Cet article est co-écrit avec Amir Souchami et Fabian Szenkier de Unity.
Aura de l'Unité (anciennement connu sous le nom de ironSource) est la norme du marché en matière de création d'expériences riches sur les appareils qui engagent et fidélisent les clients. Grâce à un ensemble puissant de solutions, Aura permet une transformation numérique complète, permettant aux opérateurs de promouvoir des services clés en dehors du magasin, directement sur l'appareil.
Redshift d'Amazon est un service recommandé pour les charges de travail de traitement analytique en ligne (OLAP) telles que les entrepôts de données cloud, les data marts et autres magasins de données analytiques. Vous pouvez utiliser du SQL simple pour analyser des données structurées et semi-structurées, des bases de données opérationnelles et des lacs de données afin d'offrir le meilleur rapport prix/performances à n'importe quelle échelle. Le Partage de données Amazon Redshift La fonctionnalité fournit un accès instantané, granulaire et hautes performances sans copies de données ni déplacement de données entre plusieurs entrepôts de données Redshift dans le même compte AWS ou dans des comptes AWS différents et dans les régions AWS. Le partage de données fournit un accès en direct aux données afin que vous puissiez toujours voir les informations les plus récentes et les plus cohérentes au fur et à mesure de leur mise à jour dans l'entrepôt de données.
Amazon Redshift sans serveur facilite l'exécution et la mise à l'échelle des analyses en quelques secondes sans avoir besoin de configurer et de gérer des clusters d'entrepôts de données. Redshift Serverless provisionne automatiquement et adapte intelligemment la capacité de l'entrepôt de données pour offrir des performances rapides, même pour les charges de travail les plus exigeantes et imprévisibles, et vous ne payez que pour ce que vous utilisez. Vous pouvez charger vos données et commencer à interroger immédiatement dans l'éditeur de requêtes Amazon Redshift ou dans votre outil de business intelligence (BI) préféré et continuer à bénéficier du meilleur rapport prix/performances et de fonctionnalités SQL familières dans un environnement facile à utiliser et sans administration. .
Dans cet article, nous décrivons l'adoption réussie et rapide par Aura de Redshift Serverless, qui leur a permis d'optimiser le temps de commercialisation global de leurs campagnes publicitaires d'enchères de 24 heures à 2 heures. Nous explorons pourquoi Aura a choisi cette solution et quels défis technologiques elle a contribué à résoudre.
Le pipeline de données initial d'Aura
Aura est un pionnier dans l'utilisation des clusters Redshift RA3 avec partage de données pour les charges de travail d'extraction, de transformation et de chargement (ETL) et BI. L'une des activités d'Aura consiste à lancer des campagnes publicitaires. Ces campagnes sont optimisées à l'aide d'un processus d'enchères basé sur l'IA qui nécessite l'exécution de centaines de requêtes analytiques par campagne. Ces requêtes sont exécutées sur des données qui résident dans un cluster Redshift provisionné par RA3.
Le pipeline intégré est composé de divers services AWS :
Le diagramme suivant illustre cette architecture.
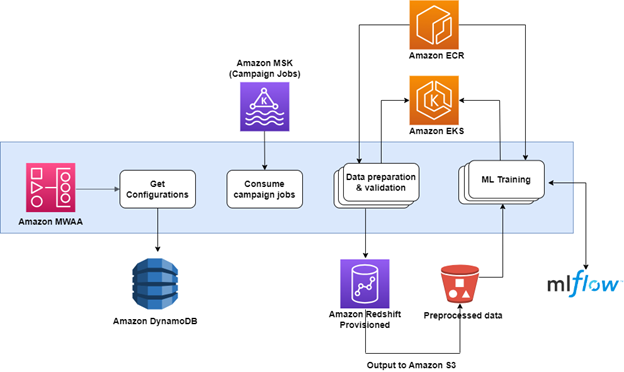
Les défis de l'architecture initiale
Les requêtes pour chaque campagne s'exécutent de la manière suivante :
Tout d’abord, une requête de préparation filtre et agrège les données brutes, les préparant pour l’opération suivante. Vient ensuite la requête principale, qui exécute la logique en fonction de l'ensemble de résultats de la requête de préparation.
À mesure que le nombre de campagnes augmentait, l'équipe Data d'Aura a dû exécuter des centaines de requêtes simultanées pour chacune de ces étapes. Le cluster provisionné existant d'Aura était déjà largement utilisé avec les charges de travail d'ingestion de données, d'ETL et de BI. L'entreprise recherchait donc des moyens rentables d'isoler cette charge de travail avec des ressources de calcul dédiées.
L'équipe a évalué diverses options, notamment le déchargement des données vers Amazon S3 et une architecture multicluster utilisant le partage de données et Redshift sans serveur. L'équipe s'est tournée vers l'architecture multicluster avec partage de données, car elle ne nécessite aucune réécriture de requête, permet un calcul dédié pour cette charge de travail spécifique, évite le besoin de dupliquer ou de déplacer les données du cluster principal et offre une concurrence élevée et une mise à l'échelle automatique. Enfin, il est facturé selon un modèle de paiement à l'utilisation, et le provisionnement est simple et rapide.
Preuve de concept
Après avoir évalué les options, l'équipe Data d'Aura a décidé de réaliser une preuve de concept en utilisant Redshift Serverless en tant que consommateur de son cluster principal provisionné par Redshift, en partageant uniquement les tables pertinentes pour exécuter les requêtes requises. Redshift Serverless mesure la capacité de l'entrepôt de données dans les unités de traitement Redshift (RPU). Un seul RPU fournit 16 Go de mémoire et un point de terminaison sans serveur peut aller de 8 RPU à 512 RPU.
L'équipe Data d'Aura a commencé la preuve de concept en utilisant un point de terminaison Redshift Serverless à 256 RPU et a progressivement réduit le RPU pour réduire les coûts tout en s'assurant que le temps d'exécution des requêtes était inférieur à l'objectif requis.
Finalement, l'équipe a décidé d'utiliser un point de terminaison Redshift Serverless de 128 RPU (2 To de RAM) comme RPU de base, tout en utilisant la fonction de mise à l'échelle automatique Redshift Serverless, qui permet d'exécuter des centaines de requêtes simultanées en mettant automatiquement à l'échelle le RPU selon les besoins.
La nouvelle solution d'Aura avec Redshift Serverless
Après une preuve de concept réussie, la configuration de production comprenait l'ajout de code pour basculer entre le cluster Redshift provisionné et le point de terminaison Redshift Serverless. Cela a été fait à l'aide d'un seuil configurable basé sur le nombre de requêtes en attente de traitement dans une rubrique MSK spécifique consommée au début du pipeline. Les requêtes de campagne à petite échelle s'exécuteraient toujours sur le cluster provisionné, et les requêtes à grande échelle utiliseraient le point de terminaison Redshift Serverless. La nouvelle solution utilise un pipeline Amazon MWAA qui récupère les informations de configuration d'une table DynamoDB, consomme des tâches qui représentent des campagnes publicitaires, puis exécute des centaines de tâches EKS déclenchées à l'aide d'EKSPodOperator. Chaque tâche exécute les deux requêtes série (la requête de préparation suivie d'une requête principale, qui renvoie les résultats vers Amazon S3). Cela se produit plusieurs centaines de fois simultanément en utilisant les ressources de calcul Redshift Serverless.
Ensuite, le processus lance un autre ensemble d'opérateurs EKSPodOperator pour exécuter le code de formation de l'IA en fonction du résultat des données enregistrées sur Amazon S3.
Le diagramme suivant illustre l'architecture de la solution.
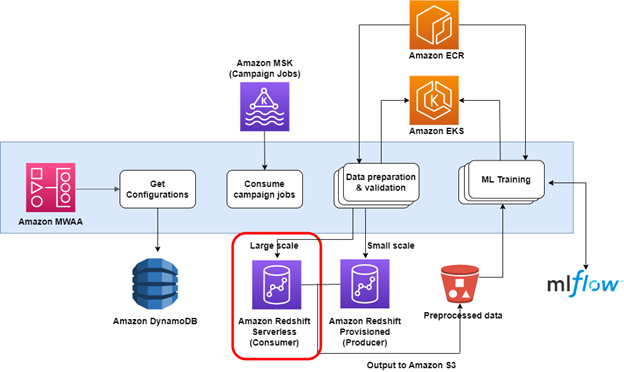
Résultat
La durée d'exécution globale du pipeline a été réduite de 24 heures à seulement 2 heures, soit une amélioration de 12 fois. Cette intégration de Redshift Serverless, associée au partage de données, a conduit à une réduction de 90 % de la durée du pipeline, éliminant ainsi la nécessité de dupliquer les données ou de réécrire les requêtes. De plus, l'introduction d'un consommateur dédié en tant que ressource de calcul exclusive a considérablement allégé la charge du cluster producteur, permettant d'exécuter des requêtes à petite échelle encore plus rapidement.
« Redshift Serverless et le partage de données nous ont permis de provisionner et de faire évoluer la capacité de notre entrepôt de données pour offrir des performances rapides, une simultanéité élevée et gérer des charges de travail de ML difficiles avec un minimum d'effort. »
– Amir Souchami, architecte principal des systèmes techniques d'Aura.
Apprentissage
L'équipe Data d'Aura se concentre fortement sur le travail de manière rentable et a donc mis en œuvre plusieurs contrôles de coûts dans son point de terminaison Redshift Serverless :
- Limitez les dépenses globales en définissant un limite maximale d'utilisation du RPU par heure (par jour, semaine, mois) pour le groupe de travail. Aura a configuré cette limite de sorte que lorsqu'elle est atteinte, Amazon Redshift envoie une alerte à l'équipe d'administrateurs Amazon Redshift concernée. Cette fonctionnalité permet également d'écrire une entrée dans une table système et même de désactiver les requêtes des utilisateurs.
- Utiliser un configuration RPU maximale, qui définit la limite supérieure des ressources de calcul que Redshift Serverless peut utiliser à tout moment. Lorsque la limite RPU maximale est définie pour le groupe de travail, Redshift Serverless évolue dans cette limite pour continuer à exécuter la charge de travail.
- Mettre en œuvre le règles de surveillance des requêtes qui évitent le gaspillage des ressources et les coûts incontrôlables causés par des requêtes mal rédigées.
Conclusion
Un entrepôt de données est un élément crucial de toute entreprise moderne axée sur les données, vous permettant de répondre à des questions commerciales complexes et de fournir des informations. L'évolution d'Amazon Redshift a permis à Aura de s'adapter rapidement aux exigences de l'entreprise en combinant le partage de données entre les entrepôts de données provisionnés et Redshift Serverless. Le parcours d'Aura avec Redshift Serverless souligne le vaste potentiel de l'intégration technologique stratégique pour améliorer l'efficacité et l'excellence opérationnelle.
Si le parcours d'Aura a suscité votre intérêt et que vous envisagez de mettre en œuvre une solution similaire dans votre organisation, voici quelques étapes stratégiques à considérer :
- Commencez par bien comprendre les besoins en données de votre organisation et comment une telle solution peut y répondre.
- Contactez les experts AWS, qui pourront vous fournir des conseils basés sur leurs propres expériences. Envisagez de participer à des séminaires, des ateliers ou des forums en ligne qui discutent de ces technologies. Les ressources suivantes sont recommandées pour commencer :
- Une partie importante de ce voyage consisterait à mettre en œuvre une preuve de concept. Une telle expérience pratique fournira des informations précieuses avant de passer à la production.
Élevez votre expertise Redshift. Vous profitez déjà de la puissance d’Amazon Redshift ? Améliorez votre parcours de données avec le dernières fonctionnalités et des conseils d'experts. Contactez votre équipe de compte AWS dédiée pour une assistance personnalisée, découvrez des fonctionnalités de pointe et débloquez encore plus de valeur à partir de vos données avec Amazon Redshift.
À propos des auteurs
 Amir Souchami, architecte en chef d'Aura chez Unity, se concentrant sur la création de systèmes cloud et d'applications mobiles résilients et performants à grande échelle.
Amir Souchami, architecte en chef d'Aura chez Unity, se concentrant sur la création de systèmes cloud et d'applications mobiles résilients et performants à grande échelle.
 Fabien Szenkier est l'architecte ML et Big Data chez Aura by Unity, travaille à la création de solutions modernes d'IA/ML et de pipelines d'ingénierie de données de pointe à grande échelle.
Fabien Szenkier est l'architecte ML et Big Data chez Aura by Unity, travaille à la création de solutions modernes d'IA/ML et de pipelines d'ingénierie de données de pointe à grande échelle.
 Liat Tzur est responsable de compte technique senior chez Amazon Web Services. Elle défend les intérêts des clients et les aide à atteindre l'excellence opérationnelle cloud conformément à leurs objectifs commerciaux.
Liat Tzur est responsable de compte technique senior chez Amazon Web Services. Elle défend les intérêts des clients et les aide à atteindre l'excellence opérationnelle cloud conformément à leurs objectifs commerciaux.
 Adi Jabkowski est un spécialiste principal de Redshift dans la région EMEA, qui fait partie de la Worldwide Specialist Organization (WWSO) d'AWS.
Adi Jabkowski est un spécialiste principal de Redshift dans la région EMEA, qui fait partie de la Worldwide Specialist Organization (WWSO) d'AWS.
 Yonatan Dolan est spécialiste principal de l'analyse chez Amazon Web Services. Il est basé en Israël et aide les clients à exploiter les services analytiques AWS pour exploiter les données, obtenir des informations et en tirer de la valeur.
Yonatan Dolan est spécialiste principal de l'analyse chez Amazon Web Services. Il est basé en Israël et aide les clients à exploiter les services analytiques AWS pour exploiter les données, obtenir des informations et en tirer de la valeur.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/how-aura-from-unity-revolutionized-their-big-data-pipeline-with-amazon-redshift-serverless/

