Il s'agit d'un article invité co-écrit avec Brandon Abear, Dinesh Sharma, John Bush et Ozcan IIikhan de GoDaddy.
GoDaddy donne du pouvoir aux entrepreneurs de tous les jours en fournissant toute l'aide et les outils nécessaires pour réussir en ligne. Avec plus de 20 millions de clients dans le monde, GoDaddy est l'endroit où les gens viennent nommer leurs idées, créer un site Web professionnel, attirer des clients et gérer leur travail.
Chez GoDaddy, nous sommes fiers d'être une entreprise axée sur les données. Notre recherche incessante d’informations précieuses à partir des données alimente nos décisions commerciales et garantit la satisfaction de nos clients. Notre engagement en faveur de l'efficacité est inébranlable et nous avons entrepris une initiative passionnante pour optimiser nos travaux de traitement par lots. Au cours de ce parcours, nous avons identifié une approche structurée que nous appelons les sept niveaux d'opportunités d'amélioration. Cette méthodologie est devenue notre guide dans la recherche de l’efficacité.
Dans cet article, nous expliquons comment nous avons amélioré l'efficacité opérationnelle avec Amazon EMR sans serveur. Nous partageons nos résultats et notre méthodologie d'analyse comparative, ainsi que nos informations sur la rentabilité d'EMR Serverless par rapport à la capacité fixe. Amazon EMR sur EC2 clusters transitoires sur nos workflows de données orchestrés à l'aide Flux de travail gérés par Amazon pour Apache Airflow (Amazon MWAA). Nous partageons notre stratégie pour l’adoption d’EMR Serverless dans les domaines où il excelle. Nos résultats révèlent des avantages significatifs, notamment une réduction des coûts de plus de 60 %, des charges de travail Spark 50 % plus rapides, une remarquable multiplication par cinq de la vitesse de développement et de test, et une réduction significative de notre empreinte carbone.
Contexte
Fin 2020, la plateforme de données de GoDaddy a lancé son parcours AWS Cloud, en migrant un cluster Hadoop de 800 nœuds avec 2.5 Po de données de son centre de données vers EMR sur EC2. Cette approche lift-and-shift a facilité une comparaison directe entre les environnements sur site et cloud, garantissant une transition en douceur vers les pipelines AWS, minimisant les problèmes de validation des données et les retards de migration.
Début 2022, nous avons réussi à migrer nos charges de travail Big Data vers EMR sur EC2. En utilisant les meilleures pratiques tirées du programme AWS FinHack, nous avons affiné les tâches gourmandes en ressources, converti les tâches Pig et Hive en Spark et réduit nos dépenses en charge de travail par lots de 22.75 % en 2022. Cependant, des problèmes d'évolutivité sont apparus en raison de la multitude de tâches. . Cela a incité GoDaddy à se lancer dans un parcours d'optimisation systématique, établissant ainsi les bases d'un traitement plus durable et plus efficace du Big Data.
Sept niveaux d'opportunités d'amélioration
Dans notre quête d'efficacité opérationnelle, nous avons identifié sept niveaux distincts d'opportunités d'optimisation au sein de nos tâches de traitement par lots, comme le montre la figure suivante. Ces couches vont d’améliorations précises au niveau du code à des améliorations plus complètes de la plateforme. Cette approche à plusieurs niveaux est devenue notre modèle stratégique dans la recherche continue d’une meilleure performance et d’une plus grande efficacité.

Les couches sont les suivantes :
- Optimisation du code – Se concentre sur le raffinement de la logique du code et sur la façon dont elle peut être optimisée pour de meilleures performances. Cela implique des améliorations de performances grâce à la mise en cache sélective, à l'élagage des partitions et des projections, aux optimisations des jointures et à d'autres réglages spécifiques aux tâches. L’utilisation de solutions de codage IA fait également partie intégrante de ce processus.
- Mises à jour de logiciel - Mise à jour vers les dernières versions des logiciels open source (OSS) pour capitaliser sur les nouvelles fonctionnalités et améliorations. Par exemple, l'exécution adaptative des requêtes dans Spark 3 apporte des améliorations significatives en termes de performances et de coûts.
- Configurations Spark personnalisées - Optimisation des configurations Spark personnalisées pour maximiser l'utilisation des ressources, la mémoire et le parallélisme. Nous pouvons réaliser des améliorations significatives en redimensionnant les tâches, par exemple en
spark.sql.shuffle.partitions,spark.sql.files.maxPartitionBytes,spark.executor.coresetspark.executor.memory. Cependant, ces configurations personnalisées peuvent être contre-productives si elles ne sont pas compatibles avec la version spécifique de Spark. - Temps de mise à disposition des ressources - Le temps nécessaire pour lancer des ressources comme des clusters EMR éphémères sur Cloud de calcul élastique Amazon (Amazon EC2). Bien que certains facteurs influençant ce délai échappent au contrôle d'un ingénieur, l'identification et le traitement des facteurs qui peuvent être optimisés peuvent contribuer à réduire le temps global de provisionnement.
- Mise à l'échelle fine au niveau des tâches - Ajustement dynamique des ressources telles que le processeur, la mémoire, le disque et la bande passante réseau en fonction des besoins de chaque étape d'une tâche. L’objectif ici est d’éviter des tailles de cluster fixes qui pourraient entraîner un gaspillage de ressources.
- Mise à l'échelle précise sur plusieurs tâches dans un flux de travail - Étant donné que chaque tâche a des besoins en ressources uniques, le maintien d'une taille de ressource fixe peut entraîner un sous-provisionnement ou un surprovisionnement pour certaines tâches au sein du même flux de travail. Traditionnellement, la taille de la tâche la plus importante détermine la taille du cluster pour un flux de travail multitâche. Cependant, l'ajustement dynamique des ressources sur plusieurs tâches et étapes d'un flux de travail permet une mise en œuvre plus rentable.
- Améliorations au niveau de la plateforme – Les améliorations apportées aux couches précédentes ne peuvent optimiser qu'une tâche ou un flux de travail donné. L'amélioration de la plateforme vise à atteindre l'efficacité au niveau de l'entreprise. Nous pouvons y parvenir par divers moyens, tels que la mise à jour ou la mise à niveau de l'infrastructure de base, l'introduction de nouveaux cadres, l'allocation de ressources appropriées pour chaque profil de poste, l'équilibrage de l'utilisation des services, l'optimisation de l'utilisation des plans d'épargne et des instances ponctuelles, ou la mise en œuvre d'autres changements complets pour stimuler efficacité dans toutes les tâches et flux de travail.
Couches 1 à 3 : réductions de coûts antérieures
Après avoir migré du site sur site vers le cloud AWS, nous avons principalement concentré nos efforts d'optimisation des coûts sur les trois premières couches présentées dans le diagramme. En transférant nos anciens pipelines Pig et Hive les plus coûteux vers Spark et en optimisant les configurations Spark pour Amazon EMR, nous avons réalisé d'importantes économies de coûts.
Par exemple, un ancien travail Pig prenait 10 heures et se classait parmi les 10 travaux DME les plus chers. Après avoir examiné les journaux TEZ et les métriques du cluster, nous avons découvert que le cluster était largement surprovisionné pour le volume de données en cours de traitement et restait sous-utilisé pendant la majeure partie de l'exécution. La transition de Pig à Spark a été plus efficace. Bien qu'aucun outil automatisé n'était disponible pour la conversion, des optimisations manuelles ont été effectuées, notamment :
- Réduction des écritures inutiles sur disque, permettant d'économiser du temps de sérialisation et de désérialisation (couche 1)
- Remplacement de la parallélisation des tâches Airflow par Spark, simplifiant le DAG Airflow (couche 1)
- Élimination des transformations Spark redondantes (couche 1)
- Mise à niveau de Spark 2 vers 3, à l'aide de l'exécution adaptative de requêtes (couche 2)
- Jointures asymétriques résolues et tables de dimensions plus petites optimisées (couche 3)
En conséquence, le coût du travail a diminué de 95 % et le temps de réalisation du travail a été réduit à 1 heure. Cependant, cette approche demandait beaucoup de main d’œuvre et n’était pas évolutive pour de nombreux emplois.
Couches 4 à 6 : trouver et adopter la bonne solution de calcul
Fin 2022, suite à nos réalisations significatives en matière d’optimisation aux niveaux précédents, notre attention s’est portée sur l’amélioration des couches restantes.
Comprendre l'état de notre traitement par lots
Nous utilisons Amazon MWAA pour orchestrer nos flux de données dans le cloud à grande échelle. Flux d'air Apache est un outil open source utilisé pour créer, planifier et surveiller par programme des séquences de processus et de tâches appelées workflows. Dans cet article, les termes workflow ainsi que JOB sont utilisés de manière interchangeable, faisant référence aux graphiques acycliques dirigés (DAG) constitués de tâches orchestrées par Amazon MWAA. Pour chaque workflow, nous avons des tâches séquentielles ou parallèles, et même une combinaison des deux dans le DAG entre create_emr ainsi que terminate_emr tâches exécutées sur un cluster EMR transitoire avec une capacité de calcul fixe tout au long de l'exécution du flux de travail. Même après avoir optimisé une partie de notre charge de travail, nous avions encore de nombreux workflows non optimisés qui étaient sous-utilisés en raison d'un surprovisionnement de ressources de calcul basé sur la tâche la plus gourmande en ressources du workflow, comme le montre la figure suivante.
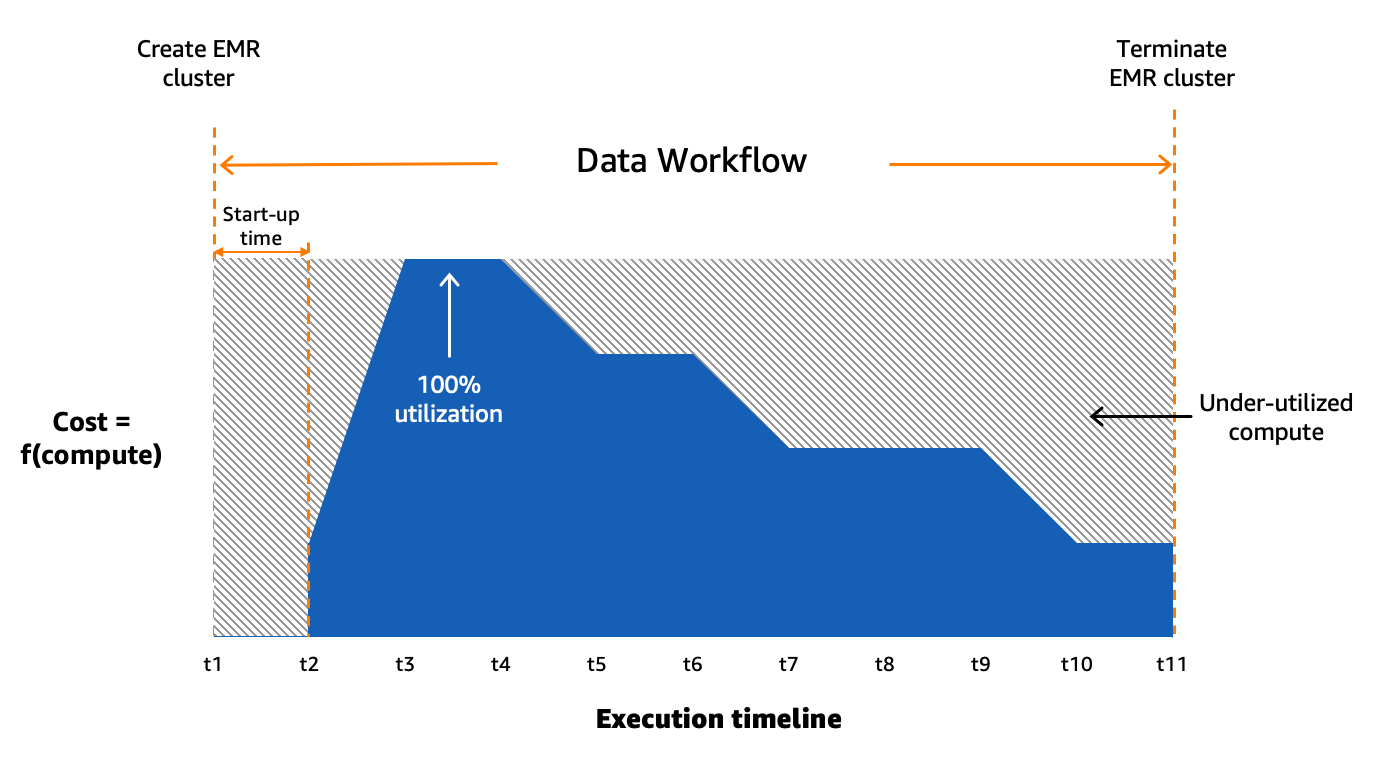
Cela a mis en évidence le caractère peu pratique de l’allocation statique des ressources et nous a amenés à reconnaître la nécessité d’un système d’allocation dynamique des ressources (DRA). Avant de proposer une solution, nous avons rassemblé de nombreuses données pour bien comprendre notre traitement par lots. L'analyse du temps d'étape du cluster, hors provisionnement et temps d'inactivité, a révélé des informations significatives : une distribution asymétrique à droite avec plus de la moitié des flux de travail s'exécutant en 20 minutes ou moins et seulement 10 % prenant plus de 60 minutes. Cette distribution a guidé notre choix d'une solution de calcul à provisionnement rapide, réduisant considérablement les temps d'exécution des flux de travail. Le diagramme suivant illustre les temps d'étape (hors provisionnement et temps d'inactivité) d'EMR sur des clusters transitoires EC2 dans l'un de nos comptes de traitement par lots.
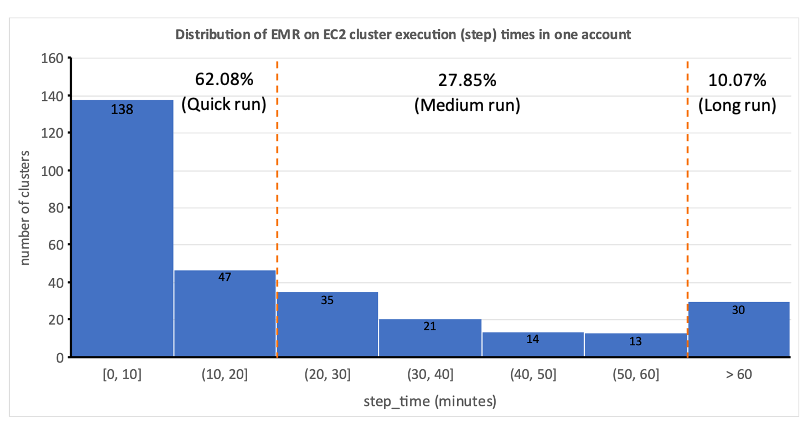
De plus, sur la base de la répartition du temps d'étape (hors provisionnement et temps d'inactivité) des workflows, nous avons classé nos workflows en trois groupes :
- Course rapide – D’une durée de 20 minutes ou moins
- Course moyenne – Dure entre 20 et 60 minutes
- Long terme – Plus de 60 minutes, s’étalant souvent sur plusieurs heures ou plus
Un autre facteur que nous devions prendre en compte était l'utilisation intensive de clusters temporaires pour des raisons telles que la sécurité, l'isolation des tâches et des coûts, ainsi que des clusters spécialement conçus. De plus, il y avait une variation significative des besoins en ressources entre les heures de pointe et les périodes de faible utilisation.
Au lieu de clusters de taille fixe, nous pourrions potentiellement utiliser une mise à l'échelle gérée sur EMR sur EC2 pour obtenir certains avantages en termes de coûts. Cependant, la migration vers EMR Serverless semble être une orientation plus stratégique pour notre plateforme de données. Outre les avantages potentiels en termes de coûts, EMR Serverless offre des avantages supplémentaires tels qu'une mise à niveau en un clic vers les dernières versions d'Amazon EMR, une expérience opérationnelle et de débogage simplifiée et des mises à niveau automatiques vers les dernières générations lors du déploiement. Ces fonctionnalités simplifient collectivement le processus d’exploitation d’une plate-forme à plus grande échelle.
Évaluation d'EMR Serverless : une étude de cas chez GoDaddy
EMR Serverless est une option sans serveur dans Amazon EMR qui élimine les complexités liées à la configuration, à la gestion et à la mise à l'échelle des clusters lors de l'exécution de frameworks Big Data comme Apache Spark et Apache Hive. Avec EMR Serverless, les entreprises peuvent bénéficier de nombreux avantages, notamment une rentabilité, un provisionnement plus rapide, une expérience de développeur simplifiée et une résilience améliorée aux pannes de zone de disponibilité.
Conscients du potentiel d'EMR Serverless, nous avons mené une étude comparative approfondie en utilisant des flux de production réels. L'étude visait à évaluer les performances et l'efficacité d'EMR Serverless tout en créant un plan d'adoption pour une mise en œuvre à grande échelle. Les résultats ont été très encourageants, démontrant qu'EMR Serverless peut gérer efficacement nos charges de travail.
Méthodologie d'analyse comparative
Nous divisons nos flux de données en trois catégories en fonction de la durée totale des étapes (hors provisionnement et temps d'inactivité) : exécution rapide (0 à 20 minutes), exécution moyenne (20 à 60 minutes) et exécution longue (plus de 60 minutes). Nous avons analysé l'impact du type de déploiement EMR (Amazon EC2 vs EMR Serverless) sur deux indicateurs clés : la rentabilité et l'accélération totale de l'exécution, qui ont servi de critères d'évaluation globaux. Bien que nous n'ayons pas mesuré formellement la facilité d'utilisation et la résilience, ces facteurs ont été pris en compte tout au long du processus d'évaluation.
Les étapes de haut niveau pour évaluer l’environnement sont les suivantes :
- Préparez les données et l’environnement :
- Choisissez trois à cinq emplois de production aléatoires dans chaque catégorie d'emplois.
- Mettre en œuvre les ajustements requis pour éviter toute interférence avec la production.
- Exécuter des tests :
- Exécutez des scripts sur plusieurs jours ou sur plusieurs itérations pour collecter des points de données précis et cohérents.
- Effectuez des tests à l'aide d'EMR sur EC2 et EMR Serverless.
- Validez les données et les tests :
- Validez les ensembles de données d’entrée et de sortie, les partitions et le nombre de lignes pour garantir un traitement de données identique.
- Recueillir des métriques et analyser les résultats :
- Rassemblez les métriques pertinentes des tests.
- Analyser les résultats pour tirer des enseignements et des conclusions.
Résultats de référence
Nos résultats de référence ont montré des améliorations significatives dans les trois catégories de tâches, tant en termes d'accélération d'exécution que de rentabilité. Les améliorations ont été plus prononcées pour les tâches rapides, résultant directement de temps de démarrage plus rapides. Par exemple, un workflow de données de 20 minutes (y compris le provisionnement et l'arrêt du cluster) exécuté sur un cluster transitoire EMR sur EC2 à capacité de calcul fixe se termine en 10 minutes sur EMR Serverless, offrant une durée d'exécution plus courte avec des avantages en termes de coûts. Dans l'ensemble, le passage à EMR Serverless a entraîné des améliorations substantielles des performances et des réductions de coûts à grande échelle dans toutes les catégories de tâches, comme le montre la figure suivante.
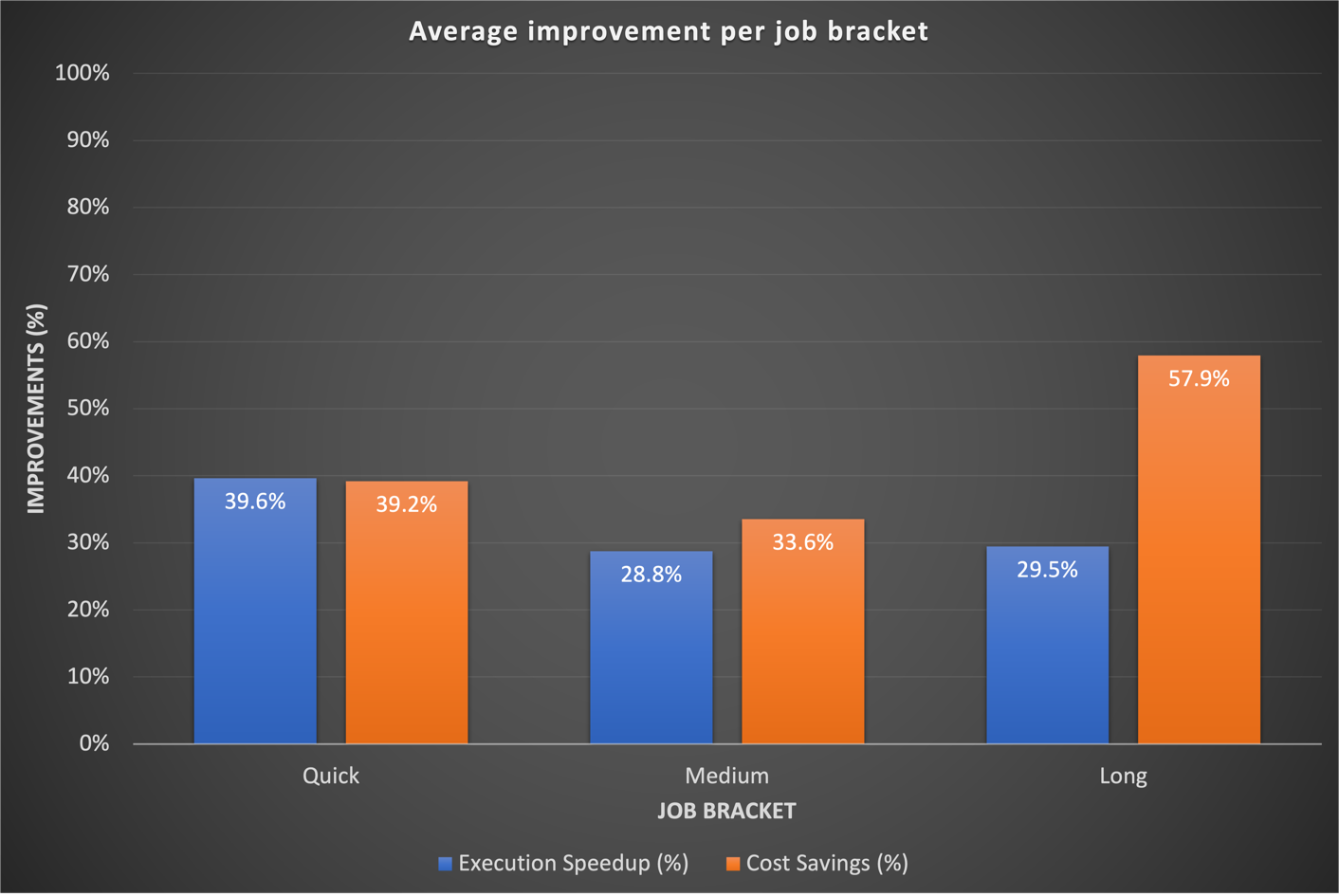
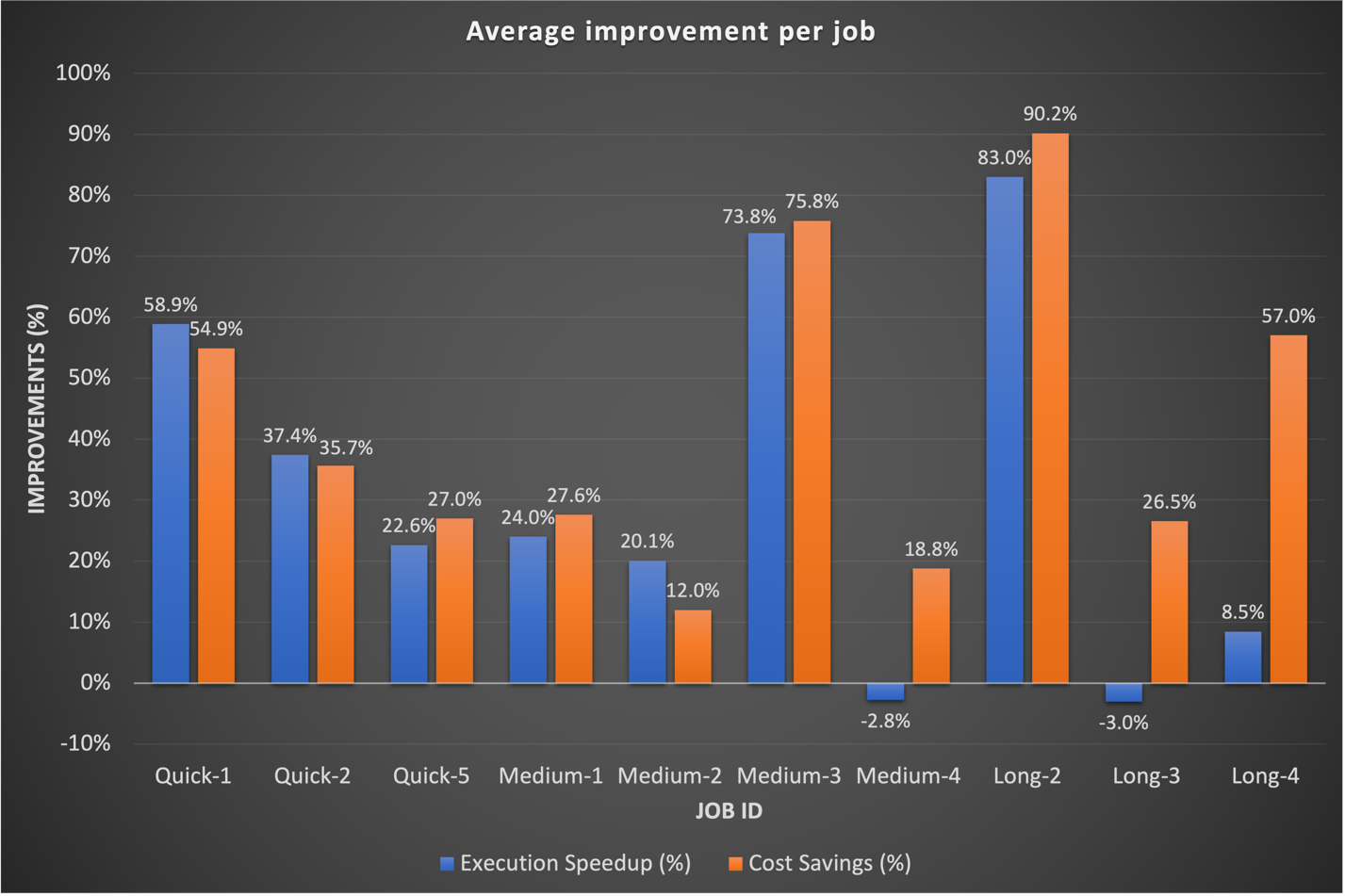
Historiquement, nous consacrions plus de temps à l’optimisation de nos flux de travail à long terme. Fait intéressant, nous avons découvert que les configurations Spark personnalisées existantes pour ces tâches ne se traduisaient pas toujours bien par EMR Serverless. Dans les cas où les résultats étaient insignifiants, une approche courante consistait à ignorer les configurations Spark précédentes liées aux cœurs d’exécuteur. En permettant à EMR Serverless de gérer de manière autonome ces configurations Spark, nous avons souvent observé de meilleurs résultats. Le graphique suivant montre la durée d'exécution moyenne et l'amélioration des coûts par tâche en comparant EMR Serverless à EMR sur EC2.
Le tableau suivant présente un exemple de comparaison des résultats pour le même flux de travail exécuté sur différentes options de déploiement d'Amazon EMR (EMR sur EC2 et EMR Serverless).
| Métrique | DME sur EC2 (Moyenne) |
EMR sans serveur (Moyenne) |
DME sur EC2 vs EMR sans serveur |
| Coût total de l'exécution ($) | 5.82 $ | 2.60 $ | 55% |
| Durée totale d'exécution (minutes) | 53.40 | 39.40 | 26% |
| Temps de mise à disposition (minutes) | 10.20 | 0.05 | . |
| Coût d'approvisionnement ($) | 1.19 $ | . | . |
| Étapes Temps (minutes) | 38.20 | 39.16 | -3% |
| Coût des étapes ($) | 4.30 $ | . | . |
| Temps d'inactivité (minutes) | 4.80 | . | . |
| Étiquette de version DME | emr-6.9.0 | . | |
| Distribution Hadoop | Amazon 3.3.3 | . | |
| Version Étincelle | Spark 3.3.0 | . | |
| Version Hive/HCatalog | Ruche 3.1.3, HCatalog 3.1.3 | . | |
| Type d'emploi | Spark | . | |
AWS Graviton2 sur l'évaluation des performances sans serveur EMR
Après avoir constaté des résultats convaincants avec EMR Serverless pour nos charges de travail, nous avons décidé d'analyser plus en profondeur les performances du AWSGraviton2 (arm64) dans EMR Serverless. AWS avait référencé Spark des charges de travail sur Graviton2 EMR Serverless à l'aide de l'échelle TPC-DS 3 To, affichant une amélioration globale du rapport prix-performance de 27 %.
Pour mieux comprendre les avantages de l'intégration, nous avons mené notre propre étude en utilisant les charges de travail de production de GoDaddy selon un calendrier quotidien et avons observé une amélioration impressionnante du rapport qualité-prix de 23.8 % sur une gamme de tâches lors de l'utilisation de Graviton2. Pour plus de détails sur cette étude, voir L'analyse comparative de GoDaddy permet d'obtenir un rapport qualité-prix jusqu'à 24 % supérieur pour leurs charges de travail Spark avec AWS Graviton2 sur Amazon EMR Serverless.
Stratégie d'adoption pour EMR Serverless
Nous avons stratégiquement mis en œuvre un déploiement progressif d'EMR Serverless via des anneaux de déploiement, permettant une intégration systématique. Cette approche progressive nous a permis de valider les améliorations et d'arrêter l'adoption ultérieure d'EMR Serverless, si nécessaire. Cela a servi à la fois de filet de sécurité pour détecter rapidement les problèmes et de moyen d'affiner notre infrastructure. Le processus a atténué l'impact du changement grâce à des opérations fluides tout en renforçant l'expertise de nos équipes d'ingénierie de données et DevOps. De plus, il a favorisé des boucles de rétroaction étroites, permettant des ajustements rapides et garantissant une intégration efficace d'EMR sans serveur.
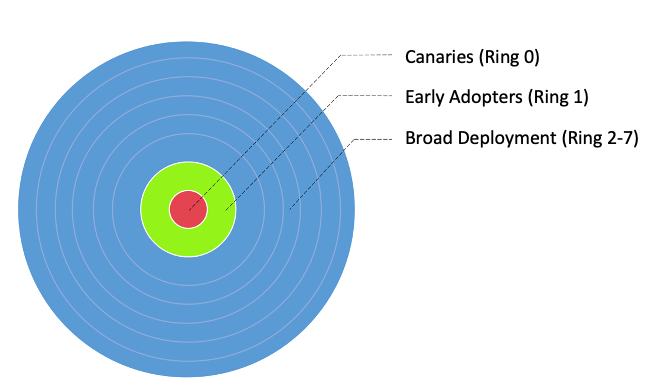
Nous avons divisé nos flux de travail en trois groupes d'adoption principaux, comme le montre l'image suivante :
- Canaries - Ce groupe aide à détecter et à résoudre tout problème potentiel dès le début de la phase de déploiement.
- Adopteurs précoces - Il s'agit du deuxième lot de flux de travail qui adoptent la nouvelle solution de calcul après que les problèmes initiaux ont été identifiés et corrigés par le groupe Canaries.
- Larges anneaux de déploiement - Plus grand groupe d'anneaux, ce groupe représente le déploiement à grande échelle de la solution. Ceux-ci sont déployés après des tests et une mise en œuvre réussis dans les deux groupes précédents.
Nous avons ensuite divisé ces flux de travail en anneaux de déploiement granulaires pour adopter EMR Serverless, comme indiqué dans le tableau suivant.
| Bague # | Nom | Détails |
| Anneau 0 | Canary | Des emplois à faible risque d’adoption qui devraient générer des économies de coûts. |
| Anneau 1 | Adopteurs précoces | Faible risque Tâches Spark à exécution rapide qui devraient générer des gains élevés. |
| Anneau 2 | Exécution rapide | Reste de l'exécution rapide (step_time <= 20 min) Tâches Spark |
| Anneau 3 | LargerJobs_EZ | Gain potentiel élevé, déplacement facile, travaux Spark à moyen et long terme |
| Anneau 4 | Emplois plus grands | Reste des travaux Spark à moyen et long terme avec des gains potentiels |
| Anneau 5 | Ruche | Des emplois Hive avec des économies de coûts potentiellement plus élevées |
| Anneau 6 | Redshift_EZ | Migration facile des tâches Redshift adaptées à EMR Serverless |
| Anneau 7 | Colle_EZ | Migration facile des tâches Glue adaptées à EMR Serverless |
Résumé des résultats de l’adoption de la production
Les résultats encourageants de l’analyse comparative et de l’adoption de Canary ont généré un intérêt considérable pour une adoption plus large d’EMR sans serveur chez GoDaddy. À ce jour, le déploiement d’EMR Serverless reste en cours. Jusqu'à présent, la solution a permis de réduire les coûts de 62.5 % et d'accélérer l'achèvement total du flux de travail par lots de 50.4 %.
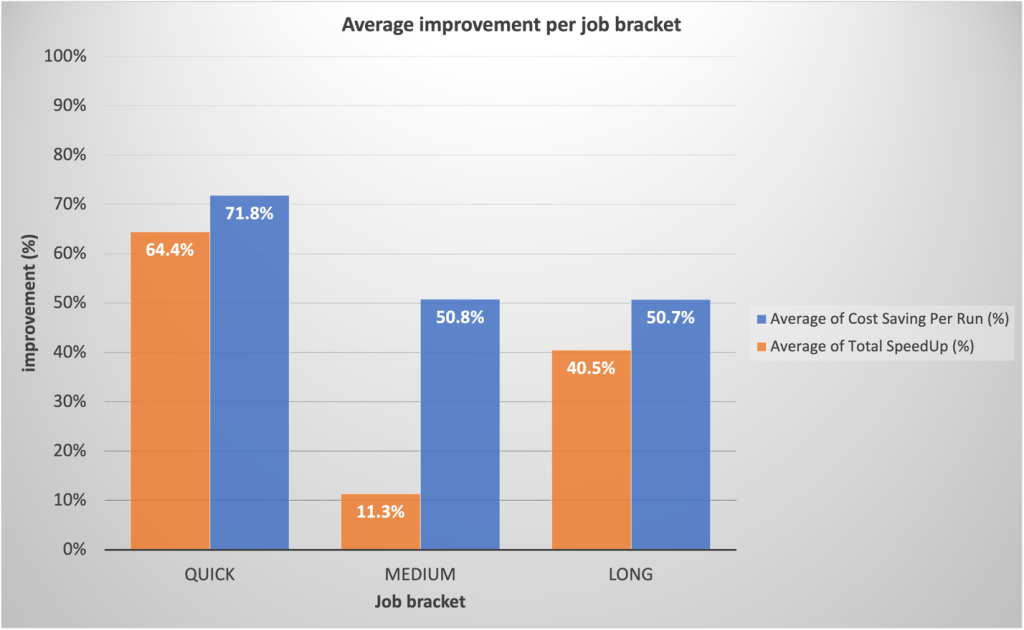
Sur la base de références préliminaires, notre équipe s'attendait à des gains substantiels pour des travaux rapides. À notre grande surprise, les déploiements de production réels ont dépassé les prévisions, étant en moyenne 64.4 % plus rapides contre 42 % prévus et 71.8 % moins chers contre 40 % prévus.
Il est remarquable que les tâches de longue durée aient également connu des améliorations significatives des performances grâce au provisionnement rapide d'EMR Serverless et à la mise à l'échelle agressive rendue possible par l'allocation dynamique des ressources. Nous avons observé une parallélisation substantielle lors des segments à ressources élevées, ce qui se traduit par un temps d'exécution total 40.5 % plus rapide par rapport aux approches traditionnelles. Le tableau suivant illustre les améliorations moyennes par catégorie d'emploi.
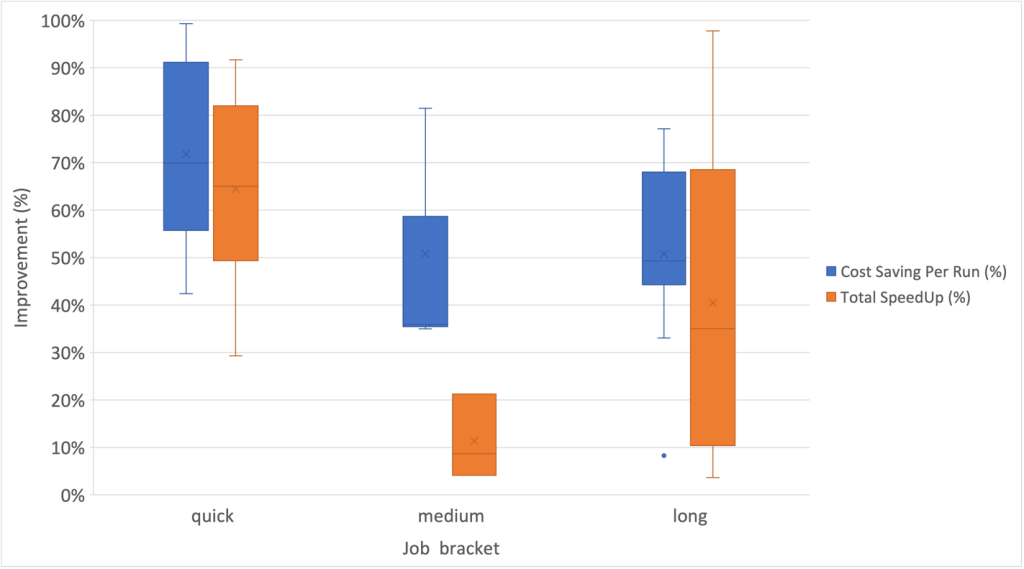
De plus, nous avons observé le plus haut degré de dispersion pour les améliorations de vitesse au sein de la catégorie des emplois à long terme, comme le montre le diagramme en boîte à moustaches suivant.
Exemples de flux de travail adoptés EMR Serverless
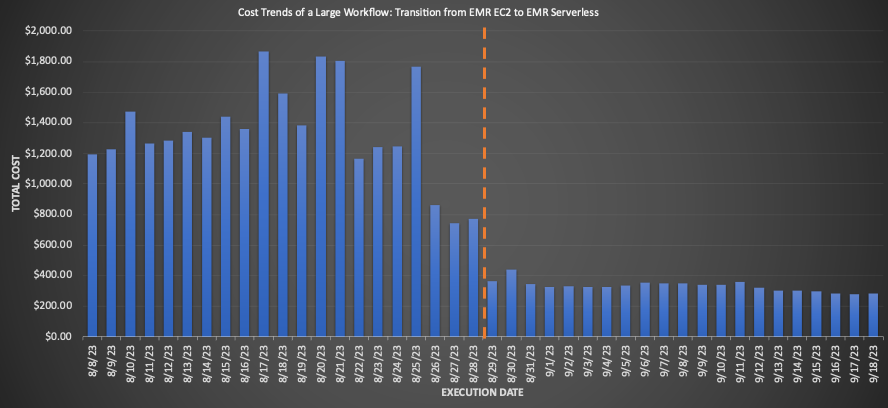
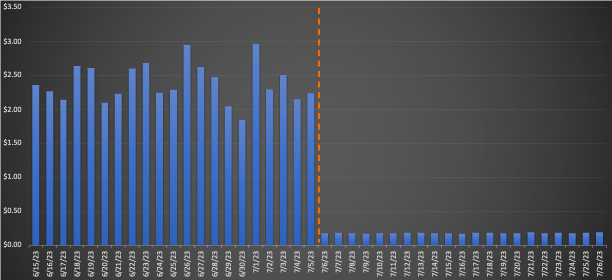
Pour un flux de travail important migré vers EMR Serverless, la comparaison des moyennes sur 3 semaines avant et après la migration a révélé des économies de coûts impressionnantes : une diminution de 75.30 % sur la base du prix de détail avec une amélioration de 10 % de la durée d'exécution totale, améliorant ainsi l'efficacité opérationnelle. Le graphique suivant illustre l’évolution des coûts.
Même si les travaux à exécution rapide ont généré des réductions de coûts par dollar minimes, ils ont généré le pourcentage d'économies de coûts le plus important. Avec des milliers de flux de travail exécutés quotidiennement, les économies accumulées sont substantielles. Le graphique suivant montre la tendance des coûts pour une petite charge de travail migrée d'EMR sur EC2 vers EMR Serverless. La comparaison des moyennes sur 3 semaines avant et après la migration a révélé une économie remarquable de 92.43 % sur les prix de détail à la demande, ainsi qu'une accélération de 80.6 % de la durée d'exécution totale.
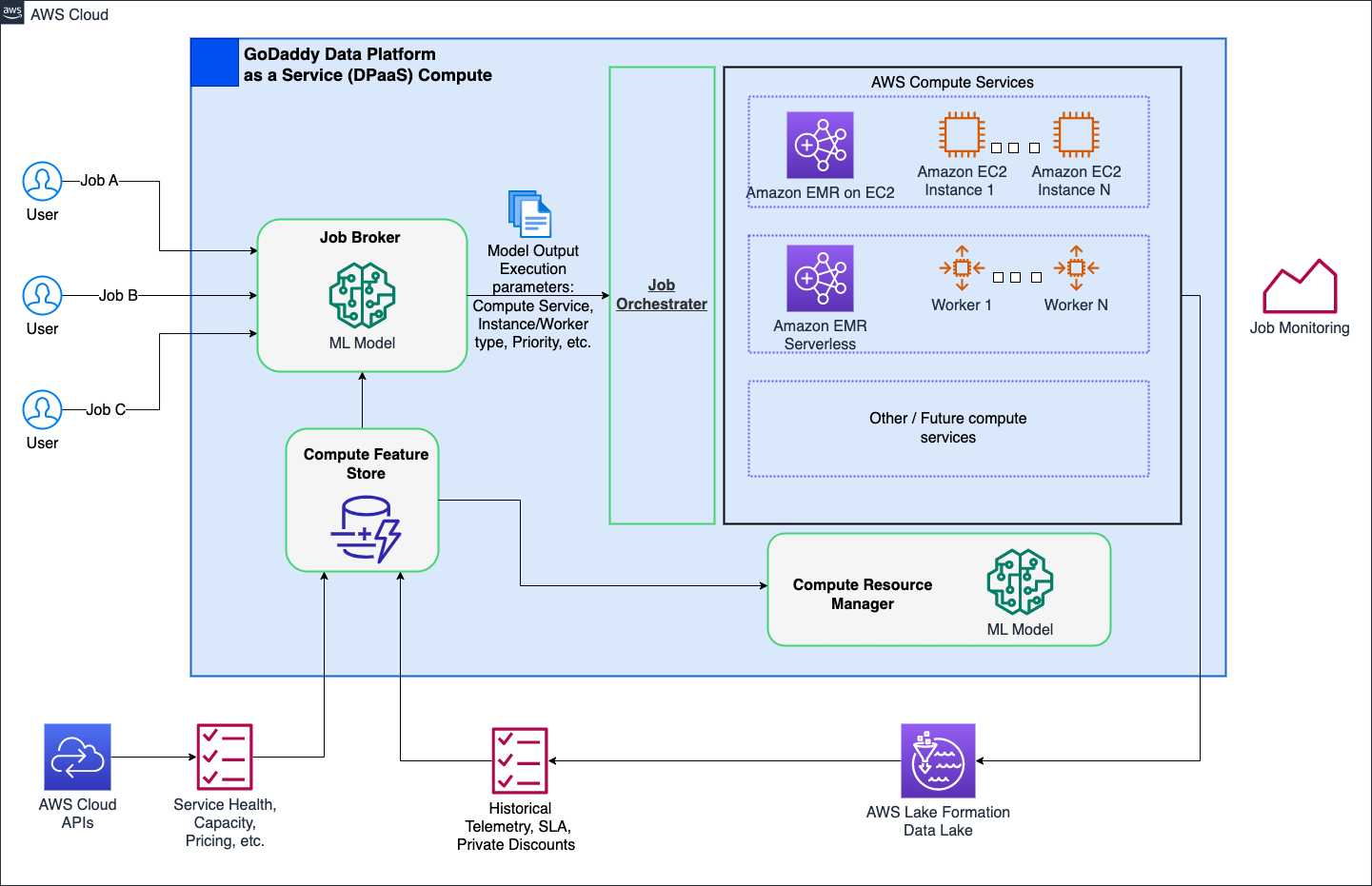
Couche 7 : améliorations à l'échelle de la plateforme
Notre objectif est de révolutionner les opérations de calcul chez GoDaddy, en fournissant des solutions simplifiées mais puissantes à tous les utilisateurs grâce à notre plateforme de calcul intelligente. Avec les solutions de calcul AWS telles que EMR Serverless et EMR sur EC2, il a fourni des exécutions optimisées de charges de travail de traitement des données et d'apprentissage automatique (ML). Un courtier de tâches basé sur le ML détermine intelligemment quand et comment exécuter les tâches en fonction de divers paramètres, tout en permettant aux utilisateurs expérimentés de les personnaliser. De plus, un gestionnaire de ressources de calcul basé sur le ML pré-approvisionne les ressources en fonction de la charge et des données historiques, offrant ainsi un provisionnement efficace et rapide à un coût optimal. Le calcul intelligent offre aux utilisateurs une optimisation prête à l'emploi, s'adressant à diverses personnalités sans compromettre les utilisateurs expérimentés.
Le diagramme suivant montre une illustration de haut niveau de l'architecture de calcul intelligente.
Informations et bonnes pratiques recommandées
La section suivante présente les informations que nous avons recueillies et les meilleures pratiques recommandées que nous avons développées au cours de nos étapes d'adoption préliminaires et plus larges.
Préparation des infrastructures
Bien qu'EMR Serverless soit une méthode de déploiement au sein d'EMR, elle nécessite une certaine préparation de l'infrastructure pour optimiser son potentiel. Tenez compte des exigences et des conseils pratiques suivants concernant la mise en œuvre :
- Utilisez de grands sous-réseaux sur plusieurs zones de disponibilité – Lorsque vous exécutez des charges de travail EMR sans serveur dans votre VPC, assurez-vous que les sous-réseaux s'étendent sur plusieurs zones de disponibilité et ne sont pas limités par les adresses IP. Faire référence à Configuration de l'accès au VPC ainsi que Meilleures pratiques pour la planification de sous-réseaux pour en savoir plus.
- Modifier le quota maximal de vCPU simultanés - Pour des besoins de calcul étendus, il est recommandé d'augmenter votre nombre maximal de processeurs virtuels simultanés par compte quota de services.
- Compatibilité des versions Amazon MWAA - Lors de l'adoption d'EMR Serverless, l'écosystème décentralisé Amazon MWAA de GoDaddy pour l'orchestration des pipelines de données a créé des problèmes de compatibilité à partir des versions disparates des fournisseurs AWS. La mise à niveau directe d'Amazon MWAA était plus efficace que la mise à jour de nombreux DAG. Nous avons facilité l'adoption en mettant à niveau nous-mêmes les instances Amazon MWAA, en documentant les problèmes et en partageant les résultats et les estimations d'efforts pour une planification précise de la mise à niveau.
- Opérateur GoDaddy DME - Pour rationaliser la migration de nombreux DAG Airflow d'EMR sur EC2 vers EMR Serverless, nous avons développé des opérateurs personnalisés adaptant les interfaces existantes. Cela a permis des transitions fluides tout en conservant les options de réglage familières. Les ingénieurs de données pourraient facilement migrer les pipelines avec de simples importations de recherche-remplacement et utiliser immédiatement EMR Serverless.
Atténuation des comportements inattendus
Voici les comportements inattendus que nous avons rencontrés et ce que nous avons fait pour les atténuer :
- Mise à l'échelle agressive de Spark DRA - Pour certaines tâches (8.33 % des benchmarks initiaux, 13.6 % de la production), le coût a augmenté après la migration vers EMR Serverless. Cela était dû au fait que Spark DRA affectait de manière excessive et brève de nouveaux travailleurs, privilégiant les performances plutôt que les coûts. Pour contrecarrer cela, nous fixons des seuils maximaux d'exécuteur en ajustant
spark.dynamicAllocation.maxExecutor, limitant efficacement les agressions liées à la mise à l'échelle d'EMR Serverless. Lors de la migration d'EMR vers EC2, nous vous suggérons d'observer le nombre maximal de cœurs dans l'interface utilisateur de Spark History pour reproduire des limites de calcul similaires dans EMR Serverless, telles que--conf spark.executor.coresainsi que--conf spark.dynamicAllocation.maxExecutors. - Gestion de l'espace disque pour les tâches à grande échelle - Lors de la transition de tâches traitant de gros volumes de données avec des remaniements importants et des besoins de disque importants vers EMR Serverless, nous vous recommandons de configurer
spark.emr-serverless.executor.disken vous référant aux métriques de tâches Spark existantes. De plus, des configurations commespark.executor.corescombiné avecspark.emr-serverless.executor.diskainsi quespark.dynamicAllocation.maxExecutorspermettre le contrôle de la taille du travailleur sous-jacent et du stockage total associé lorsque cela est avantageux. Par exemple, un travail de lecture aléatoire avec une utilisation du disque relativement faible peut bénéficier de l'utilisation d'un travailleur plus volumineux pour augmenter la probabilité de récupérations aléatoires locales.
Conclusion
Comme indiqué dans cet article, nos expériences concernant l'adoption d'EMR Serverless sur arm64 ont été extrêmement positives. Les résultats impressionnants que nous avons obtenus, notamment une réduction des coûts de 60 %, des exécutions 50 % plus rapides des charges de travail Spark par lots et une étonnante multiplication par cinq de la vitesse de développement et de test, en disent long sur le potentiel de cette technologie. De plus, nos résultats actuels suggèrent qu'en adoptant largement Graviton2 sur EMR Serverless, nous pourrions potentiellement réduire l'empreinte carbone jusqu'à 60 % pour notre traitement par lots.
Cependant, il est crucial de comprendre que ces résultats ne constituent pas un scénario unique. Les améliorations auxquelles vous pouvez vous attendre dépendent de facteurs comprenant, sans toutefois s'y limiter, la nature spécifique de vos flux de travail, les configurations de cluster, les niveaux d'utilisation des ressources et les fluctuations de la capacité de calcul. Par conséquent, nous préconisons fortement une stratégie de déploiement basée sur les données et basée sur les anneaux lorsque nous envisageons l'intégration d'EMR Serverless, ce qui peut aider à optimiser au maximum ses avantages.
Un merci spécial à Mukul Sharma ainsi que Boris Berlin pour leurs contributions à l’analyse comparative. Un grand merci à Travis Mühlestein (CDO), Abhijit Kundu (VP ingénierie), Vincent Yung (Directeur principal Ing.), et Wai Kin Lau (Sr. Director Data Eng.) pour leur soutien continu.
À propos des auteurs
 Brandon Abear est ingénieur de données principal au sein de l'organisation Data & Analytics (DnA) chez GoDaddy. Il aime tout ce qui concerne le Big Data. Dans ses temps libres, il aime voyager, regarder des films et jouer à des jeux de rythme.
Brandon Abear est ingénieur de données principal au sein de l'organisation Data & Analytics (DnA) chez GoDaddy. Il aime tout ce qui concerne le Big Data. Dans ses temps libres, il aime voyager, regarder des films et jouer à des jeux de rythme.
 Dinesh Sharma est ingénieur de données principal au sein de l'organisation Data & Analytics (DnA) chez GoDaddy. Il est passionné par l'expérience utilisateur et la productivité des développeurs, toujours à la recherche de moyens d'optimiser les processus d'ingénierie et de réduire les coûts. Dans ses temps libres, il adore lire et est un grand fan de mangas.
Dinesh Sharma est ingénieur de données principal au sein de l'organisation Data & Analytics (DnA) chez GoDaddy. Il est passionné par l'expérience utilisateur et la productivité des développeurs, toujours à la recherche de moyens d'optimiser les processus d'ingénierie et de réduire les coûts. Dans ses temps libres, il adore lire et est un grand fan de mangas.
 Jean Bush est ingénieur logiciel principal au sein de l'organisation Data & Analytics (DnA) chez GoDaddy. Il a pour passion de permettre aux organisations de gérer plus facilement leurs données et de les utiliser pour faire progresser leurs activités. Dans ses temps libres, il aime faire de la randonnée, du camping et faire du vélo électrique.
Jean Bush est ingénieur logiciel principal au sein de l'organisation Data & Analytics (DnA) chez GoDaddy. Il a pour passion de permettre aux organisations de gérer plus facilement leurs données et de les utiliser pour faire progresser leurs activités. Dans ses temps libres, il aime faire de la randonnée, du camping et faire du vélo électrique.
 Özcan Ilikhan est le directeur de l'ingénierie pour la plateforme de données et de ML chez GoDaddy. Il possède plus de deux décennies d’expérience en leadership multidisciplinaire, allant de startups à des entreprises mondiales. Il a une passion pour l'exploitation des données et de l'IA pour créer des solutions qui ravissent les clients, leur permettent d'en faire plus et améliorent l'efficacité opérationnelle. En dehors de sa vie professionnelle, il aime lire, faire de la randonnée, jardiner, faire du bénévolat et se lancer dans des projets de bricolage.
Özcan Ilikhan est le directeur de l'ingénierie pour la plateforme de données et de ML chez GoDaddy. Il possède plus de deux décennies d’expérience en leadership multidisciplinaire, allant de startups à des entreprises mondiales. Il a une passion pour l'exploitation des données et de l'IA pour créer des solutions qui ravissent les clients, leur permettent d'en faire plus et améliorent l'efficacité opérationnelle. En dehors de sa vie professionnelle, il aime lire, faire de la randonnée, jardiner, faire du bénévolat et se lancer dans des projets de bricolage.
 Harsh Vardhan est un architecte de solutions AWS, spécialisé dans le Big Data et l'analyse. Il possède plus de 8 ans d’expérience dans le domaine du big data et de la science des données. Il a pour passion d'aider les clients à adopter les meilleures pratiques et à découvrir des informations à partir de leurs données.
Harsh Vardhan est un architecte de solutions AWS, spécialisé dans le Big Data et l'analyse. Il possède plus de 8 ans d’expérience dans le domaine du big data et de la science des données. Il a pour passion d'aider les clients à adopter les meilleures pratiques et à découvrir des informations à partir de leurs données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/

