entreprise dans plusieurs secteurs, en particulier dans les soins de santé et les sciences de la vie. Tom apprend toujours de nouvelles technologies qui conduisent aux résultats commerciaux souhaités pour les clients – par ex. IA/ML, GenAI et analyse de données. Il aime également voyager vers de nouveaux endroits et jouer sur de nouveaux terrains de golf chaque fois qu'il en trouve le temps.
 Shamika Ariyawansa, architecte principal de solutions IA/ML dans la division Santé et Sciences de la vie d'Amazon Web Services (AWS), se spécialise dans l'IA générative, en mettant l'accent sur la formation des grands modèles linguistiques (LLM), les optimisations d'inférence et le MLOps (Machine Learning). Opérations). Il guide les clients dans l'intégration de l'IA générative avancée dans leurs projets, garantissant des processus de formation robustes, des mécanismes d'inférence efficaces et des pratiques MLOps rationalisées pour des solutions d'IA efficaces et évolutives. Au-delà de ses engagements professionnels, Shamika poursuit avec passion les aventures de ski et de tout-terrain.
Shamika Ariyawansa, architecte principal de solutions IA/ML dans la division Santé et Sciences de la vie d'Amazon Web Services (AWS), se spécialise dans l'IA générative, en mettant l'accent sur la formation des grands modèles linguistiques (LLM), les optimisations d'inférence et le MLOps (Machine Learning). Opérations). Il guide les clients dans l'intégration de l'IA générative avancée dans leurs projets, garantissant des processus de formation robustes, des mécanismes d'inférence efficaces et des pratiques MLOps rationalisées pour des solutions d'IA efficaces et évolutives. Au-delà de ses engagements professionnels, Shamika poursuit avec passion les aventures de ski et de tout-terrain.
 Jayadeep Pabbisetty est ingénieur ML/Data senior chez Merck, où il conçoit et développe des solutions ETL et MLOps pour débloquer la science et l'analyse des données pour l'entreprise. Il est toujours enthousiaste à l'idée d'apprendre de nouvelles technologies, d'explorer de nouvelles avenues et d'acquérir les compétences nécessaires pour évoluer avec l'industrie informatique en constante évolution. Dans ses temps libres, il poursuit sa passion pour le sport et aime voyager et explorer de nouveaux endroits.
Jayadeep Pabbisetty est ingénieur ML/Data senior chez Merck, où il conçoit et développe des solutions ETL et MLOps pour débloquer la science et l'analyse des données pour l'entreprise. Il est toujours enthousiaste à l'idée d'apprendre de nouvelles technologies, d'explorer de nouvelles avenues et d'acquérir les compétences nécessaires pour évoluer avec l'industrie informatique en constante évolution. Dans ses temps libres, il poursuit sa passion pour le sport et aime voyager et explorer de nouveaux endroits.
 Prabakaran Mathaiyan est ingénieur senior en apprentissage automatique chez Tiger Analytics LLC, où il aide ses clients à atteindre leurs objectifs commerciaux en fournissant des solutions pour la création de modèles, la formation, la validation, la surveillance, le CICD et l'amélioration des solutions d'apprentissage automatique sur AWS. Prabakaran apprend constamment de nouvelles technologies qui conduisent aux résultats commerciaux souhaités pour les clients – par ex. AI/ML, GenAI, GPT et LLM. Il aime également jouer au cricket chaque fois qu'il en trouve le temps.
Prabakaran Mathaiyan est ingénieur senior en apprentissage automatique chez Tiger Analytics LLC, où il aide ses clients à atteindre leurs objectifs commerciaux en fournissant des solutions pour la création de modèles, la formation, la validation, la surveillance, le CICD et l'amélioration des solutions d'apprentissage automatique sur AWS. Prabakaran apprend constamment de nouvelles technologies qui conduisent aux résultats commerciaux souhaités pour les clients – par ex. AI/ML, GenAI, GPT et LLM. Il aime également jouer au cricket chaque fois qu'il en trouve le temps.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/build-an-amazon-sagemaker-model-registry-approval-and-promotion-workflow-with-human-intervention/

