

La plupart d’entre nous manipulent régulièrement des fichiers PDF. Il y a toujours des cas où vous devez extraire des pages spécifiques de fichiers PDF volumineux - un demande de remboursement à partir d'un téléchargement groupé, d'une page d'un article académique, d'un table à partir d'un long rapport, ou même d'une recette d'un grand livre de cuisine.
Alors, comment extraire une page ou quelques pages d’un PDF ? Personne ne veut recourir au copier-coller ou à l’impression et à la numérisation. Ces méthodes sont fastidieuses, prennent du temps et peuvent entraîner une perte de qualité.
Cet article répertorie cinq méthodes différentes pour extraire des pages d'un document PDF. Nous vous guiderons étape par étape à travers chaque technique afin que vous puissiez choisir celle qui vous convient ou même les combiner pour une efficacité maximale.
Pourquoi devons-nous extraire des pages de PDF ?
Le PDF est largement utilisé car il est portable, offre une sécurité et préserve le formatage. Cependant, un PDF volumineux peut s'avérer fastidieux, surtout lorsque vous n'avez besoin que de certaines pages. La nécessité d'extraire des pages d'un PDF peut survenir pour plusieurs raisons :
- Partager des parties spécifiques d'un document
- Suppression des informations confidentielles
- Envoi uniquement des informations pertinentes pour économiser de l'espace et du temps
- Créer un nouveau document à partir de parties d'un document existant
- Extraire uniquement le résumé ou le mémoire d’un rapport complet
Quelle que soit votre raison, extraire des pages d'un PDF peut rendre votre travail beaucoup plus simple. Passons maintenant aux différentes méthodes pour extraire des pages d'un PDF.
C'est la méthode la plus simple. Vous n'avez pas besoin de télécharger ou d'installer de logiciel. La plupart des lecteurs PDF disposent d'une fonction d'impression qui vous permet de sélectionner les pages souhaitées et de les imprimer dans un nouveau fichier PDF.
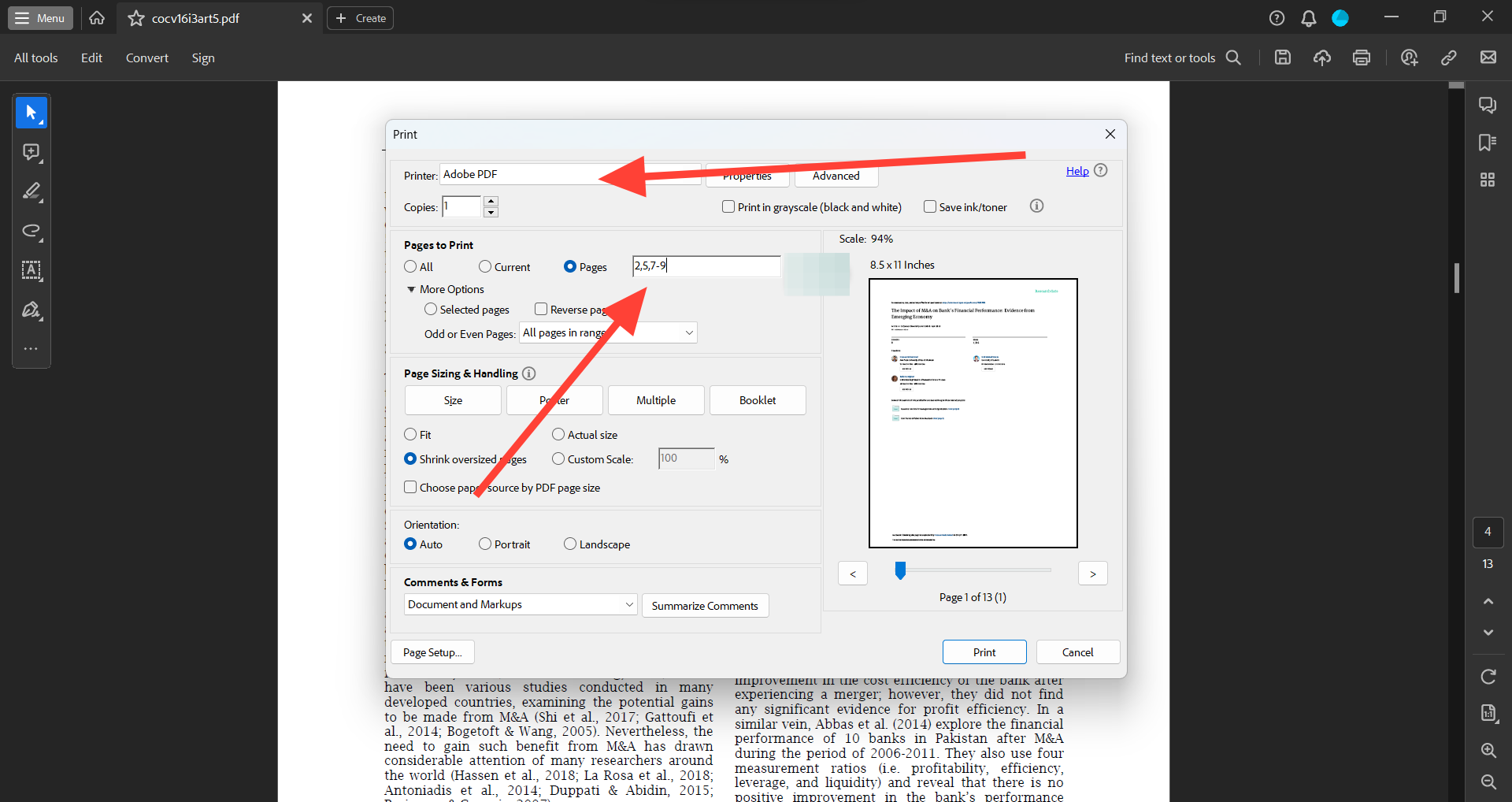
Voyons comment procéder dans votre Adobe Reader standard :
- Ouvrez le fichier PDF dont vous souhaitez extraire des pages
- Cliquez sur 'Menu'
- Choisissez l'option "Imprimer"
- Spécifiez les pages que vous souhaitez extraire dans le champ à côté de « Pages à imprimer »
- Définissez « Imprimante » sur « Adobe PDF »
- Cliquez sur "Imprimer"
- Choisissez l'emplacement où vous souhaitez enregistrer les pages extraites et renommez le nouveau fichier PDF
- Cliquez sur "Enregistrer"
Cela créera un nouveau fichier PDF contenant les pages que vous avez spécifiées. Vous pouvez saisir des pages individuelles, des plages de pages et une combinaison des deux (qui doivent être séparées par des virgules).
Bien que cette méthode soit simple et ne nécessite pas d’outils spéciaux, elle présente quelques inconvénients. Des numéros de page mal alignés pourraient entraîner l’extraction de mauvaises pages. Le traitement en masse peut être compliqué car vous devez saisir manuellement chaque numéro de page.
Il n'y a pas d'option pour réorganiser les pages après l'extraction. Et la sortie reste au format PDF : vous ne pouvez pas choisir un format de sortie différent.
Remarque : Cette méthode ne fonctionnera pas si le PDF est protégé par mot de passe ou si l'impression est désactivée..
Désormais, si vous souhaitez extraire des pages d'un PDF à une échelle plus professionnelle, vous pouvez essayer Acrobat d'Adobe. Ce logiciel n'est pas gratuit mais propose un essai gratuit de 7 jours.
Le forfait Acrobat Pro commence à 19.99 $/mois et comprend une suite de fonctionnalités qui peuvent vous aider à optimiser votre processus de gestion des documents.
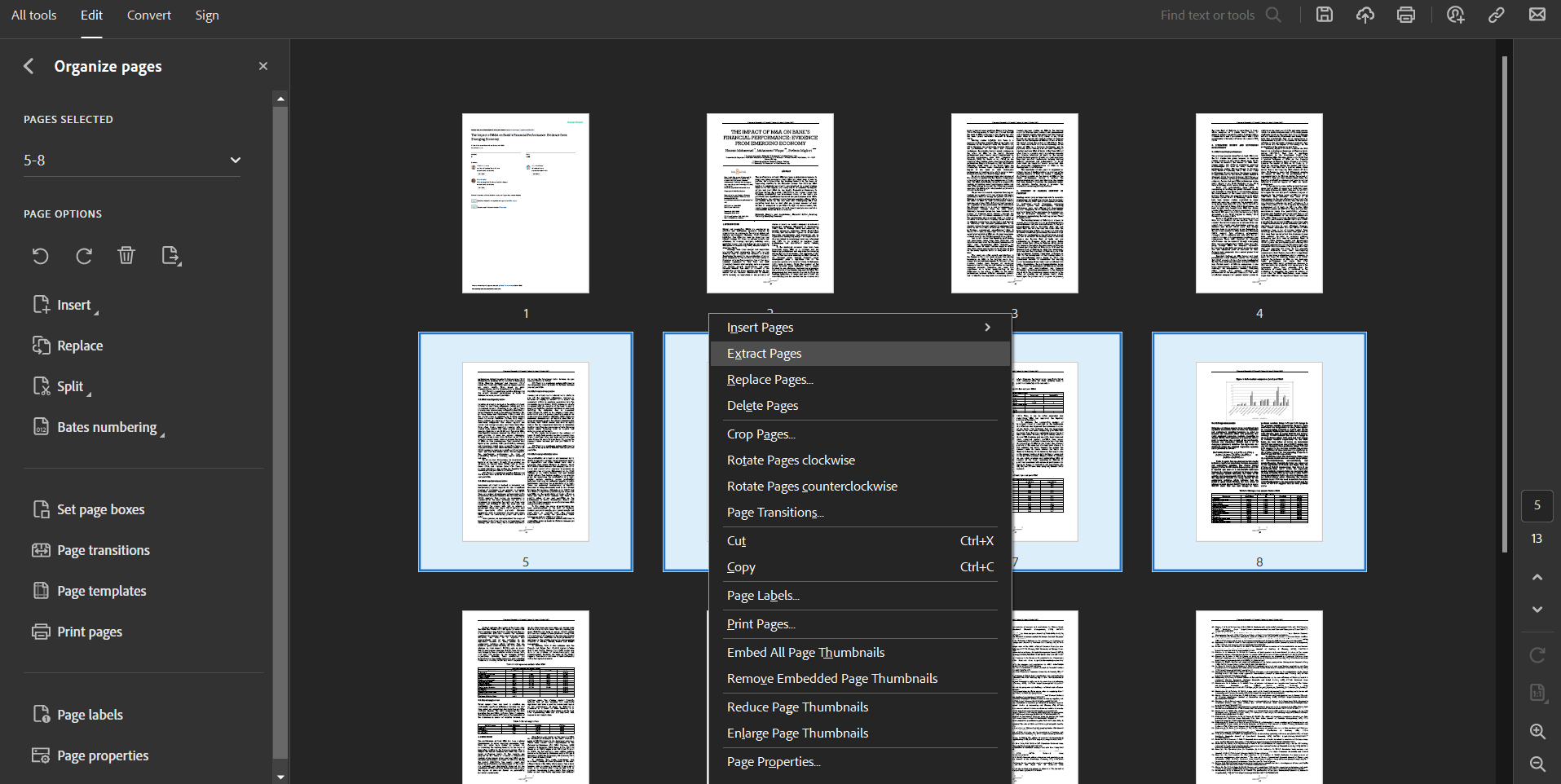
Voici comment extraire des pages à l’aide d’Adobe Acrobat :
- Ouvrez le fichier PDF dont vous souhaitez extraire les pages dans Adobe Acrobat
- Cliquez sur le menu "Modifier"
- Choisissez « Organiser les pages »
- Appuyez sur Contrôle (sous Windows) ou Commande (sous Mac) et cliquez sur les pages que vous souhaitez extraire
- Faites un clic droit sur les pages sélectionnées
- Choisissez « Extraire les pages »
- Dans la nouvelle boîte de dialogue, cochez « Extraire les pages en tant que fichiers séparés » si vous souhaitez que chaque page soit un PDF distinct.
- Choisissez l'emplacement où vous souhaitez enregistrer les pages extraites
- Cliquez sur « Extraire »
Cette méthode fonctionne bien car elle conserve tous les composants interactifs du PDF, tels que les hyperliens, les commentaires et les formulaires. Il vous permet également d'extraire autant de pages que vous le souhaitez et de les enregistrer sous forme de fichiers séparés ou même de diviser le PDF en plusieurs PDF.
Cependant, vous devez acheter le logiciel après la période d'essai, et cela peut coûter assez cher si vous n'en avez besoin que pour des tâches simples. Il ne fournit pas non plus d'option pour convertir les pages extraites dans d'autres formats de fichiers que le PDF.
3. Utilisation de PDF pour diviser des PDF en ligne
Les séparateurs de PDF peuvent s'avérer utiles si vous ne souhaitez pas télécharger de lecteur ou payer pour Adobe Acrobat. Il existe de nombreux outils en ligne gratuits qui vous permettent de diviser des fichiers PDF et d'extraire des pages spécifiques.
Tout ce que vous avez à faire est de télécharger votre PDF sur le site Web, de spécifier les pages que vous souhaitez extraire et de télécharger le nouveau PDF.
Certains des outils en ligne populaires incluent :
Voici un guide général sur la façon d'utiliser ces séparateurs de PDF en ligne pour extraire une page d'un PDF :
- Rendez-vous sur le site de l'outil en ligne que vous avez choisi
- Cliquez sur « Sélectionner un fichier PDF » ou sur une option similaire pour télécharger votre PDF.
- Une fois le PDF téléchargé, sélectionnez les pages que vous souhaitez extraire
- Cliquez sur « Extraire les pages » ou une option similaire
- Téléchargez le nouveau fichier PDF avec les pages extraites
Ces outils en ligne sont simples à utiliser et la plupart sont gratuits. Beaucoup de ces outils sont dotés de fonctionnalités supplémentaires, telles que la fusion de PDF, la conversion entre différents formats de fichiers, la compression de PDF, etc. Mais soyez prêt à explorer un peu, car chaque composant a généralement sa page ou son onglet.
L’un des inconvénients majeurs des outils en ligne est le risque de télécharger des documents confidentiels ou sensibles sur un serveur tiers. Votre fichier pourrait finir entre de mauvaises mains si la sécurité du site Web est compromise. Ainsi, si vous manipulez des données confidentielles, consultez rapidement la politique de confidentialité du site Web.
La vitesse peut être un autre problème. La congestion du serveur ou du réseau peut ralentir les choses, notamment avec des fichiers volumineux. En outre, la version gratuite peut limiter certaines fonctionnalités, vous lancer des publicités ou vous inciter à effectuer une mise à niveau pour un traitement plus rapide. Prenez SmallPDF, par exemple ; vous ne pouvez pas renommer votre fichier extrait sans payer.
La qualité de votre sortie peut également être aléatoire en fonction de l'outil, et le nombre de pages que vous pouvez extraire en une seule fois peut être limité.
Vous traitez des documents confidentiels ou gérez des fichiers volumineux ? Un logiciel open source pourrait être la solution pour vous.
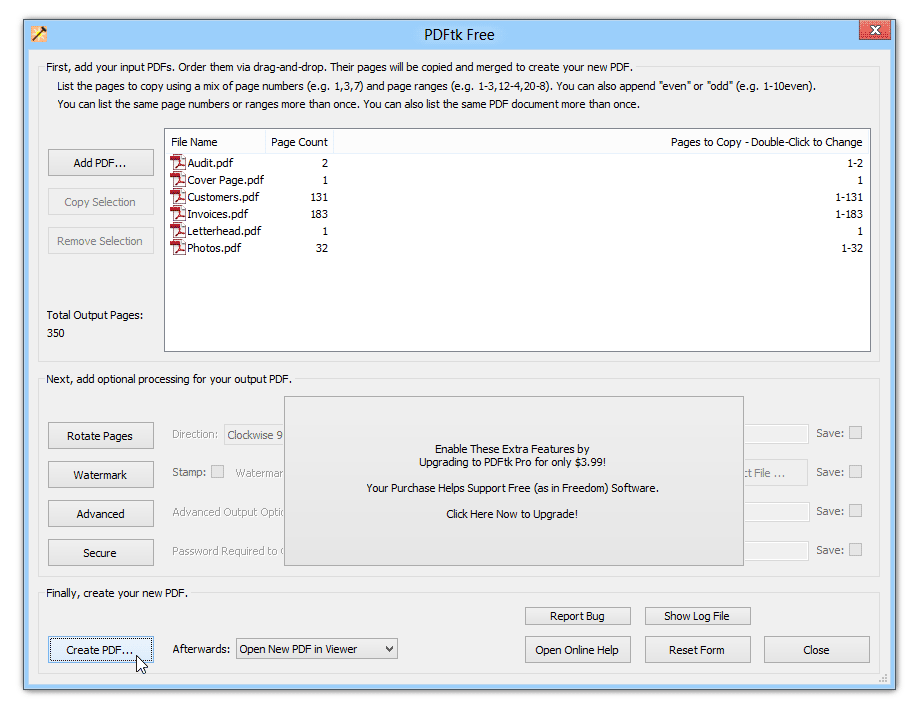
Ces outils sont gratuits et vous pouvez les utiliser sur votre ordinateur local, évitant ainsi les problèmes de sécurité associés aux outils en ligne. Ils ont tendance à être beaucoup plus puissants et flexibles, offrant de nombreuses options de gestion des fichiers PDF.
Certaines options open source incluent :
- PDFsam Visuel
- OCRmonPDF
- PDFMate
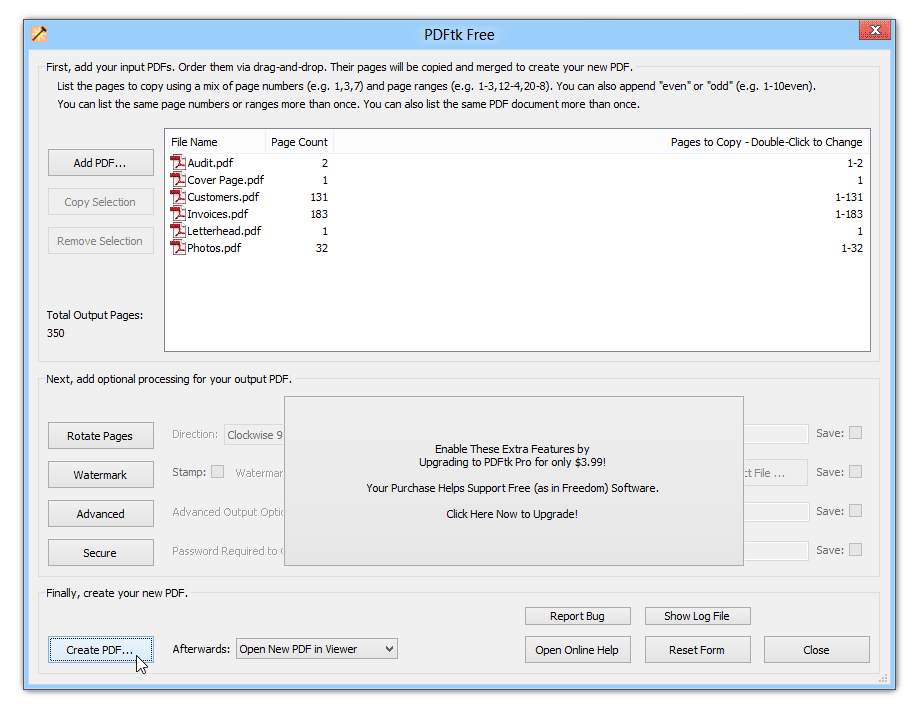
- PDFtk
- PDFill
Voici un guide général pour extraire des pages à l'aide d'un logiciel open source :
- Téléchargez et installez le logiciel open source de votre choix
- Ouvrez le logiciel et chargez votre fichier PDF
- Choisissez la fonction « Extraire » ou « Split » (la formulation exacte dépendra du logiciel)
- Spécifiez les pages que vous souhaitez extraire
- Cliquez sur « Extraire » ou « Diviser »
- Choisissez l'emplacement où vous souhaitez enregistrer les pages extraites
- Cliquez sur « Enregistrer » ou « OK »
Avec ces outils, vous pouvez extraire, fusionner, faire pivoter et effectuer de nombreuses autres opérations sur vos fichiers PDF. Ils prennent également généralement en charge le traitement par lots afin que vous puissiez extraire des pages de plusieurs PDF à la fois.
L’un des inconvénients potentiels des logiciels open source est qu’ils ne sont peut-être pas aussi conviviaux que les outils en ligne ou les logiciels commerciaux. Vous devrez peut-être lire la documentation, gérer les interfaces de ligne de commande et gérer les bogues occasionnels. Vous aurez peut-être besoin de connaissances techniques pour en tirer le meilleur parti.
De plus, même si ces outils peuvent gérer la plupart des tâches PDF, ils peuvent ne pas prendre en charge des fonctionnalités avancées telles que les éléments interactifs, les annotations ou le cryptage. Certains peuvent également manquer d’interface utilisateur graphique, ce qui rend la navigation plus difficile pour les utilisateurs non techniques.
La plupart des outils mentionnés ci-dessus fonctionnent très bien lorsque l'extraction d'informations est basée sur les numéros de page. Mais que se passe-t-il si vous devez extraire des pages en fonction de leur contenu ?
Par exemple, vous souhaitez extraire et traiter toutes les factures d'une valeur de plus de 500 $ ou toutes les pages portant un nom ou un terme spécifique. Un OCR alimenté par l'IA (Reconnaissance optique de caractères) peut être utile dans de tels cas.

Nanonets vous permet d'automatiser le processus d'extraction de données à partir de PDF. Grâce à ses capacités d'IA, Nanonets peut reconnaître et extraire du contenu spécifique de vos pages, rendant l'extraction d'informations plus efficace et précise.
Voici un guide général pour extraire des données à l'aide de Nanonets :
- Inscrivez-vous pour compte gratuit sur Nanonets
- Téléchargez vos fichiers PDF
- Configurez le modèle d'IA en sélectionnant les champs de données que vous souhaitez extraire
- Entraîner le modèle en fournissant quelques exemples
- Une fois le modèle formé, extrayez les données souhaitées du PDF téléchargé
- Téléchargez les données extraites dans votre format préféré (CSV, JSON, etc.)
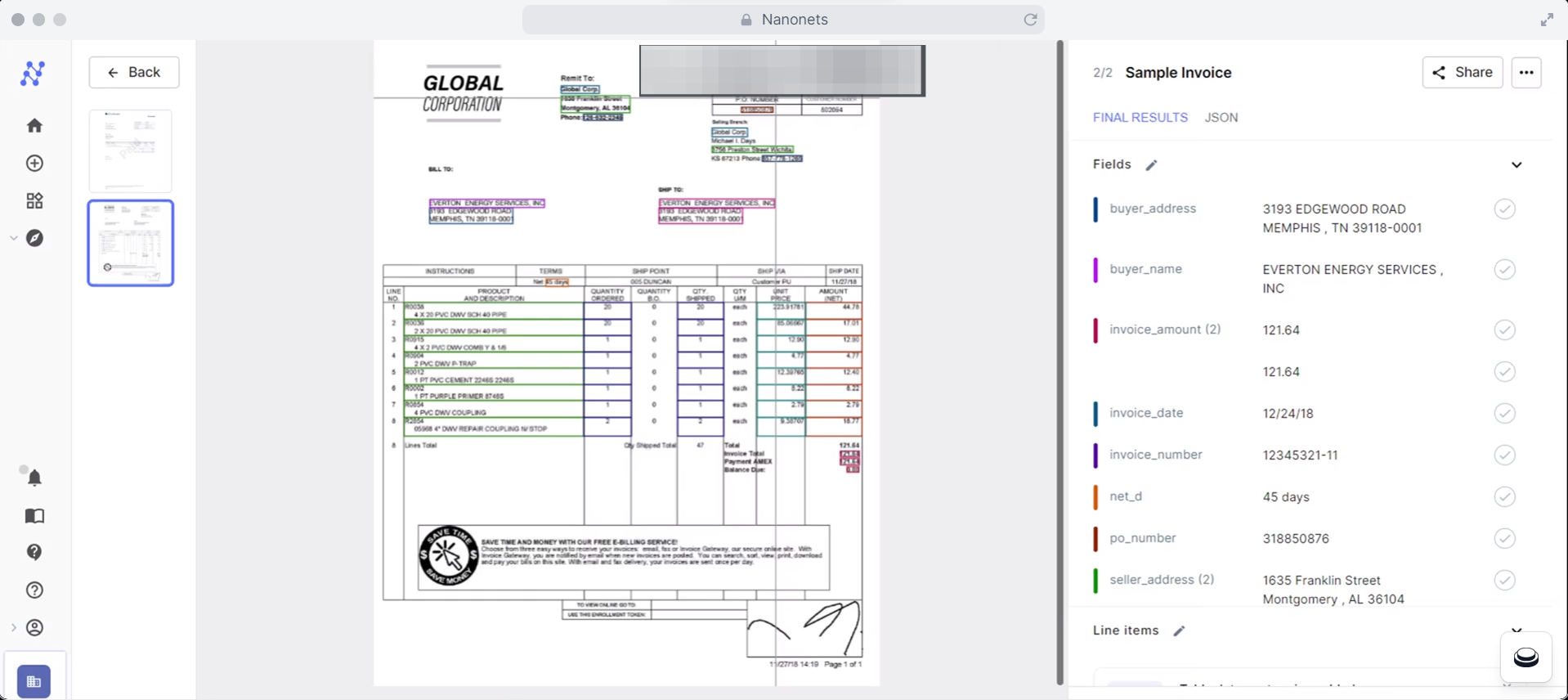
Téléchargez n'importe quel nombre de PDF et laissez les Nanonets faire le gros du travail à votre place. L'outil peut traiter plusieurs fichiers simultanément, ce qui vous fait gagner beaucoup de temps et d'efforts.
Nanonets combine la technologie avancée d'OCR et d'IA pour reconnaître le texte, les chiffres et d'autres données dans vos reçus, factures, relevés bancaires, bons de commande et autres documents. Il peut rendre vos PDF consultables et traiter des documents complexes avec plusieurs mises en page, langues et structures.

Cela permet à l'outil de gérer des documents structurés et non structurés et d'extraire avec précision uniquement les informations dont vous avez besoin. De plus, il apprend de votre intervention et s’améliore avec le temps.
De plus, Nanonets est livré avec des fonctionnalités prédéfinies, workflows d'automatisation low-code. Vous pouvez automatiser l'ensemble du processus depuis l'extraction, la vérification et la validation jusqu'à la création de pistes d'audit, le traitement des paiements ou toute autre opération. Cela vous permet de traiter les documents plus rapidement, de réduire les erreurs manuelles et de gagner un temps précieux.
nanonets s'intègre parfaitement avec vos systèmes existants tels que les logiciels ERP, CRM et comptables. Qu'il s'agisse de Xero, QuickBooks, Salesforce ou de toute autre application, vous pouvez directement introduire les données extraites dans ces systèmes avec une intervention manuelle minimale.

Il prend également en charge les services de stockage de documents tels que Google Drive, Dropbox et SharePoint, vous permettant d'accéder et de gérer facilement vos documents.
Pour ceux qui se soucient de la sécurité des données, Nanonets utilise le cryptage pour la protection des données et garantit que vos données sont traitées dans un environnement sécurisé. Il respecte également les réglementations sur la confidentialité des données telles que le RGPD et le CCPA.
Réflexions finales
Et voilà : cinq façons différentes d’extraire des pages d’un PDF. Espérons que ce guide vous a donné une idée plus claire de la façon d’aborder vos tâches d’extraction de PDF.
Évaluez toujours la complexité de vos documents, le temps et les efforts que vous pouvez vous permettre d’y consacrer ainsi que le niveau de précision requis avant de choisir une méthode. Le bon outil peut vraiment changer la donne. Il peut vous faire économiser des heures de travail manuel, éviter les erreurs, rationaliser votre flux de travail et vous aider à vous concentrer sur des tâches plus critiques.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- GraphiquePrime. Élevez votre jeu de trading avec ChartPrime. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://nanonets.com/blog/extract-pages-from-pdf/


{kind=link}