Débloquer des réponses précises et perspicaces à partir de grandes quantités de texte est une capacité intéressante offerte par les grands modèles linguistiques (LLM). Lors de la création d'applications LLM, il est souvent nécessaire de connecter et d'interroger des sources de données externes pour fournir un contexte pertinent au modèle. Une approche populaire consiste à utiliser la génération augmentée de récupération (RAG) pour créer des systèmes de questions et réponses qui comprennent des informations complexes et fournissent des réponses naturelles aux requêtes. RAG permet aux modèles d'exploiter de vastes bases de connaissances et de proposer un dialogue de type humain pour des applications telles que les chatbots et les assistants de recherche d'entreprise.
Dans cet article, nous explorons comment exploiter la puissance de LamaIndex, Lama 2-70B-Chatet LangChaîne pour créer de puissantes applications de questions-réponses. Grâce à ces technologies de pointe, vous pouvez ingérer des corpus de textes, indexer des connaissances critiques et générer du texte qui répond avec précision et clarté aux questions des utilisateurs.
Lama 2-70B-Chat
Llama 2-70B-Chat est un LLM puissant qui rivalise avec les principaux modèles. Il est pré-entraîné sur deux billions de jetons de texte et destiné par Meta à être utilisé pour l'assistance par chat aux utilisateurs. Les données de pré-formation proviennent de données accessibles au public et se terminent en septembre 2022, et les données de réglage fin se terminent en juillet 2023. Pour plus de détails sur le processus de formation du modèle, les considérations de sécurité, les apprentissages et les utilisations prévues, reportez-vous au document. Llama 2 : fondation ouverte et modèles de discussion affinés. Les modèles Llama 2 sont disponibles sur Amazon SageMaker JumpStart pour un déploiement rapide et simple.
LamaIndex
LamaIndex est un framework de données qui permet de créer des applications LLM. Il fournit des outils offrant des connecteurs de données pour ingérer vos données existantes avec diverses sources et formats (PDF, documents, API, SQL, etc.). Que vous ayez des données stockées dans des bases de données ou dans des PDF, LlamaIndex facilite l'utilisation de ces données pour les LLM. Comme nous le démontrons dans cet article, les API LlamaIndex facilitent l'accès aux données et vous permettent de créer de puissantes applications et flux de travail LLM personnalisés.
Si vous expérimentez et construisez des LLM, vous connaissez probablement LangChain, qui offre un cadre robuste, simplifiant le développement et le déploiement d'applications basées sur LLM. Semblable à LangChain, LlamaIndex propose un certain nombre d'outils, notamment des connecteurs de données, des index de données, des moteurs et des agents de données, ainsi que des intégrations d'applications telles que des outils et l'observabilité, le traçage et l'évaluation. LlamaIndex s'efforce de combler le fossé entre les données et les puissants LLM, en rationalisant les tâches de données avec des fonctionnalités conviviales. LlamaIndex est spécialement conçu et optimisé pour la création d'applications de recherche et de récupération, telles que RAG, car il fournit une interface simple pour interroger les LLM et récupérer les documents pertinents.
Vue d'ensemble de la solution
Dans cet article, nous montrons comment créer une application basée sur RAG à l'aide de LlamaIndex et d'un LLM. Le diagramme suivant montre l'architecture étape par étape de cette solution décrite dans les sections suivantes.
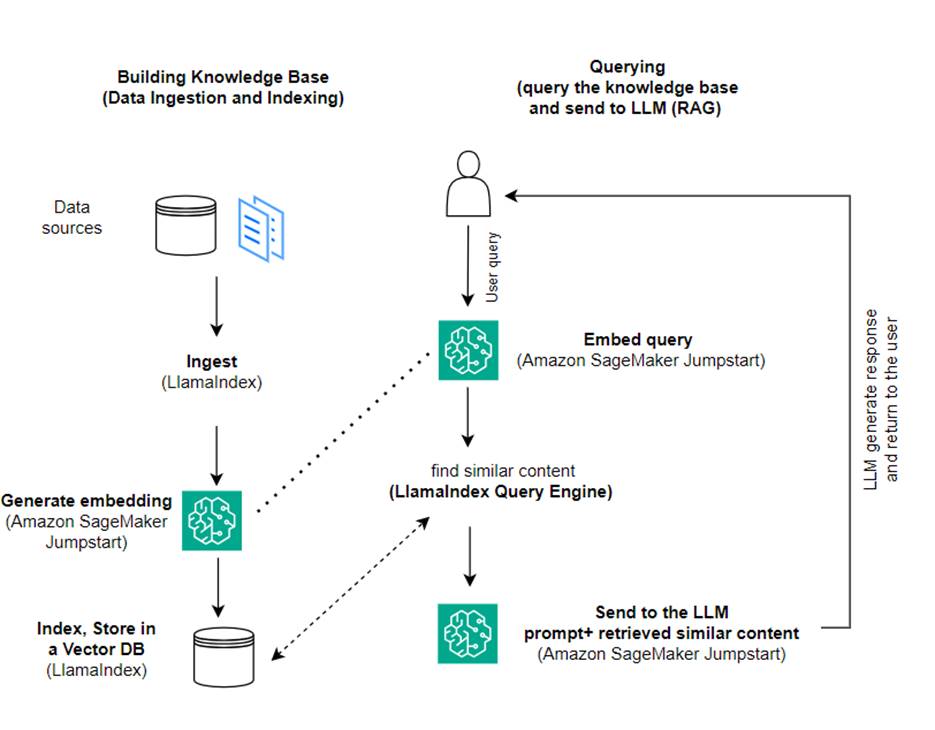
RAG combine la récupération d'informations avec la génération de langage naturel pour produire des réponses plus pertinentes. Lorsque vous y êtes invité, RAG recherche d'abord des corpus de texte pour récupérer les exemples les plus pertinents par rapport à l'entrée. Lors de la génération de réponses, le modèle prend en compte ces exemples pour augmenter ses capacités. En incorporant des passages récupérés pertinents, les réponses RAG ont tendance à être plus factuelles, cohérentes et cohérentes avec le contexte par rapport aux modèles génératifs de base. Ce cadre de récupération-génération tire parti des atouts de la récupération et de la génération, aidant à résoudre des problèmes tels que la répétition et le manque de contexte qui peuvent découler de modèles conversationnels autorégressifs purs. RAG introduit une approche efficace pour créer des agents conversationnels et des assistants IA avec des réponses contextualisées et de haute qualité.
La construction de la solution comprend les étapes suivantes :
- Mettre en place Amazon SageMakerStudio comme environnement de développement et installez les dépendances requises.
- Déployez un modèle d'intégration à partir du hub Amazon SageMaker JumpStart.
- Téléchargez les communiqués de presse à utiliser comme base de connaissances externe.
- Créez un index à partir des communiqués de presse pour pouvoir interroger et ajouter un contexte supplémentaire à l'invite.
- Interrogez la base de connaissances.
- Créez une application de questions-réponses à l'aide des agents LlamaIndex et LangChain.
Tout le code de cet article est disponible dans le GitHub repo.
Pré-requis
Pour cet exemple, vous avez besoin d'un compte AWS avec un domaine SageMaker et approprié Gestion des identités et des accès AWS (IAM). Pour les instructions de configuration du compte, voir Créer un compte AWS. Si vous n'avez pas encore de domaine SageMaker, reportez-vous à Domaine Amazon SageMaker aperçu pour en créer un. Dans cet article, nous utilisons le AmazonSageMakerFullAccess rôle. Il n'est pas recommandé d'utiliser ces informations d'identification dans un environnement de production. Au lieu de cela, vous devez créer et utiliser un rôle avec les autorisations de moindre privilège. Vous pouvez également découvrir comment utiliser Gestionnaire de rôles Amazon SageMaker pour créer et gérer des rôles IAM basés sur les personnalités pour les besoins courants d'apprentissage automatique directement via la console SageMaker.
De plus, vous devez accéder à un minimum des tailles d'instance suivantes :
- ml.g5.2xlarge pour l'utilisation du point de terminaison lors du déploiement du Visage câlin GPT-J modèle d'incorporation de texte
- ml.g5.48xlarge pour l'utilisation du point de terminaison lors du déploiement du point de terminaison du modèle Llama 2-Chat
Pour augmenter votre quota, reportez-vous à Demander une augmentation de quota.
Déployer un modèle d'intégration GPT-J à l'aide de SageMaker JumpStart
Cette section vous propose deux options lors du déploiement de modèles SageMaker JumpStart. Vous pouvez utiliser un déploiement basé sur du code à l'aide du code fourni ou utiliser l'interface utilisateur (UI) de SageMaker JumpStart.
Déployer avec le SDK SageMaker Python
Vous pouvez utiliser le SDK SageMaker Python pour déployer les LLM, comme indiqué dans le code disponible dans le dépôt. Effectuez les étapes suivantes :
- Définissez la taille de l'instance à utiliser pour le déploiement du modèle d'intégration à l'aide de
instance_type = "ml.g5.2xlarge" - Recherchez l'ID du modèle à utiliser pour les intégrations. Dans SageMaker JumpStart, il est identifié comme
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Récupérez le conteneur de modèle pré-entraîné et déployez-le pour l'inférence.
SageMaker renverra le nom du point de terminaison du modèle et le message suivant lorsque le modèle d'intégration aura été déployé avec succès :
Déployer avec SageMaker JumpStart dans SageMaker Studio
Pour déployer le modèle à l'aide de SageMaker JumpStart dans Studio, procédez comme suit :
- Sur la console SageMaker Studio, choisissez JumpStart dans le volet de navigation.

- Recherchez et choisissez le modèle GPT-J 6B Embedding FP16.
- Choisissez Déployer et personnalisez la configuration du déploiement.

- Pour cet exemple, nous avons besoin d'une instance ml.g5.2xlarge, qui est l'instance par défaut suggérée par SageMaker JumpStart.
- Choisissez à nouveau Déployer pour créer le point de terminaison.
Le point final prendra environ 5 à 10 minutes pour être en service.

Après avoir déployé le modèle d'intégration, afin d'utiliser l'intégration LangChain avec les API SageMaker, vous devez créer une fonction pour gérer les entrées (texte brut) et les transformer en intégrations à l'aide du modèle. Pour ce faire, créez une classe appelée ContentHandler, qui prend un JSON de données d'entrée et renvoie un JSON d'incorporations de texte : class ContentHandler(EmbeddingsContentHandler).
Transmettez le nom du point de terminaison du modèle au ContentHandler fonction pour convertir le texte et renvoyer les intégrations :
Vous pouvez localiser le nom du point de terminaison dans la sortie du SDK ou dans les détails du déploiement dans l'interface utilisateur de SageMaker JumpStart.
Vous pouvez tester que le ContentHandler la fonction et le point de terminaison fonctionnent comme prévu en saisissant du texte brut et en exécutant le embeddings.embed_query(text) fonction. Vous pouvez utiliser l'exemple fourni text = "Hi! It's time for the beach" ou essayez votre propre texte.
Déployer et tester Llama 2-Chat à l'aide de SageMaker JumpStart
Vous pouvez désormais déployer le modèle capable d'avoir des conversations interactives avec vos utilisateurs. Dans ce cas, nous choisissons l'un des modèles Llama 2-chat, identifié via
Le modèle doit être déployé sur un point de terminaison en temps réel à l'aide predictor = my_model.deploy(). SageMaker renverra le nom du point de terminaison du modèle, que vous pourrez utiliser pour le endpoint_name variable à référencer plus tard.
Vous définissez un print_dialogue fonction pour envoyer une entrée au modèle de discussion et recevoir sa réponse de sortie. La charge utile comprend des hyperparamètres pour le modèle, notamment les suivants :
- max_new_tokens – Fait référence au nombre maximum de jetons que le modèle peut générer dans ses sorties.
- top_p – Fait référence à la probabilité cumulée des jetons qui peuvent être conservés par le modèle lors de la génération de ses sorties
- la réactivité – Fait référence au caractère aléatoire des sorties générées par le modèle. Une température supérieure à 0 ou égale à 1 augmente le niveau d'aléatoire, alors qu'une température de 0 générera les jetons les plus probables.
Vous devez sélectionner vos hyperparamètres en fonction de votre cas d'utilisation et les tester de manière appropriée. Les modèles tels que la famille Llama nécessitent que vous incluiez un paramètre supplémentaire indiquant que vous avez lu et accepté le contrat de licence utilisateur final (CLUF) :
Pour tester le modèle, remplacez la section de contenu de la charge utile d'entrée : "content": "what is the recipe of mayonnaise?". Vous pouvez utiliser vos propres valeurs de texte et mettre à jour les hyperparamètres pour mieux les comprendre.
Semblable au déploiement du modèle d'intégration, vous pouvez déployer Llama-70B-Chat à l'aide de l'interface utilisateur SageMaker JumpStart :
- Sur la console SageMaker Studio, choisissez Début de saut dans le volet de navigation
- Recherchez et choisissez le
Llama-2-70b-Chat model - Acceptez le CLUF et choisissez Déployer, en utilisant à nouveau l'instance par défaut
Semblable au modèle d'intégration, vous pouvez utiliser l'intégration LangChain en créant un modèle de gestionnaire de contenu pour les entrées et sorties de votre modèle de discussion. Dans ce cas, vous définissez les entrées comme celles provenant d'un utilisateur, et indiquez qu'elles sont régies par le system promptL’ system prompt informe le modèle de son rôle d'assistance à l'utilisateur pour un cas d'utilisation particulier.
Ce gestionnaire de contenu est ensuite transmis lors de l'appel du modèle, en plus des hyperparamètres et attributs personnalisés susmentionnés (acceptation du CLUF). Vous analysez tous ces attributs à l'aide du code suivant :
Lorsque le point de terminaison est disponible, vous pouvez tester qu'il fonctionne comme prévu. Vous pouvez mettre à jour llm("what is amazon sagemaker?") avec votre propre texte. Vous devez également définir les spécificités ContentHandler pour invoquer le LLM à l'aide de LangChain, comme indiqué dans le code et l'extrait de code suivant :
Utilisez LlamaIndex pour créer le RAG
Pour continuer, installez LlamaIndex pour créer l'application RAG. Vous pouvez installer LlamaIndex en utilisant le pip : pip install llama_index
Vous devez d'abord charger vos données (base de connaissances) sur LlamaIndex pour les indexer. Cela implique quelques étapes :
- Choisissez un chargeur de données :
LlamaIndex fournit un certain nombre de connecteurs de données disponibles sur LamaHub pour les types de données courants tels que les fichiers JSON, CSV et texte, ainsi que d'autres sources de données, vous permettant d'ingérer une variété d'ensembles de données. Dans cet article, nous utilisons SimpleDirectoryReader pour ingérer quelques fichiers PDF comme indiqué dans le code. Notre échantillon de données est constitué de deux communiqués de presse d'Amazon en version PDF dans le communiqués de presse dossier dans notre référentiel de code. Après avoir chargé les PDF, vous pouvez voir qu'ils ont été convertis en une liste de 11 éléments.
Au lieu de charger les documents directement, vous pouvez également convertir le Document objet dans Node objets avant de les envoyer à l’index. Le choix entre envoyer l'intégralité Document objet à l'index ou en convertissant le document en Node les objets avant l'indexation dépendent de votre cas d'utilisation spécifique et de la structure de vos données. L'approche des nœuds est généralement un bon choix pour les documents longs, dans lesquels vous souhaitez diviser et récupérer des parties spécifiques d'un document plutôt que l'intégralité du document. Pour plus d'informations, reportez-vous à Documents / Nœuds.
- Instanciez le chargeur et chargez les documents :
Cette étape initialise la classe du chargeur et toute configuration nécessaire, par exemple s'il faut ignorer les fichiers cachés. Pour plus de détails, reportez-vous à SimpleDirectoryReader.
- Appelez le chargeur
load_dataméthode pour analyser vos fichiers et données sources et les convertir en objets LlamaIndex Document, prêts pour l'indexation et l'interrogation. Vous pouvez utiliser le code suivant pour terminer l'ingestion des données et la préparation de la recherche en texte intégral à l'aide des fonctionnalités d'indexation et de récupération de LlamaIndex :
- Construisez l'index :
La principale caractéristique de LlamaIndex est sa capacité à construire des index organisés sur des données, représentées sous forme de documents ou de nœuds. L'indexation facilite une interrogation efficace sur les données. Nous créons notre index avec le magasin de vecteurs en mémoire par défaut et avec notre configuration de paramètres définie. L'Indice des Lamas Paramètres est un objet de configuration qui fournit des ressources et des paramètres couramment utilisés pour les opérations d'indexation et d'interrogation dans une application LlamaIndex. Il agit comme un objet singleton, de sorte qu'il vous permet de définir des configurations globales, tout en vous permettant également de remplacer des composants spécifiques localement en les transmettant directement aux interfaces (telles que les LLM, les modèles d'intégration) qui les utilisent. Lorsqu'un composant particulier n'est pas explicitement fourni, le framework LlamaIndex revient aux paramètres définis dans le Settings objet comme valeur par défaut globale. Pour utiliser nos modèles d'intégration et LLM avec LangChain et configurer le Settings nous devons installer llama_index.embeddings.langchain ainsi que llama_index.llms.langchain. Nous pouvons configurer le Settings objet comme dans le code suivant :
Par défaut, VectorStoreIndex utilise un en mémoire SimpleVectorStore qui est initialisé dans le cadre du contexte de stockage par défaut. Dans des cas d'utilisation réels, vous devez souvent vous connecter à des magasins de vecteurs externes tels que Service Amazon OpenSearch. Pour plus de détails, reportez-vous à Moteur vectoriel pour Amazon OpenSearch sans serveur.
Vous pouvez désormais exécuter des questions et réponses sur vos documents en utilisant l'outil moteur_de requête de LlamaIndex. Pour ce faire, transmettez l'index que vous avez créé précédemment pour les requêtes et posez votre question. Le moteur de requête est une interface générique pour interroger des données. Il prend une requête en langage naturel en entrée et renvoie une réponse riche. Le moteur de requêtes est généralement construit sur un ou plusieurs index en utilisant récupérateurs.
Vous pouvez constater que la solution RAG est capable de récupérer la bonne réponse à partir des documents fournis :
Utiliser les outils et agents LangChain
Loader classe. Le chargeur est conçu pour charger des données dans LlamaIndex ou ultérieurement comme outil dans un Agent LangChain. Cela vous donne plus de puissance et de flexibilité pour l’utiliser dans le cadre de votre application. Vous commencez par définir votre outil de la classe d'agent LangChain. La fonction que vous transmettez à votre outil interroge l'index que vous avez construit sur vos documents à l'aide de LlamaIndex.
Ensuite, vous sélectionnez le bon type d'agent que vous souhaitez utiliser pour votre implémentation RAG. Dans ce cas, vous utilisez le chat-zero-shot-react-description agent. Avec cet agent, le LLM utilisera l'outil disponible (dans ce scénario, le RAG sur la base de connaissances) pour fournir la réponse. Vous initialisez ensuite l'agent en transmettant votre outil, votre LLM et votre type d'agent :
Vous pouvez voir l'agent passer thoughts, actionset observation , utilisez l'outil (dans ce scénario, interrogez vos documents indexés) ; et renvoie un résultat :
Vous pouvez trouver le code d'implémentation de bout en bout dans le document ci-joint. GitHub repo.
Nettoyer
Pour éviter des coûts inutiles, vous pouvez nettoyer vos ressources, soit via les extraits de code suivants, soit via l'interface utilisateur Amazon JumpStart.
Pour utiliser le SDK Boto3, utilisez le code suivant pour supprimer le point de terminaison du modèle d'incorporation de texte et le point de terminaison du modèle de génération de texte, ainsi que les configurations du point de terminaison :
Pour utiliser la console SageMaker, procédez comme suit :
- Sur la console SageMaker, sous Inférence dans le volet de navigation, choisissez Points de terminaison
- Recherchez les points de terminaison d’intégration et de génération de texte.
- Sur la page des détails du point de terminaison, choisissez Supprimer.
- Choisissez à nouveau Supprimer pour confirmer.
Conclusion
Pour les cas d'utilisation axés sur la recherche et la récupération, LlamaIndex offre des fonctionnalités flexibles. Il excelle dans l'indexation et la récupération pour les LLM, ce qui en fait un outil puissant pour l'exploration approfondie des données. LlamaIndex vous permet de créer des index de données organisés, d'utiliser divers LLM, d'augmenter les données pour de meilleures performances LLM et d'interroger les données en langage naturel.
Cet article a démontré certains concepts et capacités clés de LlamaIndex. Nous avons utilisé GPT-J pour l'intégration et Llama 2-Chat comme LLM pour créer une application RAG, mais vous pouvez utiliser n'importe quel modèle approprié à la place. Vous pouvez explorer la gamme complète de modèles disponibles sur SageMaker JumpStart.
Nous avons également montré comment LlamaIndex peut fournir des outils puissants et flexibles pour connecter, indexer, récupérer et intégrer des données avec d'autres frameworks comme LangChain. Avec les intégrations LlamaIndex et LangChain, vous pouvez créer des applications LLM plus puissantes, polyvalentes et perspicaces.
À propos des auteurs
 Dr Romina Sharifpour est architecte senior de solutions d'apprentissage automatique et d'intelligence artificielle chez Amazon Web Services (AWS). Elle a passé plus de 10 ans à diriger la conception et la mise en œuvre de solutions innovantes de bout en bout rendues possibles par les progrès du ML et de l'IA. Les domaines d'intérêt de Romina sont le traitement du langage naturel, les grands modèles de langage et le MLOps.
Dr Romina Sharifpour est architecte senior de solutions d'apprentissage automatique et d'intelligence artificielle chez Amazon Web Services (AWS). Elle a passé plus de 10 ans à diriger la conception et la mise en œuvre de solutions innovantes de bout en bout rendues possibles par les progrès du ML et de l'IA. Les domaines d'intérêt de Romina sont le traitement du langage naturel, les grands modèles de langage et le MLOps.
 Nicole Pinto est un architecte de solutions spécialisé en IA/ML basé à Sydney, en Australie. Son expérience dans les domaines de la santé et des services financiers lui confère une perspective unique dans la résolution des problèmes des clients. Elle est passionnée par l'accompagnement des clients grâce à l'apprentissage automatique et par l'autonomisation de la prochaine génération de femmes dans les domaines STEM.
Nicole Pinto est un architecte de solutions spécialisé en IA/ML basé à Sydney, en Australie. Son expérience dans les domaines de la santé et des services financiers lui confère une perspective unique dans la résolution des problèmes des clients. Elle est passionnée par l'accompagnement des clients grâce à l'apprentissage automatique et par l'autonomisation de la prochaine génération de femmes dans les domaines STEM.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

