Cet article est co-écrit avec Chaoyang He, Al Nevarez et Salman Avestimehr de FedML.
De nombreuses organisations mettent en œuvre l'apprentissage automatique (ML) pour améliorer leur prise de décision commerciale grâce à l'automatisation et à l'utilisation de grands ensembles de données distribuées. Avec un accès accru aux données, le ML a le potentiel de fournir des informations et des opportunités commerciales sans précédent. Cependant, le partage d’informations sensibles brutes et non nettoyées entre différents sites présente des risques importants en matière de sécurité et de confidentialité, en particulier dans les secteurs réglementés tels que la santé.
Pour résoudre ce problème, l'apprentissage fédéré (FL) est une technique de formation ML décentralisée et collaborative qui offre la confidentialité des données tout en maintenant l'exactitude et la fidélité. Contrairement à la formation ML traditionnelle, la formation FL se déroule dans un emplacement client isolé à l'aide d'une session sécurisée indépendante. Le client partage uniquement ses paramètres de modèle de sortie avec un serveur centralisé, appelé coordinateur de formation ou serveur d'agrégation, et non les données réelles utilisées pour former le modèle. Cette approche atténue de nombreux problèmes de confidentialité des données tout en permettant une collaboration efficace sur la formation des modèles.
Bien que FL soit une étape vers une meilleure confidentialité et sécurité des données, ce n’est pas une solution garantie. Les réseaux non sécurisés dépourvus de contrôle d’accès et de cryptage peuvent néanmoins exposer des informations sensibles aux attaquants. De plus, les informations formées localement peuvent exposer des données privées si elles sont reconstruites via une attaque par inférence. Pour atténuer ces risques, le modèle FL utilise des algorithmes de formation personnalisés ainsi qu'un masquage et un paramétrage efficaces avant de partager les informations avec le coordinateur de la formation. Des contrôles de réseau stricts sur des sites locaux et centralisés peuvent réduire davantage les risques d’inférence et d’exfiltration.
Dans cet article, nous partageons une approche FL utilisant FedML, Service Amazon Elastic Kubernetes (Amazon EKS), et Amazon Sage Maker pour améliorer les résultats pour les patients tout en répondant aux problèmes de confidentialité et de sécurité des données.
La nécessité d’un apprentissage fédéré dans le domaine de la santé
Les soins de santé s'appuient fortement sur des sources de données distribuées pour effectuer des prévisions et des évaluations précises sur les soins aux patients. Limiter les sources de données disponibles pour protéger la confidentialité affecte négativement l’exactitude des résultats et, en fin de compte, la qualité des soins aux patients. Par conséquent, le ML crée des défis pour les clients AWS qui doivent garantir la confidentialité et la sécurité dans les entités distribuées sans compromettre les résultats pour les patients.
Les organisations de soins de santé doivent se conformer à des réglementations de conformité strictes, telles que la Health Insurance Portability and Accountability Act (HIPAA) aux États-Unis, lors de la mise en œuvre de solutions FL. Garantir la confidentialité, la sécurité et la conformité des données devient encore plus critique dans le secteur des soins de santé, nécessitant un cryptage robuste, des contrôles d'accès, des mécanismes d'audit et des protocoles de communication sécurisés. De plus, les ensembles de données de santé contiennent souvent des types de données complexes et hétérogènes, ce qui rend la standardisation et l'interopérabilité des données un défi dans les contextes FL.
Présentation des cas d'utilisation
Le cas d'utilisation décrit dans cet article concerne les données sur les maladies cardiaques dans différentes organisations, sur lesquelles un modèle ML exécutera des algorithmes de classification pour prédire la maladie cardiaque chez le patient. Étant donné que ces données concernent plusieurs organisations, nous utilisons l’apprentissage fédéré pour rassembler les résultats.
La Ensemble de données sur les maladies cardiaques du référentiel d'apprentissage automatique de l'Université de Californie à Irvine est un ensemble de données largement utilisé pour la recherche cardiovasculaire et la modélisation prédictive. Il se compose de 303 échantillons, chacun représentant un patient, et contient une combinaison d'attributs cliniques et démographiques, ainsi que la présence ou l'absence de maladie cardiaque.
Cet ensemble de données multivariées comporte 76 attributs dans les informations sur le patient, parmi lesquels 14 attributs sont les plus couramment utilisés pour développer et évaluer des algorithmes de ML afin de prédire la présence d'une maladie cardiaque sur la base des attributs donnés.
Cadre FedML
Il existe un large choix de frameworks FL, mais nous avons décidé d'utiliser le Cadre FedML pour ce cas d'utilisation car il est open source et prend en charge plusieurs paradigmes FL. FedML fournit une bibliothèque open source populaire, une plateforme MLOps et un écosystème d'applications pour FL. Ceux-ci facilitent le développement et le déploiement de solutions FL. Il fournit une suite complète d'outils, de bibliothèques et d'algorithmes qui permettent aux chercheurs et aux praticiens de mettre en œuvre et d'expérimenter des algorithmes FL dans un environnement distribué. FedML relève les défis de la confidentialité des données, de la communication et de l'agrégation de modèles en FL, en offrant une interface conviviale et des composants personnalisables. En mettant l'accent sur la collaboration et le partage des connaissances, FedML vise à accélérer l'adoption de FL et à stimuler l'innovation dans ce domaine émergent. Le framework FedML est indépendant du modèle, y compris la prise en charge récemment ajoutée des grands modèles de langage (LLM). Pour plus d'informations, reportez-vous à Sortie de FedLLM : créez vos propres modèles de langage étendus sur des données propriétaires à l'aide de la plate-forme FedML.
Poulpe FedML
La hiérarchie et l'hétérogénéité du système constituent un défi majeur dans les cas d'utilisation réels de FL, où différents silos de données peuvent avoir une infrastructure différente avec CPU et GPU. Dans de tels scénarios, vous pouvez utiliser Poulpe FedML.
FedML Octopus est la plateforme de qualité industrielle de FL cross-silo pour la formation inter-organisations et inter-comptes. Couplé à FedML MLOps, il permet aux développeurs ou aux organisations de mener une collaboration ouverte de n'importe où et à n'importe quelle échelle de manière sécurisée. FedML Octopus exécute un paradigme de formation distribuée au sein de chaque silo de données et utilise des formations synchrones ou asynchrones.
MLOps FedML
FedML MLOps permet le développement local de code qui peut ensuite être déployé n'importe où à l'aide des frameworks FedML. Avant de lancer la formation, vous devez créer un compte FedML, ainsi que créer et télécharger les packages serveur et client dans FedML Octopus. Pour plus de détails, reportez-vous à mesures ainsi que Présentation de FedML Octopus : mettre l'apprentissage fédéré à l'échelle de la production avec des MLOps simplifiés.
Vue d'ensemble de la solution
Nous déployons FedML dans plusieurs clusters EKS intégrés à SageMaker pour le suivi des expériences. Nous utilisons Plans Amazon EKS pour Terraform pour déployer l'infrastructure requise. EKS Blueprints aide à composer des clusters EKS complets entièrement amorcés avec le logiciel opérationnel nécessaire au déploiement et à l'exploitation des charges de travail. Avec EKS Blueprints, la configuration de l'état souhaité de l'environnement EKS, tel que le plan de contrôle, les nœuds de travail et les modules complémentaires Kubernetes, est décrite comme un plan d'infrastructure en tant que code (IaC). Une fois qu'un plan est configuré, il peut être utilisé pour créer des environnements cohérents sur plusieurs comptes AWS et régions à l'aide de l'automatisation du déploiement continu.
Le contenu partagé dans cet article reflète des situations et des expériences réelles, mais il est important de noter que le déploiement de ces situations dans différents endroits peut varier. Bien que nous utilisions un seul compte AWS avec des VPC distincts, il est essentiel de comprendre que les circonstances et configurations individuelles peuvent différer. Par conséquent, les informations fournies doivent être utilisées comme guide général et peuvent nécessiter une adaptation en fonction des exigences spécifiques et des conditions locales.
Le diagramme suivant illustre notre architecture de solution.
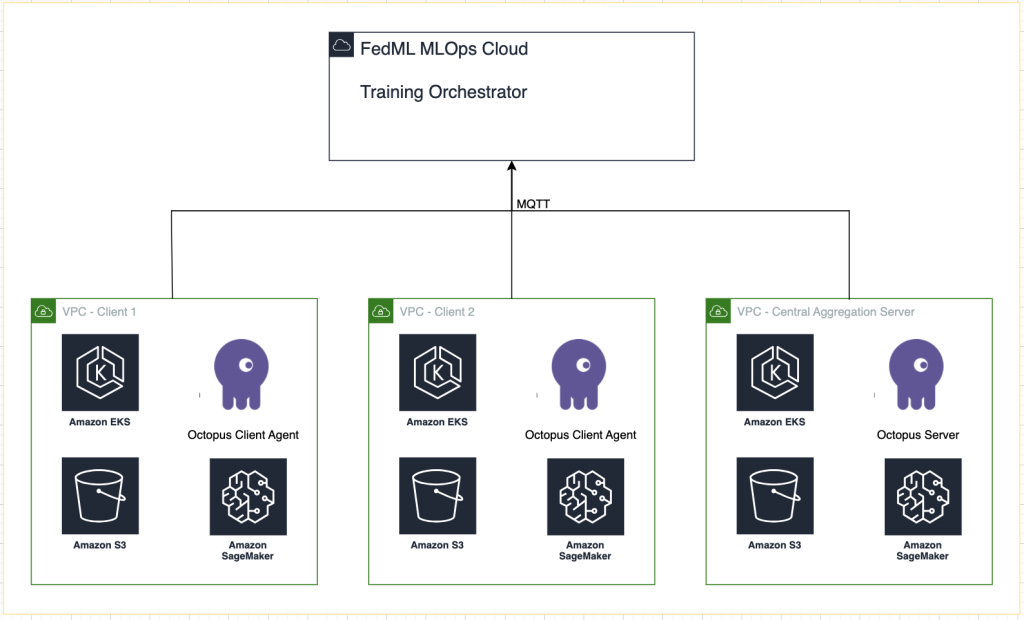
En plus du suivi fourni par FedML MLOps pour chaque exécution de formation, nous utilisons Expériences Amazon SageMaker pour suivre les performances de chaque modèle client et du modèle centralisé (agrégateur).
SageMaker Experiments est une fonctionnalité de SageMaker qui vous permet de créer, gérer, analyser et comparer vos expériences ML. En enregistrant les détails, les paramètres et les résultats des expériences, les chercheurs peuvent reproduire et valider avec précision leur travail. Il permet une comparaison et une analyse efficaces des différentes approches, conduisant à une prise de décision éclairée. De plus, le suivi des expériences facilite l'amélioration itérative en fournissant des informations sur la progression des modèles et en permettant aux chercheurs de tirer les leçons des itérations précédentes, accélérant ainsi le développement de solutions plus efficaces.
Nous envoyons les éléments suivants à SageMaker Experiments pour chaque exécution :
- Métriques d'évaluation du modèle – Perte d’entraînement et zone sous la courbe (AUC)
- Hyperparamètres – Époque, taux d’apprentissage, taille du lot, optimiseur et perte de poids
Pré-requis
Pour suivre cet article, vous devez avoir les prérequis suivants :
Déployez la solution
Pour commencer, clonez localement le dépôt hébergeant l'exemple de code :
Déployez ensuite l'infrastructure du cas d'utilisation à l'aide des commandes suivantes :
Le déploiement complet du modèle Terraform peut prendre 20 à 30 minutes. Une fois déployée, suivez les étapes des sections suivantes pour exécuter l'application FL.
Créer un package de déploiement MLOps
Dans le cadre de la documentation FedML, nous devons créer les packages client et serveur, que la plate-forme MLOps distribuera au serveur et aux clients pour commencer la formation.
Pour créer ces packages, exécutez le script suivant trouvé dans le répertoire racine :
Cela créera les packages respectifs dans le répertoire suivant du répertoire racine du projet :
Téléchargez les packages sur la plateforme FedML MLOps
Effectuez les étapes suivantes pour télécharger les packages :
- Sur l'interface utilisateur FedML, choisissez mes applications dans le volet de navigation.
- Selectionnez Nouvelle application.
- Téléchargez les packages client et serveur depuis votre poste de travail.
- Vous pouvez également ajuster les hyperparamètres ou en créer de nouveaux.

Déclencher une formation fédérée
Pour exécuter une formation fédérée, procédez comme suit :
- Sur l'interface utilisateur FedML, choisissez Liste des projets dans le volet de navigation.
- Selectionnez Créer un nouveau projet.
- Saisissez un nom de groupe et un nom de projet, puis choisissez OK.

- Choisissez le projet nouvellement créé et choisissez Créer une nouvelle course pour déclencher une course d'entraînement.
- Sélectionnez les appareils clients Edge et le serveur agrégateur central pour cette exécution de formation.
- Choisissez l'application que vous avez créée lors des étapes précédentes.

- Mettez à jour l’un des hyperparamètres ou utilisez les paramètres par défaut.
- Selectionnez Accueil pour commencer la formation.

- Choisissez le Statut de la formation et attendez la fin de l'entraînement. Vous pouvez également accéder aux onglets disponibles.
- Une fois la formation terminée, choisissez le Système pour voir les durées de formation sur vos serveurs Edge et les événements d'agrégation.
Afficher les résultats et les détails de l'expérience
Une fois la formation terminée, vous pouvez visualiser les résultats à l'aide de FedML et SageMaker.
Sur l'interface utilisateur FedML, sur le Des modèles photo , vous pouvez voir l'agrégateur et le modèle client. Vous pouvez également télécharger ces modèles depuis le site Web.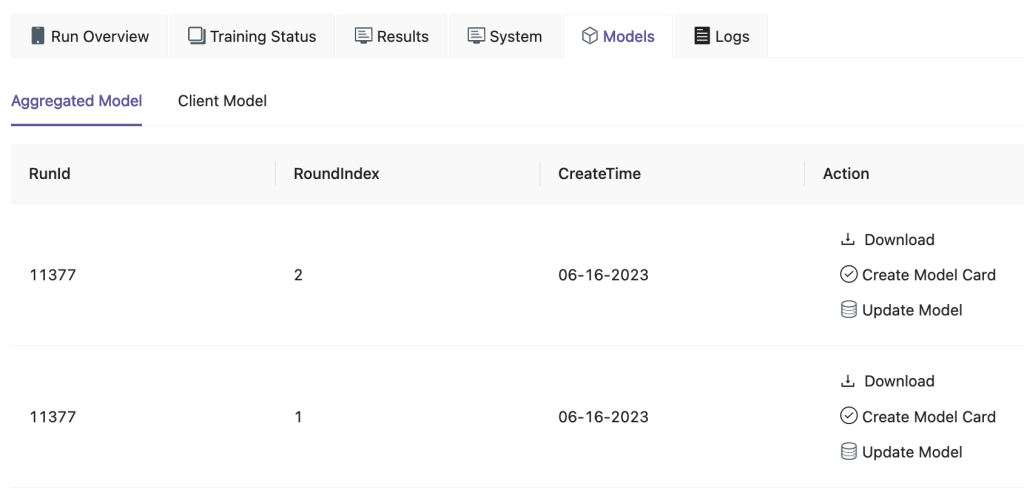
Vous pouvez également vous connecter à Amazon SageMakerStudio et choisissez Expériences dans le volet de navigation.
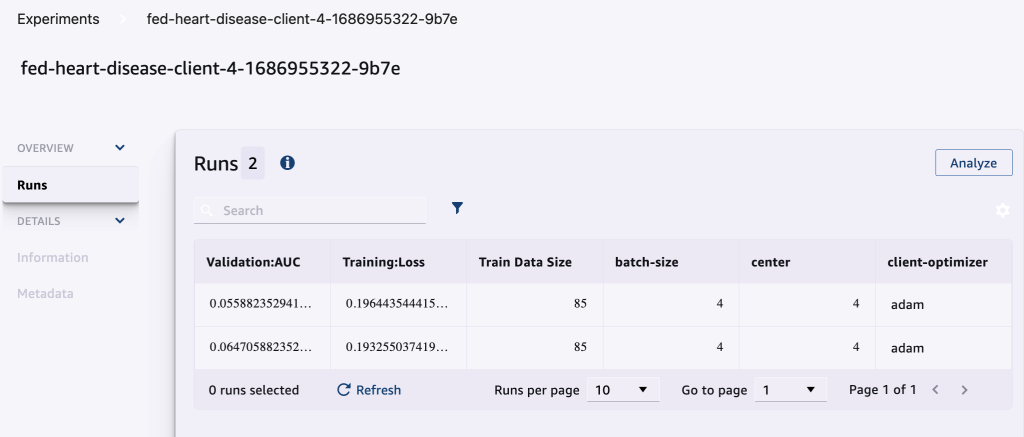
La capture d'écran suivante montre les expériences enregistrées.
Code de suivi du test
Dans cette section, nous explorons le code qui intègre le suivi des expériences SageMaker à la formation du framework FL.
Dans un éditeur de votre choix, ouvrez le dossier suivant pour voir les modifications apportées au code pour injecter le code de suivi des expériences SageMaker dans le cadre de la formation :
Pour le suivi de la formation, nous créer une expérience SageMaker avec des paramètres et des métriques enregistrés à l'aide du log_parameter ainsi que log_metric commande comme indiqué dans l’exemple de code suivant.
Une entrée dans le config/fedml_config.yaml file déclare le préfixe de l'expérience, qui est référencé dans le code pour créer des noms d'expérience uniques : sm_experiment_name: "fed-heart-disease". Vous pouvez le mettre à jour avec n'importe quelle valeur de votre choix.
Par exemple, consultez le code suivant pour le heart_disease_trainer.py, qui est utilisé par chaque client pour entraîner le modèle sur son propre ensemble de données :
Pour chaque exécution client, les détails de l'expérience sont suivis à l'aide du code suivant dans heart_disease_trainer.py :
De même, vous pouvez utiliser le code dans heart_disease_aggregator.py pour exécuter un test sur les données locales après la mise à jour des poids du modèle. Les détails sont enregistrés après chaque communication avec les clients.
Nettoyer
Lorsque vous avez terminé avec la solution, assurez-vous de nettoyer les ressources utilisées pour garantir une utilisation efficace des ressources et une gestion des coûts, et éviter les dépenses inutiles et le gaspillage de ressources. Un nettoyage actif de l'environnement, comme la suppression des instances inutilisées, l'arrêt des services inutiles et la suppression des données temporaires, contribue à une infrastructure propre et organisée. Vous pouvez utiliser le code suivant pour nettoyer vos ressources :
Résumé
En utilisant Amazon EKS comme infrastructure et FedML comme cadre pour FL, nous sommes en mesure de fournir un environnement évolutif et géré pour la formation et le déploiement de modèles partagés tout en respectant la confidentialité des données. Grâce à la nature décentralisée de FL, les organisations peuvent collaborer en toute sécurité, libérer le potentiel des données distribuées et améliorer les modèles de ML sans compromettre la confidentialité des données.
Comme toujours, AWS accueille vos commentaires. Veuillez laisser vos réflexions et vos questions dans la section commentaires.
À propos des auteurs
 Randy DeFauw est architecte principal de solutions senior chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. Il est entré dans l’espace du Big Data en 2013 et continue d’explorer ce domaine. Il travaille activement sur des projets dans le domaine du ML et a fait des présentations à de nombreuses conférences, notamment Strata et GlueCon.
Randy DeFauw est architecte principal de solutions senior chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. Il est entré dans l’espace du Big Data en 2013 et continue d’explorer ce domaine. Il travaille activement sur des projets dans le domaine du ML et a fait des présentations à de nombreuses conférences, notamment Strata et GlueCon.
 Arnab Sinha est un architecte de solutions senior pour AWS, agissant en tant que directeur technique sur le terrain pour aider les organisations à concevoir et à créer des solutions évolutives prenant en charge les résultats commerciaux dans les migrations de centres de données, la transformation numérique et la modernisation des applications, le Big Data et l'apprentissage automatique. Il a accompagné des clients dans divers secteurs, notamment l'énergie, la vente au détail, la fabrication, la santé et les sciences de la vie. Arnab détient toutes les certifications AWS, y compris la certification ML Specialty. Avant de rejoindre AWS, Arnab était un leader technologique et occupait auparavant des postes de direction en matière d'architecte et d'ingénierie.
Arnab Sinha est un architecte de solutions senior pour AWS, agissant en tant que directeur technique sur le terrain pour aider les organisations à concevoir et à créer des solutions évolutives prenant en charge les résultats commerciaux dans les migrations de centres de données, la transformation numérique et la modernisation des applications, le Big Data et l'apprentissage automatique. Il a accompagné des clients dans divers secteurs, notamment l'énergie, la vente au détail, la fabrication, la santé et les sciences de la vie. Arnab détient toutes les certifications AWS, y compris la certification ML Specialty. Avant de rejoindre AWS, Arnab était un leader technologique et occupait auparavant des postes de direction en matière d'architecte et d'ingénierie.
 Prachi Kulkarni est architecte de solutions senior chez AWS. Sa spécialisation est l'apprentissage automatique et elle travaille activement à la conception de solutions utilisant diverses offres AWS ML, Big Data et analytiques. Prachi possède de l'expérience dans plusieurs domaines, notamment les soins de santé, les avantages sociaux, la vente au détail et l'éducation, et a occupé divers postes dans les domaines de l'ingénierie et de l'architecture de produits, de la gestion et de la réussite des clients.
Prachi Kulkarni est architecte de solutions senior chez AWS. Sa spécialisation est l'apprentissage automatique et elle travaille activement à la conception de solutions utilisant diverses offres AWS ML, Big Data et analytiques. Prachi possède de l'expérience dans plusieurs domaines, notamment les soins de santé, les avantages sociaux, la vente au détail et l'éducation, et a occupé divers postes dans les domaines de l'ingénierie et de l'architecture de produits, de la gestion et de la réussite des clients.
 Dompteur Chérif est architecte de solutions principal chez AWS, avec une expérience diversifiée dans le domaine des services de conseil en technologie et aux entreprises, s'étalant sur plus de 17 ans en tant qu'architecte de solutions. En mettant l'accent sur les infrastructures, l'expertise de Tamer couvre un large éventail de secteurs industriels verticaux, notamment le commerce, la santé, l'automobile, le secteur public, la fabrication, le pétrole et le gaz, les services médiatiques, etc. Ses compétences s'étendent à divers domaines, tels que l'architecture cloud, l'informatique de pointe, les réseaux, le stockage, la virtualisation, la productivité des entreprises et le leadership technique.
Dompteur Chérif est architecte de solutions principal chez AWS, avec une expérience diversifiée dans le domaine des services de conseil en technologie et aux entreprises, s'étalant sur plus de 17 ans en tant qu'architecte de solutions. En mettant l'accent sur les infrastructures, l'expertise de Tamer couvre un large éventail de secteurs industriels verticaux, notamment le commerce, la santé, l'automobile, le secteur public, la fabrication, le pétrole et le gaz, les services médiatiques, etc. Ses compétences s'étendent à divers domaines, tels que l'architecture cloud, l'informatique de pointe, les réseaux, le stockage, la virtualisation, la productivité des entreprises et le leadership technique.
 Hans Nesbitt est un architecte de solutions senior chez AWS basé en Californie du Sud. Il travaille avec des clients de l'ouest des États-Unis pour créer des architectures cloud hautement évolutives, flexibles et résilientes. Dans ses temps libres, il aime passer du temps avec sa famille, cuisiner et jouer de la guitare.
Hans Nesbitt est un architecte de solutions senior chez AWS basé en Californie du Sud. Il travaille avec des clients de l'ouest des États-Unis pour créer des architectures cloud hautement évolutives, flexibles et résilientes. Dans ses temps libres, il aime passer du temps avec sa famille, cuisiner et jouer de la guitare.
 Chaoyang-il est co-fondateur et CTO de FedML, Inc., une startup qui œuvre pour une communauté développant une IA ouverte et collaborative de n'importe où et à n'importe quelle échelle. Ses recherches portent sur les algorithmes, systèmes et applications d’apprentissage automatique distribués et fédérés. Il a obtenu son doctorat en informatique de l'Université de Californie du Sud.
Chaoyang-il est co-fondateur et CTO de FedML, Inc., une startup qui œuvre pour une communauté développant une IA ouverte et collaborative de n'importe où et à n'importe quelle échelle. Ses recherches portent sur les algorithmes, systèmes et applications d’apprentissage automatique distribués et fédérés. Il a obtenu son doctorat en informatique de l'Université de Californie du Sud.
 Al Névarez est directeur de la gestion des produits chez FedML. Avant FedML, il était chef de produit de groupe chez Google et directeur principal de la science des données chez LinkedIn. Il possède plusieurs brevets liés aux produits de données et a étudié l'ingénierie à l'Université de Stanford.
Al Névarez est directeur de la gestion des produits chez FedML. Avant FedML, il était chef de produit de groupe chez Google et directeur principal de la science des données chez LinkedIn. Il possède plusieurs brevets liés aux produits de données et a étudié l'ingénierie à l'Université de Stanford.
 Salman Avestimehr est co-fondateur et PDG de FedML. Il a été professeur du doyen à l'USC, directeur du USC-Amazon Center on Trustworthy AI et Amazon Scholar en Alexa AI. Il est un expert en apprentissage automatique fédéré et décentralisé, en théorie de l'information, en sécurité et en confidentialité. Il est membre de l'IEEE et a obtenu son doctorat en EECS à l'UC Berkeley.
Salman Avestimehr est co-fondateur et PDG de FedML. Il a été professeur du doyen à l'USC, directeur du USC-Amazon Center on Trustworthy AI et Amazon Scholar en Alexa AI. Il est un expert en apprentissage automatique fédéré et décentralisé, en théorie de l'information, en sécurité et en confidentialité. Il est membre de l'IEEE et a obtenu son doctorat en EECS à l'UC Berkeley.
 Samir garçon est un technologue d'entreprise accompli chez AWS qui travaille en étroite collaboration avec les dirigeants de niveau C des clients. En tant qu'ancien cadre supérieur ayant piloté des transformations dans plusieurs sociétés Fortune 100, Samir partage ses précieuses expériences pour aider ses clients à réussir leur propre parcours de transformation.
Samir garçon est un technologue d'entreprise accompli chez AWS qui travaille en étroite collaboration avec les dirigeants de niveau C des clients. En tant qu'ancien cadre supérieur ayant piloté des transformations dans plusieurs sociétés Fortune 100, Samir partage ses précieuses expériences pour aider ses clients à réussir leur propre parcours de transformation.
 Stephen Kraemer est conseiller du conseil d'administration et du CxO et ancien cadre chez AWS. Stephen prône la culture et le leadership comme fondements du succès. Il considère que la sécurité et l'innovation sont les moteurs de la transformation du cloud, permettant aux organisations hautement compétitives et axées sur les données.
Stephen Kraemer est conseiller du conseil d'administration et du CxO et ancien cadre chez AWS. Stephen prône la culture et le leadership comme fondements du succès. Il considère que la sécurité et l'innovation sont les moteurs de la transformation du cloud, permettant aux organisations hautement compétitives et axées sur les données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

