Introduction
Dans le monde actuel de livraison rapide de produits alimentaires locaux, garantir la satisfaction des clients est essentiel pour les entreprises. Des acteurs majeurs comme Zomato et Swiggy dominent cette industrie. Les clients attendent des aliments frais ; s'ils reçoivent des articles gâtés, ils apprécient un remboursement ou un bon de réduction. Cependant, déterminer manuellement la fraîcheur des aliments s’avère fastidieux pour les clients et le personnel de l’entreprise. Une solution consiste à automatiser ce processus à l’aide de modèles de Deep Learning. Ces modèles peuvent prédire la fraîcheur des aliments, permettant ainsi que seules les plaintes signalées soient examinées par les employés pour validation finale. Si le modèle confirme la fraîcheur des aliments, il peut automatiquement rejeter la plainte. Dans cet article, nous allons construire un détecteur de qualité alimentaire à l'aide du Deep Learning.
Le Deep Learning, un sous-ensemble de l’intelligence artificielle, offre une utilité significative dans ce contexte. Plus précisément, les CNN (Convolutional Neural Networks) peuvent être utilisés pour former des modèles utilisant des images d'aliments afin de discerner leur fraîcheur. La précision de notre modèle dépend entièrement de la qualité de l’ensemble de données. Idéalement, l’incorporation d’images alimentaires réelles provenant des plaintes des chatbots des utilisateurs dans les applications de livraison de nourriture hyperlocale améliorerait considérablement la précision. Cependant, n’ayant pas accès à de telles données, nous nous appuyons sur un ensemble de données largement utilisé connu sous le nom de « Ensemble de données Fresh and Rotten Classification », accessible sur Kaggle. Pour explorer le code complet du deep learning, cliquez simplement sur le bouton « Copier et modifier » fourni ici.
Objectifs d'apprentissage
- Découvrez l'importance de la qualité des aliments dans la satisfaction des clients et la croissance de l'entreprise.
- Découvrez comment l'apprentissage profond contribue à la construction du détecteur de qualité alimentaire.
- Acquérez une expérience pratique grâce à une mise en œuvre étape par étape de ce modèle.
- Comprendre les défis et les solutions impliqués dans sa mise en œuvre.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Comprendre l'utilisation du Deep Learning dans le détecteur de qualité alimentaire
L'apprentissage en profondeur, un sous-ensemble de Intelligence artificielle, utilise principalement des ensembles de données spatiales pour construire des modèles. Les réseaux de neurones du Deep Learning sont utilisés pour entraîner ces modèles, imitant les fonctionnalités du cerveau humain.
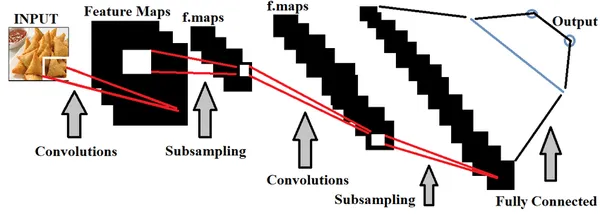
Dans le contexte de la détection de la qualité des aliments, la formation de modèles d’apprentissage profond avec de nombreux ensembles d’images alimentaires est essentielle pour distinguer avec précision les aliments de bonne et de mauvaise qualité. Nous pouvons faire réglage hyperparamètre en fonction des données alimentées, afin de rendre le modèle plus précis.
Importance de la qualité des aliments dans la livraison hyperlocale
L'intégration de cette fonctionnalité dans la livraison de nourriture hyperlocale offre plusieurs avantages. Le modèle évite les préjugés envers des clients spécifiques et prédit avec précision, réduisant ainsi le temps de résolution des réclamations. De plus, nous pouvons utiliser cette fonctionnalité pendant le processus d’emballage des commandes pour inspecter la qualité des aliments avant la livraison, garantissant ainsi aux clients de recevoir systématiquement des aliments frais.

Développement d'un détecteur de qualité alimentaire
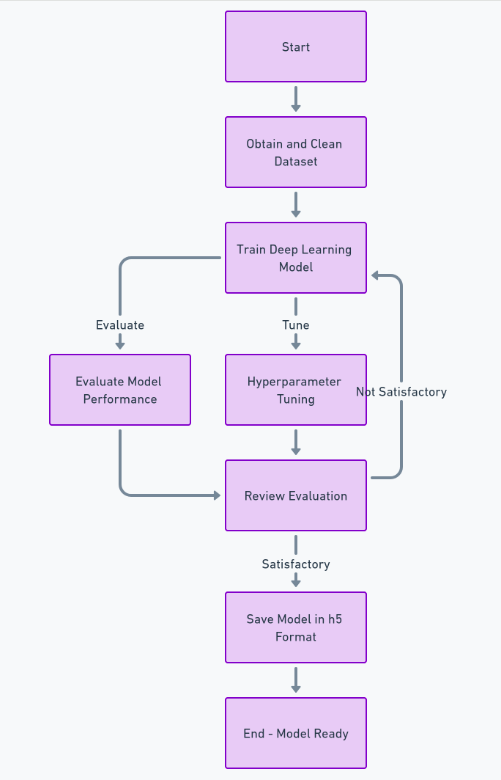
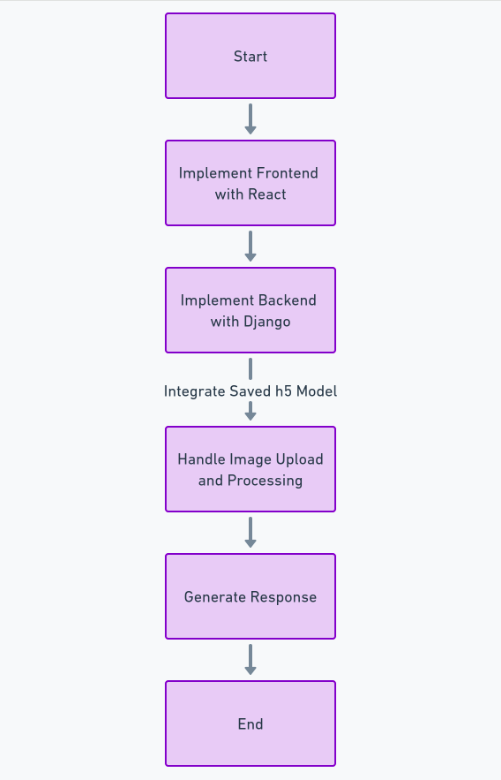
Afin de créer complètement cette fonctionnalité, nous devons suivre de nombreuses étapes telles que l'obtention et le nettoyage de l'ensemble de données, la formation du modèle d'apprentissage en profondeur, l'évaluation des performances et le réglage des hyperparamètres, et enfin l'enregistrement du modèle dans h5 format. Après cela, nous pouvons implémenter le frontend en utilisant Réagir, et le backend utilisant le framework Python Django. Nous utiliserons Django pour gérer le téléchargement d’images et le traiter.
À propos de l'ensemble de données
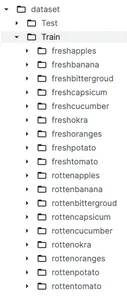
Avant d'approfondir le prétraitement des données et la création de modèles, il est crucial de comprendre l'ensemble de données. Comme indiqué précédemment, nous utiliserons un ensemble de données de Kaggle nommé Classification des aliments frais et pourris. Cet ensemble de données est divisé en deux catégories principales nommées Train ainsi que Teste qui sont utilisés respectivement à des fins de formation et de test. Sous le dossier train, nous avons 9 sous-dossiers de fruits et légumes frais et 9 sous-dossiers de fruits et légumes pourris.
Principales caractéristiques de l'ensemble de données
- Variété d'images: Cet ensemble de données contient de nombreuses images d'aliments avec de nombreuses variations en termes d'angle, d'arrière-plan et de conditions d'éclairage. Cela aide le modèle à ne pas être biaisé et à être plus précis.
- Images de haute qualité: Cet ensemble de données contient des images de très bonne qualité capturées par diverses caméras professionnelles.
Chargement et préparation des données
Dans cette section, nous allons d'abord charger les images en utilisant 'tensorflow.keras.preprocessing.image.charger_img' et visualisez les images à l'aide de la bibliothèque matplotlib. Le prétraitement de ces images pour la formation du modèle est vraiment important. Cela implique de nettoyer et d'organiser les images pour les rendre adaptées au modèle.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)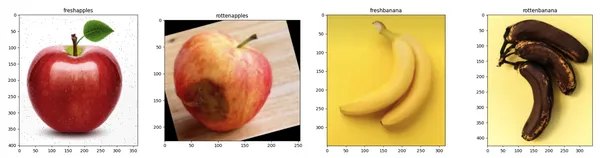
Chargeons maintenant les images de formation et de test dans des variables. Nous redimensionnerons toutes les images à la même hauteur et largeur de 180.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
Développement de modèles
Construisons maintenant le modèle d'apprentissage en profondeur à l'aide de l'algorithme séquentiel de « tensorflow.keras ». Nous ajouterons 3 couches de convolution et un optimiseur Adam. Avant de nous attarder sur la partie pratique, comprenons d'abord ce que signifient les termes 'Modèle séquentiel", "Adam Optimiseur', et 'Couche de convolution' signifier.
Modèle séquentiel
Le modèle séquentiel comprend un empilement de couches, offrant une structure fondamentale dans Keras. Il est idéal pour les scénarios dans lesquels votre réseau neuronal comporte un seul tenseur d'entrée et un seul tenseur de sortie. Vous ajoutez des couches dans l'ordre séquentiel d'exécution, ce qui le rend adapté à la construction de modèles simples avec des couches empilées. Cette simplicité rend le modèle séquentiel très utile et plus facile à mettre en œuvre.
Adam Optimiseur
L'abréviation d'Adam est « Estimation du moment adaptatif ». Il sert d'algorithme d'optimisation alternatif à la descente de gradient stochastique, mettant à jour les pondérations du réseau de manière itérative. Adam Optimizer est avantageux car il maintient un taux d'apprentissage (LR) pour chaque poids de réseau, ce qui est avantageux pour gérer le bruit dans les données.
Couche convolutive (Conv2D)
C'est le composant principal des réseaux de neurones convolutifs (CNN). Il est principalement utilisé pour traiter des ensembles de données spatiales tels que des images. Cette couche applique une fonction ou une opération de convolution à l'entrée, puis transmet le résultat à la couche suivante.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)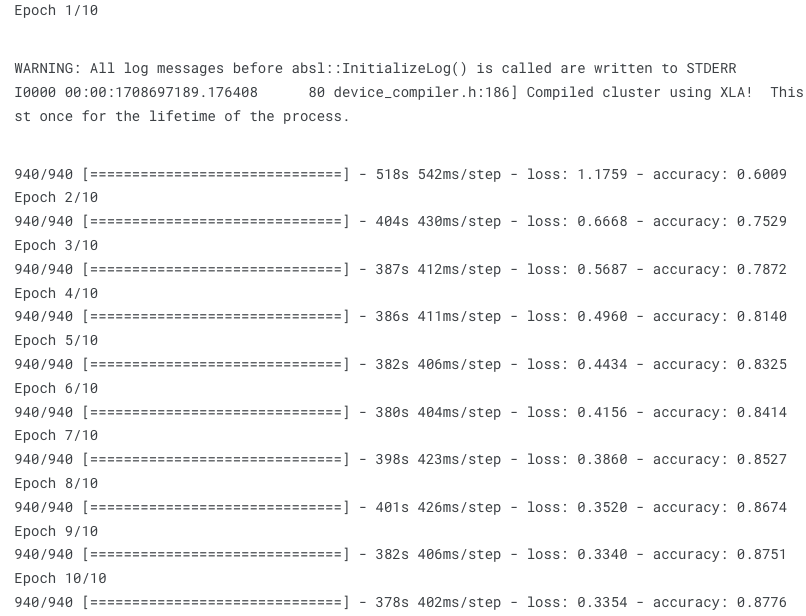
Test du détecteur de qualité alimentaire
Testons maintenant le modèle en lui donnant une nouvelle image alimentaire et voyons avec quelle précision il peut classer les aliments frais et pourris.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
Comme nous pouvons le constater, le modèle a prédit correctement. Comme nous l'avons donné orange pourrie image en entrée, le modèle l'a correctement prédit comme Pourri.
Pour le code frontend (React) et backend (Django), vous pouvez voir mon code complet sur GitHub ici : Lien
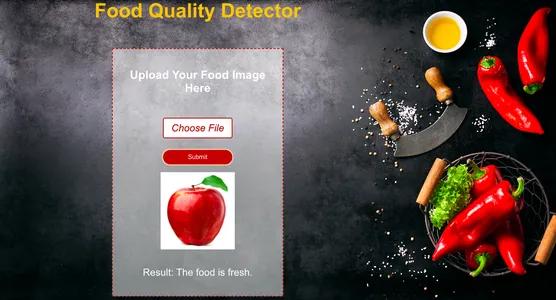
Conclusion
En conclusion, pour automatiser les réclamations sur la qualité des aliments dans les applications Hyperlocal Delivery, nous proposons de créer un modèle d'apprentissage en profondeur intégré à une application Web. Cependant, en raison des données de formation limitées, le modèle peut ne pas détecter avec précision chaque image d'aliment. Cette mise en œuvre constitue une étape fondamentale vers une solution plus large. L'accès aux images téléchargées par les utilisateurs en temps réel dans ces applications améliorerait considérablement la précision de notre modèle.
Faits marquants
- La qualité des aliments joue un rôle essentiel dans la satisfaction des clients sur le marché de la livraison de nourriture hyperlocale.
- Vous pouvez utiliser la technologie Deep Learning pour former un prédicteur précis de la qualité des aliments.
- Vous avez acquis une expérience pratique grâce à ce guide étape par étape pour créer l'application Web.
- Vous avez compris l’importance de la qualité du jeu de données pour construire un modèle précis.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

