Cet article est co-écrit par Ramdev Wudali et Kiran Mantripragada de Thomson Reuters.
En 1992, Thomson Reuters (TR) a lancé son premier service de recherche juridique IA, WIN (Westlaw Is Natural), une innovation à l'époque, car la plupart des moteurs de recherche ne prenaient en charge que les termes booléens et les connecteurs. Depuis lors, TR a franchi de nombreuses autres étapes alors que ses produits et services d'IA ne cessent de croître en nombre et en variété, soutenant les professionnels du droit, de la fiscalité, de la comptabilité, de la conformité et des services d'information dans le monde entier, avec des milliards d'informations sur l'apprentissage automatique (ML) générées chaque année. .
Avec cette formidable augmentation des services d'IA, la prochaine étape pour TR était de rationaliser l'innovation et de faciliter la collaboration. Normalisez la création et la réutilisation des solutions d'IA dans toutes les fonctions commerciales et les personnalités des praticiens de l'IA, tout en garantissant le respect des meilleures pratiques de l'entreprise :
- Automatisez et standardisez l'effort d'ingénierie indifférencié répétitif
- Assurer l'isolement et le contrôle requis des données sensibles conformément aux normes de gouvernance communes
- Fournir un accès facile à des ressources informatiques évolutives
Pour répondre à ces exigences, TR a construit la plate-forme Enterprise AI autour des cinq piliers suivants : un service de données, un espace de travail d'expérimentation, un registre central des modèles, un service de déploiement de modèles et une surveillance des modèles.
Dans cet article, nous expliquons comment TR et AWS ont collaboré pour développer la toute première Enterprise AI Platform de TR, un outil Web qui fournirait des fonctionnalités allant de l'expérimentation ML, de la formation, d'un registre central de modèles, du déploiement de modèles et de la surveillance des modèles. Toutes ces fonctionnalités sont conçues pour répondre aux normes de sécurité en constante évolution de TR et fournir des services simples, sécurisés et conformes aux utilisateurs finaux. Nous expliquons également comment TR a permis la surveillance et la gouvernance des modèles ML créés dans différentes unités commerciales avec un seul écran.
Les défis
Historiquement chez TR, le ML a été une capacité pour les équipes composées de scientifiques et d'ingénieurs de données avancés. Les équipes dotées de ressources hautement qualifiées ont pu mettre en œuvre des processus ML complexes selon leurs besoins, mais sont rapidement devenues très cloisonnées. Les approches cloisonnées n'offraient aucune visibilité pour assurer la gouvernance des prévisions de prise de décision extrêmement critiques.
Les équipes commerciales de TR ont une vaste connaissance du domaine ; cependant, les compétences techniques et les efforts d'ingénierie lourds requis dans le ML rendent difficile l'utilisation de leur expertise approfondie pour résoudre les problèmes commerciaux avec la puissance du ML. TR veut démocratiser les compétences, les rendre accessibles à plus de personnes au sein de l'organisation.
Différentes équipes de TR suivent leurs propres pratiques et méthodologies. TR souhaite développer les capacités qui s'étendent sur l'ensemble du cycle de vie ML à leurs utilisateurs pour accélérer la livraison des projets ML en permettant aux équipes de se concentrer sur les objectifs commerciaux et non sur l'effort d'ingénierie répétitif et indifférencié.
De plus, les réglementations relatives aux données et à l'IA éthique continuent d'évoluer, imposant des normes de gouvernance communes à toutes les solutions d'IA de TR.
Vue d'ensemble de la solution
La plate-forme d'IA d'entreprise de TR a été conçue pour fournir des services simples et standardisés à différentes personnes, offrant des fonctionnalités pour chaque étape du cycle de vie ML. TR a identifié cinq grandes catégories qui modularisent toutes les exigences de TR :
- Service de données – Pour permettre un accès facile et sécurisé aux ressources de données de l'entreprise
- Espace de travail d'expérimentation – Fournir des capacités pour expérimenter et former des modèles ML
- Registre central des modèles – Un catalogue d'entreprise pour les modèles construits dans différentes unités commerciales
- Service de déploiement de modèles – Fournir diverses options de déploiement d'inférence conformément aux pratiques CI/CD d'entreprise de TR
- Services de surveillance des modèles – Fournir des capacités pour surveiller les données et modéliser les biais et les dérives
Comme le montre le diagramme suivant, ces microservices sont construits avec quelques principes clés à l'esprit :
- Supprimer l'effort d'ingénierie indifférencié des utilisateurs
- Fournissez les fonctionnalités requises en un clic
- Sécurisez et régissez toutes les fonctionnalités conformément aux normes d'entreprise de TR
- Apportez une seule vitre pour les activités de ML

Les microservices AI Platform de TR sont conçus avec Amazon Sage Maker comme moteur principal, des composants sans serveur AWS pour les flux de travail et des services AWS DevOps pour les pratiques CI/CD. Studio SageMaker est utilisé pour l'expérimentation et la formation, et le registre de modèles SageMaker est utilisé pour enregistrer les modèles. Le registre central des modèles comprend à la fois le registre des modèles SageMaker et un Amazon DynamoDB tableau. Services d'hébergement SageMaker sont utilisés pour déployer des modèles, tandis que Moniteur de modèle SageMaker et de SageMaker Clarifier sont utilisés pour surveiller les modèles pour la dérive, le biais, les calculatrices de métriques personnalisées et l'explicabilité.
Les sections suivantes décrivent ces services en détail.
Service de données
Un cycle de vie de projet ML traditionnel commence par la recherche de données. En général, les data scientists passent 60 % ou plus de leur temps à trouver les bonnes données quand ils en ont besoin. Comme toute organisation, TR dispose de plusieurs magasins de données qui servent de point de vérité unique pour différents domaines de données. TR a identifié deux magasins de données d'entreprise clés qui fournissent des données pour la plupart de leurs cas d'utilisation de ML : un magasin d'objets et un magasin de données relationnelles. TR a créé un service de données AI Platform pour fournir un accès transparent aux deux magasins de données à partir des espaces de travail d'expérimentation des utilisateurs et supprimer le fardeau des utilisateurs de naviguer dans des processus complexes pour acquérir des données par eux-mêmes. La plate-forme d'IA du TR suit toutes les conformités et les meilleures pratiques définies par l'équipe de gouvernance des données et des modèles. Cela comprend une évaluation obligatoire de l'impact des données qui aide les praticiens du ML à comprendre et à suivre l'utilisation éthique et appropriée des données, avec des processus d'approbation formels pour garantir un accès approprié aux données. Au cœur de ce service, ainsi que de tous les services de la plate-forme, se trouve la sécurité et la conformité conformément aux meilleures pratiques déterminées par TR et l'industrie.
Service de stockage simple Amazon (Amazon S3) le stockage d'objets agit comme un lac de données de contenu. TR a construit des processus pour accéder en toute sécurité aux données du lac de données de contenu aux espaces de travail d'expérimentation des utilisateurs tout en maintenant l'autorisation et la vérifiabilité requises. Snowflake est utilisé comme magasin principal de données relationnelles d'entreprise. À la demande de l'utilisateur et sur la base de l'approbation du propriétaire des données, le service de données d'AI Platform fournit à l'utilisateur un instantané des données immédiatement disponible dans son espace de travail d'expérimentation.
L'accès aux données provenant de diverses sources est un problème technique qui peut être facilement résolu. Mais la complexité que TR a résolue consiste à créer des flux de travail d'approbation qui automatisent l'identification du propriétaire des données, l'envoi d'une demande d'accès, en s'assurant que le propriétaire des données est informé qu'il a une demande d'accès en attente et, en fonction du statut d'approbation, prend des mesures pour fournir des données à le demandeur. Tous les événements tout au long de ce processus sont suivis et enregistrés à des fins d'auditabilité et de conformité.
Comme le montre le schéma suivant, TR utilise Fonctions d'étape AWS orchestrer le flux de travail et AWS Lambda pour exécuter la fonctionnalité. Passerelle d'API Amazon est utilisé pour exposer la fonctionnalité avec un point de terminaison API à utiliser à partir de leur portail Web.
Expérimentation et développement de modèles
Une capacité essentielle pour normaliser le cycle de vie ML est un environnement qui permet aux data scientists d'expérimenter différents frameworks ML et tailles de données. La mise en place d'un tel environnement sécurisé et conforme dans le cloud en quelques minutes soulage les scientifiques des données du fardeau de la gestion de l'infrastructure cloud, des exigences de mise en réseau et des mesures de normes de sécurité, pour se concentrer plutôt sur le problème de la science des données.
TR construit un espace de travail d'expérimentation qui offre l'accès à des services tels que Colle AWS, Amazon DMEet SageMaker Studio pour permettre le traitement des données et les capacités de ML en respectant les normes de sécurité du cloud d'entreprise et l'isolement de compte requis pour chaque unité commerciale. TR a rencontré les défis suivants lors de la mise en œuvre de la solution :
- Au début, l'orchestration n'était pas entièrement automatisée et impliquait plusieurs étapes manuelles. Traquer où les problèmes se produisaient n'était pas facile. TR a surmonté cette erreur en orchestrant les flux de travail à l'aide de Step Functions. Avec l'utilisation de Step Functions, la création de flux de travail complexes, la gestion des états et la gestion des erreurs sont devenues beaucoup plus faciles.
- Correct Gestion des identités et des accès AWS (IAM) la définition du rôle pour l'espace de travail d'expérimentation était difficile à définir. Pour se conformer aux normes de sécurité internes de TR et au modèle de moindre privilège, à l'origine, le rôle de l'espace de travail était défini avec des politiques en ligne. Par conséquent, la stratégie en ligne a augmenté avec le temps et est devenue détaillée, dépassant la limite de taille de stratégie autorisée pour le rôle IAM. Pour atténuer ce problème, TR est passé à l'utilisation de davantage de stratégies gérées par le client et à leur référencement dans la définition du rôle de l'espace de travail.
- TR atteignait occasionnellement les limites de ressources par défaut appliquées au niveau du compte AWS. Cela entraînait des échecs occasionnels du lancement des tâches SageMaker (par exemple, des tâches de formation) en raison de la limite de type de ressource souhaitée atteinte. TR a travaillé en étroite collaboration avec l'équipe de service SageMaker sur ce problème. Ce problème a été résolu après que l'équipe AWS a lancé SageMaker en tant que service pris en charge dans Quotas de services en juin 2022.
Aujourd'hui, les data scientists de TR peuvent lancer un projet ML en créant un espace de travail indépendant et en ajoutant les membres de l'équipe requis pour collaborer. L'échelle illimitée offerte par SageMaker est à portée de main en leur fournissant des images de noyau personnalisées de tailles variées. SageMaker Studio est rapidement devenu un composant crucial de la plate-forme AI de TR et a changé le comportement des utilisateurs, passant de l'utilisation d'applications de bureau restreintes à des moteurs évolutifs et éphémères spécialement conçus. Le schéma suivant illustre cette architecture.
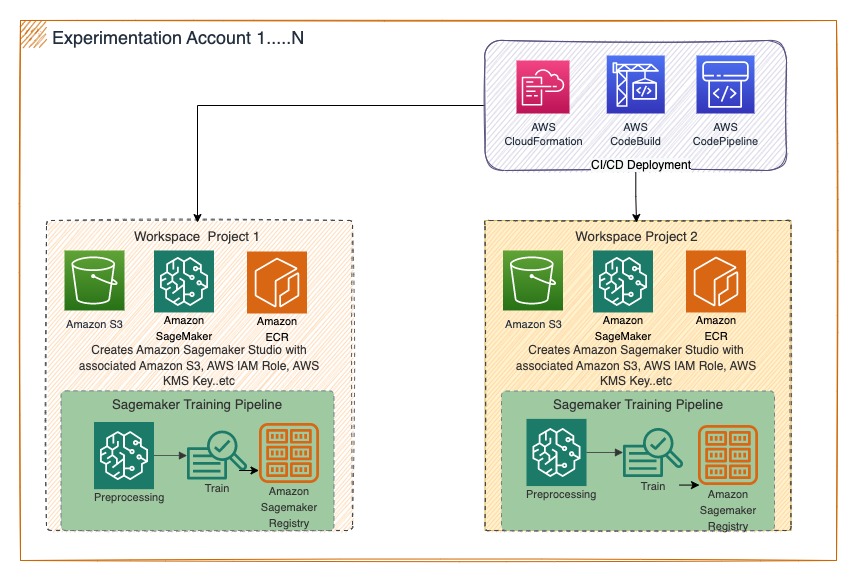
Registre central des modèles
Le registre de modèles fournit un référentiel central pour tous les modèles d'apprentissage automatique de TR, permet la gestion des risques et de la santé de ceux-ci de manière standardisée dans toutes les fonctions commerciales et rationalise la réutilisation potentielle des modèles. Par conséquent, le service devait effectuer les opérations suivantes :
- Fournir la possibilité d'enregistrer à la fois des modèles nouveaux et hérités, qu'ils soient développés à l'intérieur ou à l'extérieur de SageMaker
- Mettre en œuvre des workflows de gouvernance, permettant aux scientifiques des données, aux développeurs et aux parties prenantes de visualiser et de gérer collectivement le cycle de vie des modèles
- Augmentez la transparence et la collaboration en créant une vue centralisée de tous les modèles sur TR, ainsi que des métadonnées et des mesures de santé
TR a commencé la conception avec uniquement le registre de modèles SageMaker, mais l'une des principales exigences de TR est de fournir la possibilité d'enregistrer des modèles créés en dehors de SageMaker. TR a évalué différentes bases de données relationnelles mais a fini par choisir DynamoDB car le schéma de métadonnées pour les modèles provenant de sources héritées sera très différent. TR ne voulait pas non plus imposer de travail supplémentaire aux utilisateurs, ils ont donc mis en place une synchronisation automatique transparente entre les registres SageMaker de l'espace de travail AI Platform et le registre central SageMaker à l'aide Amazon Event Bridge règles et rôles IAM requis. TR a amélioré le registre central avec DynamoDB pour étendre les capacités d'enregistrement des modèles hérités qui ont été créés sur les postes de travail des utilisateurs.
Le registre central des modèles AI Platform de TR est intégré au portail AI Platform et fournit une interface visuelle pour rechercher des modèles, mettre à jour les métadonnées des modèles et comprendre les métriques de référence du modèle et les métriques de surveillance personnalisées périodiques. Le schéma suivant illustre cette architecture.

Déploiement de modèle
TR a identifié deux modèles majeurs pour automatiser le déploiement :
- Modèles développés à l'aide de SageMaker via des tâches de transformation par lots SageMaker pour obtenir des inférences selon un calendrier préféré
- Modèles développés en dehors de SageMaker sur des postes de travail locaux à l'aide de bibliothèques open source, via l'approche apportez votre propre conteneur en utilisant des tâches de traitement SageMaker pour exécuter un code d'inférence personnalisé, comme moyen efficace de migrer ces modèles sans refactoriser le code
Avec le service de déploiement d'AI Platform, les utilisateurs TR (data scientists et ingénieurs ML) peuvent identifier un modèle à partir du catalogue et déployer une tâche d'inférence dans le compte AWS de leur choix en fournissant les paramètres requis via un flux de travail piloté par l'interface utilisateur.
TR a automatisé ce déploiement à l'aide de services AWS DevOps tels que AWS CodePipeline et de Création de code AWS. TR utilise Step Functions pour orchestrer le flux de travail de lecture et de prétraitement des données pour créer des tâches d'inférence SageMaker. TR déploie les composants requis sous forme de code en utilisant AWS CloudFormation modèles. Le schéma suivant illustre cette architecture.

Surveillance du modèle
Le cycle de vie ML n'est pas complet sans pouvoir surveiller les modèles. L'équipe de gouvernance d'entreprise de TR mandate et encourage également les équipes commerciales à surveiller les performances de leur modèle au fil du temps pour relever tout défi réglementaire. TR a commencé avec des modèles de surveillance et des données de dérive. TR a utilisé SageMaker Model Monitor pour fournir une référence de données et une vérité terrain d'inférence afin de surveiller périodiquement la dérive des données et des inférences de TR. Parallèlement aux métriques de surveillance des modèles SageMaker, TR a amélioré la capacité de surveillance en développant des métriques personnalisées spécifiques à leurs modèles. Cela aidera les scientifiques des données de TR à comprendre quand recycler leur modèle.
Parallèlement à la surveillance de la dérive, TR souhaite également comprendre les biais dans les modèles. Les fonctionnalités prêtes à l'emploi de SageMaker Clarify sont utilisées pour créer le service de biais de TR. TR surveille à la fois les biais des données et des modèles et met ces métriques à la disposition de leurs utilisateurs via le portail AI Platform.
Pour aider toutes les équipes à adopter ces normes d'entreprise, TR a rendu ces services indépendants et facilement disponibles via le portail AI Platform. Les équipes commerciales de TR peuvent accéder au portail et déployer une tâche de surveillance de modèle ou une tâche de surveillance des biais par elles-mêmes et les exécuter selon leur calendrier préféré. Ils sont informés de l'état du travail et des métriques pour chaque exécution.
TR a utilisé les services AWS pour le déploiement CI/CD, l'orchestration des flux de travail, les infrastructures sans serveur et les points de terminaison d'API pour créer des microservices pouvant être déclenchés indépendamment, comme illustré dans l'architecture suivante.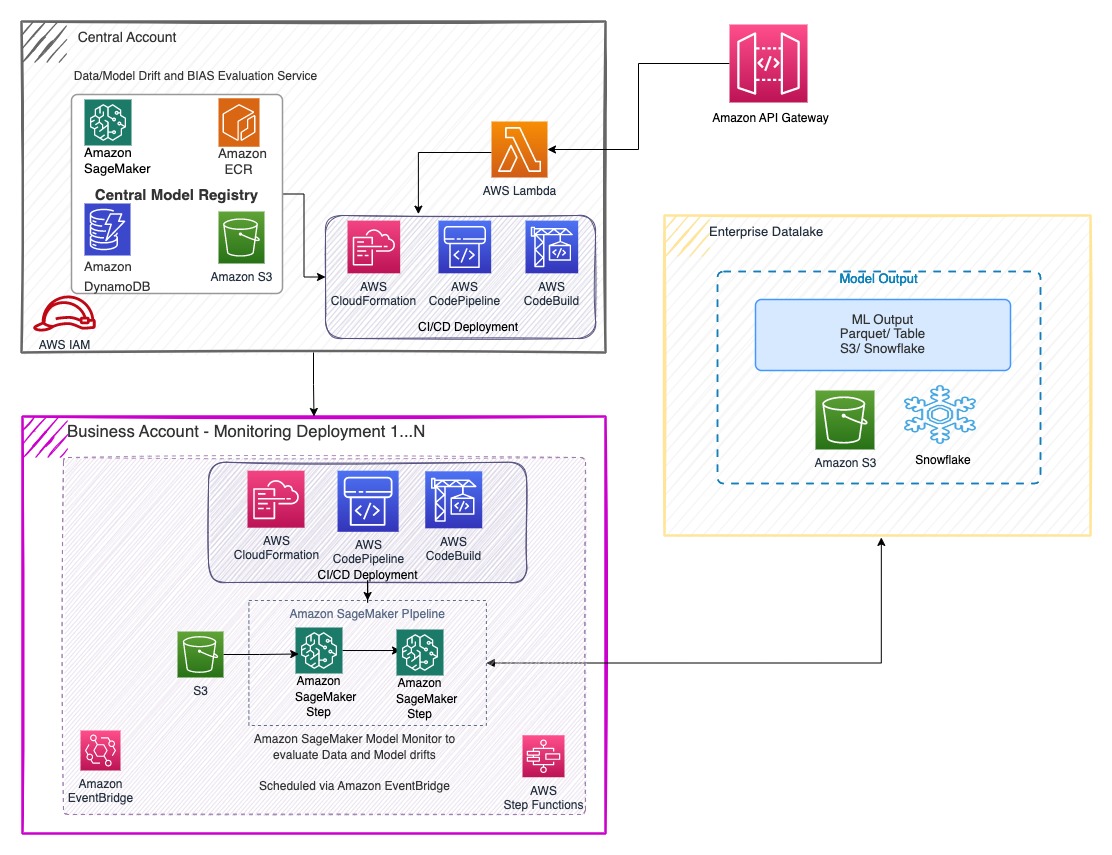
Résultats et améliorations futures
La plate-forme AI de TR a été mise en ligne au troisième trimestre 3 avec les cinq composants principaux : un service de données, un espace de travail d'expérimentation, un registre central des modèles, le déploiement des modèles et la surveillance des modèles. TR a organisé des sessions de formation internes pour ses unités commerciales afin qu'elles intègrent la plate-forme et leur a proposé des vidéos de formation autoguidées.
La plate-forme AI a fourni aux équipes de TR des capacités qui n'existaient pas auparavant ; il a ouvert un large éventail de possibilités à l'équipe de gouvernance d'entreprise de TR pour améliorer les normes de conformité et centraliser le registre, offrant une vue unique sur tous les modèles ML au sein de TR.
TR reconnaît qu'aucun produit n'est à son meilleur lors de sa sortie initiale. Tous les composants de TR sont à différents niveaux de maturité, et l'équipe Enterprise AI Platform de TR est dans une phase d'amélioration continue pour améliorer de manière itérative les fonctionnalités du produit. Le pipeline d'avancement actuel de TR comprend l'ajout d'options d'inférence SageMaker supplémentaires telles que des points de terminaison en temps réel, asynchrones et multimodèles. TR prévoit également d'ajouter l'explicabilité des modèles en tant que fonctionnalité à son service de surveillance des modèles. TR prévoit d'utiliser les capacités d'explicabilité de SageMaker Clarify pour développer son service d'explicabilité interne.
Conclusion
TR peut désormais traiter de grandes quantités de données en toute sécurité et utiliser les fonctionnalités avancées d'AWS pour faire passer un projet ML de l'idéation à la production en l'espace de quelques semaines, par rapport aux mois qu'il fallait auparavant. Grâce aux fonctionnalités prêtes à l'emploi des services AWS, les équipes de TR peuvent enregistrer et surveiller les modèles ML pour la toute première fois, en se conformant à l'évolution de leurs normes de gouvernance des modèles. TR a permis aux data scientists et aux équipes produit de libérer efficacement leur créativité pour résoudre les problèmes les plus complexes.
Pour en savoir plus sur la plateforme Enterprise AI de TR sur AWS, consultez le Session AWS re:Invent 2022. Si vous souhaitez savoir comment TR a accéléré l'utilisation de l'apprentissage automatique à l'aide de Laboratoire de données AWS programme, reportez-vous au un exemple.
À propos des auteurs
 Ramdev Wudali est un architecte de données, aidant à concevoir et à construire la plate-forme AI/ML pour permettre aux data scientists et aux chercheurs de développer des solutions d'apprentissage automatique en se concentrant sur la science des données et non sur les besoins en infrastructure. Dans ses temps libres, il aime plier du papier pour créer des mosaïques en origami et porter des T-shirts irrévérencieux.
Ramdev Wudali est un architecte de données, aidant à concevoir et à construire la plate-forme AI/ML pour permettre aux data scientists et aux chercheurs de développer des solutions d'apprentissage automatique en se concentrant sur la science des données et non sur les besoins en infrastructure. Dans ses temps libres, il aime plier du papier pour créer des mosaïques en origami et porter des T-shirts irrévérencieux.
 Kiran Mantripragada est le directeur principal d'AI Platform chez Thomson Reuters. L'équipe d'AI Platform est chargée d'activer les applications logicielles d'IA de niveau production et de permettre le travail des scientifiques des données et des chercheurs en apprentissage automatique. Passionné par la science, l'IA et l'ingénierie, Kiran aime combler le fossé entre la recherche et la production pour apporter la véritable innovation de l'IA aux consommateurs finaux.
Kiran Mantripragada est le directeur principal d'AI Platform chez Thomson Reuters. L'équipe d'AI Platform est chargée d'activer les applications logicielles d'IA de niveau production et de permettre le travail des scientifiques des données et des chercheurs en apprentissage automatique. Passionné par la science, l'IA et l'ingénierie, Kiran aime combler le fossé entre la recherche et la production pour apporter la véritable innovation de l'IA aux consommateurs finaux.
 Bhavana Chirumamilla est architecte résident principal chez AWS. Elle est passionnée par les opérations de données et de ML, et apporte beaucoup d'enthousiasme pour aider les entreprises à élaborer des stratégies de données et de ML. Dans ses temps libres, elle passe du temps avec sa famille à voyager, à faire de la randonnée, à jardiner et à regarder des documentaires.
Bhavana Chirumamilla est architecte résident principal chez AWS. Elle est passionnée par les opérations de données et de ML, et apporte beaucoup d'enthousiasme pour aider les entreprises à élaborer des stratégies de données et de ML. Dans ses temps libres, elle passe du temps avec sa famille à voyager, à faire de la randonnée, à jardiner et à regarder des documentaires.
 Shaik Srinivasa est un architecte de solutions chez AWS basé à Boston. Il aide les entreprises clientes à accélérer leur transition vers le cloud. Il est passionné par les conteneurs et les technologies d'apprentissage automatique. Dans ses temps libres, il aime passer du temps avec sa famille, cuisiner et voyager.
Shaik Srinivasa est un architecte de solutions chez AWS basé à Boston. Il aide les entreprises clientes à accélérer leur transition vers le cloud. Il est passionné par les conteneurs et les technologies d'apprentissage automatique. Dans ses temps libres, il aime passer du temps avec sa famille, cuisiner et voyager.
 Qingwei Li est un spécialiste de l'apprentissage automatique chez Amazon Web Services. Il a obtenu son doctorat en recherche opérationnelle après avoir cassé le compte de subvention de recherche de son conseiller et n'a pas réussi à remettre le prix Nobel qu'il avait promis. Actuellement, il aide les clients du secteur des services financiers et de l'assurance à créer des solutions d'apprentissage automatique sur AWS. Dans ses temps libres, il aime lire et enseigner.
Qingwei Li est un spécialiste de l'apprentissage automatique chez Amazon Web Services. Il a obtenu son doctorat en recherche opérationnelle après avoir cassé le compte de subvention de recherche de son conseiller et n'a pas réussi à remettre le prix Nobel qu'il avait promis. Actuellement, il aide les clients du secteur des services financiers et de l'assurance à créer des solutions d'apprentissage automatique sur AWS. Dans ses temps libres, il aime lire et enseigner.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-thomson-reuters-built-an-ai-platform-using-amazon-sagemaker-to-accelerate-delivery-of-ml-projects/

