Ceci est un article invité rédigé par Axfood AB.
Dans cet article, nous expliquons comment Axfood, un grand détaillant alimentaire suédois, a amélioré les opérations et l'évolutivité de ses opérations existantes d'intelligence artificielle (IA) et d'apprentissage automatique (ML) en créant des prototypes en étroite collaboration avec des experts AWS et en utilisant Amazon Sage Maker.
axfood est le deuxième plus grand détaillant alimentaire de Suède, avec plus de 13,000 300 employés et plus de XNUMX magasins. Axfood dispose d'une structure composée de plusieurs équipes décentralisées de science des données avec différents domaines de responsabilité. En collaboration avec une équipe centrale de plateforme de données, les équipes de science des données apportent à l'organisation l'innovation et la transformation numérique grâce à des solutions d'IA et de ML. Axfood utilise Amazon SageMaker pour cultiver ses données à l'aide du ML et a des modèles en production depuis de nombreuses années. Dernièrement, le niveau de sophistication et le nombre de modèles en production augmentent de façon exponentielle. Cependant, même si le rythme de l’innovation est élevé, les différentes équipes avaient développé leurs propres méthodes de travail et étaient à la recherche d’une nouvelle bonne pratique MLOps.
Notre défi
Pour rester compétitif en termes de services cloud et d'IA/ML, Axfood a choisi de s'associer à AWS et collabore avec eux depuis de nombreuses années.
Au cours de l'une de nos séances de brainstorming récurrentes avec AWS, nous discutions de la meilleure façon de collaborer entre les équipes pour augmenter le rythme de l'innovation et l'efficacité des praticiens de la science des données et du ML. Nous avons décidé de déployer un effort commun pour construire un prototype sur une meilleure pratique pour MLOps. L'objectif du prototype était de créer un modèle permettant à toutes les équipes de science des données de créer des modèles de ML évolutifs et efficaces, la base d'une nouvelle génération de plateformes d'IA et de ML pour Axfood. Le modèle doit relier et combiner les meilleures pratiques des experts AWS ML et les modèles de bonnes pratiques spécifiques à l'entreprise : le meilleur des deux mondes.
Nous avons décidé de construire un prototype à partir de l'un des modèles ML actuellement les plus développés au sein d'Axfood : prévoir les ventes en magasin. Plus précisément, les prévisions pour les fruits et légumes des prochaines campagnes pour les magasins de détail alimentaire. Des prévisions quotidiennes précises soutiennent le processus de commande des magasins, augmentant la durabilité en minimisant le gaspillage alimentaire grâce à l'optimisation des ventes en prévoyant avec précision les niveaux de stock nécessaires en magasin. C'était le point de départ idéal pour notre prototype : non seulement Axfood bénéficierait d'une nouvelle plate-forme d'IA/ML, mais nous aurions également l'occasion de comparer nos capacités de ML et d'apprendre des principaux experts AWS.
Notre solution : Un nouveau modèle ML sur Amazon SageMaker Studio
Construire un pipeline ML complet conçu pour une analyse de rentabilisation réelle peut s'avérer difficile. Dans ce cas, nous développons un modèle de prévision, il y a donc deux étapes principales à réaliser :
- Entraînez le modèle pour faire des prédictions à l’aide de données historiques.
- Appliquez le modèle entraîné pour faire des prédictions d’événements futurs.
Dans le cas d'Axfood, un pipeline fonctionnel à cet effet a déjà été mis en place à l'aide de notebooks SageMaker et orchestré par la plateforme tierce de gestion de flux de travail Airflow. Cependant, il existe de nombreux avantages évidents à moderniser notre plateforme ML et à passer à Amazon SageMakerStudio ainsi que Pipelines Amazon SageMaker. Le passage à SageMaker Studio offre de nombreuses fonctionnalités prédéfinies prêtes à l'emploi :
- Surveillance de la qualité du modèle et des données ainsi que de l'explicabilité du modèle
- Outils d'environnement de développement intégré (IDE) intégrés tels que le débogage
- Suivi coût/performance
- Cadre d'acceptation du modèle
- Registre des modèles
Cependant, l'incitation la plus importante pour Axfood est la possibilité de créer des modèles de projets personnalisés à l'aide de Projets Amazon SageMaker à utiliser comme modèle pour toutes les équipes de science des données et les praticiens du ML. L'équipe d'Axfood disposait déjà d'un niveau de modélisation ML robuste et mature, l'accent principal était donc mis sur la construction de la nouvelle architecture.
Vue d'ensemble de la solution
Le nouveau framework ML proposé par Axfood est structuré autour de deux pipelines principaux : le pipeline de construction de modèles et le pipeline d'inférence par lots:
- Ces pipelines sont versionnés dans deux référentiels Git distincts : un référentiel de construction et un référentiel de déploiement (inférence). Ensemble, ils forment un pipeline robuste pour la prévision des fruits et légumes.
- Les pipelines sont regroupés dans un modèle de projet personnalisé à l'aide de projets SageMaker en intégration avec un référentiel Git tiers (Bitbucket) et des pipelines Bitbucket pour les composants d'intégration continue et de déploiement continu (CI/CD).
- Le modèle de projet SageMaker comprend le code de départ correspondant à chaque étape des pipelines de création et de déploiement (nous discutons de ces étapes plus en détail plus loin dans cet article) ainsi que la définition du pipeline (la recette pour la façon dont les étapes doivent être exécutées).
- L'automatisation de la création de nouveaux projets basés sur le modèle est rationalisée Catalogue de services AWS, où un portefeuille est créé, servant d'abstraction pour plusieurs produits.
- Chaque produit se traduit par un AWS CloudFormation modèle, qui est déployé lorsqu'un data scientist crée un nouveau projet SageMaker avec notre plan MLOps comme base. Cela active un AWS Lambda fonction qui crée un projet Bitbucket avec deux référentiels (création de modèle et déploiement de modèle) contenant le code de départ.
Le diagramme suivant illustre l’architecture de la solution. Le workflow A décrit le flux complexe entre les deux pipelines de modèle : la construction et l'inférence. Le workflow B montre le flux pour créer un nouveau projet ML.

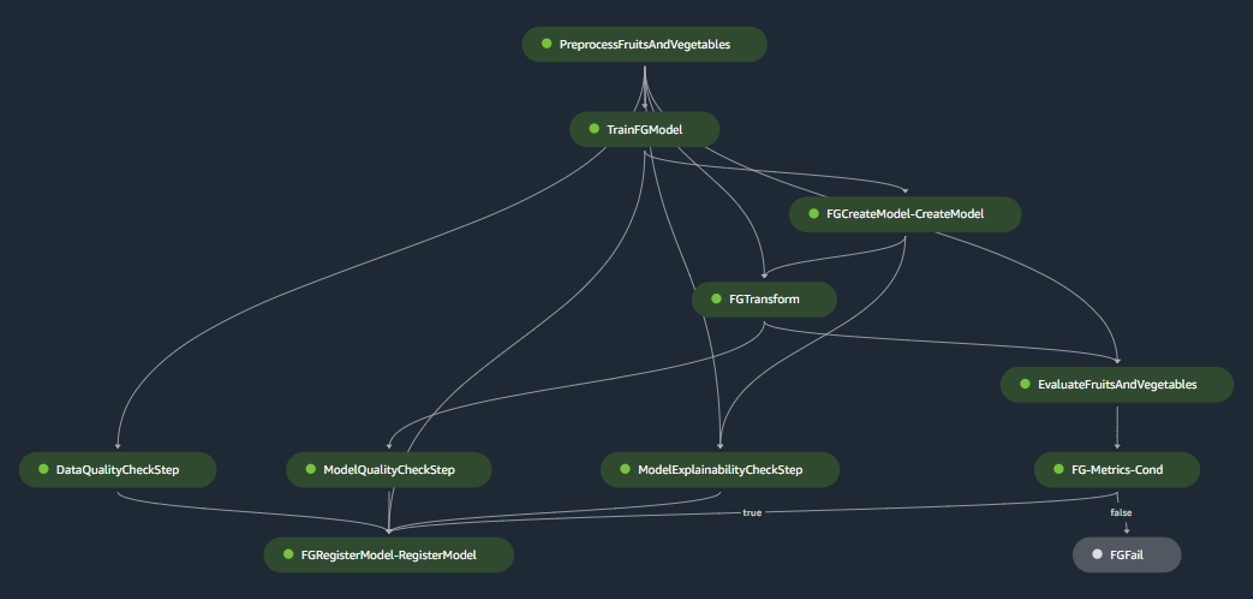
Pipeline de création de modèles
Le pipeline de création de modèles orchestre le cycle de vie du modèle, depuis le prétraitement jusqu'à l'enregistrement dans le registre des modèles :
- Prétraitement – Ici, le SageMaker
ScriptProcessorLa classe est utilisée pour l'ingénierie des fonctionnalités, ce qui donne lieu à l'ensemble de données sur lequel le modèle sera formé. - Formation et transformation par lots – Les conteneurs de formation et d'inférence personnalisés de SageMaker sont exploités pour entraîner le modèle sur des données historiques et créer des prédictions sur les données d'évaluation à l'aide d'un estimateur et d'un transformateur SageMaker pour les tâches respectives.
- Evaluation – Le modèle entraîné est évalué en comparant les prédictions générées sur les données d'évaluation à la vérité terrain à l'aide de
ScriptProcessor. - Emplois de base – Le pipeline crée des lignes de base basées sur les statistiques des données d'entrée. Ceux-ci sont essentiels pour surveiller la qualité des données et des modèles, ainsi que l’attribution des fonctionnalités.
- Registre des modèles – Le modèle formé est enregistré pour une utilisation future. Le modèle sera approuvé par des data scientists désignés pour déployer le modèle en vue d'une utilisation en production.
Pour les environnements de production, l'ingestion de données et les mécanismes de déclenchement sont gérés via une orchestration Airflow principale. Pendant ce temps, pendant le développement, le pipeline est activé chaque fois qu'un nouveau commit est introduit dans le référentiel Bitbucket de construction de modèles. La figure suivante visualise le pipeline de création de modèle.
Pipeline d'inférence par lots
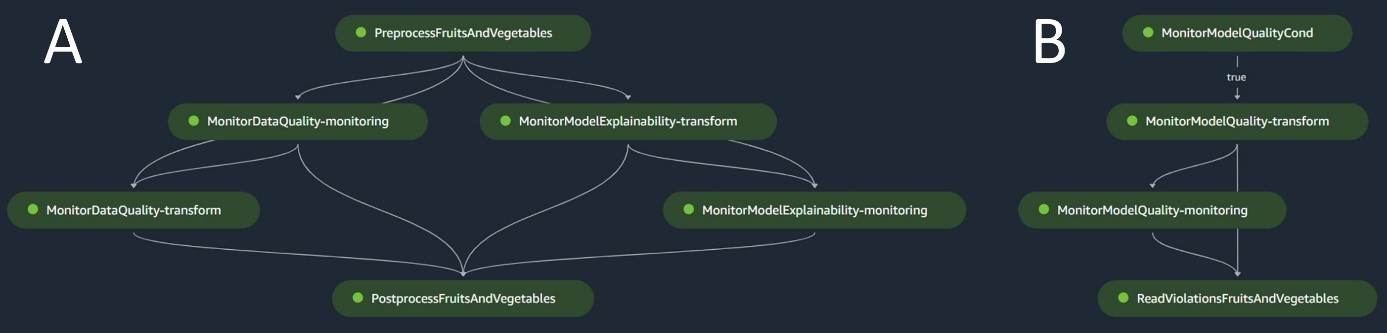
Le pipeline d'inférence par lots gère la phase d'inférence, qui comprend les étapes suivantes :
- Prétraitement – Les données sont prétraitées à l’aide
ScriptProcessor. - Transformation par lots – Le modèle utilise le conteneur d'inférence personnalisé avec un transformateur SageMaker et génère des prédictions en fonction des données d'entrée prétraitées. Le modèle utilisé est le dernier modèle formé approuvé dans le registre des modèles.
- Post-traitement – Les prédictions subissent une série d'étapes de post-traitement utilisant
ScriptProcessor. - Le Monitoring – La surveillance continue complète les vérifications des dérives liées à la qualité des données, à la qualité du modèle et à l’attribution des fonctionnalités.
Si des divergences surviennent, une logique métier au sein du script de post-traitement évalue si un recyclage du modèle est nécessaire. Le pipeline est programmé pour s'exécuter à intervalles réguliers.
Le diagramme suivant illustre le pipeline d'inférence par lots. Le workflow A correspond au prétraitement, aux contrôles de dérive de la qualité des données et d'attribution des fonctionnalités, à l'inférence et au post-traitement. Le workflow B correspond aux contrôles de dérive de qualité du modèle. Ces pipelines sont divisés car la vérification de la dérive de la qualité du modèle ne s'exécutera que si de nouvelles données de vérité terrain sont disponibles.
Moniteur de modèle SageMaker
Avec Moniteur de modèle Amazon SageMaker intégrés, les pipelines bénéficient d’un suivi en temps réel sur les éléments suivants :
- Qualité des données – Surveille toute dérive ou incohérence dans les données
- Qualité du modèle – Surveille toute fluctuation des performances du modèle
- Attribution des fonctionnalités – Vérifie la dérive dans les attributions de fonctionnalités
La surveillance de la qualité des modèles nécessite l’accès aux données de vérité terrain. Bien qu'obtenir la vérité sur le terrain puisse parfois être difficile, l'utilisation de la surveillance de la dérive d'attribution des données ou des fonctionnalités sert d'indicateur compétent de la qualité du modèle.
Plus précisément, en cas de dérive de la qualité des données, le système surveille les éléments suivants :
- Dérive du concept – Cela concerne les changements dans la corrélation entre l’entrée et la sortie, nécessitant une vérité terrain
- Changement de covariable – Ici, l’accent est mis sur les modifications de la distribution des variables d’entrée indépendantes
La fonctionnalité de dérive des données de SageMaker Model Monitor capture et examine méticuleusement les données d'entrée, en déployant des règles et des contrôles statistiques. Des alertes sont déclenchées chaque fois que des anomalies sont détectées.
Parallèlement à l'utilisation des contrôles de dérive de la qualité des données comme proxy pour surveiller la dégradation du modèle, le système surveille également la dérive d'attribution des fonctionnalités à l'aide du score de gain cumulatif actualisé normalisé (NDCG). Ce score est sensible à la fois aux changements dans l'ordre de classement d'attribution des fonctionnalités ainsi qu'aux scores d'attribution bruts des fonctionnalités. En surveillant la dérive de l'attribution des caractéristiques individuelles et leur importance relative, il est simple de repérer la dégradation de la qualité du modèle.
Explicabilité du modèle
L'explicabilité du modèle est un élément essentiel des déploiements de ML, car elle garantit la transparence des prédictions. Pour une compréhension détaillée, nous utilisons Amazon SageMaker Clarifier.
Il propose des explications de modèles à la fois globales et locales grâce à une technique d'attribution de caractéristiques indépendante du modèle basée sur le concept de valeur de Shapley. Ceci est utilisé pour décoder pourquoi une prédiction particulière a été faite lors de l'inférence. De telles explications, qui sont intrinsèquement contrastées, peuvent varier en fonction de différentes bases de référence. SageMaker Clarify aide à déterminer cette référence à l'aide de K-means ou de K-prototypes dans l'ensemble de données d'entrée, qui est ensuite ajouté au pipeline de création de modèle. Cette fonctionnalité nous permettra de créer à l’avenir des applications d’IA générative pour une meilleure compréhension du fonctionnement du modèle.
Industrialisation : Du prototype à la production
Le projet MLOps inclut un haut degré d'automatisation et peut servir de modèle pour des cas d'utilisation similaires :
- L'infrastructure peut être entièrement réutilisée, tandis que le code de départ peut être adapté à chaque tâche, la plupart des modifications étant limitées à la définition du pipeline et à la logique métier pour le prétraitement, la formation, l'inférence et le post-traitement.
- Les scripts de formation et d'inférence sont hébergés à l'aide de conteneurs personnalisés SageMaker, de sorte qu'une variété de modèles peuvent être pris en charge sans modification des données et des étapes de surveillance des modèles ou d'explicabilité du modèle, à condition que les données soient au format tabulaire.
Après avoir terminé le travail sur le prototype, nous nous sommes tournés vers la manière dont nous devrions l'utiliser en production. Pour ce faire, nous avons ressenti le besoin d'apporter quelques ajustements supplémentaires au modèle MLOps :
- Le code de départ d'origine utilisé dans le prototype du modèle comprenait des étapes de prétraitement et de post-traitement exécutées avant et après les étapes principales de ML (formation et inférence). Cependant, lors de la mise à l'échelle pour utiliser le modèle pour plusieurs cas d'utilisation en production, les étapes de prétraitement et de post-traitement intégrées peuvent conduire à une diminution de la généralité et de la reproduction du code.
- Pour améliorer la généralité et minimiser le code répétitif, nous avons choisi de réduire encore davantage les pipelines. Au lieu d'exécuter les étapes de prétraitement et de post-traitement dans le cadre du pipeline ML, nous les exécutons dans le cadre de l'orchestration Airflow principale avant et après le déclenchement du pipeline ML.
- De cette façon, les tâches de traitement spécifiques au cas d'utilisation sont extraites du modèle, et il ne reste qu'un pipeline ML principal effectuant des tâches générales dans plusieurs cas d'utilisation avec une répétition minimale du code. Les paramètres qui diffèrent selon les cas d'utilisation sont fournis en entrée au pipeline ML à partir de l'orchestration Airflow principale.
Le résultat : une approche rapide et efficace de la création et du déploiement de modèles
Le prototype en collaboration avec AWS a abouti à un modèle MLOps suivant les meilleures pratiques actuelles qui est désormais disponible pour toutes les équipes de science des données d'Axfood. En créant un nouveau projet SageMaker dans SageMaker Studio, les data scientists peuvent se lancer dans de nouveaux projets de ML rapidement et passer en toute transparence à la production, permettant une gestion du temps plus efficace. Ceci est rendu possible par l'automatisation des tâches MLOps fastidieuses et répétitives dans le cadre du modèle.
De plus, plusieurs nouvelles fonctionnalités ont été ajoutées de manière automatisée à notre configuration ML. Ces gains comprennent :
- Surveillance du modèle – Nous pouvons effectuer des contrôles de dérive pour la qualité du modèle et des données ainsi que l’explicabilité du modèle
- Lignage du modèle et des données – Il est désormais possible de retracer exactement quelles données ont été utilisées pour quel modèle
- Registre des modèles – Cela nous aide à cataloguer les modèles pour la production et à gérer les versions des modèles
Conclusion
Dans cet article, nous avons expliqué comment Axfood a amélioré les opérations et l'évolutivité de nos opérations d'IA et de ML existantes en collaboration avec des experts AWS et en utilisant SageMaker et ses produits associés.
Ces améliorations aideront les équipes de science des données d'Axfood à créer des flux de travail ML de manière plus standardisée et simplifieront considérablement l'analyse et la surveillance des modèles en production, garantissant ainsi la qualité des modèles ML construits et maintenus par nos équipes.
Veuillez laisser vos commentaires ou questions dans la section commentaires.
À propos des auteurs
 Dr Björn Blomqvist est responsable de la stratégie IA chez Axfood AB. Avant de rejoindre Axfood AB, il a dirigé une équipe de Data Scientists chez Dagab, une partie d'Axfood, créant des solutions innovantes d'apprentissage automatique avec pour mission de fournir une alimentation bonne et durable aux personnes dans toute la Suède. Né et élevé dans le nord de la Suède, Björn s'aventure pendant son temps libre dans les montagnes enneigées et au large.
Dr Björn Blomqvist est responsable de la stratégie IA chez Axfood AB. Avant de rejoindre Axfood AB, il a dirigé une équipe de Data Scientists chez Dagab, une partie d'Axfood, créant des solutions innovantes d'apprentissage automatique avec pour mission de fournir une alimentation bonne et durable aux personnes dans toute la Suède. Né et élevé dans le nord de la Suède, Björn s'aventure pendant son temps libre dans les montagnes enneigées et au large.
 Oskar Klang est Senior Data Scientist au département d'analyse de Dagab, où il aime travailler avec tout ce qui concerne l'analyse et l'apprentissage automatique, par exemple l'optimisation des opérations de la chaîne d'approvisionnement, la création de modèles de prévision et, plus récemment, les applications GenAI. Il s'engage à créer des pipelines d'apprentissage automatique plus rationalisés, améliorant ainsi l'efficacité et l'évolutivité.
Oskar Klang est Senior Data Scientist au département d'analyse de Dagab, où il aime travailler avec tout ce qui concerne l'analyse et l'apprentissage automatique, par exemple l'optimisation des opérations de la chaîne d'approvisionnement, la création de modèles de prévision et, plus récemment, les applications GenAI. Il s'engage à créer des pipelines d'apprentissage automatique plus rationalisés, améliorant ainsi l'efficacité et l'évolutivité.
 Pavel Maslov est ingénieur senior DevOps et ML au sein de l'équipe Analytic Platforms. Pavel possède une vaste expérience dans le développement de frameworks, d'infrastructures et d'outils dans les domaines DevOps et ML/AI sur la plateforme AWS. Pavel a été l'un des acteurs clés dans le développement des capacités fondamentales du ML chez Axfood.
Pavel Maslov est ingénieur senior DevOps et ML au sein de l'équipe Analytic Platforms. Pavel possède une vaste expérience dans le développement de frameworks, d'infrastructures et d'outils dans les domaines DevOps et ML/AI sur la plateforme AWS. Pavel a été l'un des acteurs clés dans le développement des capacités fondamentales du ML chez Axfood.
 Joakim Berg est le chef d'équipe et propriétaire de produit des plateformes analytiques, basé à Stockholm en Suède. Il dirige une équipe d'ingénieurs Data Platform et DevOps/MLOps fournissant des plateformes Data et ML pour les équipes Data Science. Joakim possède de nombreuses années d’expérience à la tête d’équipes senior de développement et d’architecture de différents secteurs.
Joakim Berg est le chef d'équipe et propriétaire de produit des plateformes analytiques, basé à Stockholm en Suède. Il dirige une équipe d'ingénieurs Data Platform et DevOps/MLOps fournissant des plateformes Data et ML pour les équipes Data Science. Joakim possède de nombreuses années d’expérience à la tête d’équipes senior de développement et d’architecture de différents secteurs.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

