Ce billet est co-écrit avec Aruna Abeyakoon et Denisse Colin de Light and Wonder (L&W).
Basée à Las Vegas, Lumière et merveille, Inc. est la principale société mondiale de jeux multiplateformes qui fournit des produits et services de jeux d'argent. En collaboration avec AWS, Light & Wonder a récemment développé une première solution sécurisée du secteur, Light & Wonder Connect (LnW Connect), pour diffuser des données de télémétrie et de santé des machines à partir d'environ un demi-million de machines de jeux électroniques réparties sur sa clientèle de casinos dans le monde lorsque LnW Connect atteint son plein potentiel. Plus de 500 événements de machine sont surveillés en temps quasi réel pour donner une image complète des conditions de la machine et de leurs environnements de fonctionnement. En utilisant les données diffusées via LnW Connect, L&W vise à créer une meilleure expérience de jeu pour ses utilisateurs finaux et à apporter plus de valeur à ses clients de casino.
Light & Wonder s'est associé au Laboratoire de solutions Amazon ML utiliser les données d'événements diffusées à partir de LnW Connect pour activer la maintenance prédictive basée sur l'apprentissage automatique (ML) pour les machines à sous. La maintenance prédictive est un cas d'utilisation courant du ML pour les entreprises disposant d'équipements physiques ou de machines. Grâce à la maintenance prédictive, L&W peut être averti à l'avance des pannes de machine et envoyer de manière proactive une équipe de service pour inspecter le problème. Cela réduira les temps d'arrêt des machines et évitera une perte de revenus importante pour les casinos. En l'absence de système de diagnostic à distance en place, la résolution des problèmes par l'équipe de service Light & Wonder sur le sol du casino peut être coûteuse et inefficace, tout en dégradant gravement l'expérience de jeu du client.
La nature du projet est hautement exploratoire - il s'agit de la première tentative de maintenance prédictive dans l'industrie du jeu. Le laboratoire de solutions Amazon ML et l'équipe L&W se sont lancés dans un voyage de bout en bout, depuis la formulation du problème de ML et la définition des métriques d'évaluation, jusqu'à la fourniture d'une solution de haute qualité. Le modèle ML final combine CNN et Transformer, qui sont les architectures de réseau neuronal de pointe pour la modélisation des données séquentielles du journal machine. Le billet présente une description détaillée de ce voyage, et nous espérons que vous l'apprécierez autant que nous !
Dans cet article, nous discutons des points suivants :
- Comment nous avons formulé le problème de maintenance prédictive en tant que problème de ML avec un ensemble de mesures appropriées pour l'évaluation
- Comment nous avons préparé les données pour la formation et les tests
- Techniques de prétraitement des données et d'ingénierie des fonctionnalités que nous avons utilisées pour obtenir des modèles performants
- Exécution d'une étape de réglage d'hyperparamètres avec Réglage automatique du modèle Amazon SageMaker
- Comparaisons entre le modèle de base et le modèle final CNN+Transformer
- Techniques supplémentaires que nous avons utilisées pour améliorer les performances du modèle, telles que l'assemblage
Contexte
Dans cette section, nous discutons des problèmes qui ont nécessité cette solution.
Ensemble de données
Les environnements de machines à sous sont hautement réglementés et sont déployés dans un environnement isolé. Dans LnW Connect, un processus de chiffrement a été conçu pour fournir un mécanisme sécurisé et fiable permettant aux données d'être introduites dans un lac de données AWS pour la modélisation prédictive. Les fichiers agrégés sont chiffrés et la clé de déchiffrement n'est disponible que dans Service de gestion de clés AWS (AWS KMS). Un réseau privé cellulaire dans AWS est mis en place via lequel les fichiers ont été téléchargés dans Service de stockage simple Amazon (Amazon S3).
LnW Connect diffuse un large éventail d'événements de machine, tels que le début du jeu, la fin du jeu, etc. Le système collecte plus de 500 types d'événements différents. Comme indiqué dans ce qui suit
, chaque événement est enregistré avec un horodatage du moment où il s'est produit et l'ID de la machine enregistrant l'événement. LnW Connect enregistre également lorsqu'une machine entre dans un état non jouable, et elle sera marquée comme une panne ou une panne de la machine si elle ne revient pas à un état jouable dans un laps de temps suffisamment court.
| ID de la machine | Identifiant du type d'événement | Horodatage |
|---|---|---|
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
En plus des événements de machine dynamiques, des métadonnées statiques sur chaque machine sont également disponibles. Cela inclut des informations telles que l'identifiant unique de la machine, le type d'armoire, l'emplacement, le système d'exploitation, la version du logiciel, le thème du jeu, etc., comme indiqué dans le tableau suivant. (Tous les noms du tableau sont anonymisés pour protéger les informations des clients.)
| ID de la machine | Type de Cabinet | OS | Localisation | Thème du jeu |
|---|---|---|---|---|
| 276 | A | OS_Ver0 | AA Resort & Casino | Stormmaiden |
| 167 | B | OS_Ver1 | BB Casino, Resort & Spa | UHMInde |
| 13 | C | OS_Ver0 | CC Casino & Hôtel | TerrificTigre |
| 307 | D | OS_Ver0 | DD Casino Resort | NeptunesRoyaume |
| 70 | E | OS_Ver0 | EE Resort & Casino | RLPMealTicket |
Définition du problème
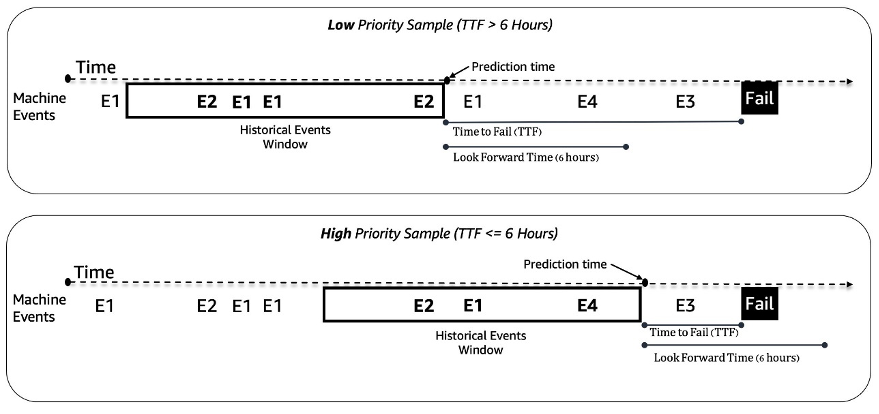
Nous traitons le problème de maintenance prédictive des machines à sous comme un problème de classification binaire. Le modèle ML prend en compte la séquence historique des événements de la machine et d'autres métadonnées et prédit si une machine rencontrera une panne dans une fenêtre temporelle future de 6 heures. Si une machine tombe en panne dans les 6 heures, elle est considérée comme une machine prioritaire pour l'entretien. Sinon, il est de faible priorité. La figure suivante donne des exemples d'échantillons de faible priorité (en haut) et de haute priorité (en bas). Nous utilisons une fenêtre de temps de rétrospection de longueur fixe pour collecter des données d'événements machine historiques à des fins de prédiction. Les expériences montrent que des fenêtres de temps de rétrospection plus longues améliorent considérablement les performances du modèle (plus de détails plus loin dans cet article).
Défis de modélisation
Nous avons été confrontés à quelques défis pour résoudre ce problème :
- Nous avons une énorme quantité de journaux d'événements qui contiennent environ 50 millions d'événements par mois (à partir d'environ 1,000 XNUMX échantillons de jeux). Une optimisation soigneuse est nécessaire dans l'étape d'extraction et de prétraitement des données.
- La modélisation de la séquence d'événements était difficile en raison de la distribution extrêmement inégale des événements dans le temps. Une fenêtre de 3 heures peut contenir des dizaines à des milliers d'événements.
- Les machines sont en bon état la plupart du temps et la maintenance prioritaire est une classe rare, ce qui a introduit un problème de déséquilibre de classe.
- De nouvelles machines sont ajoutées en permanence au système, nous avons donc dû nous assurer que notre modèle peut gérer la prédiction sur de nouvelles machines qui n'ont jamais été vues en formation.
Prétraitement des données et ingénierie des fonctionnalités
Dans cette section, nous discutons de nos méthodes de préparation des données et d'ingénierie des fonctionnalités.
Ingénierie des fonctionnalités
Les flux de machines à sous sont des flux d'événements de séries chronologiques inégalement espacés ; par exemple, le nombre d'événements dans une fenêtre de 3 heures peut aller de dizaines à des milliers. Pour gérer ce déséquilibre, nous avons utilisé des fréquences d'événements au lieu des données de séquence brutes. Une approche simple consiste à agréger la fréquence des événements pour l'ensemble de la fenêtre rétrospective et à l'intégrer au modèle. Cependant, lors de l'utilisation de cette représentation, l'information temporelle est perdue et l'ordre des événements n'est pas conservé. Nous avons plutôt utilisé le regroupement temporel en divisant la fenêtre temporelle en N sous-fenêtres égales et en calculant les fréquences d'événements dans chacune. Les caractéristiques finales d'une fenêtre temporelle sont la concaténation de toutes ses caractéristiques de sous-fenêtre. L'augmentation du nombre de casiers préserve davantage d'informations temporelles. La figure suivante illustre le regroupement temporel sur une fenêtre d'échantillon.
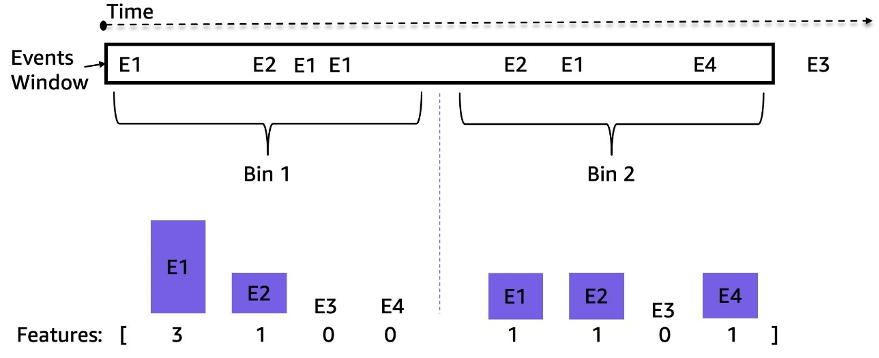
Tout d'abord, la fenêtre de temps d'échantillonnage est divisée en deux sous-fenêtres égales (bins) ; nous n'avons utilisé que deux bacs ici pour plus de simplicité à titre d'illustration. Ensuite, les décomptes des événements E1, E2, E3 et E4 sont calculés dans chaque classe. Enfin, ils sont concaténés et utilisés comme fonctionnalités.
Outre les fonctionnalités basées sur la fréquence des événements, nous avons utilisé des fonctionnalités spécifiques à la machine telles que la version du logiciel, le type d'armoire, le thème du jeu et la version du jeu. De plus, nous avons ajouté des fonctionnalités liées aux horodatages pour capturer la saisonnalité, telles que l'heure du jour et le jour de la semaine.
Préparation des données
Pour extraire efficacement les données pour la formation et les tests, nous utilisons Amazon Athena et le catalogue de données AWS Glue. Les données d'événements sont stockées dans Amazon S3 au format Parquet et partitionnées selon le jour/mois/heure. Cela facilite l'extraction efficace d'échantillons de données dans une fenêtre temporelle spécifiée. Nous utilisons les données de toutes les machines du dernier mois pour les tests et le reste des données pour la formation, ce qui permet d'éviter les fuites de données potentielles.
Méthodologie ML et formation sur les modèles
Dans cette section, nous discutons de notre modèle de base avec AutoGluon et de la manière dont nous avons construit un réseau de neurones personnalisé avec le réglage automatique du modèle SageMaker.
Construire un modèle de référence avec AutoGluon
Quel que soit le cas d'utilisation de ML, il est important d'établir un modèle de base à utiliser pour la comparaison et l'itération. Nous avons utilisé AutoGluon pour explorer plusieurs algorithmes ML classiques. AutoGluon est un outil AutoML facile à utiliser qui utilise le traitement automatique des données, le réglage des hyperparamètres et l'ensemble de modèles. La meilleure ligne de base a été obtenue avec un ensemble pondéré de modèles d'arbre de décision à gradient boosté. La facilité d'utilisation d'AutoGluon nous a aidés dans la phase de découverte à naviguer rapidement et efficacement à travers un large éventail de données possibles et de directions de modélisation ML.
Création et réglage d'un modèle de réseau neuronal personnalisé avec le réglage automatique du modèle SageMaker
Après avoir expérimenté différentes architectures de réseaux de neurones, nous avons construit un modèle d'apprentissage profond personnalisé pour la maintenance prédictive. Notre modèle a dépassé le modèle de référence AutoGluon de 121 % en rappel à 80 % de précision. Le modèle final ingère les données de séquence d'événements machine historiques, les caractéristiques temporelles telles que l'heure de la journée et les métadonnées statiques de la machine. Nous utilisons Réglage automatique du modèle SageMaker jobs pour rechercher les meilleurs hyperparamètres et architectures de modèles.
La figure suivante montre l'architecture du modèle. Nous normalisons d'abord les données de séquence d'événements regroupées par les fréquences moyennes de chaque événement dans l'ensemble d'apprentissage pour supprimer l'effet écrasant des événements à haute fréquence (début de partie, fin de partie, etc.). Les représentations vectorielles continues d'événements individuels peuvent être apprises, tandis que les représentations vectorielles temporelles (jour de la semaine, heure de la journée) sont extraites à l'aide du package GluonTS. Ensuite, nous concaténons les données de séquence d'événements avec les incorporations de caractéristiques temporelles comme entrée du modèle. Le modèle se compose des couches suivantes :
- Couches convolutives (CNN) – Chaque couche CNN consiste en deux opérations convolutives unidimensionnelles avec des connexions résiduelles. La sortie de chaque couche CNN a la même longueur de séquence que l'entrée pour permettre un empilement facile avec d'autres modules. Le nombre total de couches CNN est un hyperparamètre réglable.
- Couches de codeur de transformateur (TRANS) – La sortie des couches CNN est transmise avec le codage positionnel à une structure d'auto-attention à plusieurs têtes. Nous utilisons TRANS pour capturer directement les dépendances temporelles au lieu d'utiliser des réseaux de neurones récurrents. Ici, le regroupement des données de séquence brutes (réduisant la longueur de milliers à des centaines) aide à atténuer les goulots d'étranglement de la mémoire GPU, tout en conservant les informations chronologiques dans une mesure réglable (le nombre de bacs est un hyperparamètre réglable).
- Couches d'agrégation (AGG) – La couche finale combine les informations de métadonnées (type de thème de jeu, type d'armoire, emplacements) pour produire la prédiction de probabilité de niveau de priorité. Il se compose de plusieurs couches de regroupement et de couches entièrement connectées pour une réduction de dimension incrémentielle. Les incorporations multi-hot de métadonnées sont également apprenables et ne passent pas par les couches CNN et TRANS car elles ne contiennent pas d'informations séquentielles.
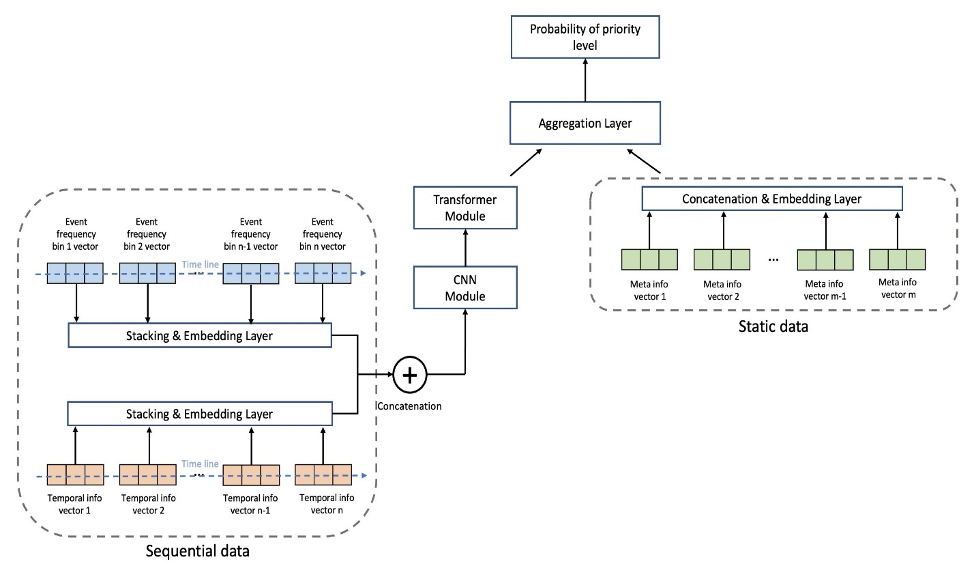
Nous utilisons la perte d'entropie croisée avec les poids de classe comme hyperparamètres réglables pour ajuster le problème de déséquilibre de classe. De plus, les nombres de couches CNN et TRANS sont des hyperparamètres cruciaux avec les valeurs possibles de 0, ce qui signifie que des couches spécifiques peuvent ne pas toujours exister dans l'architecture du modèle. De cette façon, nous avons un cadre unifié où les architectures de modèles sont recherchées avec d'autres hyperparamètres habituels.
Nous utilisons le réglage automatique du modèle SageMaker, également connu sous le nom d'optimisation des hyperparamètres (HPO), pour explorer efficacement les variations du modèle et le vaste espace de recherche de tous les hyperparamètres. Le réglage automatique du modèle reçoit l'algorithme personnalisé, les données de formation et les configurations d'espace de recherche d'hyperparamètres, et recherche les meilleurs hyperparamètres à l'aide de différentes stratégies telles que Bayesian, Hyperband, etc. avec plusieurs instances GPU en parallèle. Après évaluation sur un ensemble de validation, nous avons obtenu la meilleure architecture de modèle avec deux couches de CNN, une couche de TRANS à quatre têtes et une couche AGG.
Nous avons utilisé les plages d'hyperparamètres suivantes pour rechercher la meilleure architecture de modèle :
Pour améliorer encore la précision du modèle et réduire la variance du modèle, nous avons formé le modèle avec plusieurs initialisations de poids aléatoires indépendantes et agrégé le résultat avec des valeurs moyennes comme prédiction de probabilité finale. Il existe un compromis entre davantage de ressources informatiques et de meilleures performances du modèle, et nous avons observé que 5 à 10 devrait être un nombre raisonnable dans le cas d'utilisation actuel (résultats présentés plus loin dans cet article).
Résultats des performances du modèle
Dans cette section, nous présentons les mesures et les résultats de l'évaluation des performances du modèle.
Mesures d'évaluation
La précision est très importante pour ce cas d'utilisation de maintenance prédictive. Une faible précision signifie signaler plus de faux appels de maintenance, ce qui augmente les coûts en raison d'une maintenance inutile. Étant donné que la précision moyenne (AP) ne correspond pas entièrement à l'objectif de haute précision, nous avons introduit une nouvelle métrique appelée rappel moyen à haute précision (ARHP). L'ARHP est égal à la moyenne des rappels à 60 %, 70 % et 80 % des points de précision. Nous avons également utilisé la précision au top K% (K = 1, 10), AUPR et AUROC comme mesures supplémentaires.
Résultats
Le tableau suivant résume les résultats à l'aide des modèles de référence et de réseau de neurones personnalisés, avec le 7/1/2022 comme point de partage entraînement/test. Les expériences montrent que l'augmentation de la longueur de la fenêtre et de la taille des données d'échantillon améliore les performances du modèle, car elles contiennent plus d'informations historiques pour aider à la prédiction. Quels que soient les paramètres de données, le modèle de réseau neuronal surpasse AutoGluon dans toutes les métriques. Par exemple, le rappel à la précision fixe de 80 % est augmenté de 121 %, ce qui vous permet d'identifier rapidement davantage de machines défectueuses si vous utilisez le modèle de réseau neuronal.
| Modèle | Longueur de la fenêtre/taille des données | AUROC | AUPR | ARHP | Rappel@Prec0.6 | Rappel@Prec0.7 | Rappel@Prec0.8 | Préc@top1% | Préc@top10% |
|---|---|---|---|---|---|---|---|---|---|
| Ligne de base AutoGluon | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| Réseau neuronal | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| Ligne de base AutoGluon | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| Réseau neuronal | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
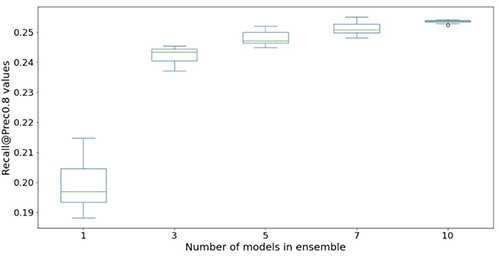
Les figures suivantes illustrent l'effet de l'utilisation d'ensembles pour améliorer les performances du modèle de réseau neuronal. Toutes les mesures d'évaluation présentées sur l'axe des abscisses sont améliorées, avec une moyenne plus élevée (plus précise) et une variance plus faible (plus stable). Chaque box-plot provient de 12 expériences répétées, d'aucun ensemble à 10 modèles dans des ensembles (axe des abscisses). Des tendances similaires persistent dans toutes les métriques en plus de Prec@top1% et Recall@Prec80% affichés.
Après avoir pris en compte le coût de calcul, nous observons que l'utilisation de 5 à 10 modèles dans des ensembles convient aux jeux de données Light & Wonder.

Conclusion
Notre collaboration a abouti à la création d'une solution de maintenance prédictive révolutionnaire pour l'industrie du jeu, ainsi qu'un cadre réutilisable qui pourrait être utilisé dans une variété de scénarios de maintenance prédictive. L'adoption de technologies AWS telles que le réglage automatique des modèles SageMaker permet à Light & Wonder de naviguer dans de nouvelles opportunités en utilisant des flux de données en temps quasi réel. Light & Wonder démarre le déploiement sur AWS.
Si vous souhaitez obtenir de l'aide pour accélérer l'utilisation du ML dans vos produits et services, veuillez contacter le Laboratoire de solutions Amazon ML .
À propos des auteurs
 Aruna Abeyakoon est le directeur principal de la science des données et de l'analyse chez Light & Wonder Land-based Gaming Division. Aruna dirige la première initiative de l'industrie Light & Wonder Connect et soutient à la fois les partenaires de casino et les parties prenantes internes avec le comportement des consommateurs et les informations sur les produits pour créer de meilleurs jeux, optimiser les offres de produits, gérer les actifs, surveiller la santé et la maintenance prédictive.
Aruna Abeyakoon est le directeur principal de la science des données et de l'analyse chez Light & Wonder Land-based Gaming Division. Aruna dirige la première initiative de l'industrie Light & Wonder Connect et soutient à la fois les partenaires de casino et les parties prenantes internes avec le comportement des consommateurs et les informations sur les produits pour créer de meilleurs jeux, optimiser les offres de produits, gérer les actifs, surveiller la santé et la maintenance prédictive.
 Denis Colin est Senior Data Science Manager chez Light & Wonder, une société mondiale de jeux multiplateformes de premier plan. Elle est membre de l'équipe Gaming Data & Analytics qui aide à développer des solutions innovantes pour améliorer les performances des produits et les expériences des clients via Light & Wonder Connect.
Denis Colin est Senior Data Science Manager chez Light & Wonder, une société mondiale de jeux multiplateformes de premier plan. Elle est membre de l'équipe Gaming Data & Analytics qui aide à développer des solutions innovantes pour améliorer les performances des produits et les expériences des clients via Light & Wonder Connect.
 Tesfagabir Meharizghi est Data Scientist au Amazon ML Solutions Lab, où il aide les clients AWS dans divers secteurs tels que les jeux, les soins de santé et les sciences de la vie, la fabrication, l'automobile, les sports et les médias, à accélérer leur utilisation de l'apprentissage automatique et des services cloud AWS pour résoudre leur activité. défis.
Tesfagabir Meharizghi est Data Scientist au Amazon ML Solutions Lab, où il aide les clients AWS dans divers secteurs tels que les jeux, les soins de santé et les sciences de la vie, la fabrication, l'automobile, les sports et les médias, à accélérer leur utilisation de l'apprentissage automatique et des services cloud AWS pour résoudre leur activité. défis.
 Mohamed Aljazaery est scientifique appliquée chez Amazon ML Solutions Lab. Il aide les clients d'AWS à identifier et à créer des solutions ML pour relever leurs défis commerciaux dans des domaines tels que la logistique, la personnalisation et les recommandations, la vision par ordinateur, la prévention de la fraude, les prévisions et l'optimisation de la chaîne d'approvisionnement.
Mohamed Aljazaery est scientifique appliquée chez Amazon ML Solutions Lab. Il aide les clients d'AWS à identifier et à créer des solutions ML pour relever leurs défis commerciaux dans des domaines tels que la logistique, la personnalisation et les recommandations, la vision par ordinateur, la prévention de la fraude, les prévisions et l'optimisation de la chaîne d'approvisionnement.
 Yawei Wang est scientifique appliquée au Amazon ML Solution Lab. Il aide les partenaires commerciaux AWS à identifier et à créer des solutions ML pour relever les défis commerciaux de leur organisation dans un scénario réel.
Yawei Wang est scientifique appliquée au Amazon ML Solution Lab. Il aide les partenaires commerciaux AWS à identifier et à créer des solutions ML pour relever les défis commerciaux de leur organisation dans un scénario réel.
 Yun Zhou est un scientifique appliqué au Amazon ML Solutions Lab, où il contribue à la recherche et au développement pour assurer le succès des clients AWS. Il travaille sur des solutions pionnières pour diverses industries en utilisant des techniques de modélisation statistique et d'apprentissage automatique. Il s'intéresse aux modèles génératifs et à la modélisation séquentielle des données.
Yun Zhou est un scientifique appliqué au Amazon ML Solutions Lab, où il contribue à la recherche et au développement pour assurer le succès des clients AWS. Il travaille sur des solutions pionnières pour diverses industries en utilisant des techniques de modélisation statistique et d'apprentissage automatique. Il s'intéresse aux modèles génératifs et à la modélisation séquentielle des données.
 Pan Pan Xu est responsable des sciences appliquées au Amazon ML Solutions Lab chez AWS. Elle travaille sur la recherche et le développement d'algorithmes d'apprentissage automatique pour les applications client à fort impact dans une variété de secteurs industriels verticaux afin d'accélérer leur adoption de l'IA et du cloud. Ses intérêts de recherche comprennent l'interprétabilité des modèles, l'analyse causale, l'IA humaine dans la boucle et la visualisation interactive des données.
Pan Pan Xu est responsable des sciences appliquées au Amazon ML Solutions Lab chez AWS. Elle travaille sur la recherche et le développement d'algorithmes d'apprentissage automatique pour les applications client à fort impact dans une variété de secteurs industriels verticaux afin d'accélérer leur adoption de l'IA et du cloud. Ses intérêts de recherche comprennent l'interprétabilité des modèles, l'analyse causale, l'IA humaine dans la boucle et la visualisation interactive des données.
 Raj Salvaji dirige l'architecture de solutions dans le segment de l'hôtellerie chez AWS. Il travaille avec les clients de l'hôtellerie en fournissant des conseils stratégiques et une expertise technique pour créer des solutions aux défis commerciaux complexes. Il s'appuie sur 25 ans d'expérience dans de multiples rôles d'ingénierie dans les secteurs de l'hôtellerie, de la finance et de l'automobile.
Raj Salvaji dirige l'architecture de solutions dans le segment de l'hôtellerie chez AWS. Il travaille avec les clients de l'hôtellerie en fournissant des conseils stratégiques et une expertise technique pour créer des solutions aux défis commerciaux complexes. Il s'appuie sur 25 ans d'expérience dans de multiples rôles d'ingénierie dans les secteurs de l'hôtellerie, de la finance et de l'automobile.
 Shane Raï est stratège ML principal au sein du laboratoire de solutions Amazon ML d'AWS. Il travaille avec des clients dans un large éventail d'industries pour résoudre leurs besoins commerciaux les plus urgents et innovants en utilisant l'étendue des services AI/ML basés sur le cloud d'AWS.
Shane Raï est stratège ML principal au sein du laboratoire de solutions Amazon ML d'AWS. Il travaille avec des clients dans un large éventail d'industries pour résoudre leurs besoins commerciaux les plus urgents et innovants en utilisant l'étendue des services AI/ML basés sur le cloud d'AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-light-wonder-built-a-predictive-maintenance-solution-for-gaming-machines-on-aws/

