Dans le monde trépidant d'aujourd'hui, le concept de patience en tant que vertu semble s'estomper, car les gens ne veulent plus rien attendre. Si Netflix prend trop de temps à charger ou si le Lyft le plus proche est trop loin, les utilisateurs passent rapidement à d'autres options. La demande de résultats instantanés ne se limite pas aux services grand public tels que le streaming vidéo et le covoiturage ; il s'étend au domaine de Analyse des données, en particulier lorsque vous servez des utilisateurs à grande échelle et des flux de travail décisionnels automatisés. La capacité à fournir des informations en temps opportun, à prendre des décisions éclairées et à prendre des mesures immédiates sur la base de données en temps réel devient de plus en plus cruciale. Des entreprises telles que Confluent, Target et bien d'autres sont des leaders du secteur car elles exploitent des analyses en temps réel et des architectures de données qui facilitent les opérations axées sur l'analyse. Cette capacité leur permet de garder une longueur d'avance dans leurs industries respectives.
Ce billet de blog se penche sur le concept d'analyse en temps réel pour les architectes de données qui commencent à explorer les modèles de conception, en fournissant des informations sur sa définition et les blocs de construction et l'architecture de données préférés couramment utilisés dans ce domaine.
En quoi consiste exactement l'analyse en temps réel ?
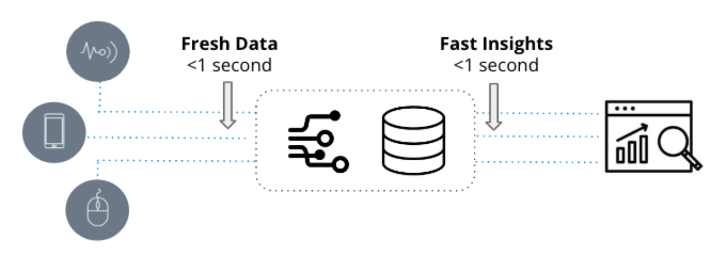
Les analyses en temps réel se caractérisent par deux qualités fondamentales : des données à jour et des informations rapides. Ils sont utilisés dans des applications urgentes où la vitesse à laquelle les nouveaux événements sont transformés en informations exploitables n'est qu'une question de secondes.
D'autre part, l'analyse traditionnelle, communément appelée l'intelligence d'entreprise, font référence à des représentations statiques de données d'entreprise principalement utilisées pour les objectifs de reporting. Ces analyses s'appuient sur des entrepôts de données tels que Snowflake et Amazon Redshift et sont visualisées via des outils d'informatique décisionnelle tels que Tableau ou PowerBI.
Contrairement aux analyses traditionnelles, qui s'appuient sur des données historiques qui peuvent dater de plusieurs jours ou semaines, les analyses en temps réel exploitent des données récentes et sont utilisées dans des flux de travail opérationnels qui nécessitent des réponses rapides à des demandes potentiellement complexes.

Par exemple, considérez un responsable de la chaîne d'approvisionnement qui recherche les tendances historiques des variations mensuelles des stocks. Dans ce scénario, l'analytique traditionnelle est le choix idéal car le dirigeant peut se permettre d'attendre quelques minutes supplémentaires pour que le rapport soit traité. D'autre part, une équipe d'opérations de sécurité vise à détecter et diagnostiquer les anomalies dans le trafic réseau. C'est là que l'analyse en temps réel entre en jeu, car l'équipe SecOps a besoin d'une analyse rapide de milliers à des millions d'entrées de journal en temps réel à des intervalles inférieurs à la seconde pour identifier les modèles et enquêter sur les comportements anormaux.
Le choix de l'architecture est-il significatif ?
De nombreux fournisseurs de bases de données prétendent être adaptés à l'analyse en temps réel, et ils ont certaines capacités à cet égard. Par exemple, considérez le scénario de la surveillance météorologique, où les relevés de température doivent être échantillonnés toutes les secondes à partir de milliers de stations météorologiques, et les requêtes impliquent des alertes basées sur des seuils et une analyse des tendances. SingleStore, InfluxDB, MongoDB et même PostgreSQL peuvent gérer cela facilement. En créant une API push pour envoyer les métriques directement à la base de données et en exécutant une requête simple, des analyses en temps réel peuvent être réalisées.
Alors, quand la complexité de l'analyse en temps réel augmente-t-elle ? Dans l'exemple mentionné, l'ensemble de données est relativement petit et les analyses impliquées sont simples. Avec un seul événement de température généré par seconde et une requête SELECT simple avec une instruction WHERE pour récupérer les derniers événements, une puissance de traitement minimale est requise, ce qui le rend gérable pour toute série chronologique ou base de données OLTP.
Les véritables défis se présentent et les bases de données sont poussées à leurs limites lorsque le volume d'événements ingérés augmente, les requêtes deviennent plus complexes avec de nombreuses dimensions et les ensembles de données atteignent des téraoctets, voire des pétaoctets. Alors qu'Apache Cassandra est souvent considéré pour l'ingestion à haut débit, ses performances d'analyse peuvent ne pas répondre aux attentes. Dans les cas où le cas d'utilisation de l'analyse nécessite de joindre plusieurs sources de données en temps réel à grande échelle, des solutions alternatives doivent être explorées.
Voici quelques facteurs à prendre en compte qui aideront à déterminer les spécifications nécessaires pour l'architecture appropriée :
- Travaillez-vous avec un nombre élevé d'événements par seconde, allant de milliers à des millions ?
- Est-il important de minimiser la latence entre les événements créés et le moment où ils peuvent être interrogés ?
- Votre ensemble de données total est-il volumineux, et pas seulement quelques Go ?
- Quelle est l'importance des performances des requêtes (moins d'une seconde ou de quelques minutes par requête) ?
- À quel point les requêtes sont-elles compliquées, exportant quelques lignes ou des agrégations à grande échelle ?
- Est-il important d'éviter les temps d'arrêt du flux de données et du moteur d'analyse ?
- Essayez-vous de joindre plusieurs flux d'événements à des fins d'analyse ?
- Avez-vous besoin de mettre en contexte des données en temps réel avec des données historiques ?
- Prévoyez-vous de nombreuses requêtes simultanées ?
Si l'un de ces aspects est pertinent, discutons des caractéristiques de l'architecture idéale.
Blocs de construction
L'analyse en temps réel nécessite plus qu'une simple base de données performante. Cela commence par la nécessité d'établir des connexions, de transmettre et de gérer des données en temps réel, ce qui nous amène à l'élément fondamental initial : le streaming d'événements.
1. Diffusion d'événements
Dans les situations où le temps réel est de la plus haute importance, les pipelines de données conventionnels basés sur des lots ont tendance à arriver trop tard, ce qui donne lieu à l'émergence de files d'attente de messagerie. Dans le passé, la livraison des messages reposait sur des outils comme ActiveMQ, RabbitMQ et TIBCO. Cependant, l'approche contemporaine implique la diffusion d'événements avec des technologies telles qu'Apache Kafka et Amazon Kinesis.
Apache Kafka et Amazon Kinesis résolvent les limitations d'évolutivité souvent rencontrées avec les files d'attente de messagerie traditionnelles, en autorisant des mécanismes de publication/abonnement à haut débit pour collecter et distribuer efficacement des flux étendus de données d'événements provenant de diverses sources (appelées producteurs dans la terminologie Amazon) vers diverses destinations ( appelés consommateurs dans la terminologie d'Amazon) en temps réel.
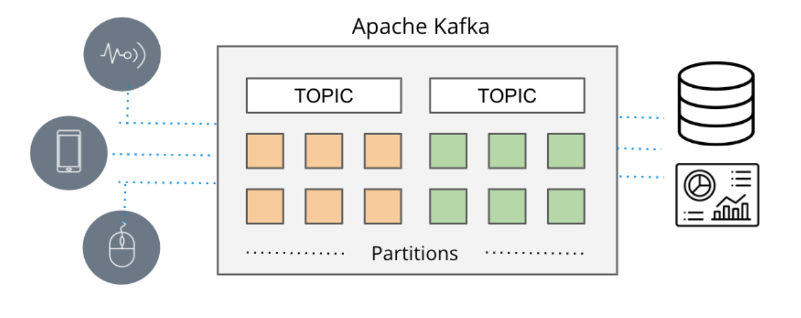
Ces systèmes acquièrent de manière transparente des données en temps réel à partir d'une gamme de sources telles que des bases de données, des capteurs et des services cloud, les encapsulant sous forme de flux d'événements et facilitant leur transmission à d'autres applications, bases de données et services.
Compte tenu de leur évolutivité impressionnante (comme en témoigne la prise en charge par Apache Kafka de plus de sept billions de messages par jour sur LinkedIn) et de leur capacité à prendre en charge de nombreuses sources de données simultanées, le streaming d'événements est devenu le mécanisme dominant pour fournir des données en temps réel dans les applications.
Maintenant que nous avons la capacité de capturer des données en temps réel, la prochaine étape consiste à explorer comment nous pouvons les analyser en temps réel.
2. Base de données d'analyse en temps réel
L'analyse en temps réel nécessite une base de données spécialisée qui peut pleinement exploiter les données de streaming d'Apache Kafka et d'Amazon Kinesis, fournissant des informations en temps réel. Druide Apache est précisément cette base de données.
Apache Druid est devenu la base de données préférée pour les applications d'analyse en temps réel en raison de ses hautes performances et de sa capacité à gérer les données en continu. Avec sa prise en charge d'une véritable ingestion de flux et le traitement efficace de gros volumes de données dans des délais inférieurs à la seconde, même sous de lourdes charges, Apache Druid excelle dans la fourniture d'informations rapides sur les nouvelles données. Son intégration transparente avec Apache Kafka et Amazon Kinesis renforce encore sa position de choix incontournable pour l'analyse en temps réel.
Lors du choix d'une base de données d'analyse pour le streaming de données, des considérations telles que l'échelle, la latence et la qualité des données sont cruciales. La capacité à gérer l'ensemble de la diffusion d'événements, à ingérer et à corréler plusieurs rubriques Kafka ou fragments Kinesis, à prendre en charge l'ingestion basée sur les événements et à garantir l'intégrité des données pendant les perturbations sont des exigences clés. Apache Druid répond non seulement à ces critères, mais va au-delà pour répondre à ces attentes et fournir des fonctionnalités supplémentaires.
Druid a été délibérément conçu pour exceller dans l'ingestion rapide et l'interrogation en temps réel des événements au fur et à mesure qu'ils arrivent. Il a une approche unique pour diffuser des données, ingérant des événements sur une base individuelle plutôt que de s'appuyer sur des fichiers de données séquentiels par lots pour simuler un flux. Cela élimine le besoin de connecteurs vers Kafka ou Kinesis. De plus, Druid assure Qualité des données en prenant en charge la sémantique exactement une fois, garantissant l'intégrité et l'exactitude des données ingérées.
Comme Apache Kafka, Apache Druid a été spécialement conçu pour gérer les données d'événements à l'échelle d'Internet. Son architecture basée sur les services permet une évolutivité indépendante de l'ingestion et du traitement des requêtes, ce qui lui permet d'évoluer presque à l'infini. En mappant les tâches d'ingestion avec les partitions Kafka, Druid évolue de manière transparente avec les clusters Kafka, garantissant un traitement efficace et parallèle des données.
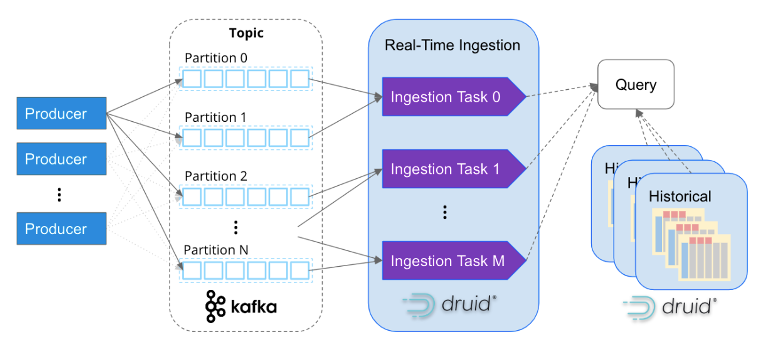
Il est de plus en plus courant pour les entreprises d'ingérer des millions d'événements par seconde dans Apache Druid. Par exemple, Confluent, les créateurs de Kafka, a construit sa plate-forme d'observabilité à l'aide de Druid et ingère avec succès plus de cinq millions d'événements par seconde à partir de Kafka. Cela met en valeur l'évolutivité et les capacités hautes performances de Druid dans la gestion de volumes d'événements massifs.
Cependant, l'analyse en temps réel va au-delà du simple accès aux données en temps réel. Pour mieux comprendre les modèles et les comportements, il est également essentiel de corréler les données historiques. Apache Druid excelle à cet égard, comme illustré dans le diagramme ci-dessus, en prenant en charge de manière transparente l'analyse en temps réel et historique via une seule requête SQL. Druid gère efficacement de gros volumes de données, jusqu'à des pétaoctets, en arrière-plan, permettant des analyses complètes et intégrées sur différentes périodes.
Lorsque tous les éléments sont réunis, une architecture de données hautement évolutive pour l'analyse en temps réel émerge. Cette architecture est le choix préféré de milliers d'architectes de données lorsqu'ils ont besoin d'une évolutivité élevée, d'une faible latence et de la capacité d'effectuer des agrégations complexes sur des données en temps réel. En tirant parti du streaming d'événements avec Apache Kafka ou Amazon Kinesis, combiné à la puissance d'Apache Druid pour une analyse efficace en temps réel et historique, les organisations peuvent obtenir des informations solides et complètes à partir de leurs données.
Étude de cas : Garantir une expérience de visionnage de premier ordre – L'approche Netflix
L'analyse en temps réel est un élément essentiel dans la poursuite incessante de Netflix pour offrir une expérience exceptionnelle à plus de 200 millions d'utilisateurs, qui consomment collectivement 250 millions d'heures de contenu par jour. Avec une application d'observabilité conçue pour la surveillance en temps réel, Netflix supervise efficacement plus de 300 millions d'appareils pour garantir des performances optimales et la satisfaction des clients.

En tirant parti des journaux en temps réel générés par les appareils de lecture, qui sont diffusés de manière transparente via Apache Kafka et ingérés événement par événement dans Apache Druid, Netflix obtient des informations précieuses et des mesures quantifiables concernant les performances des appareils des utilisateurs pendant les activités de navigation et de lecture.
Avec un débit étonnant de plus de deux millions d'événements par seconde et des requêtes ultra-rapides en moins d'une seconde exécutées sur un ensemble de données massif de 1.5 billion de lignes, les ingénieurs de Netflix possèdent la capacité d'identifier et d'enquêter avec précision sur les anomalies au sein de leur infrastructure, l'activité des terminaux et le flux de contenu. .
Débloquez des informations en temps réel avec Apache Druid, Apache Kafka et Amazon Kinesis
Si vous êtes intéressé par la construction de solutions d'analyse en temps réel, je vous encourage fortement à explorer Apache Druid en conjonction avec Apache Kafka et Amazon Kinesis.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://www.dataversity.net/architecting-real-time-analytics-for-speed-and-scale/

