
Image par auteur
Avoir un bon titre est crucial pour le succès d’un article. Les gens ne passent qu'une seconde (si l'on en croit le livre de Ryan Holiday "Faites-moi confiance, je mens" décider s'il faut cliquer sur le titre pour ouvrir l'article en entier. Les médias sont obsédés par l'optimisation taux de clics (CTR), le nombre de clics reçus par un titre divisé par le nombre de fois où le titre est affiché. Avoir un titre click-bait augmente le CTR. Les médias choisiront probablement un titre avec un CTR plus élevé entre les deux titres, car cela générera plus de revenus.
Je n’ai pas vraiment envie de réduire les revenus publicitaires. Il s'agit plutôt de diffuser mes connaissances et mon expertise. Et pourtant, les téléspectateurs disposent d’un temps et d’une attention limités, alors que le contenu sur Internet est pratiquement illimité. Je dois donc rivaliser avec d'autres créateurs de contenu pour attirer l'attention des téléspectateurs.
Comment choisir un titre approprié pour mon prochain article ? Bien sûr, j’ai besoin d’un ensemble d’options parmi lesquelles choisir. J'espère pouvoir les générer moi-même ou demander à ChatGPT. Mais que dois-je faire ensuite ? En tant que data scientist, je suggère d'effectuer un test A/B/N pour comprendre quelle option est la meilleure d'une manière basée sur les données. Mais il y a un problème. Premièrement, je dois décider rapidement car le contenu expire rapidement. Deuxièmement, il se peut qu’il n’y ait pas suffisamment d’observations pour détecter une différence statistiquement significative dans les CTR, car ces valeurs sont relativement faibles. Il existe donc d’autres options que d’attendre quelques semaines pour décider.
Espérons qu'il existe une solution ! Je peux utiliser un algorithme d'apprentissage automatique « bandit à plusieurs bras » qui s'adapte aux données que nous observons sur le comportement des téléspectateurs. Plus les gens cliquent sur une option particulière dans l’ensemble, plus nous pouvons allouer de trafic à cette option. Dans cet article, je vais expliquer brièvement ce qu'est un « bandit bayésien à plusieurs bras » et montrer comment il fonctionne en pratique avec Python.
Bandits multi-armés sont des algorithmes d’apprentissage automatique. Le type bayésien utilise Échantillonnage de Thompson choisir une option basée sur nos convictions antérieures concernant les distributions de probabilité des CTR qui sont ensuite mises à jour en fonction des nouvelles données. Tous ces mots relatifs à la théorie des probabilités et aux statistiques mathématiques peuvent sembler complexes et intimidants. Laissez-moi vous expliquer tout le concept en utilisant le moins de formules possible.
Supposons qu’il n’y ait que deux titres parmi lesquels choisir. Nous n'avons aucune idée de leurs CTR. Mais nous voulons avoir le titre le plus performant. Nous avons plusieurs options. La première est de choisir le titre auquel nous croyons le plus. C’est ainsi que cela a fonctionné pendant des années dans l’industrie. Le second alloue 50% du trafic entrant au premier titre et 50% au second. Cela est devenu possible avec l'essor des médias numériques, où vous pouvez décider quel texte afficher précisément lorsqu'un téléspectateur demande une liste d'articles à lire. Avec cette approche, vous pouvez être sûr que 50 % du trafic a été alloué à l’option la plus performante. Est-ce une limite ? Bien sûr que non!
Certaines personnes lisaient l’article quelques minutes après sa publication. Certaines personnes le feraient en quelques heures ou quelques jours. Cela signifie que nous pouvons observer comment les « premiers » lecteurs ont réagi à différents titres et déplacer l'allocation du trafic de 50/50 vers l'option la plus performante. Après un certain temps, nous pouvons à nouveau calculer les CTR et ajuster la répartition. À la limite, nous souhaitons ajuster la répartition du trafic après que chaque nouveau spectateur clique ou saute le titre. Nous avons besoin d’un cadre pour adapter la répartition du trafic de manière scientifique et automatisée.
Voici le théorème de Bayes, la distribution bêta et l'échantillonnage de Thompson.
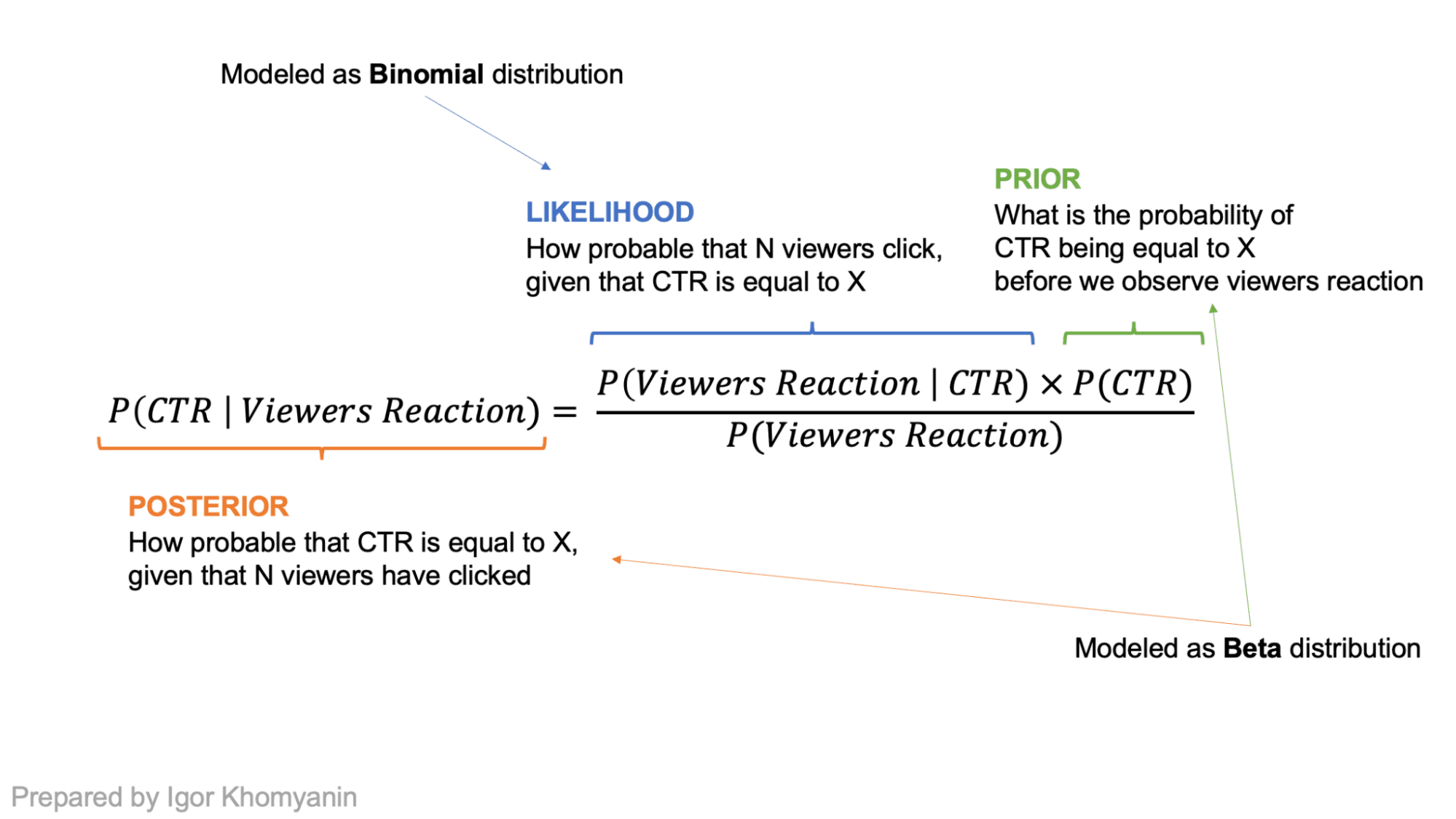
Supposons que le CTR d'un article soit une variable aléatoire « thêta ». De par sa conception, il se situe entre 0 et 1. Si nous n’avons aucune croyance préalable, il peut s’agir de n’importe quel nombre compris entre 0 et 1 avec une probabilité égale. Après avoir observé certaines données « x », nous pouvons ajuster nos croyances et avoir une nouvelle distribution pour « thêta » qui sera plus proche de 0 ou 1 en utilisant le théorème de Bayes.
Le nombre de personnes qui cliquent sur le titre peut être modélisé comme un Distribution binomiale où « n » est le nombre de visiteurs qui voient le titre et « p » est le CTR du titre. C'est notre chance ! Si nous modélisons le prior (notre croyance sur la distribution du CTR) comme un Distribution bêta et prenons la vraisemblance binomiale, la postérieure serait également une distribution bêta avec des paramètres différents ! Dans de tels cas, la distribution bêta est appelée une conjuguer avant à la vraisemblance.
La preuve de ce fait n’est pas si difficile mais nécessite un exercice mathématique qui n’est pas pertinent dans le contexte de cet article. Veuillez vous référer à la belle preuve ici:
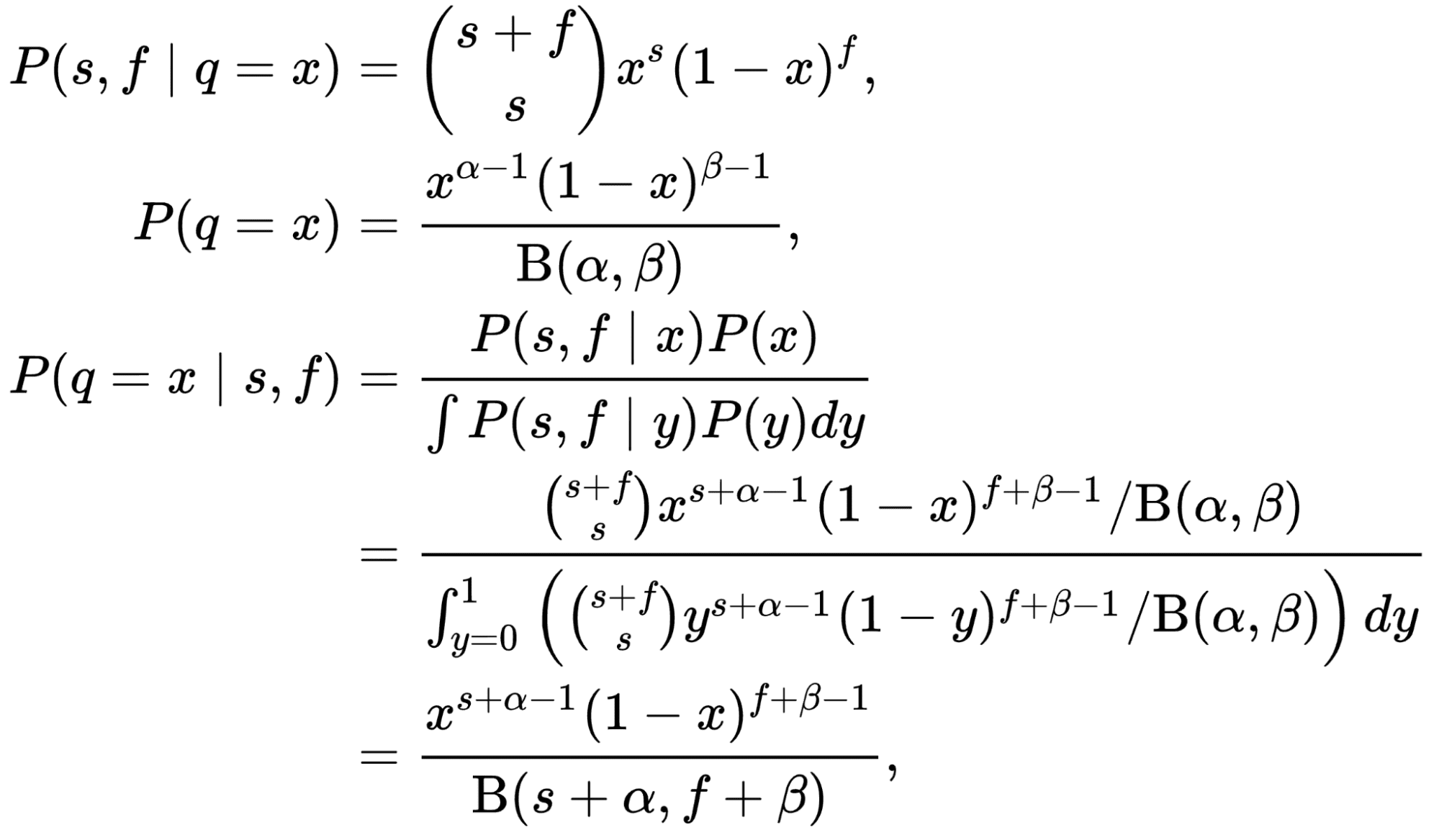
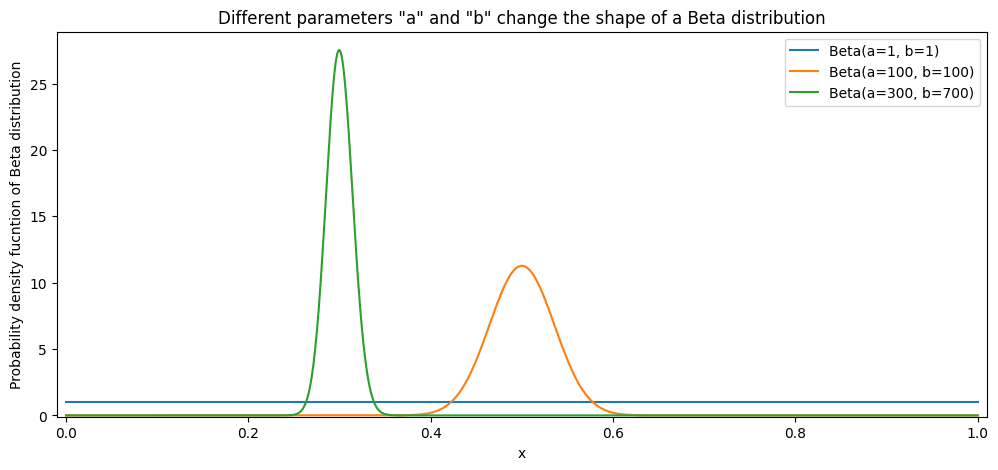
La distribution bêta est limitée par 0 et 1, ce qui en fait un candidat parfait pour modéliser une distribution de CTR. Nous pouvons partir de « a = 1 » et « b = 1 » comme paramètres de distribution bêta qui modélisent le CTR. Dans ce cas, nous n’aurions aucune conviction sur la distribution, ce qui rendrait tout CTR tout aussi probable. Ensuite, nous pouvons commencer à ajouter les données observées. Comme vous pouvez le voir, chaque « succès » ou « clic » augmente « a » de 1. Chaque « échec » ou « saut » augmente « b » de 1. Cela fausse la distribution du CTR mais ne change pas la famille de distribution. C'est encore une distribution bêta !
Nous supposons que le CTR peut être modélisé comme une distribution bêta. Ensuite, il existe deux options de titre et deux distributions. Comment choisissons-nous ce que nous montrons à un spectateur ? C’est pourquoi l’algorithme est appelé « bandit à plusieurs bras ». Au moment où un téléspectateur demande un titre, vous « tirez les deux bras » et échantillonnez les CTR. Après cela, vous comparez les valeurs et affichez un titre avec le CTR échantillonné le plus élevé. Ensuite, le spectateur clique ou saute. Si vous cliquez sur le titre, vous ajusterez le paramètre de distribution bêta de cette option « a », représentant les « succès ». Sinon, vous augmentez le paramètre de distribution bêta de cette option « b », ce qui signifie « échecs ». Cela fausse la distribution, et pour le prochain téléspectateur, il y aura une probabilité différente de choisir cette option (ou « bras ») par rapport aux autres options.
Après plusieurs itérations, l'algorithme aura une estimation des distributions CTR. L'échantillonnage de cette distribution déclenchera principalement le bras CTR le plus élevé, mais permettra toujours aux nouveaux utilisateurs d'explorer d'autres options et de réajuster l'allocation.
Eh bien, tout cela fonctionne en théorie. Est-ce vraiment mieux que la répartition 50/50 dont nous avons déjà parlé ?
Tout le code pour créer une simulation et construire des graphiques se trouve dans mon Repo GitHub.
Comme mentionné précédemment, nous n’avons le choix que parmi deux titres. Nous n'avons aucune opinion préalable sur les CTR de ce titre. Nous partons donc de a=1 et b=1 pour les deux distributions bêta. Je vais simuler un simple trafic entrant en supposant une file d'attente de téléspectateurs. Nous savons précisément si le spectateur précédent a « cliqué » ou « sauté » avant de montrer un titre au nouveau spectateur. Pour simuler les actions « clic » et « sauter », je dois définir de vrais CTR. Qu'ils soient de 5 % et 7 %. Il est essentiel de mentionner que l’algorithme ne sait rien de ces valeurs. J'en ai besoin pour simuler un clic ; vous auriez des clics réels dans le monde réel. Je lancerai une pièce de monnaie très biaisée pour chaque titre qui tombe sur face avec une probabilité de 5 % ou 7 %. S’il atterrit face, alors il y a un clic.
Ensuite, l’algorithme est simple :
- Sur la base des données observées, obtenez une distribution bêta pour chaque titre
- Exemple de CTR des deux distributions
- Comprenez quel CTR est le plus élevé et lancez une pièce de monnaie pertinente
- Comprendre s'il y a eu un clic ou non
- Augmentez le paramètre « a » de 1 s'il y a eu un clic ; augmenter le paramètre «b» de 1 s'il y a eu un saut
- Répétez jusqu'à ce qu'il y ait des utilisateurs dans la file d'attente.
Pour comprendre la qualité de l'algorithme, nous enregistrerons également une valeur représentant une part de téléspectateurs exposés à la deuxième option car elle a un CTR « réel » plus élevé. Utilisons une stratégie de répartition 50/50 comme contrepartie pour avoir une qualité de base.
Code par auteur
Après 1000 utilisateurs dans la file d'attente, notre « bandit multi-armé » a déjà une bonne compréhension de ce que sont les CTR.
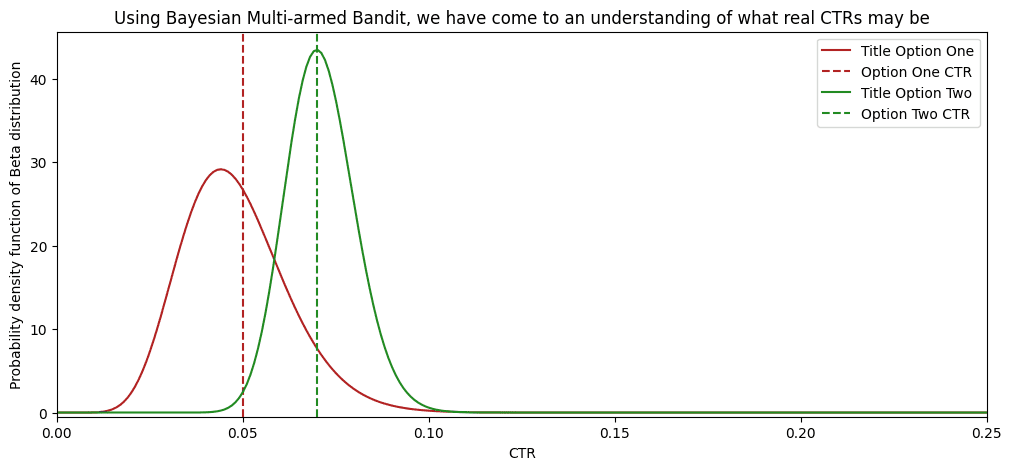
Et voici un graphique qui montre qu’une telle stratégie donne de meilleurs résultats. Après 100 téléspectateurs, le « bandit aux multiples bras » a dépassé la part de 50 % des téléspectateurs proposés pour la deuxième option. Parce que de plus en plus de preuves soutenaient le deuxième titre, l'algorithme a alloué de plus en plus de trafic au deuxième titre. Près de 80 % de tous les téléspectateurs ont vu l’option la plus performante ! Dans la répartition 50/50, seulement 50 % des personnes ont vu l’option la plus performante.
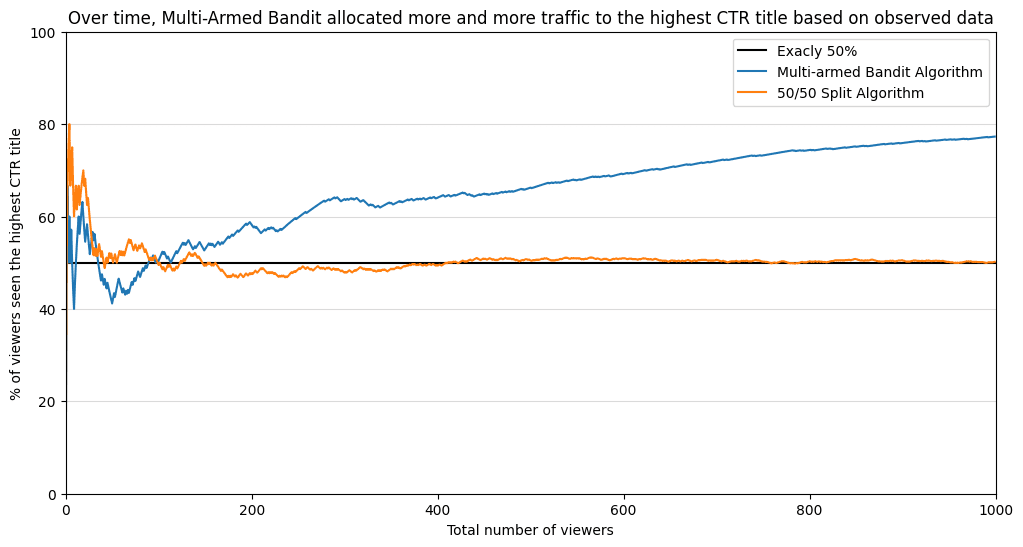
Le bandit bayésien à plusieurs bras a exposé 25 % de téléspectateurs supplémentaires à une option plus performante ! Avec davantage de données entrantes, la différence ne fera qu’augmenter entre ces deux stratégies.
Bien sûr, les « bandits multi-armés » ne sont pas parfaits. L’échantillonnage et la présentation des options en temps réel sont coûteux. Il serait préférable d’avoir une bonne infrastructure pour mettre en œuvre le tout avec la latence souhaitée. De plus, vous ne voudrez peut-être pas effrayer vos téléspectateurs en changeant de titre. Si vous avez suffisamment de trafic pour effectuer un A/B rapide, faites-le ! Ensuite, modifiez manuellement le titre une fois. Cependant, cet algorithme peut être utilisé dans de nombreuses autres applications au-delà des médias.
J'espère que vous comprenez maintenant ce qu'est un « bandit multi-armé » et comment il peut être utilisé pour choisir entre deux options adaptées aux nouvelles données. Je ne me suis pas spécifiquement concentré sur les mathématiques et les formules, car les manuels l'expliqueraient mieux. J'ai l'intention d'introduire une nouvelle technologie et de susciter l'intérêt pour elle !
Si vous avez des questions, n'hésitez pas à nous contacter LinkedIn.
Le cahier avec tout le code se trouve dans mon GitHub repo.
Igor Khomyanine est Data Scientist chez Salmon, avec des rôles antérieurs en matière de données chez Yandex et McKinsey. Je me spécialise dans l'extraction de valeur à partir de données à l'aide de statistiques et de visualisation de données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/beyond-guesswork-leveraging-bayesian-statistics-for-effective-article-title-selection?utm_source=rss&utm_medium=rss&utm_campaign=beyond-guesswork-leveraging-bayesian-statistics-for-effective-article-title-selection

