Cet article est co-écrit avec Santosh Waddi et Nanda Kishore Thatikonda de BigBasket.
BigBasket est la plus grande épicerie et épicerie en ligne d'Inde. Ils opèrent sur plusieurs canaux de commerce électronique tels que le commerce rapide, la livraison par créneaux horaires et les abonnements quotidiens. Vous pouvez également acheter dans leurs magasins physiques et distributeurs automatiques. Ils proposent un large assortiment de plus de 50,000 1,000 produits répartis dans 500 10 marques et sont présents dans plus de XNUMX villes et villages. BigBasket sert plus de XNUMX millions de clients.
Dans cet article, nous expliquons comment BigBasket a utilisé Amazon Sage Maker pour former leur modèle de vision par ordinateur pour l'identification des produits de grande consommation (FMCG), ce qui les a aidés à réduire le temps de formation d'environ 50 % et à économiser les coûts de 20 %.
Défis clients
Aujourd'hui, la plupart des supermarchés et des magasins physiques en Inde proposent un paiement manuel à la caisse. Cela pose deux problèmes :
- Cela nécessite une main d’œuvre supplémentaire, des autocollants de poids et une formation répétée pour l’équipe opérationnelle en magasin au fur et à mesure de son évolution.
- Dans la plupart des magasins, la caisse est différente des comptoirs de pesée, ce qui ajoute à la friction dans le parcours d'achat du client. Les clients perdent souvent l’autocollant de poids et doivent retourner aux comptoirs de pesée pour en récupérer un à nouveau avant de procéder au processus de paiement.
Processus de paiement automatique
BigBasket a introduit dans ses magasins physiques un système de paiement basé sur l'IA qui utilise des caméras pour distinguer les articles de manière unique. La figure suivante donne un aperçu du processus de paiement.
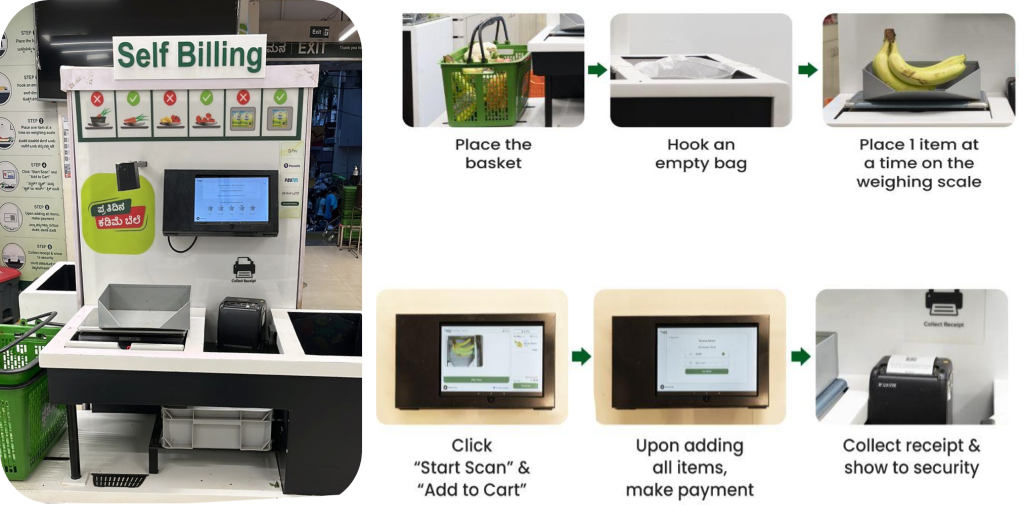
L'équipe BigBasket exécutait des algorithmes de ML open source et internes pour la reconnaissance d'objets par vision par ordinateur afin d'alimenter le paiement activé par l'IA dans leur magasin. Fraîcheur magasins (physiques). Nous étions confrontés aux défis suivants pour exploiter leur configuration existante :
- Avec l'introduction continue de nouveaux produits, le modèle de vision par ordinateur devait intégrer en permanence de nouvelles informations sur les produits. Le système devait gérer un vaste catalogue de plus de 12,000 600 unités de gestion de stock (SKU), de nouvelles références étant continuellement ajoutées à un rythme de plus de XNUMX par mois.
- Pour suivre le rythme des nouveaux produits, un nouveau modèle a été produit chaque mois en utilisant les dernières données de formation. Il était coûteux et fastidieux de former fréquemment les modèles pour qu'ils s'adaptent aux nouveaux produits.
- BigBasket souhaitait également réduire la durée du cycle de formation afin d'améliorer les délais de mise sur le marché. En raison de l'augmentation du nombre de SKU, le temps nécessaire au modèle augmentait de manière linéaire, ce qui avait un impact sur leur délai de mise sur le marché car la fréquence de formation était très élevée et prenait beaucoup de temps.
- L'augmentation des données pour la formation des modèles et la gestion manuelle du cycle de formation complet de bout en bout ajoutaient des frais généraux importants. BigBasket l'exécutait sur une plateforme tierce, ce qui entraînait des coûts importants.
Vue d'ensemble de la solution
Nous avons recommandé à BigBasket de réorganiser sa solution existante de détection et de classification des produits FMCG à l'aide de SageMaker pour relever ces défis. Avant de passer à la production à grande échelle, BigBasket a testé un projet pilote sur SageMaker pour évaluer les indicateurs de performances, de coûts et de commodité.
Leur objectif était d’affiner un modèle d’apprentissage automatique (ML) de vision par ordinateur existant pour la détection des SKU. Nous avons utilisé une architecture de réseau neuronal convolutif (CNN) avec ResNet152 pour la classification des images. Un ensemble de données important d'environ 300 images par SKU a été estimé pour la formation du modèle, ce qui donne un total de plus de 4 millions d'images de formation. Pour certains SKU, nous avons augmenté les données pour englober un plus large éventail de conditions environnementales.
Le diagramme suivant illustre l'architecture de la solution.

Le processus complet peut être résumé dans les étapes de haut niveau suivantes :
- Effectuez le nettoyage, l’annotation et l’augmentation des données.
- Stocker les données dans un Service de stockage simple Amazon (Amazon S3) seau.
- Utilisez SageMaker et Amazon FSx pour Lustre pour une augmentation efficace des données.
- Divisez les données en ensembles d’entraînement, de validation et de test. Nous avons utilisé FSx pour Lustre et Service de base de données relationnelle Amazon (Amazon RDS) pour un accès rapide aux données parallèles.
- Utiliser une coutume PyTorch Conteneur Docker comprenant d'autres bibliothèques open source.
- Utilisez Parallélisme des données distribuées SageMaker (SMDDP) pour une formation distribuée accélérée.
- Enregistrer les métriques de formation du modèle.
- Copiez le modèle final dans un compartiment S3.
BigBasket d'occasion Carnets SageMaker pour entraîner leurs modèles ML et ont pu facilement porter leur PyTorch open source existant et d'autres dépendances open source vers un conteneur SageMaker PyTorch et exécuter le pipeline de manière transparente. Il s’agissait du premier avantage constaté par l’équipe BigBasket, car aucune modification n’était nécessaire au code pour le rendre compatible avec un environnement SageMaker.
Le réseau modèle se compose d'une architecture ResNet 152 suivie de couches entièrement connectées. Nous avons gelé les couches de fonctionnalités de bas niveau et conservé les poids acquis grâce à l'apprentissage par transfert du modèle ImageNet. Le nombre total de paramètres du modèle était de 66 millions, soit 23 millions de paramètres pouvant être entraînés. Cette approche basée sur l'apprentissage par transfert les a aidés à utiliser moins d'images au moment de la formation, a également permis une convergence plus rapide et a réduit la durée totale de la formation.
Construire et entraîner le modèle dans Amazon SageMakerStudio fourni un environnement de développement intégré (IDE) avec tout le nécessaire pour préparer, créer, former et régler des modèles. L'augmentation des données d'entraînement à l'aide de techniques telles que le recadrage, la rotation et le retournement des images a contribué à améliorer les données d'entraînement du modèle et sa précision.
La formation des modèles a été accélérée de 50 % grâce à l'utilisation de la bibliothèque SMDDP, qui comprend des algorithmes de communication optimisés conçus spécifiquement pour l'infrastructure AWS. Pour améliorer les performances de lecture/écriture des données lors de la formation du modèle et de l'augmentation des données, nous avons utilisé FSx pour Lustre pour un débit haute performance.
La taille de leurs données de formation de départ était supérieure à 1.5 To. Nous en avons utilisé deux Cloud de calcul élastique Amazon (Amazon EC2) p4d.24 grandes instances avec 8 GPU et 40 Go de mémoire GPU. Pour la formation distribuée SageMaker, les instances doivent se trouver dans la même région AWS et la même zone de disponibilité. De plus, les données de formation stockées dans un compartiment S3 doivent se trouver dans la même zone de disponibilité. Cette architecture permet également à BigBasket de passer à d'autres types d'instances ou d'ajouter davantage d'instances à l'architecture actuelle pour répondre à toute croissance significative des données ou réduire davantage le temps de formation.
Comment la bibliothèque SMDDP a contribué à réduire le temps, les coûts et la complexité de la formation
Dans la formation traditionnelle sur les données distribuées, le cadre de formation attribue des rangs aux GPU (workers) et crée une réplique de votre modèle sur chaque GPU. Au cours de chaque itération de formation, le lot de données global est divisé en morceaux (fragments de lots) et un morceau est distribué à chaque travailleur. Chaque travailleur procède ensuite aux passes avant et arrière définies dans votre script de formation sur chaque GPU. Enfin, les poids et gradients du modèle des différentes répliques du modèle sont synchronisés à la fin de l'itération via une opération de communication collective appelée AllReduce. Une fois que chaque travailleur et GPU dispose d’une réplique synchronisée du modèle, l’itération suivante commence.
La bibliothèque SMDDP est une bibliothèque de communication collective qui améliore les performances de ce processus de formation parallèle de données distribuées. La bibliothèque SMDDP réduit la surcharge de communication des principales opérations de communication collective telles que AllReduce. Son implémentation d'AllReduce est conçue pour l'infrastructure AWS et peut accélérer la formation en chevauchant l'opération AllReduce avec la passe arrière. Cette approche permet d'obtenir une efficacité de mise à l'échelle quasi linéaire et une vitesse de formation plus rapide en optimisant les opérations du noyau entre les processeurs et les GPU.
Notez les calculs suivants :
- La taille du lot global est (nombre de nœuds dans un cluster) * (nombre de GPU par nœud) * (par fragment de lot)
- Un fragment de lot (petit lot) est un sous-ensemble de l'ensemble de données attribué à chaque GPU (travailleur) par itération
BigBasket a utilisé la bibliothèque SMDDP pour réduire son temps de formation global. Avec FSx pour Lustre, nous avons réduit le débit de lecture/écriture des données lors de la formation du modèle et de l'augmentation des données. Grâce au parallélisme des données, BigBasket a pu réaliser une formation près de 50 % plus rapide et 20 % moins chère par rapport à d'autres alternatives, offrant ainsi les meilleures performances sur AWS. SageMaker arrête automatiquement le pipeline de formation une fois terminé. Le projet s'est terminé avec succès avec un temps de formation 50 % plus rapide sur AWS (4.5 jours sur AWS contre 9 jours sur leur plateforme existante).
Au moment de la rédaction de cet article, BigBasket exécutait la solution complète en production depuis plus de 6 mois et faisait évoluer le système en s'adressant à de nouvelles villes, et nous ajoutons de nouveaux magasins chaque mois.
« Notre partenariat avec AWS sur la migration vers une formation distribuée utilisant leur offre SMDDP a été une grande victoire. Non seulement cela a réduit nos temps de formation de 50 %, mais c’était également 20 % moins cher. Dans l'ensemble de notre partenariat, AWS a placé la barre en matière d'obsession client et d'obtention de résultats, en travaillant avec nous tout au long du processus pour concrétiser les avantages promis.
– Keshav Kumar, responsable de l'ingénierie chez BigBasket.
Conclusion
Dans cet article, nous avons expliqué comment BigBasket a utilisé SageMaker pour former son modèle de vision par ordinateur pour l'identification des produits FMCG. La mise en œuvre d'un système de caisse automatique alimenté par l'IA offre une expérience client de détail améliorée grâce à l'innovation, tout en éliminant les erreurs humaines dans le processus de paiement. L'accélération de l'intégration de nouveaux produits à l'aide de la formation distribuée SageMaker réduit le temps et les coûts d'intégration des SKU. L'intégration de FSx pour Lustre permet un accès rapide aux données parallèles pour un recyclage efficace des modèles avec des centaines de nouveaux SKU chaque mois. Dans l’ensemble, cette solution de paiement en libre-service basée sur l’IA offre une expérience d’achat améliorée, sans erreurs de paiement front-end. L'automatisation et l'innovation ont transformé leurs opérations de paiement et d'intégration au détail.
SageMaker fournit des fonctionnalités de développement, de déploiement et de surveillance de ML de bout en bout, telles qu'un environnement de bloc-notes SageMaker Studio pour l'écriture de code, l'acquisition de données, le marquage des données, la formation de modèles, le réglage de modèles, le déploiement, la surveillance et bien plus encore. Si votre entreprise est confrontée à l'un des défis décrits dans cet article et souhaite gagner du temps de commercialisation et améliorer les coûts, contactez l'équipe de compte AWS de votre région et lancez-vous avec SageMaker.
À propos des auteurs
 Santosh Waddi est ingénieur principal chez BigBasket, apporte plus d'une décennie d'expertise dans la résolution des défis de l'IA. Fort d'une solide expérience en vision par ordinateur, en science des données et en apprentissage profond, il est titulaire d'un diplôme de troisième cycle de l'IIT Bombay. Santosh est l'auteur de publications notables de l'IEEE et, en tant qu'auteur chevronné de blogs technologiques, il a également apporté une contribution significative au développement de solutions de vision par ordinateur au cours de son mandat chez Samsung.
Santosh Waddi est ingénieur principal chez BigBasket, apporte plus d'une décennie d'expertise dans la résolution des défis de l'IA. Fort d'une solide expérience en vision par ordinateur, en science des données et en apprentissage profond, il est titulaire d'un diplôme de troisième cycle de l'IIT Bombay. Santosh est l'auteur de publications notables de l'IEEE et, en tant qu'auteur chevronné de blogs technologiques, il a également apporté une contribution significative au développement de solutions de vision par ordinateur au cours de son mandat chez Samsung.
 Nanda Kishore Thatikonda est un responsable de l'ingénierie dirigeant l'ingénierie des données et l'analyse chez BigBasket. Nanda a créé plusieurs applications pour la détection d'anomalies et a déposé un brevet dans un espace similaire. Il a travaillé à la création d'applications d'entreprise, à la création de plates-formes de données dans plusieurs organisations et de plates-formes de reporting pour rationaliser les décisions fondées sur des données. Nanda a plus de 18 ans d'expérience dans les technologies Java/J2EE, Spring et Big Data utilisant Hadoop et Apache Spark.
Nanda Kishore Thatikonda est un responsable de l'ingénierie dirigeant l'ingénierie des données et l'analyse chez BigBasket. Nanda a créé plusieurs applications pour la détection d'anomalies et a déposé un brevet dans un espace similaire. Il a travaillé à la création d'applications d'entreprise, à la création de plates-formes de données dans plusieurs organisations et de plates-formes de reporting pour rationaliser les décisions fondées sur des données. Nanda a plus de 18 ans d'expérience dans les technologies Java/J2EE, Spring et Big Data utilisant Hadoop et Apache Spark.
 La haine de Sudhanshu est un spécialiste principal de l'IA et du ML chez AWS et travaille avec les clients pour les conseiller sur leur parcours MLOps et IA générative. Dans son rôle précédent, il a conceptualisé, créé et dirigé des équipes pour construire une plate-forme d'IA et de gamification open source et l'a commercialisée avec succès auprès de plus de 100 clients. Sudhanshu a à son actif quelques brevets ; a écrit 2 livres, plusieurs articles et blogs ; et a présenté son point de vue dans divers forums. Il est un leader d'opinion et un conférencier et travaille dans l'industrie depuis près de 25 ans. Il a travaillé avec des clients Fortune 1000 à travers le monde et, plus récemment, avec des clients natifs du numérique en Inde.
La haine de Sudhanshu est un spécialiste principal de l'IA et du ML chez AWS et travaille avec les clients pour les conseiller sur leur parcours MLOps et IA générative. Dans son rôle précédent, il a conceptualisé, créé et dirigé des équipes pour construire une plate-forme d'IA et de gamification open source et l'a commercialisée avec succès auprès de plus de 100 clients. Sudhanshu a à son actif quelques brevets ; a écrit 2 livres, plusieurs articles et blogs ; et a présenté son point de vue dans divers forums. Il est un leader d'opinion et un conférencier et travaille dans l'industrie depuis près de 25 ans. Il a travaillé avec des clients Fortune 1000 à travers le monde et, plus récemment, avec des clients natifs du numérique en Inde.
 Ayush Kumar est architecte de solutions chez AWS. Il travaille avec une grande variété de clients AWS, les aidant à adopter les dernières applications modernes et à innover plus rapidement grâce aux technologies cloud natives. Vous le trouverez en train d'expérimenter en cuisine pendant son temps libre.
Ayush Kumar est architecte de solutions chez AWS. Il travaille avec une grande variété de clients AWS, les aidant à adopter les dernières applications modernes et à innover plus rapidement grâce aux technologies cloud natives. Vous le trouverez en train d'expérimenter en cuisine pendant son temps libre.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

